Learning and Planning Based on Merged Experience from Multiple Situations for a Service Robot


Abstract
:1. Introduction
- We introduce abstract methods to integrate the empirical activity schemas of multiple situations, allowing the robot to adapt task plans in a dynamically changing environment by selecting the branches that correspond to learned activity schema from a similar situation.
- We present a novel algorithm that learns an activity schema with abstract methods for scenarios with complex tasks.
- We present an approach of generation of HTN plans based on integrated empirical activity schema with merging optimization, which solves the tasks with loops in the plan layer.
- We present a replanning algorithm that partially backtracks to the parent node layer by layer in the activity schema tree.
- We demonstrate the proposed algorithms with simulation and physical experiment in two scenarios.
2. Learning and Planning Methods
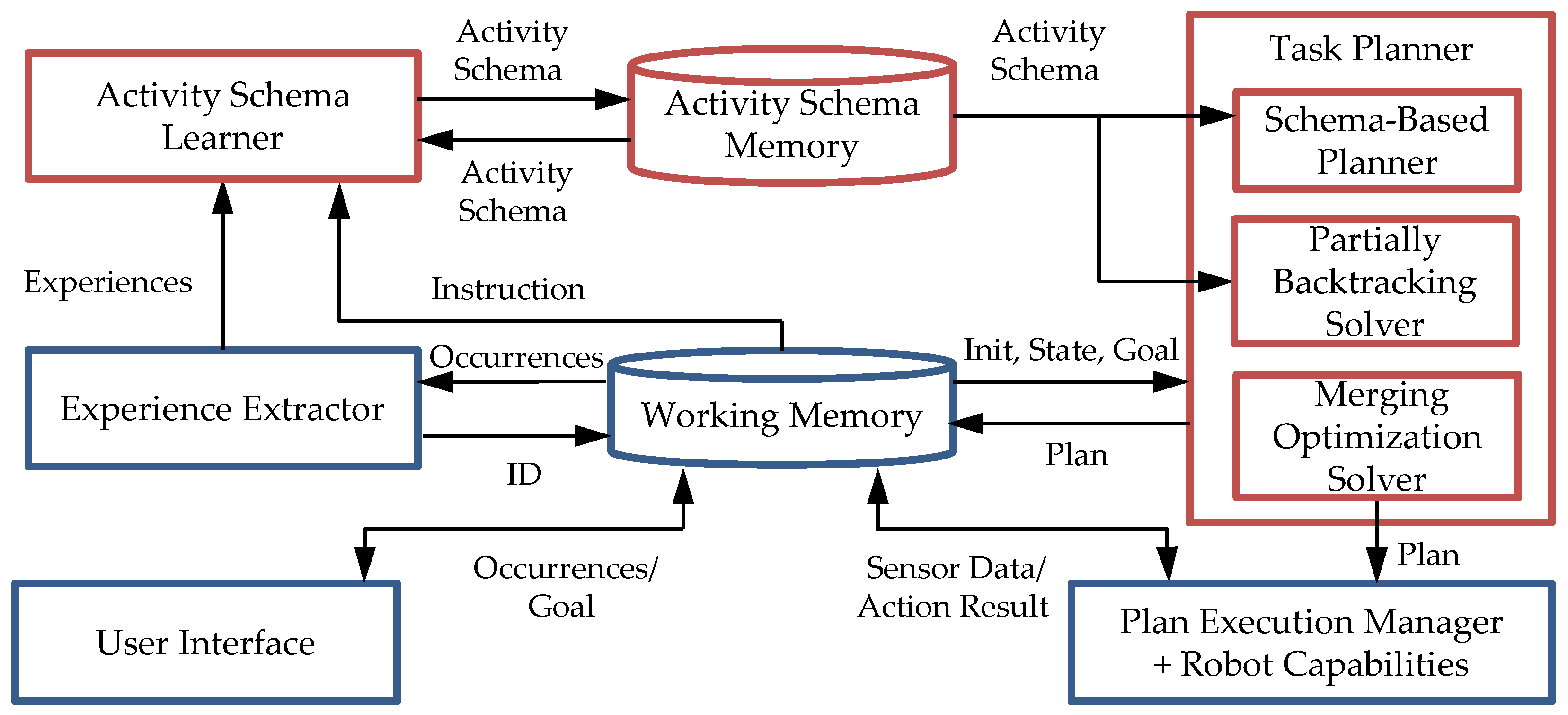
2.1. Overall Framework
2.2. Representation
2.3. Learn Activity Schema with Abstract Methods
2.3.1. Relevant Predicates Extraction
2.3.2. Determine the Structure of the Abstract Method
| Algorithm 1 Learning activity schema with abstract methods |
| 1: generalize a robot activity experience e using EBG |
| 2: abstract and translate operators to enriched abstract operators Ω |
| 3: AM ← abstract (M) |
| 4: │ for each mi in M do |
| 5: │ name(ami) ← name(mi); argument(ami) ← argument(mi) |
| 6: │ subtasks of ami ← sequence of enriched abstract operators Ωi under ami |
| 7: │ preconditions of ami ← F(Ωi) |
| 8: │ F(AM) ← F(M) |
| 9: ma ← (t, AM, Ω) |
| 10: Merge(ma, ma’) |
| 11: │ if AM’ AM then |
| 12: │ if AM’ AM then |
| 13: │ AMF ← add generalize(AM’ – AM) ; return |
| 14: │ else |
| 15: │ add subtask to the ma under the preconditions F(AM) |
| 16: │ F(AM’) ← add not(F(AM) - F(AM’)); return |
| 17: │ F(AM’)← F(AM)∩F(AM’) |
| 18: │ for each ami in ma do |
| 19: │ for k = 1 to num(subk’) |
| 20: │ if subk’ = Ωi then presubk’← F(Ωi)∩presubk’; return |
| 21: │ elseif subk’ Ωi then |
| 22: │ amf ← generalize (Ωi –subk’) under the preconditions F(Ωi)-F(subk’) |
| 23: │ AMF ← add amf ; return |
| 24: │ add Ωi to the ami under the preconditions F(Ωi); num(subk’)← num(subk’)+1 |
| 25: │ for k = 1 to num(subk’)-1 do |
| 26: │ F(subj’) ← add not(F(Ωi) - F(subj’)) |
| 27: │ return ma’ |
- Generalize a robot activity experience e using explanation-based generalization (EBG) as the work [2].
- The generalized operators are abstracted and translated to enriched abstract operators Ω [2] with features.
- In the first case, the taught subtask sequence M can be directly transformed into a corresponding abstract method sequence AM (line 3). The name and arguments of the abstract method are the same as the corresponding subtasks (lines 5–6), and each abstract method consists of a sequence of corresponding abstract operators (line 7). In this way, the initial three-layer structure of an activity schema is built: the schema layer, the abstract method layer and the abstract operator layer.
- In the second case, the corresponding abstract method sequence AM is obtained using the previous method. If AM’ (original abstract method sequence) is a true subset of AM, the complement of set AM’ in set AM will be extracted as a free abstract method and generalized as AMF (line 13). The generalization process involves replacing the observed constants in the arguments of abstract methods, operators and their preconditions with variables. If AM does not contain the same sequence as AM’, it is created as a new branch of the activity schema ma under the preconditions F(AM) (line 15), and preconditions of other branches will be adjusted as noted in line 16. Otherwise, the preconditions of AM and AM’ (AM is the same as AM’) will be merged, and the abstract operator sequence Ωi under each ami should be checked. Three potential cases are noted: 1) if an identical abstract operator sequence subk’ as Ωi exists in the branches of the abstract method in ma’, the preconditions of them will be combined by intersection (line 20); 2) if a branch subk’ which is a subset of Ωi exists, the complement of set subk’ in set Ωi will be extracted as a free abstract method and generalized as amf; and 3) otherwise, Ωi will be regarded as a novel branch and added to ami under the preconditions F(Ωi) (line 24), and preconditions of other branches will be adjusted as noted in line 26.
2.4 Planning Based on Activity Schema with Merging Optimization and Partially Backtracking Techniques
2.4.1. Planning Based on Activity Schema with Merging Optimization
| Algorithm 2 Schema-Based Optimized Planner (SBOP) |
| Procedure SBOP(D, P, ma) |
| 1: │(t, AM, Ω) ← select an activity schema ma(t, AM, Ω)∈MA for task t |
| 2: │instantiate(t, P) |
| 3: │activenode = root node of ma; state(ma) ← 0 |
| 4: │while state of state(ma) ≠ 1 do |
| 5: │ │if activenode is an instance of abstract method am∈AM then |
| 6: │ │ │ if state(activenode) = 2 then |
| 7: │ │ │ for each node ni in sub i of activenode do |
| 8: │ │ │ if state(ni) = 1 and state(ni+1) = 0 then |
| 9: │ │ │ activenode ← ni+1; return |
| 10: │ │ │ if state(ni) = 1 and ni+1 =φ then |
| 11: │ │ │ state(activenode) = 1; return |
| 12: │ │ │ return |
| 13: │ │ │ if state(activenode) = 1 then |
| 14: │ │ │ if next node of activenode belonging to the same branch is φ then |
| 15: │ │ │ state(parent(activenode)) = 1; return |
| 16: │ │ │ else activenode ← next node of activenode; return |
| 17: │ │ │ if state(activenode) = 0 then |
| 18: │ │ │ get sharing states and update S in P |
| 19: │ │ │ check ← whether there exist subi in activenode applicable in a state S |
| 20: │ │ │ if check is false then publish the preconditions which are not ready |
| 21: │ │ │ else break |
| 22: │ │ │ tasktree.add_children(subiθ) |
| 23: │ │ │ state(activenode) ← 2; activenode ← head(sub iθ) |
| 24: │ │ │ return |
| 25: │ │else |
| 26: │ │ │ if state(activenode) = 0 then |
| 27: │ │ │ get sharing states and update S in P |
| 28: │ │ │ pick the action a applicable to S with the lowest cost using SBP |
| 29: │ │ │ S’← γ(S, a) ; transition function |
| 30: │ │ │ if S’; is true then |
| 31: │ │ │ tasktree.add_child (a); plantree.add_child (a); state(activenode) ← 1; |
| return |
| 32: │ │ │ return failure |
| 33: │if state(ma) =1 and goal proposition is not satisfied in S’then return to line 3 |
| 34: │if state(ma) =1 and goal proposition is satisfied in S’then |
| 35: │ translate plantree to plantree (AC) based on action relations analysis |
| 36: │ a plan π ← Optimize the plantree (AC) |
| 37: │else return failure |
2.4.2. Planning Based on Activity Schema with Partially Backtracking Technique
| Algorithm 3 Replanning Based on Partially Backtracking |
| replanning_pb (S, failedAction) |
| 1: │ solution ← False |
| 2: │ failedTask ← Action2Task (failedAction) |
| 3: │ failedParent ← failedTask.up |
| 4: │ while solution = False do |
| 5: │ │ am ← abstract (failedParent) |
| 6: │ │ check ← whether there exist presubi in am applicable in a state S |
| 7: │ │ if check is false then |
| 8: │ │ check ← whether there exist amfi in AMF applicable in a state S |
| 9: │ │ if check is false then |
| 10: │ │ if failedParent is the root of tasktree then return failure |
| 11: │ │ failedParent ← failedParent.up; return |
| 12: │ │ else |
| 13: │ │ tasktree.add_children(amfiθ); go to line17 |
| 14: │ │ else |
| 15: │ │ find the abstract operator ωf whose feature is satisfied under subi |
| 16: │ │ tasktree.delete_children(failedParent); tasktree.add_children(subiθ after ωfθ) |
| 17: │ │ state(activenode) ← 2; activenode ← head(sub i) |
| 18: │ │ search the plan solution according to SBOP until to state(ma) =1 |
| 19: │ │ solution = True ; return |
| 20: │translate plantree to plantree (AC) and optimize the plantree (AC) |
3. Demonstration and Evaluation
3.1. Demonstration 1: Simulation in Scenario “Deal with Obstacles in Serving a Coffee to a Guest”
3.1.1. Learning Abstract Methods and Robot Activity Schema
3.1.2. Planning Based on Activity Schema with Abstract Methods
3.2. Demonstration 2: Physical Experiment in the Scenario “Collect and Deliver Drink Boxes to a Counter”
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ingrand, F.; Ghallab, M. Deliberation for autonomous robots: A survey. Artif. Intell. 2017, 247, 10–44. [Google Scholar] [CrossRef]
- Mokhtari, V.; Lopes, L.S.; Pinho, A.J. Experience-based planning domains: An integrated learning and deliberation approach for intelligent robots. J. Intell. Rob. Syst. 2016, 83, 463–483. [Google Scholar] [CrossRef]
- Tenorth, M.; Klank, U.; Pangercic, D.; Beetz, M. Web-enabled robots. IEEE Rob. Autom Mag. 2011, 18, 58–68. [Google Scholar] [CrossRef]
- Zablith, F.; Antoniou, G.; d’Aquin, M.; Flouris, G.; Kondylakis, H.; Motta, E.; Plexousakis, D.; Sabou, M. Ontology evolution: A process-centric survey. Knowl. Eng. Rev. 2015, 30, 45–75. [Google Scholar] [CrossRef]
- Rockel, S.; Neumann, B.; Zhang, J.; Dubba, K.S.R.; Cohn, A.G.; Konecny, S.; Mansouri, M.; Pecora, F.; Saffiotti, A.; Günther, M. An ontology-based multi-level robot architecture for learning from experiences. In Proceedings of the AAAI 2013 Spring Symposium, Palo Alto, CA, USA, 25–27 March 2013; AAAI: San Francisco, CA, USA; pp. 2–4. [Google Scholar]
- Martínez-Costa, C.; Schulz, S. Ontology-based reinterpretation of the snomed ct context model. In Proceedings of the International Conference on Biomedical Ontologies (ICBO 2013), Montreal, QC, Canada, 8–9 July 2013; pp. 90–95. [Google Scholar]
- Lopes, L.S. Failure recovery planning in assembly based on acquired experience: Learning by analogy. In Proceedings of the 1999 IEEE International Symposium on Assembly and Task Planning (ISATP’99), Porto, Portugal, 21–24 July 1999; pp. 294–300. [Google Scholar]
- Lopes, L.S. Failure recovery planning for robotized assembly based on learned semantic structures. In Proceedings of the IFAC International Workshops Intelligent Assembly and Disassembly (IAD’07), Alicante, Spain, 23–25 May 2007; pp. 65–70. [Google Scholar]
- Lim, G.H.; Oliveira, M.; Mokhtari, V.; Kasaei, S.H.; Chauhan, A.; Lopes, L.S.; Tomé, A.M. Interactive teaching and experience extraction for learning about objects and robot activities. In Proceedings of the The 23rd IEEE International Symposium on Robot and Human Interactive Communication (IEEE RO-MAN 2014), Edinburgh, UK, 25–29 August 2014; pp. 153–160. [Google Scholar]
- Mokhtari, V.; Lim, G.H.; Lopes, L.S.; Pinho, A.J. Gathering and conceptualizing plan-based robot activity experiences. In Proceedings of the 13th International Conference on Intelligent Autonomous Systems (IAS-13), Padova, Italy, 15–18 July 2014; pp. 993–1005. [Google Scholar] [CrossRef]
- Mokhtari, V.; Lopes, L.S.; Pinho, A.J. An approach to robot task learning and planning with loops. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2017), Vancouver, BC, Canada, 24–28 September 2017; pp. 6033–6038. [Google Scholar]
- Ilghami, O.; Munoz-Avila, H.; Nau, D.S.; Aha, D.W. Learning approximate preconditions for methods in hierarchical plans. In Proceedings of the 22nd International Conference on Machine Learning (ICML 2005), Bonn, Germany, 7–11 August 2005; Luc, D.R., Stefan, W., Eds.; ACM: New York, NY, USA, 2005; pp. 337–344. [Google Scholar]
- Xu, K.; Muñoz-Avila, H. A domain-independent system for case-based task decomposition without domain theories. In Proceedings of the 20th national conference on Artificial intelligence (AAAI 2005), Pittsburgh, PA, USA, 9–13 July 2005; AAAI: San Francisco, CA, USA, 2005; pp. 234–240. [Google Scholar]
- Nejati, N.; Langley, P.; Konik, T. Learning hierarchical task networks by observation. In Proceedings of the 23rd International Conference on Machine Learning (ICML 2006), Pittsburgh, PA, USA, 25–29 June 2006; Cohen, W.W., Moore, A., Eds.; ACM: New York, NY, USA, 2006; pp. 665–672. [Google Scholar]
- Hogg, C.; Munoz-Avila, H.; Kuter, U. Htn-maker: Learning htns with minimal additional knowledge engineering required. In Proceedings of the 23rd AAAI Conference on Artificial Intelligence (AAAI 2008), Chicago, IL, USA, 13–17 July 2008; AAAI: San Francisco, CA, USA, 2008; pp. 950–956. [Google Scholar]
- Zhuo, H.H.; Hu, D.H.; Hogg, C.; Yang, Q.; Munoz-Avila, H. Learning htn method preconditions and action models from partial observations. In Proceedings of the 21st International Joint Conference on Artificial Intelligence (IJCAI 2009), Pasadena, CA, USA, 11–17 July 2009; Craig, B., Ed.; AAAI: San Francisco, CA, USA, 2009; pp. 1804–1810. [Google Scholar]
- Mokhtari, V.; Lopes, L.S.; Pinho, A.J.; Lim, G.H. Planning with activity schemata: Closing the loop in experience-based planning. In Proceedings of the 2015 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC 2015), Espinho, Portugal, 14–15 May 2014; IEEE: New York, NY, USA, 2014; pp. 9–14. [Google Scholar]
- Chen, Z.; Zhang, J.; Hu, Y.; Dong, X.; Jin, H.; Zhang, J. Multitasking planning for service robot based on hierarchical decomposing. ICIC Express LeTt. Part B, Appl. 2016, 7, 77–83. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, Z.; Hu, Y.; Zhang, J.; Luo, Z.; Dong, X. Multitasking planning and executing of intelligent vehicles for restaurant service by networking. Int. J. Distrib. Sens. Netw. 2015, 11, 273825. [Google Scholar] [CrossRef]
- Harman, H.; Chintamani, K.; Simoens, P. Architecture for incorporating internet-of-things sensors and actuators into robot task planning in dynamic environments. In Proceedings of the 2017 IEEE International Symposium on Robotics and Intelligent Sensors (IRIS2017), Ottawa, ON, Canada, 5–7 October 2017; IEEE: New York, NY, USA, 2017; pp. 13–18. [Google Scholar]
- Meditskos, G.; Bassiliades, N. Rule-based owl ontology reasoning using dynamic abox entailment. In Proceedings of the 18th European Conference on Artificial Intelligence (ECAI 2008), Patras, Greece, 21–25 July 2008; Ghallab, M., Spyropoulos, C.D., Fakotakis, N., Avouris, N., Eds.; IOS Press: Amsterdam, Netherlands; pp. 731–732. [Google Scholar]
- Erol, K.; Hendler, J.A.; Nau, D.S. Umcp: A sound and complete procedure for hierarchical task-network planning. In Proceedings of the 2nd International Conference on Artificial Intelligence Planning Systems (AIPS-94), Chicago, IL, USA, 13–15 June 1994; Kristian, H., Ed.; AAAI: San Francisco, CA, USA, 1994; pp. 249–254. [Google Scholar]
- Neumann, B.; Hotz, L.; Rost, P.; Lehmann, J. A robot waiter learning from experiences. In Proceedings of the 10th International Conference on Machine Learning and Data Mining (MLDM 2014), St. Petersburg, Russia, 21–24 July 2014; pp. 285–299. [Google Scholar]
- Östergård, P.R. A new algorithm for the maximum-weight clique problem. Nord. J. Comput. 2001, 8, 424–436. [Google Scholar] [CrossRef]
- Zhang, L.; Rockel, S.; Pecora, F.; Hotz, L.; Lu, Z.; Klimentjew, D.; Zhang, J. Evaluation metrics for an experience-based mobile artificial cognitive system. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2013), Workshop on Metrics of Embodied Learning Processes in Robots and Animals, Tokyo, Japan, 3–7 November 2013; IEEE: New York, NY, USA, 2014; pp. 2225–2232. [Google Scholar]
- Rockel, S.; Klimentjew, D.; Zhang, L.; Zhang, J. An hyperreality imagination based reasoning and evaluation system (hires). In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA 2014), Hong Kong, China, 31 May–7 June 2014; IEEE: New York, NY, USA, 2014; pp. 5705–5711. [Google Scholar]
- Hayashi, H.; Tokura, S.; Ozaki, F. Towards real-world htn planning agents. In Knowledge Processing and Decision Making in Agent-Based Systems; Jain, L.C., Nguyen, N.T., Eds.; Springer: Berlin, Germany, 2009; pp. 13–41. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1. [serve_a_coffee (guest1)) 2. ((condition1; 3. (Instance PlacingArea paerc1) (Instance Counter counter1)(HasPlacingArea counter1 paerc1) 4. (Instance At at1)(HasPhysicalEntity at1 guest1)(HasArea at1 saw1) 5. (Instance SittingArea saw1)(HasPlacingAreaRight saw1 pawrt1) (Instance PlacingArea pawlt1) 6. not((hasArea blockingAt1 mast1)(hasPhysicalEntity blockingAt1 obstacle1)(Instance Table obstacle1)) 7. ) 8. [drive(part1,pmaec1), grasp(mug1,rarm1), drive(pmaec1,pmast1), put(mug1, pawrt1)]) 9. ((condition2; 10. .…(Instance SittingArea saw1)(HasPlacingAreaRight saw1 pawrt1) 11. (hasArea blockingAt1 mast1)(hasPhysicalEntity blockingAt1 obstacle1) (Instance Table obstacle1) 12. (HasPlacingAreaLeft saw1 pawlt1) (Instance PlacingArea pawlt1)) 13. [drive(part1,pmaec1) grasp(mug1,rarm1) drive(pmaec1,pmast1) put(mug1, pawlt1)]) 14.Free abstract method; 15. ((Instance At ?at)(hasArea ?at ?manArea)(hasPhysicalEntity ?at ?obstacle) 16. (Instance Person ?obstacle)) 17. [wait _unblocked (?manArea)] ] |
| Method | SBOP | SBP |
|---|---|---|
| Number of intervention instructions during execution | 0 | ≥2 |
| Recover from the failure automatically | √ | × |
| Adapt among multiple learned activity schemas during execution | √ | × |
| Plan-generating time cost for the first recovery | 205 s | 149 s |
| Plan-generating time cost for the second recovery | 223 s | 205 s |
| Total time for plan recovery from failure | 428 s | 487 s |
| Planner | SBOP | SBP | Reducing Rate |
|---|---|---|---|
| Number of actions | 21 | 25 | 16.0% |
| Cost time of execution | 845 s | 1023 s | 17.4% |
| Cost time of planning | 423 s | 356 s | −18.1% |
| Total cost time | 1268 s | 1379 s | 8.0% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhao, B.; Zhao, S.; Hu, Y.; Zhang, J. Learning and Planning Based on Merged Experience from Multiple Situations for a Service Robot. Appl. Sci. 2018, 8, 1832. https://doi.org/10.3390/app8101832
Chen Z, Zhao B, Zhao S, Hu Y, Zhang J. Learning and Planning Based on Merged Experience from Multiple Situations for a Service Robot. Applied Sciences. 2018; 8(10):1832. https://doi.org/10.3390/app8101832
Chicago/Turabian StyleChen, Zhixian, Baoliang Zhao, Shijia Zhao, Ying Hu, and Jianwei Zhang. 2018. "Learning and Planning Based on Merged Experience from Multiple Situations for a Service Robot" Applied Sciences 8, no. 10: 1832. https://doi.org/10.3390/app8101832
APA StyleChen, Z., Zhao, B., Zhao, S., Hu, Y., & Zhang, J. (2018). Learning and Planning Based on Merged Experience from Multiple Situations for a Service Robot. Applied Sciences, 8(10), 1832. https://doi.org/10.3390/app8101832