Silicon Photonics towards Disaggregation of Resources in Data Centers



 and
and 
Abstract
:1. Introduction
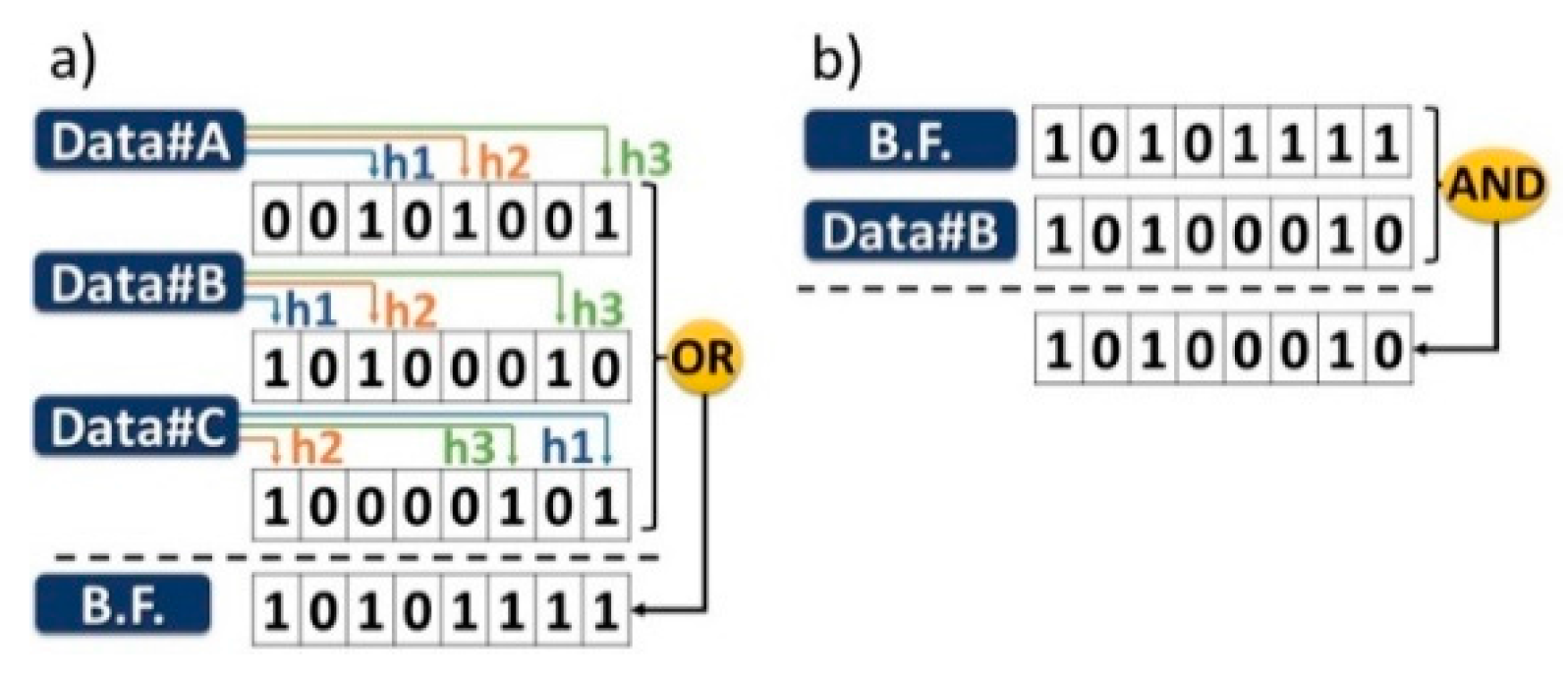
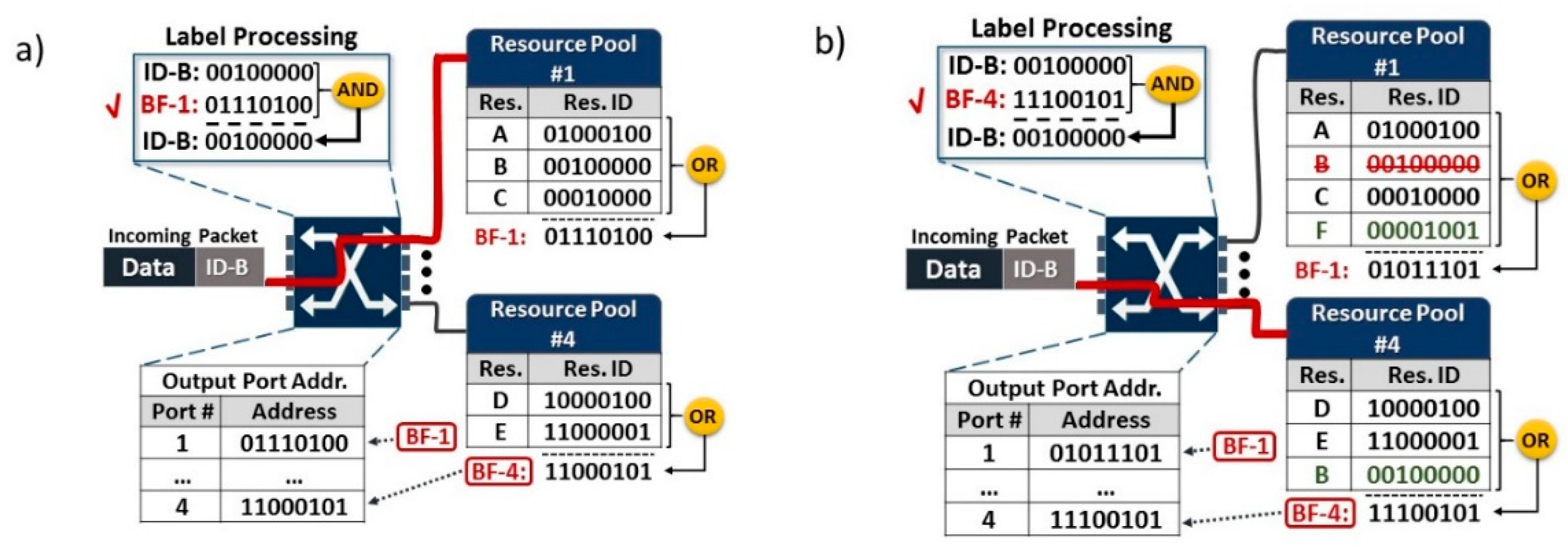
2. Bloom Filter Labelling for Packet Switching with Photonic Integrated Switches
2.1. Concept
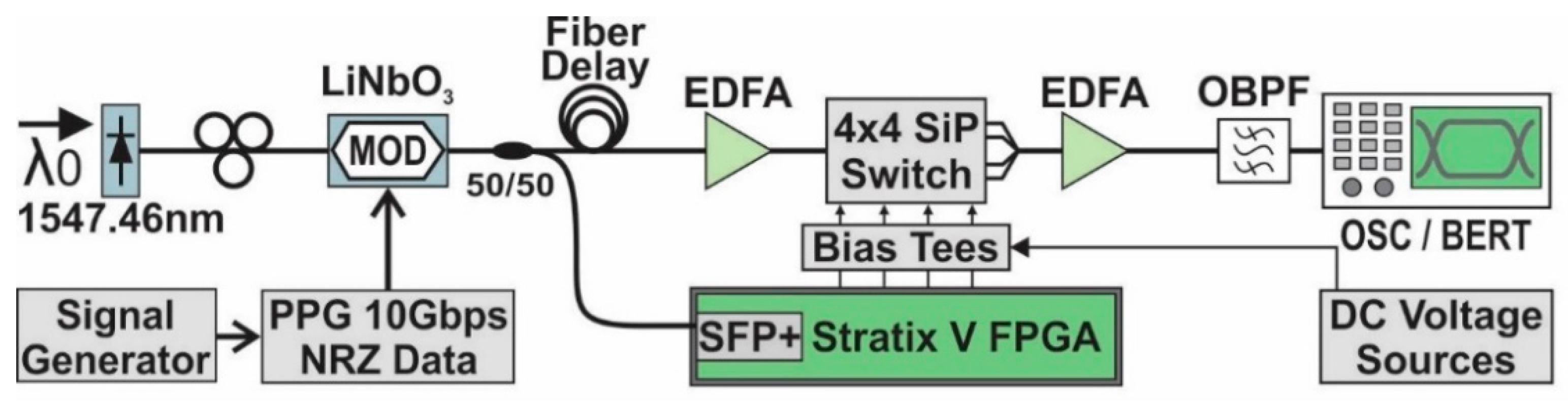
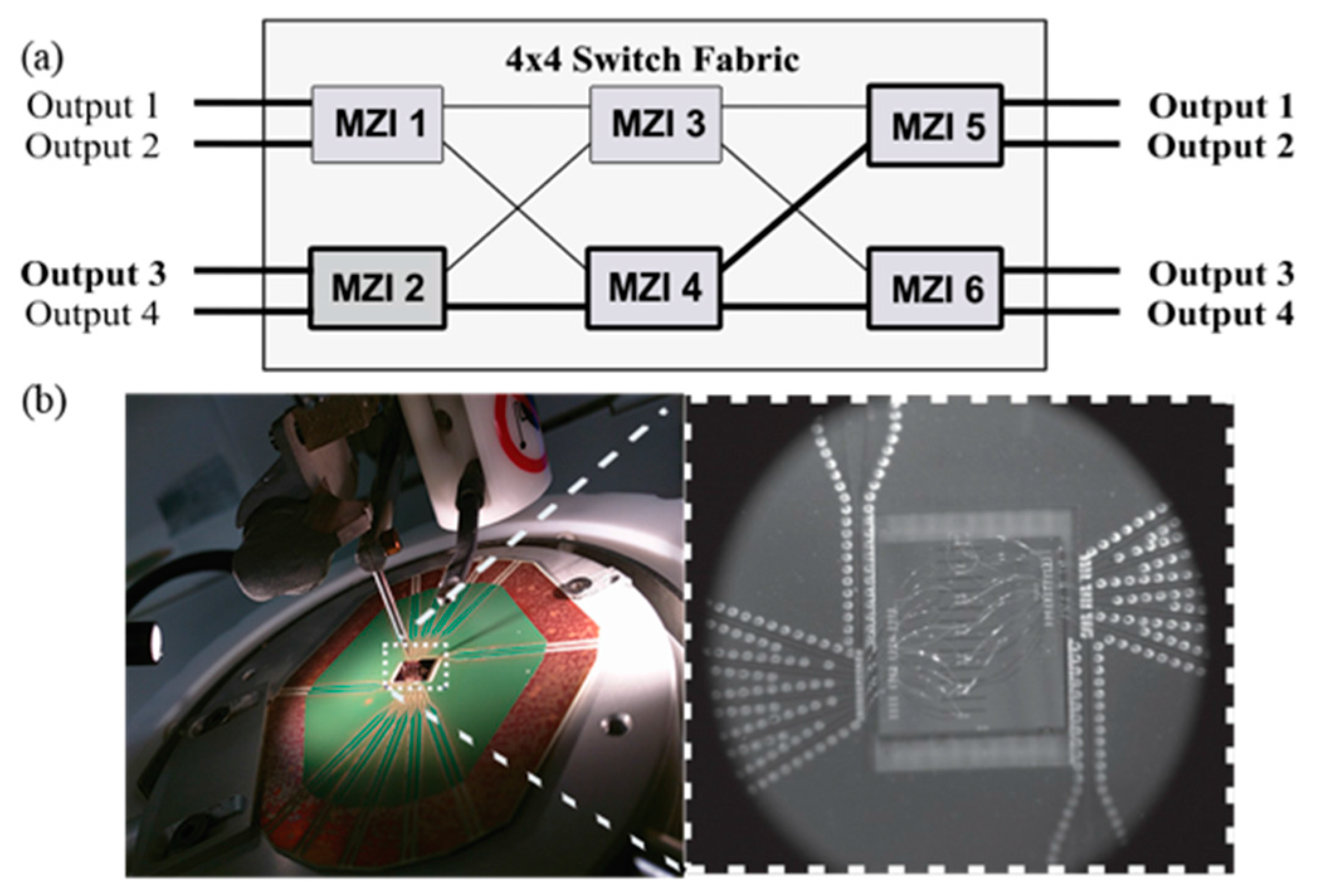
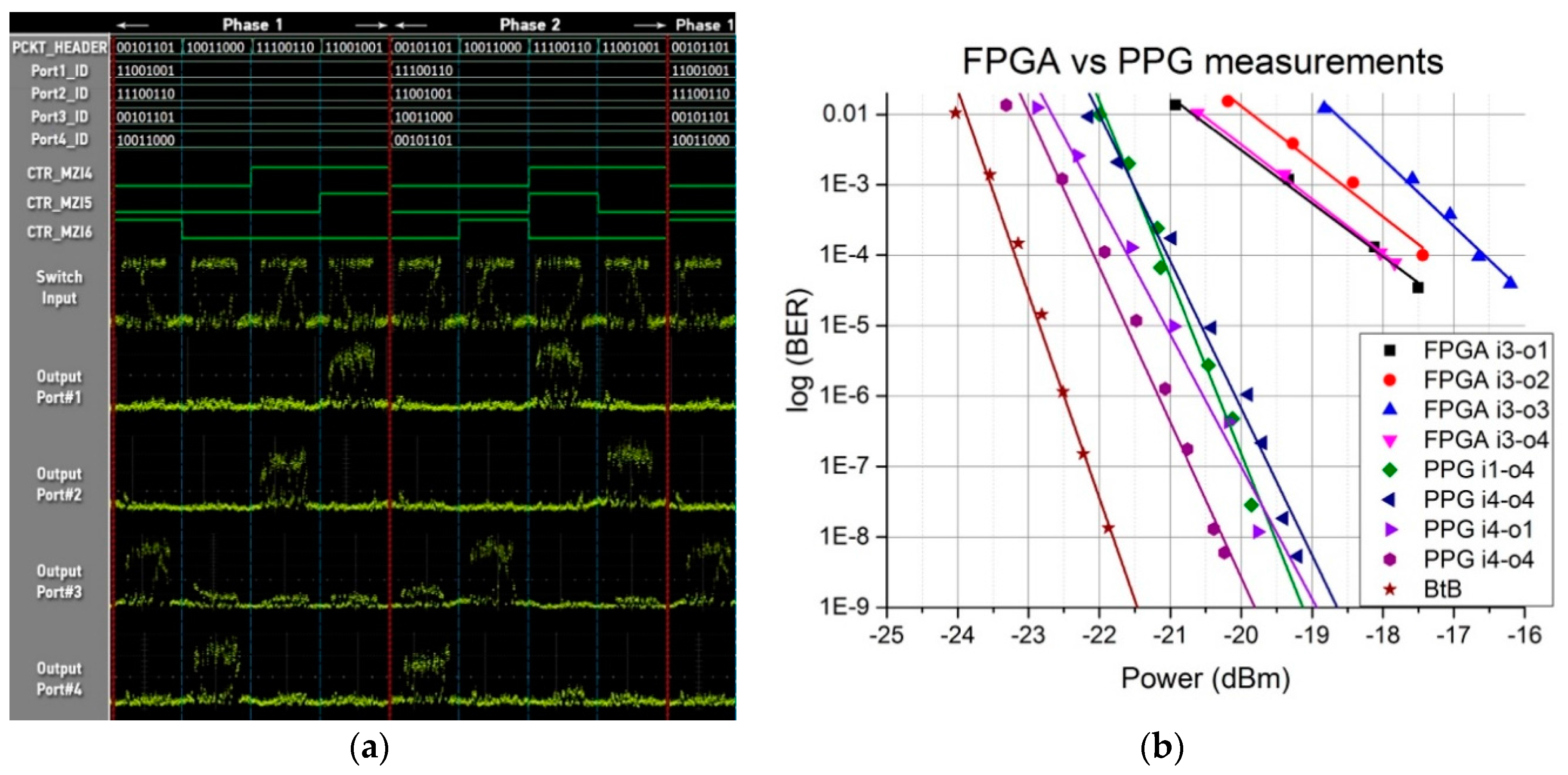
2.2. Experimental Setup
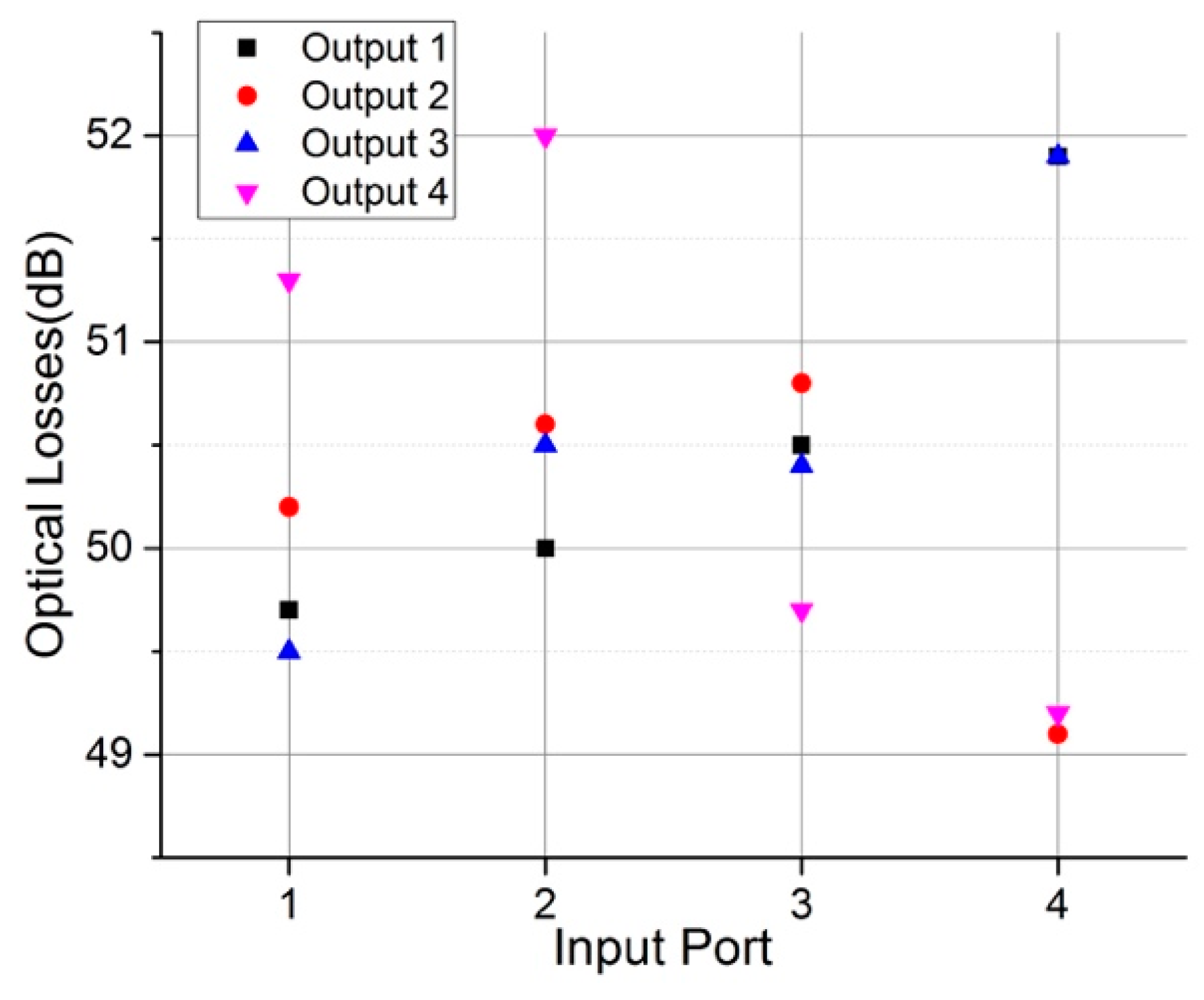
2.3. Results
3. Optical Buffering and TSI with Integrated Delay Lines
3.1. Concept
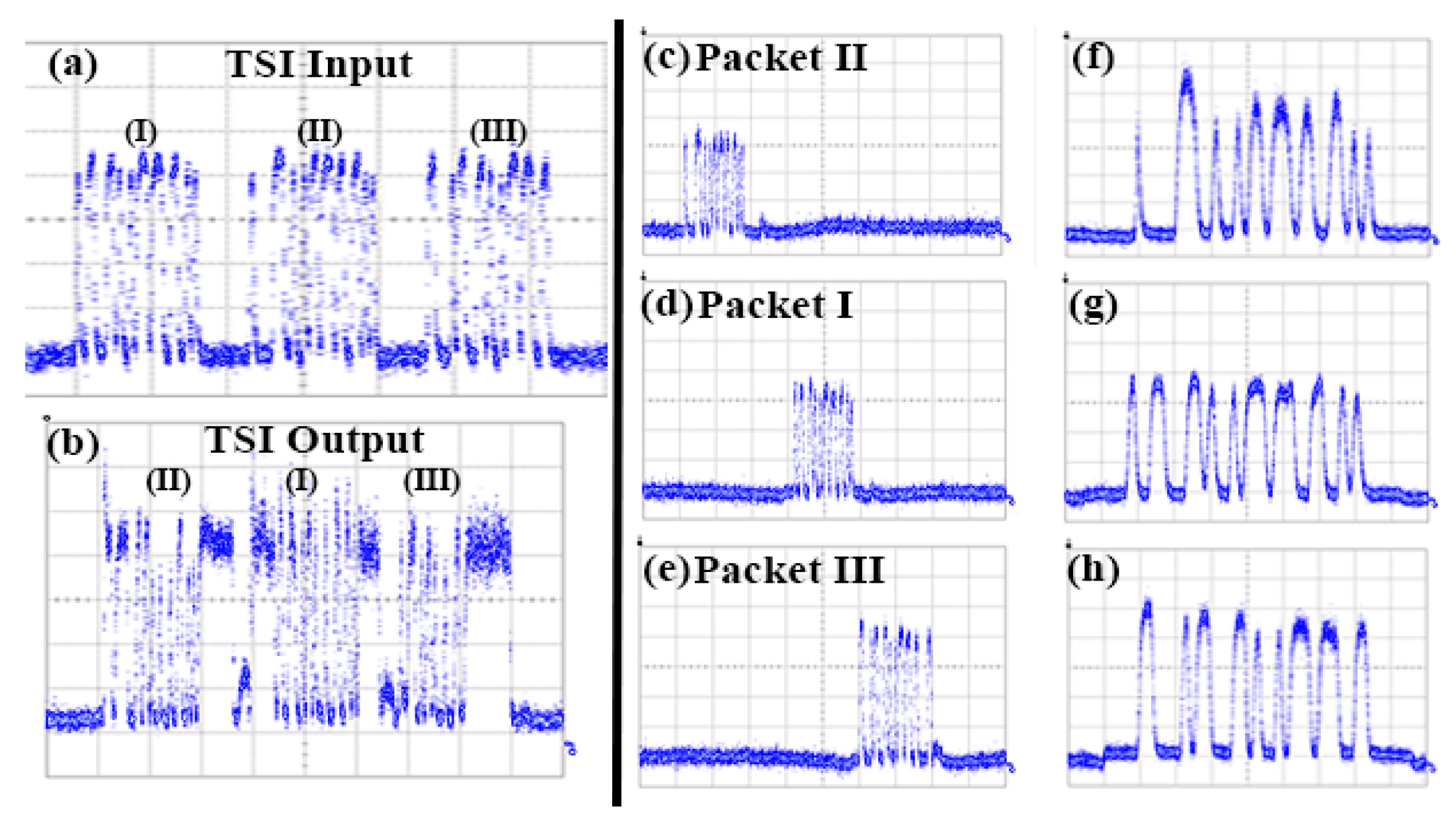
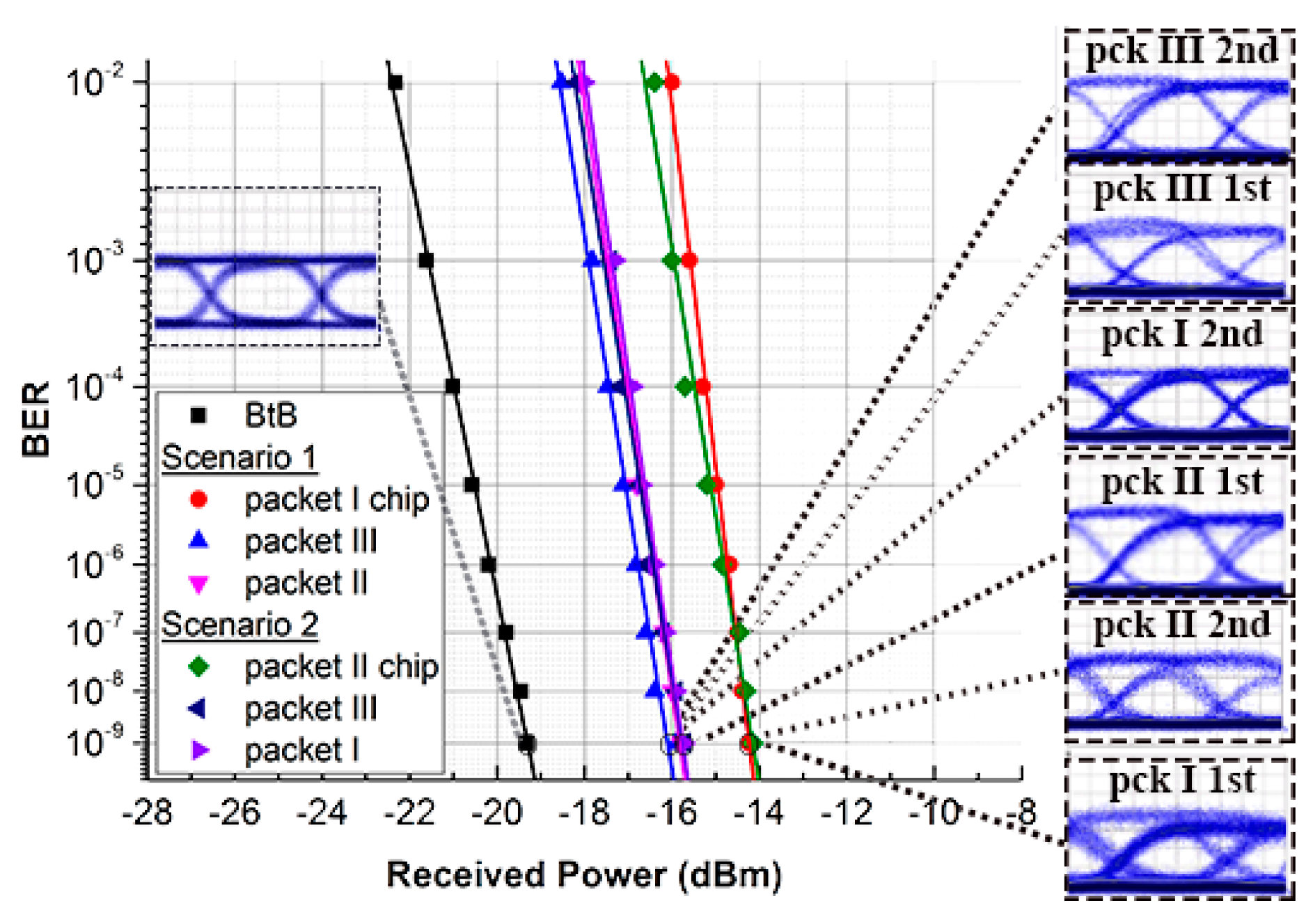
3.2. Experimental Setup and Results for Optical Packet Buffering
3.3. Experimental Setup and Results for Optical TSI
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Di, S.; Kondo, D.; Cappello, F. Characterizing Cloud Applications on a Google Data Center. In Proceedings of the 42nd International Conference on Parallel Processing (ICPP), Lyon, France, 1–4 October 2013; pp. 468–473. [Google Scholar]
- Reiss, C.; Tumanov, A.; Ganger, G.R.; Katz, R.H.; Kozuch, M.A. Heterogeneity and dynamicity of clouds at scale: Google trace analysis. In Proceedings of the Third ACM Symposium on Cloud Computing, San Jose, CA, USA, 14–17 October 2012; pp. 1–13. [Google Scholar]
- Facebook. The Open Compute Server Architecture Specications. Available online: www.opencompute.org (accessed on 1 November 2017).
- Intel. Rack Scale Architecture. Available online: http://www.intel.com/content/www/us/en/architecture-and-technology/rack-scale-design-overview.html (accessed on 1 November 2017).
- Weiss, J.; Dangel, R.; Hofrichter, J.; Horst, F.; Jubin, D.; Meier, N.; La Porta, A.; Jan Offrein, B. Optical Interconnects for Disaggregated Resources in Future Datacenters; European Conference on Optical Communication (ECOC): Cannes, France, 2014; pp. 1–3. [Google Scholar]
- Ali, H.M.M.; Lawey, A.Q.; El-Gorashi, T.E.H.; Elmirghani, J.M.H. Energy efficient disaggregated servers for future data centers. In Proceedings of the 20th European Conference on Networks and Optical Communications—(NOC), London, UK, 30 June–2 July 2015; pp. 1–6. [Google Scholar]
- Papaioannou, A.D.; Nejabati, R.; Simeonidou, D. The Benefits of a Disaggregated Data Centre: A Resource Allocation Approach. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–7. [Google Scholar]
- Available online: http://www.brocade.com/content/html/en/solution-design-guide/brocade-dc-fabric-architectures-sdg/GUID-A0E2AF7F-C47A-458D-989A-35EC97E262DD.html (accessed on 1 November 2017).
- Yu, M.; Fabrikant, A.; Rexford, J. BUFFALO: Bloom filter forwarding architecture for large organizations. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; pp. 313–324. [Google Scholar]
- Li, D.; Li, Y.; Wu, J.; Su, S.; Yu, J. ESM: Efficient and Scalable Data Center Multicast Routing. IEEE/ACM Trans. Netw. 2012, 20, 944–955. [Google Scholar] [CrossRef]
- Rothenberg, C.E.; Macapuna, C.; Verdi, F.; Magalhães, M.; Zahemszky, A. Data center networking with in-packet Bloom filters. In Proceedings of the SBRC, Gramado, Brazil, 24 May 2010; pp. 553–566. [Google Scholar]
- Qiao, L.; Tang, W.; Chu, T. Ultra-large-scale silicon optical switches. In Proceedings of the IEEE 13th International Conference on Group IV Photonics (GFP), Shanghai, China, 24–26 August 2016; pp. 1–2. [Google Scholar]
- Seok, T.J.; Quack, N.; Han, S.; Muller, R.S.; Wu, M.C. Large-scale broadband digital silicon photonic switches with vertical adiabatic couplers. Optica 2016, 3, 64–70. [Google Scholar] [CrossRef]
- Suzuki, K.; Tanizawa, K.; Matsukawa, T.; Cong, G.; Kim, S.-H.; Suda, S.; Ohno, M.; Chiba, T.; Takadoro, H.; Yanagihara, M.; et al. Ultra-compact 8 × 8 strictly-non-blocking Si-wire PILOSS switch. Opt. Express 2014, 22, 3887–3894. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.P.; Zhu, X.; Liu, Y.; Wen, K.; Chik, M.S.; Baehr-Jones, T.; Hochberg, M.; Bergman, K. Programmable Dynamically-Controlled Silicon Photonic Switch Fabric. J. Lightwave Technol. 2016, 34, 2952–2958. [Google Scholar] [CrossRef]
- Dupuis, N.; Rylyakov, A.V.; Schow, C.L.; Kuchta, D.M.; Baks, C.W.; Orcutt, J.S.; Gill, M.D.; Green, W.; Lee, B. Nanosecond-Scale Mach-Zehnder-Based CMOS Photonic Switch Fabrics. J. Lightwave Technol. 2017, 35, 615–623. [Google Scholar] [CrossRef]
- Nikolova, D.; Calhoun, D.M.; Liu, Y.; Rumley, S.; Novack, A.; Baehr-Jones, T.; Hochberg, M.; Bergman, K. Modular architecture for fully non-blocking silicon photonic switch fabric. Microsyst. Nanoeng. 2017, 3, 16071. [Google Scholar] [CrossRef]
- Shiraishi, T.; Li, Q.; Liu, Y.; Zhu, X.; Padmaraju, K.; Ding, R.; Hochberg, M.; Bergman, K. A Reconfigurable and Redundant Optically-Connected Memory System using a Silicon Photonic Switch. In Proceedings of the Optical Fiber Communication Conference, San Francisco, CA, USA, 9–13 March 2014; p. Th2A.10. [Google Scholar]
- Xiong, Y.; de Magalhães, F.G.; Radi, B.; Nicolescu, G.; Hessel, F.; Liboiron-ladouceur, O. Towards a Fast Centralized Controller for Integrated Silicon Photonic Multistage MZI-based Switches. In Proceedings of the Optical Fiber Communication Conference, Anaheim, CA, USA, 20–22 March 2016; p. W1J.2. [Google Scholar]
- Calhoun, D.; Wen, K.; Zhu, X.; Rumley, S.; Luo, L.; Liu, Y.; Ding, R.; Baehr-Jones, T.; Hochberg, M.; Lipson, M.; Bergman, K. Dynamic reconfiguration of silicon photonic circuit switched interconnection networks. In Proceedings of the IEEE High Perform Extreme Computer Conference, Waltham, MA, USA, 9–11 September 2014. [Google Scholar]
- Lou, F.; Fard, M.M.P.; Liao, P.; Hai, M.S.; Priti, R.; Huangfu, Y.; Qui, C.; Hao, Q.; Wei, Z.; Liboiron-Ladouceur, O. Towards a centralized controller for silicon photonic MZI-based interconnects. In Proceedings of the IEEE Optical Interconnects Conference (OI), San Diego, CA, USA, 20–22 April 2015; pp. 146–147. [Google Scholar]
- Calhoun, D.M.; Li, Q.; Browning, C.; Abrams, N.C.; Liu, Y.; Ding, R.; Barry, L.; Baehr-Jones, T.; Hochberg, M.; Bergman, K. Programmable wavelength locking and routing in a silicon-photonic interconnection network implementation. In Proceedings of the 2015 Optical Fiber Communications Conference and Exhibition (OFC), Los Angeles, CA, USA, 22–26 March 2015; pp. 1–3. [Google Scholar]
- Yiannopoulos, K.; Vlachos, K.G.; Varvarigos, E. Multiple-Input-Buffer and Shared-Buffer Architectures for Optical Packet- and Burst-Switching Networks. J. Lightwave Technol. 2007, 25, 1379–1389. [Google Scholar] [CrossRef]
- Miao, W.; Yan, F.; Calabretta, N. Towards Petabit/s All-Optical Flat Data Center Networks Based on WDM Optical Cross-Connect Switches with Flow Control. J. Lightwave Technol. 2016, 34, 4066–4075. [Google Scholar] [CrossRef]
- Terzenidis, N.; Moralis-Pegios, M.; Vagionas, C.; Pitris, S.; Chatzianagnostou, E.; Maniotis, P.; Syrivelis, D.; Tassiulas, L.; Miliou, A.; Pleros, N.; et al. Optically-Enabled Bloom Filter Label Forwarding Using a Silicon Photonic Switching Matrix. J. Lightwave Technol. 2017, 35, 4758–4765. [Google Scholar] [CrossRef]
- Moralis-Pegios, M.; Mourgias-Alexandris, G.; Terzenidis, N.; Cherchi, M.; Harjanne, M.; Aalto, T.; Miliou, A.; Pleros, N.; Vyrsokinos, K. On-chip SOI Delay Line Bank for Optical Buffers and Time Slot Interchangers. IEEE Photonics Technol. Lett. 2018, 30, 31–34. [Google Scholar] [CrossRef]
- Morichetti, F.; Melloni, A.; Ferrari, C.; Martinelli, M. Error-free continuously-tunable delay at 10 Gbit/s in a reconfigurable on-chip delay-line. Opt. Exp. 2008, 16, 8395–8405. [Google Scholar] [CrossRef]
- Kwack, M.J.; Oyama, T.; Hashizume, Y.; Mino, S.; Zaitsu, M.; Tanemura, T.; Nakano, Y. Integrated Optical Buffer Using InP 1 × 8 Switch and Silica-Based Delay Line Circuit; OFC: Los Angeles, CA, USA, 2012; pp. 1–3. [Google Scholar]
- Lee, H.; Chen, T.; Li, J.; Painter, O.; Vahala, K.J. Ultra-low-loss optical delay line on a silicon chip. Nat. Commun. 2012, 3, 867. [Google Scholar] [CrossRef] [PubMed]
- Burmeister, E.F.; Mack, J.P.; Poulsen, H.N.; Mašanović, M.L.; Stamenic, B.; Blumenthal, D.J.; Bowers, J.E. Photonic integrated circuit optical buffer for packet-switched networks. Opt. Exp. 2009, 17, 6629–6635. [Google Scholar] [CrossRef]
- LeGrange, J.D.; Simsarian, J.E.; Bernasconi, P.; Neilson, D.T.; Buhl, L.L.; Gripp, J. Demonstration of an integrated buffer for an all-optical packet router. IEEE Photonics Technol. Lett. 2009, 21, 781–783. [Google Scholar] [CrossRef]
- Moreira, R.L.; Garcia, J.; Li, W.; Bauters, J.; Barton, J.S.; Heck, M.J.; Blumenthal, D.J. Integrated Ultra-Low-Loss 4-Bit Tunable Delay for Broadband Phased Array Antenna Applications. IEEE Photonics Technol. Lett. 2013, 25, 1165–1168. [Google Scholar] [CrossRef]
- Pan, Z.; Subbaraman, H.; Lin, X.; Li, Q.; Zhang, C.; Ling, T.; Jay Guo, L.; Chen, R. Reconfigurable thermo-optic polymer switch based true-time-delay network utilizing imprinting and inkjet printing. In Proceedings of the Confrence on Lasers and Electro-Optics (CLEO), San Jose, CA, USA, 10–15 May 2014; pp. 1–2. [Google Scholar]
- Stopinski, S.; Malinowski, M.; Piramidowicz, R.; Kleijn, E.; Smit, M.K.; Leijtens, X.J.M. Integrated Optical Delay Lines for Time-Division Multiplexers. IEEE Photonics Technol. Lett. 2013, 5, 7902109. [Google Scholar] [CrossRef]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Broder, A.; Mitzenmacher, M. Network applications of bloom filters: A survey. Internet Math. 2004, 1, 485–509. [Google Scholar] [CrossRef]
- Syrivelis, D.; Parisis, G.; Trossen, D.; Flegkas, P.; Sourlas, V.; Korakis, T.; Tassiulas, L. Pursuing a Software Defined Information-centric Network. In Proceedings of the European Workshop on Software Defined Networking, Darmstadt, Germany, 25–26 October 2012; pp. 103–108. [Google Scholar]
- You, W.; Mathieu, B.; Truong, P.; Peltier, J.F.; Simon, G. DiPIT: A Distributed Bloom-Filter Based PIT Table for CCN Nodes. In Proceedings of the 21st International Conference on Computer Communications and Networks (ICCCN), München, Germany, 30 July–2 August 2012; pp. 1–7. [Google Scholar]
- Du, Y.; He, G.; Yu, D. Efficient Hashing Technique Based on Bloom Filter for High-Speed Network. In Proceedings of the 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 27–28 August 2016; pp. 58–63. [Google Scholar]
- Vyrsokinos, K.; Moralis-Pegios, M.; Vagionas, C.; Brimont, A.; Zanzi, A.; Sanchis, P.; Marti, J.; Kraft, J.; Rochracher, K.; Dorrestein, S.; et al. Single Mode Optical Interconnects for future data centers. In Proceedings of the 2016 18th International Conference on Transparent Optical Networks (ICTON), Trento, Italy, 10–14 July 2016; pp. 1–4. [Google Scholar]
- Xiong, Y.; Magalhães, F.G.D.; Nicolescu, G.; Hessel, F.; Liboiron-Ladouceur, O. Co-design of a low-latency centralized controller for silicon photonic multistage MZI-based switches. In Proceedings of the 2017 Optical Fiber Communications Conference and Exhibition (OFC), Los Angeles, CA, USA, 19–23 March 2017; pp. 1–3. [Google Scholar]
- T.I. Incorporated. LM7171 Datasheet. Available online: http://www.ti.com/product/LM7171/datasheet (accessed on 1 November 2017).
- Celo, D.; Goodwill, D.J.; Jia, J.; Dumais, P.; Chunshu, Z.; Fei, Z.; Tu, X.; Zhang, C.; Yan, S.; He, J.; et al. 32 × 32 silicon photonic switch. In Proceedings of the 2016 21st OptoElectronics and Communications Conference (OECC) Held Jointly with 2016 International Conference on Photonics in Switching (PS), Niigata, Japan, 3–7 July 2016; pp. 1–3. [Google Scholar]
- Cheng, Q.; Wonfor, A.; Wei, J.L.; Penty, R.V.; White, I.H. Demonstration of the feasibility of large-port-count optical switching using a hybrid Mach-Zehnder interferometer-semiconductor optical amplifier switch module in a recirculating loop. Opt. Lett. 2014, 39, 5244–5247. [Google Scholar] [CrossRef] [PubMed]
- Dupuis, N.; Rylyakov, A.V.; Schow, C.L.; Kuchta, D.M.; Baks, C.W.; Orcutt, J.S.; Gill, M.D.; Green, W.; Lee, B.G. Ultralow crosstalk nanosecond-scale nested 2 × 2 Mach–Zehnder silicon photonic switch. Opt. Lett. 2016, 41, 3002–3005. [Google Scholar] [CrossRef] [PubMed]
- Pitris, S.; Vagionas, C.; Tekin, T.; Broeke, R.; Kanellos, G.T.; Pleros, N. WDM-enabled optical RAM at 5 Gb/s using a monolithic InP flip-flop chip. IEEE Photonics J. 2016, 8, 1–7. [Google Scholar] [CrossRef]
- Beheshti, N.; Burmeister, E.; Ganjali, Y.; Bowers, J.E.; Blumenthal, D.J.; McKeown, N. Optical Packet Buffers for Backbone Internet Routers. IEEE/ACM Trans. Netw. 2010, 18, 1599–1609. [Google Scholar] [CrossRef]
- Geldenhuys, R.; Van der Merwe, J.S.; Thakulsukanant, K.; Wang, Z.; Chi, N.; Yu, S. Contention resolution and variable length optical packet switching using the active vertical-coupler-based optical Crosspoint switch. Opt. Switch. Netw. 2011, 8, 86–92. [Google Scholar] [CrossRef]
- Zouraraki, O.; Yiannopoulos, K.; Zakynthinos, P.; Petrantonakis, D.; Varvarigos, E.; Poustie, A.; Maxwell, G.; Avramopoulos, H. Implementation of an all-optical time-slot-interchanger architecture. IEEE Photonics Technol. Lett. 2007, 19, 1307–1309. [Google Scholar] [CrossRef]
- Sheng, X.; Feng, Z.; Li, B. Experimental investigation of all-optical packet-level time slot assignment using two optical buffers cascaded. Appl. Opt. 2013, 52, 2917–2922. [Google Scholar] [CrossRef] [PubMed]
- Moralis-Pegios, M.; Terzenidis, N.; Mourgias-Alexandris, G.; Vyrsokinos, K.; Pleros, N. A Low-Latency High-Port Count Optical Switch with Optical Delay Line Buffering for Disaggregated Data Centers; SPIE: San Francisco, CA, USA, 29 January 2018; pp. 10538–10544. [Google Scholar]
- Cherchi, M.; Ylinen, S.; Harjanne, M.; Kapulainen, M.; Vehmas, T.; Aalto, T. Low-loss spiral waveguides with ultra-small footprint on a micron scale SOI platform. In Proceedings of the SPIE, San Francisco, CA, USA, 8 March 2014. [Google Scholar]
- Aalto, T.; Solehmainen, K.; Harjanne, M.; Kapulainen, M.; Heimala, P. Low-loss converters between optical silicon waveguides of different sizes and types. IEEE Photonics Technol. Lett. 2006, 18, 709–711. [Google Scholar] [CrossRef]
- Apostolopoulos, D.; Vyrsokinos, K.; Zakynthinos, P.; Pleros, N.; Avramopoulos, H. A SOA-MZI NRZ Wavelength Conversion Scheme With Enhanced 2R Regeneration Characteristics. IEEE Photonics Technol. Lett. 2009, 21, 1363–1365. [Google Scholar] [CrossRef]
- Aalto, T.; Solehmainen, K.; Harjanne, M.; Kapulainen, M.; Heimala, P. Silicon photonics for optical connectivity: Small footprint with large dimensions. In Proceedings of the 2015 IEEE OI, Optical Interconnects Conference (OI), San Diego, CA, USA, 20–22 April 2015; pp. 40–41. [Google Scholar]
- Apostolopoulos, D.; Klonidis, D.; Zakynthinos, P.; Vyrsokinos, K.; Pleros, N.; Tomkos, I.; Avramopoulos, H. Cascadability Performance Evaluation of a new NRZ SOA-MZI Wavelength Converter. IEEE Photonics Technol. Lett. 2009, 21, 1341–1343. [Google Scholar] [CrossRef]
- Spyropoulou, M.; Pleros, N.; Vyrsokinos, K.; Apostolopoulos, D.; Bougioukos, M.; Petrantonakis, D.; Miliou, A.; Avramopoulos, H. 40 Gb/s NRZ Wavelength Conversion using a Differentially-Biased SOA-MZI: Theory and Experiment. J. Lightwave Technol. 2011, 29, 1489–1499. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S1 | S2 | S3 | S4 | S5 | S6 | |
|---|---|---|---|---|---|---|
| CROSS | 1.08 V (21 mA) | 0 V | 1.03 V (17 mA) | 0.98 V (11 mA) | 0.89 V (6 mA) | 1.18 V (36 mA) |
| BAR | 0.89 V (4 mA) | 1.02 V (16 mA) | 0 V | 0 V | 0 V | 0.9 V (7 mA) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moralis-Pegios, M.; Terzenidis, N.; Mourgias-Alexandris, G.; Vyrsokinos, K. Silicon Photonics towards Disaggregation of Resources in Data Centers. Appl. Sci. 2018, 8, 83. https://doi.org/10.3390/app8010083
Moralis-Pegios M, Terzenidis N, Mourgias-Alexandris G, Vyrsokinos K. Silicon Photonics towards Disaggregation of Resources in Data Centers. Applied Sciences. 2018; 8(1):83. https://doi.org/10.3390/app8010083
Chicago/Turabian StyleMoralis-Pegios, Miltiadis, Nikolaos Terzenidis, George Mourgias-Alexandris, and Konstantinos Vyrsokinos. 2018. "Silicon Photonics towards Disaggregation of Resources in Data Centers" Applied Sciences 8, no. 1: 83. https://doi.org/10.3390/app8010083
APA StyleMoralis-Pegios, M., Terzenidis, N., Mourgias-Alexandris, G., & Vyrsokinos, K. (2018). Silicon Photonics towards Disaggregation of Resources in Data Centers. Applied Sciences, 8(1), 83. https://doi.org/10.3390/app8010083