TRSDL: Tag-Aware Recommender System Based on Deep Learning–Intelligent Computing Systems




Abstract
:1. Introduction
- We use the pre-trained Word2Vec to represent tags, instead of the bag-of-words (BOW) model that is used in many TRS. By using word embeddings of tags, TRSDL alleviates problems of tag redundancy and ambiguity, and takes advantage of tags’ semantic information at the same time. Besides, it reduces the dimensionality of BOW-based representations so that it speeds up learning process and uses less memory resources.
- Users’ preferences evolve over time and are influenced by their historical behaviors. By organizing the user’s tagging records chronologically, and using the excellent ability of the recurrent neural networks to process temporal sequence, we obtain more useful user dynamic preferences to enhance RS’s performance.
- Interpret ability of deep structure methods is more powerful than shallow structure in the face of complex data. We model items characteristics and users preferences through deep learning algorithms, which captures the complex nonlinear relationships within the data, and extracts high-level abstract features.
2. Related Work
2.1. Traditional Tag-Aware Recommender Systems
2.2. Recommender Systems Based on Deep Learning
2.3. Tag-Aware Recommender Systems Based on Deep Learning
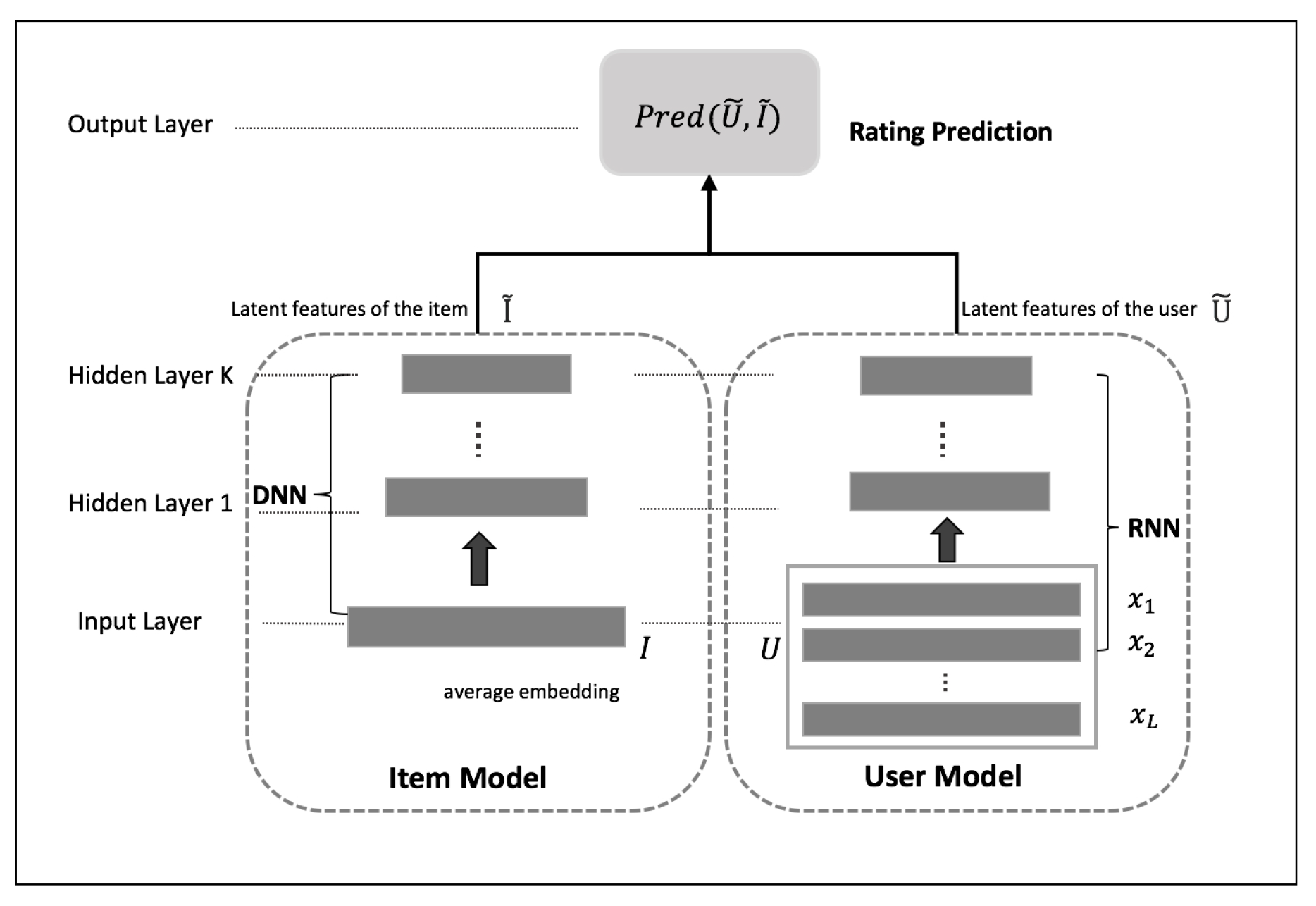
3. Methodology
3.1. Item Model
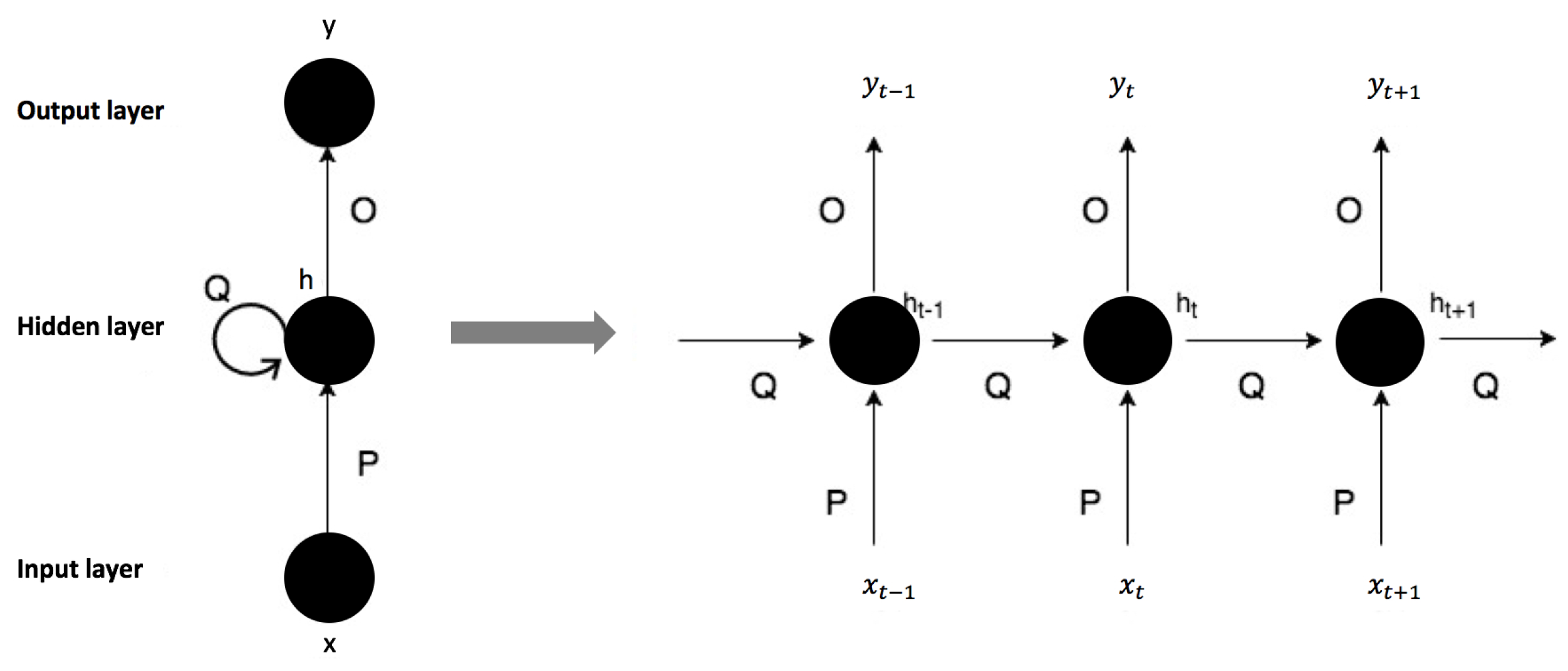
3.2. User Model
3.3. Rating Prediction
4. Experiments
4.1. Dataset
4.2. Measurements
4.3. Experimental Results and Discussions
4.3.1. Evaluation of Model Architectures
- (1)
- In the first model, we learn both users’ and items’ latent features from two single-layer neural networks.
- (2)
- The second one is built on Model (1)—we stack multiple hidden layers of both networks to verify whether the increase of layers can improve the model’s performance.
- (3)
- We apply a single-layer LSTM in the user model instead of the DNN of Model (1).
- (4)
- In the last model, we stack multiple hidden layers based on the third model.
- (a)
- TRSDL@3 provides the best results with an of 0.658 and an of 0.870, which are 5.18% and 3.87% lower than the best results of NNs, respectively. The worst performance of TRSDL group is from the single-layer structure TRSDL@1, with an of 0.688 and an of 0.905, which still outperforms all of the NNs’ experiments.
- (b)
- As the number of network layers increases, the value of the NNs experiment decreases from 0.862 to 0.694 (the value decreases from 1.104 to 0.905), and the of the TRSDL group decreases from 0.688 to 0.658 (the decreases from 0.905 to 0.870).
4.3.2. Comparative Results and Evaluations
- ItemCF: For every item of the test set, the weighted average ratings of the nearest items in the training set are returned. The cosine similarity is used to measure the degree of items’ similarity.
- UserCF: Similar to the itemCF model, the nearest user neighbors’ weighted average ratings are regarded as predictive ratings. User similarity is measured by cosine similarity.
- TAG-CF: This method integrates tag information to the collaborative filtering and proposes a tag-aware hybrid prediction algorithm [54]. The principle process is shown in the following steps.(1) Calculate item co-occurrence similarity based on Item-Tag matrix T. (2) Establish a predictive rating matrix C based on item similarity. (3) Construct a pseudo-matrix M to integrate the rating matrix R and the predictive rating matrix C. (4) Calculate user similarity through M, the similarity is measured with Pearson correlation coefficient [55]. (5) Predict ratings based on the user similarity matrix. The rating formula is defined as:
- BiasedMF: BiasedMF is the state-of-the-art collaborative filtering technique [11]. Features of users and items are mapped to a latent factor space, and the interaction between user’s latent vector and item latent vector is learned to predict ratings. The rating formula is defined as follows:where and indicate the bias of the item i and the user u, respectively; and is the global average rating.
- I-AutoRec: I-AutoRec is a novel rating framework based on AutoEncoder [35]. It takes item vectors as input and reconstructs them in the output layer. The values in the reconstructed vectors are the predicted value of the corresponding position.where is the reconstruction of input r, for transformations W, V, and biases , b. The parameters we used in experiments are: learning rate , the number of hidden units and the regularization strength .
- DNN: In the DNN model, item profiles are the same as those of TRSDL, while user profiles are constructed from corresponding items’ average embeddings rather than from chronological item embeddings. Ratings are predicted by latent features extracted from two parallel deep neural networks. The parameters of DNN model are the same as those of NNs@3.
- BOW-TRSDL: The state-of-the-art tag-aware recommenders are found in [9,10]. Unfortunately, we cannot compare with them directly because our ultimate targets are different (i.e., their application scenario is top-n recommendations). Considering the biggest difference is the way tags are represented during the profile constructions, we leverage the bag-of-words (BOW) model to build users’ and items’ profiles. The model is denoted as “BOW-TRSDL”. In the model, tags used less than 10 times are cut down to reduce the amount of computation and the noise. Other parameters are the same as those of TRSDL.
- TRSDL: TRSDL is our proposed model. We utilize the DNNs to obtain items’ latent features and leverage the LSTM to extract users’ latent preferences from their temporal tagging sequences. Then, these hidden features are interacted to predict corresponding ratings. The parameters in the experiment are the same as those of TRSDL@3.
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Shepitsen, A.; Gemmell, J.; Mobasher, B.; Burke, R. Personalized recommendation in social tagging systems using hierarchical clustering. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 259–266. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Zhao, S.; Du, N.; Nauerz, A.; Zhang, X.; Yuan, Q.; Fu, R. Improved recommendation based on collaborative tagging behaviors. In Proceedings of the 13th International Conference on Intelligent User Interfaces, Gran Canaria, Spain, 13–16 January 2008; pp. 413–416. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Tomar, A.; Godin, F.; Vandersmissen, B.; De Neve, W.; Van de Walle, R. Towards Twitter hashtag recommendation using distributed word representations and a deep feed forward neural network. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics, New Delhi, India, 24–27 September 2014; pp. 362–368. [Google Scholar]
- Zhang, Q.; Wang, J.; Huang, H.; Huang, X.; Gong, Y. Hashtag recommendation for multimodal microblog using co-attention network. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3420–3426. [Google Scholar]
- Nguyen, H.T.; Wistuba, M.; Grabocka, J.; Drumond, L.R.; Schmidt-Thieme, L. Personalized Deep Learning for Tag Recommendation. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Jeju, South Korea, 23–26 May 2017; pp. 186–197. [Google Scholar]
- Xu, Z.; Chen, C.; Lukasiewicz, T.; Miao, Y.; Meng, X. Tag-aware personalized recommendation using a deep-semantic similarity model with negative sampling. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 1921–1924. [Google Scholar]
- Zuo, Y.; Zeng, J.; Gong, M.; Jiao, L. Tag-aware recommender systems based on deep neural networks. Neurocomputing 2016, 204, 51–60. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Liu, S.; Pan, Z.; Cheng, X. A novel fast fractal image compression method based on distance clustering in high dimensional sphere surface. Fractals 2017, 25, 1740004. [Google Scholar] [CrossRef]
- Lu, M.; Liu, S.; Kumarsangaiah, A.; Zhou, Y.; Pan, Z.; Zuo, Y. Nucleosome Positioning with Fractal Entropy Increment of Diversity in Telemedicine. IEEE Access 2017. [Google Scholar] [CrossRef]
- Liu, G.; Liu, S.; Muhammad, K. Object Tracking in Vary Lighting Conditions for Fog based Intelligent Surveillance of Public Spaces. IEEE Access 2018. [Google Scholar] [CrossRef]
- Nakamoto, R.; Nakajima, S.; Miyazaki, J.; Uemura, S. Tag-based contextual collaborative filtering. IAENG Int. J. Comput. Sci. 2007, 34, 214–219. [Google Scholar]
- Marinho, L.B.; Schmidt-Thieme, L. Collaborative tag recommendations. In Data Analysis, Machine Learning and Applications; Springer: Heidelberg/Berlin, Germany, 2008; pp. 533–540. [Google Scholar]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to Recommender Systems Handbook; Springer: Heidelberg/Berlin, Germany, 2011. [Google Scholar]
- Tso-Sutter, K.H.; Marinho, L.B.; Schmidt-Thieme, L. Tag-aware recommender systems by fusion of collaborative filtering algorithms. In Proceedings of the 2008 ACM Symposium on Applied Computing, Fortaleza, Ceara, Brazil, 16–20 March 2008; pp. 1995–1999. [Google Scholar]
- Wetzker, R.; Umbrath, W.; Said, A. A hybrid approach to item recommendation in folksonomies. In Proceedings of the WSDM’09 Workshop on Exploiting Semantic Annotations in Information Retrieval, Barcelona, Spain, 9 February 2009; pp. 25–29. [Google Scholar]
- Szomszor, M.; Cattuto, C.; Alani, H.; O’Hara, K.; Baldassarri, A.; Loreto, V.; Servedio, V.D. Folksonomies, the semantic web, and movie recommendation. In Proceedings of the 4th European semantic web conference, Innsbruck, Australia, 3–7 June 2007; pp. 25–29. [Google Scholar]
- Symeonidis, P.; Nanopoulos, A.; Manolopoulos, Y. Tag recommendations based on tensor dimensionality reduction. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 43–50. [Google Scholar]
- Rendle, S.; Balby Marinho, L.; Nanopoulos, A.; Schmidt-Thieme, L. Learning optimal ranking with tensor factorization for tag recommendation. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 727–736. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Hotho, A.; Jäschke, R.; Schmitz, C.; Stumme, G. Information retrieval in folksonomies: Search and ranking. In Proceedings of the European Semantic Web conference, Budva, Montenegro, 11–14 June 2006; Springer: Heidelberg/Berlin, Germany; pp. 411–426. [Google Scholar]
- Zhang, Z.K.; Zhou, T.; Zhang, Y.C. Personalized recommendation via integrated diffusion on user–item–tag tripartite graphs. Phys. A Stat. Mech. Appl. 2010, 389, 179–186. [Google Scholar] [CrossRef]
- Rendle, S.; Schmidt-Thieme, L. Pairwise interaction tensor factorization for personalized tag recommendation. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 4–6 February 2010; pp. 81–90. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Wang, Z.; Deng, Z. Tag recommendation based on bayesian principle. In Proceedings of the International Conference on Advanced Data Mining and Applications, Chongqing, China, 19–21 November 2010; Springer: Heidelberg/Berlin, Germany; pp. 191–201. [Google Scholar]
- Salakhutdinov, R.; Mnih, A.; Hinton, G. Restricted Boltzmann machines for collaborative filtering. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 791–798. [Google Scholar]
- Wang, H.; Wang, N.; Yeung, D.Y. Collaborative deep learning for recommender systems. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chongqing, China, 19–21 November 2010; pp. 1235–1244. [Google Scholar]
- Slaney, M. Web-scale multimedia analysis: Does content matter? IEEE MultiMedia 2011, 18, 12–15. [Google Scholar] [CrossRef]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Ying, H.; Chen, L.; Xiong, Y.; Wu, J. Collaborative deep ranking: A hybrid pair-wise recommendation algorithm with implicit feedback. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 15 September 2016; Springer: Heidelberg/Berlin, Germany; pp. 555–567. [Google Scholar]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar]
- Zhang, S.; Yao, L.; Xu, X. Autosvd++: An efficient hybrid collaborative filtering model via contractive auto-encoders. arXiv, 2017; arXiv:1704.00551. [Google Scholar]
- Zhuang, F.; Zhang, Z.; Qian, M.; Shi, C.; Xie, X.; He, Q. Representation learning via Dual-Autoencoder for recommendation. Neur. Netw. 2017, 90, 83–89. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Zheng, H.T.; Mao, X.X. Extracting Deep Semantic Information for Intelligent Recommendation. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; pp. 134–144. [Google Scholar]
- Zheng, H.T.; Chen, J.Y.; Yao, X.; Sangaiah, A.K.; Jiang, Y.; Zhao, C.Z. Clickbait Convolutional Neural Network. Symmetry 2018, 10. [Google Scholar] [CrossRef]
- Van den Oord, A.; Dieleman, S.; Schrauwen, B. Deep content-based music recommendation. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Nevada, 5–10 December 2013; pp. 2643–2651. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. arXiv, 2015; arXiv:1511.06939. [Google Scholar]
- Tan, Y.K.; Xu, X.; Liu, Y. Improved recurrent neural networks for session-based recommendations. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 17–22. [Google Scholar]
- Hidasi, B.; Quadrana, M.; Karatzoglou, A.; Tikk, D. Parallel recurrent neural network architectures for feature-rich session-based recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 241–248. [Google Scholar]
- Quadrana, M.; Karatzoglou, A.; Hidasi, B.; Cremonesi, P. Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 130–137. [Google Scholar]
- Wang, X.; Yu, L.; Ren, K.; Tao, G.; Zhang, W.; Yu, Y.; Wang, J. Dynamic attention deep model for article recommendation by learning human editors’ demonstration. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 2051–2059. [Google Scholar]
- Smirnova, E.; Vasile, F. Contextual Sequence Modeling for Recommendation with Recurrent Neural Networks. arXiv, 2017; arXiv:1706.07684. [Google Scholar]
- Wu, C.Y.; Ahmed, A.; Beutel, A.; Smola, A.J.; Jing, H. Recurrent recommender networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 495–503. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. Deepfm: A factorization-machine based neural network for CTR prediction. arXiv, 2017; arXiv:1703.04247. [Google Scholar]
- Wang, J.; Yu, L.; Zhang, W.; Gong, Y.; Xu, Y.; Wang, B.; Zhang, P.; Zhang, D. Irgan: A minimax game for unifying generative and discriminative information retrieval models. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 515–524. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernockỳ, J.; Khudanpur, S. Recurrent Neural Network Based Language Model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; Volume 2, p. 3. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Neur. Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Liu, D.Z.; Singh, G. A Recurrent Neural Network Based Recommendation System. Available online: http://cs224d.stanford.edu/reports/LiuSingh.pdf (accessed on 16 May 2018).
- Wang, W.P.; Wang, J.H. Hybrid Recommendation Method Based on Tag and Collaborative Filtering. Comput. Eng. 2011, 14, 10. [Google Scholar]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Heidelberg/Berlin, Germany, 2009; pp. 1–4. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Routledge: Abingdon, UK, 1988. [Google Scholar]



{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| - matrix | |
| - matrix | |
| T | the tag consisting of tokens |
| G | the token list of Metadata |
| average embeddings of tags | |
| average embeddings of metadata | |
| d | dimensionality of the Word2Vec model |
| D | dimensionality of an item’s embedding representation |
| M | the number of items in the training set |
| N | the number of users in the training set |
| latent features of the item | |
| latent features of the user | |
| L | the max RNN sequence length |
| z | the concatenated vector of user and item latent features |
| the shift balance factor | |
| the balance factor of L2 regularization | |
| R | the space that users have rated on items |
| Y | predicted rating scores |
| J | the prediction loss function |
| the set of training parameters |
| Item | Quantity |
|---|---|
| Users (u) | 7159 |
| Movies (i) | 13,396 |
| Ratings (r) | 126,083 |
| Tags (t) | 34,065 |
| Genres (g) | 19 |
| Structures | Settings |
|---|---|
| NNs@1 | , , , , , |
| NNs@2 | , , , , , , |
| NNs@3 | , , , , , , , |
| TRSDL@1 | , , , , , |
| TRSDL@2 | , , , , , , |
| TRSDL@3 | , , , , , , , |
| Structures | MAE | RMSE |
|---|---|---|
| NNs@1 | 0.862 | 1.104 |
| NNs@2 | 0.711 | 0.934 |
| NNs@3 | 0.694 | 0.905 |
| TRSDL@1 | 0.688 | 0.905 |
| TRSDL@2 | 0.670 | 0.881 |
| TRSDL@3 | 0.658 | 0.870 |
| Models | MAE | RMSE |
|---|---|---|
| ItemCF | 1.091 | 1.329 |
| UserCF | 1.237 | 1.481 |
| TAG-CF | 1.042 | 1.366 |
| BiasedMF | 0.673 | 0.904 |
| I-AutoRec | 0.703 | 1.057 |
| DNN | 0.735 | 1.011 |
| BOW-TRSDL | 0.736 | 0.971 |
| TRSDL | 0.658 | 0.870 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, N.; Zheng, H.-T.; Chen, J.-Y.; Sangaiah, A.K.; Zhao, C.-Z. TRSDL: Tag-Aware Recommender System Based on Deep Learning–Intelligent Computing Systems. Appl. Sci. 2018, 8, 799. https://doi.org/10.3390/app8050799
Liang N, Zheng H-T, Chen J-Y, Sangaiah AK, Zhao C-Z. TRSDL: Tag-Aware Recommender System Based on Deep Learning–Intelligent Computing Systems. Applied Sciences. 2018; 8(5):799. https://doi.org/10.3390/app8050799
Chicago/Turabian StyleLiang, Nan, Hai-Tao Zheng, Jin-Yuan Chen, Arun Kumar Sangaiah, and Cong-Zhi Zhao. 2018. "TRSDL: Tag-Aware Recommender System Based on Deep Learning–Intelligent Computing Systems" Applied Sciences 8, no. 5: 799. https://doi.org/10.3390/app8050799
APA StyleLiang, N., Zheng, H. -T., Chen, J. -Y., Sangaiah, A. K., & Zhao, C. -Z. (2018). TRSDL: Tag-Aware Recommender System Based on Deep Learning–Intelligent Computing Systems. Applied Sciences, 8(5), 799. https://doi.org/10.3390/app8050799