Image Segmentation by Searching for Image Feature Density Peaks

 ,
,  ,
,
Abstract
:1. Introduction
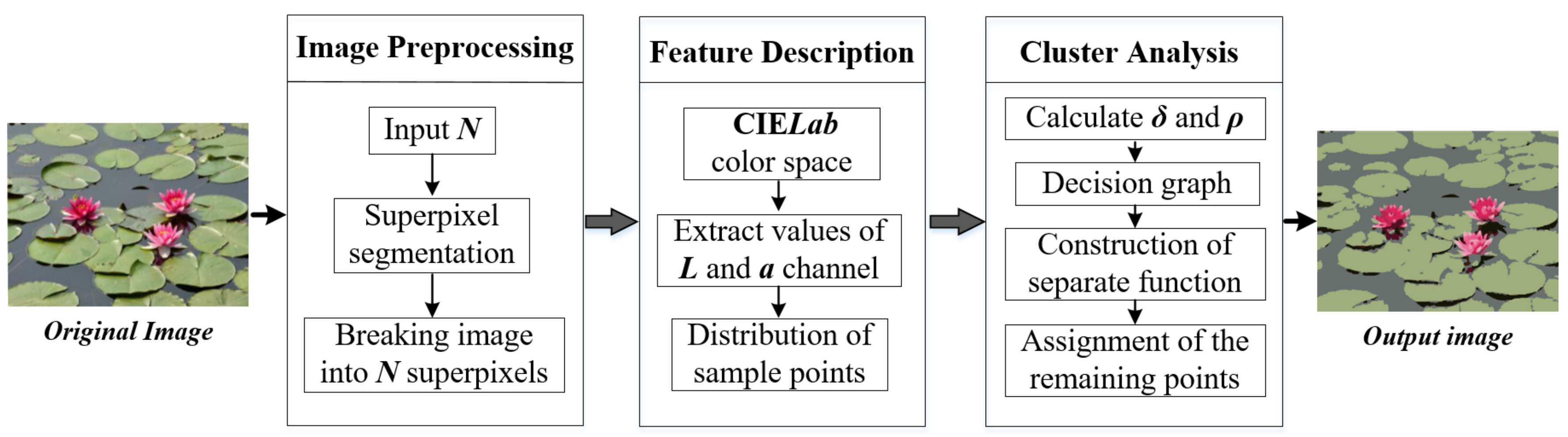
2. Materials and Methods
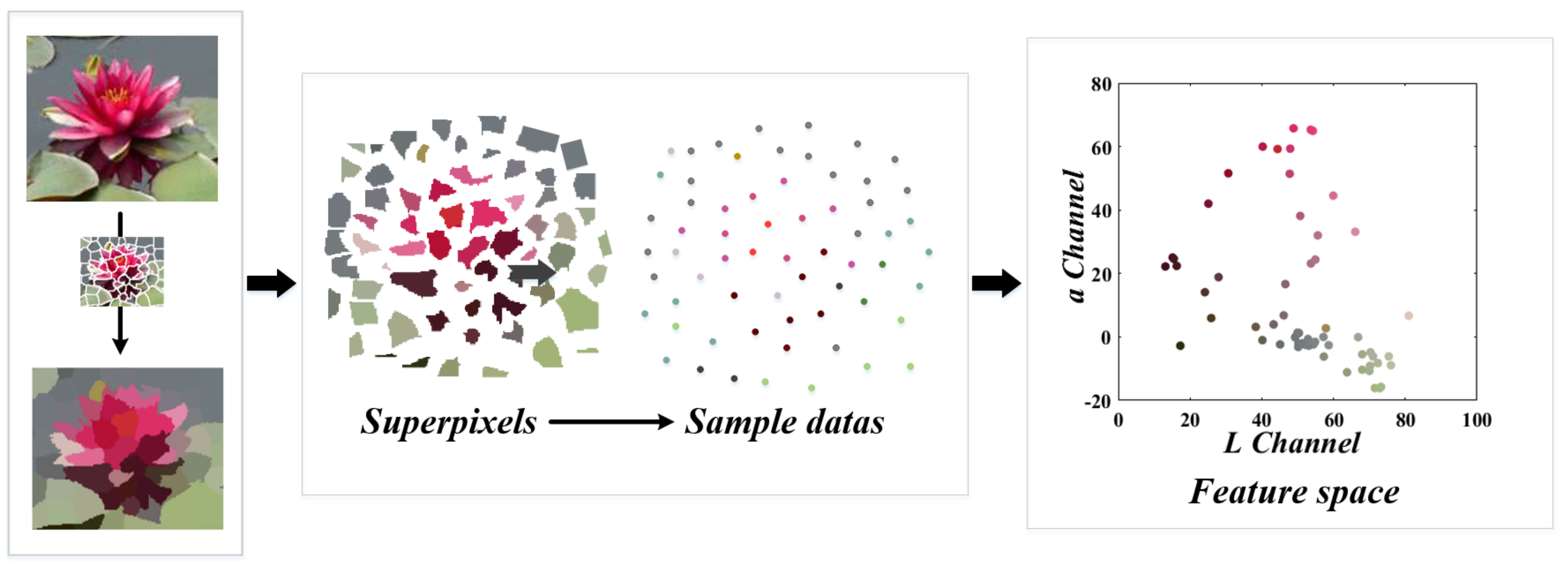
2.1. Superpixel Method for Image Preprocessing
2.2. CIE Color Space for Image Feature Description
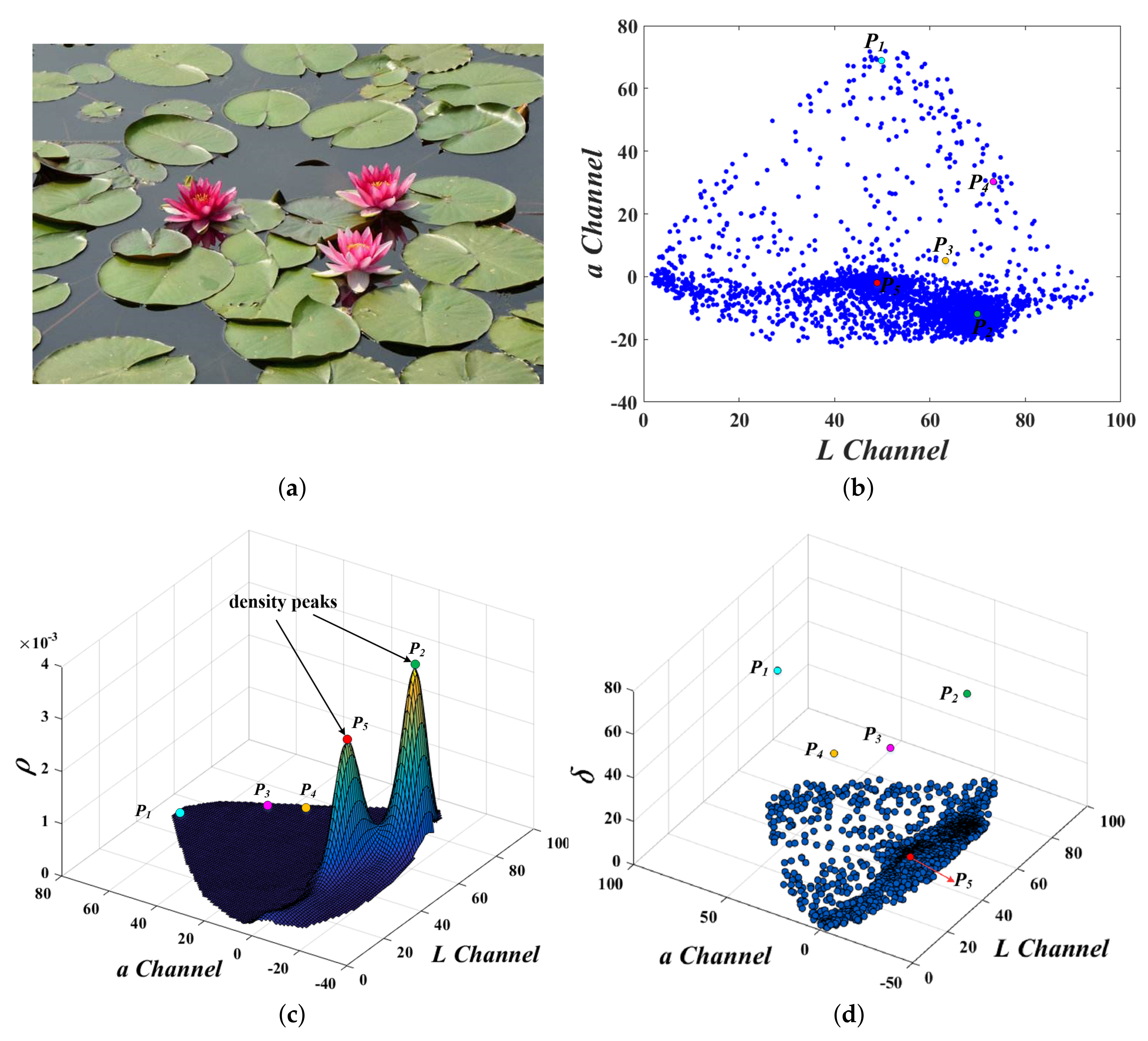
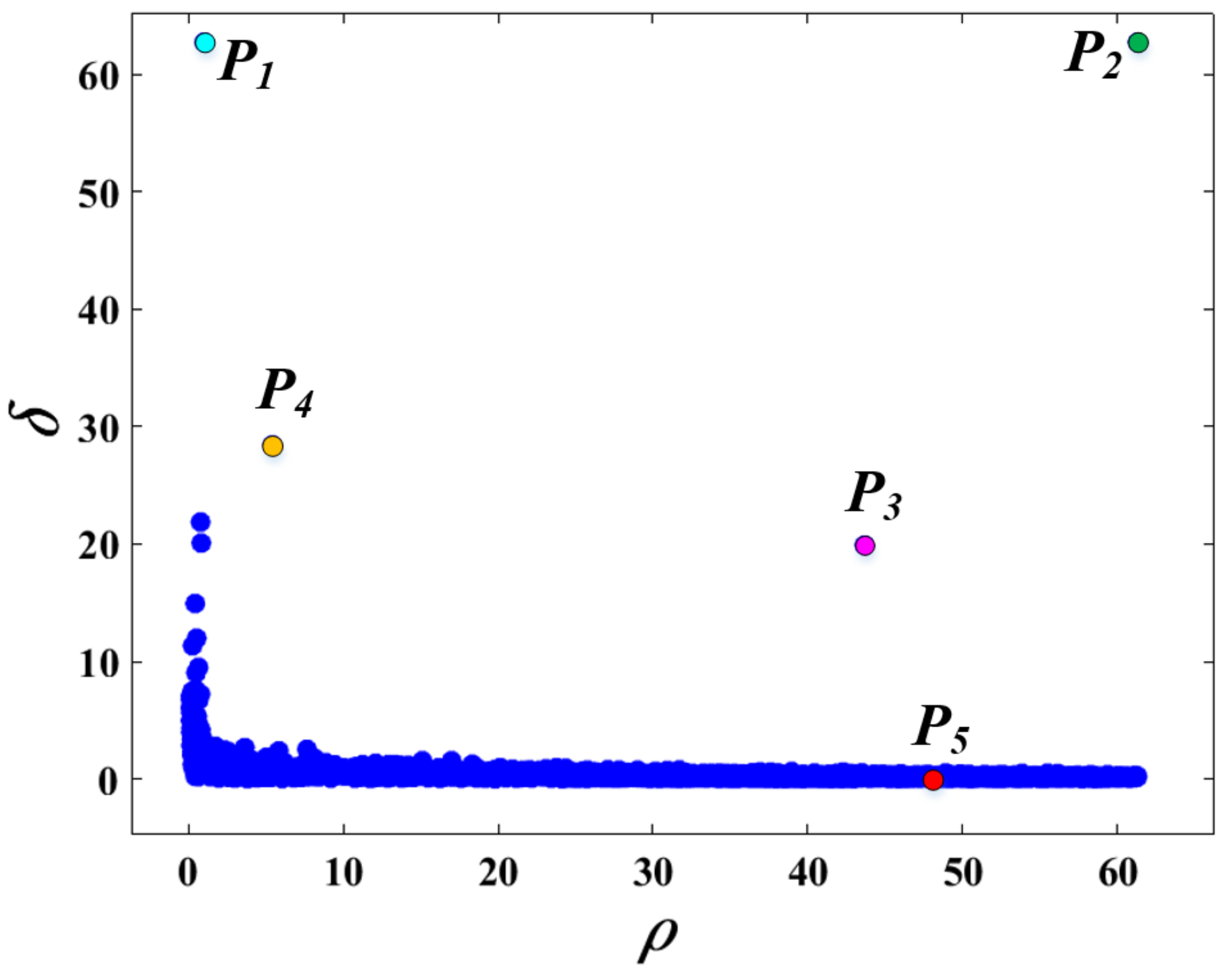
2.3. Improvement of the Clustering Method
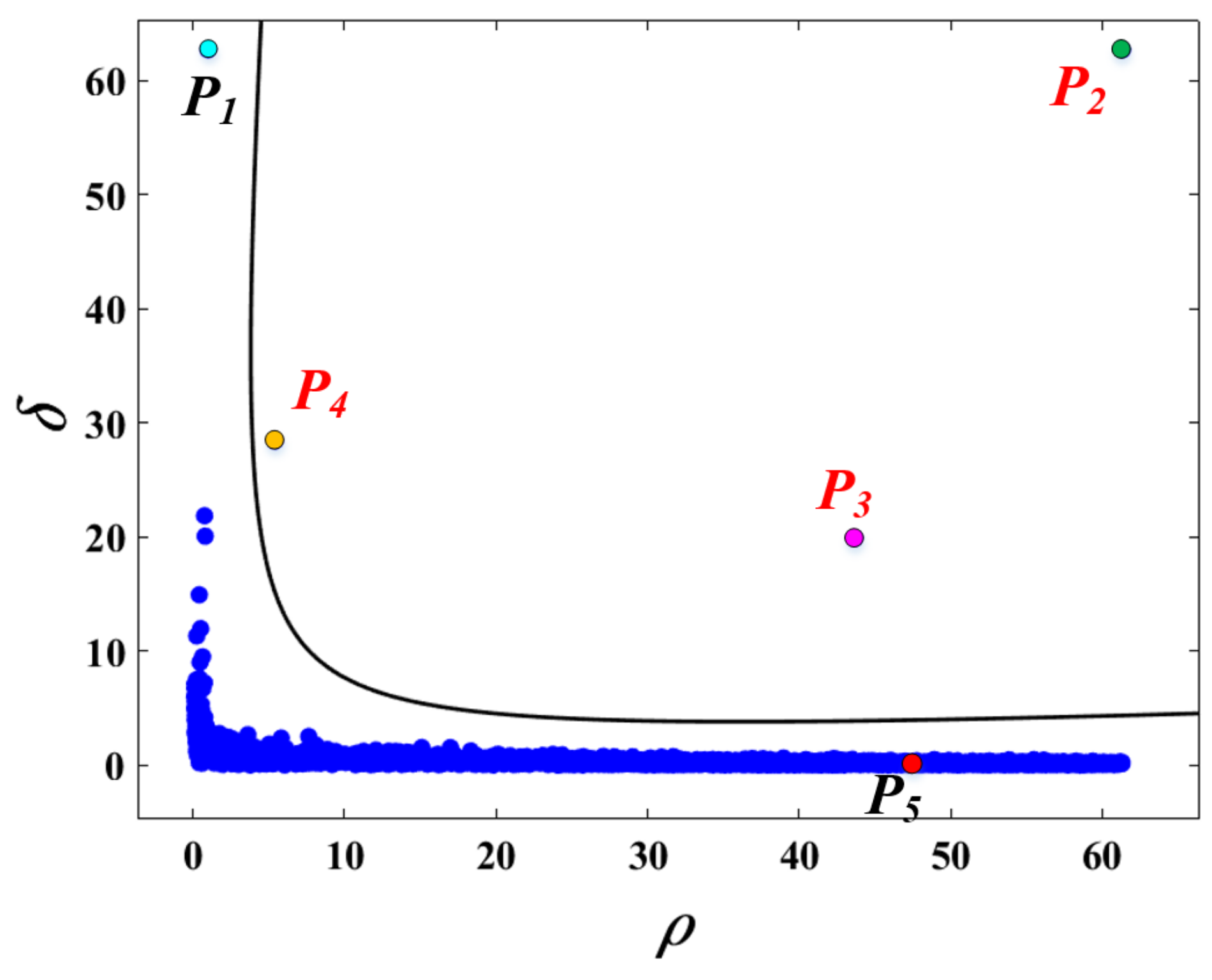
2.4. Adaptive Selection of Cluster Centers
| Algorithm 1 Assignment of remaining points |
Input: cluster centers ; the local density set and distance set for all superpixels computed from the original image.
|
3. Experiment
3.1. Data and Experimental Setting
3.2. Evaluation
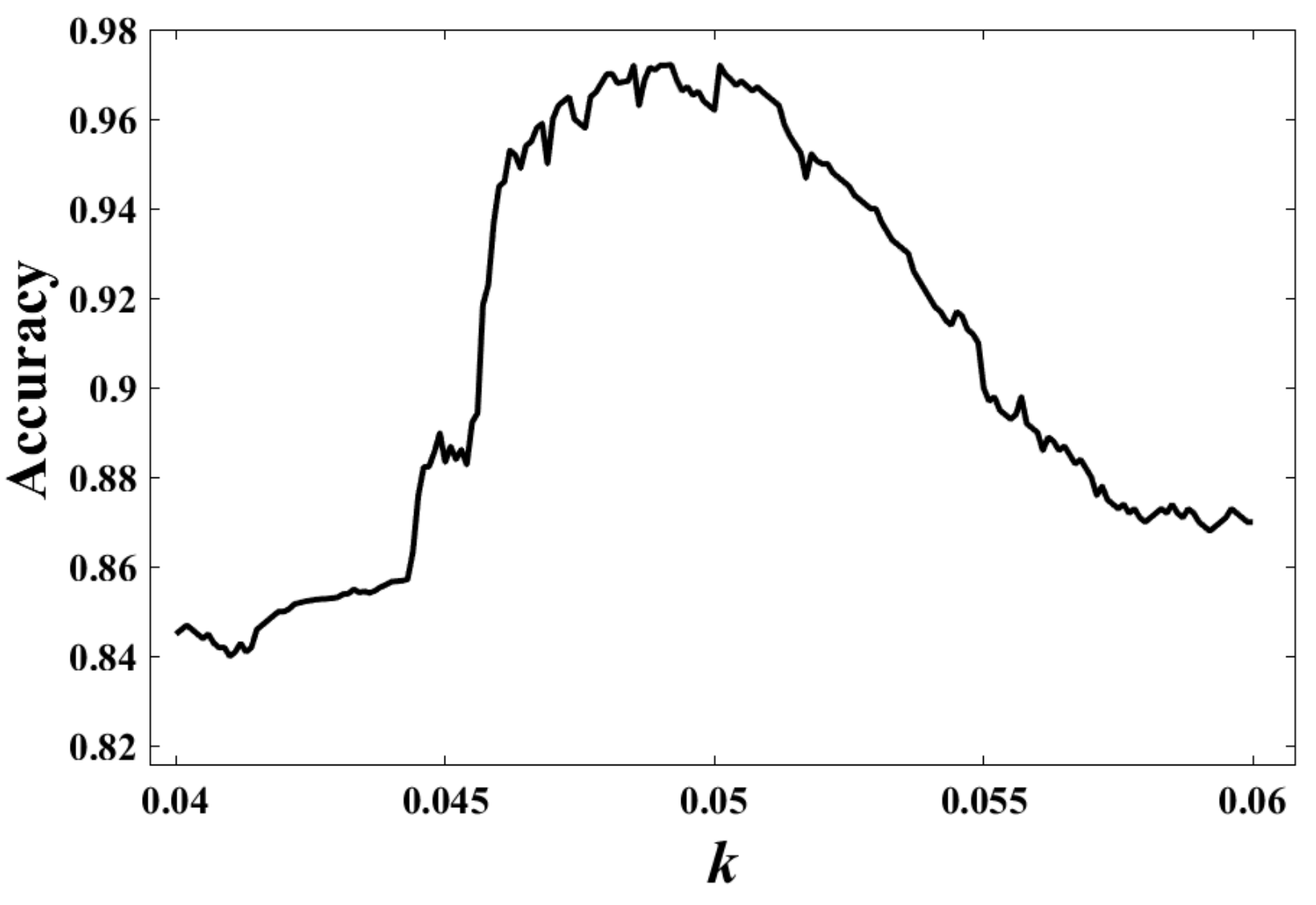
3.2.1. Effects of Parameters
3.2.2. Quantitative Evaluation
3.2.3. Qualitative Evaluation
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Qi, Z.; Meng, F.; Cui, L.; Shi, Y. Image segmentation via improving clustering algorithms with density and distance. Procedia Comput. Sci. 2015, 55, 1015–1022. [Google Scholar] [CrossRef]
- Shapiro, L.; Stockman, G.C. Computer Vision; Prentice Hall: Englewood Cliffs, NJ, USA, 2001. [Google Scholar]
- Barghout, L.; Lee, L. Perceptual Information Processing System. US Patent App. 10/618,543, 11 July 2003. [Google Scholar]
- Zhuang, H.; Low, K.S.; Yau, W.Y. Multichannel pulse-coupled-neural-network-based color image segmentation for object detection. IEEE Trans. Ind. Electron. 2012, 59, 3299–3308. [Google Scholar] [CrossRef]
- Kim, D.S.; Jeon, I.J.; Lee, S.Y.; Rhee, P.K.; Chung, D.J. Embedded face recognition based on fast genetic algorithm for intelligent digital photography. IEEE Trans. Ind. Electron. 2006, 52, 726–734. [Google Scholar]
- Kumar, V.D.; Thomas, T. Clustering of invariance improved legendre moment descriptor for content based image retrieval. In Proceedings of the 2008 International Conference on Signal Processing, Communications and Networking (ICSCN’08), Chennai, India, 4–6 January 2008; pp. 323–327. [Google Scholar]
- Pham, D.L.; Xu, C.; Prince, J.L. Current methods in medical image segmentation. Ann. Rev. Biomed. Eng. 2000, 2, 315–337. [Google Scholar] [CrossRef] [PubMed]
- Md. Abul Hasnat, O.A.; Tremeau, A. Joint Color-Spatial-Directional Clustering and Region Merging (JCSD-RM) for Unsupervised RGB-D Image Segmentation; IEEE Computer Society: Washington, DC, USA, 2016; pp. 2255–2268. [Google Scholar]
- Angelova, A.; Zhu, S. Efficient object detection and segmentation for fine-grained recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 811–818. [Google Scholar]
- Al Aghbari, Z.; Al-Haj, R. Hill-manipulation: An effective algorithm for color image segmentation. Image Vis. Comput. 2006, 24, 894–903. [Google Scholar] [CrossRef]
- Cheng, H.; Li, J. Fuzzy homogeneity and scale-space approach to color image segmentation. Pattern Recogn. 2003, 36, 1545–1562. [Google Scholar] [CrossRef]
- Boykov, Y.Y.; Jolly, M.P. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001; Volume 1, pp. 105–112. [Google Scholar]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning about Data; Springer Science & Business Media: New York, NY, USA, 2012; Volume 9. [Google Scholar]
- Dev, S.; Savoy, F.M.; Lee, Y.H.; Winkler, S. Rough-set-based color channel selection. IEEE Geosci. Remote Sens. Lett. 2017, 14, 52–56. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, H. A study of 3D model similarity based on surface bipartite graph matching. Eng. Comput. 2017, 34, 174–188. [Google Scholar] [CrossRef]
- Kandwal, R.; Kumar, A.; Bhargava, S. Existing Image Segmentation Techniques. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2014, 4, 153–156. [Google Scholar]
- Zhang, H.; Wu, Q.J.; Nguyen, T.M. Image segmentation by a robust generalized fuzzy c-means algorithm. In Proceedings of the 2013 20th IEEE International Conference on Image Processing (ICIP), Melbourne, VIC, Australia, 15–18 September 2013; pp. 4024–4028. [Google Scholar]
- Naik, D.; Shah, P. A review on image segmentation clustering algorithms. Int. J. Comput. Sci. Inform. Technol. 2014, 5, 3289–3293. [Google Scholar]
- Zhang, H.; Lu, J. Creating ensembles of classifiers via fuzzy clustering and deflection. Fuzzy Sets Syst. 2010, 161, 1790–1802. [Google Scholar] [CrossRef]
- Tan, K.S.; Lim, W.H.; Isa, N.A.M. Novel initialization scheme for Fuzzy C-Means algorithm on color image segmentation. Appl. Soft Comput. 2013, 13, 1832–1852. [Google Scholar] [CrossRef]
- Zheng, Y.; Jeon, B.; Xu, D.; Wu, Q.; Zhang, H. Image segmentation by generalized hierarchical fuzzy C-means algorithm. J. Intell. Fuzzy Syst. 2015, 28, 961–973. [Google Scholar]
- Wang, S.; Wang, D.; Li, C.; Li, Y. Comment on “Clustering by Fast Search and Find of Density Peaks”. arXiv, 2015; arXiv:1501.04267. [Google Scholar]
- Mehra, J.; Neeru, N. A brief review: Super-pixel based image segmentation methods. Imp. J. Interdiscip. Res. 2016, 2, 8–12. [Google Scholar]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An evaluation of the state-of-the-art. Comput. Vis. Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Bowman, A.W.; Azzalini, A. Applied Smoothing Techniques for Data Analysis: The Kernel Approach with S-Plus Illustrations; OUP: Oxford, UK, 1997; Volume 18. [Google Scholar]
- Yan, Y.; Shen, Y.; Li, S. Unsupervised color-texture image segmentation based on a new clustering method. In Proceedings of the 2009 International Conference on New Trends in Information and Service Science (NISS’09), Beijing, China, 30 June–2 July 2009; pp. 784–787. [Google Scholar]
- Yheng, Y.; Lin, S.; Kambhamettu, C.; Yu, J.; Kang, S.B. Single-Image Vignetting Correction. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2243–2256. [Google Scholar]
- Luo, C.; Zhang, X.; Zheng, Y. Chaotic Evolution of Prisoner’s Dilemma Game with Volunteering on Interdependent Networks. Commun. Nonlinear Sci. Numer. Simul. 2017, 47, 407–415. [Google Scholar] [CrossRef]
- Botev, Z.I.; Grotowski, J.F.; Kroese, D.P. Kernel Density Estimation Via Diffusio. Ann. Stat. 2010, 38, 2916–2957. [Google Scholar] [CrossRef]
- Sheather, S.J.; Jones, M.C. A Reliable Data-Based Bandwidth Selection Method for Kernel Density Estimation. J. R. Stat. Soc. 1991, 53, 683–690. [Google Scholar]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Computer Vision—ECCV 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Donoser, M.; Urschler, M.; Hirzer, M.; Bischof, H. Saliency driven total variation segmentation. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 817–824. [Google Scholar]
- Unnikrishnan, R.; Hebert, M. Measures of similarity. In Proceedings of the Seventh IEEE Workshops on Application of Computer Vision (WACV/MOTIONS’05), Washington, DC, USA, 5–7 January 2005; Volume 1, p. 394. [Google Scholar]
- Rand, W.M. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Unnikrishnan, R.; Pantofaru, C.; Hebert, M. Toward objective evaluation of image segmentation algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 929–944. [Google Scholar] [CrossRef] [PubMed]
- Yang, A.Y.; Wright, J.; Ma, Y.; Sastry, S.S. Unsupervised segmentation of natural images via lossy data compression. Comput. Vis. Image Underst. 2008, 110, 212–225. [Google Scholar] [CrossRef] [Green Version]
- Rohit, S. Comparitive Analysis of Image Segmentation Techniques. Int. J. Adv. Res. Comput. Eng. Technol. 2013, 2, 2615–2619. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007; pp. 1027–1035. [Google Scholar]
- Chen, S.; Zhang, D. Robust image segmentation using FCM with spatial constraints based on new kernel-induced distance measure. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2004, 34, 1907–1916. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Type | FCM-S | K-Means | Our Method |
|---|---|---|---|
| human | 0.510 | 0.674 | 0.672 |
| transport | 0.503 | 0.563 | 0.592 |
| intensity inhomogeneity | 0.608 | 0.653 | 0.651 |
| building 1 | 0.715 | 0.694 | 0.712 |
| animal | 0.816 | 0.803 | 0.837 |
| landscape | 0.704 | 0.783 | 0.818 |
| building 2 | 0.819 | 0.885 | 0.897 |
| Mean | 0.668 | 0.722 | 0.740 |
| average computation time | 5.782s | 4.237s | 5.331s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Qi, M.; Lian, J.; Jia, W.; Zou, W.; He, Y.; Liu, H.; Zheng, Y. Image Segmentation by Searching for Image Feature Density Peaks. Appl. Sci. 2018, 8, 969. https://doi.org/10.3390/app8060969
Sun Z, Qi M, Lian J, Jia W, Zou W, He Y, Liu H, Zheng Y. Image Segmentation by Searching for Image Feature Density Peaks. Applied Sciences. 2018; 8(6):969. https://doi.org/10.3390/app8060969
Chicago/Turabian StyleSun, Zhe, Meng Qi, Jian Lian, Weikuan Jia, Wei Zou, Yunlong He, Hong Liu, and Yuanjie Zheng. 2018. "Image Segmentation by Searching for Image Feature Density Peaks" Applied Sciences 8, no. 6: 969. https://doi.org/10.3390/app8060969
APA StyleSun, Z., Qi, M., Lian, J., Jia, W., Zou, W., He, Y., Liu, H., & Zheng, Y. (2018). Image Segmentation by Searching for Image Feature Density Peaks. Applied Sciences, 8(6), 969. https://doi.org/10.3390/app8060969