TF-YOLO: An Improved Incremental Network for Real-Time Object Detection


Abstract
:1. Introduction
2. Related Work
2.1. Preliminaries on YOLO
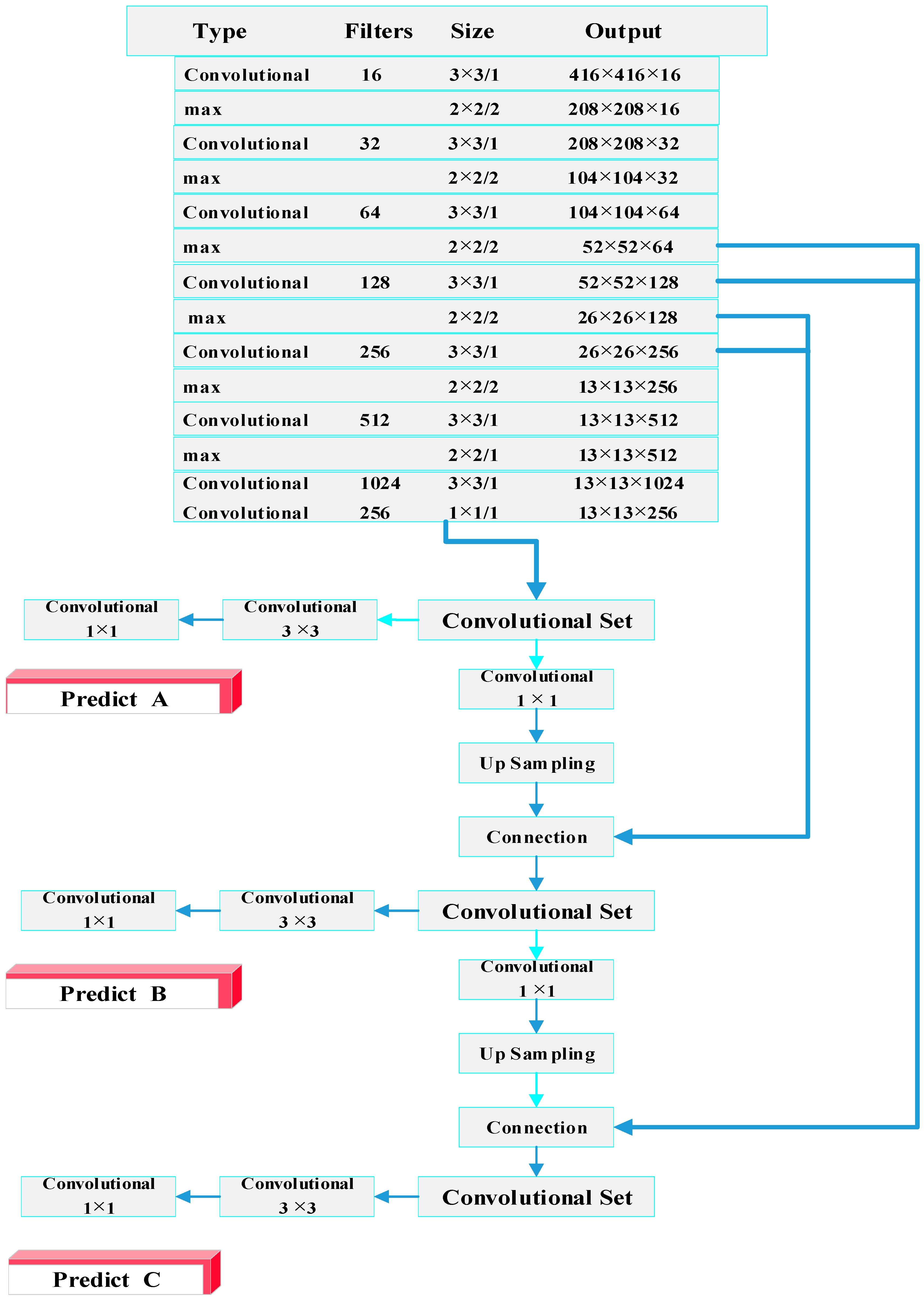
2.2. The Network of Darknet19
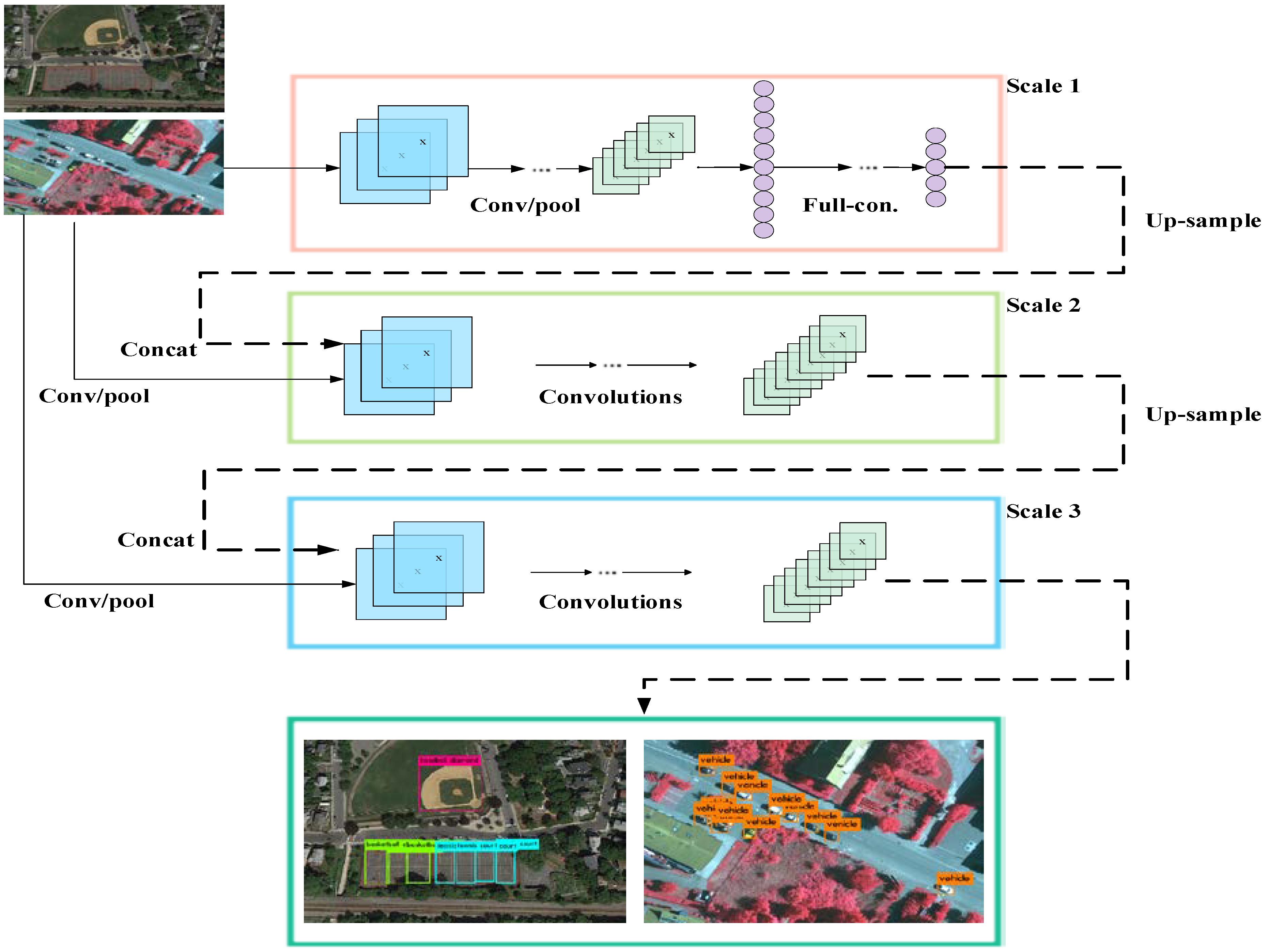
2.3. Multi-Scale Prediction in Detecting Objects
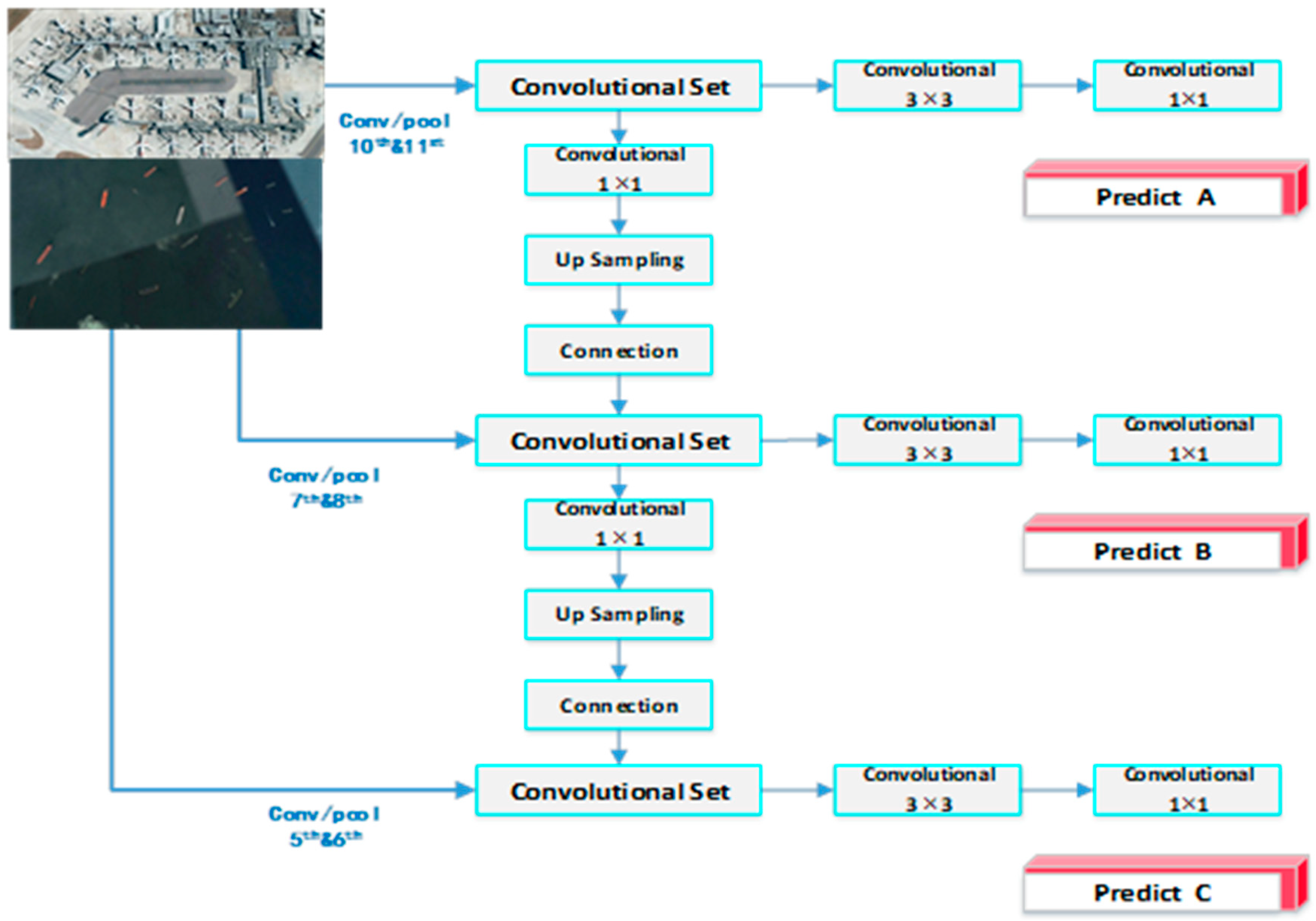
3. Proposed TF-YOLO Network
3.1. The Features of Multiple Layers Concatenation
3.2. Multi-Scale Prediction Framework
3.3. K-means++ Clustering in Pre-Processing
- Step 1: Choose an initial center uniformly at random from the dataset .
- Step 2: Choose the next center , selecting with probability , where D(x) is the distance from a data point to the closest center.
- Step 3: Repeat Step 2, until is the shortest distance. After which, center is chosen.
- Step 4: Define center .
- Step 5: For , set the cluster to be the set of points in that are closer to than they are to for all .
- Step 6: For , set to be the center of mass of all points in : .
- Step 7: Repeat Step 5 and Step 6 until converges.
4. Experimental Verification and Result Analysis
4.1. Comparison of Speed and Precision
4.2. Comparison of Loss Curves
4.3. Comparison of IOU Curve
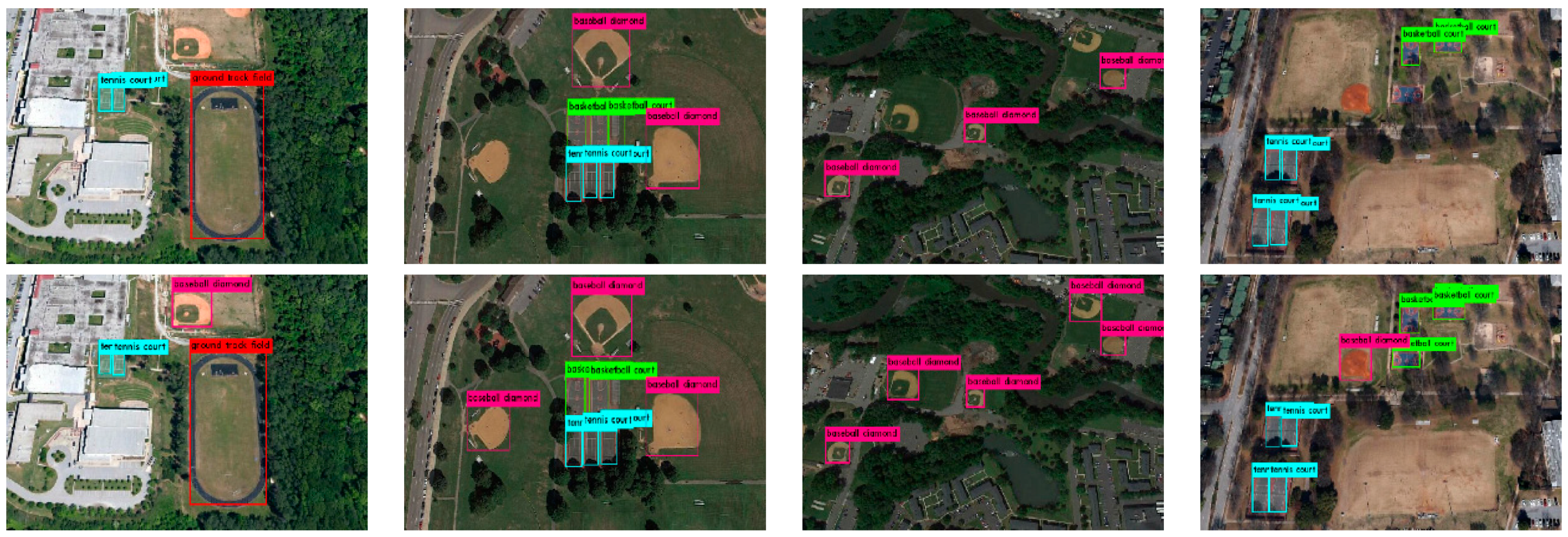
4.4. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Jiang, H.; Wang, J.; Yuan, Z.; Wu, Y.; Zheng, N.; Li, S. Salient object detection: A discriminative regional feature integration approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2083–2090. [Google Scholar]
- Tang, C.; Ling, Y.; Yang, X.; Jin, W.; Zheng, C. Muti-view object detection based on deep learning. Appl. Sci. 2018, 8, 1423. [Google Scholar] [CrossRef]
- Jeong, Y.N.; Son, S.R.; Jeong, E.H.; Lee, B.K. An Integrated Self-Diagnosis System for an Autonomous Vehicle Based on an IoT Gateway and Deep Learning. Appl. Sci. 2018, 7, 1164. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 346–361. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vison, Boston, MA, USA, 8–10 June2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the International Conference on Neural Information Processing Systems, Barcelona, Spain, 9 December 2016; pp. 379–387. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Perazzi, F.; Krahenbuhl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Hu, F.; Zhu, Z.; Mejia, J.; Tang, H.; Zhang, J. Real-time indoor assistive localization with mobile omnidirectional vision and cloud GPU acceleration. AIMS Electron. Electr. Eng. 2017, 1, 74–99. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, OR, Florida, FL, USA, 37 November 2014; pp. 675–678. [Google Scholar]
- Hao, Q.; Zhang, L.; Wu, X.; He, X.; Hu, X.; Wen, X. Multiscale Object Detection in Infrared Streetscape Images Based on Deep Learning and Instance Level Data Augmentation. Appl. Sci. 2019, 9, 565. [Google Scholar] [Green Version]
- Zhang, X.; Jiang, Z.; Zhang, H.; Wei, Q. Vision-based pose estimation for textureless space objects by contour points matching. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 2342–2355. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Chang, C.; Siagian, C.; Itti, L. Mobile robot vision navigation & localization using Gist and Saliency. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 4147–4154. [Google Scholar]
- Zhang, J.; Sclaroff, S.; Lin, Z.; Shen, X.; Price, B.; Mech, R. Minimum barrier salient object detection at 80 FPS. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1404–1412. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. arXiv 2016, arXiv:1612.08242. Available online: https://arxiv.org/abs/1612.08242 (accessed on 23 July 2018).
- Shafiee, M.J.; Chywl, B.; Li, F. Fast YOLO: A fast you only look once system for real-time embedded object detection In video. arXiv 2017, arXiv:1709.05943. [Google Scholar] [CrossRef]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Mousavian, A.; Kosecka, J. Deep convolutional features for image based retrieval and scene categorization. arXiv 2015, arXiv:1509.06033. [Google Scholar]
- Wan, J.; Wang, D.; Hoi, S.C.H.; Wu, P.; Zhu, J.; Zhang, Y.; Li, J. Deep Learning for Content-Based Image Retrieval: A Comprehensive Study. In Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 157–166. [Google Scholar]
- Mao, H.; Yao, S.; Tang, T. Towards real-time object detection on embedded systems. IEEE Trans. Emerg. Top. Comput. 2018, 6, 417–431. [Google Scholar] [CrossRef]
- Wu, J.; Xue, T.; Lim, J.J.; Tian, Y.; Tenenbaum, J.B.; Torralba, A.; Freeman, W.T. 3D Interpreter networks for viewer-centered wireframe modeling. Int. J. Comput. Vis. 2018, 126, 1009–1026. [Google Scholar] [CrossRef]
- Chen, J.; Luo, X.; Liu, Y.; Wang, J.; Ma, Y. Selective Learning Confusion Class for Text-Based CAPTCHA Recognition. IEEE Access 2019, 7, 22246–22259. [Google Scholar] [CrossRef]
- Xiang, Y.; Kim, W.; Chen, W.; Ji, J.; Choy, C.; Su, H.; Savarese, S. ObjectNet3D: A large-scale database for 3D object recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 160–176. [Google Scholar]
- Huang, G.; Liu, Z.; Van, D. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HL, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yu, X.; Zhou, F.; Chandraker, M. Deep deformation network for object landmark localization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 52–70. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ye, G.; Tang, Z.; Fang, D.; Zhu, Z.; Feng, Y.; Xu, P.; Chen, X.; Wang, Z. Yet Another Text Captcha Solver: A Generative Adversarial Network Based Approach. In Proceedings of the ACM Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018. [Google Scholar]
- Piras, L.; Giacinto, G. Information fusion in content based image retrieval: A comprehensive overview. Inf. Fusion. 2017, 37, 50–60. [Google Scholar] [CrossRef]
- Frintrop, S.; Klodt, M.; Rome, E. A real-time visual attention system using integral images. In Proceedings of the 5th International Conference on Computer Vision Systems, Bielefeld, Germany, 21–24 March 2007; pp. 1–10. [Google Scholar]
- Zhou, X.; Zhu, M.; Leonardos, S.; Daniilidis, K. Sparse representation for 3D shape estimation: A convex relaxation approach. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1648–1661. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Zhang, L. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. IEEE Trans. Image Process. 2010, 19, 185–198. [Google Scholar] [PubMed]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1470–1477. [Google Scholar]
- Liu, D.; Hua, G.; Viola, P.; Chen, T. Integrated feature selection and higher-order spatial feature extraction for object categorization. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Filters | Size/Stride | Input | Output |
|---|---|---|---|---|---|
| 0 | Convolutional | 16 | 3 × 3/1 | 416 × 416 × 3 | 416 × 416 × 16 |
| 1 | Maxpool | 2 × 2/2 | 416 × 416 × 16 | 208 × 208 × 16 | |
| 2 | Convolutional | 32 | 3 × 3/1 | 208 × 208 × 16 | 208 × 208 × 32 |
| 3 | Maxpool | 2 × 2/2 | 208 × 208 × 32 | 104 × 104 × 32 | |
| 4 | Convolutional | 64 | 3 × 3/1 | 104 × 104 × 32 | 104 × 104 × 64 |
| 5 | Maxpool | 2 × 2/2 | 104 × 104 × 64 | 52 × 52 × 64 | |
| 6 | Convolutional | 128 | 3 × 3/1 | 52 × 52 × 64 | 52 × 52 × 128 |
| 7 | Maxpool | 2 × 2/2 | 52 × 52 × 128 | 26 × 26 × 128 | |
| 8 | Convolutional | 256 | 3 × 3/1 | 26 × 26 × 128 | 26 × 26 × 256 |
| 9 | Maxpool | 2 × 2/2 | 26 × 26 × 256 | 13 × 13 × 256 | |
| 10 | Convolutional | 512 | 3 × 3/1 | 13 × 13 × 256 | 13 × 13 × 512 |
| 11 | Maxpool | 2 × 2/1 | 13 × 13 × 512 | 13 × 13 × 512 | |
| 12 | Convolutional | 1024 | 3 × 3/1 | 13 × 13 × 512 | 13 × 13 × 1024 |
| 13 | Convolutional | 256 | 1 × 1/1 | 13 × 13 × 1024 | 13 × 13 × 256 |
| 14 | Convolutional | 512 | 3 × 3/1 | 13 × 13 × 256 | 13 × 13 × 512 |
| 15 | Convolutional | 255 | 1 × 1/1 | 13 × 13 × 512 | 13 × 13 × 255 |
| 16 | YOLO | ||||
| 17 | Route 13 | ||||
| 18 | Convolutional | 128 | 1 × 1/1 | 13 × 13 × 256 | 13 × 13 × 128 |
| 19 | Up-sampling | 2 × 2/1 | 13 × 13 × 128 | 26 × 26 × 128 | |
| 20 | Route 19 8 | ||||
| 21 | Convolutional | 256 | 3 × 3/1 | 13 × 13 × 384 | 13 × 13 × 256 |
| 22 | Convolutional | 255 | 1 × 1/1 | 13 × 13 × 256 | 13 × 13 × 256 |
| 23 | YOLO |
| Precision | Classes | YOLOv3-tiny | YOLO_k | TF-YOLO |
|---|---|---|---|---|
| AP(%) | airplane | 0.81806 | 0.81926 | 0.85771 |
| ship | 0.89595 | 0.92718 | 0.99084 | |
| storage tank | 0.74237 | 0.76223 | 0.77361 | |
| baseball diamond | 0.73624 | 0.82734 | 0.84513 | |
| tennis court | 0.88762 | 0.89091 | 0.89542 | |
| basketball court | 0.91849 | 0.93965 | 0.95219 | |
| ground track field | 1.0 | 1.0 | 1.0 | |
| harbor | 0.92718 | 0.94183 | 1.0 | |
| bridge | 0.75806 | 0.79562 | 0.81266 | |
| vehicle | 0.68493 | 0.73731 | 0.81731 | |
| mAP(%) | 0.83689 | 0.86413 | 0.89449 |
| Method | mAP (%) | AP (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Aero | Bird | Boat | Car | Chair | Dog | Person | Plant | Sheep | Cow | ||
| SPP-net | 30.3 | 42.7 | 33.9 | 27.5 | 24.8 | 25.3 | 11.2 | 34.2 | 15.1 | 41.6 | 43.7 |
| RCNN | 36.2 | 44.9. | 38.2 | 23.4 | 38.6 | 29.3 | 15.2 | 37.6 | 19.7 | 46.5 | 68.6 |
| Faster RCNN | 67.9 | 74.0 | 58.7 | 66.3 | 72.5 | 45.7 | 69.5 | 73.6 | 56.7 | 86.4 | 75.7 |
| YOLOv3 | 55.9 | 68.5 | 41.2 | 50.4 | 80.3 | 57.9 | 68.5 | 36.7 | 32.6 | 51.6 | 71.4 |
| YOLOv3-tiny | 27.2 | 39.9 | 20.5 | 12.9 | 33.6 | 18.7 | 11.4 | 23.4 | 15.3 | 41.7 | 54.7 |
| TF-YOLO | 31.5 | 42.6 | 35.4 | 19.7 | 35.4 | 22.1 | 12.7 | 29.7 | 15.7 | 42.1 | 59.2 |
| Method | SPP-net | RCNN | Faster RCNN | YOLOv3 | YOLOv3-tiny | TF-YOLO |
|---|---|---|---|---|---|---|
| mAP (%) | 30.3 | 36.2 | 67.9 | 55.9 | 27.2 | 31.5 |
| Run time (sec/img) | 0.38 | 0.82 | 0.26 | 0.13 | 0.10 | 0.09 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, W.; Huang, Z.; Wei, Z.; Li, C.; Guo, B. TF-YOLO: An Improved Incremental Network for Real-Time Object Detection. Appl. Sci. 2019, 9, 3225. https://doi.org/10.3390/app9163225
He W, Huang Z, Wei Z, Li C, Guo B. TF-YOLO: An Improved Incremental Network for Real-Time Object Detection. Applied Sciences. 2019; 9(16):3225. https://doi.org/10.3390/app9163225
Chicago/Turabian StyleHe, Wangpeng, Zhe Huang, Zhifei Wei, Cheng Li, and Baolong Guo. 2019. "TF-YOLO: An Improved Incremental Network for Real-Time Object Detection" Applied Sciences 9, no. 16: 3225. https://doi.org/10.3390/app9163225
APA StyleHe, W., Huang, Z., Wei, Z., Li, C., & Guo, B. (2019). TF-YOLO: An Improved Incremental Network for Real-Time Object Detection. Applied Sciences, 9(16), 3225. https://doi.org/10.3390/app9163225