A Review of Text Corpus-Based Tourism Big Data Mining


Abstract
:1. Introduction
2. Review Protocol Used in This Review
- Google Scholar;
- Science Direct;
- ACM Digital Library;
- Citeseer Library;
- Springer Link;
- IEEE explore; and
- Web of Science.
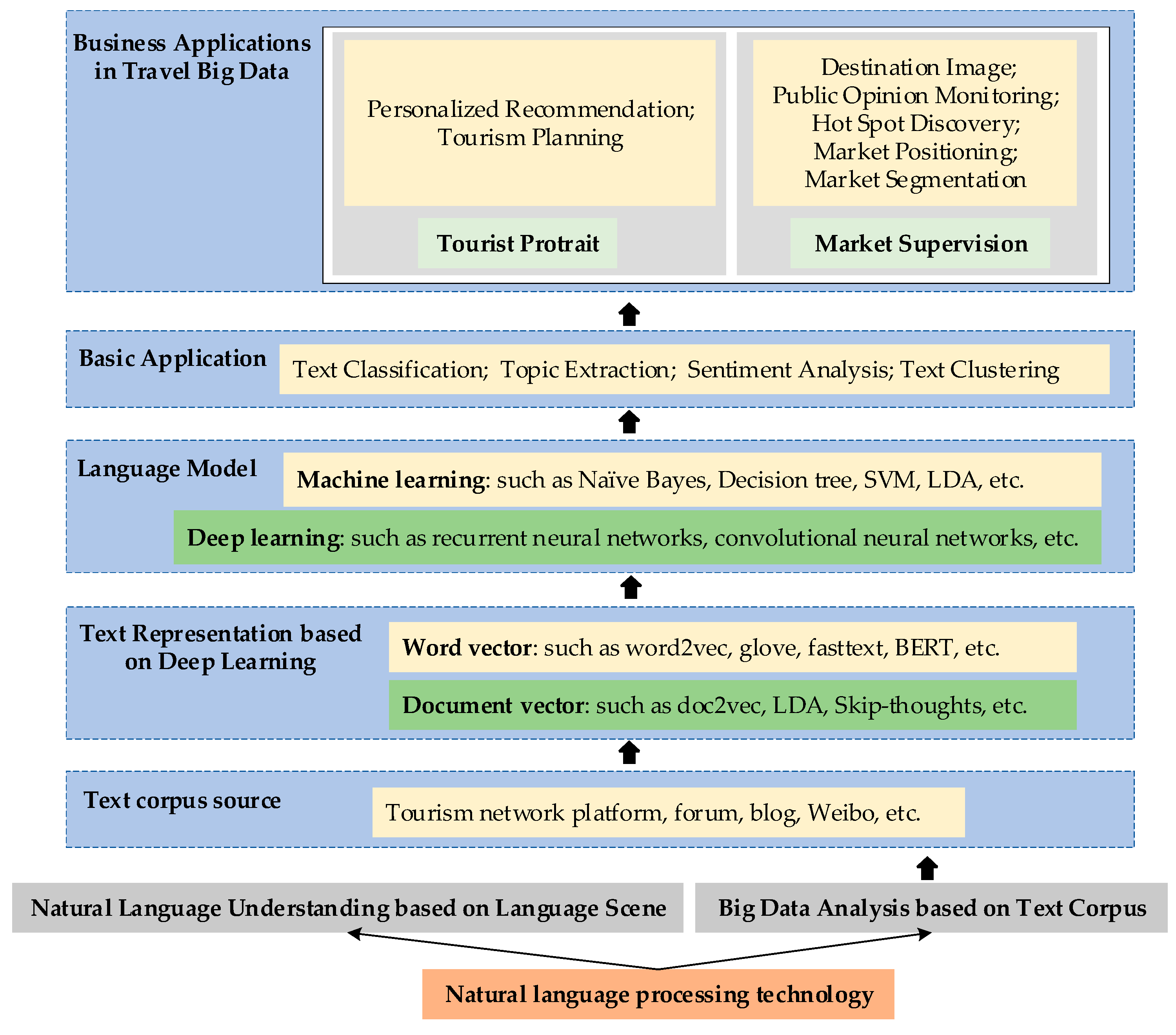
3. Text Corpus-Based Tourism Big Data Mining Techniques
3.1. Text Representations
3.2. Text Corpus-Based NLP Techniques in Tourism Data Mining
3.2.1. Topic Extraction
3.2.2. Text Classification
3.2.3. Sentiment Analysis
3.2.4. Text Clustering
4. Applications of Text Corpus-Based Tourism Big Data Mining
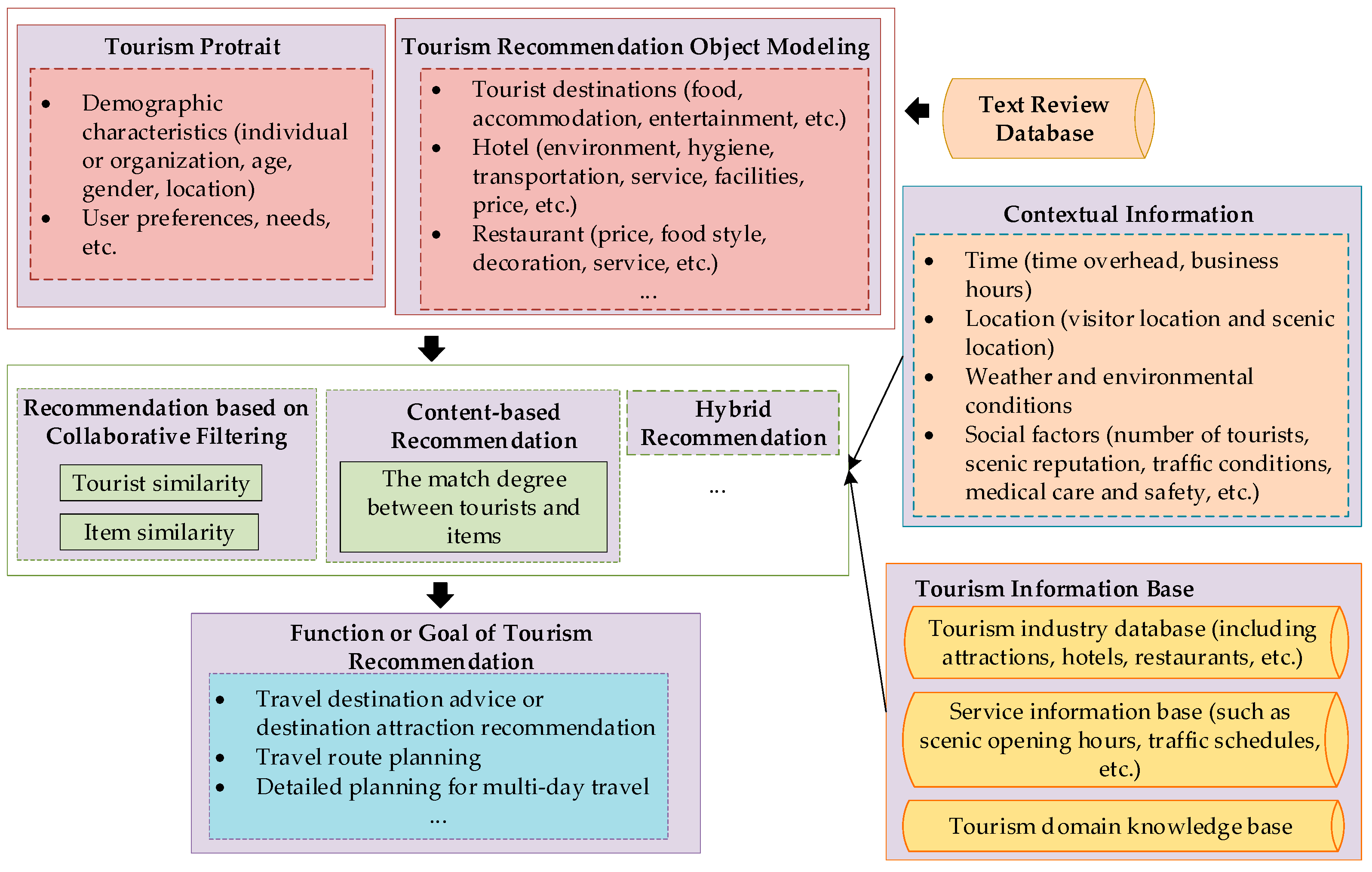
4.1. Tourist Profile
4.2. Market Supervision
5. Outlook
- (1)
- Lack of domain corpus. The languages of the existing tourism corpora are mostly English and the limited multi-language categories make the existing tourism corpora not universally adaptable. In addition, the annotation of the tourism corpus often relies on manual labor, lack of system and formativeness, and the scale of the corpus is usually small. How to automatically and effectively construct a standardized large-scale multi-language tourism corpus has become one of the keys to the successful application of tourism big data. Given the impact of publicly annotated data sets on tourism big data mining and for the convenience of research, we summarize some of the relevant publicly available text data sets currently in the tourism domain, with the data sets described and the dataset sources listed in Table 7.
- (2)
- Limitations of deep learning. The first one is poor interpretability. For a long time, deep learning has been lacking in rigorous mathematical theory, and it is impossible to explain the quality of the results and the variables that lead to the results. In the tourism domain, the interpretable performance of deep learning is more conducive to discover knowledge and understand the nature of the problem, thus the practitioners can make operational service adjustments. The use of attention mechanisms in deep learning also provides an interpretable channel for deep learning. However, for deep learning itself, it still seems to be a black box problem. Some scholars also consider using the knowledge graph to eliminate the semantic gap between NLP and deep learning, which will provide vital support for deep learning interpretability in the future.
- (3)
- The future trend of text corpus-based tourism application. Tourism has a high degree of social nature. It uses the text information shared in social network media to explore the new vitality of tourism services or develop products by feedbacks from tourists, which is the general way of tourism text data mining currently. Tourism personalized recommendation is a significant and potential direction because it caters to current social needs. However, in tourism recommendation, the cold start problem for tourists or tourism items has always been a difficult task for scholars to explore, and thus fail to solve. Combined with other enriched multimedia content such as videos, photographs, text, links to websites, etc., text-based recommendation will be enhanced [164,165], which is also a supplement for addressing the cold start problem. Besides, how to dynamically explore tourist preferences and how to explore the unknown or unfamiliar tourism area or travel style for tourists will become a hot spot for future research.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ye, Q.; Law, R.; Gu, B.; Chen, W. The influence of user-generated content on traveler behavior: An empirical investigation on the effects of e-word-of-mouth to hotel online bookings. Comput. Hum. Behav. 2011, 27, 634–639. [Google Scholar] [CrossRef]
- Li, Q.; Li, S.; Hu, J.; Zhang, S.; Hu, J. Tourism Review Sentiment Classification Using a Bidirectional Recurrent Neural Network with an Attention Mechanism and Topic-Enriched Word Vectors. Sustainability 2018, 10, 3313. [Google Scholar] [CrossRef]
- Marrese-Taylor, E.; Velásquez, J.D.; Bravo-Marquez, F.; Matsuo, Y. Identifying Customer Preferences about Tourism Products Using an Aspect-based Opinion Mining Approach. Proc. Comput. Sci. 2013, 22, 182–191. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Fan, Y.; Bai, B. Knowledge mining and visualizing for scenic spots with probabilistic topic model. J. Comput. Appl. 2016, 36, 2103–2108. [Google Scholar]
- Huang, C.; Wang, Q.; Yang, D.; Xu, F. Topic mining of tourist attractions based on a seasonal context aware LDA model. Intell. Data Anal. 2018, 22, 383–405. [Google Scholar] [CrossRef]
- Al-Horaibi, L.; Khan, M.B. Sentiment analysis of Arabic tweets using text mining techniques. In Proceedings of the First International Workshop on Pattern Recognition, Tokyo, Japan, 11–13 May 2016; p. 100111F. [Google Scholar]
- Okazaki, S.; Andreu, L.; Campo, S. Knowledge sharing among tourists via social media: A comparison between Facebook and TripAdvisor. Int. J. Tour. Res. 2017, 19, 107–119. [Google Scholar] [CrossRef]
- Wang, J.; Li, S.; Zhou, G. Joint Learning on Relevant User Attributes in Micro-blog. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4130–4136. [Google Scholar]
- Gu, H.; Wang, J.; Wang, Z.; Zhuang, B.; Su, F. Modeling of User Portrait Through Social Media. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018. [Google Scholar]
- Wang, J.; Li, S.; Jiang, M.; Wu, H.; Zhou, G. Cross-media User Profiling with Joint Textual and Social User Embedding. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 21–25 August 2018; pp. 1410–1420. [Google Scholar]
- Pennacchiotti, M.; Popescu, A. A Machine Learning Approach to Twitter User Classification. In Proceedings of the International Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Zhao, K.; Cong, G.; Yuan, Q.; Zhu, K.Q. SAR: A Sentiment-aspect-region Model for User Preference Analysis in Geo-tagged Reviews. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 675–686. [Google Scholar]
- Teso, E.; Olmedilla, M.; Martínez-Torres, M.; Toral, S. Application of text mining techniques to the analysis of discourse in eWOM communications from a gender perspective. Technol. Forecast. Soc. Chang. 2018, 129, 131–142. [Google Scholar] [CrossRef]
- Škrlj, B.; Martinc, M.; Kralj, J.; Lavrač, N.; Pollak, S. tax2vec: Constructing Interpretable Features from Taxonomies for Short Text Classification. arXiv 2019, arXiv:1902.00438. [Google Scholar]
- Li, Y.; Zhang, Z.; Peng, Y.; Yin, H.; Xu, Q. Matching user accounts based on user generated content across social networks. Fut. Gen. Comput. Syst. 2018, 83, 104–115. [Google Scholar] [CrossRef]
- Költringer, C.; Dickinger, A. Analyzing destination branding and image from online sources: A web content mining approach. J. Bus. Res. 2015, 68, 1836–1843. [Google Scholar] [CrossRef]
- Yue, G.; Barnes, S.J.; Jia, Q. Mining meaning from online ratings and reviews: Tourist satisfaction analysis using latent dirichletallocation. Tour. Manag. 2017, 59, 467–483. [Google Scholar] [CrossRef]
- Wang, Y. More Important than Ever: Measuring Tourist Satisfaction; Griffith Institute for Tourism, Griffith University: Queensland, Australia, 2016. [Google Scholar]
- Kim, K.; Park, O.; Yun, S.; Yun, H. What makes tourists feel negatively about tourism destinations? Application of hybrid text mining methodology to smart destination management. Technol. Forecast. Soc. Chang. 2017, 123. [Google Scholar] [CrossRef]
- Govers, R.; Go, F.M. Projected destination image online: Website content analysis of pictures and text. Inf. Technol. Tour. 2005, 7, 73–89. [Google Scholar] [CrossRef]
- Chi, T.; Wu, B.; Morrison, A.M.; Zhang, J.; Chen, Y.C. Travel blogs on China as a destination image formation agent: A qualitative analysis using Leximancer. Tour. Manag. 2015, 46, 347–358. [Google Scholar] [CrossRef]
- Ren, G.; Hong, T. Investigating Online Destination Images Using a Topic-Based Sentiment Analysis Approach. Sustainability 2017, 9, 1765. [Google Scholar] [CrossRef]
- Rodrigues, A.I.; Correia, A.; Kozak, M.; Tuohino, A. Lake-destination image attributes: Content analysis of text and pictures. In Marketing Places and Spaces; Emerald Group Publishing Limited: Bingley, UK, 2015; pp. 293–314. [Google Scholar]
- Yuan, H.; Xu, H.; Qian, Y.; Ye, K. Towards Summarizing Popular Information from Massive Tourism Blogs. In Proceedings of the IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 409–416. [Google Scholar]
- Yuan, H.; Xu, H.; Qian, Y.; Li, Y. Make your travel smarter: Summarizing urban tourism information from massive blog data. Int. J. Inf. Manag. 2016, 36, 1306–1319. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, CA, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- McCann, B.; Bradbury, J.; Xiong, C.; Socher, R. Learned in translation: Contextualized word vectors. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6294–6305. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. N. Am. Chapter Assoc. Comput. Linguist. 2018, 1, 2227–2237. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/languageunsupervised/language understanding paper.pdf (accessed on 7 June 2018).
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Xu, G.; Wang, H. The Development of Topic Models in Natural Language Processing. Chin. J. Comput. 2011, 34, 1423–1436. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. Empir. Methods Nat. Lang. Process. 2014, 1746–1751. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 13–15 June 2016; pp. 1480–1489. [Google Scholar]
- Suyal, H.; Panwar, A.; Negi, A.S. Text Clustering Algorithms: A Review. Int. J. Comput. Appl. 2014, 96, 36–40. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in neural information processing systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Genc-Nayebi, N.; Abran, A. A systematic literature review: Opinion mining studies from mobile app store user reviews. J. Syst. Softw. 2017, 125, 207–219. [Google Scholar] [CrossRef]
- Moher, D.; Shamseer, L.; Clarke, M.; Ghersi, D.; Liberati, A.; Petticrew, M.; Shekelle, P.; Stewart, L.A. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement. Syst. Rev. 2015, 4, 1. [Google Scholar] [CrossRef] [PubMed]
- Keele, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report Ver. 2.3 EBSE Technical Report; EBSE: Durham, UK, 2007. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Qiao, C.; Huang, B.; Niu, G.; Li, D.; Dong, D.; He, W.; Yu, D.; Wu, H. A New Method of Region Embedding for Text Classification. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Xiong, S.; Lv, H.; Zhao, W.; Ji, D. Towards Twitter sentiment classification by multi-level sentiment-enriched word embeddings. Neurocomputing 2018, 275, 2459–2466. [Google Scholar] [CrossRef] [Green Version]
- Xiong, S. Improving Twitter Sentiment Classification via Multi-Level Sentiment-Enriched Word Embeddings. arXiv 2016, arXiv:1611.00126. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. Conf. Eur. Chapter Assoc. Comput. Linguist. 2017, 2, 427–431. [Google Scholar] [CrossRef]
- Ji, S.; Yun, H.; Yanardag, P.; Matsushima, S.; Vishwanathan, S.V.N. WordRank: Learning Word Embeddings via Robust Ranking. Comput. Sci. 2015, 658–668. [Google Scholar] [CrossRef]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Arora, S.; Liang, Y.; Ma, T. A Simple but Tough-to-Beat Baseline for Sentence Embeddings. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.R.; Zemel, R.; Urtasun, R.; Torralba, A.; Fidler, S. Skip-thought vectors. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Canada, 7–12 December 2015; pp. 3294–3302. [Google Scholar]
- Logeswaran, L.; Lee, H. An efficient framework for learning sentence representations. arXiv 2018, arXiv:1803.02893. [Google Scholar]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 31 October–4 November 2018; pp. 670–680. [Google Scholar]
- Subramanian, S.; Trischler, A.; Bengio, Y.; Pal, C. Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning. In Proceedings of the International Conference on Learning Representations, Vancouver, Canada, 30 April–3 May 2018. [Google Scholar]
- Liu, G.; Xu, X.; Zhu, Y.; Li, L. An Improved Latent Dirichlet Allocation Model for Hot Topic Extraction. In Proceedings of the IEEE Fourth International Conference on Big Data and Cloud Computing, Sydney, Australia, 3–5 December 2014; pp. 470–476. [Google Scholar]
- Hu, N.; Zhang, T.; Gao, B.; Bose, I. What do hotel customers complain about? Text analysis using structural topic model. Tour. Manag. 2019, 72, 417–426. [Google Scholar] [CrossRef]
- Roberts, M.E.; Stewart, B.M.; Tingley, D.; Lucas, C.; Lederluis, J.; Gadarian, S.K.; Albertson, B.; Rand, D.G. Structural topic models for open ended survey responses. Am. J. Polit. Sci. 2014, 58, 1064–1082. [Google Scholar] [CrossRef]
- Zarrinkalam, F.; Kahani, M.; Bagheri, E. Mining user interests over active topics on social networks. Inf. Process. Manag. 2018, 54, 339–357. [Google Scholar] [CrossRef]
- Rana, T.A.; Cheah, Y.N. Aspect extraction in sentiment analysis: Comparative analysis and survey. Artif. Intell. Rev. 2016, 1–25. [Google Scholar] [CrossRef]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic Keyword Extraction from Individual Documents. Text Min. Appl. Theory 2010, 1–20. [Google Scholar] [CrossRef]
- Bougouin, A.; Boudin, F.; Daille, B. TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction. In Proceedings of the International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–18 October 2013; pp. 543–551. [Google Scholar]
- Ning, J.; Liu, J. Using Word2vec with TextRank to Extract Keywords. New Technol. Libr. Inf. Serv. 2016, 32, 20–27. [Google Scholar] [CrossRef]
- Xun, G.; Li, Y.; Zhao, W.X.; Gao, J.; Zhang, A. A Correlated Topic Model Using Word Embeddings. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australian, 19–25 August 2017; pp. 4207–4213. [Google Scholar]
- Alam, M.H.; Ryu, W.-J.; Lee, S. Joint multi-grain topic sentiment: Modeling semantic aspects for online reviews. Inf. Sci. 2016, 339, 206–223. [Google Scholar] [CrossRef]
- Yao, L.; Zhang, Y.; Chen, Q.; Qian, H.; Wei, B.; Hu, Z. Mining coherent topics in documents using word embeddings and large-scale text data. Eng. Appl. Arti. Intell. 2017, 64, 432–439. [Google Scholar] [CrossRef]
- Moody, C.E. Mixing dirichlet topic models and word embeddings to make lda2vec. arXiv 2016, arXiv:1605.02019. [Google Scholar]
- Wang, Z.; Ma, L.; Zhang, Y. A hybrid document feature extraction method using latent Dirichlet allocation and word2vec. In Proceedings of the 2016 IEEE First International Conference on Data Science in Cyberspace (DSC), Changsha, China, 13–16 June 2016; pp. 98–103. [Google Scholar]
- Cao, Z.; Li, S.; Liu, Y.; Li, W.; Ji, H. A novel neural topic model and its supervised extension. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2210–2216. [Google Scholar]
- Lau, J.H.; Baldwin, T.; Cohn, T. Topically driven neural language model. arXiv 2017, arXiv:1704.08012. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. An Unsupervised Neural Attention Model for Aspect Extraction. In Proceedings of the Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 388–397. [Google Scholar]
- Qiu, L.; Yu, J. CLDA: An effective topic model for mining user interest preference under big data background. Complexity 2018, 2018. [Google Scholar] [CrossRef]
- Zheng, C.T.; Liu, C.; San Wong, H. Corpus-based topic diffusion for short text clustering. Neurocomputing 2018, 275, 2444–2458. [Google Scholar] [CrossRef]
- Li, X.; Zhang, A.; Li, C.; Ouyang, J.; Cai, Y. Exploring coherent topics by topic modeling with term weighting. Inf. Process. Manag. 2018, 54, 1345–1358. [Google Scholar] [CrossRef]
- Liang, Y.; Liu, Y.; Chen, C.; Jiang, Z. Extracting topic-sensitive content from textual documents—A hybrid topic model approach. Eng. Appl. Artif. Intell. 2018, 70, 81–91. [Google Scholar] [CrossRef]
- Xu, Y.; Yin, J.; Huang, J.; Yin, Y. Hierarchical topic modeling with automatic knowledge mining. Expert Syst. Appl. 2018, 103, 106–117. [Google Scholar] [CrossRef]
- Afzaal, M.; Usman, M.; Fong, A.C.M.; Fong, S.; Zhuang, Y. Fuzzy Aspect Based Opinion Classification System for Mining Tourist Reviews. Adv. Fuzzy Syst. 2016, 2016, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Tang, B.; Kay, S.; He, H. Toward optimal feature selection in naive Bayes for text categorization. IEEE Trans. Knowl. Data Eng. 2016, 28, 2508–2521. [Google Scholar] [CrossRef]
- Hamzah, A.; Widyastuti, N. Opinion classification using maximum entropy and K-means clustering. In Proceedings of the 2016 International Conference on Information & Communication Technology and Systems (ICTS), Surabaya, Indonesia, 12 October 2016; pp. 162–166. [Google Scholar]
- Chen, K.; Zhang, Z.; Long, J.; Zhang, H. Turning from TF-IDF to TF-IGM for term weighting in text classification. Expert Syst. Appl. 2016, 66, 245–260. [Google Scholar] [CrossRef]
- An, J.; Chen, Y.P. Keyword extraction for text categorization. In Proceedings of the Active Media Technology, Kagawa, Japan, 19–21 May 2005; pp. 556–561. [Google Scholar]
- Hu, J.; Li, S.; Yao, Y.; Yu, L.; Yang, G.; Hu, J. Patent keyword extraction algorithm based on distributed representation for patent classification. Entropy 2018, 20, 104. [Google Scholar] [CrossRef]
- Hu, J.; Li, S.; Hu, J.; Yang, G. A Hierarchical Feature Extraction Model for Multi-Label Mechanical Patent Classification. Sustainability 2018, 10, 219. [Google Scholar] [CrossRef]
- Ogada, K.; Mwangi, W.; Cheruiyot, W. N-gram Based Text Categorization Method for Improved Data Mining. J. Inf. Eng. Appl. 2015, 5, 35–43. [Google Scholar]
- Zhang, H.; Zhong, G. Improving short text classification by learning vector representations of both words and hidden topics. Knowl. Based Syst. 2016, 102, 76–86. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.J.; Lecun, Y. Character-level convolutional networks for text classification. Neural Inf. Process. Syst. 2015, 649–657. [Google Scholar] [CrossRef]
- Li, S.; Hu, J.; Cui, Y.; Hu, J. DeepPatent: Patent classification with convolutional neural networks and word embedding. Scientometrics 2018, 117, 721–744. [Google Scholar] [CrossRef]
- Zhou, P.; Qi, Z.; Zheng, S.; Xu, J.; Bao, H.; Xu, B. Text Classification Improved by Integrating Bidirectional LSTM with Two-dimensional Max Pooling. Int. Conf. Comput. Ling. 2016, 3485–3495. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Brisbane, QLD, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y.; Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very Deep Convolutional Networks for Text Classification. Comput. Sci. 2016, 1107–1116. [Google Scholar] [CrossRef]
- Katz, G.; Caragea, C.; Shabtai, A. Vertical Ensemble Co-Training for Text Classification. ACM Trans. Intell. Syst. Technol. TIST 2018, 9, 21. [Google Scholar] [CrossRef]
- Zhu, W.; Liu, Y.; Hu, G.; Ni, J.; Lu, Z. A Sample Extension Method Based on Wikipedia and Its Application in Text Classification. Wirel. Pers. Commun. 2018, 102, 3851–3867. [Google Scholar] [CrossRef]
- Jiang, X.; Havaei, M.; Chartrand, G.; Chouaib, H.; Vincent, T.; Jesson, A.; Chapados, N.; Matwin, S. On the Importance of Attention in Meta-Learning for Few-Shot Text Classification. arXiv 2018, arXiv:1806.00852. [Google Scholar]
- Merity, S.; Keskar, N.S.; Socher, R. Regularizing and optimizing LSTM language models. arXiv 2017, arXiv:1708.02182. [Google Scholar]
- Zheng, X.; Luo, Y.; Sun, L.; Ji, Z.; Chen, F. A tourism destination recommender system using users’ sentiment and temporal dynamics. J. Intell. Inf. Syst. 2018, 1–22. [Google Scholar] [CrossRef]
- Serna, A.; Gerrikagoitia, J.K.; Bernabe, U.; Ruiz, T. A Method to Assess Sustainable Mobility for Sustainable Tourism: The Case of the Public Bike Systems. In Proceedings of the Enter Conference | Etourism: Sustaining Culture & Creativity Organized by International Federation for Information Technology & Travel & Tourism, Rome, Italy, 24–26 January 2017. [Google Scholar]
- Li, Q.; Wu, Y.; Wang, S.; Lin, M.; Feng, X.; Wang, H. VisTravel: Visualizing tourism network opinion from the user generated content. J. Vis. 2016, 19, 489–502. [Google Scholar] [CrossRef]
- Zong, C. Statistical Natural Language Processing; Tsinghua University Press: Beijing, China, 2013. [Google Scholar]
- Zhao, Y.; Qin, B.; Liu, T. Sentiment Analysis. J. Softw. 2010, 21, 1834–1848. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, R.; Gui, L.; Lu, Q. Combining Convolutional Neural Networks and Word Sentiment Sequence Features for Chinese Text Sentiment Analysis. J. Chin. Inf. Process. 2015, 29, 172–178. [Google Scholar]
- Fu, Y.; Hao, J.-X.; Li, X.; Hsu, C.H. Predictive Accuracy of Sentiment Analytics for Tourism: A Metalearning Perspective on Chinese Travel News. J. Travel Res. 2018, 0047287518772361. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Santos, C.N.D.; Gatti, M.A.D.C. Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In Proceedings of the International Conference on Computational Linguistics, Dublin, Ireland, 23–29 August 2014; pp. 69–78. [Google Scholar]
- Dieng, A.B.; Wang, C.; Gao, J.; Paisley, J. Topicrnn: A recurrent neural network with long-range semantic dependency. arXiv 2016, arXiv:1611.01702. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. Meet. Assoc. Comput. Ling. 2014, 655–665. [Google Scholar]
- Hassan, A.; Mahmood, A. Deep Learning approach for sentiment analysis of short texts. In Proceedings of the International Conference on Control and Automation, Ohrid, Macedonia, 3–6 July 2017; pp. 705–710. [Google Scholar]
- Tang, D.; Wei, F.; Yang, N.; Zhou, M.; Liu, T.; Qin, B. Learning Sentiment-Specific Word Embedding for Twitter Sentiment Classification. In Proceedings of the Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; pp. 1555–1565. [Google Scholar]
- Ambartsoumian, A.; Popowich, F. Self-Attention: A Better Building Block for Sentiment Analysis Neural Network Classifiers. Empir. Methods Nat. Lang. Process. 2018, 130–139. [Google Scholar] [CrossRef]
- Jiang, T.; Wan, C.; Liu, D. Extracting Target-Opinion Pairs Based on Semantic Analysis. Chin. J. Comput. 2017, 40, 617–633. [Google Scholar]
- He, W.; Tian, X.; Tao, R.; Zhang, W.; Yan, G.; Akula, V. Application of social media analytics: A case of analyzing online hotel reviews. Online Inf. Rev. 2017, 41, 921–935. [Google Scholar] [CrossRef]
- Hu, C.; Liang, N. Deeper attention-based LSTM for aspect sentiment analysis. Appl. Res. Comput. 2019, 36. [Google Scholar]
- Fu, X.; Wei, Y.; Xu, F.; Wang, T.; Lu, Y.; Li, J.; Huang, J.Z. Semi-supervised Aspect-level Sentiment Classification Model based on Variational Autoencoder. Knowl. Based Syst. 2019, 171, 81–92. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, M.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Tay, Y.; Tuan, L.A.; Hui, S.C. Learning to attend via word-aspect associative fusion for aspect-based sentiment analysis. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for target-dependent sentiment classification. arXiv 2015, arXiv:1512.01100. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. arXiv 2017, arXiv:1709.00893. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Liu, T. Aspect level sentiment classification with deep memory network. arXiv 2016, arXiv:1605.08900. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, H.; Jiang, B.; Li, K. Aspect-based sentiment analysis with alternating coattention networks. Inf. Process. Manag. 2019, 56, 463–478. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Y. Attention modeling for targeted sentiment. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2, Short Papers), Valencia, Spain, 3–7 April 2017; pp. 572–577. [Google Scholar]
- Li, X.; Bing, L.; Lam, W.; Shi, B. Transformation networks for target-oriented sentiment classification. arXiv 2018, arXiv:1805.01086. [Google Scholar]
- Shuang, K.; Ren, X.; Yang, Q.; Li, R.; Loo, J. AELA-DLSTMs: Attention-Enabled and Location-Aware Double LSTMs for aspect-level sentiment classification. Neurocomputing 2019, 334, 25–34. [Google Scholar] [CrossRef]
- Ma, X.; Zeng, J.; Peng, L.; Fortino, G.; Zhang, Y. Modeling multi-aspects within one opinionated sentence simultaneously for aspect-level sentiment analysis. Fut. Gen. Comput. Syst. 2019, 93, 304–311. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, L.; Zou, Y.; Gan, C. The optimally designed dynamic memory networks for targeted sentiment classification. Neurocomputing 2018, 309, 36–45. [Google Scholar] [CrossRef]
- Fan, F.; Feng, Y.; Zhao, D. Multi-grained attention network for aspect-level sentiment classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3433–3442. [Google Scholar]
- Xu, H.; Liu, B.; Shu, L.; Yu, P.S. BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis. arXiv 2019, arXiv:1904.02232. [Google Scholar]
- Yang, M.; Yin, W.; Qu, Q.; Tu, W.; Shen, Y.; Chen, X. Neural Attentive Network for Cross-Domain Aspect-level Sentiment Classification. IEEE Trans. Affect. Comput. 2019. [Google Scholar] [CrossRef]
- Almars, A.; Li, X.; Zhao, X. Modelling user attitudes using hierarchical sentiment-topic model. Data Knowl. Eng. 2019, 119, 139–149. [Google Scholar] [CrossRef]
- Li, J.; Yujie, C.; Zhao, Z. Tibetan Tourism Hotspots: Co-word Cluster Analysis of English Blogs. Tour. Trib. 2015, 30, 35–43. [Google Scholar]
- Ding, S.; Gong, S.; Li, H. A New Method to Detect Bursty Events from Micro-blog Posts Based on Bursty Topic Words and Agglomerative Hierarchical Clustering Algorithm. New Technol. Libr. Inf. Serv. 2016, 32, 12–20. [Google Scholar] [CrossRef]
- Celardo, L.; Iezzi, D.F.; Vichi, M. Multi-mode partitioning for text clustering to reduce dimensionality and noises. In Proceedings of the 13th International Conference on Statistical Analysis of Textual Data, Nice, France, 7–10 June 2016. [Google Scholar]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. A Brief Survey of Text Mining: Classification, Clustering and Extraction Techniques. Min. Text Data 2017. [Google Scholar] [CrossRef]
- Huang, L.-J.; Cheng, M.-Z.; Xiao, Y. Text Clustering Algorithm Based on Random Cluster Core. In Proceedings of the ITM Web of Conferences, Julius, France; 2016; p. 05001. [Google Scholar]
- Xiong, C.; Hua, Z.; Lv, K.; Li, X. An Improved K-means Text Clustering Algorithm by Optimizing Initial Cluster Centers. In Proceedings of the International Conference on Cloud Computing & Big Data, Macau, China, 16–18 November 2016. [Google Scholar]
- Huan, Z.; Pengzhou, Z.; Zeyang, G. K-means Text Dynamic Clustering Algorithm Based on KL Divergence. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6 June 2018; pp. 659–663. [Google Scholar]
- Abualigah, L.M.; Khader, A.T.; Al-Betar, M.A. Unsupervised feature selection technique based on genetic algorithm for improving the Text Clustering. In Proceedings of the 7th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 13–15 July 2016; pp. 1–6. [Google Scholar]
- Jin, C.X.; Bai, Q.C. Text Clustering Algorithm Based on the Graph Structures of Semantic Word Co-occurrence. In Proceedings of the International Conference on Information System and Artificial Intelligence, Hangzhou, China, 14–16 July 2017; pp. 497–502. [Google Scholar]
- Wang, B.; Liu, W.; Lin, Z.; Hu, X.; Wei, J.; Liu, C. Text clustering algorithm based on deep representation learning. J. Eng. 2018, 2018, 1407–1414. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Al-Betar, M.A. Multi-objectives-based text clustering technique using K-mean algorithm. In Proceedings of the International Conference on Computer Science & Information Technology, Amman, Jordan, 13–15 July 2016. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. A survey of text clustering algorithms. In Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 77–128. [Google Scholar]
- Yu, J.C.X. Ontology Concepts Clustering Based on Encyclopedia Entr. J. Univ. Electron. Sci. Technol. China 2017, 46, 636–640. [Google Scholar]
- Horner, S.; Swarbrooke, J. Consumer Behaviour in Tourism; Routledge: London, UK, 2016. [Google Scholar]
- Alén, E.; Losada, N.; Domínguez, T. The Impact of Ageing on the Tourism Industry: An Approach to the Senior Tourist Profile. Soc. Indic. Res. 2016, 127, 1–20. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, K.; Bao, J.; Chen, K. Listen to the voices from home: An analysis of Chinese tourists’ sentiments regarding Australian destinations. Tour. Manag. 2019, 71, 337–347. [Google Scholar] [CrossRef]
- Ezeuduji, I.O.; November, K.L.; Haupt, C. Tourist Profile and Destination Brand Perception: The Case of Cape Town, South Africa. Acta Univ. Danub. Oeconomica 2016, 12, 115–132. [Google Scholar]
- Padilla, J.J.; Kavak, H.; Lynch, C.J.; Gore, R.J.; Diallo, S.Y. Temporal and Spatiotemporal Investigation of Tourist Attraction Visit Sentiment on Twitter. PLoS ONE 2018, 13, e0198857. [Google Scholar] [CrossRef]
- Pan, M.H.; Yang, X.X.; Pan, Z. Influence Factors of the Old-age Care Tourism Decision Making Behavior based on the Life Course Theory: A Case of Chongqing. Hum. Geogr. 2017, 6, 154–160. [Google Scholar] [CrossRef]
- Qi, S.; Wong, C.U.I.; Chen, N.; Rong, J.; Du, J. Profiling Macau cultural tourists by using user-generated content from online social media. Inf. Technol. Tour. 2018, 1–20. [Google Scholar] [CrossRef]
- Zheng, X.; Luo, Y.; Xu, Z.; Yu, Q.; Lu, L. Tourism Destination Recommender System for the Cold Start Problem. KSII Trans. Internet Inf. Syst. 2016, 10. [Google Scholar] [CrossRef]
- Leal, F.; González–Vélez, H.; Malheiro, B.; Burguillo, J.C. Semantic profiling and destination recommendation based on crowd-sourced tourist reviews. In Proceedings of the International Symposium on Distributed Computing and Artificial Intelligence, Porto, Portugal, 21–23 June 2017; pp. 140–147. [Google Scholar]
- Rossetti, M.; Stella, F.; Cao, L.; Zanker, M. Analysing User Reviews in Tourism with Topic Models; Springer International Publishing: Lugano, Switzerland, 2015; pp. 47–58. [Google Scholar]
- Borràs, J.; Moreno, A.; Valls, A. Intelligent tourism recommender systems: A survey. Expert Syst. Appl. 2014, 41, 7370–7389. [Google Scholar] [CrossRef]
- Qiao, X.; Zhang, L. Overseas Applied Studies on Travel Recommender System in the Past Ten Years. Tour. Trib. 2014. [Google Scholar] [CrossRef]
- Batat, W.; Phou, S. Building Understanding of the Domain of Destination Image: A Review; Springer International Publishing: Atlanta, GA, USA, 2016. [Google Scholar]
- Dickinger, A.; Költringer, C.; Körbitz, W. Comparing Online Destination Image with Conventional Image Measurement—The Case of Tallinn; Springer: Vienna, Austria, 2011; pp. 165–177. [Google Scholar]
- Gunn, C.A. Vacationscape: Designing Tourist Regions; Van Nostrand Reinhold: New York, NY, USA, 1988. [Google Scholar]
- Castro, J.C.; Quisimalin, M.; de Pablos, C.; Gancino, V.; Jerez, J. Tourism Marketing: Measuring Tourist Satisfaction. J. Serv. Sci. Manag. 2017, 10, 280. [Google Scholar] [CrossRef]
- San Martín, H.; Herrero, A.; García de los Salmones, M.d.M. An integrative model of destination brand equity and tourist satisfaction. Curr. Iss. Tour. 2018, 1–22. [Google Scholar] [CrossRef]
- Kim, J.; Bae, J.; Hastak, M. Emergency information diffusion on online social media during storm Cindy in US. Int. J. Inf. Manag. 2018, 40, 153–165. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Liao, X.; Wu, X.; Gui, L.; Huang, J.; Chen, G. Cross-Domain Sentiment Classification Based on Representation Learning and Transfer Learning. Beijing Da Xue Xue Bao 2019, 55, 37–46. [Google Scholar] [CrossRef]
- Yu, M.; Guo, X.; Yi, J.; Chang, S.; Potdar, S.; Cheng, Y.; Tesauro, G.; Wang, H.; Zhou, B. Diverse Few-Shot Text Classification with Multiple Metrics. arXiv 2018, arXiv:1805.07513. [Google Scholar] [CrossRef] [Green Version]
- Lampinen, A.; Mcclelland, J.L. One-shot and few-shot learning of word embeddings. arXiv 2017, arXiv:1710.10280. [Google Scholar]
- Gu, J.; Wang, Y.; Chen, Y.; Li, V.O.K.; Cho, K. Meta-Learning for Low-Resource Neural Machine Translation. Empir. Methods Nat. Lang. Process. 2018, 3622–3631. [Google Scholar]
- Stai, E.; Kafetzoglou, S.; Tsiropoulou, E.E.; Papavassiliou, S. A holistic approach for personalization, relevance feedback & recommendation in enriched multimedia content. Multimed. Tools Appl. 2018, 77, 283–326. [Google Scholar] [CrossRef]
- Pouli, V.; Kafetzoglou, S.; Tsiropoulou, E.E.; Dimitriou, A.; Papavassiliou, S. Personalized multimedia content retrieval through relevance feedback techniques for enhanced user experience. In Proceedings of the 13th International Conference on Telecommunications (ConTEL), Graz, Austria, 13–15 July 2015; pp. 1–8. [Google Scholar]
- Zhang, H.; Yu, H.; Xu, W. Listen, interact and talk: Learning to speak via interaction. arXiv 2017, arXiv:1705.09906. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Li, J.; Xu, L.; Tang, L.; Wang, S.; Li, L. Big data in tourism research: A literature review. Tour. Manag. 2018, 68, 301–323. [Google Scholar] [CrossRef]
- Quan, H.; Li, S.; Hu, J. Product Innovation Design Based on Deep Learning and Kansei Engineering. Appl. Sci. 2018, 8, 2397. [Google Scholar] [CrossRef]
- Li, W.; Guo, K.; Shi, Y.; Zhu, L.; Zheng, Y. DWWP: Domain-specific new words detection and word propagation system for sentiment analysis in the tourism domain. Knowl. Based Syst. 2018, 146, 203–214. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Include | Exclude |
|---|---|
| Studies focused on text mining techniques based on macro corpus analysis, including topic extraction, text classification, sentiment classification, and text clustering. | NLP based on language scenes which requires knowledge rather than text, such as knowledge of domains and common sense. |
| Tourism related studies in which text is the main research object, and other data structures can be the auxiliary means. Text corpus-based tourism big data mining related to tourist profiling and market supervision. | Tourism related studies in which other data structures (pictures, videos, etc.) are the main research object, while text can be the auxiliary means. Text corpus-based tourism big data mining related to question answering, or others. |
| English texts. | All other languages. |
| Studies published between 2014 and 2019. | Studies published before 2014. |
| Peer reviewed academic journals or books, conference proceedings. | Dissertations, non-peer reviewed sources. |
| In person context. | Online context. |
| Time | Pre-Trained Model | URL | Accessed Data |
|---|---|---|---|
| 2013 | Word2vec | https://radimrehurek.com/gensim/models/word2vec.html | 24 July 2019 |
| 2014 | Glove | https://nlp.stanford.edu/projects/glove/ | 24 July 2019 |
| 2016 | FastText [45] | https://fasttext.cc/ | 24 July 2019 |
| 2016 | WordRank [46] | https://radimrehurek.com/gensim/models/wrappers/wordrank.html | 24 July 2019 |
| 2017 | CoVe | https://github.com/salesforce/cove | 24 July 2019 |
| 2018 | ULMFiT [47] | http://nlp.fast.ai/ulmfit | 24 July 2019 |
| 2018 | ELMO | https://github.com/allenai/allennlp/blob/master/tutorials/how_to/elmo.md | 24 July 2019 |
| 2018 | OpenAI-GPT | https://openai.com/blog/language-unsupervised/ | 24 July 2019 |
| 2018 | BERT | https://github.com/ google-research/bert | 24 July 2019 |
| Author-Study | Contribution | Basic Language Model/Classifier |
|---|---|---|
| [91] | It proposes a novel co-training algorithm which uses an ensemble of classifiers created in multiple training iterations, with labeled data and unlabeled data trained jointly and with no added computational complexity. | Naïve Bayes; Support Vector Machine |
| [92] | It uses the knowledge of Wikipedia to extend the training samples, which is realized by network graph construction. | Naïve Bayes; Support Vector Machine; Random Forest |
| [93] | It introduces an attentive meta-learning method for task-agnostic representation and realizes fast adaption in different tasks, thus having the ability of learning shared representation across tasks. | Temporal Convolutional Networks (TCN) |
| [47] | It proposes a transfer learning method of universal language model fine-tuning (ULMFiT), which trains on three common text classification tasks; it can prevent overfitting, even with few labeled data in classification tasks by novel fine-tuning techniques. | Averaged stochastic gradient descent Weight-Dropped LSTM (AWD-LSTM) [94] |
| Time | Model | Basic Idea | Accuracy (%) |
|---|---|---|---|
| 2016 | AE-LSTM [113] | The target words given in each sentence of the training corpus are vectorized and added to the LSTM model as input for training together. | 76.20 |
| 2016 | AT-LSTM [113] | An attention mechanism is proposed to capture key parts of a sentence related to a given aspect. | 77.90 |
| 2018 | AF-LSTM [114] | A new association layer that defines two correlation operators, circular convolution and cyclic correlation, is introduced to learn the relationship between sentence words and aspects. | 75.44 |
| 2015 | TD-LST [115] | Two LSTM networks are adopted to model separately, based on context before and after target words for target-dependent sentiment analysis tasks. | 75.63 |
| 2015 | TC-LSTM [115] | On the basis of TD-LSTM, target word information is added as an input. | 76.01 |
| 2016 | ATAE-LSTM [113] | On the basis of TD-LSTM, aspect information is introduced in two parts of the model: Input part and hidden part | 77.20 |
| 2017 | IAN [116] | It learns attentions in target and context words interactively, and generates the representations for targets and contexts separately. | 78.60 |
| 2016 | MemNet(k) [117] | It uses deep memory network with multiple computational layers (hops) to classify sentiments at the aspect level, where k is the number of layers. | (k = 2) 78.61 (k = 3) 79.06 |
| 2018 | Coattention-LSTM Coattention-MemNet(3) [118] | A collaborative attention mechanism is proposed to alternately use target-level and context-level attention mechanisms. | 78.8 79.7 |
| 2017 | BILSTM-ATT-G [119] | Based on the Vanilla Attention Model, this model is extended to differentiate left and right contexts, and uses the gate method to control the output of the data stream. | 79.73 |
| 2018 | TNet-LF TNet-AS [120] | The CNN is used to replace the attention-based recurrent neural network (RNN) to extract the classification features, and the context-preserving transformation (CPT) structure such as lossless forwarding (LF) and adaptive scaling (AS) is used to capture the target entity information and the retention context information. | 80.79 80.69 |
| 2018 | AE-DLSTMs [121] | On the basis of AE-LSTMs, this model captures contextual semantic information in both forward and backward directions in aspect words. | 79.57 |
| 2018 | AELA-DLSTMs [121] | Based on AE-DLSTMs, this model introduces the context position information weight of the aspect word. | 80.35 |
| 2018 | StageI+StageII [122] | It introduces a position attention mechanism based on position context between aspect and context, and also considers the disturbance of other aspects in the same sentence. | 80.10 |
| 2018 | DMN+AttGRU (k = 3) [123] | A dynamic memory network which uses multiple attention blocks of multiple attention mechanisms is proposed to extract sentiment-related features in memory information, where k stands for attention steps. | 81.41 |
| 2018 | MGAN [124] | This model designs an aspect alignment loss to depict aspect-level interactions among aspects with the same context, and to strengthen the attention differences among aspects with the same context and different sentiment polarities. | 81.25 |
| Time | Model | Basic Idea | Accuracy (%) |
|---|---|---|---|
| 2019 | BERT [125] | Bidirectional Transformer (BERT) is extended with an additional task-specific layer and fine-tuned on each end task | 81.54 |
| 2019 | BERT-PT [125] | On the basis of BERT, two pre-training objectives are used: Masking language model (MLM) and next sentence prediction (NSP), to post-train domain knowledge, and else task (MRC) knowledge. | 84.95 |
| Contributions | Benefits | Methods | |
|---|---|---|---|
| [5] | The topic features of attractions in the context of seasons are firstly explored, which are precisely at the fine-grained season levels. | The proposed a season topic model based on LDA (STLDA) model can distinguish attractions with different seasonal feature distributions, which helps improve personalized recommendations. | Latent Dirichlet Allocation (LDA) |
| [12] | This paper proposes a sentiment-aspect-region model with the information of Point of Interests (POIs) and geo-tagged reviews to identify the topical-region, topical-aspect, and sentiment for each user; it also proposes an efficient online recommendation algorithm and can provide explanations for recommendations. | POI recommendation, user recommendation, and aspect satisfaction analysis in regions can be achieved by this model. | Probability generative model; expectation-maximization (EM) |
| [25] | It firstly divides tourism blog contents into semantic word vectors and creatively uses the frequent pattern mining and maximum confidence to capture the neighborhood relationships of the attractions in the tourist log. | Popular attractions and frequent travel routes from massive blog data analysis can be extracted, and thus potential tourists can schedule their travel plans efficiently. | Term Frequency (TF); frequent pattern mining; maximum confidence |
| [55] | It proposes a negative review detection method by adapting Structure Topic Model (STM); the variation of document-topic proportions with different level of covariates can be easily determined. | It enhances our understanding of the aspects of dissatisfaction in text reviews. | STM |
| [95] | It employs text mining techniques to access sentiment tendency which is incorporated into an enhanced Singular Value Decomposition (SVD++) model for model amendment also with the temporal influence, such as seasons and holidays on the tourists’ sentiments. | It can help alleviate the cold-start problem effectively and thus improve the tourism recommendation system. | SVD++ |
| [127] | It proposes a topic model which can judge users’ sentiment distribution and topic sentiment distribution in a topical tree format. | It offers a general model for practitioners to determine why users like or dislike the topics. | Hierarchical probability generative model |
| [150] | It proposes a Topic Criterion (TC) model and the Topic Sentiment Criterion (TSC) model to calculate tourist profiles and item profiles, as well as their matching degrees to achieve recommendations. | It can be beneficial to tourism recommendation and provide an interpretation of users and item profiles. | LDA; JST (Joint Sentiment-Topic model) |
| Name | Description | Source | Accessed Date |
|---|---|---|---|
| Hotel_Reviews 515,000 | It contains 515,000 customer reviews with positive and negative aspects and ratings of 1493 luxury hotels across Europe, as well as the location of the hotel. | https://www.kaggle.com/jiashenliu/515k-hotel-reviews-data-in-europe | 24 July 2019 |
| TripAdvisor Hotel Review Dataset | It contains 20,490 hotel customer reviews and related review ratings. | https://zenodo.org/record/1219899#.XFSETygzY2w | 24 July 2019 |
| Citysearch Restaurant Review Dataset | It contains 35,000 food reviews and lists representative words related to the attributes of each entity. It also includes 3418 sentences with labeled sentiment polarity for the attributes of each entity. | http://dilab.korea.ac.kr/jmts/jmtsdataset.zip | 24 July 2019 |
| OpinRank Dataset | It contains 259,000 reviews of 10 different cities (Dubai, Beijing, London, New York, New Delhi, San Francisco, Shanghai, Montreal, Las Vegas, and Chicago), each city of which has approximately 80–700 hotels, with dates, comment title, and full comment included. | https://github.com/kavgan/OpinRank/blob/master/OpinRankDatasetWithJudgments.zip | 24 July 2019 |
| SemEval ABSA Restaurant Reviews-English (2014–2016) SemEval ABSA Hotels Domain-English (2015–2016) | It includes multiple English data sets for restaurants and hotels which are composed of comments, with the attributes (E#A pairs) and the target and the corresponding sentiment polarities marked. | http://metashare.ilsp.gr:8080/repository/search/?q=SemEval | 24 July 2019 |
| SentiBridge: A Knowledge Base for Entity-Sentiment Representation | The dictionary contains a total of 300,000 entity-sentiment pairs, currently from the three domains of news, travel, and catering. | https://github.com/rainarch/SentiBridge | 24 July 2019 |
| ChnSentiCorp-Htl-unba-10000 | It contains 7000 positive and 3000 negative hotel reviews in Chinese. | https://download.csdn.net/download/sinat_30045277/9862005 | 24 July 2019 |
| TourPedia | It contains two main data sets: Places, and reviews about places. Places contains accommodations, restaurants, attractions, and points of interest, and each place is descripted with address, location, polarity, etc. Reviews about places has some auxiliary information such as rating, time, polarity, place, etc. | http://tour-pedia.org/about/datasets.html | 24 July 2019 |
| Museum reviews from TripAdvisor | It contains 1600 museum data including address, category, review, rating, popularity, etc. | https://www.kaggle.com/annecool37/museum-data | 24 July 2019 |
| Main Take-Aways |
|---|
| Topic probability model is a basic model used in most topic extraction algorithms, which can be improved by enhancing topic coherence of short texts or exploiting the sematic feature of words and text enabled by deep learning. |
| Language models based on deep learning models such as CNN and RNN, etc., are widely applied in text classification. Focusing on their requirement for abundant labeled data for supervised learning, many strategies have been proposed such as co-training, training samples extension, meta-learning, and transfer learning. |
| One of the mainstream trends in sentiment classification is to exploit the attention mechanism in deep learning. Based on the study of sentiment targets or sentiment aspects, the sentiments can be more fine-grained and interpretable, which is more conducive to practical application analysis. |
| K-means is a method often commonly used in text clustering due to its small time complexity. Optimization of initial clustering points, improvement of text representation, and optimization of objective functions are all popular aspects of improvements to K-means-based text clustering. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Li, S.; Zhang, S.; Hu, J.; Hu, J. A Review of Text Corpus-Based Tourism Big Data Mining. Appl. Sci. 2019, 9, 3300. https://doi.org/10.3390/app9163300
Li Q, Li S, Zhang S, Hu J, Hu J. A Review of Text Corpus-Based Tourism Big Data Mining. Applied Sciences. 2019; 9(16):3300. https://doi.org/10.3390/app9163300
Chicago/Turabian StyleLi, Qin, Shaobo Li, Sen Zhang, Jie Hu, and Jianjun Hu. 2019. "A Review of Text Corpus-Based Tourism Big Data Mining" Applied Sciences 9, no. 16: 3300. https://doi.org/10.3390/app9163300
APA StyleLi, Q., Li, S., Zhang, S., Hu, J., & Hu, J. (2019). A Review of Text Corpus-Based Tourism Big Data Mining. Applied Sciences, 9(16), 3300. https://doi.org/10.3390/app9163300