4.1. Overview
GeneDiff is a novel binary-oriented clone detection approach based on semantic similarity for cross-architectures.
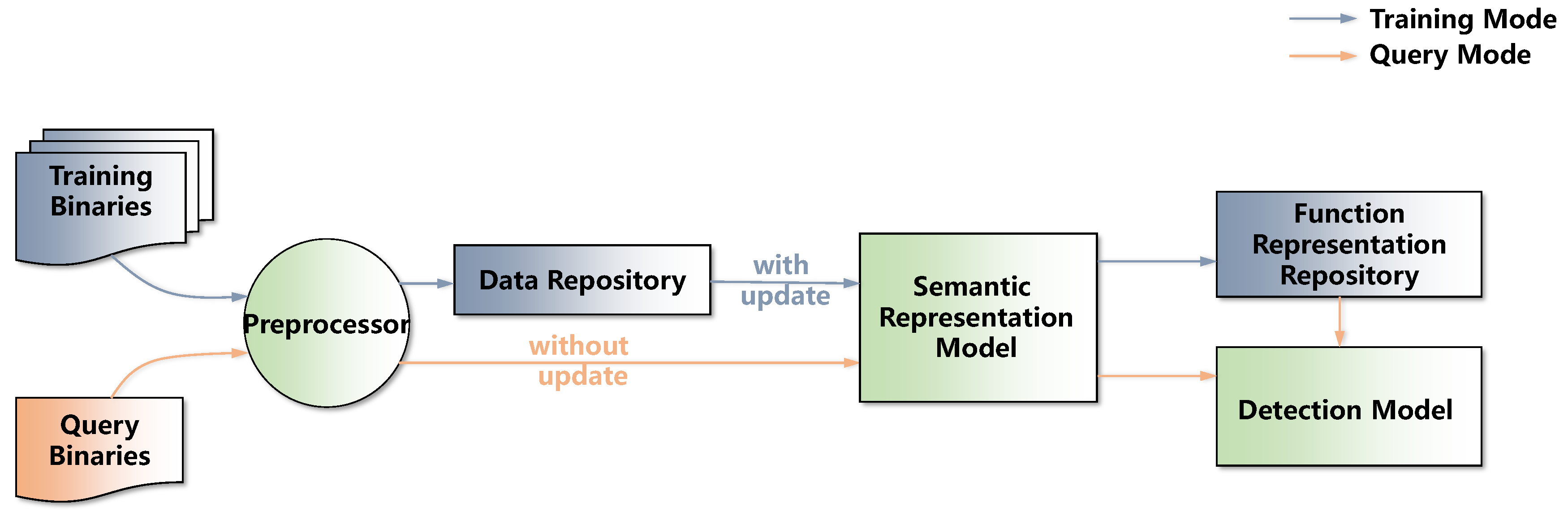
Figure 1 provides a flowchart. GeneDiff includes two operating modes: a training mode and a query mode. In
Figure 1, the grey line indicates the flow of the training mode, which is utilized to generate the function representation repository, while the orange line indicates the flow of the query mode, which is used to detect the target binaries. GeneDiff’s architecture is shown in
Figure 2. GeneDiff has three components: a preprocessor, a semantic representation model and a detection model.
In GeneDiff’s preprocessor, GeneDiff uses a binary extractor to extract data from binaries, including architecture types, compilers, call graphs (callers and callees), function information, basic blocks and assembly code. Then, the assembly code is converted into a VEX intermediate representation by a PyVEX translator at the function level. To address the out-of-vocabulary (OOV) issue, GeneDiff also abstracts some low-frequency (possibly single-occurrence) words in the preprocessor.
In GeneDiff, the semantic representation model is used to build a representation learning model for intermediate representation functions. Before training, GeneDiff used a callee expansion to expand the CFG of functions, and utilized a multi-path generation to generate multiple paths as training sequences. In the training mode, the semantic representation model utilizes the provided training data to update the values of the word matrix without prior knowledge. For each function, the model generates a semantic-based high-dimensional vector representation that is stored in the function representation repository. In the query mode, the model does not update the word matrix; instead, it uses the word matrix constructed by the training model to generate a high-dimensional representation of each function in the target binaries.
After generating vector representations of the target functions, the detection model compares them with the vectors in the function representation repository by using cosine similarity and outputs the top-k results.
4.2. Intermediate Representation
Intermediate representation (IR) is a type of abstract code designed to provide an unambiguous representation of the binary. IR can convert binaries from different ISAs into the same abstract representation, which makes it easier to analyze cross-architecture binary code. Our work uses PyVEX [
27] as an intermediate representation.
PyVEX exposes the VEX module from Valgrind [
25], which provides a series of python application programming interface (API) interfaces. It is a side-effect-free representation of different ISAs (such as MIPS, ARM, and AMD). To solve the problem of the differences between different architectures, VEX possesses the following features:
Consistent registers. Although the quantity and names of registers vary according to the architecture, each type of architecture contains several general-purpose registers. VEX provides a consistent abstraction interface with memory integer offset for the registers of different architectures.
Memory operation. Different architectures also access memory differently. Some architectures support memory segmentation using special segment registers. VEX abstracts these differences as well.
Side-effects representation. Many instructions have side effects. For example, on the AMD64 architecture, an add instruction may update the condition flags (OF or CF). For instruction side effects, VEX updates only certain operations, such as the stack pointer. Other side effects, such as condition flags are not tracked.
VEX possesses four main abstract object classes: (i)
expressions represent a calculated or constant value, (ii)
operations describe a modification of VEX expressions, (iii) statements describe model changes in the state of the target architectures, and (iv)
temporary variables are used to store the temporary results of
expressions.
Figure 3 shows a snippet that was compiled into AArch64 assembly and AMD64 assembly. The different ISAs and different registers show differences between the two snippets of assembly code. These differences increase the difficulty of binary similarity comparisons. After being converted into VEX code, the snippets have the same format and similar content. In
Figure 3, the similar parts are highlighted by same-colour boxes. This converts the problem of binary similarity comparison on different architectures into a similar comparison problem of the same IR, which effectively reduces the analysis difficulty.
4.3. Word and Paragraph Embedding
Word and paragraph embedding algorithms have been used to help with various text analysis tasks such as semantics analysis [
17] and document classification [
28].
The PV-DM model [
17] is an extension of the original word2vec model and is designed for paragraph vectors and word vectors. A trained PV-DM model can generate paragraph semantic vectors for each paragraph according to the words in the paragraph. These paragraph semantic vectors can be used for semantic analysis and similarity analysis at the paragraph level. In binary semantic analysis inspired by NLP, instructions correspond to words, basic blocks correspond to sentences, functions correspond to paragraphs. GeneDiff is a clone detection approach at the function level, which means that GeneDiff has similar application scenarios with PV-DM model. Besides, PV-DM model is a popular NLP technique for generating paragraph vectors, so we learn from PV-DM model to build a representation learning model for intermediate representation functions.
For example, given a text paragraph that contains many sentences, reference [
17] utilized PV-DM to predict a center word from the context words and a paragraph id.
Figure 4 details the method. As shown in
Figure 4, given a paragraph
p from a document
and given a sentence
s, with the words “A cat slept on the sofa”, the model utilizes a sliding window to address the words in the sentence. The sliding window, with a size of
k, starts from the beginning of the sentence and slides forward the end. The sliding window in
Figure 4 contains “a”, “cat”, “slept”, “on” and “the”. The model would learn to predict the target word “slept”, which is in the middle of the sliding window.
First, the current paragraph is mapped into a high-dimensional vector based on the index of the paragraph id, and the context words are mapped to vectors with the same dimensions. Second, the model averages the above vectors to calculate the vector of the target word. Third, the model utilizes the backpropagation algorithm to update the above vectors. Its purpose is to maximize the following expression:
where
is the length of sentence
s. Finally, the model obtains the appropriate vector representations of the words. However, because assembly code and intermediate representations have more complex associations than plain text, such as control flow and richer syntax, the NLP models cannot be applied directly to binary analysis. One aspect of our work is to propose a representation model that can be applied to the intermediate representation.
4.4. Preprocessor
To find the similarity between different binaries of different architectures and various IoT devices, GeneDiff utilizes the preprocessor to extract data from the binaries. First, the preprocessor utilizes a Python script via IDA Pro [
29] as a binary extractor to extract metadata about the binaries such as their architecture type, imagebase, import tables, hash value, endians and compilers. This metadata effectively helps the preprocessor to select a reasonable solution to further analyze the binaries. For example, architecture type, imagebase and endians can be used as parameters to generate intermediate representations. After confirming the metadata about the binaries, the preprocessor extracts the name, callers, callees, basic blocks, bytecode and assembly code for each function in the binaries.
Table 1 shows the details of the extracted information.
After extracting the metadata required to analyze the binaries, the preprocessor converts the bytecode into VEX via a PyVEX translator. A large number of low-frequency words are imported during this phase. For example, large numbers of numeric constants (e.g., a number in the range [
,
]) and strings would make the word corpus too large, while these words may appear less frequently; in addition, it is difficult to accurately obtain their semantic word vectors. When a word that never appeared during training is present in the target binaries, it is called an OOV word. An attempt to generate a vector for such words will fail. Considering the OOV issue, our Python script abstracts some of the low-frequency words into tags during the conversion. The details of these abstraction rules are listed in
Table 2.
Note that the abstraction rules are applied in both the training and query modes. This approach significantly reduces the size of the word corpus and makes the trained model more practical for further research. Some architectures and some IoT devices have their unique instructions, which may impact the clone detection accuracy. For the unique instructions of different architectures and various IoT devices, GeneDiff removes their unimportant instructions and unifies the necessary instructions (e.g., registers), which can reduce the number of differences and keep the high clone detection accuracy.
4.5. Semantic Representation Model
Inspired by the PV-DM model, we proposed a novel semantic-based representation learning model for binaries. In this semantic representation model, every VEX instruction is treated as a letter, and combinations of VEX instructions are regarded as words in the NLP models, basic blocks are regarded as sentences, and functions are regarded as paragraphs. Therefore, the model for the semantic representation vector of functions can learn from the model of paragraph vectors, although they have certain differences. Compared with the extraction of paragraph vectors, the extraction of the function vector differs primarily in the following ways: (i) the calling relationships between functions are complex, (ii) the execution flows of the functions have multiple paths, and (iii) each expression consists of multiple parts. To address these differences, GeneDiff utilizes the following scheme.
Callee expansion. In software code, a function often calls another function (the ) to achieve some goals. When compiling source code into binary files, the compiler may apply compiler optimization techniques to these functions. Function inlining is one such compiler optimization technique. This technique can extend callees in callers to eliminate the call overhead and improve the performance of the binaries. In binary similarity comparisons, however, such techniques may produce obstacles because they substantially modify the control flow graph of the caller function.
Figure 5 shows three examples of calling a function.
Figure 5a,b perform the same function using a normal call and function inlining, respectively. When using function inlining, the CFG of the function of
Figure 5b is significantly different from the CFG of the original function in
Figure 5a. To perform a similarity comparison in this case, if callee expansion of the original function is not performed, the two functions may be considered as different. If we use callee expansion for all callees without distinction, then the situation in
Figure 5c will be questionable. In
Figure 5c, the length of the callee is much greater than the length of the original function. Thus, callee expansion of the callee (
) in the original function may cause the expanded original function to be similar to the callee.
Considering the above cases, the callee expansion approach used by GeneDiff is shown in Algorithm 1. We use f to represent the original function, to represent a callee function, and to indicate the instruction length of f. GeneDiff does not expand callees when they satisfy the following two conditions: (i) callees are not in the list of the data repository (Algorithm 1, Line 3), (ii) the ratio of to is greater than a , and is greater than . In this study, and are set to 10 and 0.5 respectively.
Multi-path generation. In assembly functions, instructions are usually not executed in order, and there are usually multiple execution paths. Given a function f, we obtain a CFG from the data repository of GeneDiff. Then, we randomly pick edges from and expand them into sequences until all the basic blocks in are fully covered. The pseudocode of this multi-path generation process is given in Algorithm 2.
| Algorithm 1: Callee expansion |
![Applsci 09 03283 i001]() |
| Algorithm 2: Generating multiple paths |
![Applsci 09 03283 i002]() |
This method ensures that all the blocks of f are fully covered. Lines 7–23 of Algorithm 2 are used to expand an into a sequence, where prev( ) means { prev( ) }. To avoid too many blocks being repeated in , unselected blocks are selected first when expanding (Algorithm 2, lines 10–13 and lines 18–20). Finally, we add all the expanded sequences to and return it. In , every sequence represents a potential execution trace.
Training model. After generating the multiple paths of functions, we take each path as an input, train a representation learning model based on semantics, and map instructions and functions into high-dimensional vectors.
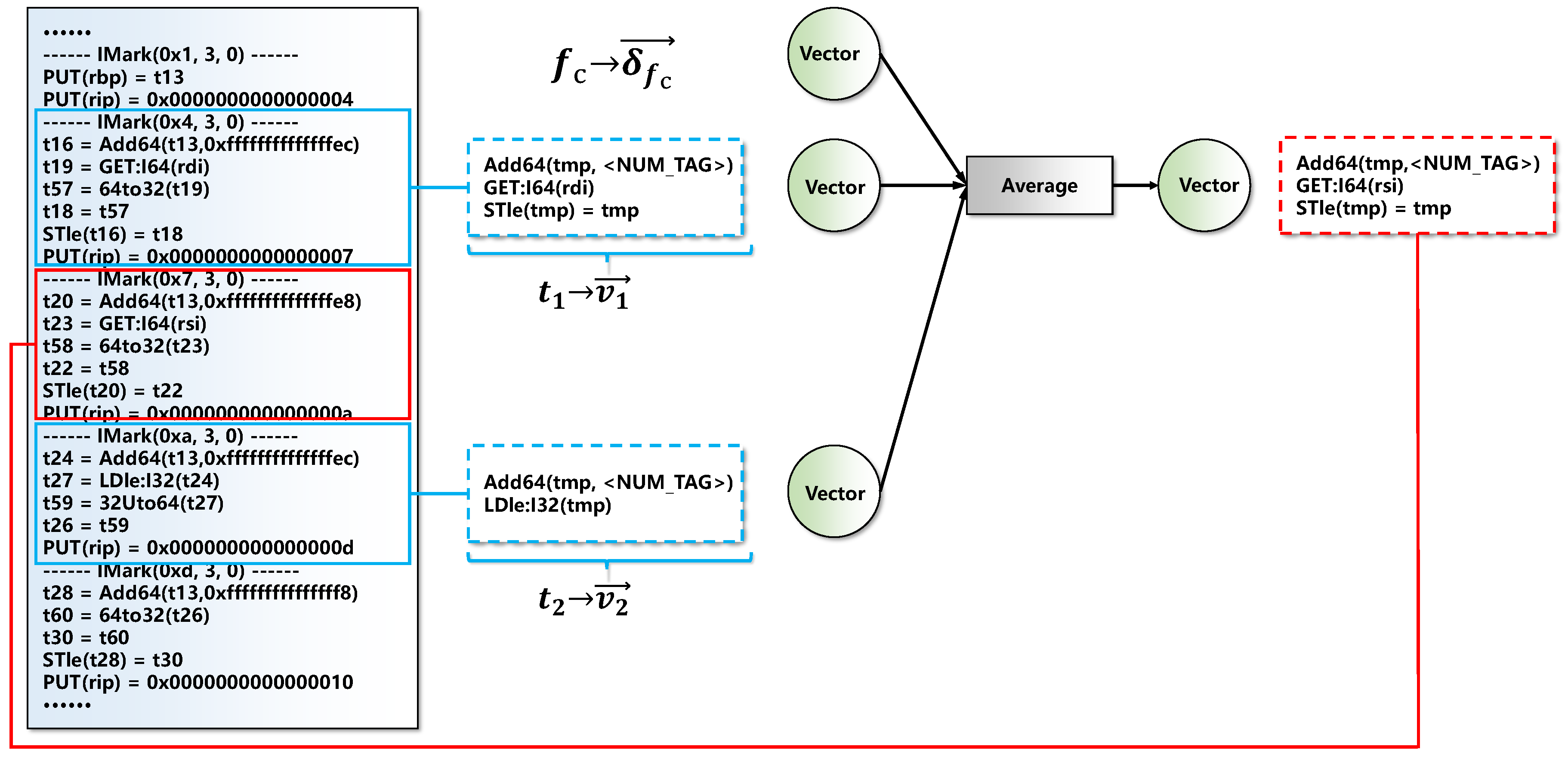
Figure 6 shows the structure of the model.
For functions in the data repository, we map each function
into a numeric vector
. Each dimension of
is initialized to a small random value near zero. Similarly, we map each token of the data repository into a vector
. Unlike references [
18,
26], each token in GeneDiff consists of several VEX instructions from the same assembly instruction. For example,
in
Figure 6 consists of three VEX instructions (after deletion). These VEX instructions come from the same IMark(0x4, 3, 0), where an IMark represents an assembly instruction. The initialization method of
is the same as that of
.
Given a function
from the data repository, where
represents the multiple paths of
, for each path
in
, the model walks through the basic blocks from their beginning. When traversing VEX instructions in a basic block, we treat an IMark as a token. When we calculate
of the current token
, the first
k tokens and the last
k tokens are treated as the context
. Simultaneously, we look up the vector representation
in the previously built dictionary. We use
to represent the average of the neighbour tokens and
. This can be formulated as follows:
The proposed model attempts to maximize the following log probability:
The prediction task is typically performed via a softmax algorithm, which is a multi-class classifier:
where
D denotes all the tokens constructed in the data repository. Each
is an un-normalized log probability for each output token
, computed as follows:
where
U and
b are the softmax parameters. According to Equations (
2), Equations (
3) and (
5) can be rewritten as
However, it would be computationally extremely expensive to traverse
for each calculation because the
is too large for the softmax classification. To minimize the computational cost, we use a
k negative sampling model [
30] to approximate
.
Then, we calculate the gradients by taking the derivatives of
and
in Equation (
7). In training mode, we use back-propagation to update
and all the involved
values based on the gradients. In query mode, we update only the
of the target function.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}