Lexicon-Enhanced Attention Network Based on Text Representation for Sentiment Classification

Abstract
:
1. Introduction
- We propose a lexicon-enhanced attention mechanism in the word embedding module that combines the common sentiment lexicon with the attention mechanism so as to incorporate sentiment linguistic knowledge into deep learning methods.
- We introduce a multi-head attention mechanism in the deep neural network module to learn the contextual information from different representation subspaces at different positions, so that our model can generate the high-quality representation of text.
- We stack an attention-based neural network to construct a document-level hierarchical model for sentiment classification. On the basis of hierarchical structure, we can effectively integrate sentiment linguistic knowledge into document-level representation for large-scale text sentiment classification.
- We conduct extensive experiments to evaluate the performance of text sentiment classification on four real-world datasets at both the sentence level and the document level. The experimental results demonstrate that the proposed models can achieve substantial improvements over the state-of-the-art baselines on 3 out of 4 datasets.
2. Related Work
2.1. Statistical Machine Learning-Based Model
2.2. Deep Learning-Based Model
2.3. Attention Mechanism
3. Methodology
3.1. Task Definition and Notation
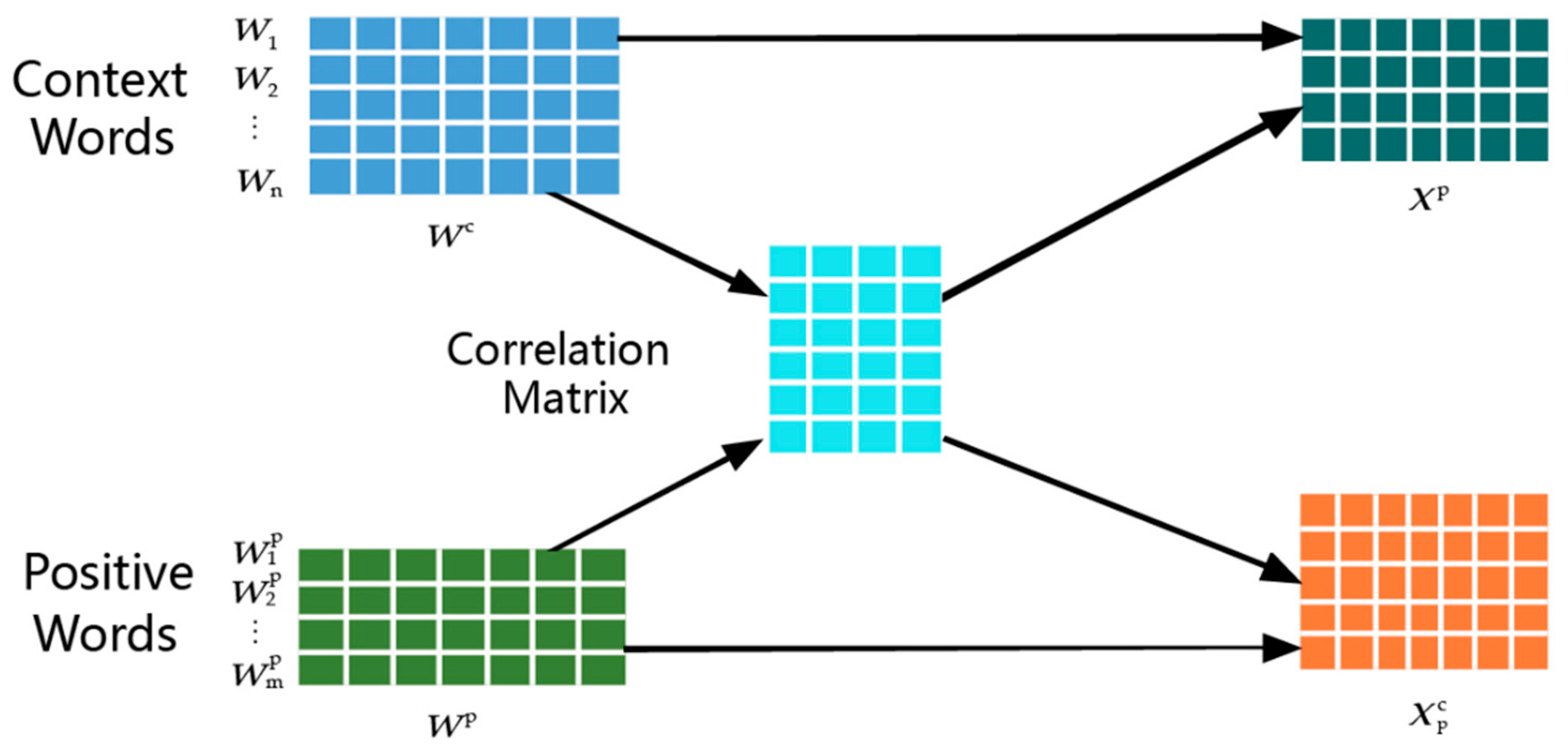
3.2. Word Embedding Module Based on Lexicon-enhanced Attention Mechanism
3.3. Deep Neural Network Module Based on Multi-head Attention Mechanism
3.4. Hierarchical Lexicon-Enhanced Attention Network
3.5. Text Classifier Module
4. Experiments
4.1. Datasets and Evaluation Metrics
- Movie Review (MR) collected by Pang and Lee [43] is an authoritative movie review dataset for binary sentiment classification task, in which each review contains only one sentence. The corpus has 5331 negative samples and 5331 positive samples.
- Stanford Sentiment Treebank (SST) is an extended sentence-level version of the MR dataset proposed by Socher et al. [44], where each sentence is annotated as very positive, positive, neutral, negative, or very negative. To effectively avoid the poor generalization ability caused by the uneven distribution of samples, this dataset follows the same sample distribution of the MR dataset.
- Internet Movie Database (IMDB) proposed by Maas et al. [45] is a representative dataset for document-level sentiment classification task, which contains a large amount of movie reviews and recommendations with binary classes (i.e., positive and negative). It is made up of 50,000 movie reviews, and each movie review has several sentences.
- Yelp2013 obtained from the Yelp Dataset Challenge in 2013 [46], is another popular document-level sentiment classification dataset, which includes large-scale restaurant reviews labeled with five levels of ratings from 1 to 5 (i.e., very positive, positive, neutral, negative, and very negative).
4.2. Implementation Details
4.3. Baseline Methods
- SVM [24]: A classic support vector machine classifier applied in text sentiment classification, which is trained with the following groups of features: n-grams, lexicon features, and part-of-speech tags.
- CNN [29]: Convolutional neural network consists of multiple one-dimensional convolution filters and a max pooling layer. This structure can capture the local features inside a multi-dimensional field to generate context-aware text representation.
- LSTM [32]: The standard recurrent neural network based on long short-term memory unit uses the last hidden state as the representation of the whole text, which can extract sequential correlation information in the raw text.
- CNN-LSTM [31]: A deep neural network combines kernel from multiple branches of CNN with LSTM, which can extract local features within the raw text and sequence information across the raw text.
- Tree-LSTM [34]: Tree-structured long short-term memory network utilizes pre-defined syntax tree structure as external knowledge to guide the training of LSTM network. It can better learn the representation of text from the syntax perspective.
- LR-Bi-LSTM [35]: Linguistically regularized-based bidirectional long short-term memory network is similar to Tree-LSTM, except that linguistic regularization is used as external knowledge to the intermediate outputs of bidirectional LSTM network with KL divergence.
- LE-LSTM [17]: Lexicon-enhanced LSTM network which uses sentiment lexicon as an extra information to train a sentiment-based word embedding and then combines the sentiment embedding with its word embedding to make word representation more accurate.
- LSTM-GRNN [49]: Hierarchical neural network which consists of a LSTM-based word encoder and a GRU-based sentence encoder for document-level sentiment classification task.
- Self-attention [50]: A self-attention mechanism and a special regularization term are integrated into deep neural networks to construct sentence embedding for sentiment classification task.
- HAN [37]: Hierarchical attention network for document-level sentiment classification which progressively builds a document vector aggregating important words into a sentence and then aggregating important sentences vector into document vectors.
4.4. Experimental Results
4.4.1. Overall Performance
4.4.2. Effects of the Dimension of Sentiment Resource Words
4.4.3. Effects of the Length of Document
4.4.4. Visualization of Sentence Representation
4.4.5. Visualization of Document Representation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ren, F.; Wu, Y. Predicting User Topic Opinions in Twitter with Social and Topical Context. IEEE Trans. Affect. Comput. 2013, 4, 412–424. [Google Scholar] [CrossRef]
- Li, Z.; Guo, H.; Wang, W.M. A Blockchain and AutoML Approach for Open and Automated Customer Service. IEEE Trans. Ind. Inform. 2019, 15, 3642–3651. [Google Scholar] [CrossRef]
- Gao, Y.; Zhen, Y.; Li, H. Filtering of Brand-related Microblogs using Discriminative Social-Aware Multiview Embedding. IEEE Trans. Multimed. 2016, 18, 2115–2126. [Google Scholar] [CrossRef]
- Kim, Y.; Shim, K. TWILITE: A recommendation system for Twitter using a probabilistic model based on latent Dirichlet allocation. Inf. Syst. 2014, 42, 59–77. [Google Scholar] [CrossRef]
- Abdul, A.; Chen, J.; Liao, H.Y.; Chang, S.H. An Emotion-Aware Personalized Music Recommendation System Using a Convolutional Neural Networks Approach. Appl. Sci. 2018, 8, 1103. [Google Scholar] [CrossRef]
- Bing, L. Sentiment Analysis and Opinion Mining. In Encyclopedia of Machine Learning and Data Mining; Springer: Boston, MA, USA, 2012; Volume 30, p. 167. [Google Scholar]
- Damashek, M. Gauging Similarity with n-Grams: Language-Independent Categorization of Text. Science 1995, 267, 843–848. [Google Scholar] [CrossRef]
- Zhao, R.; Mao, K. Fuzzy Bag of Words Model for Document Representation. IEEE Trans. Fuzzy Syst. 2018, 26, 794–804. [Google Scholar] [CrossRef]
- Wu, H.C.; Luk, R.W.P.; Wong, K.F. Interpreting TF-IDF term weights as making relevance decisions. ACM Trans. Inf. Syst. 2008, 26, 1–37. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Tom, Y.; Devamanyu, H.; Soujanya, P. Recent Trends in Deep Learning Based Natural Language Processing Review Article. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar]
- Li, H. Deep learning for natural language processing: Advantages and challenges. Natl. Sci. Rev. 2018, 5, 28–30. [Google Scholar] [CrossRef]
- Nal, K.; Edward, G.; Phil, B. A convolutional neural network for modelling sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; pp. 655–665. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Lin, Q.; Yong, C.; Nie, Z. Learning word representation considering proximity and ambiguity. In Proceedings of the Twenty-eighth AAAI Conference on Artificial Intelligence, Québec City, QB, Canada, 27–31 July 2014; pp. 1572–1578. [Google Scholar]
- Tang, D.; Wei, F.; Qin, B. Sentiment Embeddings with Applications to Sentiment Analysis. IEEE Trans. Knowl. Data Eng. 2016, 28, 496–509. [Google Scholar] [CrossRef]
- Fu, X.; Yang, J.; Li, J. Lexicon-enhanced LSTM with Attention for General Sentiment Analysis. IEEE Access 2018, 6, 71884–71891. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Tian, S. Feature selection for text classification with Naïve Bayes. Expert Syst. Appl. 2009, 36, 5432–5435. [Google Scholar] [CrossRef]
- Wawre, S.V.; Deshmukh, S.N. Sentiment classification using machine learning techniques. Int. J. Sci. Res 2016, 5, 819–821. [Google Scholar]
- Lee, L.H.; Wan, C.H.; Rajkumar, R. An enhanced Support Vector Machine classification framework by using Euclidean distance function for text document categorization. Appl. Intell. 2012, 37, 80–99. [Google Scholar] [CrossRef]
- Tang, D.; Wei, F.; Qin, B.; Zhou, M.; Liu, T. Building Large-Scale Twitter-Specific Sentiment Lexicon: A Representation Learning Approach. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 172–182. [Google Scholar]
- Kang, H.; Yoo, S.J.; Han, D. Senti-lexicon and improved Naïve Bayes algorithms for sentiment analysis of restaurant reviews. Expert Syst. Appl. 2012, 39, 6000–6010. [Google Scholar] [CrossRef]
- Chien, B.C.; He, S.Y. A Lexical Decision Tree Scheme for Supporting Schema Matching. Int. J. Inf. Technol. Decis. Mak. 2011, 10, 519–537. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Saif, M. Detecting aspects and sentiment in customer reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 437–442. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Deep Learning for Sentiment Analysis: Successful Approaches and Future Challenges. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 292–303. [Google Scholar] [CrossRef]
- Tang, D.; Zhang, M. Deep Learning in Sentiment Analysis. In Deep Learning in Natural Language Processing; Deng, L., Liu, Y., Eds.; Springer: Singapore, 2018; pp. 219–253. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Zhang, X.; Zhao, J.; Lecun, Y. Character-level Convolutional Networks for Text Classification. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Alec, Y.; Abhishek, V. Deep CNN-LSTM with combined kernels from multiple branches for IMDb review sentiment analysis. In Proceedings of the 8th IEEE Annual Ubiquitous Computing, Electronics and Mobile Communication Conference, New York, NY, USA, 19–21 October 2017; pp. 540–546. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Bahdanau, C.F.; Bougares, H.; Bengio, Y. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X. Target-Dependent Sentiment Classification with Long Short Term Memory. Comput. Sci. 2015, 24, 74–82. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 30–31 July 2015; pp. 1556–1566. [Google Scholar]
- Qian, Q.; Huang, M.; Lei, J. Linguistically Regularized LSTMs for Sentiment Classification. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1679–1689. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Zhou, X.J.; Wan, X.J.; Xiao, J.G. Attention-based LSTM network for cross-lingual sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 247–256. [Google Scholar]
- Gui, L.; Du, J.; Xu, R. Stance Classification with Target-specific Neural Attention. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3988–3994. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. SentiWordNet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the International Conference on Language Resources and Evaluation, Valletta, Malta, 17–23 May 2010; pp. 83–90. [Google Scholar]
- Warriner, A.B.; Kuperman, V.; Brysbaert, M. Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav. Res. Methods 2013, 45, 1191–1207. [Google Scholar] [CrossRef] [Green Version]
- Sukhbaatar, S.; Weston, J.; Fergus, R. End-to-end memory networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2440–2448. [Google Scholar]
- Pang, B.; Lee, L. A Sentimental Education: Sentiment Analysis Using Subjectivity, Summarization Based on Minimum Cuts. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 271–278. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.Y.; Chuang, J.; Manning, C.D.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; Volume 1631, p. 1642. [Google Scholar]
- Andrew, L.; Maas, R.E.; Daly, P.T.; Pham, D.H.; Andrew, Y.N.; Christopher, P. Learning word vectors for sentiment analysis. In Proceedings of the 49nd Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Learning semantic representations of users and products for document level sentiment classification. In Proceedings of the 53nd Annual Meeting of the Association for Computational Linguistics, Beijing, China, 26–31 July 2015; pp. 1014–1023. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; Mcclosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Kinga, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference of Learning Representation, San Diego, CA, USA, 7–9 May 2015; p. 115. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 7–21 September 2015; pp. 1422–1432. [Google Scholar]
- Gui, L.; Zhou, Y.; Xu, R.; He, Y.; Lu, Q. Learning representations from heterogeneous network for sentiment classification of product reviews. Knowl. Based Syst. 2017, 124, 34–45. [Google Scholar] [CrossRef] [Green Version]
- Graves, A. Long Short-Term Memory; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1735–1780. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | C | L | Train | Dev | Test | V |
|---|---|---|---|---|---|---|---|
| MR | Sentence | 2 | 21 | 10,662 | - | CV | 20,191 |
| SST | Sentence | 5 | 18 | 8544 | 1101 | 2210 | 17,836 |
| IMDB | Document | 2 | 126 | 25,000 | - | 25,000 | 106,249 |
| Yelp2013 | Document | 5 | 179 | 62,522 | 7773 | 8671 | 73,691 |
| Models | MR | SST | IMDB | Yelp2013 | ||||
|---|---|---|---|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | |
| SVM | 76.4 | 78.8 | 40.7 # | 42.4 | 79.8 | 81.7 | 57.6 | 59.4 |
| CNN | 81.5 # | 82.7 | 48.0 # | 49.3 | 87.0 # | 88.3 | 59.7 # | 61.4 |
| LSTM | 77.4 # | 79.6 | 46.4 # | 47.6 | 86.2 # | 88.7 | 62.0 | 63.6 |
| CNN-LSTM | - | - | - | - | 89.5 # | 90.2 | - | - |
| Tree-LSTM | 80.7 # | 82.2 | 50.1 # | 51.8 | 88.0 # | 89.3 | 64.6 | 66.9 |
| LR-Bi-LSTM | 82.1 # | 83.6 | 50.6 # | 52.3 | - | - | - | - |
| LSTM-GRNN | - | - | - | - | 88.2 | 89.5 | 65.1 # | 67.2 |
| LE-LSTM | 80.8 # | 82.4 | - | - | 89.6 # | 90.9 | 60.6 # | 62.7 |
| HAN | - | - | - | - | 88.6 | 89.8 | 68.2 # | 70.1 |
| Self-attention | 81.7 | 82.9 | 48.9 | 50.1 | - | - | - | - |
| H-LAN | - | - | - | - | 89.5 | 90.6 | 68.7 | 70.8 |
| LAN | 83.9 | 85.0 | 51.3 | 52.9 | - | - | - | - |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Li, D.; Yin, H.; Zhang, L.; Zhu, Z.; Liu, P. Lexicon-Enhanced Attention Network Based on Text Representation for Sentiment Classification. Appl. Sci. 2019, 9, 3717. https://doi.org/10.3390/app9183717
Li W, Li D, Yin H, Zhang L, Zhu Z, Liu P. Lexicon-Enhanced Attention Network Based on Text Representation for Sentiment Classification. Applied Sciences. 2019; 9(18):3717. https://doi.org/10.3390/app9183717
Chicago/Turabian StyleLi, Wenkuan, Dongyuan Li, Hongxia Yin, Lindong Zhang, Zhenfang Zhu, and Peiyu Liu. 2019. "Lexicon-Enhanced Attention Network Based on Text Representation for Sentiment Classification" Applied Sciences 9, no. 18: 3717. https://doi.org/10.3390/app9183717
APA StyleLi, W., Li, D., Yin, H., Zhang, L., Zhu, Z., & Liu, P. (2019). Lexicon-Enhanced Attention Network Based on Text Representation for Sentiment Classification. Applied Sciences, 9(18), 3717. https://doi.org/10.3390/app9183717