1. Introduction
Anomalies in Smart-Meter (SM) data, due to a malfunction of the meter or a theft from users, cause a major problem for electric companies [
1]. In this regard, in recent years, many research efforts have been devoted to the development of specific computational algorithms that would be able to quickly identify the anomaly with high accuracy. Among the different approaches presented in the literature, the most interesting ones are those based on computational intelligence, such as Deep Neural Networks (DNNs), clustering [
1], and those based on linear programming [
2].
Recently, promising techniques are developed by exploiting deep learning approaches [
3]. In fact, when correctly trained on the available recorded data, these methods are able to attain high accuracy [
4]. However, since a deep architecture consists in the cascade of several computational layers, the resulting layered structure usually makes the training phase difficult, due to vanishing gradient problem among others [
4]. To overcome this problem, a layer-wise pretraining solution, followed by a fine-tuning of the resultant whole architecture, was proposed in the literature. This method provides good results in practical applications [
5].
In all cases, approaches based on deep learning suffer high computational complexity, since very large architectures with a huge number of parameters have to be trained [
5]. A (partial) solution to this problem is to resort to the Cloud Computing (CC) paradigm, that enables the ubiquitous access to large-size pools of virtualized computing resources by establishing (typically) multi-hop wireless communication paths [
6]. Although CC offers a huge computational capability, it is characterized by its high energy consumption [
7].
The quite recent paradigm of Fog Computing (FC) can help to overcome this problem [
7,
8]. In fact, by definition, FC enables the pervasive local access to distributed and
virtualized small-size energy-saving pools of computing resources that can be quickly provisioned, dynamically scaled up/down and released on an on-demand basis. Nearby resource-limited edge devices (e.g., SMs) may access these resources by establishing single-hop WiFi-supported communication links [
7]. Hence, in principle, virtualized Fog nodes could be exploited in a distributed way to implement the unsupervised pretraining of the layer of a deep architecture. The (possible) supervised final fine-tuning of the whole SDAE can be performed by a CC node, being this phase of centralized type.
However, a potential problem of multi-tier architectures (composed of devices, Fog nodes and Cloud nodes) is the considerable amount of energy wasted by the networking resources needed for inter-node communication. Also in this case, in literature there exist some solutions being able to optimize the total energy consumption, such as the Genetic Algorithm (GA) [
9]. Hence, it is reasonable to expect that the exploitation of the Fog architecture, along with the distributed pretraining procedure, could reduce the energy consumption with respect to solutions based on the use of the Cloud only.
Motivated by these considerations, the contribution of this paper is threefold:
we introduce a Stacked Denoising Auto-Encoder (SDAE) architecture for the anomaly detection of SM data, and exploit the FC to implement the distributed pretraining of the SDAE layers;
we engineer the overall networked Fog infrastructure, in order to minimize the total communication-plus-computing energy wasted by the proposed anomaly detector; and,
we design a new Adaptive Elitist GA (AEGA) to optimize the mapping of the SDAE layers to be pretrained to the available Fog nodes, in order to meet the aforementioned energy minimization tasks. The adaptive mechanism implemented by the proposed AEGA makes it robust against trapping phenomena generated by the attraction basins of local minima of the underlying objective function and, then, reduces the resulting convergence time.
The rest of the paper is organized as follows. After a review of the related work in
Section 2, in
Section 3, we present the overall architecture of the SmartFog platform, while, in
Section 4, we point out the formal models adopted for the analytical evaluation of the resulting computing and networking energy. In
Section 5, we present the main design principles behind the proposed AEGA and, then, we detail the AEGA pseudo-code.
Section 6 is devoted to numerically testing the performance of the resulting optimized SmartFog platform in terms of detection accuracy, execution time and energy consumption. For this purpose, the results of performance comparisons against some competing state-of-the-art benchmark solutions are also presented. Finally, in
Section 7, we recap the main contributions of this paper and point out some areas for future research.
2. Related Work
It is expected that the convergence of the DNN and FC paradigms will be fostered by the results stemming from (at least) three on-going research lines, namely [
10]: (i) the design of anomaly detection algorithms; (ii) the design and optimization of hierarchically organized multi-tier Fog platforms; and, (iii) the development of “ad hoc” algorithms for the supervised distributed training of DNNs.
Anomaly detection algorithms exploiting DNNs—A very challenging issue when dealing with SM data is represented by the early detection of anomalies. In this regard, the literature offers several contributions, like [
11,
12,
13,
14].
Specifically, the work in [
11] is focused on a Bayesian approach for the segmentation of data sequences and the identification of anomalies based on an empirical estimate of the recurrent behavior of observed changepoints. Paper [
12] provides a comparative analysis of some traditional “shallow” machine learning algorithms (like k-NN, MLP and SVM), which were used to classify measurements as regular or anomaly. In this work, well-known batch and online learning algorithms (both supervised and semisupervised) were employed to cope with the anomaly detection problem. Differently from our paper, works in [
11,
12] do not exploit deep learning and do not take account of the distribution of the detection algorithm over several Fog nodes.
More recently, another line of research is addressed towards deep learning techniques, e.g., see [
13,
14] and references therein. Specifically, the work in [
13] integrates a DNN with a cyber-physical protocol to identify and mitigate the information corruption in sensor-acquired data. The proposed technique exploits unsupervised training based on Deep Belief Networks (DBN). The authors in [
14] propose a real-time detection of anomalies in Smart Grid by using an architecture based on Conditional Deep Belief Networks (CDBNs). This work is also characterized by a model that copes with the limited number of available measurements. Differently from our paper, works in [
13,
14] are based on DBNs that exhibit a slow convergence behavior and high computational costs, while we focus on the use of SDAE that retains a good compromise between convergence speed and computational cost.
Overall,
unlike our paper, works in [
11,
12,
13,
14] and references therein do not take account of the accuracy-vs.-energy performance over a distributed and virtualized networked Fog platform, deeply investigated in this paper.
Multi-tier Fog Computing platforms for the support of DNNs—The general topic of the design of multi-tier FC platforms is receiving large attention, mainly due to the emerging areas of the Mobile Cloud, Pervasive Computing and Edge Computing [
15,
16]. For the most part, these contributions focus on the energy-efficient (and, typically, time-constrained) offloading of (parts of) application programs from mobile devices to nearby FC servers through the exploitation of WiFi/Cellular-based communication technologies (see, for example, [
17] and references therein for an updated overview of this topic).
Up to now, a few papers [
18,
19,
20,
21] are devoted, indeed, to the novel area of the integration of DNN models onto FC platforms. In this regard, the authors of [
19] developed a proof of concept that aims at deploying DNNs onto Fog nodes for ML-based health prognosis. The underlying driving principle is to perform a suitable search among the candidate Fog nodes, in order to find free nodes with sufficient spare resources to delegate mining tasks. The work in [
20] proposes an ecosystem that exploits the synergic cooperation of mobile devices and Fog nodes running DNN models for fast object recognition. In [
21], a DNN-based face recognition application is simulated and the obtained performance exhibits reduced mining time when smartphones’ photos are processed by proximate Fog nodes as opposed to the remote Cloud. The work in [
18] generalizes this result, and gives some numerical evidence that the exploitation of Fog platforms for the joint fusion and distributed mining of sensor-acquired data may reduce the processing time and the energy-bandwidth consumption with respect to the corresponding fully centralized implementation of DNN models at the remote Cloud data centers. Overall, like our paper, these contributions test the feasibility of FC platforms for the distributed execution of DNN models under various operating conditions. However,
unlike our paper, they do not formally address the problem of the optimized mapping of the computing tasks needed to support the DNN models for distributed Fog platforms.
3. The Proposed SmartFog Platform
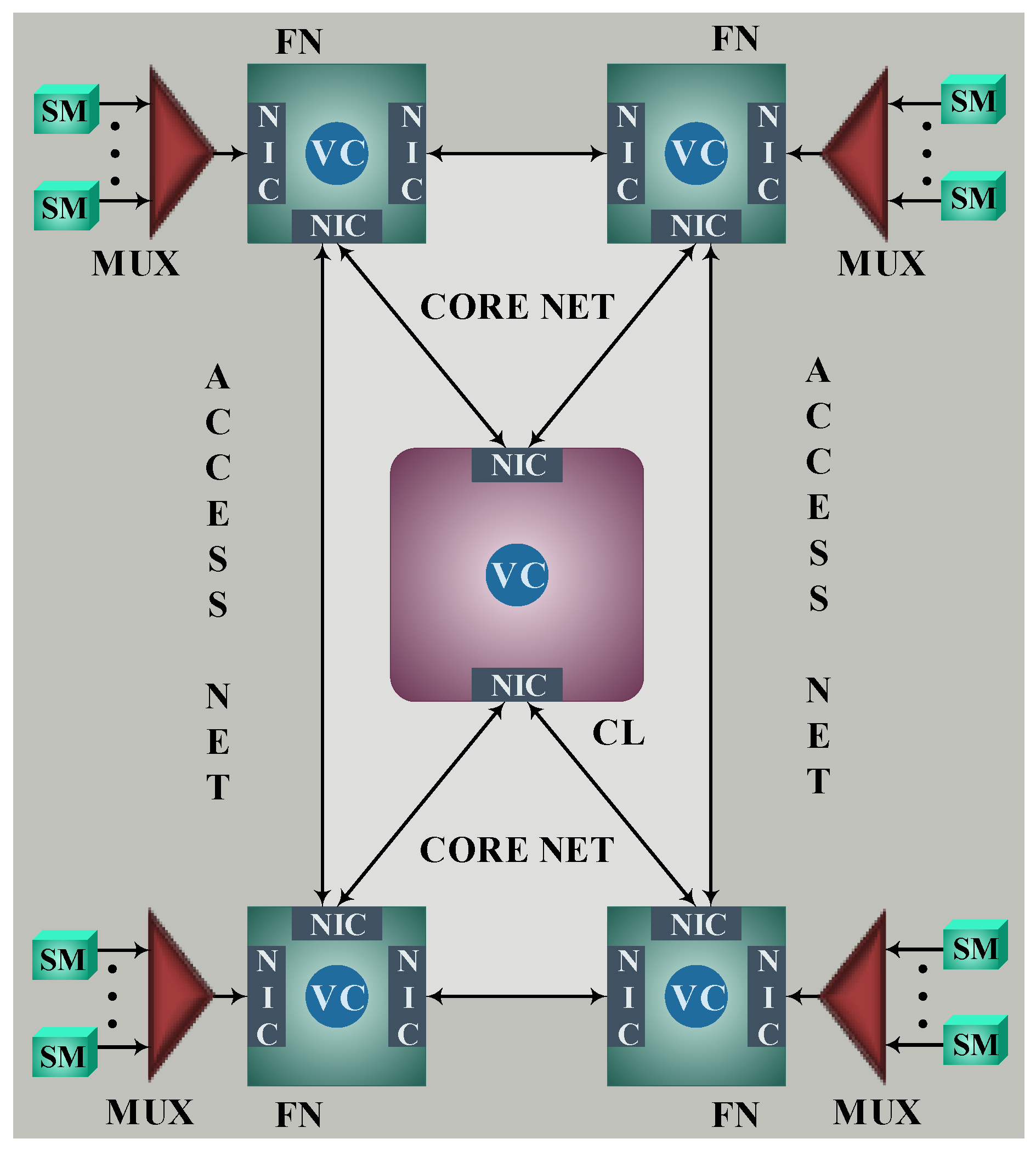
The proposed SmartFog technological platform is sketched in
Figure 1. It consists of
N virtualized Fog nodes and a virtualized Cloud node that can communicate with each other and the SMs through a set of Network Interface Cards (NICs). Each Fog node can gather data measurements from several SMs by using a Multiplexer (MUX). It uses an SDAE [
3,
4,
5] for data analytics and a networked Fog platform for SDAE pretraining and execution.
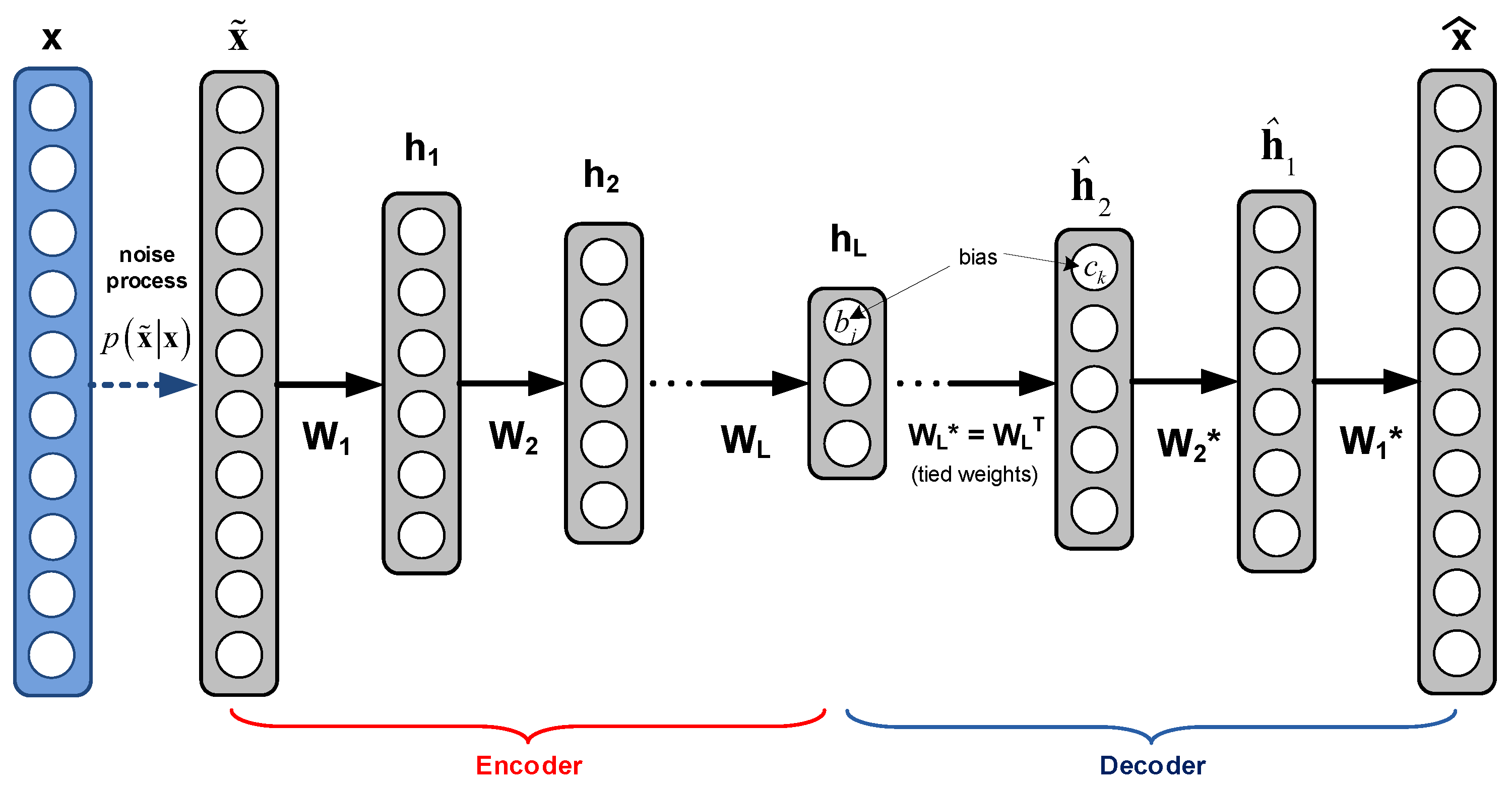
In this regard, we shortly point out that a Stacked Auto-Encoder (SAE) is a feed-forward neural network with
hidden layers trained to (quasi)
reproduce its input at the output layer (see
Figure 2). The aim of an SAE is to learn a compressed and distributed representation
(
encoding) for a set of (possibly, noisy) input data
(typically for the purpose of dimensionality reduction), using a set of weight matrices
,
. Then, an estimate
of the data
is recovered (
decoding) by using tied weights (i.e.,
), as depicted in
Figure 2 [
4]. As a robust variant, the Stacked
Denoising Auto-Encoder (SDAE) [
5] is a stochastic version of the SAE, where a stochastically corrupted
version of the input
is employed to feed the SAE (usually, using a Gaussian additive noise), while the uncorrupted input
is still used as the target for the optimization of the weight matrices (see
Figure 2).
As shown in
Figure 2, the computation of the
k-th layer in the encoding phase is performed according to the following relationship [
5]:
With
, while the companion decoding layer acts as follows [
5]:
In Equations (
1) and (
2),
is the weight matrix of the
k-th layer of the considered SDAE,
and
are the bias vectors of the encoder and decoder at the
k-th layer,
is the element-wise nonlinear activation function of the
k-th layer of the encoder (e.g., sigmoid or ReLU) and
. The decoder transformation in (
2) is of affine type due to the continuous-valued nature of the input vector
.
The unsupervised pretraining of such an architecture is done on a per-layer basis [
5]. Specifically, each layer is trained as a denoising auto-encoder by minimizing with respect to
,
and
the total squared reconstruction error:
where
t is the batch index [
5] and
is the
t-th batch of the input vector at layer
k. In our framework, the minimization of (
3) is pursued by applying the Adam algorithm, a variant of the stochastic gradient descent that is based on the adaptive estimation of the first and second order moments of the gradient of (
3) with respect to weights and bias of
Figure 2 [
4].
A
k-NN classifier [
4] is used atop the final hidden representation
to detect whether or not the input
contains an anomaly. The implemented classifier is binary and its output is 0 for “no anomalies” while it is 1 for “anomalies” detected in the data
. The
k-NN classifier assigns the input to the class with most examples among the
k neighbors of the input. All neighbors have equal vote, and the class with the maximum number of votes among the
k neighbors is selected. For this purpose, similarity is defined according to a suitable distance metric (usually the Euclidean one) between two data points.
4. Implementing SDAE over the Computing Nodes of SmartFog
To perform the per-layer pretraining over the available Fog and Cloud nodes of
Figure 1, we propose a (novel) adaptive version of the elitist GA [
9]. The goal is to minimize the total computing-plus-networking energy consumed by the resulting SmartFog platform of
Figure 1. Specifically, in the implemented GA, the chromosome is the vector
containing the
L indexes of the involved computing nodes. The goodness of each chromosome
is measured through an appropriate fitness function. In each generation, a set of elements is selected by comparing their fitness, the best element is retained, a fraction of the “best” elements of the current population is recombined through crossover, while the remaining “worst” elements are modified by randomly mutating each one over randomly selected positions. For this purpose, the implemented Crossover function generates a random pointer to the location index at which the crossover is performed and, then, carries out the corresponding swapping [
4]. After generating a random vector of pointers to the locations to be mutated, the Mutation function returns the generated mutated values at the pointed locations of the vector
. The fitness function used by SmartFog is the
inverse of the total computing-plus-networking energy
consumed by the SmartFog platform for the execution of these operations. It equates to [
7]:
According to the clone-based virtualized Fog architecture detailed in [
7], in (
4), we have that: (i)
is the power consumed by the virtual clone at the
j-th Fog node for the computing; (ii)
is the power consumed by the
j-th Fog node in the idle state; (iii)
is the power consumed by the virtual clone at the
j-th Fog node for the communication with the SM, the Cloud node and/or with other Fog nodes; and, (iv)
is the power consumed by the
j-th network card in the idle state, while the related
is the execution time of state
j. The power consumed by the computing nodes of
Figure 1 for computing and networking is proportional to the squared values of the CPU frequencies and communication bandwidths [
7]. Detailed analytical models for the evaluation of the computing/networking power present in (
4) are developed in [
7] and, for the sake of brevity, are not replicated here.
5. The Proposed Adaptive Elitist GA
A main advantage of the (previously mentioned) elitist mechanism is that it guarantees that, by design, the “best” chromosome delivered at the current iteration is also
globally the best chromosome generated up to the current iteration [
22]. This implies that, in our framework, the sequence of the energy returned by the Elitist GA is guaranteed to exhibit a non-increasing behavior. However, this pro is typically counterbalanced by one major disadvantage. In fact, elitism is, by design, a conservative strategy that tends to enhance the exploitation capability of the GA by reducing the corresponding exploration capability [
22]. This means, in turn, that elitist GAs tend to be trapped by the local minima of the underlying objective functions and, then, they are slow to converge [
22].
Motivated by these considerations, we propose a suitable Adaptive version of the standard Elitist GA (namely the AEGA), whose ultimate goal is to attain an improved trade-off between the two contrasting requirements of high exploitation and exploration capabilities.
Algorithm 1 reports a pseudo-code of the proposed AEGA, together with a description of its input, output and local variables. Roughly speaking, the following main design principles are on the basis of the proposed AEGA:
the size of the full population to be generated at each iteration is specified as an input parameter and it is held constant (see the list of the input parameters of Algorithm 1). However, the sizes and of the sub-lists of the elite chromosomes and the crossed over-plus-mutated chromosomes are adaptively updated at each iteration. The goal is to adaptively balance the exploitation-vs.-exploration capabilities of the resulting AEGA (see the “for” statement at line #7 of Algorithm 1), while guaranteeing that the summation: remains equal to (see lines #14 and #18 of Algorithm 1);
at each iteration, the relative (absolute) gap: between the energy and returned by the AEGA at the current iteration and the previous one is used for indicating if the algorithm is trapped by the attraction basin of an already explored local minimum or is just entering the still unexplored attraction basin of the new local minimum (see the two “if” statements at lines #12 and #16 of Algorithm 1);
when the relative energy gap is below a (user defined) lower threshold (see line #12 of Algorithm 1), it is reasonable to expect that the algorithm is currently trapped by the attraction basin of an already explored local minimum. Hence, in order to quickly escape it, the exploration capability of the AEGA should be increased. For this purpose, the size of the list of the elite chromosomes is reduced by a (user defined) factor r, with (see line #13 of Algorithm 1), while the corresponding size of the list of the crossed over-plus-mutated chromosomes is increased as reported in line #14 of Algorithm 1. Such updated values of and will be used for performing the next iteration (see the “for” statement at line #7 of Algorithm 1);
when the relative energy gap is larger than a (user defined) upper threshold (see line #16 of Algorithm 1), it is reasonable to expect that the AEGA is just entering the still unexplored attraction basin of a new local/global minimum. Hence, in order to finely examine this new region of the solution landscape, the exploitation capability of the AEGA should be increased. For this purpose, the size of the list of the crossed over-plus-mutated chromosomes is reduced by the factor r (see line #17 of Algorithm 1), while the size of the list of the elite chromosomes is increased as reported in line #18 of Algorithm 1;
finally, when the relative energy gap falls into the inter-threshold interval , and remain unchanged.
| Algorithm 1 Adaptive Elitist GA (AEGA). |
Input:: integer-valued population size;
: positive-valued lower threshold;
: positive-valued upper threshold, with ;
: number of performed iterations;
r: reducing factor, with .
Output:: energy consumed by the globally best generated chromosome.
Local variables:: energy consumed by the best chromosome of the current population;
: energy consumed by the best chromosome of the previous population;
: integer-valued size of the current set of elite chromosomes;
: integer-valued size of the current set of crossed over-plus-mutated chromosomes, with ;
: full list (of size ) of the currently generated chromosomes.
— Initialization phase —- 1:
Randomly generate a list of chromosomes of size ; - 2:
Compute the energy of the generated chromosomes through Equation ( 4); - 3:
Sort the chromosomes into ascending order of their consumed energy values and return the sorted list ; - 4:
Store into the energy of the first (i.e., the best) element of the sorted list ; - 5:
Initialize the size of the set of the elite chromosomes, with ; - 6:
Initialize the size of the set of the crossed over-plus-mutated chromosomes at ;
— Iterative phase —- 7:
fordo - 8:
Perform the crossover and mutation of the last chromosomes of the current population and return the updated population list ; - 9:
Evaluate the energy of the chromosomes of the returned list ; - 10:
Sort the chromosomes into ascending order of their consumed energy values and return the sorted list ; - 11:
Store the energy of the first chromosome of the sorted list into ; - 12:
if then ▹ Increase the exploration capability of the AEGA - 13:
; - 14:
; - 15:
end if - 16:
if then ▹ Increase the exploitation capability of the AEGA - 17:
; - 18:
; - 19:
end if - 20:
Update: ; - 21:
end for
— End of the iterative phase —- 22:
; ▹ Store the energy of the globally best generated chromosome - 23:
return.
|
Due to the elitist nature of the proposed AEGA, the energy returned at the end of the last iteration (i.e., at ; see line #7 of Algorithm 1) is also the minimum energy obtained over the overall set of carried out iterations (see line #22 of Algorithm 1). Hence, it constitutes the final output of the AEGA (see line #23 of Algorithm 1).
Before proceeding, three main remarks about the expected impact on the performance of the AEGA of the setting of the input parameters
,
and
r of Algorithm 1 are in order. First, since these parameters play, indeed, the role of
hyper-parameters, their optimized setting depends on the actual landscape of the adopted objective function, and, then, we must resort to numerical trials for their optimization (see the following
Section 6 for additional details on this topic). Second, we expect that, by design, the exploration capability of the proposed AEGA increases for increasing values of the lower threshold
(see line #12 of Algorithm 1), while lower values of the upper threshold
enhances the corresponding exploitation capability (see line #16 of Algorithm 1). Third, we expect that the sensitivity of the AEGA on local variations of the landscape of the adopted objective function increases for decreasing values of the reducing factor
r. This means, in turn, that lower values of
r may shorten the transient phase and speed up the convergence of the AEGE toward
local (or even global) minima, but, at the same time, they may also induce oscillation phenomena in the converged performance. Therefore, we expect that the right setting of
r is the suitable trade-off among the two contrasting requirements of short transient phases and stable performance at the convergence.
6. Numerical Performance of the Proposed SmartFog
The goal of this section is threefold. First, we describe the implemented setting for the simulation of the proposed SmartFog platform. Second, we numerically test the accuracy performance of the proposed SDAE of
Figure 2 and compare it with the corresponding one of a benchmark solution that uses a shallow Support Vector Machine (SVM) for anomaly detection. Third, we test the energy performance of the SmartFog platform equipped with the proposed AEGA of Algorithm 1 and compare it to the corresponding ones of two benchmark solutions. Specifically, the first benchmark solution performs the mapping of the SDAE layers of
Figure 2 onto the SmartFog platform of
Figure 1 by resorting to a
non-adaptive conventional Elitist GA, while the second one uses only the Cloud node for performing the training of the implemented SDAE of
Figure 1.
Implemented test framework—Numerical tests of the SmartFog platform have been carried out by using the UCI “Individual household electric power consumption” data set available at:
https://archive.ics.uci.edu/ml/datasets/individual+household+electric+power+consumption. It embraces more than 2 millions of measurements gathered in a house located in Sceaux (near Paris, France) between December 2006 and November 2010. Instances in the dataset represent the active per-minute energy (in Watt hour) consumed by the household and measured by the SM. From this data set, we have selected 30 days from 10 SMs (43,200 instances) for the train set and 10 days (14,400 instances) for the test set. The number of anomalies in the data set is about 12% of the total. These anomalies consist of time-series representing faulty meters or fraudulent users.
The performance of the proposed SmartFog platform was simulated by leveraging the recently proposed VirtFogSim toolbox [
9]. It provides several primitives for the customized simulations of virtualized (i.e., clone-based) networked Fog ecosystems.
The input provided to the simulated SDAE consists of frames of duration of one, two, four and six hours, which are equivalent to 60, 120, 240 and 360 input units, respectively. A Gaussian noise with zero mean and a variance equal to 1% of the mean squared value of the considered training data was added to the input vector
, in order to guarantee a robust classification (see
Figure 2).
We tested two SDAEs with
(3L-SDAE) and
(5L-SDAE) hidden layers and four different lengths of the input vector
. The number of units in the hidden layers are detailed in
Table 1. We used the sigmoid function as nonlinear function in all layers. In the implemented Adam algorithm [
4], the learning rate is set to
for all layers, and the hyper-parameters
and
[
4] are set to
and
, respectively. For the
k-NN classifier, we have used 5 neighbors and the Euclidean distance as similarity measure.
Comparative accuracy performance—The obtained numerical results in terms of classification accuracy are reported in
Table 2. Accuracy is defined as the ratio between the number of instances correctly classified out the total instances. From
Table 2, we can argue that the accuracy decreases when the length of the analysis window is too short or too long: interestingly, a time window of two hours produces the best accuracy. Moreover, we can see that the use of three hidden layers produces better results than five hidden layers. Hence, the 3L-SDAE with a time window of two hours can be considered as the most reliable solution for detecting anomalies in SM data.
As a benchmark, a Support Vector Machine (SVM) classifier was trained on the same set of raw data. The corresponding soft-margin parameter
C was optimized by a grid search algorithm over the set:
, selecting the best value of
. The accuracy obtained by the tested SVM is detailed in
Table 3. This table puts in evidence that the SVM produces a worse accuracy than the 3L-SDAE architecture of about 5%.
Comparative energy performance— Passing to consider the energy consumption of the underlying SmartFog execution platform of
Figure 1, we carried out several tests by varying the strategy for the mapping of the hidden layers of SDAE of
Figure 2 onto the available Fog-Cloud computing nodes of
Figure 1. For this purpose, three mapping strategies were implemented and numerically tested. The first one relies on the proposed AEGA of Algorithm 1. The second one implements a
Non-Adaptive Elitist GA (NA-EGA), that is obtained by removing from the pseudo-code of Algorithm 1 both the “if” statements at lines #12 and #16. The last strategy is the simplest one and maps all the hidden layers of the considered SDAE of
Figure 2 to the Cloud node of
Figure 1 for their training. In this last case, no energy consumption can be obtained since the entire algorithm is running on the unique Cloud node. In all performed tests, the size
of the populations of the simulated GAs is held constant, equal to 10, the only-Cloud solution is included in the initial populations and a maximum of
iterations are run. Furthermore, the (numerically optimized) hyper-parameters
,
and
r used for the simulation of the proposed AEGA of Algorithm 1 are set to 0.1, 1.1 and 0.85 respectively, while, in the simulated NA-EGA, the (numerically optimized) sizes
and
of the elite and crossed over-plus-mutated sub-lists are fixed to 4 and 6, respectively. In the following, the optimized inter-threshold interval will be denoted as
.
According to
Figure 1, the simulated SmartFog platform is composed of five Fog nodes and a single Cloud node, with each node being equipped with a corresponding virtual clone [
9]. The computing and network capacities of each Fog clone are randomly selected over the sets: 5–12 Mbit/s for the processing rates of CPUs, 5–10 Mbit/s for the SM-to-Fog transmission rates and 10–20 Mbit/s for the intra-Fog and the Fog-Cloud transmission rates. However, the computing and network capacities of the Cloud clone are fixed to their respective maximum values (i.e., 12, 10 and 20 Mbit/s, respectively), in order to reflect the more stable and larger resources made available by the Cloud. Furthermore, the simulated inter-node network topology is meshed, with inter-Fog and Fog-Cloud links that are bidirectional and symmetric. Since we consider here the 3L-SDAE, we need to allocate
hidden layers over the available computing (i.e., Fog-plus-Cloud) nodes.
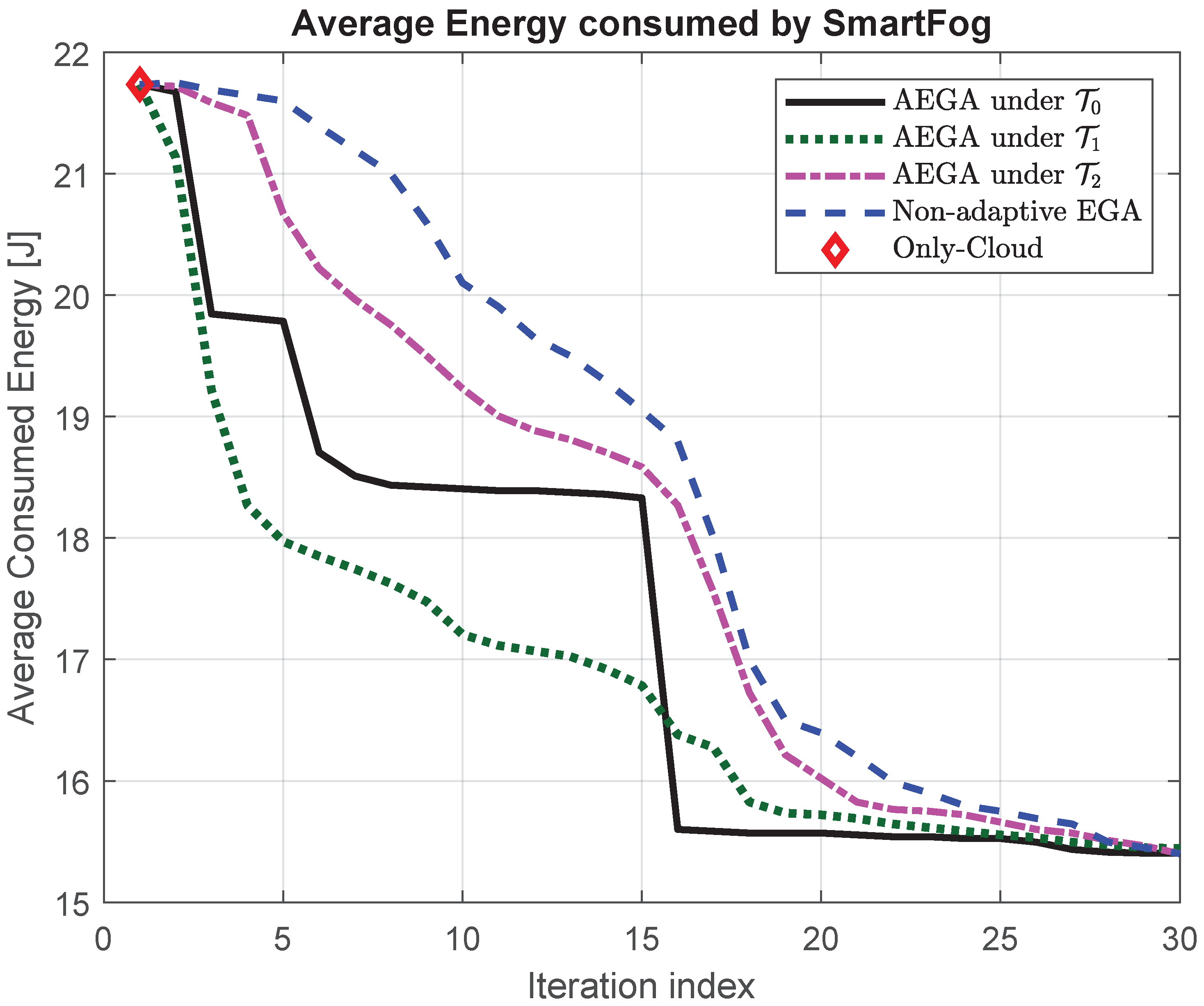
The resulting energy plots are reported in
Figure 3. Each simulated point was obtained by averaging over 30 independent runs of randomly generated computing and network capacities of the (aforementioned) five Fog nodes that compose the simulated SmartFog platform. Specifically, in
Figure 3, the continuous black (resp., dashed blue) curve plots the simulated average energy consumption of the proposed AEGA of Algorithm 1 under the optimized inter-threshold
(resp., the benchmark NA-EGA), while the point marked by the red diamond reports the average energy consumption of the (aforementioned) only-Cloud solution that uses only the Cloud node for the training of the implemented 3L-SDAE.
An examination of the energy plots of
Figure 3 leads to three main insights.
First, being of elitist type, both the proposed AEGA and benchmark NA-EGA converge to the same final energy value by following non-increasing trajectories. However, the convergence time (in multiple of the generated populations) of the proposed AEGA (resp., benchmark NA-EGA) is around 16 (resp., 27), so that the convergence of the AEGA is about 1.7 times faster than the corresponding one of the benchmark NA-EGA.
Second, the behavior of the energy curve of the AEGA is step-like (see the cliffs at the iteration indexes 3, 6 and 16 in
Figure 3), while the corresponding behavior of the NA-EGA is smoother. We have numerically ascertained that the step-like behavior of the energy plot of the AEGA is induced, indeed, by the adaptive mechanism implemented by the “if” statements at lines #12 and #16 of Algorithm 1, which allows the AEGA to quickly escape already explored regions of the underlying objective function and to fast enter still unexplored attraction basins of new local/global minima.
Third, the gap between the energy consumption of the only-Cloud solution (i.e., the red diamond in
Figure 3) and the steady-state one of the proposed AEGA is noticeable (e.g., around 30%) and it is approached by the AEGA after several iterations limited up to 16 (see the continuous curve of
Figure 3).
Sensitivity on the threshold setting—In this paragraph, we consider the impact of the setting of the two hyper-parameters
and
on the average energy consumption of the proposed SmartFog platform. Specifically, we performed the tests by using the following two additional inter-threshold intervals
and
, respectively, while the hyper-parameter
r was set to the previous value of 0.85. The average energy consumption of the proposed AEGA of Algorithm 1 under the inter-threshold intervals
and
is shown by the dotted dark green curve and the dash-dotted magenta curve of
Figure 3, respectively.
Interestingly enough, we can observe from the dotted dark green curve of
Figure 3 that when the more stressed inter-threshold interval
is used, the proposed AEGA converges to the same final energy value of the optimized interval
. However, the convergence time is very different from the previous one. Since, in fact, the threshold are more restrictive, the proposed AEGA shows a fast transitory behavior, but after a few iterations the convergence becomes flat (the thresholds are too restrictive and more iterations are needed) and the time period for obtaining the final solution is stretched. The total convergence time is around 20 iterations. On the other hand, when the more relaxed inter-threshold interval
is used, the dash-dotted magenta curve of
Figure 3 shows that the convergence behavior tends to emulate the shape of the non-adaptive GA strategy depicted by the dashed blue curve of
Figure 3. In this case, the convergence time is about 24 iterations while the AEGA converges to the same final energy value of the optimized interval
.
7. Conclusions and Hints for Future Research
In this contribution, we focused on the optimized design of SmartFog, a Fog-based networked computing platform for the distributed training of deep auto-encoders for anomaly detection in data streams generated by Smart-Meters (SMs). For this purpose, after defining the main building blocks of the SmartFog platform, we proposed a new Adaptive Elitist GA (i.e., the AEGA) for the energy-efficient distributed training of the implemented SDAE. The performance of the resulting optimized SmartFog platform was numerically tested and compared with the corresponding ones of some state-of-the-art benchmark solutions in terms of accuracy, energy consumption and execution time.
Overall, the main insights stemming from the reported numerical results are that: (i) the proposed SmartFog platform reaches an accuracy of 92.6% by using an SDAE with three hidden layers and a time window of two hours; and, (ii) the proposed AEGA equipping the SmartFog platform allows us to reduce the convergence time of about 1.6 times with respect to the conventional NA-GA, while guaranteeing a 30% of energy saving with respect to the only-Cloud benchmark solution.
Being the integration of the Deep Neural Networks and Fog Computing paradigms in its infancy [
10], we believe that the reported results are, indeed, only the tip of the iceberg and, then, they could be further developed along (at least) three main research lines.
First, the present paper focuses on the energy-efficient implementation of SDAEs atop Fog platforms. However, SDAEs represent only an instance of the overall family of DNNs [
4]. Hence, the generalization of the presented results to DNN models described by general directed acyclic graphs could be a first research line of potential interest.
Second, this work focuses on the training phase of the SDAEs, that is typically considered the most cumbersome one from a computational point of view. However, emerging IoT-oriented real-time applications demand for stringent delay requirements during the inference phase [
10]. Hence, the design and testing of distributed Fog technological platforms for the energy-saving and real-time inference of big data through DNNs may be a second research line of potential interest.
Finally, the presented results rely on the (implicit) assumption that both the volume of data to be processed and the states (that is, the bandwidths) of the communication links of the SmartFog platform of
Figure 1 stay unchanged over time intervals at least equal to the time required to carry out the training of the SDAE of
Figure 2. As (recently) pointed out, for example, in [
23], this assumption is typically met in SmartGrid networks for emerging Green Smart Home applications, in which both SMs and Fog nodes are statically installed in buildings that communicate over fixed power line-based wired links (see, for example,
Section 3 of [
23] and the reference framework of
Figure 2). However, in principle, both the here proposed SDAE-based approach to the anomaly detection and the related AEGA-based resource management solution could be effectively employed even in the emerging field of the so-called Vehicular Fog Computing (VFC) [
24,
25]. In this environment, devices on board of parked or slowly moving vehicles are used to form a wireless (possibly, mobile) intermediary Fog layer. These devices collect the data from wireless sensors installed on the vehicles, mine them and communicates the pre-processed results to remote Clouds for further processing by using nearby Road Side Units (see, for example, Figures 1–4 of [
24] for some sketches of the underlying reference scenarios). Hence, in principle, VFC fits the general architecture in
Figure 1 of the proposed SmartFog technological platform provided that (see
Figure 1): (i) SMs are replaced by wireless (possibly, mobile) sensors; (ii) Fog nodes are replaced by vehicles; and, (iii) both inter-Fog and Cloud-Fog links are assumed to be wireless. However, in the resulting VFC scenario, both the assumptions of time-invariant volume of data to be processed and time-invariant link bandwidths may fall short [
26,
27]. This needs the introduction of imperfect channel estimation techniques [
28,
29,
30]. How the proposed SmartFog platform could be refined for effectively coping with the environmental time fluctuations of VFC-based application scenarios could be an additional hint for future research.








{kind=link}
{kind=link}
{kind=link}