Classification of Inter-Floor Noise Type/Position Via Convolutional Neural Network-Based Supervised Learning †



Abstract
:1. Introduction
1.1. Research Motivation
1.2. Related Literature
1.3. Research Approach
1.4. Contributions of this Paper
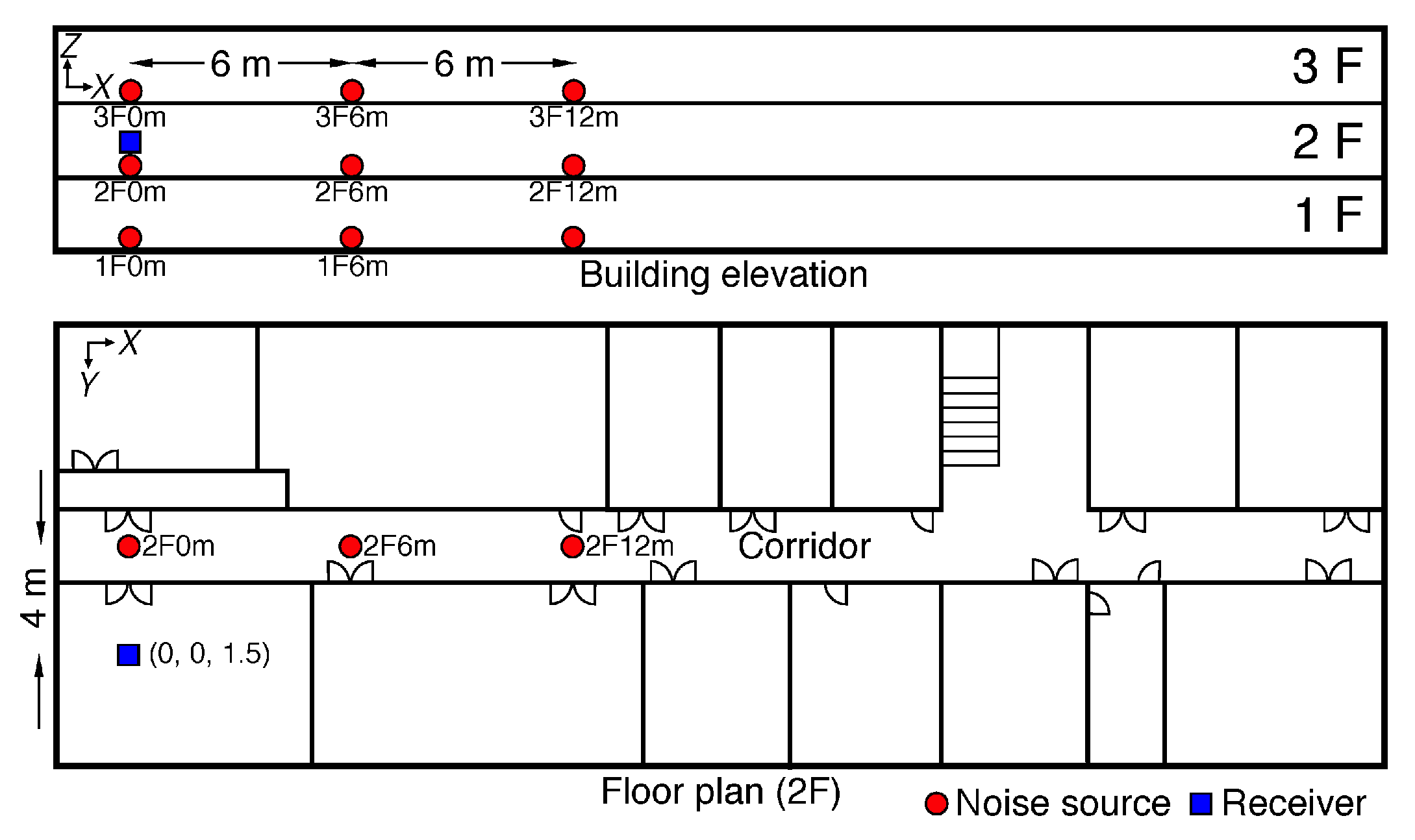
2. Inter-Floor Noise Dataset
2.1. Selecting Type and Position of Noise Source
2.2. Generating and Collecting Inter-Floor Noise
3. Supervised Learning of Inter-Floor Noises
3.1. Convolutional Neural Networks for Acoustic Scene Classification
3.2. Network Architecture
3.3. Evaluation
3.4. Type Classification Results
3.5. Position Classification Results
4. Type/Position Classification of Inter-Floor Noises Generated on Unlearned Positions
4.1. Type Classification of Inter-Floor Noises Generated from Unlearned Positions
4.2. Position Classification of Inter-Floor Noises Generated from Unlearned Positions
5. Summary and Future Study
Author Contributions
Funding
Conflicts of Interest
References
- Jeon, J.Y. Subjective evaluation of floor impact noise based on the model of ACF/IACF. J. Sound Vib. 2001, 10, 147–155. [Google Scholar] [CrossRef]
- Jeon, J.Y.; Ryu, J.K.; Lee, P.J. A quantification model of overall dissatisfaction with indoor noise environment in residential buildings. Appl. Acoust. 2010, 71, 914–921. [Google Scholar] [CrossRef]
- Ryu, J.; Sato, H.; Kurakata, K.; Hiramitsu, A.; Tanaka, M.; Hirota, T. Relation between annoyance and single-number quantities for rating heavy-weight floor impact sound insulation in wooden houses. J. Acoust. Soc. Am. 2011, 129, 3047–3055. [Google Scholar] [CrossRef] [PubMed]
- Park, S.H.; Lee, P.J.; Yang, K.S.; Kim, K.W. Relationships between non-acoustic factors and subjective reactions to floor impact noise in apartment buildings. J. Acoust. Soc. Am. 2016, 139, 1158–1167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Statistics Korea. 2015 Population and Housing Census. Available online: http://www.census.go.kr/dat/ysr/ysrList.do?q_menu=5&q_sub=7 (accessed on 28 February 2019).
- Shin, J.; Song, H.; Shin, Y. Analysis on the characteristic of living noise in residential buildings. J. Korea Inst. Build. Constr. 2015, 15, 123–131. [Google Scholar] [CrossRef]
- Floor Noise Management Center. Monthly Report (March 2018). Available online: http://www.noiseinfo.or.kr/about/data_view.jsp?boardNo=199&keyfield=whole&keyword=&pg=2 (accessed on 28 December 2018).
- Poston, J.D.; Buehrer, R.M.; Tarazaga, P.A. Indoor footstep localization from structural dynamics instrumentation. Mech. Syst. Signal Process. 2017, 88, 224–239. [Google Scholar] [CrossRef]
- Bahroun, R.; Michel, O.; Frassati, F.; Carmona, M.; Lacoume, J.L. New algorithm for footstep localization using seismic sensors in an indoor environment. J. Sound Vib. 2014, 333, 1046–1066. [Google Scholar] [CrossRef] [Green Version]
- Mirshekari, M.; Pan, S.; Fagert, J.; Schooler, E.M.; Zhang, P.; Noh, H.Y. Occupant localization using footstep-induced structural vibration. Mech. Syst. Signal Process. 2018, 112, 77–97. [Google Scholar] [CrossRef]
- Peck, L.; Lacombe, J. Seismic-based personnel detection. In Proceedings of the 41st Annual IEEE International Carnahan Conference on Security Technology, Ottawa, ON, Canada, 8–11 October 2007; pp. 77–97. [Google Scholar]
- Sabatier, J.M.; Ekimov, A.E. Range limitation for seismic footstep detection. In Proceedings of the Unattended Ground, Sea, and Air Sensor Technologies and Applications X, Orlando, FL, USA, 16–20 March 2008; p. 69630. [Google Scholar]
- Choi, H.; Lee, S.; Yang, H.; Seong, W. Classification of noise between floors in a building using pre-trained deep convolutional neural networks. In Proceedings of the 16th International Workshop on Acoustic Signal Enhancement (IWAENC), Tokyo, Japan, 17–20 September 2018; pp. 535–539. [Google Scholar]
- Choi, H.; Lee, S.; Yang, H.; Seong, W. SNU-B36-50. Available online: http://github.com/yodacatmeow/SNU-B36-50 (accessed on 10 January 2019).
- Jeon, J.Y.; Ryu, J.K.; Jeong, J.H.; Tachibana, H. Review of the impact ball in evaluating floor impact sound. Acta. Acust. United Ac. 2006, 92, 777–786. [Google Scholar]
- The Ministry of Land, Infrastructure and Transport Korea. Statistics of Housing Construction (Construction Consent). Available online: http://kosis.kr/statHtml/statHtml.do?orgId=116&tblId=DT_MLTM_564&conn_path=I2 (accessed on 24 June 2019).
- The Seoul Institute. Construction Consent. Available online: http://data.si.re.kr/node/344 (accessed on 24 June 2019).
- Samsung Electronics. Galaxy S6. Available online: https://www.samsung.com/global/galaxy/galaxys6/galaxy-s6 (accessed on 10 January 2019).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Proc. Let. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P.; Farnsworth, A.; Kelling, S. Fusing shallow and deep learning for bioacoustic bird species classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 141–145. [Google Scholar]
- Ibrahim, A.K.; Zhuang, H.; Chérubin, L.M.; Schärer-Umpierre, M.T.; Erdol, N. Automatic classification of grouper species by their sounds using deep neural networks. J. Acoust. Soc. Am. 2018, 144, EL196–EL202. [Google Scholar] [CrossRef] [Green Version]
- Plumbley, M.D.; Kroos, C.; Bello, J.P.; Richard, G.; Ellis, D.P.; Mesaros, A. Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018). In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), Surrey, UK, 19–20 November 2018. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the Proceedings of the 14th python in science conference (SCIPY), Austin, TX, USA, 6–12 July 2015; pp. 18–25. [Google Scholar]
- Chu, S.; Narayanan, S.; Kuo, C.-C.J. Environmental sound recognition with time–frequency audio features. IEEE/ACM Trans. Audio Speech Lang. Process. 2009, 17, 1142–1158. [Google Scholar] [CrossRef]
- Rakotomamonjy, A.; Gasso, G. Histogram of gradients of time-frequency representations for audio scene classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 142–153. [Google Scholar]
- Khunarsal, P.; Lursinsap, C.; Raicharoen, T. Very short time environmental sound classification based on spectrogram pattern matching. Inf. Sci. 2013, 243, 57–74. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Representation learning. In Deep Learning; Dietterich, T., Bishop, C., Heckerman, D., Jordan, M., Kearns, M., Eds.; The MIT Press: Cambridge, MA, USA; London, UK, 2017; pp. 517–547. [Google Scholar]
- Amiriparian, S.; Gerczuk, M.; Ottl, S.; Cummins, N.; Freitag, M.; Pugachevskiy, S.; Baird, A.; Schuller, B. Snore sound classification using image-based deep spectrum features. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 3512–3516. [Google Scholar]
- Ren, Z.; Cummins, N.; Pandit, V.; Han, J.; Qian, K.; Schuller, B. Learning image-based representations for heart sound classification. In Proceedings of the Proceedings of the 2018 International Conference on Digital Health, Lyon, France, 23–26 April 2018; pp. 143–147. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Available online: https://www.tensorflow.org (accessed on 10 January 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1026–1034. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Choi, H.; Yang, H.; Lee, S.; Seong, W. Inter-Floor Noise Classification. Available online: https://github.com/yodacatmeow/indoor-noise/tree/master/inter-floor-noise-classification (accessed on 25 April 2019).
- Choi, H.; Yang, H.; Lee, S.; Seong, W. SNU-B36-50E. Available online: https://github.com/yodacatmeow/indoor-noise/tree/master/indoor-noise-set/SNU-B36-50E (accessed on 9 August 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1F0m | 1F6m | 1F12m | 2F0m | 2F6m | 2F12m | 3F0m | 3F6m | 3F12m | |
|---|---|---|---|---|---|---|---|---|---|
| MB | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| HD | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| HH | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| CD | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| VC | 50 | 50 | 50 |
| MB | HD | HH | CD | VC | Average | |
|---|---|---|---|---|---|---|
| AlexNet | 98.7 | 99.1 | 99.8 | 99.6 | 100 | 99.3 |
| VGG16 | 99.3 | 99.1 | 99.8 | 99.8 | 100 | 99.5 |
| ResNet V1 50 | 95.8 | 95.8 | 97.6 | 96.4 | 96.7 | 96.7 |
| 1F0m | 1F6m | 1F12m | 2F0m | 2F6m | 2F12m | 3F0m | 3F6m | 3F12m | Average | |
|---|---|---|---|---|---|---|---|---|---|---|
| AlexNet | 85.5 | 79.5 | 95.0 | 100 | 98.0 | 99.2 | 96.0 | 92.0 | 95.5 | 93.8 |
| VGG16 | 86.0 | 89.5 | 96.5 | 100 | 96.0 | 98.4 | 95.5 | 95.0 | 99.0 | 95.3 |
| ResNet V1 50 | 80.0 | 73.0 | 86.5 | 92.4 | 86.4 | 92.8 | 87.5 | 82.0 | 87.0 | 85.7 |
| 1F | 2F | 3F | Average | |
|---|---|---|---|---|
| AlexNet | 98.7 | 100.0 | 98.8 | 99.2 |
| VGG16 | 99.0 | 100.0 | 99.5 | 99.5 |
| ResNet V1 50 | 95.8 | 98.5 | 95.2 | 96.7 |
| 3F1m | 3F2m | 3F3m | 3F4m | 3F5m | 3F7m | 3F8m | 3F9m | 3F10m | 3F11m | |
|---|---|---|---|---|---|---|---|---|---|---|
| MB | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| HH | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| Predicted Label | ||||||
|---|---|---|---|---|---|---|
| MB | HD | HH | CD | VC | ||
| True label | MB | 97.7 | 0.00 | 1.20 | 1.10 | 0.00 |
| HH | 0.60 | 0.00 | 99.4 | 0.00 | 0.00 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, H.; Yang, H.; Lee, S.; Seong, W. Classification of Inter-Floor Noise Type/Position Via Convolutional Neural Network-Based Supervised Learning. Appl. Sci. 2019, 9, 3735. https://doi.org/10.3390/app9183735
Choi H, Yang H, Lee S, Seong W. Classification of Inter-Floor Noise Type/Position Via Convolutional Neural Network-Based Supervised Learning. Applied Sciences. 2019; 9(18):3735. https://doi.org/10.3390/app9183735
Chicago/Turabian StyleChoi, Hwiyong, Haesang Yang, Seungjun Lee, and Woojae Seong. 2019. "Classification of Inter-Floor Noise Type/Position Via Convolutional Neural Network-Based Supervised Learning" Applied Sciences 9, no. 18: 3735. https://doi.org/10.3390/app9183735
APA StyleChoi, H., Yang, H., Lee, S., & Seong, W. (2019). Classification of Inter-Floor Noise Type/Position Via Convolutional Neural Network-Based Supervised Learning. Applied Sciences, 9(18), 3735. https://doi.org/10.3390/app9183735