1. Introduction
Classification is one of the most important techniques for solving problems [
1,
2]. Infinitely many problems can be viewed as classification problems. In daily life, telling a female person from a male one is a classification problem, which is probably one of the earliest problems people face to solve. Giving grades to a class of students could be an uneasy classification task for a teacher to work with. Deciding the disease a patient may have based on the symptoms is a difficult classification task for a doctor. Classification is also useful in engineering applications [
3,
4,
5,
6], e.g., mechanical systems, mechanics and design innovations, applied materials in nanotechnologies, etc. For example, classification of structures, systems, and components is very important to safety for fusion applications [
7]. The product quality has been found to be influenced by the engineering design, type of materials selected, and the processing technology employed. Therefore, classification of engineering materials and processing techniques is an important aspect of engineering design and analysis [
8].
In general, classification consists of two phases, training and testing, as shown in
Figure 1. In the training phase, a collection of labeled objects is given. After attribute extraction, a set of training instances is obtained, and they are used to train a model. In the testing phase, the trained model is used to evaluate any input objects to determine which categories the input objects belong to. Normally, there are
m categories,
, such as Medicine, Finance, History, Management, and Education, involved in the multi-class classification problem [
9]. The data to be dealt with can be either single-label or multi-label. If the given object belongs to one category, it is called single-label classification. On the other hand, it is called multi-label classification if the given object can belong to two or more categories [
10,
11].
In this paper, multi-class classification is concerned with a given set of N training instances,
, where
, , is the input vector of instance i. There are n attributes, with real attribute values in .
, is the input vector of instance i. There are m, , categories, category 1, category 2,…, category m. For instance, i, if the instance belongs to category j and if the instance does not belong to category j, .
Note that indicates the k-vector . The aim of this paper is, given the set of N training instances, to decide which categories a given input vector, , belongs to. For single-label classification, one and only one +1 appears in every target vector, while for multi-label classification, two or more entries in any target vector can be allowed to be +1.
Traditionally, statistical methods were used for multi-class classification [
12,
13]. Recently, machine learning techniques have been proposed for solving the multi-class classification problem. The decision tree (DT) algorithm [
14,
15] uses a tree structure with if-then rules, running the input values through a series of decisions until it reaches a termination condition. It is highly intuitive, but it can easily overfit the data. Random forest (RandForest) [
16] creates an ensemble of decision trees and can reduce the problem of overfitting. The naive Bayesian classifier [
2] is a probability-based classifier. It calculates the likelihood that each data point exists in each of the target categories. It is easily implemented but may be sensitive to the characteristics of the attributes involved. The k-Nearest neighbor (KNN) algorithm [
17,
18,
19] classifies each data point by analyzing its nearest neighbors among the training examples. It is intuitive and easily implemented. However, it is computationally intensive.
Neural networks are another machine learning technique, carrying out the classification work by passing the input values through multiple layers of neurons that can perform nonlinear transformations on the data. A neural network derives its computing power mainly through its massively parallel, distributed structure and its ability of learning and generalization, which make it possible for neural networks to find good approximate solutions to complex problems that are intractable. There are many types of neural networks. Perhaps the most common one is multiple-layer perceptrons (MLPs). An MLP is a class of fully connected, feedforward neural network, consisting of an input layer, an output layer, and a certain number of hidden layers [
20,
21]. Each node is a neuron associated with a nonlinear activation function, and the gradient descent backpropagation algorithm is adopted to train the weights and biases involved in the network. In general, trial-and-error is needed to determine the number of hidden layers and the number of neurons in each hidden layer, and long learning time is required by the backpropagation algorithm. Support vector machines (SVMs) are models with associated learning algorithms that analyze data used for classification [
22,
23,
24]. Training instances of the separate categories are divided by a gap as wide as possible. One disadvantage is that several key parameters need to be set correctly for SVMs to achieve good classification results. Other limitations include the speed in training and the optimal design for multi-class SVM classifiers [
25]. Recently, deep learning neural networks have successfully been applied to analyzing visual imagery [
26,
27,
28]. They impose less burden on the user compared to other classification algorithms. The independence from prior knowledge and human effort in feature design is a major advantage. However, deep learning networks are computationally expensive. A large dataset for training is required. Hyperparameter tuning is non-trivial.
The radial basis function (RBF) network is another type of neural network for multi-class classification problems. Broomhead and Lowe [
29] were the first to develop the RBF network model. An RBF network is a two-layer network. In the first layer, the distances between the input vector and the centers of the basis functions are calculated. The second layer is a standard linearly weighted layer. While MLP uses global activation functions, RBF uses local basis functions, which means that the outputs are close to zero for a point that is far away from the center points. There are pros and cons with RBF networks. The configuration of hyper-parameters, e.g., the fixed number of layers and the choice of basis functions, is much simpler than that of MLP, SVM, or CNN. Unlike the MLP network, RBF can have fewer problems with local minima and the local basis functions adopted by RBF can lead to faster training [
30]. Also, the local basis functions can be very useful for adaptive training, in which the network continues to be incrementally trained while it is being used. For new training data coming from a certain region of the input space, the weights of those neurons will not be adjusted if the neurons fall outside that region. However, because of locality, basis centers of the RBF network must be spread throughout the range of the input space. This leads to the problem of the curse of dimensionality and there is a greater likelihood that the network will overfit the training data [
31].
In this paper, we develop RBF-based neural network schemes for single-label and multi-label classification, respectively. The number of hidden nodes, as well as the centers and deviations associated with them, in the first layer of RBF networks are determined automatically by applying an iterative self-constructing clustering algorithm to the given training dataset. The weights and biases in the second layer are derived optimally by least squares. Also, dimensionality reduction techniques, e.g., information gain, mutual information, and linear discriminant analysis (LDA), are developed and integrated to reduce the curse of dimensionality to avoid the overfitting problem associated with the RBF networks. The rest of this paper is organized as follows. The RBF-based network schemes for multi-class classification are proposed and described in
Section 2. Techniques for reducing the curse of dimensionality are given in
Section 3. Experimental results from benchmark datasets to demonstrate the effectiveness of the proposed schemes are presented in
Section 4. Finally, conclusions and future work are commented in
Section 5.
2. Proposed Network Schemes
In this section, we first describe the proposed RBF-based network schemes. Then, we describe how to construct the RBF networks involved in the schemes, followed by the learning of the parameters associated with the RBF networks.
2.1. RBF-Based Network Schemes
Two schemes, named SL-Scheme and ML-Scheme, are developed. SL-Scheme, as shown in
Figure 2, is for single-label multi-class classification. Note that M-RBF is a multi-class RBF network. The competitive activation function [
31], compet, is used in
Figure 2 at all the output nodes, defined as
Note that compet could also be defined as a continuous function like the competitive layer in a Hamming network. Namely, the neurons compete with each other to determine a winner and only the winner will have a nonzero output. The winning neuron indicates which category of input was presented to the network. Both definitions can achieve the same goal.
The architecture of M-RBF is shown in
Figure 3. There are
n nodes in the input layer,
J nodes in the hidden layer, and
m nodes in the second layer of M-RBF. Each node
j in the hidden layer of M-RBF is associated with a basis function
. For a given input vector
p, node
j in the hidden layer of M-RBF has its output as
for
. Node
i in the second layer of M-RBF has its output as
where
is the bias of the output node and
are the weights between node
i of the second layer and node
j of the hidden layer. Then,
is computed. If the
kth output of
is +1, i.e.,
,
p is classified to category
k.
ML-Scheme, as shown in
Figure 4, is used for multi-label multi-class classification. Note that the symmetrical hard limit activation function [
31], hardlims, is used at every output node, defined as
To predict the classifications of any input vector
p, we calculate the network output
, as
If for any i, p is classified to category i. Therefore, p can be classified to several categories.
2.2. Construction and Learning of RBF Networks
Next, we describe how the M-RBF network is constructed. In a neural network application, one has to try many possible values of hyper-parameters and select the best configuration of hyper-parameters. Typically, hyper-parameters include the number of hidden layers, the number of nodes in each hidden layer, the activation functions involved, the learning algorithms used, etc. Several methods can be used to tune hyper-parameters, such as manual hyper-parameter tuning, grid search, random search, and Bayesian optimization. For MLPs and CNNs, many different activation functions can be used, e.g., symmetrical hard limit, linear, saturating linear, log-sigmoid, hyperbolic tangent sigmoid, positive linear, competitive, etc. The networks can be trained by many different learning algorithms. Also, the number of hidden layers and the number of hidden nodes can vary in a wide range. This may lead to a huge search space, and thus finding the best configuration of hyper-parameters from it is a very inefficient and tedious tuning process.
Determining the hyper-parameters is comparatively easier for RBF networks. An RBF is a two-layer network, i.e., containing only one hidden layer. Clustering techniques, e.g., a self-constructing clustering algorithm, can be applied to determine the number of hidden neurons. There are several types of activation function that can be used, but the Gaussian function is the one most commonly used. RBF networks can be trained by the same learning techniques used in MLPs. However, they are commonly trained by a more efficient two-stage learning algorithm. In the first stage, the centers and deviations in the first layer are found by clustering. In the second stage, the weights and biases associated with the second layer are calculated by least squares. In summary, regarding the configuration of hyper-parameters, (1) the number of layers, i.e., two layers, the Gaussian basis function, the least squares method, and the activation functions associated with the output layer are the decisions taken, and (2) the number of neurons in the hidden layer is the customized parameter and is determined by clustering.
Here, we describe how the multi-class RBF network, M-RBF, is constructed and trained. Firstly, the training instances are divided, by the iterative self-constructing clustering algorithm (SCC) [
32] briefly summarized in the
Appendix A, into
J clusters each having center
and deviation
,
. Then, the hidden layer in M-RBF
i has
J hidden nodes. The basis function
of node
j in the hidden layer of M-RBF is the Gaussian function
for
. Note that several different types of basis function can be used [
29], but Gaussian is the one most commonly used in the neural network community.
The settings for
,
, …,
,
, are optimally derived as follows. For training instance
,
, let
In this way, for each
i,
, we have
N equations, which are expressed as
with
Then, we have the following cost function:
By minimizing the cost function with the linear least squares method [
33], we obtain the optimal bias and weights for M-RBF as
for
.
2.3. An Illustration
An example is given here for illustration. Suppose we have a single-label application with 3 categories, having 12 training instances:
Note that
n = 2 and
m = 3. We apply SCC to these training instances. Let
be 0.001. Three clusters are obtained:
Then, we build the M-RBF network with 2 input nodes (
n = 2), 3 hidden nodes (
J = 3), and 3 output nodes (
m = 3). From Equation (14), the settings for
,
,
are optimally derived by
The detailed SL-Scheme for this example is shown in
Figure 5.
For the input vector
p = (0.4, 0.5), we have
,
, and
. Consequently, we have
Since is the largest, through the competitive transfer function we have ,
, and . Therefore, o(p) = (+1, −1, −1) and p is classified to category 1.
5. Conclusions and Future Work
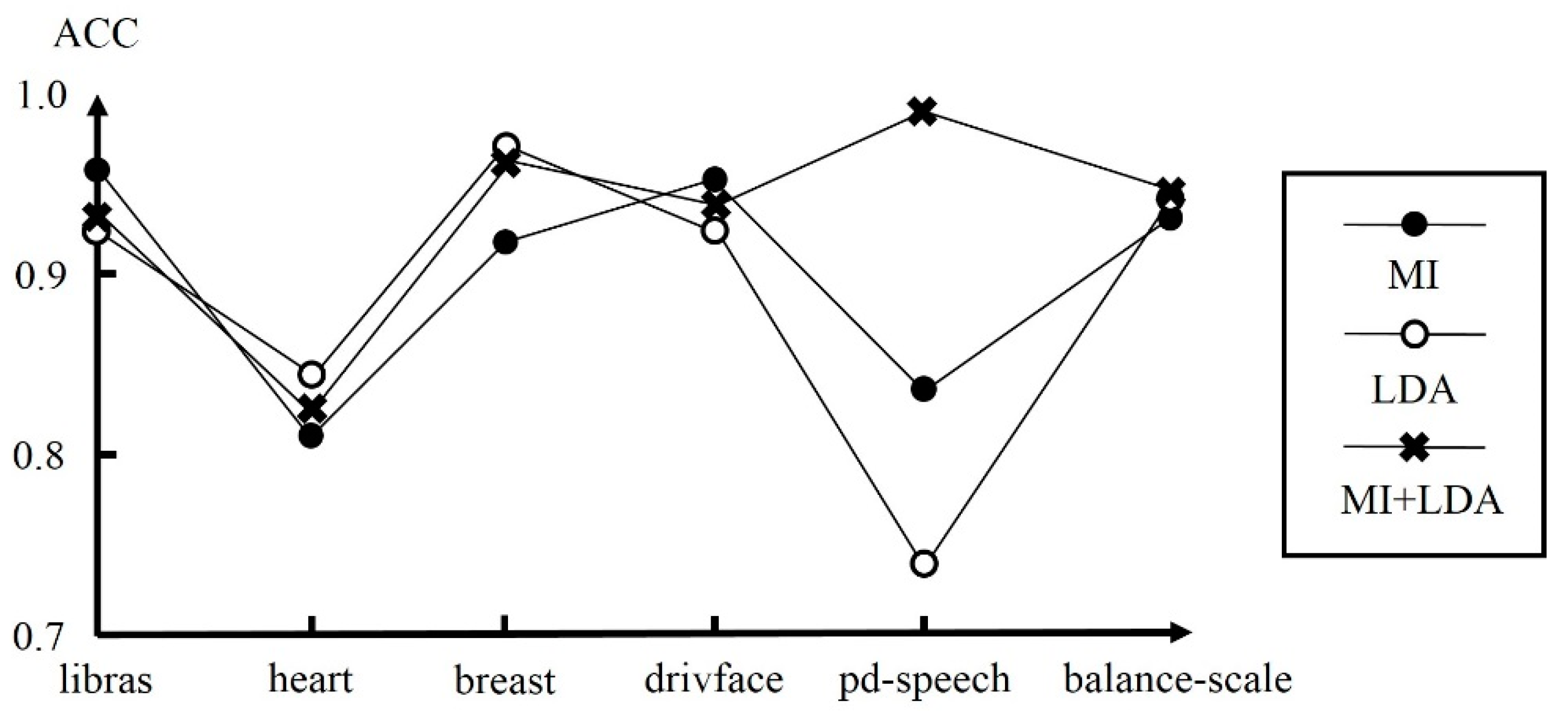
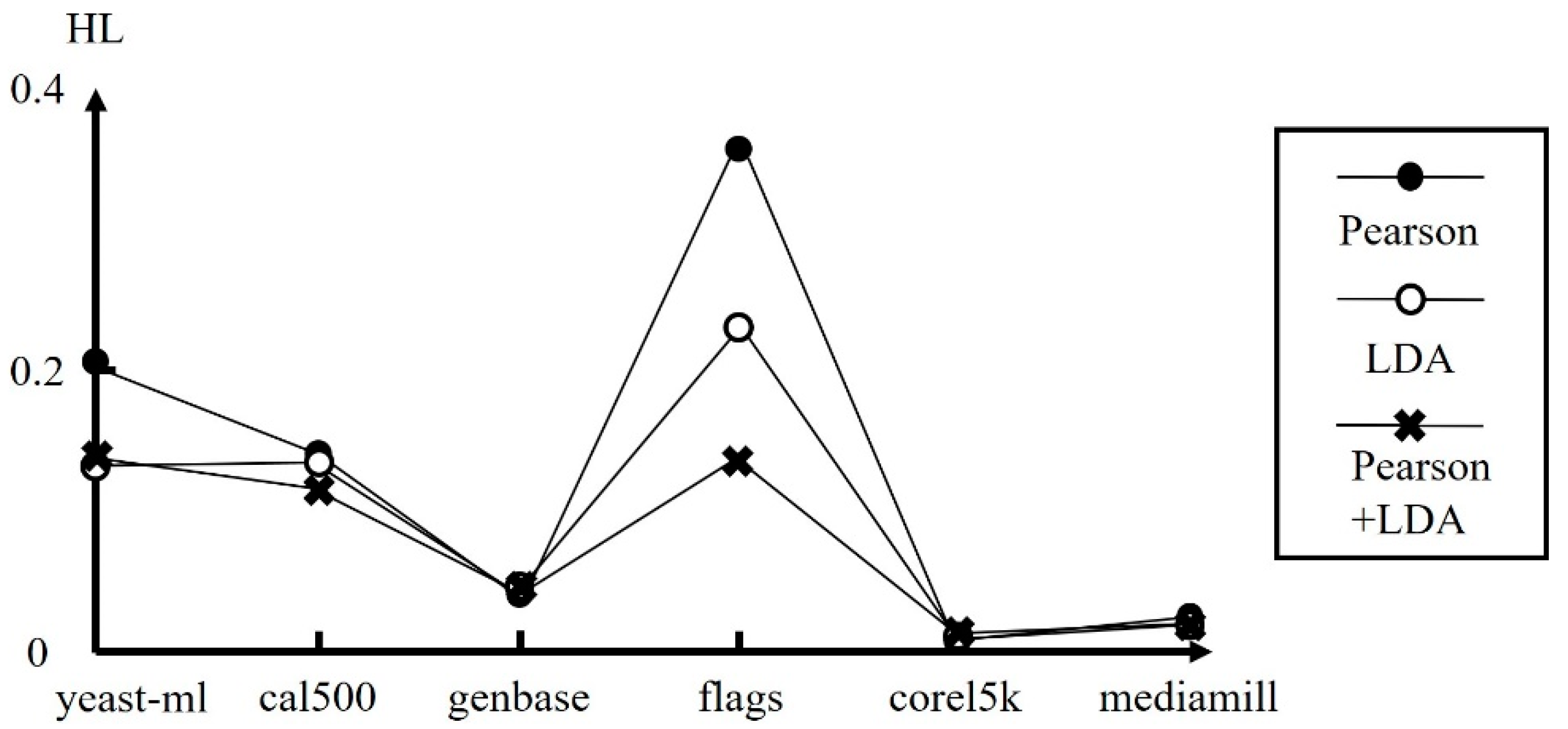
We adopt radial basis function (RBF) networks for multi-class classification. RBF networks are two-layer networks with only one hidden layer and can have fewer problems with local minima and learn faster. We have described how the configuration of hyper-parameters is decided and how the curse of dimensionality is reduced for RBF networks. We use an iterative self-constructing clustering to determine the number of hidden neurons. The centers and deviations of the basis functions can also be determined from the clustered results. We have presented several techniques, mutual information, Pearson correlation, information gain, and LDA, to reduce the dimensionality of the inputs to make the RBF networks less likely to overfit.
We have presented two RBF-based neural network schemes for multi-class classification. The first scheme, SL-Scheme, is for single-label multi-class classification. The competitive activation function is used with the output nodes. As a result, an input object can be classified to only one category. The second scheme, ML-Scheme, is for multi-label multi-class classification. The symmetrical hard limit activation function is used with the output nodes. An input object can therefore be classified to two or more categories.
In addition to the techniques adopted, ensemble classification [
47,
48] can also be applied to deal with the curse of dimensionality problem. An ensemble of classifiers, each of which deals with a small subset of attributes, are created from a given dataset. For an unseen instance, the predicted classifications of the instance for each of the classifiers is computed. By combining the outputs of all the classifiers, the final predicted classifications for the unseen instance is determined. Intuitively, the ensemble of classifiers as a whole can provide a higher level of classification accuracy than any one of the individual classifiers. Overfitting can be improved by reducing the number of hidden nodes in the first layer. Given the basis functions obtained by the SCC clustering algorithm, the orthogonal least squares (OLS) technique [
31] can be applied to select the most effective ones. Firstly, the basis function, which creates the largest reduction in error, is selected. Then, one basis function is added at a time until some stopping criterion is met. Furthermore, nested cross validation [
49] can be applied to help determine the best configuration of hyperparameters for RBF networks. The total dataset is split in
k sets. One by one, a set is selected as the outer test set and the
k-1 other sets are combined as the corresponding outer training set. Each outer training set is further sub-divided into
sets, and each time a set is selected as the inner test set and the
other sets are combined as the corresponding inner training set. For each outer training set, the best values of the hyperparameters are obtained from the inner cross-validation, and the performance of the underlying RBF model is then evaluated using the outer test set. We will investigate these techniques in our future research.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}