1. Introduction
The vehicle routing problem (VRP) involves the definition of an optimal route set for several delivery vehicles satisfying the requirements of the customers. In particular, the VRP with time windows (VRPTW) is a VRP variant in which a slot of time is assigned for the delivery to the customer. This problem is known as one NP-hard combinatorial optimization problem, and many algorithms have been proposed in the existing literature to try to solve it, highlighting the use of swarm and evolutionary algorithms such as genetic algorithms and particle swarm optimization methods. In a genetic algorithm (GA), each candidate solution to VRPTW is encoded in one chromosome, and a population of them evolves by applying the selection, crossover, and mutation operators. This evolutionary process is guided by a fitness function, helping to reach a near-optimal solution. Since the permutation characteristics of a VRPTW candidate solution, new chromosomes must represent only feasible solutions, but traditional recombination operators can create infeasible solutions with repeated values. In a previous work, Díaz-Parra and Cruz-Chávez [
1] describe an approach named GA-VRPTW (Genetic Algorithm to Vehicle Routing Problem with Time Windows) evolving only feasible VRPTW routes by the use of modified genetic operators for selection, crossover, and mutation. Experimental results with several Solomon benchmark problems with 100 customers indicate that GA-VRPTW is very competitive compared with other GA-based algorithms and in some cases is even better. Otherwise, GA-VRPTW is a sequential algorithm whose performance analysis shows that the mutation operator requires the most computational time.
In this paper, one grid-based genetic algorithm (GGA) to improve the GA-VRPTW performance using an experimental MiniGrid is introduced. GGA uses the computing resources of two clusters that are geographically separated but linked together since they are part of a MiniGrid configured as one virtual private network (VPN). Based on the genetic operators proposed in the GA-VRPTW algorithm, GGA splits the population of chromosomes in several segments, which are simultaneously mutated in each process generated by the MiniGrid. After the application of the mutation operator in each MiniGrid node, the mutated segments are used to build a new population of improved chromosomes.
Since VRPTW is considered an NP-hard problem, many approaches have been proposed to find appropriate solutions, and its study has importance since several real-problems in manufacturing, scheduling, and logistics can be formulated as one vehicle routing problem. These approaches can be grouped into exact methods such as dynamic programming [
2], branch-and-bound [
3], and branch-and-cut [
4], as well as metaheuristic-based algorithms such as Tabu Search (TS) [
5], ant colony optimization (ACO) [
6], simulated annealing (SA) [
7], and evolutionary algorithms (EAs) [
8,
9,
10,
11].
Kohl et al. [
12] introduce a set-partitioning-based approach known in the existing literature as the KDMSS algorithm, in which a Dantzig–Wolfe decomposition scheme is used in conjunction with a two-path cut procedure to reach better lower bounds to several VRPTW instances of the Solomon benchmark problems with 100 and 150 customers. Arbelaitz et al. [
13] present a two-phase parallel SA algorithm to solve the VRPTW using a message-passing communication scheme. Experimental results of 56 Solomon benchmarks problems with 100 customers reach near-optimal solutions. Also, it was observed that increasing the number of processors improved the algorithm efficiency. A similar scheme was proposed by Wieczorek [
14] where experimental results show that depending on the problem characteristics, some improve their efficacy as the number of processors increased, and with others, the quality decreased or remained the same regardless of the number of processors. Gehring and Homberger [
15] introduce two parallel two-phase hybrid metaheuristics using TS and SA, designated as the HM4 and HM4C methods, improving the solution quality of several problems generated by the authors. Berger and Barkaoui [
16] propose one parallel master-slave co-evolutionary approach using two populations with different fitness functions: The first minimizing the total travel distance and the second reducing the time window constraints violations. Le Bouthillier and Crainic [
17] implement a combination of TS and GA running in several cooperative threads and using the population as shared memory. One GA in each thread is used to evolve the population using different selection and crossover operators, and TS is a local search method applied to improve the offspring quality. Ropke and Pisinger [
18] apply the adaptive large neighborhood search (ALNS) heuristic to solve five different VRP variants. First, each variant is transformed in a rich pickup and delivery problem with time windows (RPDPTW), and then the ALNS is used to solve it. This algorithm was able to improve the best-known solution in 183 of 486 benchmark problems.
Furthermore, Nalepa and Czech [
19] propose several thread-cooperation schemes to solve VRPTW instances: Two use a constant cooperation frequency rate, and the others use two adaptive cooperation rates. Experimental results with several Gehring and Homberger benchmark problems show that, for harder instances, the cooperation frequency increases, and higher solution accuracy is obtained, and this behavior is contrary for less hard instances. Nalepa and Blocho [
20] propose an island-model-based approach for a parallel memetic algorithm (PMA-VRPTW) applying refinements to a population of candidate solutions evolving in a parallel scheme. Experimental tests with a symmetric-multiprocessor cluster report better solutions than the best-known solutions of 19 Gehring and Homberger benchmark problems with 1000 customers. Baños et al. [
21] present another island-based parallel method to solve the capacitated VRPTW named multiple temperature Pareto simulated annealing (MT-PSA). Experimental results with several Solomon benchmark problems show that the parallel version produces better solutions than those obtained by the sequential version of the algorithm. Barbucha [
22] proposes one cooperative population learning algorithm (CPLA) using several search heuristics implemented as software agents cooperating in a two-stage procedure that first learn and then promote the best solutions. CPLA is evaluated using 56 Solomon benchmark problems with 100 customers, and its results are comparable to those produced by other methods. Jawarneh and Abdullah [
23] apply the bee colony optimization (BCO) with one sequential insertion heuristic maintaining an acceptable population diversification rate to solve several Solomon benchmark problems. They apply a self-adapting tuning strategy to decide the search behavior of each bee in the swarm. Pierre and Zakaria [
24] implement a multi-objective GA with a stochastic partially optimized cyclic shift crossover operator to build feasible candidate solutions in its evolutionary process guiding using the distance route and the number of vehicles as fitness functions. The performance of this method is evaluated using 56 Solomon benchmarks problems, and the results indicate that this approach produces 16 solutions comparable with the best-known solutions. Bychkov and Batsyn [
25] propose a hybrid algorithm combining ACO and TS to solve the capacitated VRPTW. In this approach, a set of ants is used to find promising candidate solutions, and TS is applied to improve the quality of these solutions in each step of its iterative process.
Wang et al. [
26] implement a message-passing communication scheme with a parallel SA (p-SA) algorithm, including one insertion-based heuristic to solve a VRP variant with simultaneous pickup and delivery with time windows. Experimental tests were performed with several Gehring and Homberger benchmark problems and with 65 Wang and Chen benchmark problems. Results show the algorithm effectiveness since it obtains better solutions for 12 Wang and Chen instances, and also reach the best-known solution for the remaining instances.
On the other hand, the use of grid environments to solve optimization problems has been scarcely documented in the existing literature. For example, Fujisawa et al. [
27] describe the use of a clusters grid to solve several optimization problems such as the nonconvex quadratic optimization problem and the semidefinite problem, as well as to solve polynomial systems of equations, and Zunino et al. [
28] introduce a general framework to implement exact optimization algorithms on a grid environment. In particular, Rodriguez-León et al. [
29] implement a parallel GA using a two-stage communication scheme to share the population of candidate solutions in the nodes of an experimental grid with two clusters. First, the populations evolve in each cluster in independent form using point-to-point communication with send/receive methods provided by the MPI library, and then the information exchange between the clusters of the grid is achieved through the FTP protocol using only one node in each cluster. In general, algorithms implemented in grid environments can be classified into two groups: The first one include those developed over the middleware supporting a grid environment such as NetSolve [
30], Condor [
31,
32], Globus [
33], and gLite [
34], and the other are those applied in grids configured as one VPN [
29,
35,
36]. Each one has its advantages and disadvantages. In this work, GGA is implemented in an experimental MiniGrid configured as one VPN to solve VRPTW instances. The main contributions of this work are: (a) The proposed structure for the GGA including the migration scheme of mutated segments between grid nodes, (b) the communication scheme among the clusters of the MiniGrid, using collective communication methods provided by the MPI library, and (c) the use of the grid computing to efficiently solve complex problems. It can be used to solve problems using the total computing capacity (number of cores) of one virtual supercomputer (grid). The resolution of the NP-hard problems is intractable [
37] due to the significant size problem, and the use of many computer resources is required to allow an extensive exploration of the solution space and one full exploitation of promising areas in relatively shorter times. Parallelization of algorithmic processes can lead to improved algorithmic designs for the treatment of these problems. This impact is stronger where computing infrastructure is a constraint in the study of these problems, and the use of several computational clusters to build a grid environment is a viable option in the study of these complex problems.
The rest of this document is structured as follows:
Section 2 describes the VRPTW and the application of metaheuristics to solve this problem. A description of the MiniGrid components is included in
Section 3, and
Section 4 describes the proposed approach for the GA parallelization and its implementation in a grid environment.
Section 5 presents the experimental study. Finally, the results and discussion of this approach are summarized in
Section 6.
3. MiniGrid Infrastructures
Grid computing is an emerging technology where a set of heterogeneously networked resources distributed in geographically dispersed locations are coordinated to provide transparent, dependable, pervasive, and consistent computing support to diverse types of applications [
48]. There are different levels of integration that range from the use of computing resources of two or more organizations to the extensive use of all grid resources [
49].
There are several approaches to build and configure grid environments, and there are many efforts to define general schemes for grid resources exploitation. First, grid environments using Globus, Condor, or gLite are considered high-throughput grids or service grids. These grids manage the resource set (machines or clusters) and distribute the processes among these resources. The service grid’s goal is to provide an abstraction level for the users so that they can use all the grid’s resources while maintaining an adequate security level. Service grids can implement either sequential or parallel applications. On the other hand, the use of a VPN to cluster integration in grid environments avoids the need for specialized packages such as Globus or gLite [
50]. A VPN-based grid can be considered a high-performance grid since it can run parallel applications using the resources of several clusters connected in the grid. A VPN creates an encrypted communication channel between groups to ensure secure data exchange.
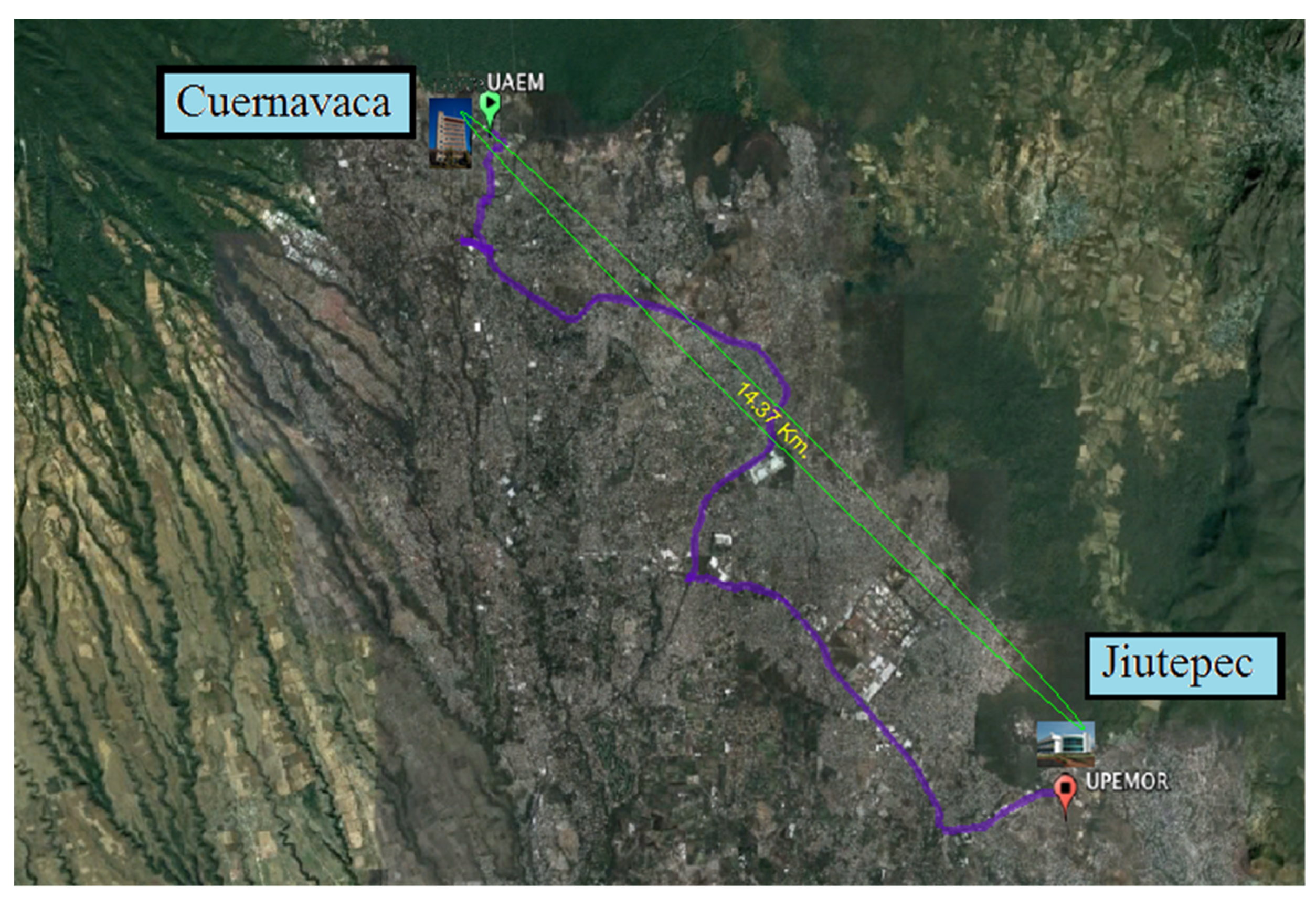
In this work, the MiniGrid is composed of two clusters with homogeneous machines (
Table 3), each belonging to a different organization, geographically distant (14.37 km), as is shown in
Figure 3. One cluster is in the Autonomous University of Morelos State (UAEM), in Cuernavaca city, and the other in the Polytechnic University of Morelos State (UPEMOR), in Jiutepec city, both in the Mexican state of Morelos. In this case, OpenVPN is used to integrate the clusters in a grid environment. Communication between clusters is via a wireless WAN link between institutions (UAEM-UPEMOR) implemented via a point-to-point microwave link with ISM frequency bands with a bandwidth of 30 Mbs [
51]. Message passing interface (MPI) is used to exchange data, and to reduce the communication rate between MiniGrid clusters. MPI has been used to develop applications with both Globus-based grids [
52] and VPN-based environments [
29,
53,
54].
4. Grid-Based Genetic Algorithm to Solve the VRPTW
This paper proposes a grid version of the GA-VRPTW algorithm, named GGA, where the mutation-s operator is applied only to a segment of each population generated in the processes created by the MiniGrid, and a two-stage communication scheme is defined to the result exchanging into the MiniGrid clusters. First, a procedure to combine the mutated segments between cluster nodes is applied, and then the mutated segments are exchanged between the MiniGrid clusters.
4.1. Performance Analysis of the GA-VRPTW Algorithm
Experimental results of the sequential GA-VRPTW algorithm show that it is a very competitive evolutionary algorithm to solve VRPTW instances, but its mutation operator consumes a lot of computing time, as evidenced by his performance analysis (
Figure 4). This performance analysis is based on the running time consumed by the algorithm to solve two Solomon benchmark problems (C101 and C106), using five generations and 100 individuals.
Figure 4 shows that 99.96% of the computation time in the sequential algorithm is used for the mutation-s operator. In contrast, the
best-selection operator uses only 0.04% of the computation time.
Based on these results, the selection and crossover operators are applied to the entire population in each process, but the mutation-s operator modifies only one segment of the population in each MiniGrid process.
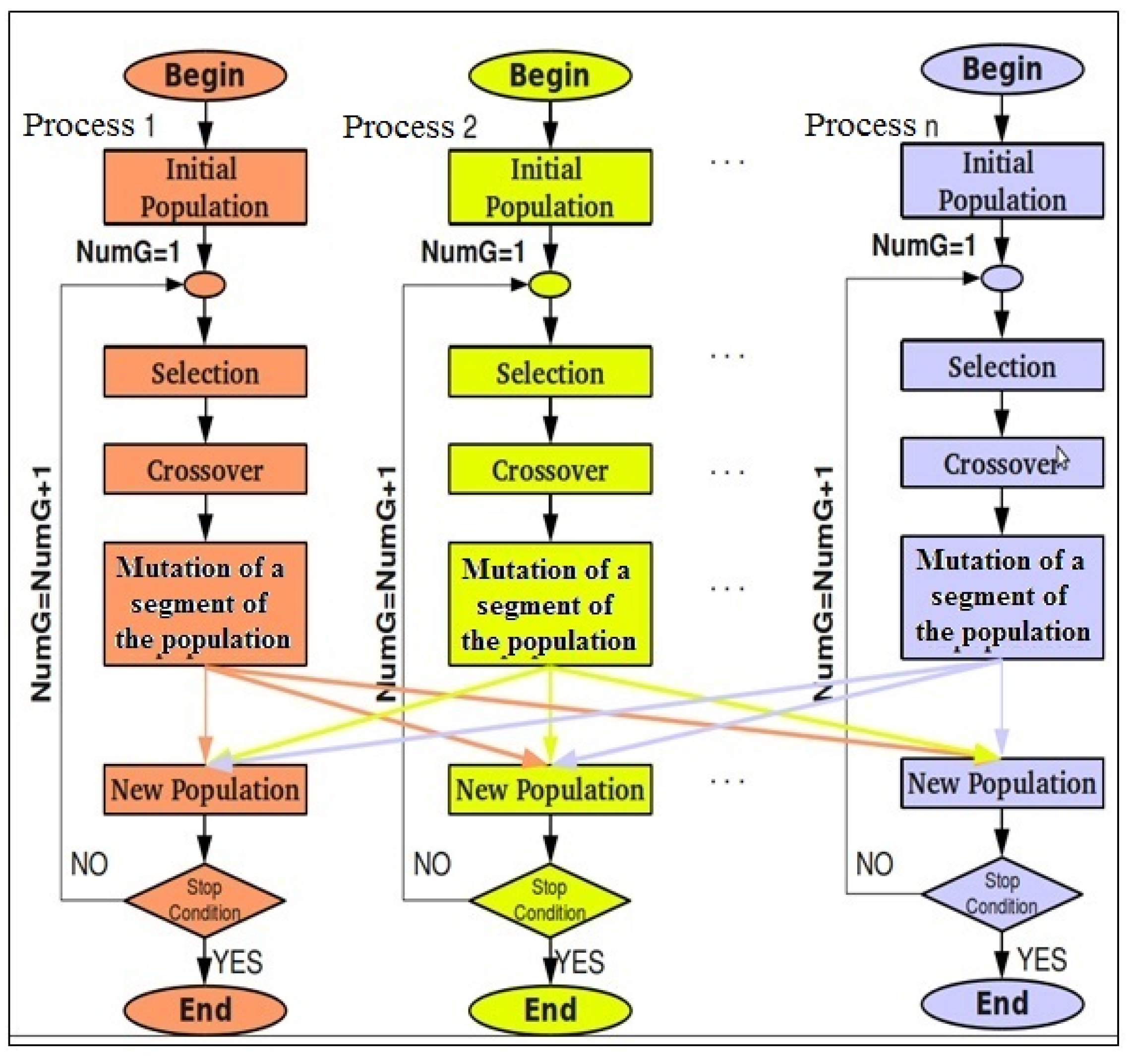
4.2. Grid-based Genetic Algorithm
GGA splits the population of candidate solutions into several segments, which are mutated in each process of the MiniGrid nodes.
Figure 5 shows the general scheme of the algorithm. The population division bounds are defined in Equations (12) and (13).
In Equations (12) and (13), L is the population size, Ni is the i-th node, NN is the number of nodes in the MiniGrid, and res represents the remainder of the division between L and NN.
First, one initial population with only feasible candidate solutions is created in each process of the MiniGrid. Next, these populations evolve until an optimal solution is found, or until a specified number of generations is reached. The genetics operators are applied as follows:
Each process applies both the best-selection operator and the crossover-k operator in the entire population.
The resulting population is split into NN segments, using the Loweri and Upperi values, and the i-th node Ni applies the mutation-s operator in the assigned segment.
Each process sends the mutated segment to the other processes of the MiniGrid. All collected chromosomes are used to build a new population.
The distributed mutation step and the segments migration are conducted in each process of the MiniGrid, allowing the increase in the population diversity, as compared to that of the original GA-VRPTW. For example, if the GGA is running in a MiniGrid with 20 process, using a mutation rate of 80%, and each population has 100 candidate solutions, each process applies the selection and crossover operators in the entire population and the mutation operator js applied with 80 individuals. These mutated individuals migrate to the other 19 processes in a balanced way, i.e., four mutated individuals per population.
4.3. Distribution and Migration of Mutated Segments
To ensure that the mutated segments are shared between the processes created by the MiniGrid, broadcast with MPI_Scatter function is used to distribute the mutated individuals from each process to the rest of the processes. Each process receives the same amount of sent information so the size of the population will be the same in each process of the MiniGrid. For example, in
Figure 6, the MPI_Scatter function distributed the individuals of the population in an equal and parallel manner. The individuals that were stored in an array of structures were distributed to created processes. Each row in the array represents an individual, which is a solution, and a sequence of six customers of the VRPTW. In this example, MPI_Scatter distributed two processes, P1 and P2, in a parallel manner. Individual one was distributed to process P1, and individual two to process P2, and so on. This is done in each process that contains a population of individuals. One process is generally assigned to each core of the MiniGrid, but the MiniGrid can be overloaded so that there is more than one process per core. Each process can only read the population that it owns and can only be responsible for distributing information to each of the remaining processes.
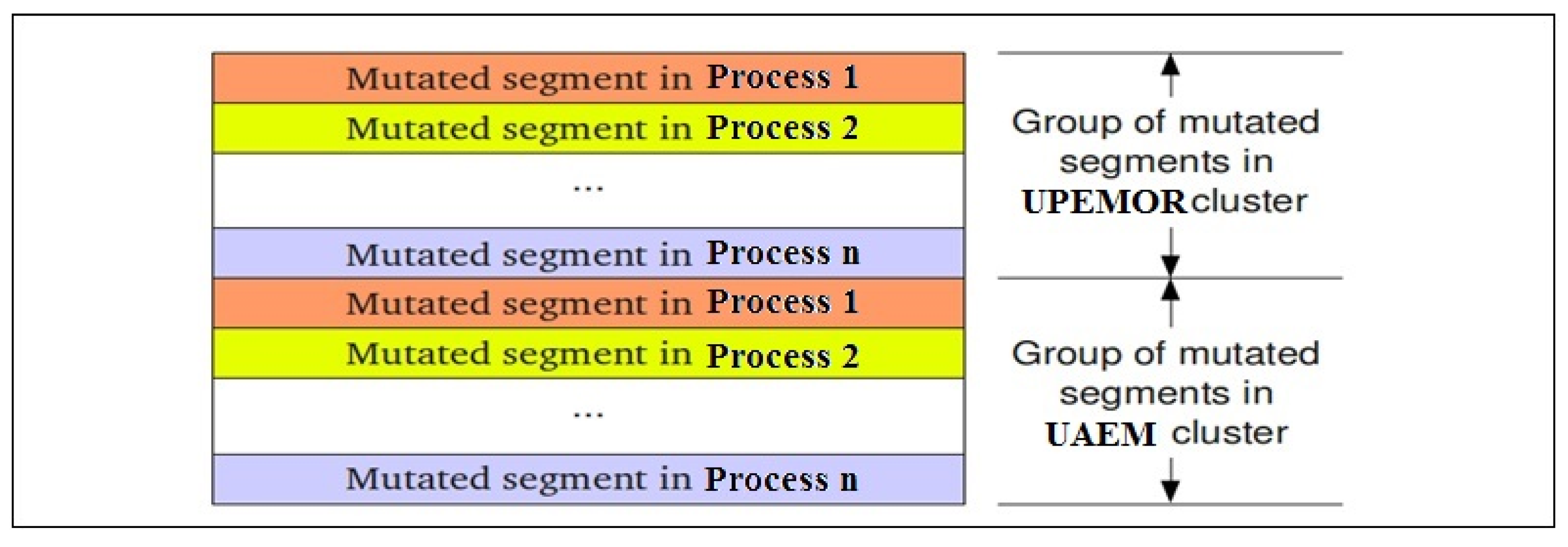
Figure 7 shows the general scheme of this distribution stage, where S1 is the mutated segment of process 1, s2 is the mutated segment of process 2, and so on. Each process only alters the population assigned to it and, at the end of its mutation stage, must send the mutated segment to the other processes. One process is generally associated with each MiniGrid core, but the environment can be overloaded so that one core can run more than one process.
Figure 8 shows the final population created after applying the distributed mutation and conducting the segments migration between the MiniGrid processes.
In GGA, the exploitation rate is high since each MiniGrid process carries out a specialized mutation in conjunction with one iterative local search to improve the quality of the candidate solutions. Furthermore, since a different population evolves in each process by means of one independent recombination, the exploration of new candidate solutions is conducted in different areas of the solution space.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}