UAV Motion Strategies in Uncertain Dynamic Environments: A Path Planning Method Based on Q-Learning Strategy †



Abstract
:1. Introduction
- Learning and cognition in an unstructured environment. In general, learning and cognition are key behaviors of human beings. However, in unstructured environment, there is no established information for the UAV to use directly. If it wonders where to go, it must explore the environment like a person. As a result, learning and cognition become very important for UAVs to fly in such an unstructured environment.
- Real-time planning and re-planning. In fact, a preplanned flight path will not meet the demands of an actual flight for a UAV, because there would not always exist a path suitable for the UAV to fly in an unstructured environment. It must re-plan a flightworthy path according to the actual circumstances. Real-time planning and re-planning forma complex problem that involves meeting the physical constraints of the UAVs, constraints from the operating environment, constraints from the threat or no-fly zones, and other operational requirements.
- Multi-UAVs’ collaborative planning and control. Multi-UAV collaborations have become a vital platform in the military field, and will also be the cutting-edge technologies in the future. Enabling the multi-UAV effective autonomous cooperative wide area target search ability is the key to carrying out the task chain of search, attack, and evaluation, so research on such a problem has a very important military application value. To obtain an effective autonomous cooperative search, the UAV platform must be equipped with the ability of autonomous decision-making, which is dealing with these basic problems: decision-making structure, information model, decision-making method, and also dealing with two extended problems, delayed information compensating and system scale control. In the future, the above problems should be well studied and a UAV autonomous cooperative wide area target search mechanism should be established as well.
- Automatic generation and calculation of flight strategy. We develop the UAV and hope it can fly autonomously without human control. As a result, unlike remote control systems in which the sensors present information in a form that is as operator-friendly as possible, in a UAV, a system platform that performs the autonomous mission usually possesses an onboard navigation system instead of sensors of various physical nature. So, the measurement results should be converted into input signals of the control system, which requires other approaches. At the same time, in an autonomous flight, the observing system should be able to search for characteristic objects in the observed landscape and give the control system their coordinates and estimate the distances between them [7]. So, it is very important to study how to produce a decision/control that can be executed directly by the onboard control system.
2. Related Work
3. UAV Path Planning Model Based on Q-Learning Strategy
3.1. Q-Learning Theory
3.2. Specification of the Motion Strategies Problems
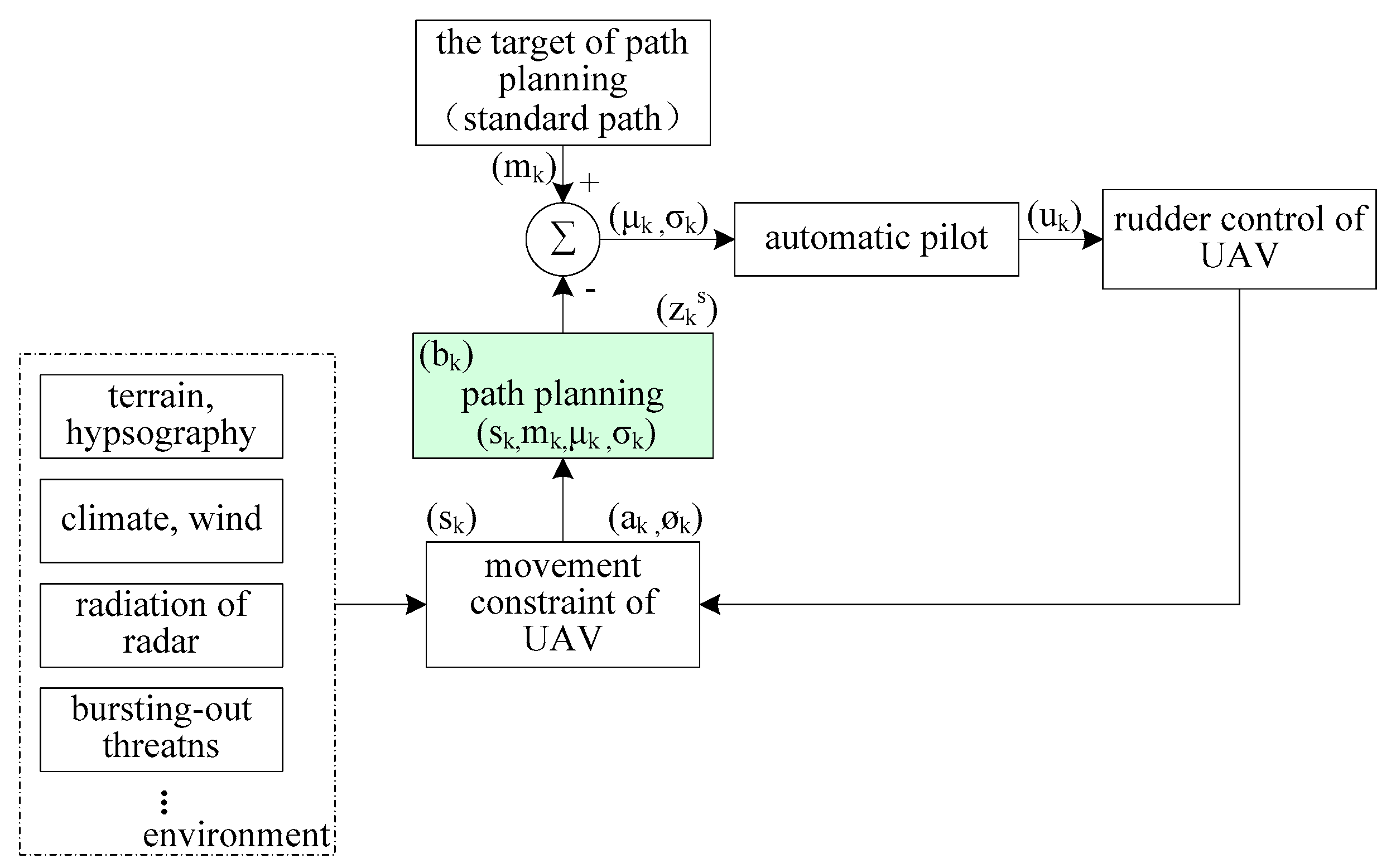
3.3. The Solution Framework for UAV Path Planning Based on Q-Learning
4. Strategy Creation for UAV Path Planning Based on Q-Learning
4.1. The System State Transition of UAV Path Planning
4.2. Cost Function
4.3. The Optimal Strategy for UAV Path Planning Based on Q-Learning
5. Simulation and Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Petritoli, E.; Leccese, F.; Ciani, L. Reliability degradation, preventive and corrective maintenance of UAV systems. In Proceedings of the 2018 5th IEEE International Workshop on Metrology for aeroSpace (MetroAeroSpace), Rome, Italy, 20–22 June 2018; pp. 430–434. [Google Scholar]
- Kanellakis, C.; Nikolakopoulos, G. Survey on computer vision for UAVs: Current developments and trends. J. Intell. Robot. Syst. 2017, 87, 141–168. [Google Scholar] [CrossRef]
- Kim, Y.; Gu, D.W.; Postlethwaite, I. Real-time path planning with limited information for autonomous unmanned air vehicles. Automatica 2008, 44, 696–712. [Google Scholar] [CrossRef]
- Bottasso, C.L.; Leonello, D.; Savini, B. Path planning for autonomous vehicles by trajectory smoothing using motion primitives. IEEE Trans. Control Syst. Technol. 2008, 16, 1152–1168. [Google Scholar] [CrossRef]
- Pachter, M.; Chandler, P.R. Challenges of autonomous control. IEEE Control Syst. Mag. 1998, 18, 92–97. [Google Scholar]
- Sun, X.J.; Wang, G.F.; Fan, Y.S.; Mu, D.; Qiu, B. An automatic navigation system for unmannedsurface vehicles in realistic sea environments. Appl. Sci. 2018, 8. [Google Scholar] [CrossRef]
- Ivan, K.; Elena, K.; Alexander, M.; Boris, M.; Alexey, P.; Denis, S.; Karen, S. Co-optimization of communication and sensing for multiple unmanned aerial vehicles in cooperative target tracking. Appl. Sci. 2018, 8, 899. [Google Scholar] [CrossRef]
- Lee, D.T.; Robert, L.; Drysdale, R. Generalization of Voronoi diagrams in the plane. SIAM J. Comput. 1981, 10, 73–87. [Google Scholar] [CrossRef]
- Khabit, O. Real-time obstacle avoidance for manipulators and mobile robots. Int. J. Robot. Res. 1986, 5, 90–98. [Google Scholar]
- Chen, H.D.; Chang, K.C.; Agate, C.S. UAV path planning with tangent-plus-Lyapunov vector field guidance and obstacle avoidance. IEEE Trans. Aerosp. Electr. Syst. 2013, 49, 840–856. [Google Scholar] [CrossRef]
- Fu, Y.G.; Ding, M.Y.; Zhou, C.P. Route planning for unmanned aerial vehicle (UAV) on the sea using hybrid differential evolution and quantum-behaved particle swarm optimization. IEEE Trans. Syst. Man Cyber.-Syst. 2013, 43, 1451–1465. [Google Scholar] [CrossRef]
- Cekmez, U.; Ozsiginan, M.; Sahingoz, O.K. A UAV path planning with parallel ACO algorithm on CUDA platform. In Proceedings of the International Conference on Unmanned Aircraft Systems (ICUAS), Orlando, FL, USA, 28–31 May 2014; pp. 347–354. [Google Scholar]
- Xu, C.; Duan, H.; Liu, F. Chaotic artificial bee colony approach to uninhabited combat air vehicle (UCAV) path planning. Aerosp. Sci. Technol. 2010, 14, 535–541. [Google Scholar] [CrossRef]
- LaValle, S.M. Planning Algorithms; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Ozgur, K.S. Generation of bezier curve-based flyable trajectories for multi-UAV systems with parallel genetic algorithm. J. Intell. Robot. Syst. 2014, 74, 499–511. [Google Scholar]
- Nikolos, I.K. Evolutionary algorithm based offline/online path planner for UAV navigation. IEEE Trans. Syst. Man Cyber. B 2003, 33, 898–912. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahul, K. Multi-robot path planning using co-evolutionary genetic programming. Expert Syst. Appl. 2012, 39, 3817–3831. [Google Scholar]
- Saleha, R.; Sajjad, H. Path planning in robocup soccer simulation 3D using evolutionary artificial neural network. Lect. Notes Comput. Sci. 2013, 7929, 351–359. [Google Scholar]
- Lee, J.; Bang, H. A robust terrain aided navigation using the Rao-Blackwellized particle filter trained by long short-term memory networks. Sensors 2018, 18, 2886. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Chai, T.; Lewis, F.L.; Ding, Z.; Jiang, Y. Off-policy interleaved Q-learning: Optimal control for affine nonlinear discrete-time systems. IEEE. Tran. Neur. Net. Lear. Syst. 2018, 9. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, Z.; Zhang, H. Data-based optimal control of multiagent systems: A reinforcement learning design approach. IEEE Trans. Cyber 2018, 9. [Google Scholar] [CrossRef] [PubMed]
- Zhao, F.; Zeng, Y.; Xu, B. A brain-inspired decision-making spiking neural network and its application in unmanned aerial vehicle. Front. Neurorobot 2018, 9. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Kim, K.; Kim, H.; Kim, H. Formation control algorithm of multi-UAV-based network infrastructure. Appl. Sci. 2018, 8, 1740. [Google Scholar] [CrossRef]
- Halil, C.; Kadir, A.D.; Nafiz, A. Comparison of 3D versus 4D path planning for unmanned aerial vehicles. Def. Sci. J. 2016, 66, 651–664. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Shankarachary, R.; Edwin, K.P.C. UAV path planning in a dynamic environment via partially observable Markov decision process. IEEE Trans. Aerosp. Electr. Syst. 2013, 49, 2397–2412. [Google Scholar]
- Mohanmmed, I.A.; Frank, L.L.; Magdi, S.M.; Mikulski, D.G. Discrete-time dynamic graphical games: Model-free reinforcement learning solution. Control Theory Technol. 2015, 13, 55–69. [Google Scholar]
- Liu, Y.C.; Zhao, Y.J. A virtual-waypoint based artificial potential field method for UAV path planning. In Proceedings of the 2016 IEEE Chinese Guidance, Navigation and Control Conference (CGNCC), Nanjing, China, 12–14 August 2016. [Google Scholar]
- Zhang, C.; Zhen, Z.; Wang, D.B.; Li, M. UAV path planning method based on ant colony optimization. In Proceedings of the 2010 Chinese Control and Decision Conference, Xuzhou, China, 26–28 May 2010; pp. 3790–3792. [Google Scholar]
- Zhang, H.; Cao, C.; Xu, L.; Gulliver, T.A. A UAV detection algorithm based on an Aartificial neural network. IEEE Access 2018, 6, 24720–24728. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Angles of Relative Motion | 0° | 30° | 60° | 90° | 120° | 150° |
|---|---|---|---|---|---|---|
| The minimum relative distance (km) | 1.120 | 0.881 | 0.465 | 0.652 | 1.894 | 1.872 |
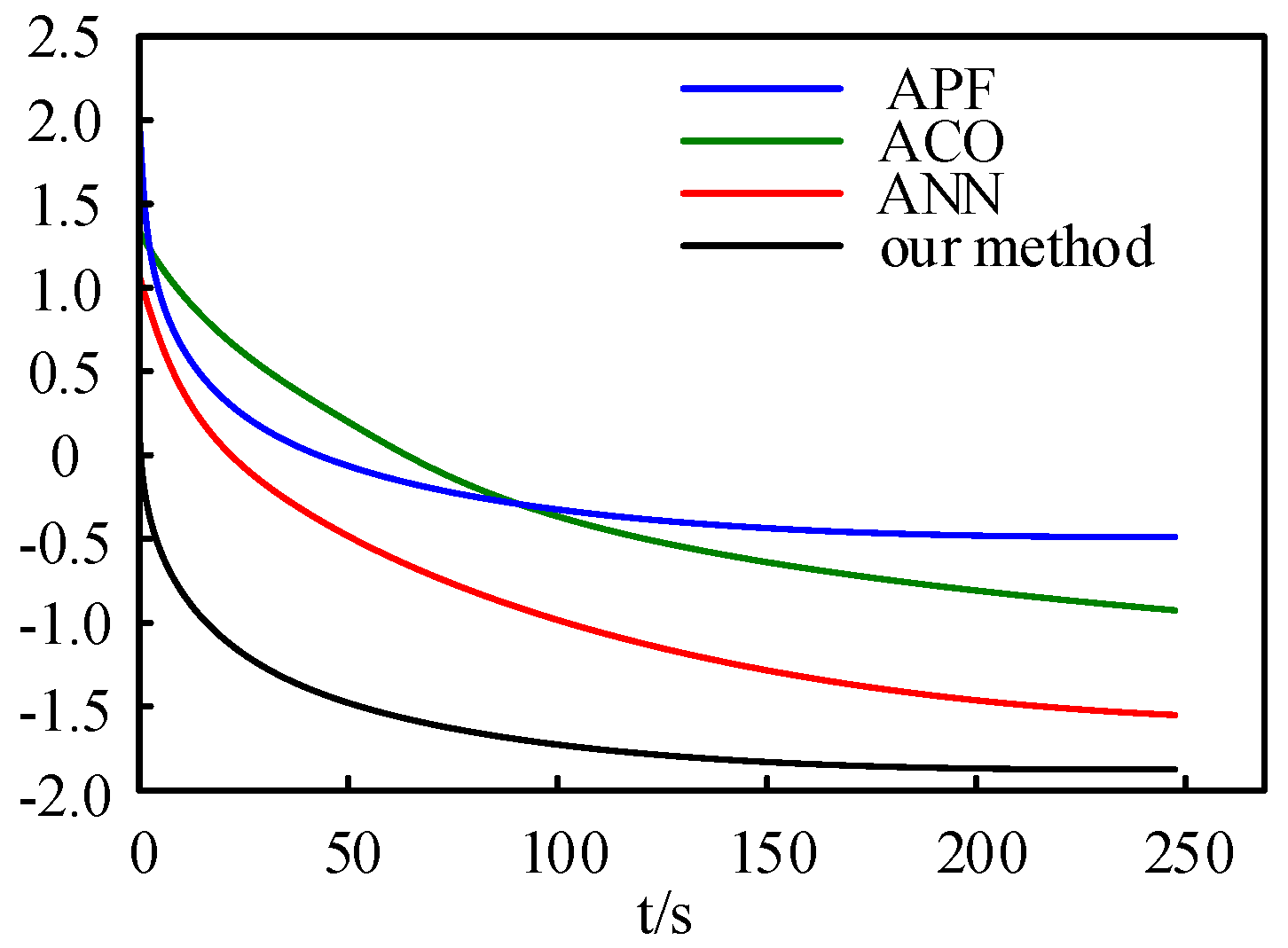
| Method | Processing Time/s | Path Length/m |
|---|---|---|
| APF | 2.428 | 90,860 |
| ACO | 1.914 | 94,251 |
| ANN | 1.833 | 103,584 |
| our method | 0.213 | 91,037 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, J.-h.; Wei, R.-x.; Liu, Z.-c.; Zhou, K. UAV Motion Strategies in Uncertain Dynamic Environments: A Path Planning Method Based on Q-Learning Strategy. Appl. Sci. 2018, 8, 2169. https://doi.org/10.3390/app8112169
Cui J-h, Wei R-x, Liu Z-c, Zhou K. UAV Motion Strategies in Uncertain Dynamic Environments: A Path Planning Method Based on Q-Learning Strategy. Applied Sciences. 2018; 8(11):2169. https://doi.org/10.3390/app8112169
Chicago/Turabian StyleCui, Jun-hui, Rui-xuan Wei, Zong-cheng Liu, and Kai Zhou. 2018. "UAV Motion Strategies in Uncertain Dynamic Environments: A Path Planning Method Based on Q-Learning Strategy" Applied Sciences 8, no. 11: 2169. https://doi.org/10.3390/app8112169
APA StyleCui, J. -h., Wei, R. -x., Liu, Z. -c., & Zhou, K. (2018). UAV Motion Strategies in Uncertain Dynamic Environments: A Path Planning Method Based on Q-Learning Strategy. Applied Sciences, 8(11), 2169. https://doi.org/10.3390/app8112169