Chinese Character Boxes: Single Shot Detector Network for Chinese Character Detection



Abstract
:1. Introduction
- CCB-SSD network was proposed for Chinese character detection based on a single-scale structure that can be trained by end-to-end. This can make the network deep enough without additional steps such as deconvolution-based up-sampling and feature map concatenation to overcome the limitations of conventional methods. Therefore, semantic information can be fully exploited and even smaller characters can be detected as a result.
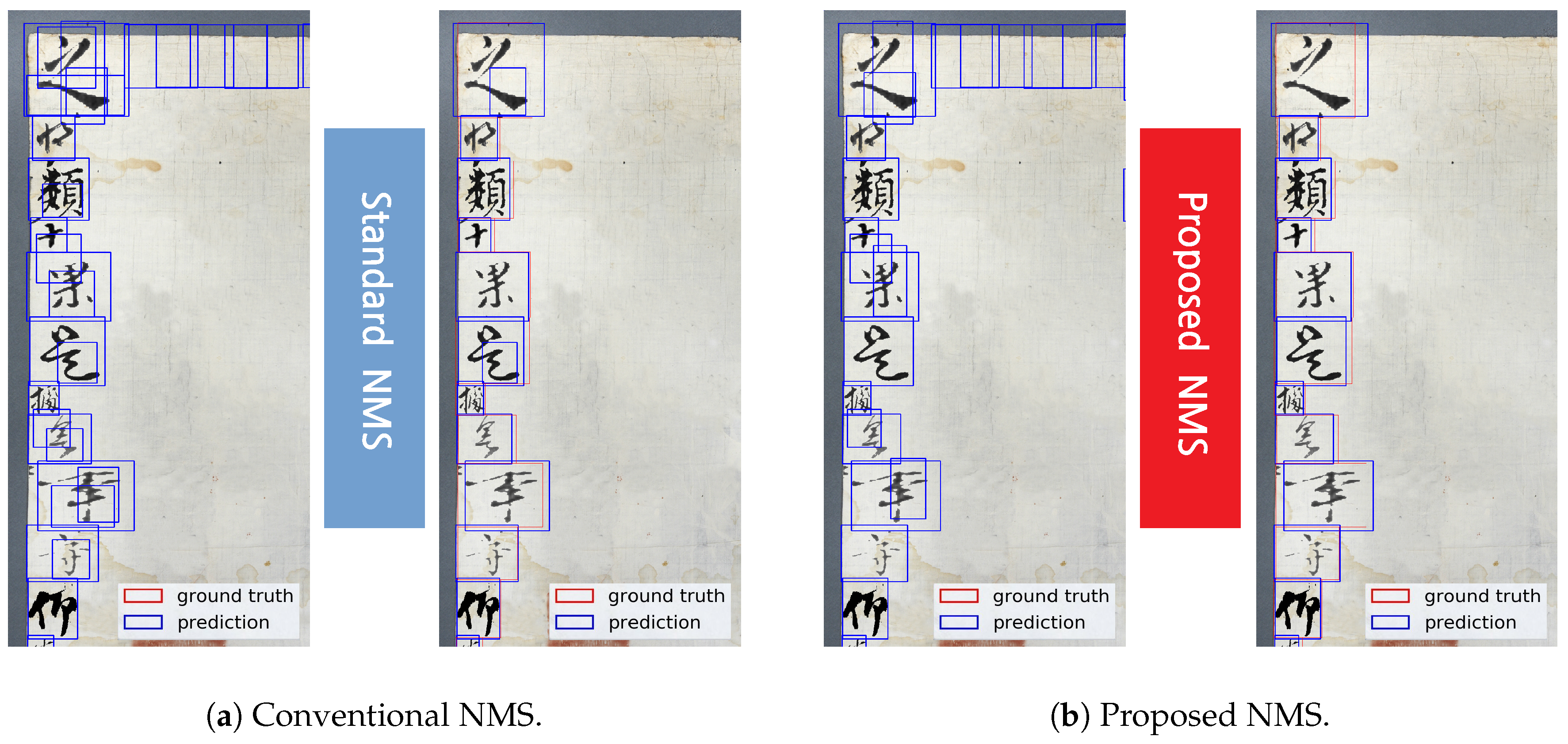
- Using the proposed single-scale structure and NMS, the problem of the existence of unnecessary layers and the relationship between the classifiers was solved and the problem of overlap caused by the use of several default boxes was resolved.
- The FPPC, a new evaluation index that can be a more objective indicator than the FPPI was proposed for the detection of Chinese characters in old documents. In addition, an augmentation method of data-sets with document type and cropped data type was introduced.
2. Related Works
3. Proposed Method
3.1. Baseline Method: SSD
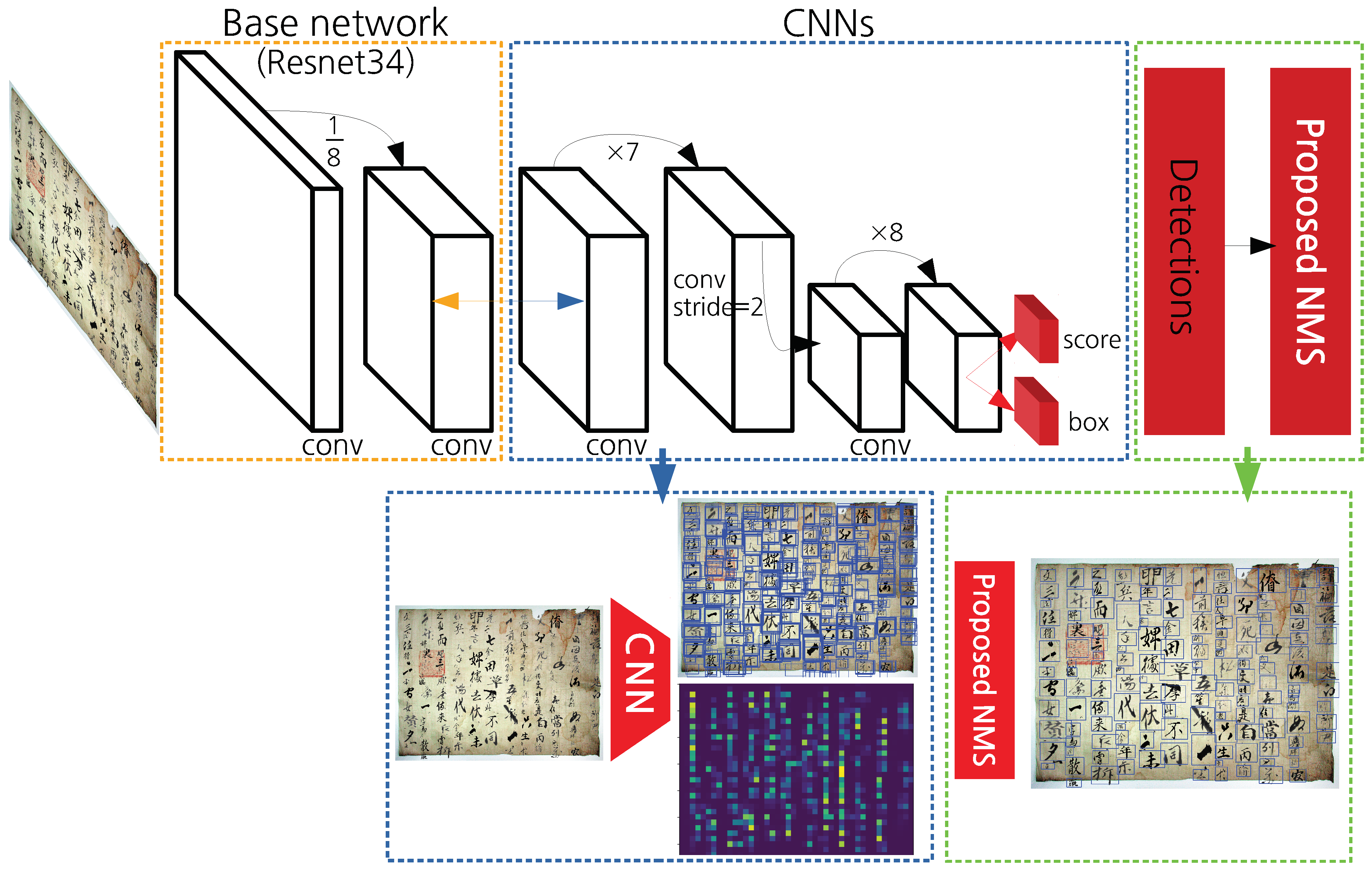
3.2. Proposed CCB-SSD Network and NMS
4. Experimental Results
4.1. Proposed Criterion: False Positives per Character
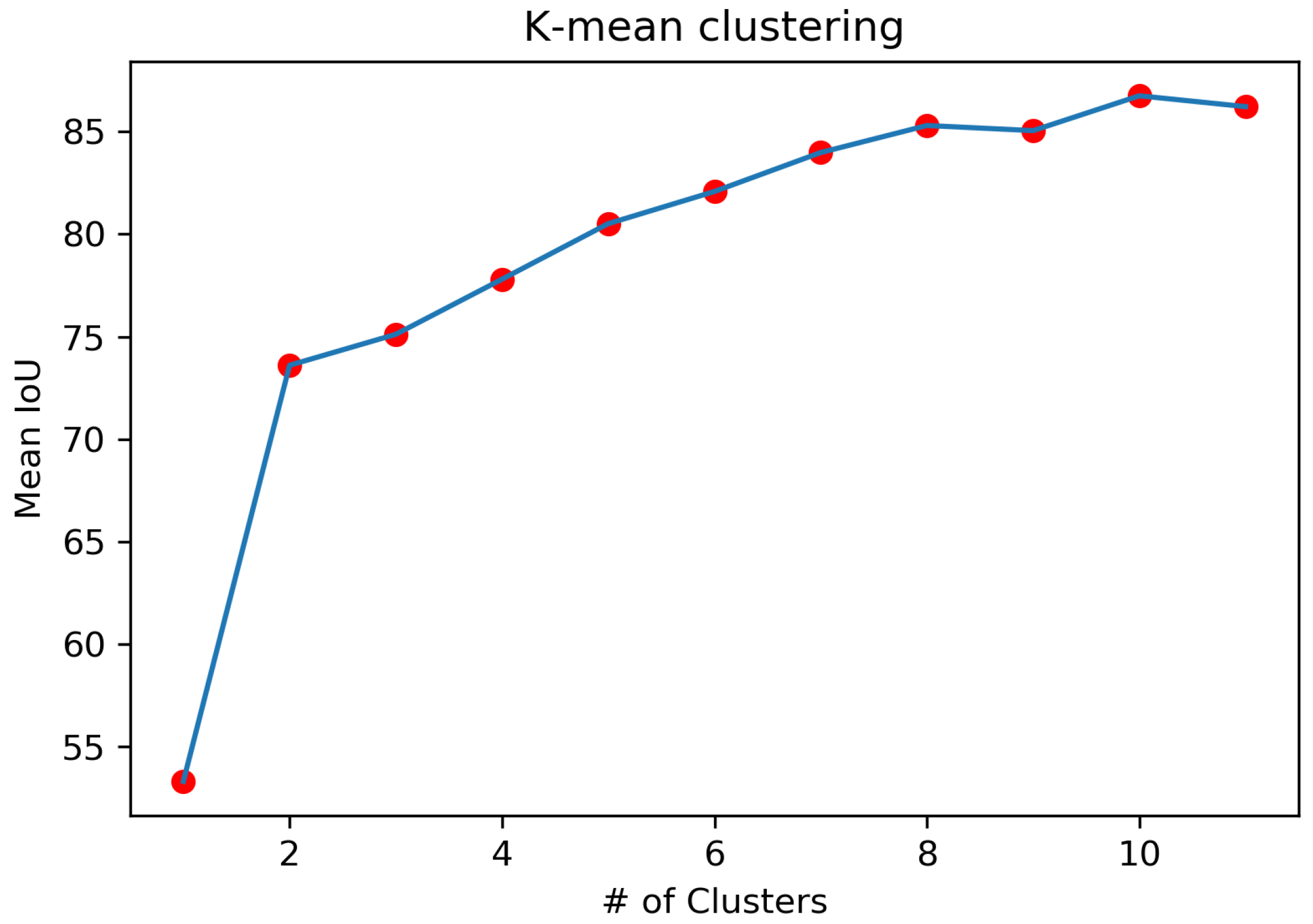
4.2. Kyungpook National University (KNU) Data-Set
4.3. Augmentation Method
4.4. Detection Performance Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Nguyen, K.C.; Nakagawa, M. Text-Line and Character Segmentation for Offline Recognition of Handwritten Japanese Text. IEICE Techn. Rep. 2016, 115, 53–58. [Google Scholar]
- Arica, N.; Yarman-Vural, F.T. Optical character recognition for cursive handwriting. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 801–813. [Google Scholar] [CrossRef]
- Roy, A.; Bhowmik, T.K.; Parui, S.K.; Roy, U. A novel approach to skew detection and character segmentation for handwritten Bangla words. In Proceedings of the 2005 Digital Image Computing: Techniques and Applications (DICTA’05), Queensland, Australia, 6–8 December 2005; p. 30. [Google Scholar]
- Tse, J.; Jones, C.; Curtis, D.; Yfantis, E. An OCR-independent character segmentation using shortest-path in grayscale document images. In Proceedings of the Sixth International Conference on Machine Learning and Applications (ICMLA 2007), Cincinnati, OH, USA, 13–15 December 2007; pp. 142–147. [Google Scholar]
- Yoon, Y.; Ban, K.D.; Yoon, H.; Kim, J. Blob detection and filtering for character segmentation of license plates. In Proceedings of the 2012 IEEE 14th International Workshop on Multimedia Signal Processing (MMSP), Banff, AB, Canada, 17–19 September 2012; pp. 349–353. [Google Scholar]
- Subramanian, K.; Natarajan, P.; Decerbo, M.; Castanon, D. Character-stroke detection for text-localization and extraction. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Parana, Brazil, 23–26 September 2007; Volume 1, pp. 33–37. [Google Scholar]
- Uchida, S.; Shigeyoshi, Y.; Kunishige, Y.; Yaokai, F. A keypoint-based approach toward scenery character detection. In Proceedings of the 2011 International Conference on Document Analysis and Recognition (ICDAR), Beijing, China, 18–21 September 2011; pp. 819–823. [Google Scholar]
- Kunishige, Y.; Yaokai, F.; Uchida, S. Scenery character detection with environmental context. In Proceedings of the 2011 International Conference on Document Analysis and Recognition (ICDAR), Beijing, China, 18–21 September 2011; pp. 1049–1053. [Google Scholar]
- Chen, H.; Tsai, S.S.; Schroth, G.; Chen, D.M.; Grzeszczuk, R.; Girod, B. Robust text detection in natural images with edge-enhanced maximally stable extremal regions. In Proceedings of the 2011 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 2609–2612. [Google Scholar]
- Yi, C.; Yang, X.; Tian, Y. Feature representations for scene text character recognition: A comparative study. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 907–911. [Google Scholar]
- Huang, R.; Shivakumara, P.; Uchida, S. Scene character detection by an edge-ray filter. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 462–466. [Google Scholar]
- Zhang, J.; Kasturi, R. A novel text detection system based on character and link energies. IEEE Trans. Image Process. 2014, 23, 4187–4198. [Google Scholar] [CrossRef] [PubMed]
- Sung, M.C.; Jun, B.; Cho, H.; Kim, D. Scene text detection with robust character candidate extraction method. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 426–430. [Google Scholar]
- Zhao, Y.X.; Chou, C.H. Feature Selection Method Based on Neighborhood Relationships: Applications in EEG Signal Identification and Chinese Character Recognition. Sensors 2016, 16, 871. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Babenko, B.; Belongie, S. End-to-end scene text recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1457–1464. [Google Scholar]
- Shi, C.; Wang, C.; Xiao, B.; Zhang, Y.; Gao, S.; Zhang, Z. Scene text recognition using part-based tree-structured character detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2961–2968. [Google Scholar]
- Shi, C.; Wang, C.; Xiao, B.; Gao, S.; Hu, J. Scene Text Recognition Using Structure-Guided Character Detection and Linguistic Knowledge. IEEE Trans. Circuits Syst. Video Tech. 2014, 24, 1235–1250. [Google Scholar]
- Tsai, C. Recognizing Handwritten Japanese Characters Using Deep Convolutional Neural Networks; Technical Report; Stanford University: Stanford, CA, USA, 2016; pp. 1–7. [Google Scholar]
- Maidana, R.G.; dos Santos, J.M.; Granada, R.L.; de Morais Amory, A.; Barros, R.C. Deep Neural Networks for Handwritten Chinese Character Recognition. In Proceedings of the 2017 Brazilian Conference on Intelligent Systems (BRACIS), Uberlandia, Brazil, 2–5 October 2017; pp. 192–197. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffer, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 88, 2278–2324. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 818–833. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading text in the wild with convolutional neural networks. Int. J. Comput. Vis. 2016, 116, 1–20. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 391–405. [Google Scholar]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. TextBoxes: A Fast Text Detector with a Single Deep Neural Network. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 4161–4167. [Google Scholar]
- Bušta, M.; Neumann, L.; Matas, J. Deep textspotter: An end-to-end trainable scene text localization and recognition framework. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2231. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration of data-Set | Cropped Character Data-Set | Caoshu Data-Set | Background Data-Set |
|---|---|---|---|
| # of data-set | 200,000 | 1000 | 100 |
| example |  |  |  |
| Fine-Tuning | Character Data-Set | Caoshu Data-Set | ||
|---|---|---|---|---|
| # of Layers | Detection Rate (%) | FPPC (#) | Detection Rate (%) | FPPC (#) |
| 8 | 97.4 | 0.27 | 91.1 | 10.9 |
| 10 | 99.2 | 0.46 | 93.3 | 8.9 |
| 12 | 98.3 | 0.27 | 93.2 | 8.4 |
| 16 | 99.4 | 0.27 | 94.2 | 8.4 |
| 18 | 99.0 | 0.27 | 93.8 | 8.4 |
| 20 | 99.2 | 0.45 | 93.5 | 10.2 |
| Fine-Tuning | Character Data-Set | Caoshu Data-Set | ||
|---|---|---|---|---|
| # of Layers | Detection Rate (%) | FPPC (#) | Detection Rate (%) | FPPC (#) |
| 8 | 98.2 | 0.31 | 92.5 | 8.9 |
| 10 | 98.9 | 0.28 | 93.9 | 8.5 |
| 12 | 98.3 | 0.13 | 93.0 | 9.1 |
| 16 | 99.1 | 0.50 | 94.1 | 7.4 |
| 18 | 99.4 | 0.37 | 93.0 | 8.7 |
| 20 | 99.4 | 0.37 | 94.5 | 8.0 |
| Unrestricted Random Parameter | Restricted Random Parameter | ||
|---|---|---|---|
| Detection Rate (%) | FPPC (#) | Detection Rate (%) | FPPC (#) |
| 99.4 | 0.713 | 99.9 | 0.00238 |
| Layers | Detection Rate (%) | FPPC (#) |
|---|---|---|
| 10 | 95.20 | 1.54 |
| 16 | 96.10 | 0.89 |
| 22 | 89.14 | 0.74 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, J.; Kim, S. Chinese Character Boxes: Single Shot Detector Network for Chinese Character Detection. Appl. Sci. 2019, 9, 315. https://doi.org/10.3390/app9020315
Ryu J, Kim S. Chinese Character Boxes: Single Shot Detector Network for Chinese Character Detection. Applied Sciences. 2019; 9(2):315. https://doi.org/10.3390/app9020315
Chicago/Turabian StyleRyu, Junhwan, and Sungho Kim. 2019. "Chinese Character Boxes: Single Shot Detector Network for Chinese Character Detection" Applied Sciences 9, no. 2: 315. https://doi.org/10.3390/app9020315
APA StyleRyu, J., & Kim, S. (2019). Chinese Character Boxes: Single Shot Detector Network for Chinese Character Detection. Applied Sciences, 9(2), 315. https://doi.org/10.3390/app9020315