Temporal Action Detection in Untrimmed Videos from Fine to Coarse Granularity


Abstract
:1. Introduction
- We propose to detect action from fine to coarse granularity, and build our action detection method in the ‘proposal then classification’ framework.
- The proposed and designed components in our method, such as: a Res3D version for the segment with 16 frames, transfer learning from RGB to optical flow, discriminative selective search, regression network via multi-task learning can be used in other action recognition or detection methods.
- The experimental results show that our method achieves state-of-the-art performance on THUMOS’14 and has a relatively balanced performance for different action categories.
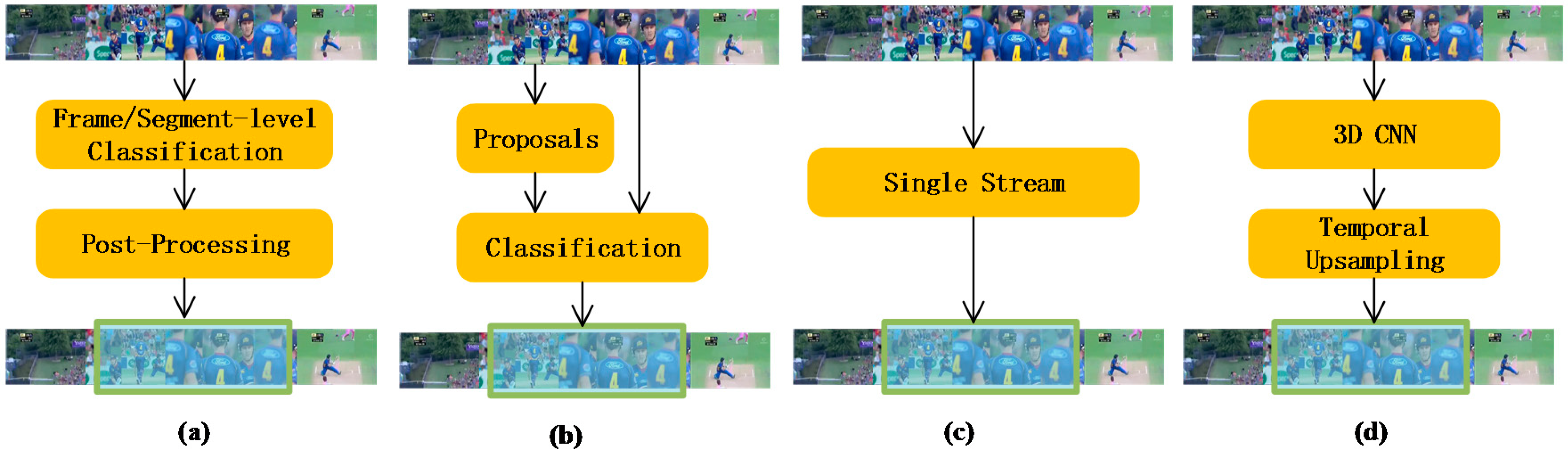
2. Previous Works
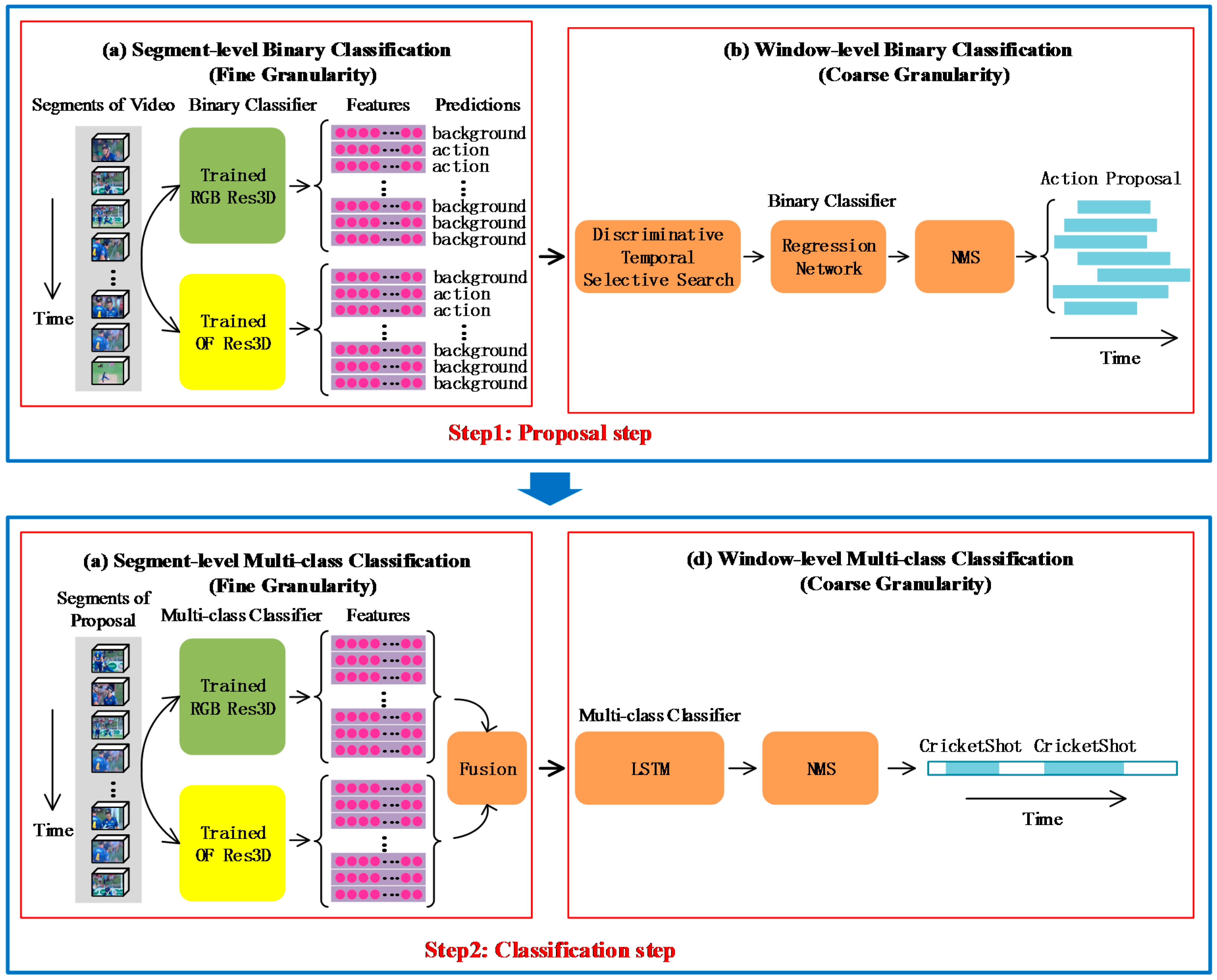
3. Our Method
3.1. Overview of Our Method
3.2. Res3D Architecture
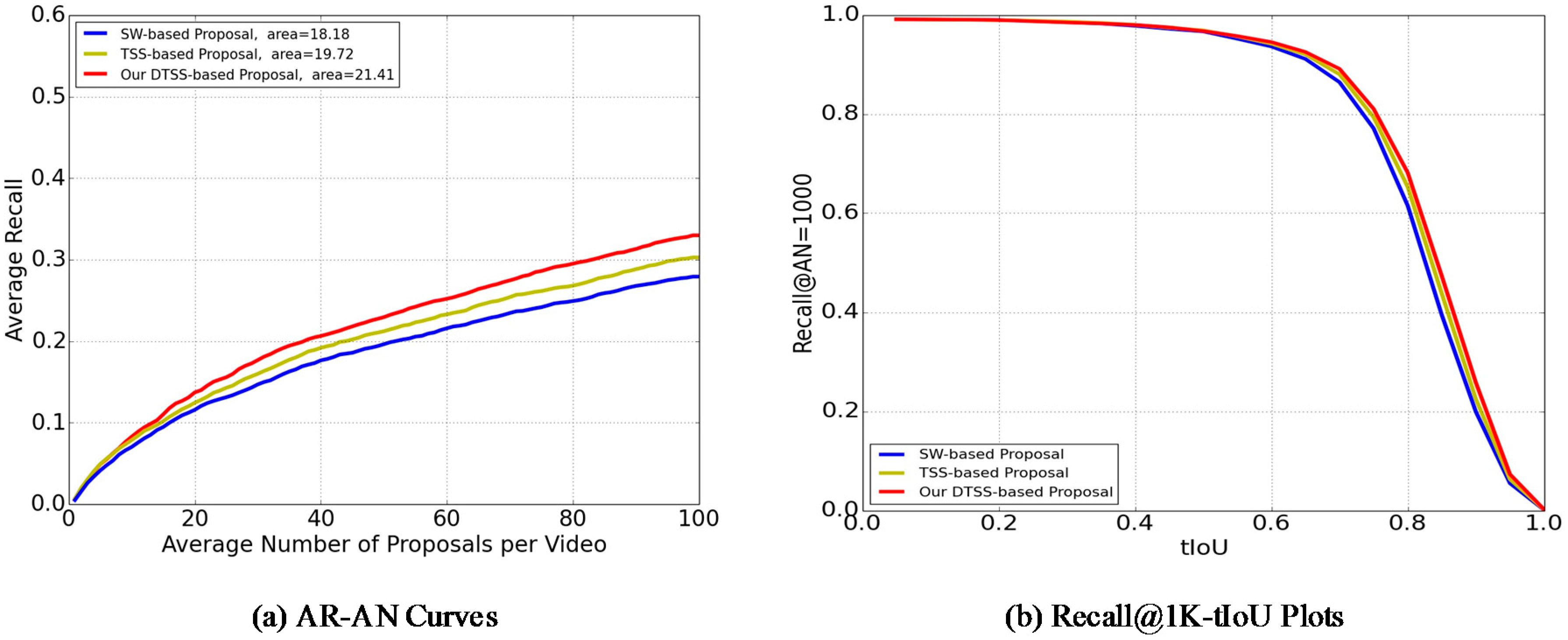
3.3. Discriminative Temporal Selective Search
- Merge Principle: In each iteration, the merged segment or temporal region should contain action segment.
- Keep Principle: For a temporal region, if the percentage of predicted action segments is below a threshold , it would be excluded from the set of proposal candidates.
- Stop Principle: The merging is stopped until there is only one temporal region containing action segments.
| Algorithm 1. Discriminative temporal selective search |
| Input: the video and its segments set |
| discriminative segment-level features set |
| segment-level prediction set |
| Output: Set of the temporal action proposal candidates |
| Initialize similarity set |
| Initialize proposal candidates set |
| foreach consecutive segment pair do |
| Calculate similarity ; |
| ; |
| while more than one contains action segment do |
| Get the highest similarity , where or contains action segment; |
| Merge and : ; |
| Merge the features of and : ; |
| Calculate similarity set between and its consecutive segments or regions; |
| Update similarity set: ; |
| Update features set: ; |
| Update segments set: ; |
| if the percentage of action segments in beyond threshold then |
| ; |
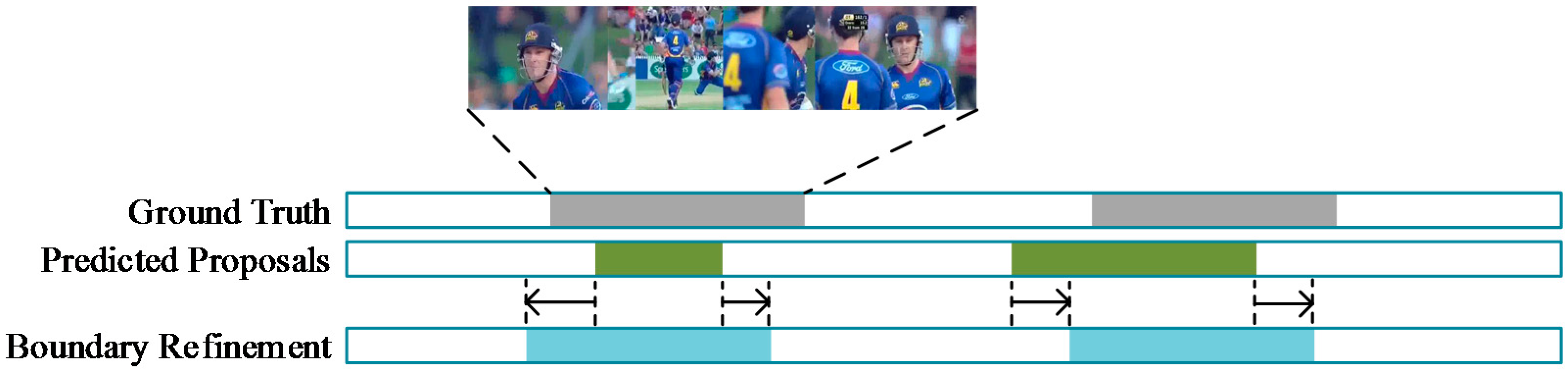
3.4. Regression Network
4. Experiments
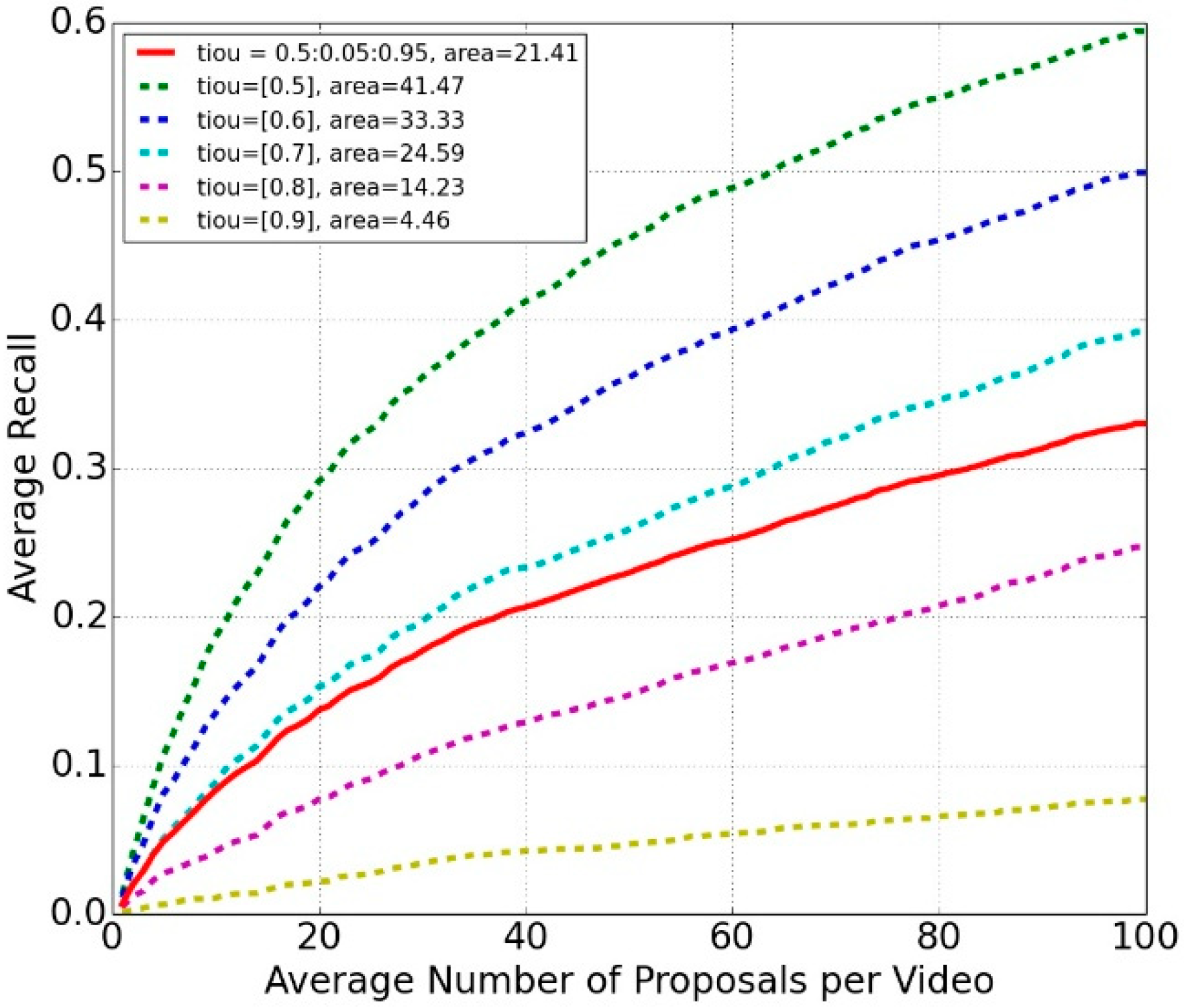
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Exploratory Study
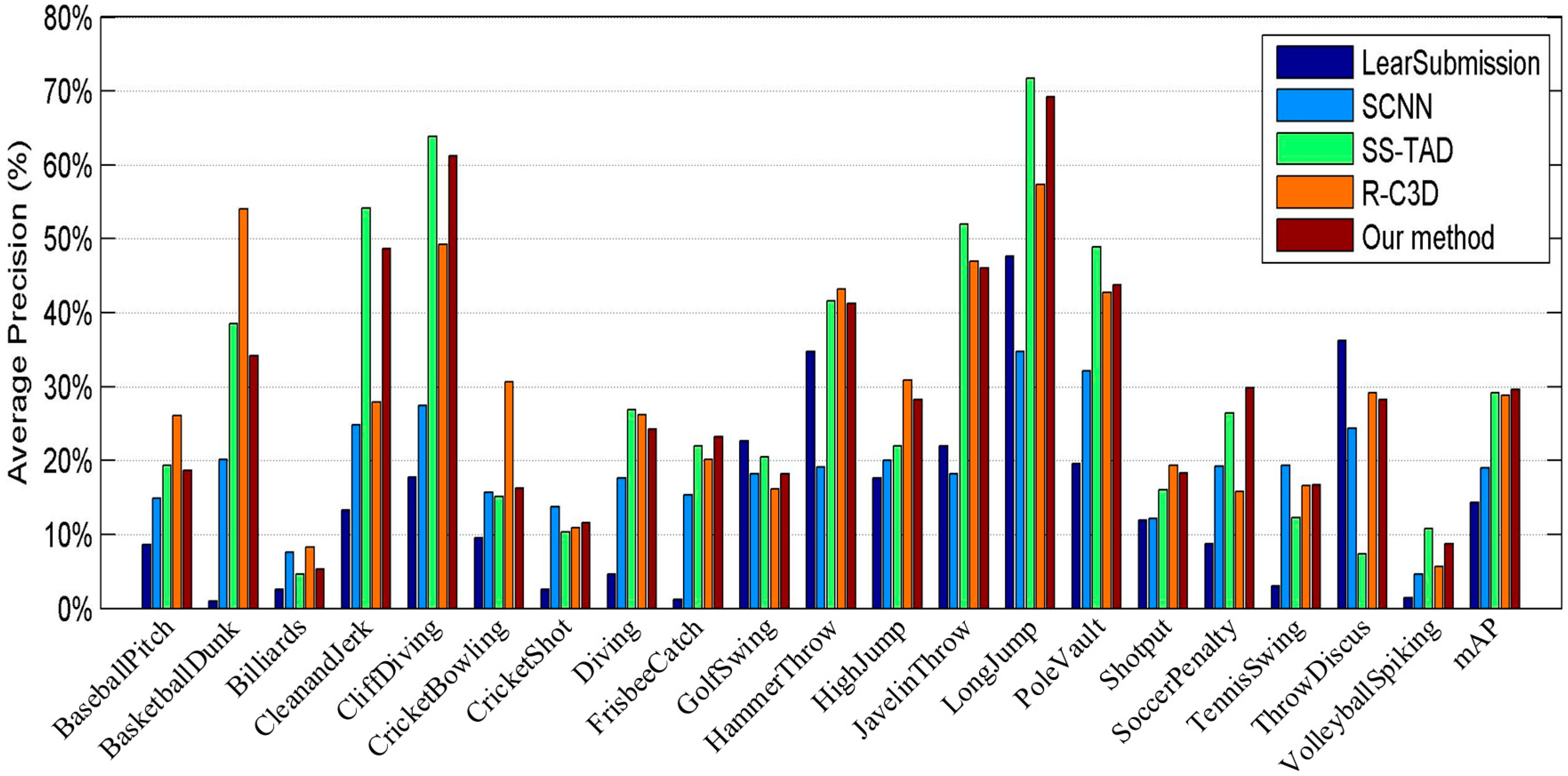
4.4. Comparison with State-of-the-Art Methods
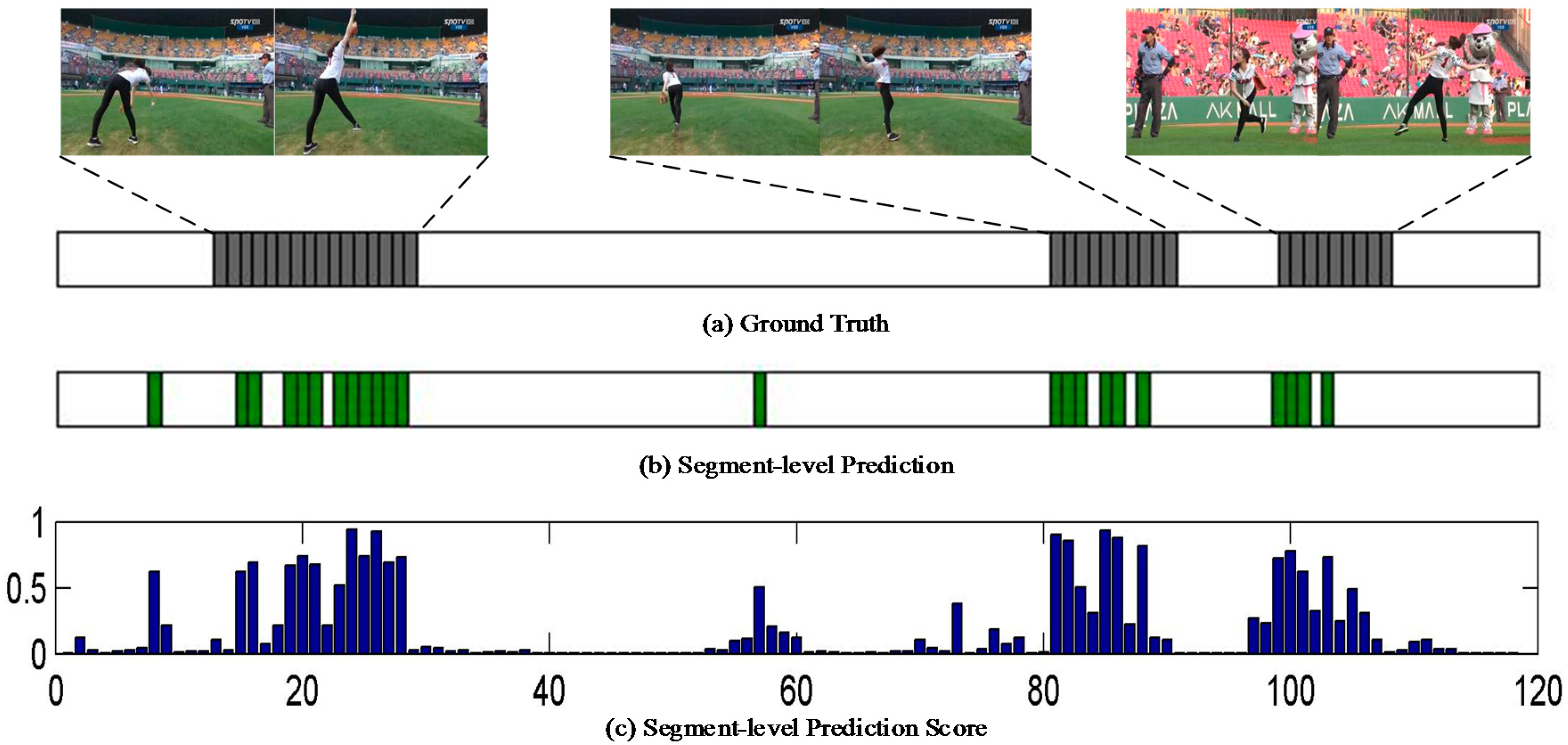
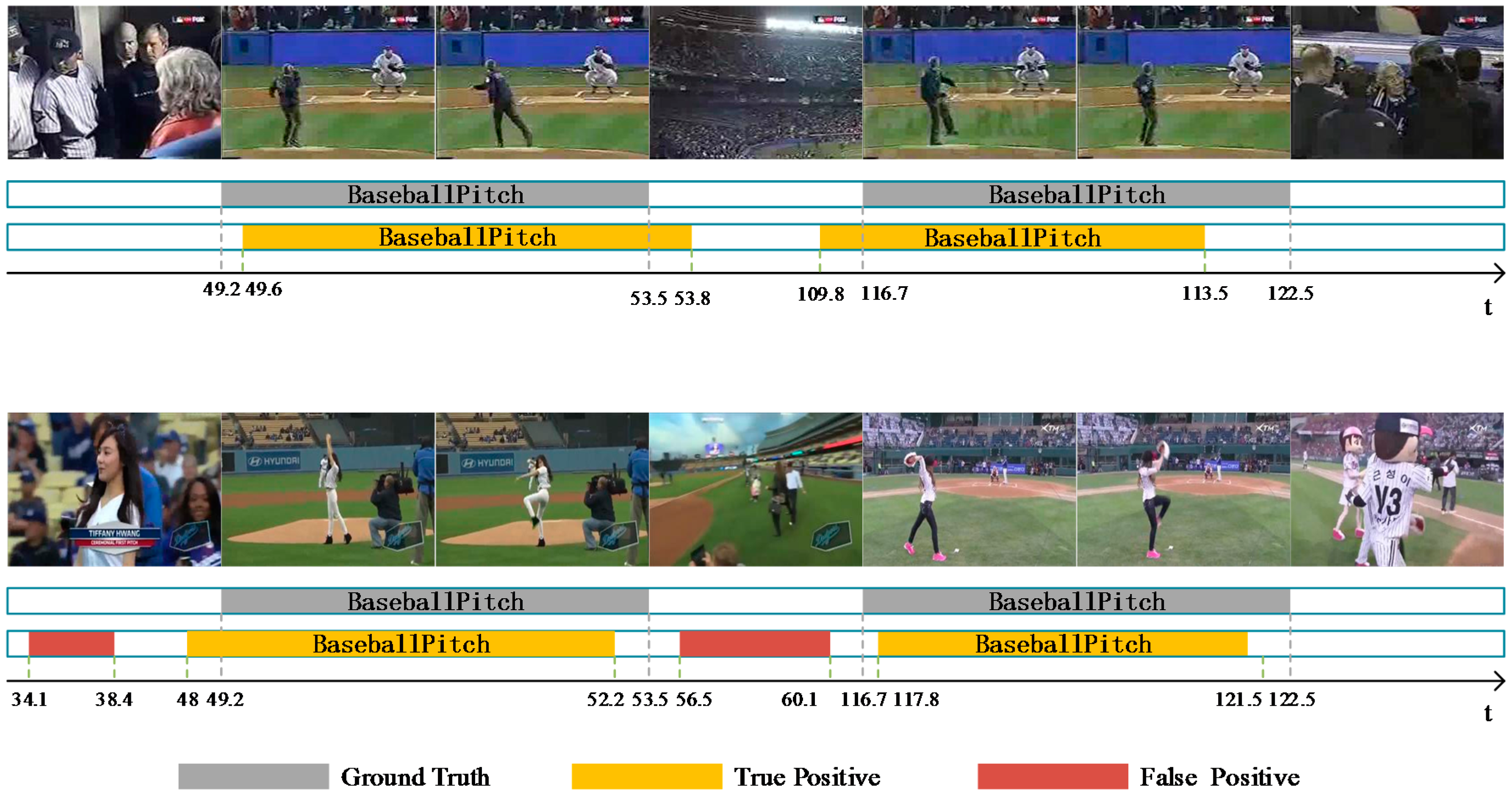
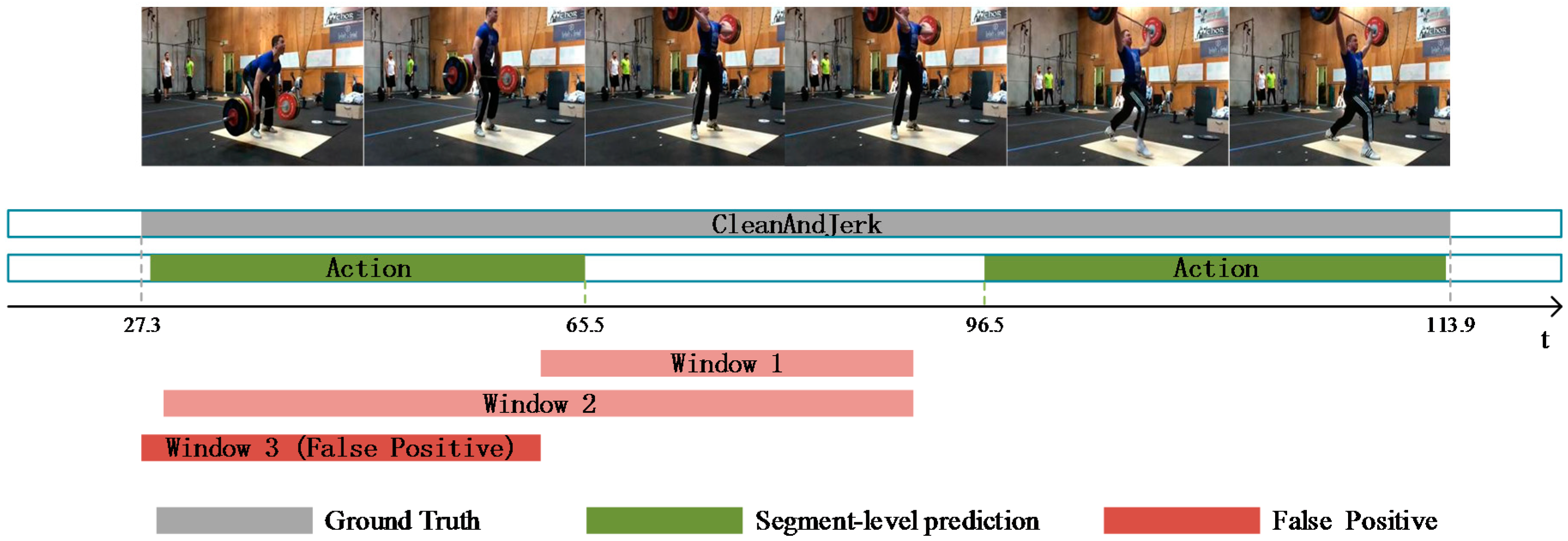
4.5. Qualitative Aanalysis of A Limitation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yuan, J.; Ni, B.; Yang, X.; Kassim, A.A. Temporal action localization with pyramid of score distribution features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3093–3102. [Google Scholar]
- Montes, A.; Salvador, A.; Pascual, S.; Giro-i-Nieto, X. Temporal activity detection in untrimmed videos with recurrent neural networks. arXiv, 2017; arXiv:1608.08128. [Google Scholar]
- Shou, Z.; Wang, D.; Chang, S. Temporal action localization in untrimmed videos via multi-stage CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1049–1058. [Google Scholar]
- Zhu, Y.; Newsam, S. Efficient action detection in untrimmed videos via multi-task learning. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 24–31 March 2017; pp. 197–206. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Zhao, X.; Shou, Z. Single shot temporal action detection. In Proceedings of the ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017. [Google Scholar]
- Buch, S.; Escorcia, V.; Ghanem, B.; Li, F.; Niebles, C.J. End-to-end, single-stream temporal action detection in untrimmed videos. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HW, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot multiBox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 Octorber 2016; pp. 21–37. [Google Scholar]
- Shou, Z.; Chan, J.; Zareian, A.; Miyazawa, K.; Chang, S. CDC: Convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HW, USA, 21–26 July 2017; pp. 1417–1426. [Google Scholar]
- Yang, K.; Qiao, P.; Li, D.; Lv, S.; Dou, Y. Exploring temporal preservation networks for precise temporal action localization. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Gao, J.; Yang, Z.; Sun, C.; Chen, K.; Nevatia, R. TURN TAP: Temporal unit regression network for temporal action proposals. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3648–3656. [Google Scholar]
- Tran, D.; Ray, J.; Shou, Z.; Chang, S.; Paluri, M. ConvNet architecture search for spatiotemporal feature learning. arXiv, 2017; arXiv:1708.05038. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4489–4497. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition and detection by combining motion and appearance features. THUMOS14 Action Recognit. Chall. 2014, 1, 2. [Google Scholar]
- Perronnin, F.; Dance, C. Fisher kernels on visual vocabularies for image Categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Xu, H.; Das, A.; Saenko, K. R-C3D: Region convolutional 3D network for temporal activity detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5794–5803. [Google Scholar]
- Escorcia, V.; Heilbron, C.F.; Niebles, C.J.; Ghanem, B. DAPs: Deep action proposals for action understanding. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 Octorber 2016. [Google Scholar]
- Buch, S.; Escorcia, V.; Shen, C.; Ghanem, B.; Niebles, C.J. SST: Single-stream temporal action proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HW, USA, 21–26 July 2017; pp. 6373–6382. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Zeiler, M.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representation, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Towards good practices for very deep two-stream convnets. arXiv, 2015; arXiv:1507.02159. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A duality based approach for realtime tv-L1 optical flow. In Proceedings of the DAGM Symposium on Pattern Recognition, Heidelberg, Germany, 12–14 September 2007; pp. 214–223. [Google Scholar]
- Uijlings, J.; Sande, K.; Gevers, T.; Smeulders, A. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Jiang, Y.; Liu, J.; Roshan, Z.A.; Toderici, G.; Laptev, I.; Shah, M.; Sukthankar, R. THUMOS Challenge: Action Recognition with a Large Number of Classes. Available online: http://crcv.ucf.edu/THUMOS14/ (accessed on 18th August 2018).
- Caba, H.F.; Escorcia, V.; Ghanem, B.; Niebles, J.C. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Karaman, S.; Seidenari, O.; Bimbo, D.A. Fast saliency based pooling of Fisher encoded dense trajectories. THUMOS14 Action Recognit. Chall. 2014, 1, 7. [Google Scholar]
- Oneata, D.; Verbeek, J.; Schmid, C. The LEAR submission at Thumos 2014. 2014. Available online: https://hal.inria.fr/hal-01074442 (accessed on 9 October 2018).
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Caba, F.H.; Carlos, J.N.; Bernard, G. Fast Temporal activity proposals for efficient detection of human actions in untrimmed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1914–1923. [Google Scholar]
- Laptev, I. On space-time interest points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Huang, J.; Li, N.; Zhang, T.; Li, G. A self-adaptive proposal model for temporal action detection based on reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lin, T.; Zhao, X.; Fan, Z. Temporal action localization with two-stream segment-based RNN. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 3400–3404. [Google Scholar]
- Gao, J.; Yang, Z.; Nevatia, R. Cascaded boundary regression for temporal action detection. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Wang, L.; Xiong, Y.; Lin, D.; Gool, V.L. UntrimmedNets for weakly supervised action recognition and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HW, USA, 21–26 July 2017; pp. 6402–6411. [Google Scholar]
- Xiong, Y.; Zhao, Y.; Wang, L.; Lin, D.; Tang, X. A pursuit of temporal accuracy in general activity detection. arXiv, 2017; arXiv:1703.02716. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Building Blocks | Shape of The Input | |||
|---|---|---|---|---|---|
| Res3D | Res3D-16D | Res3D-16S | Our Res3D | ||
| Conv1 | 3 × 7 × 7.64 | 3 × 8 × 112 × 112 | 3 × 16 × 112 × 112 | 3 × 8 × 112 × 112 | 3 × 16 × 112 × 112 |
| Conv2_x | 64 × 8 × 56 × 56 | 64 × 16 × 56 × 56 | 64 × 8 × 56 × 56 | 64 × 16 × 56 × 56 | |
| Conv3_x | 64 × 8 × 56 × 56 | 64 × 18 × 56 × 56 | 64 × 8 × 56 × 56 | 64 × 8 × 56 × 56 | |
| Conv4_x | 128 × 4 × 28 × 28 | 128 × 8 × 28 × 28 | 128 × 4 × 28 × 28 | 128 × 4 × 28 × 28 | |
| Conv5_x | 256 × 2 × 14 × 14 | 256 × 4 × 14 × 14 | 256 × 2 × 14 × 14 | 256 × 2 × 14 × 14 | |
| FC | InnerProduct, Softmax | 512 × 1 × 7 × 7 | 512 × 2 × 7 × 7 (Not functional) | 512 × 1 × 7 × 7 | 512 × 1 × 7 × 7 |
| Classifiers | Res3D-16D | Res3D-16S | Our Res3D |
|---|---|---|---|
| Binary Classifier | Not Functional | 68.1 | 78.3 |
| Multi-class Classifier | Not Functional | 67.3 | 69.8 |
| Input Fields | mAP (%) |
|---|---|
| RGB | 25.2 |
| OF | 24.9 |
| RGB + OF | 29.6 |
| Methods | 0.5 | 0.4 | 0.3 | 0.2 | 0.1 | Input Fields | Involved Features |
|---|---|---|---|---|---|---|---|
| Classification then Post-Processing | |||||||
| UnifiSubmission [42] | 0.9 | 1.4 | 2.1 | 3.4 | 4.6 | RGB + OF | iDT |
| PSDF [1] | 18.8 | 26.1 | 33.6 | 42.6 | 51.4 | RGB + OF | iDT |
| CUHKSubmission [22] | 8.3 | 11.7 | 14.0 | 17.0 | 18.2 | RGB + OF | iDT + CNN |
| Temporal Upsampling | |||||||
| CDC [13] | 23.3 | 29.4 | 40.1 | - | - | RGB | 3D CNN |
| TPC [14] | 28.2 | 37.1 | 44.1 | - | - | RGB | 3D CNN |
| Single Stream | |||||||
| SSAD [8] | 24.6 | 35.0 | 43.0 | 47.8 | 50.1 | RGB + OF | CNN + 3D CNN |
| SS-TAD [9] | 29.2 | - | - | - | - | RGB | 3D CNN |
| Proposal then Classification | |||||||
| LearSubmission [43] | 14.4 | 20.8 | 27.0 | 33.6 | 33.6 | RGB | SIFT [44] + Color + CNN |
| SparseLearning [45] | 13.5 | 18.2 | 25.7 | 32.9 | 36.1 | RGB | STIP [46] |
| SCNN [3] | 19 | 28.7 | 36.3 | 43.5 | 47.7 | RGB | CNN |
| Daps [26] | 13.9 | - | - | - | - | RGB | 3D CNN |
| SST [27] | 23 | - | - | - | - | RGB | 3D CNN |
| SelfAdaptive [47] | 27.7 | - | - | - | - | RGB | 3D CNN |
| R-C3D [25] | 28.9 | 35.6 | 44.8 | 51.5 | 54.5 | RGB | 3D CNN |
| Two-stream RNN [48] | 18.8 | 28.9 | 36.9 | 42.9 | 46.1 | RGB + OF | CNN |
| Multi-task Learning [4] | 19 | 28.9 | 36.2 | 43.6 | 47.7 | RGB | 3D CNN |
| TURN [18] | 25.6 | 34.9 | 44.1 | 50.9 | 54 | GRB + OF | CNN |
| Cascade [49] | 31 | 41.3 | 50.1 | 56.7 | 60.1 | RGB + OF | CNN |
| WeakSupervision [50] | 13.7 | 21.1 | 28.2 | 37.7 | 44.4 | RGB + OF | CNN |
| Generalization [51] | 28.2 | 39.8 | 48.7 | 57.7 | 64.1 | RGB | CNN |
| Our method | 29.6 | 40.1 | 48.9 | 57.3 | 64.7 | RGB + OF | 3D CNN |
| Archery | 31.2 | Doing a powerbomb | 33.5 | Playing kickball | 47.2 |
| Baton twirling | 23.6 | Doing motocross | 51.6 | Pole vault | 38.2 |
| Bungee jumping | 46.8 | Hammer throw | 32.7 | Powerbocking | 29.5 |
| Camel ride | 48.2 | High jump | 33.4 | Rollerblading | 23.8 |
| Cricket | 37.9 | Hurling | 35.2 | Shot put | 32.1 |
| Croquet | 43.1 | Javelin throw | 34.8 | Skateboarding | 41.2 |
| Curling | 29.3 | Long jump | 56.7 | Starting a campfire | 39.2 |
| Discus throw | 44.1 | Longboarding | 44.3 | Triple jump | 27.9 |
| Dodgeball | 36.9 | Paintball | 43.1 | mAP | 37.9 |
| ActivityNet [41] | 9.7 | ActivityNet1.3 |
| R-C3D [25] | 28.4 | ActivityNet1.3 |
| Generalization [51] | 40.7 | ActivityNet1.3 |
| TURN [18] | 37.1 | ‘Participating in Sports, Exercise, or Recreat.’ subset of ActivityNet1.1 |
| TURN [18] | 41.2 | ‘Housework’ subset of ActivityNet1.1 |
| Out method | 37.9 | ‘Playing sports’ subset of AcvitityNet1.3 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, G.; Lei, T.; Liu, X.; Jiang, P. Temporal Action Detection in Untrimmed Videos from Fine to Coarse Granularity. Appl. Sci. 2018, 8, 1924. https://doi.org/10.3390/app8101924
Yao G, Lei T, Liu X, Jiang P. Temporal Action Detection in Untrimmed Videos from Fine to Coarse Granularity. Applied Sciences. 2018; 8(10):1924. https://doi.org/10.3390/app8101924
Chicago/Turabian StyleYao, Guangle, Tao Lei, Xianyuan Liu, and Ping Jiang. 2018. "Temporal Action Detection in Untrimmed Videos from Fine to Coarse Granularity" Applied Sciences 8, no. 10: 1924. https://doi.org/10.3390/app8101924
APA StyleYao, G., Lei, T., Liu, X., & Jiang, P. (2018). Temporal Action Detection in Untrimmed Videos from Fine to Coarse Granularity. Applied Sciences, 8(10), 1924. https://doi.org/10.3390/app8101924