1. Introduction
Due to the influence of short gravity waves and capillary waves on the sea surface, Bragg scattering of the sea surface is greatly weakened, causing the oil film to produce dark spots on synthetic aperture radar (SAR) images [
1]. Solberg et al. pointed out that SAR oil spill detection includes three steps: (1) dark spot detection; (2) feature extraction; and (3) discrimination of oil slicks and lookalikes [
2]. Among them, the accuracy of dark spot detection is bound to affect the extraction of oil spill location and area. However, some natural phenomena (such as waves, ocean currents, and low wind belts, as well as human factors) may change the backscatter intensity on the surface of the sea, thus leading to an uneven intensity, high noise, or blurred boundaries of oil slicks or lookalikes, making the automatic segmentation of the oil spill area sometimes very difficult. Therefore, a robust and accurate segmentation method plays a crucial role in monitoring oil spills.
There are many studies on dark spot detection on SAR images of oil spill, among which the most widely used method is based on pixel grayscale threshold segmentation, such as a manual single threshold segmentation [
3], an adaptive threshold segmentation method [
4], and some double threshold segmentation methods [
5]. Those methods have simple principles and fast implementation speeds, but they are easily affected by speckle noise and global gray unevenness, thus reducing the accuracy of dark spot recognition. The active contour models (ACM) are another common image segmentation method [
6,
7]. Compared with traditional segmentation methods, the smooth and closed contours can be obtained by ACM. The most famous and widely used region-based ACM is the borderless ACM proposed by Chan and Vese [
7]. The Chan-Vese model performs well in processing images with weak edge and noise, but it cannot process images with uneven intensity and high speckle noise.
With the popularization of neural networks and machine learning algorithms, some studies have used these methods for dark spot detection. Topouzelis et al. proposed a fully connected feed forward neural network to monitor the dark spots in an oil spill area, and obtained a very high detection accuracy at that time [
8]. Taravat et al. used a Weibull multiplication filter to suppress speckle noise, enhance the contrast between target and background, and used a multi-layer perceptron (MLP) neural network to segment the filtered SAR images [
9]. Taravat et al. also proposed a new method to distinguish dark spots from the combination of the Weibull multiplication model (WMM) and pulse coupled neural networks (PCNN) [
10]. Singha used artificial neural networks (ANN) to identify the characteristics of oil slicks and lookalikes [
11]. Although this method improved the segmentation accuracy to some extent and suppressed the influence of speckle noise on dark spot extraction, it still cannot obtain high segmentation accuracy and robustness. Jing et al. discussed the application of fuzzy c-means (FCM) clustering in SAR oil spill segmentation, in which it is easy to generate fragments in the segmentation process due to speckle noise images [
12]. To suppress the influence of speckle noise on SAR image segmentation of an oil spill, Teng et al. proposed a hierarchical clustering-based SAR image segmentation algorithm, which effectively maintained the shape characteristics of oil slicks in SAR images using the idea of multi-scale segmentation [
13]. However, its ability to suppress speckle noise was not good, and the segmentation of weak boundary region was also not ideal.
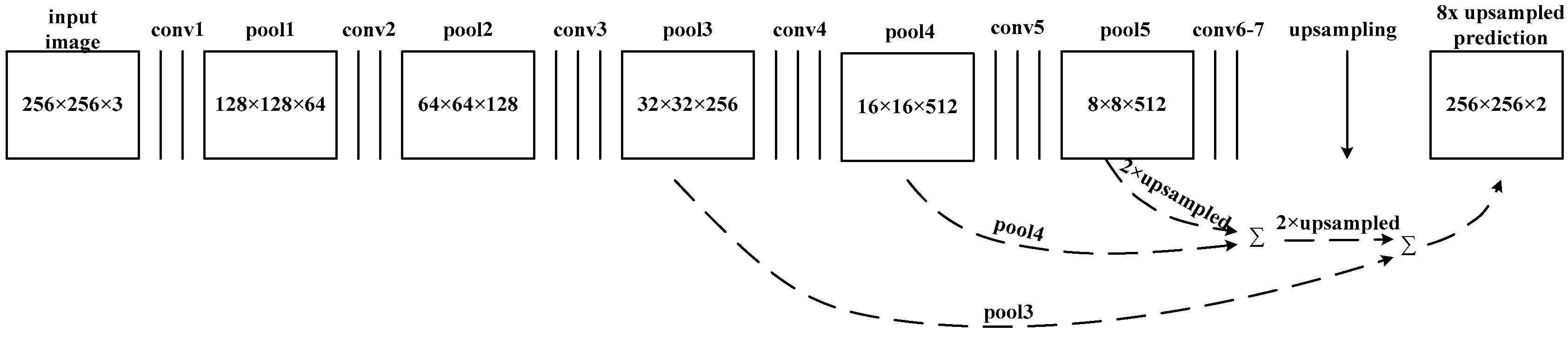
In recent years, deep learning methods have been successfully applied in extracting high level feature representations of images, especially in semantic segmentation. Long et al. changed the full connection layer of the traditional convolution neural networks (CNN) for pixel-based classification [
14]. Persello et al. used fully convolutional networks (FCN) to improve the detection accuracy of informal residential areas in high-resolution satellite images [
15]. Huang et al. successfully applied the FCN model to weed identification in paddy fields [
16]. However, FCN is not sensitive to the details in the images, and its up-sampling results are often blurred. Badanlayan et al. proposed a classic deep learning method (i.e., Segnet) for image semantic segmentation, which was used for automatic driving or intelligent robots [
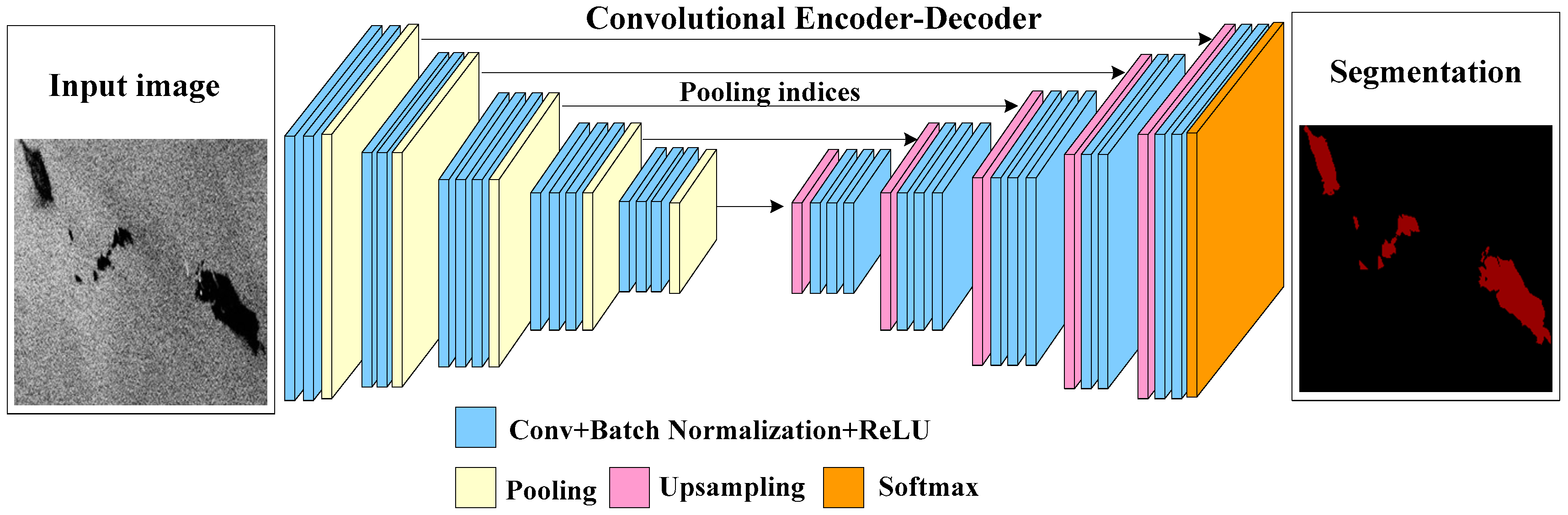
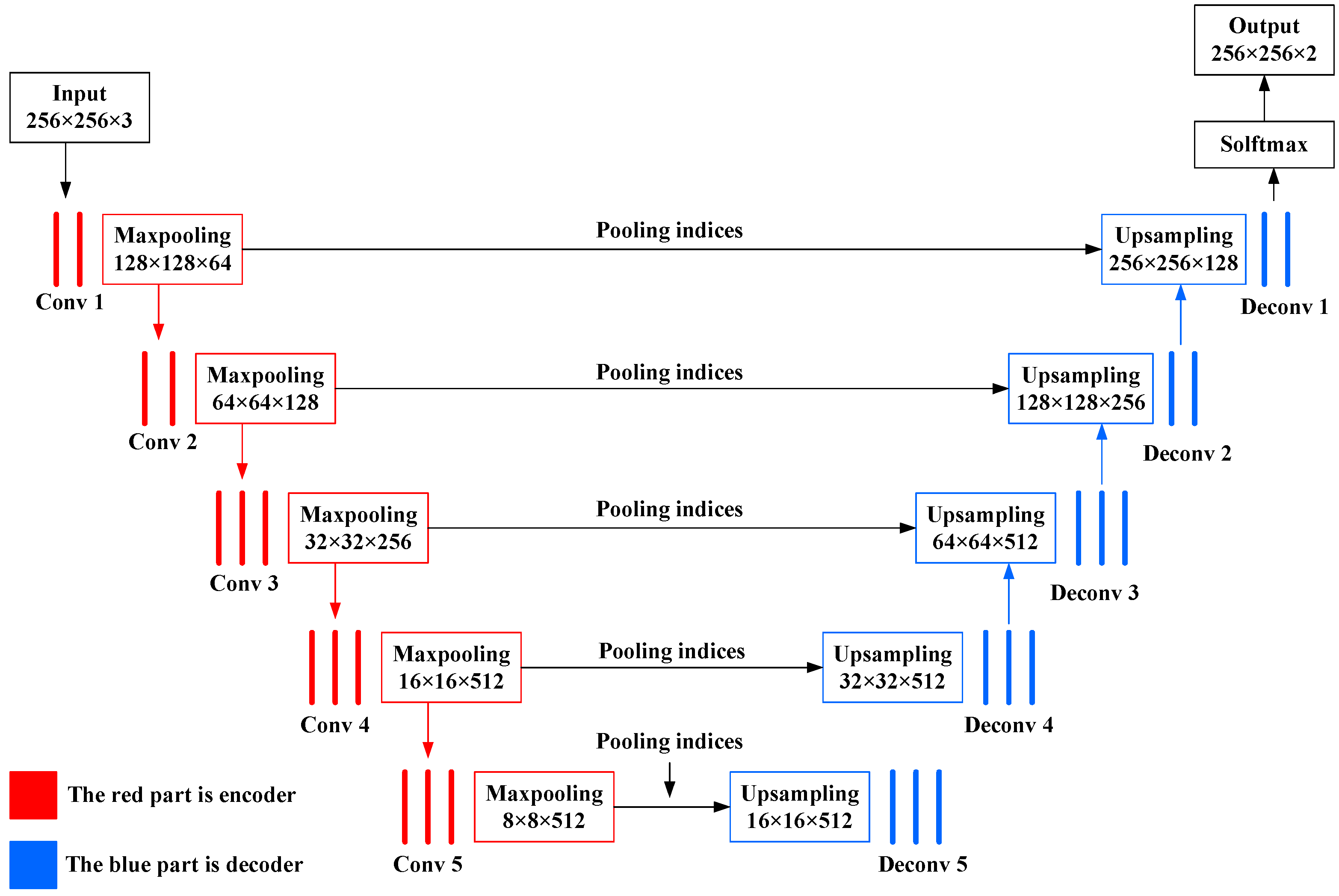
17]. The model has obvious advantages over FCN in storage, calculation time, and segmentation accuracy.
Inspired by the great success of Segnet in image semantic segmentation [
17,
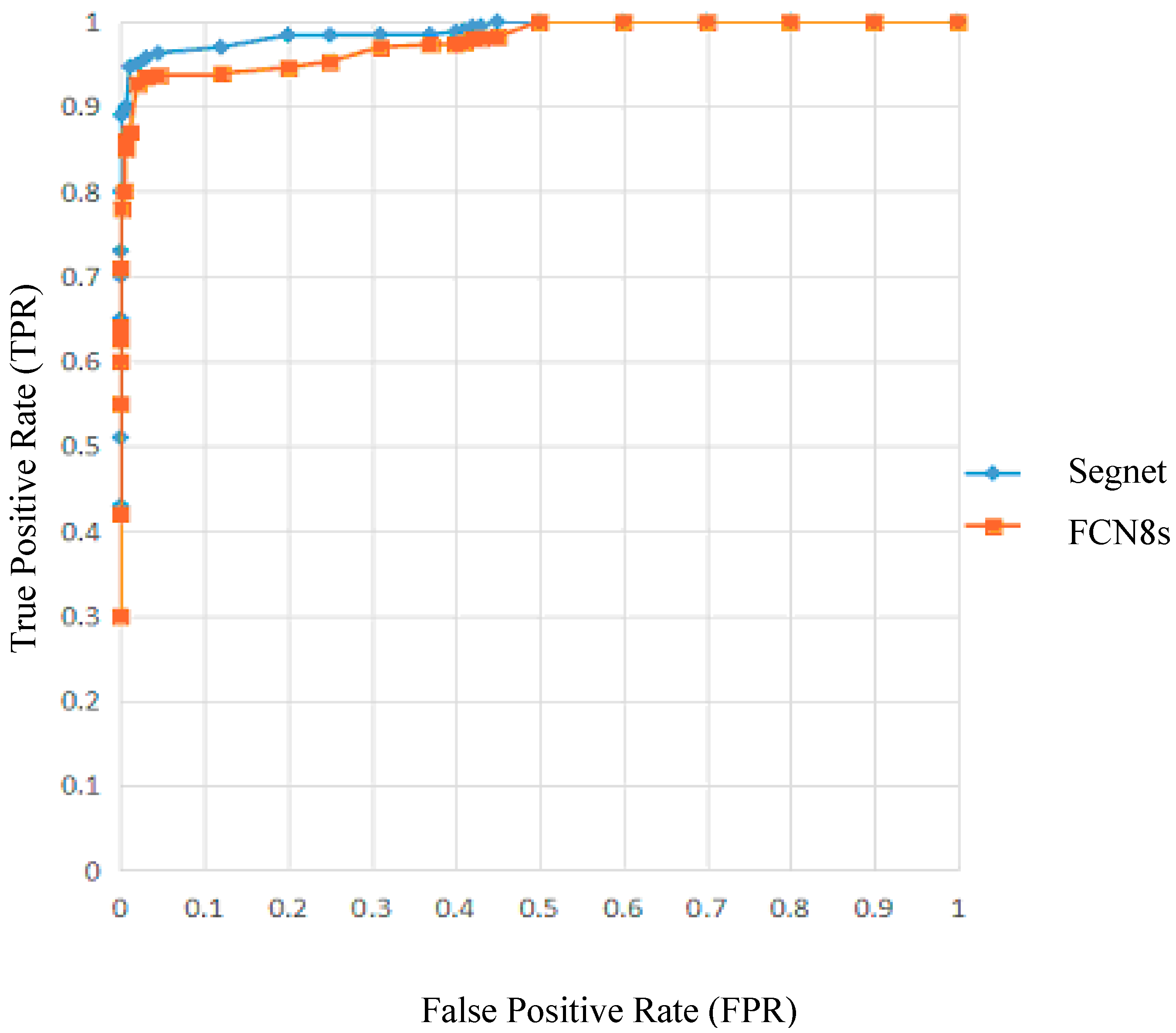
18], we used Segnet as a segmentation model to detect dark spots in oil spill areas. The proposed method is applied to a data set of 4200 from five original SAR images of oil spill. Each scene image is cropped according to four different window sizes, and samples containing oil slicks and seawater are selected from the cropped pieces as data sets. Four hundred and twenty samples were selected from each oil slick scene, with a total of 2100 sample data. To enhance the robustness of the training model, 21 samples in each oil slick scene were added with 10 noise levels of multiplicative and additive noise, respectively, totaling 2100 noisy images. The training set consisted of 1800 original samples and 1800 noisy samples, totaling 3600. The testing set consisted of 600 samples, including 300 original samples and 300 sets of noisy samples (20 noise level data corresponding to three samples randomly selected in each oil slick scene). The effectiveness of the method is demonstrated through the comparison with FCN and some classical segmentation methods (such as support vector machine (SVM), classification and regression tree (CART), random forests (RF), and Otsu, etc.). The segmentation accuracy based on Segnet can reach 93.92% under high noise and weak boundary conditions. It is here observed that the proposed method can not only accurately identify the dark spots in SAR images, but also show higher robustness.
The rest of this paper is organized as follows.
Section 2 focuses on the preparation process of the data set, which includes description, preprocessing, and sampling of five SAR oil slick scenes acquired by C-band Radarsat-2. In
Section 3, we describe the segmentation based on the Segnet model and the parameter selection in the training process. The validity of the algorithm is verified through analysis and compared with the experimental results of the semantic segmentation model FCN8s. In
Section 4, we analyze the validity and stability of the model. The conclusions and outlooks are discussed in the final section.
5. Conclusions and Outlooks
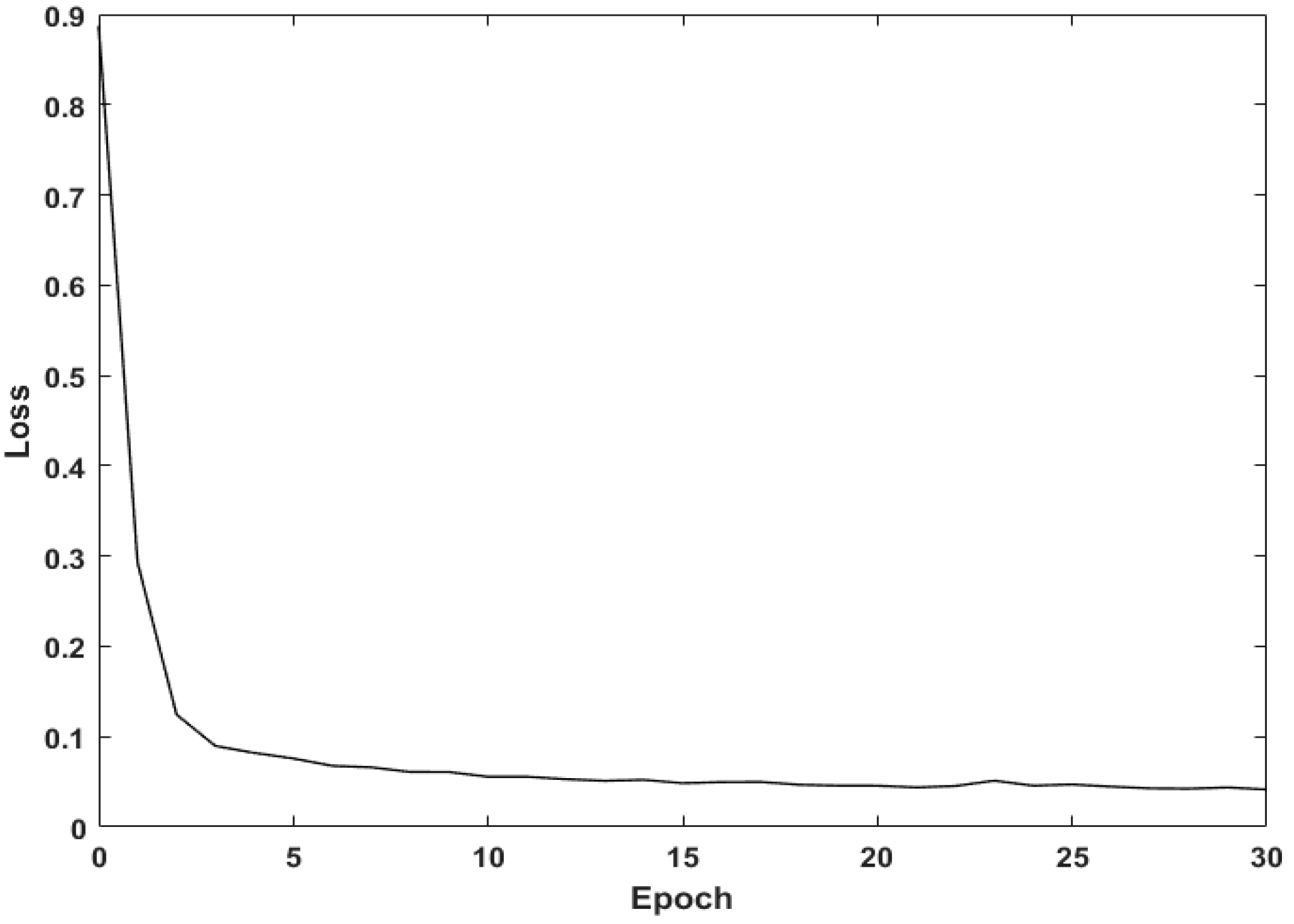
The current research used Segnet to extract dark spots in SAR images of an oil spill. To reduce the computational and storage pressure of GPU, we chose a Segnet’s batch size of 1 (i.e., inputting one sample at a time), and found that in this case, the Segnet achieved a better segmentation effect without using the batch normalization layer. The proposed method effectively distinguished between oil slicks and seawater based on the data set (OIL_SPILL_DATASET), and high accuracy segmentation results were obtained for SAR images with high noise and weak boundaries.
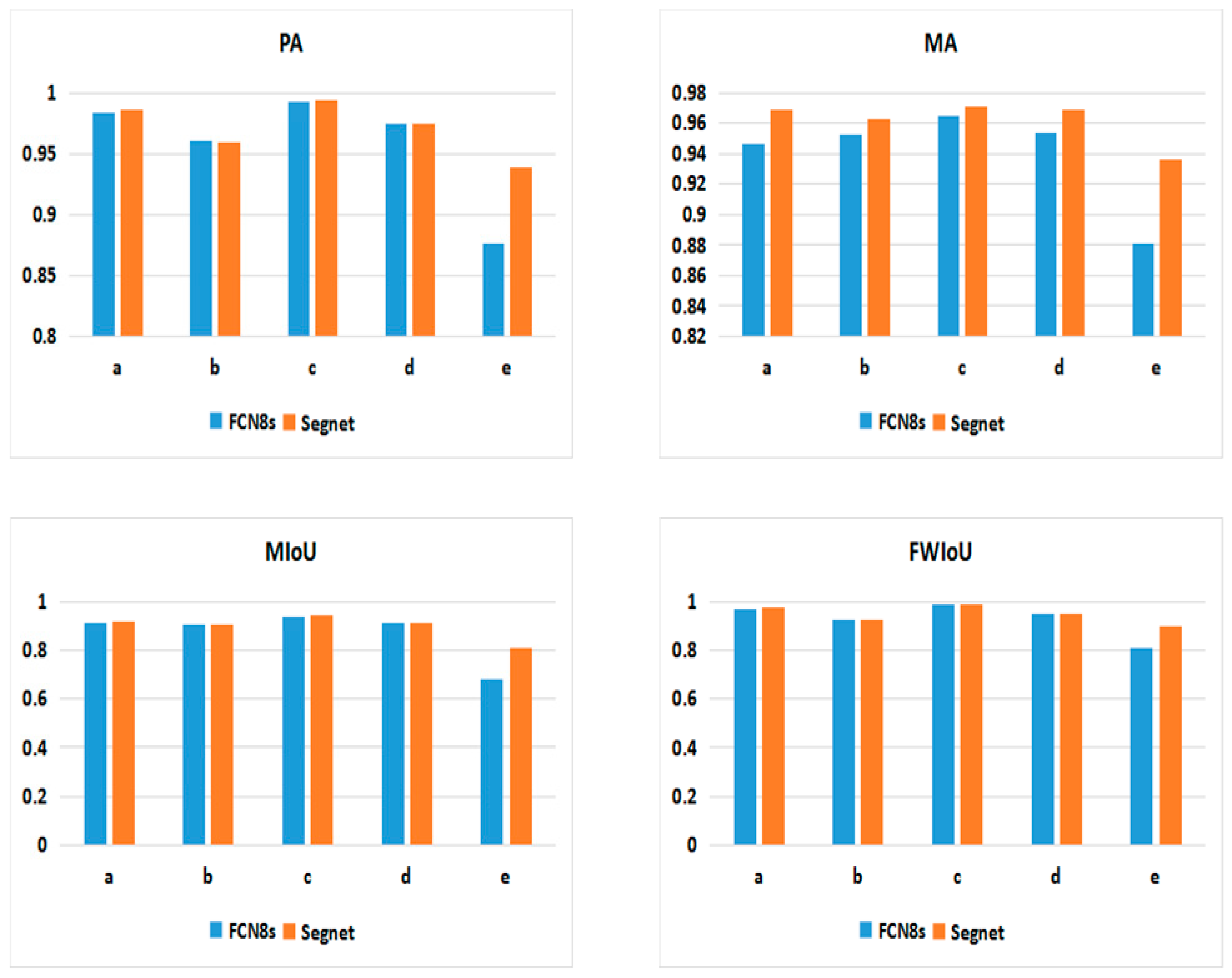
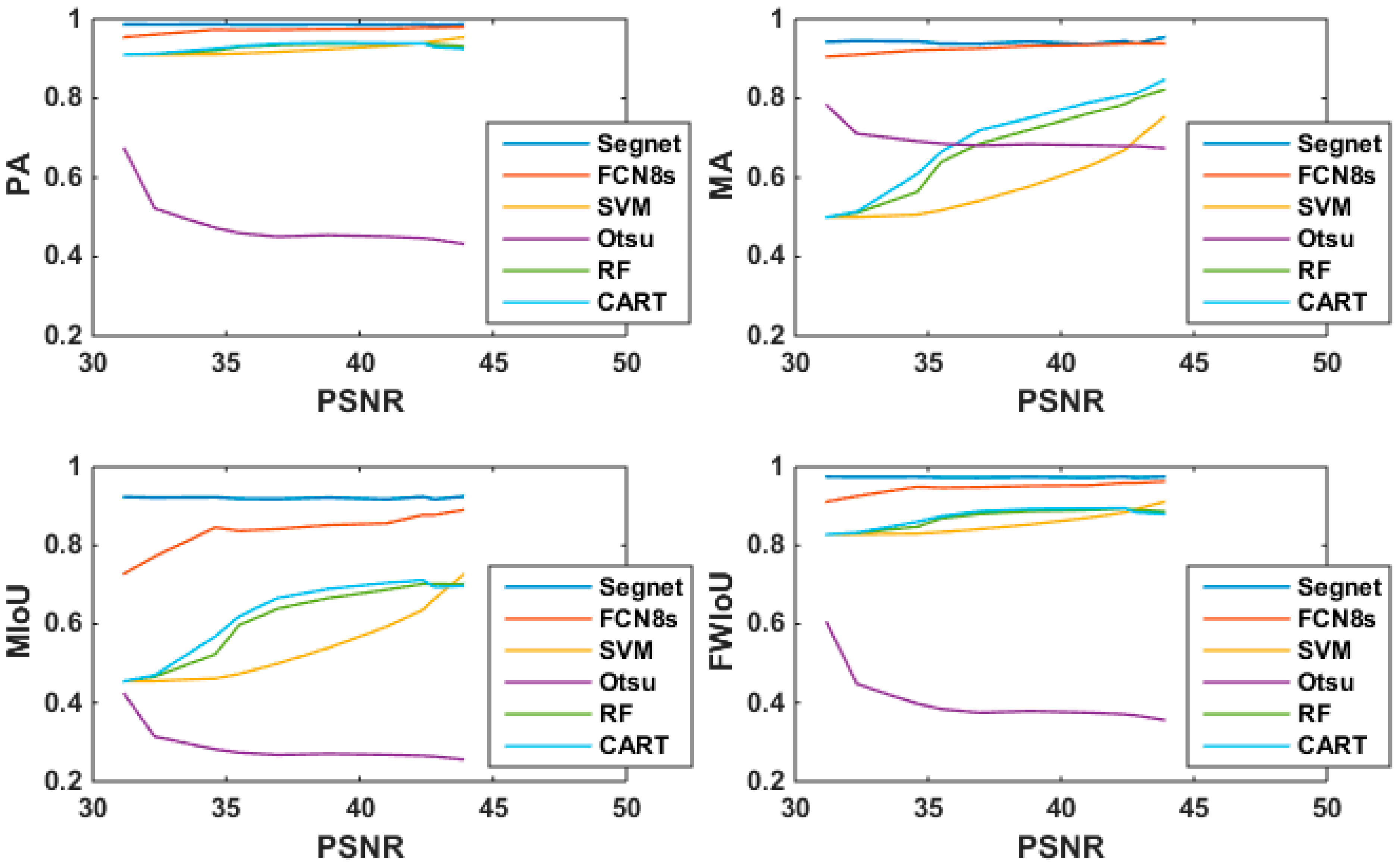
The OIL_SPILL_DATASET was also applied to FCN8s and some other classical segmentation methods. By comparing the four parameters (PA, MA, MIoU, and FWIoU) of different addition and multiplication noise levels, the following trends were found:
Segnet and FCN8s showed high stability and tolerance to addition and multiplicative noise, although the overall performance of FCN8s was not as good as that of Segnet. In addition, Segnet was obviously superior to FCN8s in weak boundary regions.
Some classical segmentation methods (such as SVM, CART, RF, and Otsu) were much more sensitive to addition and multiplicative noise than the deep learning models.
However, Segnet’s training process was supervised, and its training relies on a large number of label images. The production of labels was not only time-consuming and laborious in the data preparation stage, but also the training effect could be easily affected by human factors. In the future, we hope to shift to a weak or unsupervised training process to improve the convenience of application.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}