
A New Engine Fault Diagnosis Method Based on Multi-Sensor Data Fusion


Abstract
:1. Introduction
- Compared with single source data, multi-source information fusion or multi-sensor information fusion can improve the accuracy and promptness of fault diagnosis.
- Multi-sensor data fusion method has the ability to deal with the uncertainty of data in fault diagnosis so as to enhance the credibility of diagnostic results.
2. Preliminaries
2.1. Dempster–Shafer Evidence Theory
2.2. Evidence Distance
2.3. Weighted Average Approach for Evidence Combination
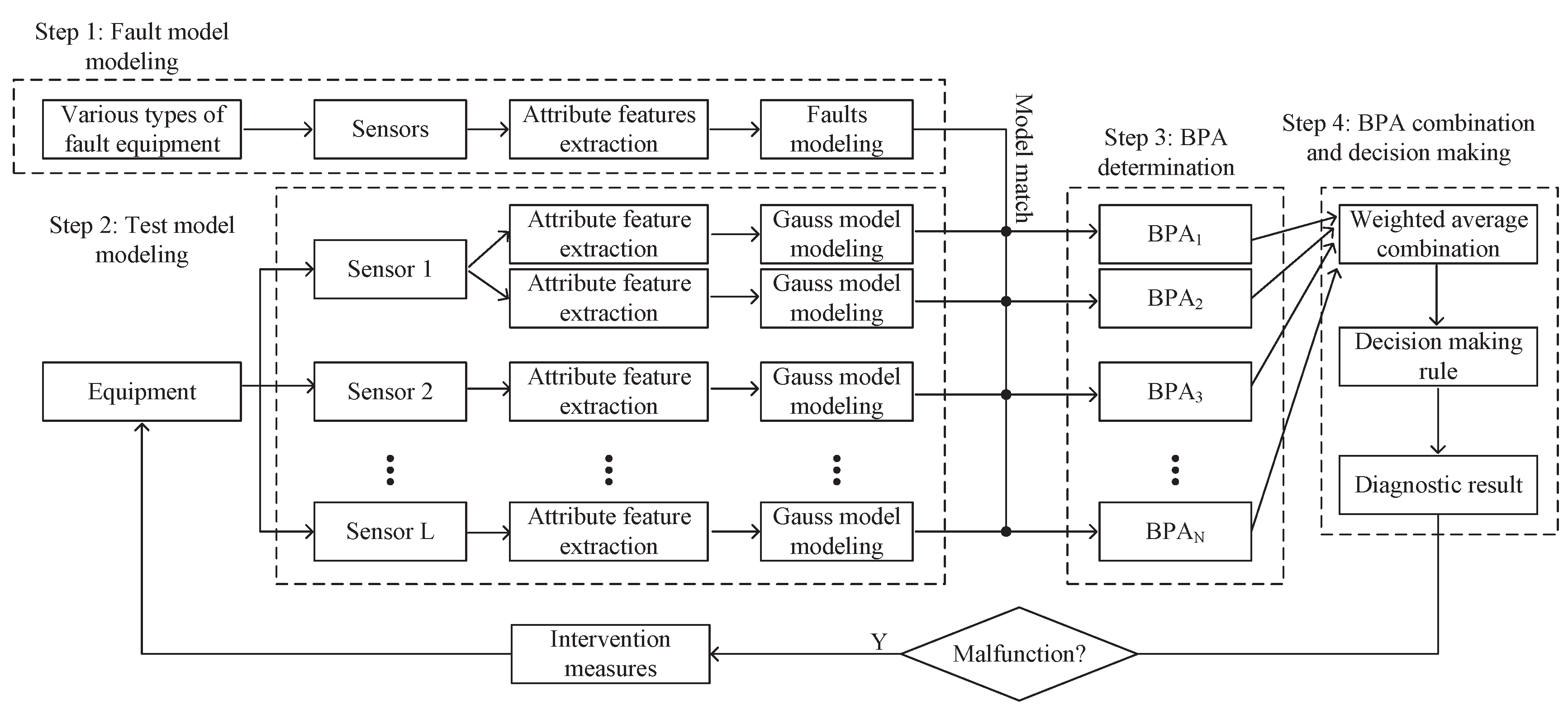
3. The Proposed Method for Fault Diagnosis
3.1. Fault Model Modeling
- Assuming n groups of data are observed, each group consists of m consecutive observations in the same time interval . In order to make the generated fault model representative, n should be more than 3 and 30, respectively, and n groups of data should be observed at different times.
- Calculate the mean value μ and standard deviation σ of the n groups’ observations. Here, observation i in group j is denoted as . The mean value μ and standard deviation σ can be obtained as:
- The Gaussian type of membership function is obtained as:
3.2. Test Model Modeling
3.3. BPA Determination
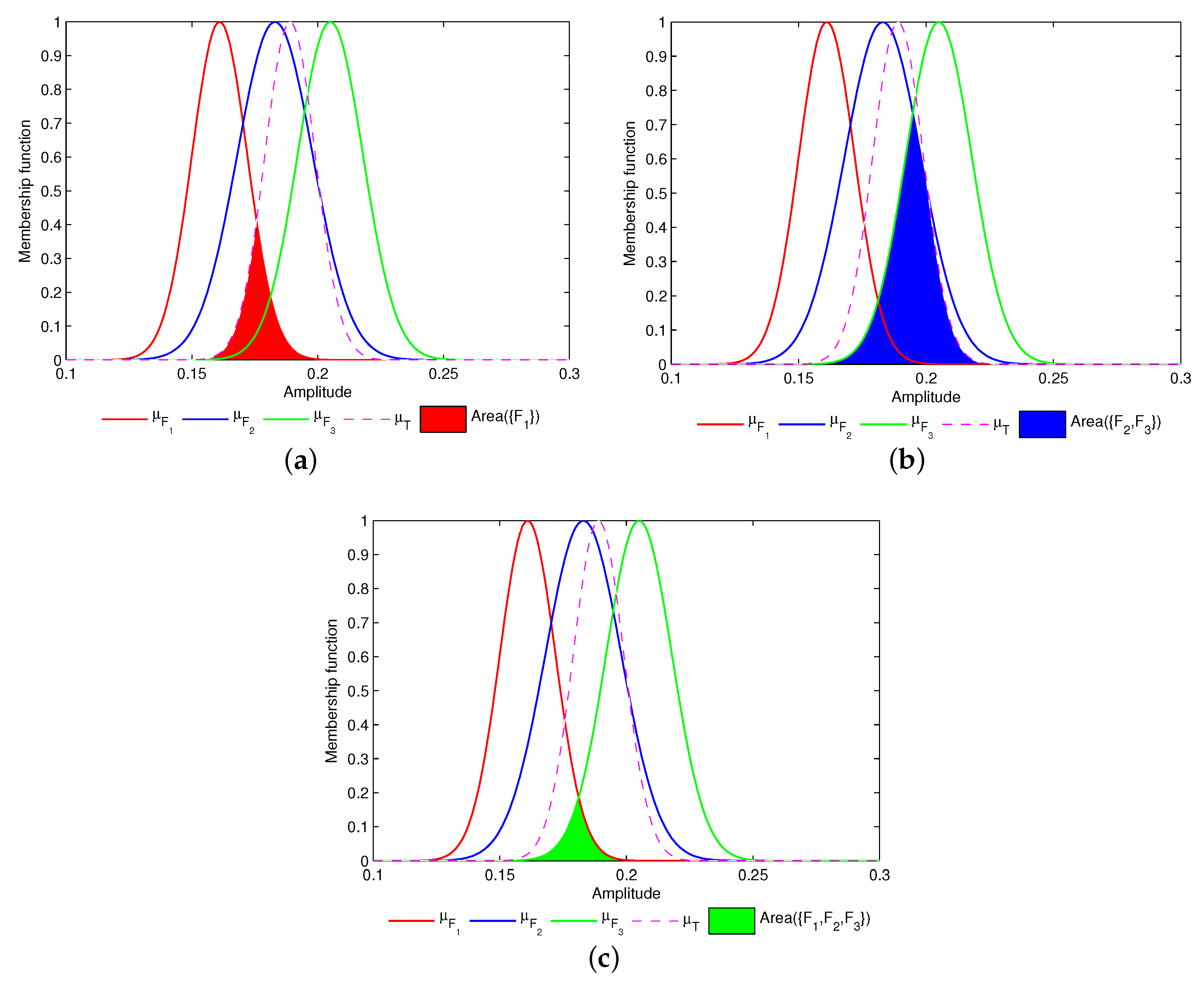
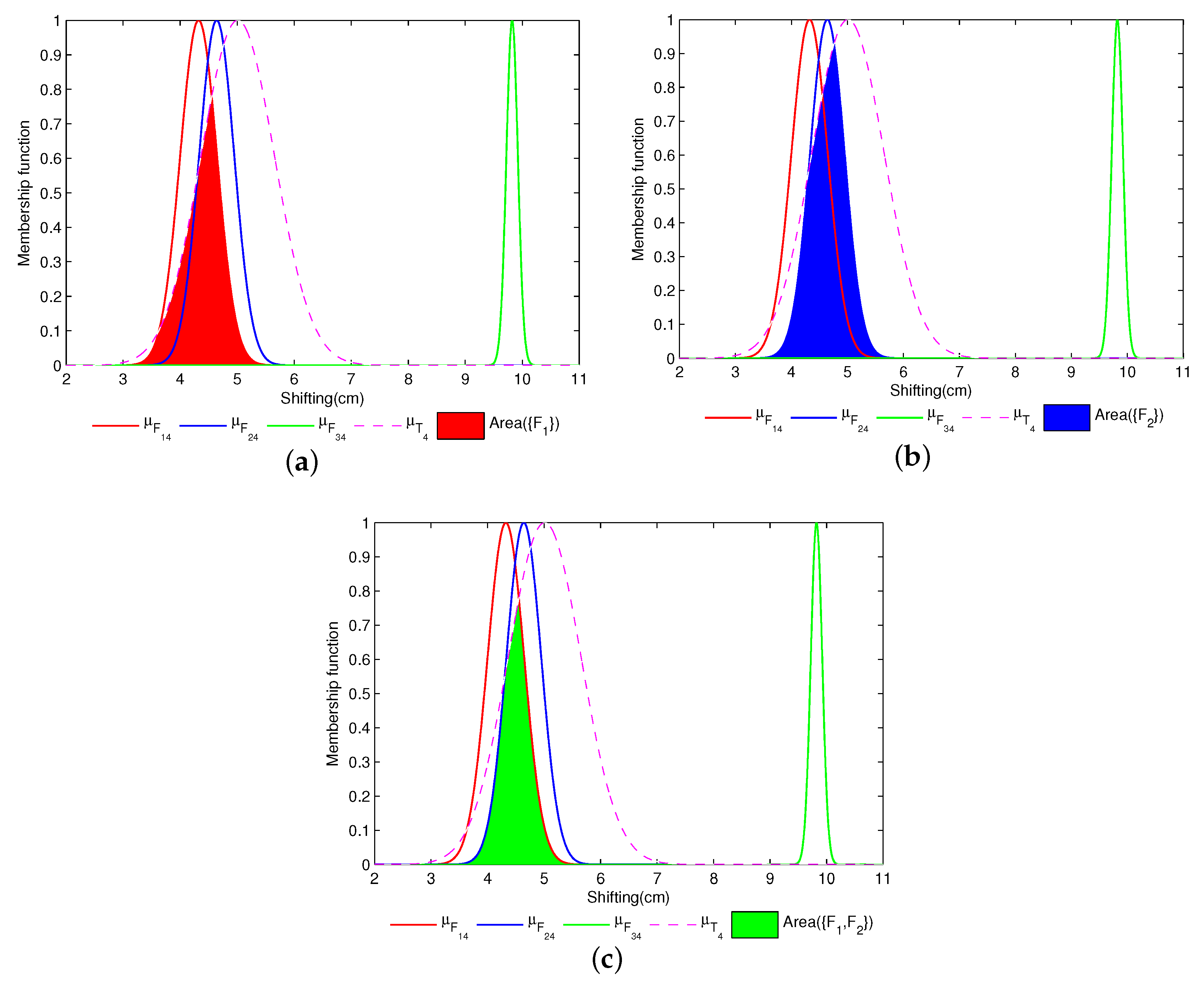
3.3.1. Support Degree Calculation of Singleton Propositions
3.3.2. Support Degree Calculation of Propositions with Two Elements
3.3.3. Support Degree Calculation of Propositions with Multiple Elements
3.3.4. Normalization
3.4. BPA Combination and Decision Making
- should have the maximum belief in final BPA that is (i = 1, 2, ..., M) and should exceed a threshold . is the minimum belief of . should be a slightly larger value to ensure the high credibility of diagnostic result so as to make sure the correctness of diagnostic result. Here, is designated as 0.5. The purpose of this rule is to make the reliability of the diagnostic result sufficiently large.
- The BPA of dual set proposition and multi-subset proposition, such as , , , should be less than a certain threshold . is the maximum belief of the uncertain components. If larger than , it is considered that the uncertainty of diagnostic result is too large, which may lead to the wrong diagnostic result. should be a smaller value so that the uncertainty of the diagnostic result is small. Here, is designated as 0.3. The purpose of this rule is to make the uncertainty of the diagnostic result smaller.
- The difference between and should be larger than a certain threshold that is , where (i = 1, 2, ..., ). is minimum difference between the maximum and the second largest in (i = 1, 2, ..., M). If larger than , it is considered that the diagnostic result can be clearly distinguished from the credibility of the other fault types, which can avoid false diagnostic results. Hence, to avoid false diagnostic results, can not be too small. Here, is designated as 0.2 because that is too large may cause a missing alarm. The purpose of this rule is to make the difference between the maximum and the second largest in larger, which means that is relatively larger in (i = 1, 2, ..., M).
4. Applications
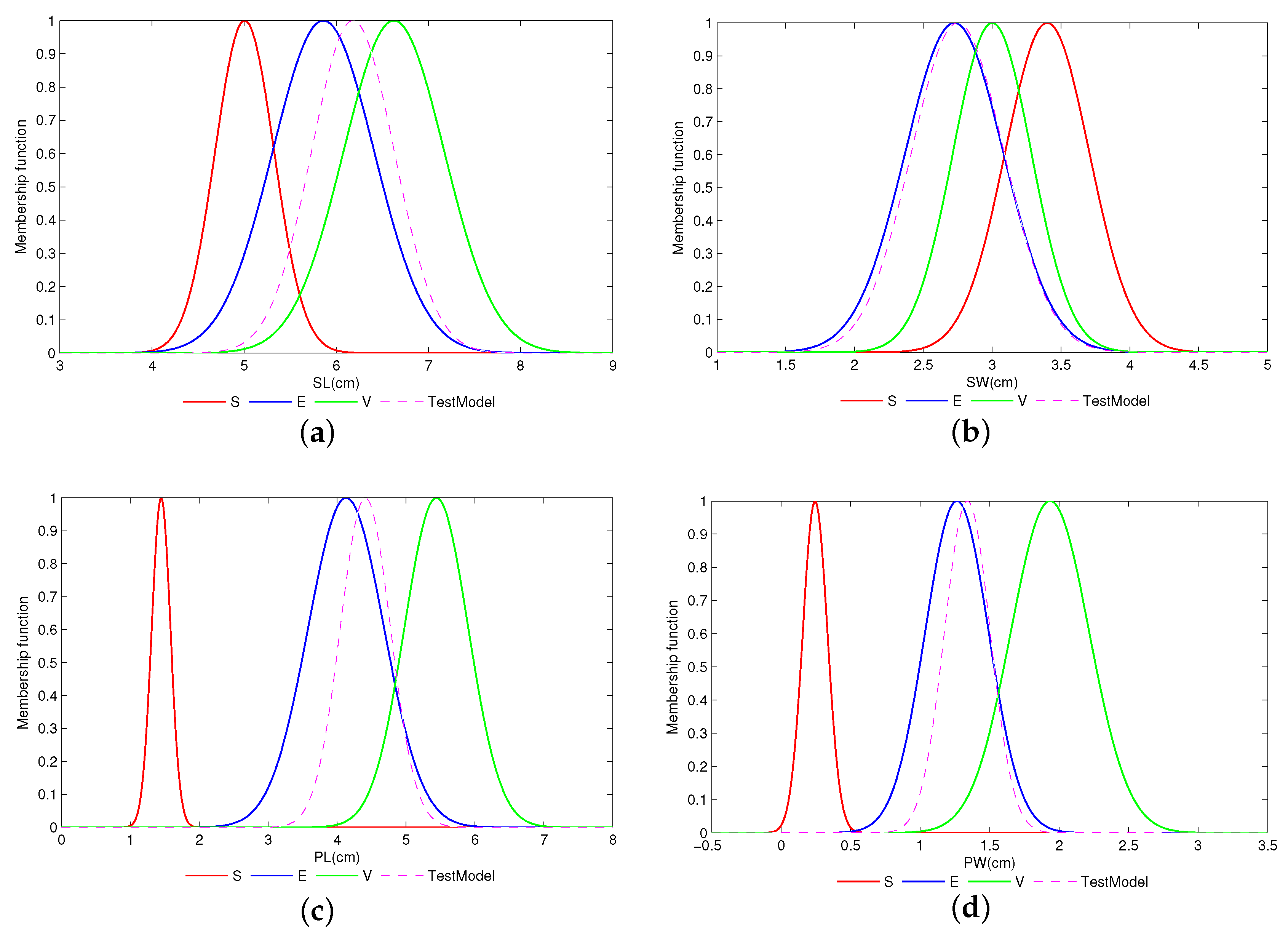
4.1. Iris Data Set Classification
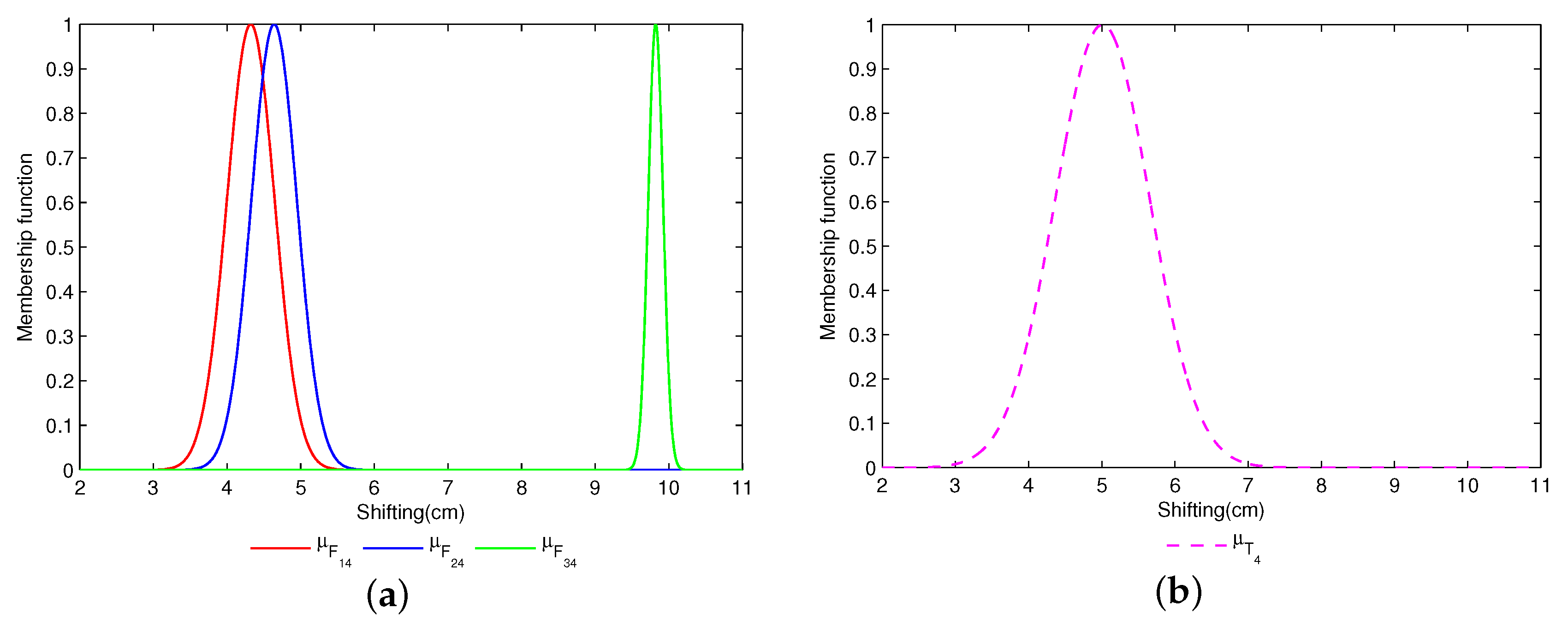
4.2. Motor Rotor Fault Diagnosis
- For , the integral interval is (3.0740,6.9470).
- For , the integral interval is (3.0740,6.9470).
- For , the integral interval is (3.0740,6.9470).
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chen, J.; Patton, R.J. Robust Model-Based Fault Diagnosis for Dynamic Systems; Springer: New York, NY, USA, 1999. [Google Scholar]
- Isermann, R. Fault-Diagnosis Systems. An Introduction from Fault Detection to Fault Tolerance; Springer: New York, NY, USA, 2006; Volume 28, pp. 195–197. [Google Scholar]
- Al-Busaidi, W.; Pilidis, P. Modelling of the non-reactive deposits impact on centrifugal compressor aerothermo dynamic performance. Eng. Fail. Anal. 2016, 60, 57–85. [Google Scholar] [CrossRef]
- Xue, R.; Hu, C.; Sethi, V.; Nikolaidis, T.; Pilidis, P. Effect of steam addition on gas turbine combustor design and performance. Appl. Therm. Eng. 2016, 104, 249–257. [Google Scholar] [CrossRef]
- Ramesh, T.S.; Shum, S.K.; Davis, J.F. A structured framework for efficient problem solving in diagnostic expert systems. Comput. Chem. Eng. 1988, 12, 891–902. [Google Scholar] [CrossRef]
- Wu, J.D.; Wang, Y.H.; Bai, M.R. Development of an expert system for fault diagnosis in scooter engine platform using fuzzy-logic inference. Expert Syst. Appl. 2007, 33, 1063–1075. [Google Scholar] [CrossRef]
- Yang, J.B.; Liu, J.; Wang, J.; Sii, H.S.; Wang, H.W. Belief rule-base inference methodology using the evidential reasoning Approach-RIMER. IEEE Trans. Syst. Man Cybern. A Syst. Hum. 2006, 36, 266–285. [Google Scholar] [CrossRef]
- Tayarani-Bathaie, S.S.; Vanini, Z.S.; Khorasani, K. Dynamic neural network-based fault diagnosis of gas turbine engines. Neurocomputing 2014, 125, 153–165. [Google Scholar] [CrossRef]
- Tamilselvan, P.; Wang, P. Failure diagnosis using deep belief learning based health state classification. Reliab. Eng. Syst. Saf. 2013, 115, 124–135. [Google Scholar] [CrossRef]
- Yan, R.; Gao, R.X.; Chen, X. Wavelets for fault diagnosis of rotary machines: A review with applications. Signal Process. 2014, 96, 1–15. [Google Scholar] [CrossRef]
- Pichler, K.; Lughofer, E.; Pichler, M.; Buchegger, T.; Klement, E.P.; Huschenbett, M. Detecting cracks in reciprocating compressor valves using pattern recognition in the pV diagram. Pattern Anal. Appl. 2015, 18, 461–472. [Google Scholar] [CrossRef]
- Pichler, K.; Lughofer, E.; Pichler, M.; Buchegger, T.; Klement, E.P.; Huschenbett, M. Fault detection in reciprocating compressor valves under varying load conditions. Mech. Syst. Signal Process. 2016, 70–71, 104–119. [Google Scholar] [CrossRef]
- Fernando, H.; Surgenor, B. An unsupervised artificial neural network versus a rule-based approach for fault detection and identification in an automated assembly machine. Robot. Comput. Integr. Manuf. 2015, 43, 79–88. [Google Scholar] [CrossRef]
- Delgado-Arredondo, P.A.; Morinigo-Sotelo, D.; Osornio-Rios, R.A.; Avina-Cervantes, J.G.; Rostro-Gonzalez, H.; Romero-Troncoso, R.D.J. Methodology for fault detection in induction motors via sound and vibration signals. Mech. Syst. Signal Process. 2016, 83, 568–589. [Google Scholar] [CrossRef]
- Serdio, F.; Lughofer, E.; Pichler, K.; Buchegger, T.; Pichler, M.; Efendic, H. Fault detection in multi-sensor networks based on multivariate time-series models and orthogonal transformations. Inf. Fusion 2014, 20, 272–291. [Google Scholar] [CrossRef]
- Serdio, F.; Lughofer, E.; Zavoianu, A.C.; Pichler, K.; Pichler, M.; Buchegger, T.; Efendic, H. Improved Fault Detection employing Hybrid Memetic Fuzzy Modeling and Adaptive Filters. Appl. Soft Comput. 2017, 51, 60–82. [Google Scholar] [CrossRef]
- Serdio, F.; Lughofer, E.; Pichler, K.; Pichler, M.; Buchegger, T.; Efendic, H. Fuzzy Fault Isolation using Gradient Information and Quality Criteria from System Identification Models. Inf. Sci. 2015, 316, 18–39. [Google Scholar] [CrossRef]
- Mitchell, H.B. Multi-Sensor Data Fusion; Artech House: Norwood, MA, USA, 1990; pp. 585–610. [Google Scholar]
- Crowley, J.L. Principles and Techniques for Sensor Data Fusion; Springer: Berlin/Heidelberg, Germany, 1993; pp. 5–27. [Google Scholar]
- Alexandridis, A. Evolving RBF neural networks for adaptive soft-sensor design. Int. J. Neural Syst. 2013, 23, 1350029. [Google Scholar] [CrossRef] [PubMed]
- Graziani, S.; Pagano, F.; Xibilia, M.G. Soft sensor for a Propylene Splitter with seasonal variations. In Proceedings of the 2010 IEEE Instrumentation and Measurement Technology Conference (I2MTC), Austin, TX, USA, 3–6 May 2010; pp. 273–278.
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Shafer, G. A mathematical theory of evidence. Technometrics 1976, 20, 242. [Google Scholar]
- Deng, X.; Xiao, F.; Deng, Y. An improved distance-based total uncertainty measure in belief function theory. Appl. Intell. 2017, in press. [Google Scholar] [CrossRef]
- Deng, X.; Han, D.; Dezert, J.; Deng, Y.; Shyr, Y. Evidence combination from an evolutionary game theory perspective. IEEE Trans. Cybern. 2016, 46, 2070–2082. [Google Scholar] [CrossRef] [PubMed]
- Jiang, W.; Zhan, J. A modified combination rule in generalized evidence theory. Appl. Intell. 2017. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Walczak, B.; Massart, D.L. Rough sets theory. Chemom. Intell. Lab. Syst. 1999, 47, 1–16. [Google Scholar] [CrossRef]
- Shen, L.; Tay, F.E.H.; Qu, L.; Shen, Y. Fault diagnosis using Rough Sets Theory. Comput. Ind. 2000, 43, 61–72. [Google Scholar] [CrossRef]
- Zadeh, L.A. A Note on Z-numbers. Inf. Sci. 2011, 181, 2923–2932. [Google Scholar] [CrossRef]
- Jiang, W.; Xie, C.; Zhuang, M.; Shou, Y.; Tang, Y. Sensor Data Fusion with Z-Numbers and Its Application in Fault Diagnosis. Sensors 2016, 16, 1509. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Shi, Y.; Deng, X.; Deng, Y. D-DEMATEL: A new method to identify critical success factors in emergency management. Saf. Sci. 2017, 91, 93–104. [Google Scholar] [CrossRef]
- Zhou, X.; Deng, X.; Deng, Y.; Mahadevan, S. Dependence assessment in human reliability analysis based on D numbers and AHP. Nucl. Eng. Des. 2017, 313, 243–252. [Google Scholar] [CrossRef]
- Deng, X.; Hu, Y.; Deng, Y.; Mahadevan, S. Supplier selection using AHP methodology extended by D numbers. Expert Syst. Appl. 2014, 41, 156–167. [Google Scholar] [CrossRef]
- Deng, X.; Lu, X.; Chan, F.T.; Sadiq, R.; Mahadevan, S.; Deng, Y. D-CFPR: D numbers extended consistent fuzzy preference relations. Knowl. Based Syst. 2015, 73, 61–68. [Google Scholar] [CrossRef]
- Yao, J.; Wu, C.; Xie, X.; Qian, K. A new method of information decision-making based on D–S evidence theory. In Proceedings of the IEEE International Conference on Systems Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1804–1811.
- Li, Z.; Wen, G.; Xie, N. An approach to fuzzy soft sets in decision making based on grey relational analysis and Dempster–Shafer theory of evidence. Artif. Intell. Med. 2015, 64, 161–171. [Google Scholar] [CrossRef] [PubMed]
- Xie, N.; Wen, G.; Li, Z. A method for fuzzy soft sets in decision making based on grey relational analysis and d-s theory of evidence: Application to medical diagnosis. Comput. Math. Methods Med. 2014, 2014, 581316. [Google Scholar] [CrossRef] [PubMed]
- Li, L.L.; Li, Z.G.; Zhao, Q.M.; Zhang, H.J. An Algorithm of General Closeness Degree Based on Evidence Theory and Its Applications in Fuzzy Pattern Recognition. In Proceedings of the 9th International Conference on Control, Automation, Robotics and Vision, Singapore, 5–8 December 2006; pp. 1–5.
- Jiang, H.Q.; Gao, J.M.; Liang, Z.M.; Gao, Z.Y.; Zhang, X.W. Pattern recognition of die casting process based on D–S evidence theory. Jisuanji Jicheng Zhizao Xitong/Comput. Integr. Manuf. Syst. Cims 2015, 21, 1343–1349. [Google Scholar]
- Denœux, T. Application of evidence theory to k -NN pattern classification. Mach. Intell. Pattern Recognit. 1994, 16, 13–24. [Google Scholar]
- Mu, C.P.; Li, X.J.; Huang, H.K.; Tian, S.F. Online Risk Assessment of Intrusion Scenarios Using D–S Evidence Theory. In Proceedings of the 13th European Symposium on Research in Computer Security: Computer Security, Málaga, Spain, 6–8 October 2008; pp. 35–48.
- Lu, S.; Zhang, J.; Hao, S.; Luo, L. Security Risk Assessment Model Based on AHP/D–S Evidence Theory. In Proceedings of the 2009 International Forum on Information Technology and Applications, Chengdu, China, 15–17 May 2009; pp. 530–534.
- Zhang, G.; Duan, M.; Zhang, J.; Chen, D.; Yang, J. Power system risk assessment based on the evidence theory and utility theory. Autom. Electr. Power Syst. 2009, 33, 1–7. [Google Scholar]
- Dutta, P. Uncertainty Modeling in Risk Assessment Based on Dempster–Shafer Theory of Evidence with Generalized Fuzzy Focal Elements. Fuzzy Inf. Eng. 2015, 2, 15–30. [Google Scholar] [CrossRef]
- Jiang, W.; Wei, B.; Zhan, J.; Xie, C.; Zhou, D. A visibility graph power averaging aggregation operator: A methodology based on network analysis. Comput. Ind. Eng. 2016, 101, 260–268. [Google Scholar] [CrossRef]
- Jiang, W.; Wei, B.; Tang, Y.; Zhou, D. Ordered visibility graph average aggregation operator: An application in produced water management. Chaos 2017, 27, 023117. [Google Scholar] [CrossRef] [PubMed]
- Song, M.; Jiang, W.; Xie, C.; Zhou, D. A new interval numbers power average operator in multiple attribute decision making. Int. J. Intell. Syst. 2016. [Google Scholar] [CrossRef]
- Cheng, G.; Chen, X.H.; Shan, X.L.; Liu, H.G.; Zhou, C.F. A new method of gear fault diagnosis in strong noise based on multi-sensor information fusion. J. Vib. Control 2014, 22. [Google Scholar] [CrossRef]
- Li, Y.; Yang, T.; Liu, J.; Fu, N.; Wu, G. A fault diagnosis method by multi sensor fusion for spacecraft control system sensors. In Proceedings of the IEEE International Conference on Mechatronics and Automation, Harbin, China, 7–10 August 2016; pp. 748–753.
- Hang, J.; Zhang, J.; Cheng, M. Fault diagnosis of wind turbine based on multisensors information fusion technology. IET Renew. Power Gener. 2014, 8, 289–298. [Google Scholar] [CrossRef]
- Song, M.; Jiang, W. Engine fault diagnosis based on sensor data fusion using evidence theory. Adv. Mech. Eng. 2016, 8, 1–9. [Google Scholar] [CrossRef]
- Xu, P.; Deng, Y.; Su, X.; Mahadevan, S. A new method to determine basic probability assignment from training data. Knowl. Based Syst. 2013, 46, 69–80. [Google Scholar] [CrossRef]
- Hégarat-Mascle, S.L.; Bloch, I.; Vidal-Madjar, D. Application of Dempster–Shafer evidence theory to unsupervised classification in multisource remote sensing. IEEE Trans. Geosci. Remote Sens. 1997, 35, 1018–1031. [Google Scholar] [CrossRef]
- Salzenstein, F.; Boudraa, A.O. Unsupervised multisensor data fusion approach. In Proceedings of the Symposium on Signal Processing and ITS Applications, Sixth International, Kuala Lumpur, Malaysia, 13–16 August 2001; Volume 1, pp. 152–155.
- Yong, D.; WenKang, S.; ZhenFu, Z.; Qi, L. Combining belief functions based on distance of evidence. Decis. Support Syst. 2004, 38, 489–493. [Google Scholar] [CrossRef]
- Sirbiladze, G.; Khutsishvili, I.; Badagadze, O.; Kapanadze, M. More Precise Decision-Making Methodology in the Temporalized Body of Evidence. Application in the Information Technology Management. Int. J. Inf. Technol. Decis. Mak. 2016, 15, 1–34. [Google Scholar] [CrossRef]
- Bauer, M. Approximation algorithms and decision making in the Dempster–Shafer theory of evidence—An empirical study. Int. J. Approx. Reason. 1997, 17, 217–237. [Google Scholar] [CrossRef]
- Merigó, J.M.; Casanovas, M.; Martínez, L. Linguistic aggregation operators for linguistic decision making with Dempster–Shafer theory of evidence. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2010, 18, 287–304. [Google Scholar] [CrossRef]
- Baba, V.V.; Hakemzadeh, F. Toward a theory of evidence based decision making. Manag. Decis. 2012, 50, 832–867. [Google Scholar] [CrossRef]
- Peng, L.I.; Liu, S.F. Intuitionistic fuzzy decision-making methods based on grey incidence analysis and D–S theory of evidence. Grey Syst. 2012, 2, 54–62. [Google Scholar]
- Li, F.J.; Qian, Y.H.; Wang, J.T.; Liang, J.Y. Multigranulation information fusion: A dempster-shafer evidence theory based clustering ensemble method. In Proceedings of the 2015 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 12–15 July 2015; pp. 58–63.
- Leung, Y.; Ji, N.N.; Ma, J.H. An integrated information fusion approach based on the theory of evidence and group decision-making. Inf. Fusion 2013, 14, 410–422. [Google Scholar] [CrossRef]
- Zhang, X.; Mahadevan, S.; Deng, X. Reliability analysis with linguistic data: An evidential network approach. Reliab. Eng. Syst. Saf. 2017, 162, 111–121. [Google Scholar] [CrossRef]
- Sun, R.; Huang, H.Z.; Miao, Q. Improved information fusion approach based on D–S evidence theory. J. Mech. Sci. Technol. 2008, 22, 2417–2425. [Google Scholar] [CrossRef]
- Jousselme, A.L.; Grenier, D.; Bossé, É. A new distance between two bodies of evidence. Inf. Fusion 2001, 2, 91–101. [Google Scholar] [CrossRef]
- Zadeh, L.A. A simple view of the Dempster–Shafer theory of evidence and its implication for the rule of combination. Ai Mag. 1986, 7, 85–90. [Google Scholar]
- Yager, R.R. On the Dempster–Shafer framework and new combination rules. Inf. Sci. Int. J. 1987, 41, 93–137. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Representation And Combination Of Uncertainty With Belief Functions And Possibility Measures. Comput. Intell. 2007, 4, 244–264. [Google Scholar] [CrossRef]
- Lefevre, E.; Colot, O.; Vannoorenberghe, P. Belief function combination and conflict management. Inf. Fusion 2002, 3, 149–162. [Google Scholar] [CrossRef]
- Murphy, C.K. Combining belief functions when evidence conflicts. Decis. Support Syst. 2000, 29, 1–9. [Google Scholar] [CrossRef]
- Casella, G.; Berger, R.L. Statistical Inference, 2nd ed.; Duxbury Press: Pacific Grove, CA, USA, 2002. [Google Scholar]
- Jiang, W.; Zhang, A.; Yang, Q. Fuzzy Approach to Construct Basic Probability Assignment and Its Application in Multi-Sensor Data Fusion Systems. Chin. J. Sens. Actuators 2008, 21, 1717–1720. [Google Scholar]
- Pan, Q.; Cheng, Y.; Liang, Y.; Yang, F.; Wang, X. Multi-Source Information Fusion Theory and Its Application; Tsinghua University Press: Beijing, China, 2013. [Google Scholar]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Hum. Genet. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Lichman, M. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2013; Available online: http://archive.ics.uci.edu/ml (accessed on 12 March 2017).
- Wen, C.; Xu, X. Theories and Applications in Multi-Source Uncertain Information Fusion—Fault Diagnosis and Reliability Evaluation; Beijing Science Press: Beijing, China, 2012. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | ||||
|---|---|---|---|---|
| S | (5.0050, 0.3203) | (3.4000, 0.3061) | (1.4450, 0.1356) | (0.2450, 0.0887) |
| E | (5.8600, 0.5510) | (2.7250, 0.3567) | (4.1300, 0.5497) | (1.2650, 0.2277) |
| V | (6.6250, 0.5466) | (3.0000, 0.2847) | (5.4400, 0.4627) | (1.9350, 0.2815) |
| TestModel | (6.1800, 0.4492) | (2.7500, 0.3375) | (4.4100, 0.3635) | (1.3400, 0.1647) |
| Category | |||||||
|---|---|---|---|---|---|---|---|
| 0.1086 | 0.8324 | 0.7254 | 0.1086 | 0.0595 | 0.5934 | 0.0595 | |
| 0.2982 | 0.9919 | 0.6336 | 0.2974 | 0.2980 | 0.6289 | 0.2974 | |
| 2 × | 0.9196 | 0.2416 | 1.9 × | 2 × | 0.2385 | 2 × | |
| 1.2 × | 0.9660 | 0.2470 | 1.1 × | 5.5 × | 0.2471 | 5.5 × |
| Category | |||||||
|---|---|---|---|---|---|---|---|
| 0.0437 | 0.3346 | 0.2916 | 0.0437 | 0.0239 | 0.2385 | 0.0239 | |
| 0.0865 | 0.2879 | 0.1839 | 0.0863 | 0.0865 | 0.1825 | 0.0863 | |
| 1.4 × | 0.6570 | 0.1726 | 1.3 × | 1.4 × | 0.1704 | 1.4 × | |
| 8.2 × | 0.6616 | 0.1692 | 8.2 × | 3.8 × | 0.1692 | 3.8 × | |
| Final BPA | 4.9 × | 0.8798 | 0.1130 | 3.3 × | 2.2 × | 0.0066 | 1.5 × |
| Category | Test Times | Identification Accuracy |
|---|---|---|
| S | 10,000 | |
| E | 10,000 | |
| V | 10,000 |
| Category of Models | Mean Value | Standard Deviation |
|---|---|---|
| 4.3241 | 0.3240 | |
| 4.6414 | 0.3087 | |
| 9.8220 | 0.1010 | |
| 5.0105 | 0.6455 |
| Category | |||||||
|---|---|---|---|---|---|---|---|
| 0.0773 | 0.8452 | 0 | 0.0775 | 0 | 0 | 0 | |
| 0 | 0.4052 | 0.2974 | 0 | 0 | 0.2974 | 0 | |
| 0 | 0.9995 | 0.0002 | 0 | 0 | 0.0003 | 0 | |
| Final BPA | 0.0020 | 0.9973 | 0.00056 | 0.0001 | 0 | 0.00004 | 0 |
| Case | Real Category | Combined BPA | Diagnostic Category |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Hu, W.; Xie, C. A New Engine Fault Diagnosis Method Based on Multi-Sensor Data Fusion. Appl. Sci. 2017, 7, 280. https://doi.org/10.3390/app7030280
Jiang W, Hu W, Xie C. A New Engine Fault Diagnosis Method Based on Multi-Sensor Data Fusion. Applied Sciences. 2017; 7(3):280. https://doi.org/10.3390/app7030280
Chicago/Turabian StyleJiang, Wen, Weiwei Hu, and Chunhe Xie. 2017. "A New Engine Fault Diagnosis Method Based on Multi-Sensor Data Fusion" Applied Sciences 7, no. 3: 280. https://doi.org/10.3390/app7030280
APA StyleJiang, W., Hu, W., & Xie, C. (2017). A New Engine Fault Diagnosis Method Based on Multi-Sensor Data Fusion. Applied Sciences, 7(3), 280. https://doi.org/10.3390/app7030280