1. Introduction
As one of the most significant sources of marine pollution, oil spills have caused serious environmental and economic impacts to the ocean and coastal zone [
1]. Oil spills near the coast can be caused by ship accidents, explosion of oil rig platforms, broken pipelines, and deliberate discharge of tank-cleaning wastewater from ships. The NEREIDs program, sponsored by the European Commission, was the first robust attempt to use shipping, geological and metocean data to characterize oil spills in one of the major oil exploration areas of the world, prior to any major oil spill accident. Based on this data, oil spill models were established to simulate the development and trajectories of oil spills and investigate the susceptibility of coastal zone and find suitable measures to alleviate its impacts to the environment [
2,
3,
4,
5].
Early warning and near-real-time monitoring of oil slicks plays a very important role in cleaning up operation of oil spill to alleviate its impact to coastal environment [
2,
3]. Synthetic aperture radar (SAR) is one of most promising remote sensing systems for oil spill monitoring, for it can provide valuable information about the position and size of the oil spill [
1]. Moreover, the wide coverage and all-day, all-weather capabilities make SAR very suitable for large scale oil spill monitoring and early warning [
6,
7,
8].
In their early stages, studies of oil spill detection are mainly based on single polarimetric SAR images [
9,
10,
11,
12]. The theoretical rationale of SAR oil spill detection is that the presence of oil slicks on the sea surface dampens short-gravity and capillary waves, so the Bragg scattering from the sea surface is largely weakened. The ideal sea surface wind speed for oil spills detection is 3–14 m/s [
13]. As a result, oil spills can be detected as “dark” areas in SAR images. However, some other manmade or natural phenomena can result in very similar low scattering areas on the sea surface, e.g., biogenic slicks, waves, currents and low-wind areas, etc. Conventional oil spill detection procedures use intensity, morphological texture, and auxiliary information to distinguish mineral oil and its lookalikes, with its processing chain divided into three main steps [
13]: (1) dark spot detection; (2) features extraction; and (3) classification between mineral and its lookalikes.
Single polarimetric SAR-based oil spill detection algorithms need auxiliary information and large number of data samples to classify mineral oil and its lookalikes. Sometimes the shape and texture of oil slicks may vary, affecting the robustness of intensity-based oil spill classification algorithms. Polarimetric observation capabilities provided by advanced SAR sensors have much stronger capabilities for oil spills detection [
14]. For instance, biogenic slicks and mineral oil are difficult to distinguish by single polarimetric SAR images. Yet, their polarimetric scattering mechanisms are largely different: for oil-covered areas, Bragg scattering is largely suppressed, and high polarimetric entropy can be documented. In the case of a biogenic slick, Bragg scattering is still dominant, but with a low intensity. Thus, similar polarimetric behaviors as those of oil-free areas should be expected in the presence of biogenic films. Hence, polarimetric features can largely help the image classification between mineral and biogenic lookalikes [
14].
Various polarimetric features have been proposed to classify oil spills. The standard deviation of copolarized phase difference (phase difference between Vertical transmit and Vertical receive-VV and Horizonal transmit and Horizonal receive-HH channel) has shown a strong oil classification capability on C-, X-, and L-band data [
15]. Nunziata et al. (2011) proposed pedestal height to describe the different polarization signature between mineral oil and biogenic lookalikes [
16]. Minchew et al. (2012) took the advantage of copolarization ratio to study the mixing status of crude oil and sea water [
17]. Zhang et al. (2011) used the conformity coefficient as a binary classifier [
18]. Other polarimetric features such as degree of polarization, entropy, alpha angle, and Bragg likelihood angle were also used to classify oil spills [
19,
20,
21].
Some previous studies conducted automatic oil-spill classification algorithms. Marghany (2001) developed models to discriminate textures between oil and water by using co-occurrence textures [
22]. Gambardella et al. (2008) proposed one-class classification with an optimized feature selection algorithm and obtained a promising oil spill classification [
23]. Frate et al. (2000) proposed a semiautomatic detection of oil spills by neural network [
24]. Garcia-Pineda et al. (2008) developed the Textural Classifier Neural Network Algorithm (TCNNA) to map an oil spill in the Gulf of Mexico Deepwater Horizon accident [
11]. Marghany (2013) used a genetic algorithm (GA) for automatic detection of an oil spill from ENVISAT ASAR (Advanced Synthetic Aperture Radar) data [
25]. Li et al. (2013) used a Support Vector Machine (SVM) to detect oil spills based on morphological features on very limited data samples [
26].
Polarimetric SAR features contain massive complementary and redundancy information. The extraction and optimization of them are closely related to the performance of oil spill classification [
27]. Deep learning algorithms have very strong capabilities of exploring complex correlation between features and achieve very promising fitting result on complicated problems. It has been a very popular technique for image processing, computer vision, and natural language processing. According to the authors, deep learning has not been used in features optimization for oil spills detection based on polarimetric SAR data, and it should be a very promising research topic.
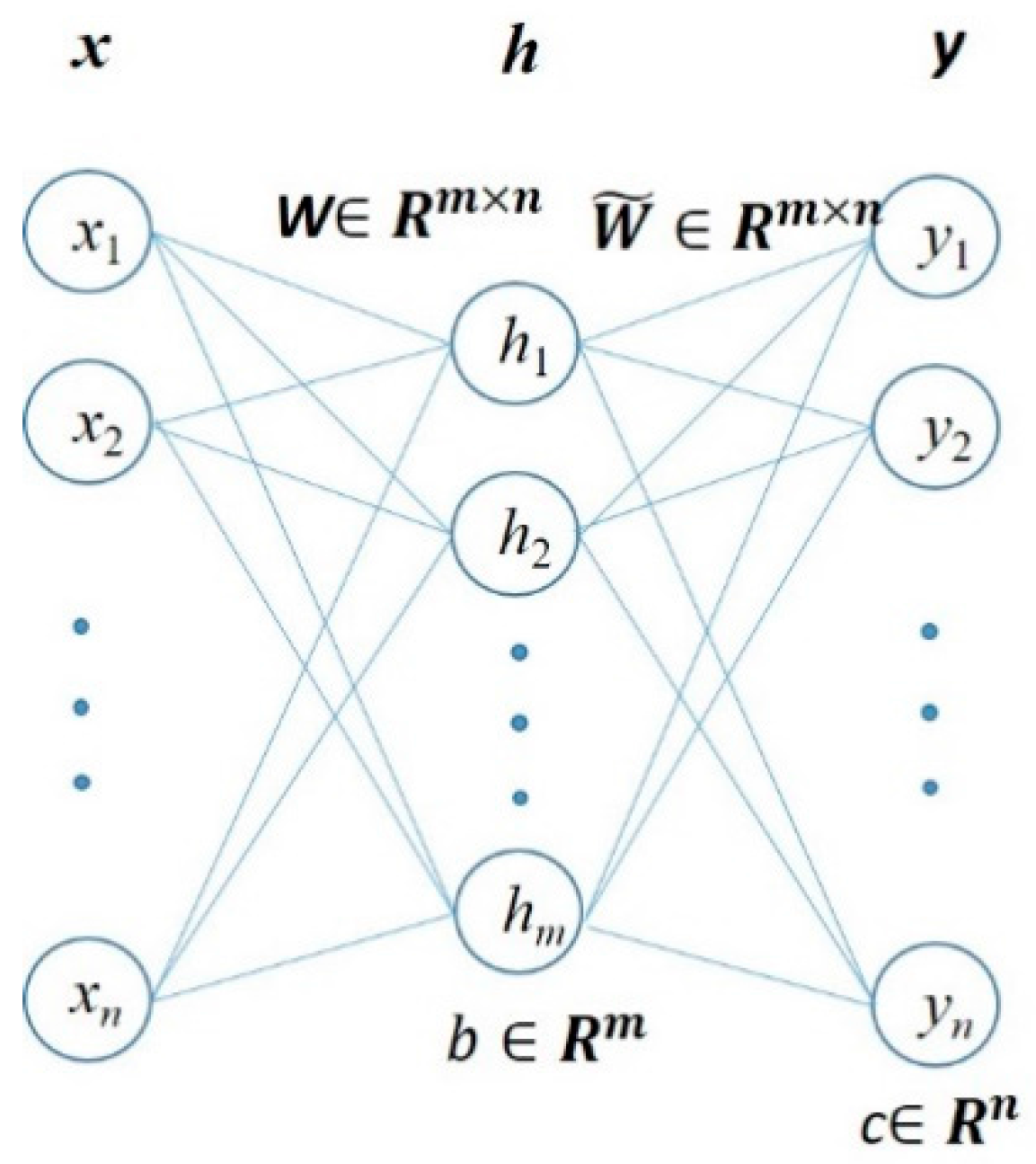
Deep neural network with multilayer neuron has powerful capabilities in describing complex functions compared with shallow networks [
28]. However, the traditional gradient descent technique works poorly on a deep neural network when the weights are initialized randomly. The reason is that when the derivative is calculated using the back propagation method, the magnitude of the gradient (from the output layer to the initial layer of the network) decreases dramatically as the network depth increases. As the result, the gradient of the overall loss function, with respect to the weights of the first few layers, is very small. Thus, when the gradient descent method is used, the weights of the first layers change very slowly, so that they cannot learn effectively from the samples. This problem is often referred to as “gradient dispersion”. In 2006, Hinton et al. proposed the deep belief network (DBN), which is a belief network composed of Restricted Boltzmann Machine (RBM) one layer at a time, to take the advantage of complementary priors of the data. Inspired by DBN, Beigio et al. (2006) used a stacked autoencoder, which is a deep multilayer neural network that initialized its weights by a greedy layer-wise unsupervised training strategy [
29].
Moreover, feature dimension reduction can be seen as an early fusion step. Fusion at different stages of classification procedures is a booming research field that has shown capabilities for improvement of classification results. For instance, Vergara et al. fused the output of nonindependent detectors to derive the optimum classification result [
30]. Late fusion of scores of several classifiers could be adapted to the proposed problem as a future research work.
The aims of this paper are exploring the capabilities of deep learning algorithms on polarimetric SAR-based marine oil spill detection. In
Section 2, research methods including the representation of polarimetric SAR data, feature extraction methods and deep learning algorithms including DBN and SAE will be introduced. In
Section 3, experiments were conducted on RADARSAT-2 data containing verified oil spills and biogenic lookalikes. The performance of different algorithms on various sample sizes for oil spill classification will be compared. Finally, conclusions are drawn in
Section 4, and the significance and future work of the study will be briefly presented.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}