1. Introduction
The sound of an object swinging through the air has a very distinctive swoosh sound. We expect this sound when watching a sword fight in a movie or playing a golfing game. This is a common sound within films, TV programmes and games covering genres like sports, material arts or a swashbuckling yarn. These distinct sounds are all generated by a similar physical process as the objects move through the air.
When sounds are added into media to replicate or emphasise original sounds, like a sword swoosh, they are classed as sound effects. A sound effect is usually implemented as a pre-recorded sample or from sound synthesis. Pre-recorded samples have a drawback in media like games and virtual reality as they are unable to change or evolve with the environment, but they are often viewed as more perceptually accurate than synthesised effects. Synthesised effects have the advantage of being based on algorithms and hence have the potential to adapt with their environments.
Being able to replicate these sounds within a single synthesis model offers the opportunity to cover a wide variety of objects travelling through the air. This potentially gives a programmer the ability to obtain the results required without having to find a sample within a sound effects library or record the sound themselves. It also provides an audio programmer the ability to integrate parameters of the model into a game engine. Thus, the synthesis model can evolve with the environment, increasing immersion within a game or virtual reality. A video illustrating the model being used to synthesise a sword swing within the Unity game engine is shown at
https://www.youtube.com/watch?v=zVvNthqKQIk.
This article is a revised and extended version of [
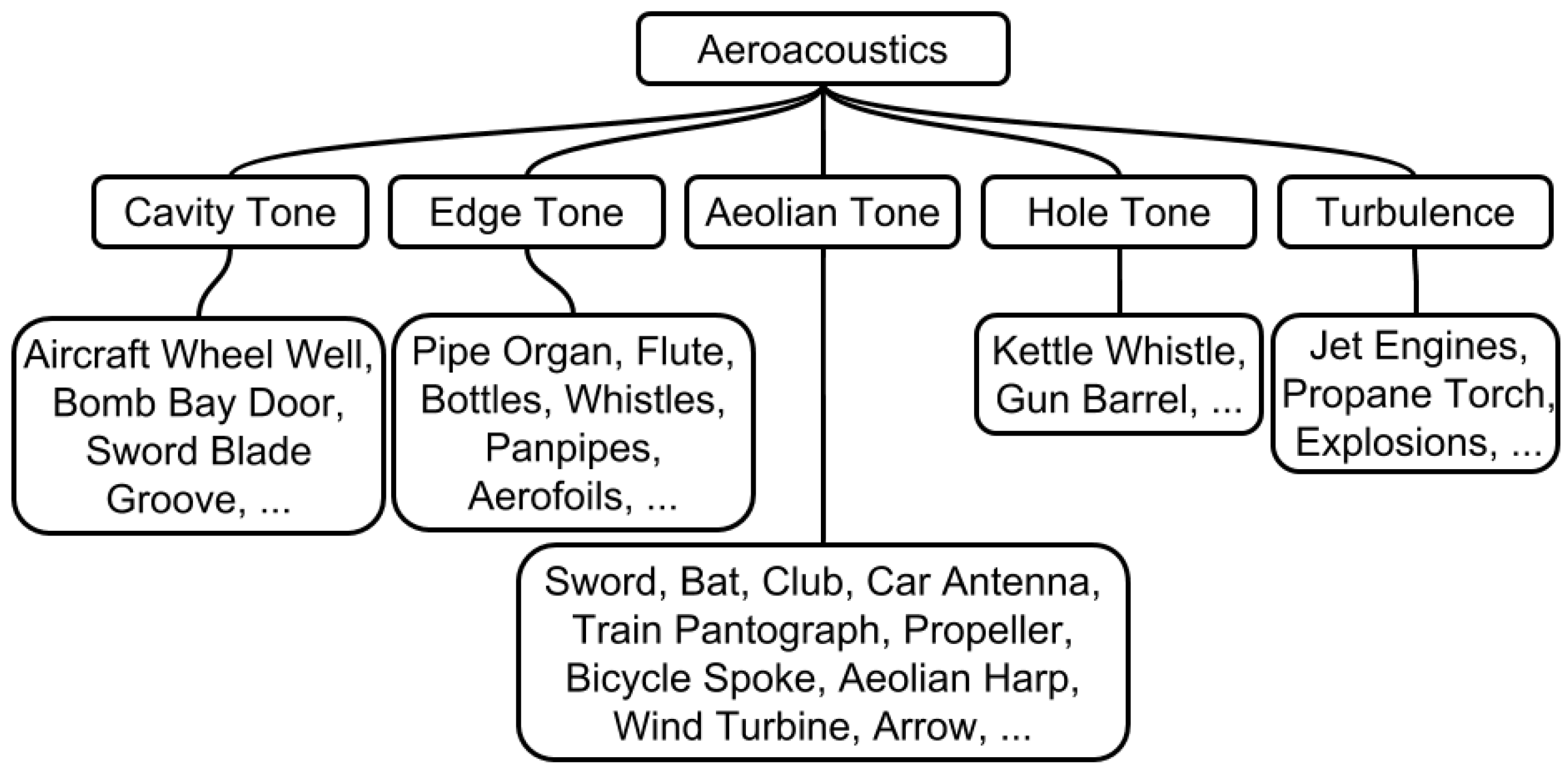
1], which won the best paper award at the 14th Sound and Music Computing Conference 2017. It presents a new sound synthesis method illustrating the design, implementation and analysis of a real-time physically-derived model that can be used to produce sounds similar to those of an object swooshing through the air. The objects examined were a metal sword, a wooden sword, a baseball bat, a golf club and a broom handle, which represent different object geometries commonly heard swinging through the air. To our knowledge, this is the first synthesis model that replicates a wide variety of objects swinging through the air by using bona fide fluid dynamics equations to calculate the sound output in real time.
Section 2 describes the state of the art and related work, while
Section 3 gives a detailed description of our method. The implementation is given in
Section 4 followed by both subjective and objective evaluations of our model in
Section 5. A discussion of the work is presented in
Section 6 followed by conclusions in
Section 7.
2. Background and Related Work
Sound synthesis techniques can be split into two broad approaches, signal-based and physical models [
2]. Signal-based models aim to replicate the sound properties; matching frequency components, replicating the time envelope or similar. Physical models aim to replicate the processes behind the natural sound creation by mathematical models.
The advantage of a signal-based model is that it is relatively computationally inexpensive to replicate the spectrum of a sound using established techniques such as additive synthesis or noise shaping. A drawback of this approach is that it is rarely possible to relate changes in signal properties to the physical processes creating the sound. For example, an increase in speed of a sword not only changes the fundamental tone frequency, but also the gain. Therefore, changing one signal-based property could lose realism in another.
Physical models aim to replicate the physics behind the sound generation process. Sounds generated by these models have the advantage of possessing greater authenticity in the generated sounds, especially in relation to parameter adjustments. A potential drawback is that the computational cost required to produce sounds is often high, and the physical models typically cannot adapt quickly to parameter adjustments, making real-time operation challenging and often not possible.
In the middle of these traditional techniques lay physically-inspired models. These hybrid approaches replicate the signal produced, but add characteristics of the physics that are behind the sound creation. For a simple sword model, this might be noise shaping with a bandpass filter with centre frequency proportional to the speed of the swing. A variety of examples of physically-inspired models was given in [
3]; the model for whistling wires being exactly the bandpass filter mentioned.
Four different sword models were evaluated in [
4]. Here, the application was for interactive gaming, and the evaluation was focused on perception and preference rather than accuracy of sound. The user was able to interact with the sound effect through the use of a Wii Controller. One model was a band-filtered noise signal with the centre frequency proportional to the acceleration of the controller. A physically-inspired model replicated the dominant frequency modes extracted from a recording of a bamboo stick swung through the air. The amplitude of the modes was mapped to the real-time acceleration data.
The other synthesis methods in [
4] both mapped acceleration data from the Wii Controller to different parameters; one using the data to threshold between two audio samples, the other a granular synthesis method mapping acceleration to the playback speed of grains. Tests revealed that the granular synthesis was the preferred method for expression and perception. One possible reason that the physical model was less popular could be the lack of correlation between speed and frequency pitch, which the band-filtered noise had. This may also be present in the granular model.
A signal-based approach to a variety of environmental sound effects, including sword whoosh, waves and wind sounds, was undertaken in [
2]. Analysis and synthesis occur in the frequency domain using a sub-band method to produce narrow band coloured noise. In [
5], a rapier sword sound was replicated, but this focused on the impact rather than the swoosh when swung through the air.
A physical model of sword sounds was explored in [
6]. Here, offline sound textures were generated based on the physical dimensions of the sword. The sound textures were then played back with speed proportional to the movement. The sound textures were generated using computational fluid dynamics software (CFD), solving the Navier–Stokes equations and used Lighthill’s acoustic analogy [
7] extended by Curle’s method [
8]. In this model [
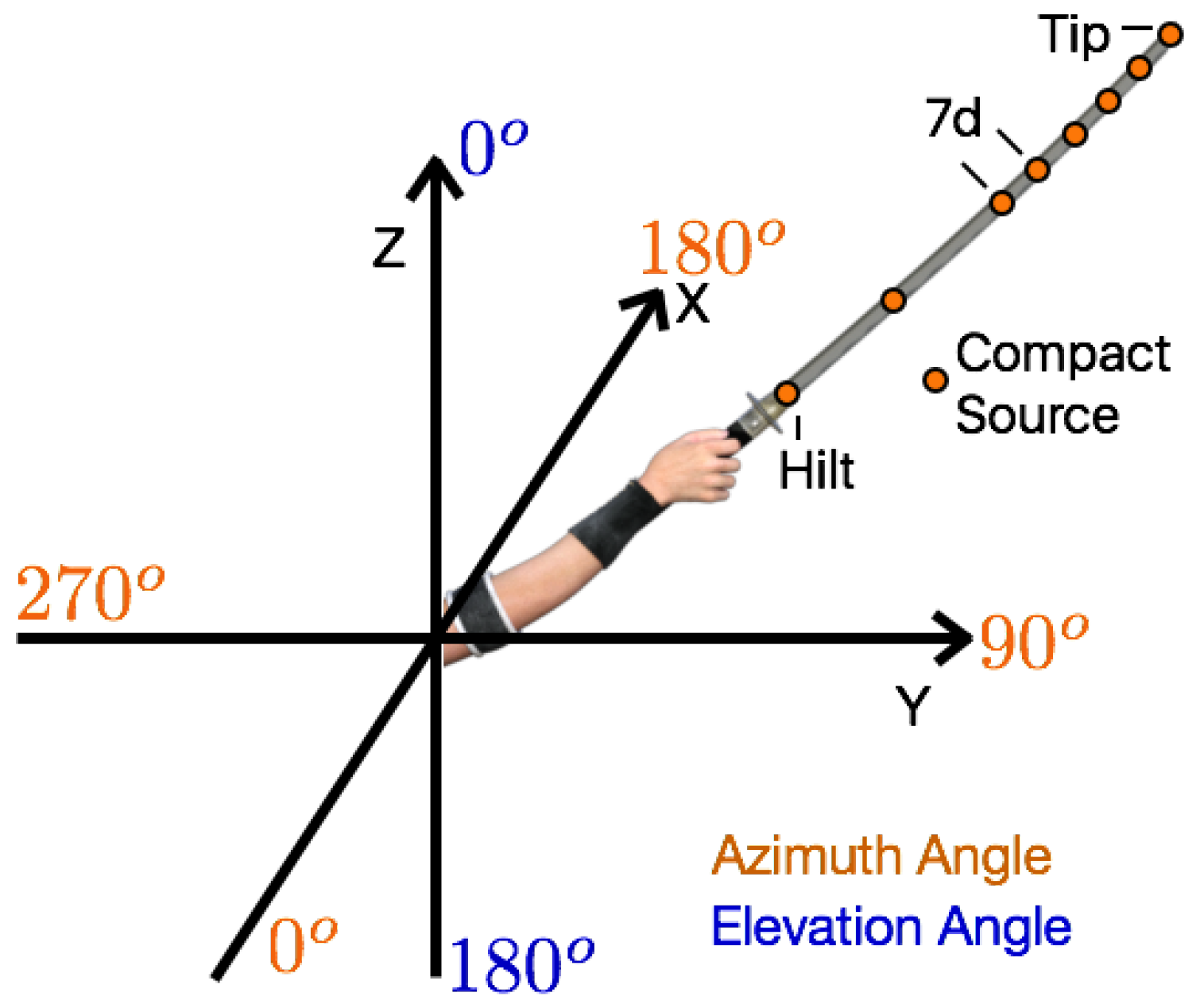
6], the sword was split into a number of compact sound sources (discussed in
Section 3.2), spaced along the length of the sword. As the sword was swept thought the air, each source moved at a different speed; therefore, the sound texture for each source was adjusted accordingly. The sounds from each source were summed and output to the listener.
An overview of the different synthesis methods and parameters available to a user are presented in table form in
Table 1. It can be seen that the only model offering real-time operation with instantaneous variability of physical parameter was [
1]. Outputs from [
4,
6] were used within our listening test,
Section 5, to represent alternative synthesis methods.
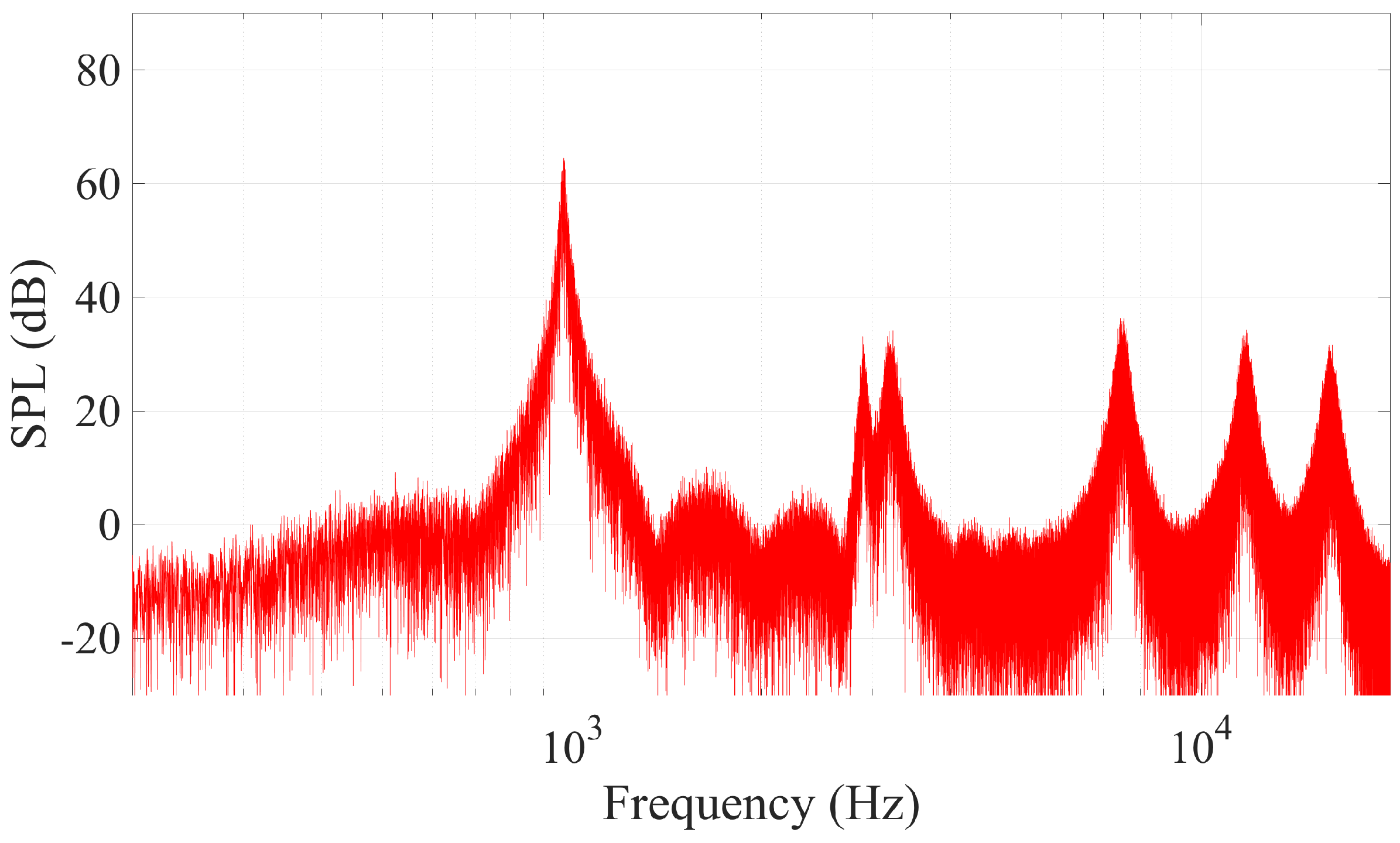
A Japanese katana sword was analysed in [
9] by means of wind tunnel experiments. A number of harmonics from vortex shedding were observed along with additional harmonics from a cavity tone due to the shinogi or blood grooves in the profile of the sword.
6. Discussion
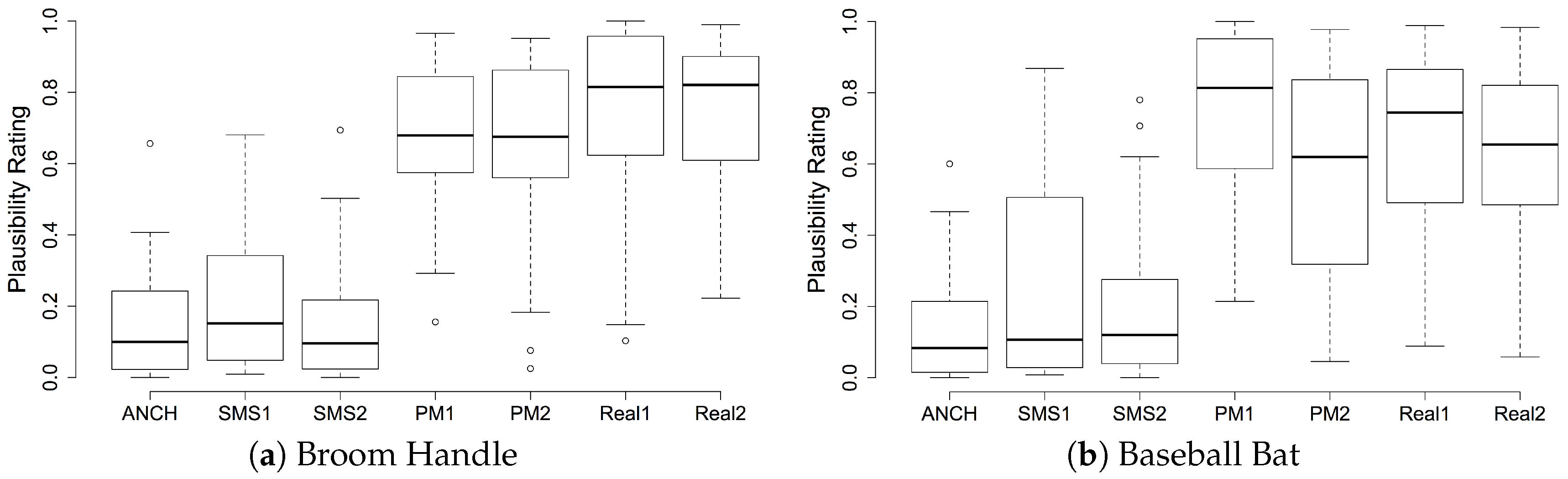
The results from the listening test indicate that overall, our model performs well compared to other synthesis models. It has exceptional performance for the broom handle, baseball bat, golf club and wooden sword objects, where participants found sounds generated by our model to be as plausible as real recordings. The exception to this was the metal sword physical model sound effect, which actually performed worse in this test compared to our previously published test [
1]. During the previous listening test [
1], we did not have the physical dimensions of the sword samples. In this test, we had the dimensions, as well as the impulse response of the room in which the samples were recorded, thus enabling a fairer comparison.
One possible reason for the poorer performance of the metal sword physical model was that all the other modelled objects were thicker than the metal sword. Thicker objects have higher Reynolds numbers, which results in lower Q values. Spectral modelling synthesis analyses a recording and extracts sinusoidal components. Thinner objects produce sounds closer to pure tones and hence are better synthesised using SMS than thicker objects.
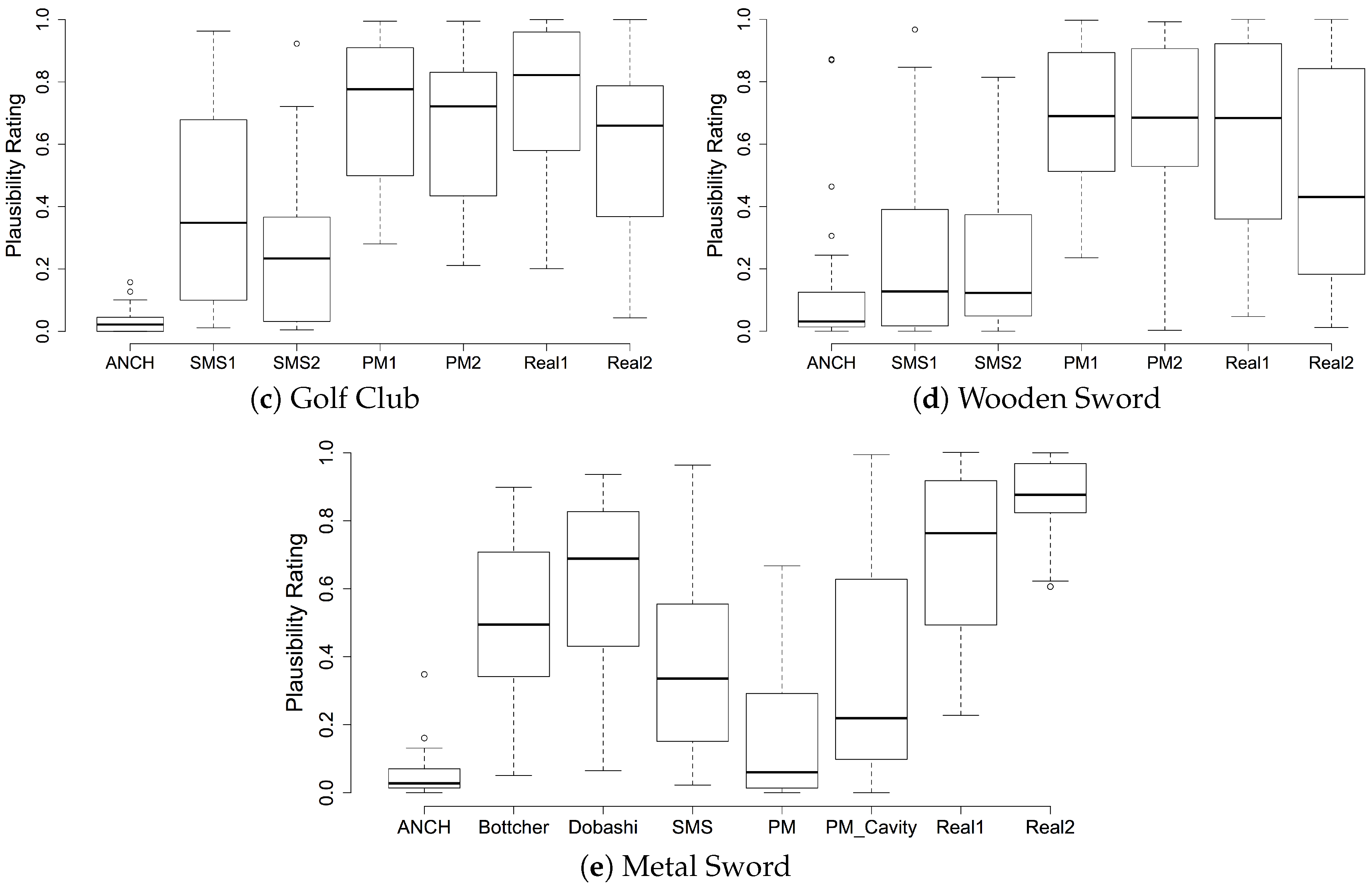
Table 8 shows that our physical model was significantly different from all other sounds, especially the real sounds and those synthesised by other methods. Since only one physical model sound was compared with a number of others, it is believed that a further listening test would be necessary to investigate if this result would be repeated over the range of sword dimensions and speeds. Results given in [
1] indicated that the lower quality physical model sounds were rated as more plausible. These sounds had a fixed
Q value that gave the impression of a thicker object. The diameter used to generate sounds in [
6] was 0.01 m, substantially thicker than the sword we were modelling. It may be the case that listeners perceive a thicker sound as more plausible even if not physically accurate. This could be revealed in future perceptual evaluations.
In the original paper [
1], the value of
in Equation (
6) was set to
. This was set perceptually as no exact relationship between dipole and wake noise had been identified. During the design of the listening test for this article, the value was again set perceptually, but this time, all objects were considered, including sounds generated using the Wii Controller. This resulted in the value of
being set to
, increasing the wake gain.
The broom handle, baseball bat and golf club objects were all cylindrical with thickness to width ratios of 1:1. For the wooden sword, this ratio decreases to approximately 0.37:1 and for a metal sword to approximately 0.14:1. The Aeolian tone model is designed around vortex shedding from cylindrical objects, and it is reasonable to assume that additional discrepancies may exist when there is a deviation from the thickness to width ratio of a cylinder.
Another possible reason for the poor rating of the metal sword object compared to the other objects is that the number of participants who have swung a real sword and heard the sound may well be less than those who have perhaps swung a golf club and the other objects. Memory plays an important role in perception [
31]. If participants have heard a Foley sound effect for a sword more often than an actual sword sound, this may influence their perception of the physical model.
In contrast, it can be argued that participants will have more likely heard the actual sounds of a golf club at a live sporting event or within sporting broadcasts, and hence, their memory of these sounds would be closer to the physical model. Since all participants were from the U.K., the baseball bat would most likely not be as familiar to them as other objects, and hence, they might not have as strong a memory of the sound made by this object. This would make the difference between a memory of a Foley sound and an actual sound diminish.
It is clear from the object recognition that, with zero training, it was extremely difficult to identify an object from controlling the speed parameter from the swing of a Wii Controller. This is corroborated by the variation in results from those who did the object recognition test before the listening test to those who took the test after. Clearly, the listening tests provided participants with some form of informal training for the object recognition (it was found that the object recognition test provides negligible training for the listening test). This is in line with results from [
32] where it was found that participant training was the dominant factor in determining whether or not similar tests produced significant results.
A common comment from participants when completing recognition tests was that they would like to have some visual stimulus to assist them with making their decision. It is anticipated that participants may have given more accurate choices if they were able to choose from pictures of the five objects being modelled rather than the names. The label of broom handle could produce a wide variety of images in the minds of participants, but a picture of the actual broom handle we were modelling would allow participants to focus on the same object. A further comment was that the participant would prefer a none of the above option when they believed the sound did not match any of the objects.
The use of a Wii Controller was an obvious interface for participants to swing and generate the sounds due to the sensors and ergonomic design. It was noted in a previous test as part of [
1] that a participant would have liked some sense of weight in their hand to increase their sense of belief. This comment, along with the previous comment requesting visual stimulus, indicates that participants look for non-aural cues to assist in identifying sounds. Further research into which cues participants prefer and the effects on identification is required.
Since all sounds from the objects modelled were generated by the same physical model, it was understandable that there was some confusion between choices, possibly due to sonic similarities between the sound effects. The only differences between each synthesis model were the dimensions of the object being swung and the speed, either set as in the listening test or generated by each participant using the Wii Controller. A listening test that only provides a choice between a metal sword and a baseball bat would be expected to produce more clear-cut results.
The classification of different sound effects with sonic similarities was examined in [
33] where nine categories of sound effects were identified. It is anticipated that objects modelled herein would be categorised into the same category in [
33], but within weapons and sports in a traditional sound effect library.
Comparison with results published in [
9] indicates that we have good agreement with the Aeolian tone frequency generated by vortex shedding. Wind tunnel results show the sword tested in [
9] having an Aeolian tone peak at 960 Hz, while our model predicts the frequency at 969 Hz, a difference of 0.9%.
The inclusion of the cavity tone within the sword model provides the possibility to model more complex blade profiles. Listening tests indicate that it was found as plausible as the SMS sample, similar to Bottcher’s sample, but not as plausible as Dobashi’s sample and the real recordings. None of the other profiles are believed to include the cavity tone, but it was found that inclusion of it makes our model more plausible. It is difficult to draw overriding conclusions why this occurred, but it may be linked to Foley sword sound effects previously heard by participants.
Future research into the inclusion of the cavity tone compared to actual swords with known cavity profiles would be advantageous, enabling us to better judge how plausible the inclusion of this tone is in the generation of sword swoosh sounds. This would also assist in evaluating how the lack of modulation between the Aeolian tone and cavity tone in our model affects perception and if we need to extend our model to include this.
The range of sword profiles that we are able to model from using only the Aeolian tone and cavity tone is yet to be explored. Similarly, it is yet to be established if the sword material, bronze, steal, etc., plays an important role in the sound produced. It is known that when the vortex shedding frequency is approximately equal to a vibration frequency of the object, the sound is re-enforced. A physical model replicating this in the form of an Aeolian harp was given in [
34]. Adding some of the physical properties implemented in this model would allow for consideration of the mass density of the metal and damping of the construction to be considered. Whether this would have an influence on perception is another area for further research.
Further objective evaluation would include obtaining exact velocity data for known object swings and comparing the physical model using these data and a recording of the swing from which these data were captured. This may involve wind tunnel measurements as in [
9].
It is recognised that the swing sounds recorded for the listening tests were mono, and the output from the physical model includes basic stereo panning. The listener position within the virtual space of the physical model was set to replicate the microphone position when the other sounds were recorded. Although we believe this would not have a strong affect on plausible ratings, examination of spatialisation should be undertaken within future evaluation, and recording swing sounds binaurally would be preferred.
Additional models could be developed to replicate other sporting equipment, for example hockey sticks, cricket bats or even tennis racquets or lacrosse sticks, which have meshed faces. A physical model of a ball travelling through the air may also be possible although the fluid dynamics will differ from that of a cylinder, and the spinning of the ball may add other sounds not possible from our model. Authenticity may also be increased if the swinging arc of the objects was not restricted to great circles on the surface of a sphere. Normal swings often have the arms extending at the elbow, creating more elliptical arcs.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}