Comparing Deep Learning and Classical Machine Learning Approaches for Predicting Inpatient Violence Incidents from Clinical Text


Abstract
:1. Introduction
Related Work
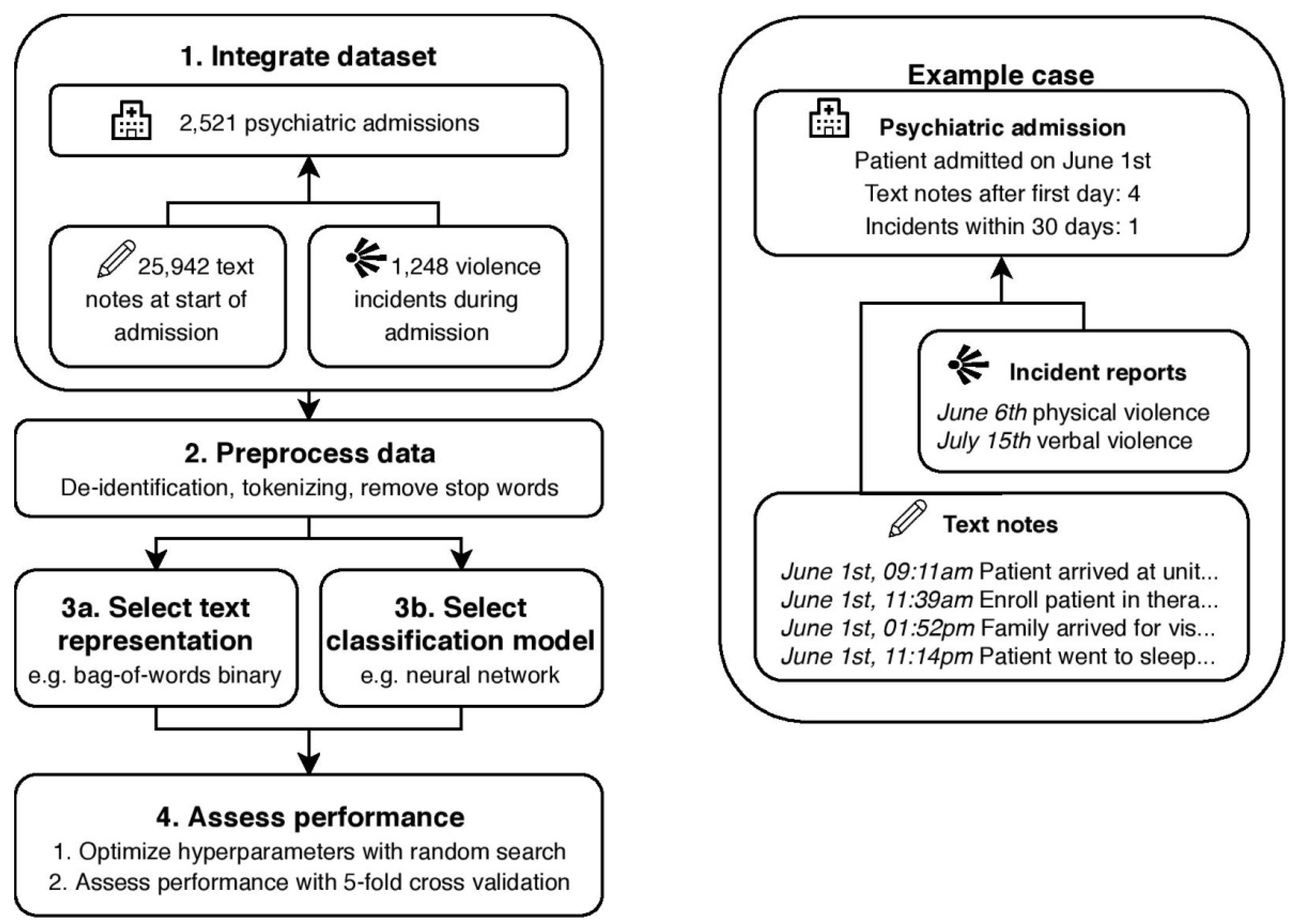
2. Materials and Methods
2.1. Prediction Objective
2.2. Text Dataset
2.3. Text Representations
2.4. Classification Models
2.5. Experiment Setup
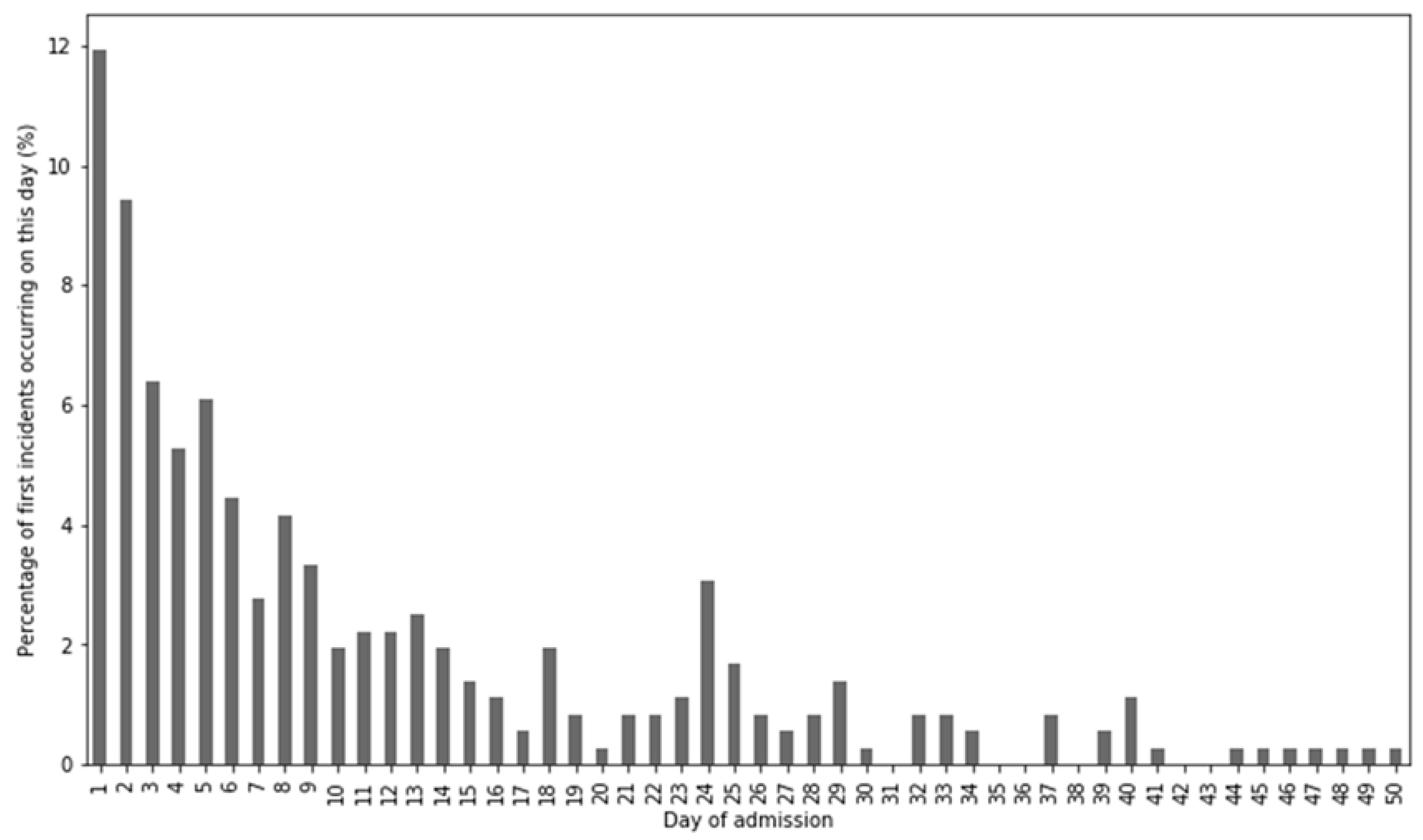
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Model | Hyperparameter | Bag-of-Words Binary | Bag-of-Words tf-idf | Word Embeddings | Document Embeddings |
|---|---|---|---|---|---|
| RNN 1 | Learning rate | 4.1 × 10−2 | 5.3 × 10−2 | 8.3 × 10−3 | 4.6 × 10−2 |
| Cell type | LSTM | LSTM | GRU | LSTM | |
| Layer size | 193 | 63 | 185 | 129 | |
| Dropout rate | 0.8 | 0.7 | 0.5 | 0.8 | |
| CNN 2 | Learning rate | 1.4 × 10−2 | 2.0 × 10−2 | 4.2 × 10−3 | 1.3 × 10−2 |
| No. filters | 41 | 69 | 45 | 49 | |
| Filter size | 3 | 3 | 3 | 4 | |
| Pooling size | 5 | 6 | 5 | 6 | |
| Dropout rate | 0.9 | 0.7 | 0.5 | 0.9 | |
| Fully connected layer size | 18 | 36 | 121 | 85 | |
| NN 3 | Learning rate | 1.5 × 10−3 | 1.2 × 10−3 | 6.4 × 10−2 | 1.1 × 10−2 |
| Layer size | 172 | 30 | 36 | 254 | |
| Regularization constant | 4.7 × 10−4 | 2.2 × 10−4 | 7.1 × 10−2 | 9.9 × 10−2 | |
| NB 4 | N/a | - | - | - | - |
| SVM 5 | C | 0.40 | 0.50 | 2.52 | 0.40 |
| Gamma | 3.1 × 10−4 | 1.7 × 10−4 | 3.6 × 10−4 | 7.9 × 10−4 | |
| Kernel | radial | radial | radial | radial | |
| DT 6 | Max depth | 2 | 3 | 2 | 4 |
| Max features | 0.52 | 0.47 | 0.56 | 0.84 | |
| Min samples split | 5 | 3 | 11 | 3 |
References
- Adler-Milstein, J.; Everson, J.; Lee, S.Y.D. EHR Adoption and Hospital Performance: Time-Related Effects. Health Serv. Res. 2015, 50, 1751–1771. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peters, T.E. Transformational Impact of Health Information Technology on the Clinical Practice of Child and Adolescent Psychiatry. Child Adolesc. Psychiatr. Clin. N. Am. 2017, 26, 55–66. [Google Scholar] [CrossRef] [PubMed]
- Menger, V.; Spruit, M.; Hagoort, K.; Scheepers, F. Transitioning to a Data Driven Mental Health Practice: Collaborative Expert Sessions for Knowledge and Hypothesis Finding. Comput. Math. Methods Med. 2016, 2016, 9089321. [Google Scholar] [CrossRef] [PubMed]
- Priyanka, K.; Kulennavar, N. A survey on big data analytics in health care. IJCSIT 2014, 5, 5865–5868. [Google Scholar]
- Bates, D.W.; Saria, S.; Ohno-Machado, L.; Shah, A.; Escobar, G. Big data in health care: Using analytics to identify and manage high-risk and high-cost patients. Health Aff. 2014, 33, 1123–1131. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.H.; Yoon, H.-J. Medical big data: Promise and challenges. Kidney Res. Clin. Pract. 2017, 36, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Murdoch, T.B.; Detsky, A.S. The Inevitable Application of Big Data to Health Care. JAMA 2013, 309, 1351–1352. [Google Scholar] [CrossRef] [PubMed]
- Whitson, J.R. Gaming the quantified self. Surveill. Soc. 2013, 11, 163–176. [Google Scholar] [CrossRef]
- Chapman, W.W.; Nadkarni, P.M.; Hirschman, L.; D’Avolio, L.W.; Savova, G.K.; Uzuner, O. Overcoming barriers to NLP for clinical text: The role of shared tasks and the need for additional creative solutions. J. Am. Med. Inform. Assoc. 2011, 18, 540–543. [Google Scholar] [CrossRef] [PubMed]
- Ford, E.; Stockdale, J.; Jackson, R.; Cassell, J. For the greater good? Patient and public attitudes to use of medical free text data in research. Int. J. Popul. Data Sci. 2017, 1. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.-Y.; Lee, P.H.; Castro, V.M.; Minnier, J.; Charney, A.W.; Stahl, E.A.; Ruderfer, D.M.; Murphy, S.N.; Gainer, V.; Cai, T.; et al. Genetic validation of bipolar disorder identified by automated phenotyping using electronic health records. Transl. Psychiatry 2018, 8, 86. [Google Scholar] [CrossRef] [PubMed]
- Garla, V.; Taylor, C.; Brandt, C. Semi-supervised clinical text classification with Laplacian SVMs: An application to cancer case management. J. Biomed. Inform. 2013, 46, 869–875. [Google Scholar] [CrossRef] [PubMed]
- Pestian, J.P.; Brew, C.; Matykiewicz, P.; Hovermale, D.J.; Johnson, N.; Cohen, K.B.; Duch, W. A shared task involving multi-label classification of clinical free text. In Proceedings of the Workshop on BioNLP 2007: Biological, Translational, and Clinical Language Processing, Prague, Czech Republic, 29 June 2007; pp. 97–104. [Google Scholar] [CrossRef]
- Sarker, A.; Gonzalez, G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J. Biomed. Inform. 2015, 53, 196–207. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Corrado, G.; Chen, K.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. arXiv, 2014; arXiv:1405.4053. [Google Scholar]
- Goldberg, Y. A primer on neural network models for natural language processing. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Suresh, H.; Hunt, N.; Johnson, A.; Celi, L.A.; Szolovits, P.; Ghassemi, M. Clinical Intervention Prediction and Understanding using Deep Networks. arXiv, 2017; arXiv:1705.08498. [Google Scholar]
- Miotto, R.; Li, L.; Kidd, B.A.; Dudley, J.T. Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records. Sci. Rep. 2016, 6, 26094. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lv, X.; Guan, Y.; Yang, J.; Wu, J. Clinical Relation Extraction with Deep Learning. Int. J. Hybrid Inf. Technol. 2016, 9, 237–248. [Google Scholar] [CrossRef]
- Wu, Y.; Jiang, M.; Lei, J.; Xu, H. Named Entity Recognition in Chinese Clinical Text Using Deep Neural Network. Stud. Health Technol. Inform. 2015, 216, 624–628. [Google Scholar] [PubMed]
- Ekbal, A.; Saha, S.; Bhattacharyya, P. Deep Learning Architecture for Patient Data De-identification in Clinical Records. In Proceedings of the Clinical Natural Language Processing Workshop, Osaka, Japan, 11–17 December 2016; pp. 32–41. [Google Scholar]
- Shickel, B.; Tighe, P.J.; Bihorac, A.; Rashidi, P. Deep EHR: A Survey of Recent Advances in Deep Learning Techniques for Electronic Health Record (EHR) Analysis. IEEE J. Biomed. Health Inform. 2017, 1. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA J. Am. Med. Assoc. 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Lipton, Z.C.; Kale, D.C.; Elkan, C.; Wetzel, R. Learning to Diagnose with LSTM Recurrent Neural Networks. arXiv, 2015; arXiv:1511.03677. [Google Scholar]
- Hammerla, N.Y.; Halloran, S.; Ploetz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition using Wearables. arXiv, 2016; arXiv:1604.08880. [Google Scholar]
- Jacobson, O.; Dalianis, H. Applying deep learning on electronic health records in Swedish to predict healthcare-associated infections. In Proceedings of the 15th Workshop on Biomedical Natural Language Processing, Berlin, Germany, 12 August 2016; pp. 191–195. [Google Scholar]
- Li, H.; Li, X.; Ramanathan, M.; Zhang, A. Identifying informative risk factors and predicting bone disease progression via deep belief networks. Methods 2014, 69, 257–265. [Google Scholar] [CrossRef] [PubMed]
- Liang, Z.; Zhang, G.; Huang, J.X.; Hu, Q.V. Deep learning for healthcare decision making with EMRs. In Proceedings of the 2014 IEEE International Conference on Bioinformatics and Biomedicine, Belfast, UK, 2–5 November 2014; pp. 556–559. [Google Scholar]
- Nickerson, P.; Tighe, P.; Shickel, B.; Rashidi, P. Deep neural network architectures for forecasting analgesic response. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, Orlando, FL, USA, 16–20 August 2016; pp. 2966–2969. [Google Scholar]
- Iozzino, L.; Ferrari, C.; Large, M.; Nielssen, O.; De Girolamo, G. Prevalence and risk factors of violence by psychiatric acute inpatients: A systematic review and meta-analysis. PLoS ONE 2015, 10, e0128536. [Google Scholar] [CrossRef] [PubMed]
- Amore, M.; Menchetti, M.; Tonti, C.; Scarlatti, F.; Lundgren, E.; Esposito, W.; Berardi, D. Predictors of violent behavior among acute psychiatric patients: Clinical study. Psychiatry Clin. Neurosci. 2008, 62, 247–255. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McDermott, B.E.; Edens, J.F.; Quanbeck, C.D.; Busse, D.; Scott, C.L. Examining the role of static and dynamic risk factors in the prediction of inpatient violence: Variable- and person-focused analyses. Law Hum. Behav. 2008, 32, 325–338. [Google Scholar] [CrossRef] [PubMed]
- Papadopoulos, C.; Ross, J.; Stewart, D.; Dack, C.; James, K.; Bowers, L. The antecedents of violence and aggression within psychiatric in-patient settings. Acta Psychiatr. Scand. 2012, 125, 425–439. [Google Scholar] [CrossRef] [PubMed]
- Pfeffer, C.R.; Solomon, G.; Plutchik, R.; Mizruchi, M.S.; Weiner, A. Variables that Predict Assaultiveness in Child Psychiatric Inpatients. J. Am. Acad. Child Psychiatry 1985, 24, 775–780. [Google Scholar] [CrossRef]
- Reynolds, G.P.; McKelvey, J.S.; Reinharth, J.; Payne, E.B.; Tropper, A.; Selig, P.; Malhotra, A.; Russ, M.; Serper, M.R. Predictors of persistent aggression on the psychiatric inpatient service. Compr. Psychiatry 2013, 54, e34. [Google Scholar] [CrossRef]
- Dack, C.; Ross, J.; Papadopoulos, C.; Stewart, D.; Bowers, L. A review and meta-analysis of the patient factors associated with psychiatric in-patient aggression. Acta Psychiatr. Scand. 2013, 127, 255–268. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Steinert, T. Prediction of inpatient violence. Acta Psychiatr. Scand. 2002, 106, 133–141. [Google Scholar] [CrossRef]
- Ægisdóttir, S.; White, M.J.; Spengler, P.M.; Maugherman, A.S.; Anderson, L.A.; Cook, R.S.; Nichols, C.N.; Lampropoulos, G.K.; Walker, B.S.; Cohen, G.; et al. The Meta-Analysis of Clinical Judgment Project: Fifty-Six Years of Accumulated Research on Clinical Versus Statistical Prediction. Couns. Psychol. 2006, 34, 341–382. [Google Scholar] [CrossRef]
- Teo, A.R.; Holley, S.R.; Leary, M.; McNiel, D.E. The Relationship Between Level of Training and Accuracy of Violence Risk Assessment. Psychiatr. Serv. 2012, 63, 1089–1094. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Higgins, N.; Watts, D.; Bindman, J.; Slade, M.; Thornicroft, G. Assessing violence risk in general adult psychiatry. Psychiatr. Bull. 2005, 29, 131–133. [Google Scholar] [CrossRef] [Green Version]
- Quinsey, V.; Harris, G.; Rice, M.E.; Cormier, C. Violent Offenders: Appraising and Managing Risk; APA Books: Washington, DC, USA, 1998; ISBN 9781433805226. [Google Scholar]
- Borum, R.; Bartel, P.A.; Forth, A.E. Structured Assessment of Violence Risk in Youth; PAR: Lutz, FL, USA, 2005. [Google Scholar]
- Webster, C.D.; Douglas, K.S.; Eaves, D.; Hart, S.D. HCR-20: Assessing Risk of Violence, Version 2; Mental Health, Law and Policy Institute: Burnaby, BC, Canada, 1997. [Google Scholar]
- Fazel, S.; Singh, J.P.; Doll, H.; Grann, M. Use of risk assessment instruments to predict violence and antisocial behaviour in 73 samples involving 24,827 people: Systematic review and meta-analysis. BMJ 2012, 345, e4692. [Google Scholar] [CrossRef] [PubMed]
- Singh, J.P.; Grann, M.; Fazel, S. A comparative study of violence risk assessment tools: A systematic review and metaregression analysis of 68 studies involving 25,980 participants. Clin. Psychol. Rev. 2011, 31, 499–513. [Google Scholar] [CrossRef] [PubMed]
- Yang, M.; Wong, S.C.P.; Coid, J. The efficacy of violence prediction: A meta-analytic comparison of nine risk assessment tools. Psychol. Bull. 2010, 136, 740–767. [Google Scholar] [CrossRef] [PubMed]
- Campbell, M.A.; French, S.; Gendreau, P. The prediction of violence in adult offenders: A meta-analytic comparison of instruments and methods of assessment. Crim. Justice Behav. 2009, 36, 567–590. [Google Scholar] [CrossRef]
- Maden, A. Standardized risk assessment: Why all the fuss? Psychiatr. Bull. 2003, 27, 201–204. [Google Scholar] [CrossRef]
- Viljoen, J.L.; McLachlan, K.; Vincent, G.M. Assessing violence risk and psychopathy in juvenile and adult offenders: A survey of clinical practices. Assessment 2010, 17, 377–395. [Google Scholar] [CrossRef] [PubMed]
- Ozomaro, U.; Wahlestedt, C.; Nemeroff, C.B. Personalized medicine in psychiatry: Problems and promises. BMC Med. 2013, 11, 132. [Google Scholar] [CrossRef] [PubMed]
- Menger, V.; Scheepers, F.; van Wijk, L.M.; Spruit, M. DEDUCE: A pattern matching method for automatic de-identification of Dutch medical text. Telemat. Inform. 2017. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python; O’Reilly Media, Inc.: Newton, MA, USA, 2009. [Google Scholar]
- Lan, M.; Tan, C.-L.; Low, H.-B.; Sung, S.-Y. A comprehensive comparative study on term weighting schemes for text categorization with support vector machines. In Proceedings of the Special Interest Tracks and Posters of the 14th International Conference on World Wide Web—WWW’05, Chiba, Japan, 10–14 May 2005; ACM Press: New York, NY, USA, 2005; p. 1032. [Google Scholar] [Green Version]
- Fürnkranz, J. A Study Using N-Gram Features for Text Categorization; Austrian Research Institute for Artificial Intelligence: Vienna, Austria, 1998. [Google Scholar]
- Dalal, M.K.; Zaveri, M.A. Automatic Text Classification: A. Technical Review. Int. J. Comput. Appl. 2011, 28, 37–40. [Google Scholar] [CrossRef]
- Li, T.; Zhang, C.; Ogihara, M. A comparative study of feature selection and multiclass classification methods for tissue classification based on gene expression. Bioinformatics 2004, 20, 2429–2437. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chiu, B.; Crichton, G.; Korhonen, A.; Pyysalo, S. How to Train good Word Embeddings for Biomedical NLP. In Proceedings of the 15th Workshop on Biomedical Natural Language Processing, Berlin, Germany, 12 August 2016; pp. 166–174. [Google Scholar]
- Aggarwal, C.C.; Zhai, C.X. Mining Text Data; Springer: Boston, MA, USA, 2013; ISBN 9781461432234. [Google Scholar]
- Korde, V. Text Classification and Classifiers: A Survey. Int. J. Artif. Intell. Appl. 2012, 3, 85–99. [Google Scholar] [CrossRef]
- Rajan, K.; Ramalingam, V.; Ganesan, M.; Palanivel, S.; Palaniappan, B. Automatic classification of Tamil documents using vector space model and artificial neural network. Expert Syst. Appl. 2009, 36, 10914–10918. [Google Scholar] [CrossRef]
- Deshpande, V.P.; Erbacher, R.F.; Harris, C. An evaluation of Naïve Bayesian anti-spam filtering techniques. In Proceedings of the 2007 IEEE Workshop on Information Assurance, IAW, West Point, NY, USA, 20–22 June 2007; pp. 333–340. [Google Scholar]
- Alsaleem, S. Automated Arabic Text Categorization Using SVM and NB. Int. Arab J. Technol. 2011, 2, 124–128. [Google Scholar]
- Sun, A.; Lim, E.P.; Liu, Y. On strategies for imbalanced text classification using SVM: A comparative study. Decis. Support Syst. 2009, 48, 191–201. [Google Scholar] [CrossRef]
- Uǧuz, H. A two-stage feature selection method for text categorization by using information gain, principal component analysis and genetic algorithm. Knowl. Based Syst. 2011, 24, 1024–1032. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, M.; Wang, X.; Chen, Q.; Tang, B.; Wang, Z.; Xu, H. Entity recognition from clinical texts via recurrent neural network. BMC Med. Inform. Decis. Mak. 2017, 17. [Google Scholar] [CrossRef] [PubMed]
- Tang, D.; Qin, B.; Liu, T. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Hughes, M.; Li, I.; Kotoulas, S.; Suzumura, T. Medical Text Classification Using Convolutional Neural Networks. Stud. Health Technol. Inform. 2017, 235, 246–250. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level Convolutional Networks for Text Classification. arXiv, 2015; arXiv:1509.01626. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. arXiv, 2012; arXiv:1206.5533. [Google Scholar]


| Unit | Population | Type of Unit | Type of Admission | No. Admissions | Violent Admissions (%) |
|---|---|---|---|---|---|
| 1 | Adult | Closed | Planned | 307 | 3.6 |
| 2 | Adult | Closed | Acute | 1047 | 7.5 |
| 3 | Child, adolescent | Closed | Acute | 415 | 13.7 |
| 4 | Adolescent, adult | Closed | Planned | 428 | 14.3 |
| 5 | Child | Closed | Planned | 139 | 34.5 |
| 6 | Child | Day treatment | Planned | 185 | 17.3 |
| Representation | Parameter | Value |
|---|---|---|
| Bag of words | Weighting | binary, tf-idf |
| N-gram range | 1–3 | |
| No. features | 1000 | |
| Text embeddings | Level | word, document |
| Model size | 320 | |
| Min frequency | 50 | |
| Epochs | 20 |
| Model | Hyperparameter | Range |
|---|---|---|
| Recurrent Neural Network | Learning rate | 10−5–10−1 |
| Cell type Layer size Dropout rate | GRU, LSTM 24–28 0.5–0.9 | |
| Convolutional Neural Network | Learning rate No. filters Filter size Pooling size Dropout rate Fully connected layer size | 10−5–10−1 24–28 3–7 2–7 0.5–0.9 24–28 |
| Neural Network | Learning rate | 10−5–10−1 |
| Layer size | 24–28 | |
| Regularization constant | 10−5–10−1 | |
| Naive Bayes | N/a | - |
| Support Vector Machine | Gamma | 10−5–10−1 |
| C | 10−5–10−1 | |
| Kernel | linear, radial | |
| Decision Tree | Max depth | 21–24 |
| Max features | 0.25–0.75 | |
| Min samples split | 21–24 |
| Model | Bag-of-Words Binary | Bag-of-Words tf-idf | Word Embeddings | Document Embeddings |
|---|---|---|---|---|
| RNN 1 | 0.771 ± 0.018 b | 0.753 ± 0.031 | 0.654 ± 0.043 | 0.788 ± 0.018 a,b |
| CNN 2 | 0.729 ± 0.030 | 0.716 ± 0.038 | 0.684 ± 0.038 | 0.763 ± 0.024 a |
| NN 3 | 0.727 ± 0.033 | 0.717 ± 0.038 | 0.751 ± 0.036 a | 0.745 ± 0.022 |
| NB 4 | 0.686 ± 0.026 | 0.704 ± 0.034 a | 0.700 ± 0.051 | 0.692 ± 0.046 |
| SVM 5 | 0.759 ± 0.040 | 0.756 ± 0.036 b | 0.764 ± 0.024 b | 0.770 ± 0.029 a |
| DT 6 | 0.727 ± 0.018 a | 0.719 ± 0.041 | 0.685 ± 0.041 | 0.665 ± 0.035 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Menger, V.; Scheepers, F.; Spruit, M. Comparing Deep Learning and Classical Machine Learning Approaches for Predicting Inpatient Violence Incidents from Clinical Text. Appl. Sci. 2018, 8, 981. https://doi.org/10.3390/app8060981
Menger V, Scheepers F, Spruit M. Comparing Deep Learning and Classical Machine Learning Approaches for Predicting Inpatient Violence Incidents from Clinical Text. Applied Sciences. 2018; 8(6):981. https://doi.org/10.3390/app8060981
Chicago/Turabian StyleMenger, Vincent, Floor Scheepers, and Marco Spruit. 2018. "Comparing Deep Learning and Classical Machine Learning Approaches for Predicting Inpatient Violence Incidents from Clinical Text" Applied Sciences 8, no. 6: 981. https://doi.org/10.3390/app8060981
APA StyleMenger, V., Scheepers, F., & Spruit, M. (2018). Comparing Deep Learning and Classical Machine Learning Approaches for Predicting Inpatient Violence Incidents from Clinical Text. Applied Sciences, 8(6), 981. https://doi.org/10.3390/app8060981