Traffic Light Cycle Configuration of Single Intersection Based on Modified Q-Learning



Abstract
:1. Introduction
2. Related Works
2.1. Intelligent Transportation System
2.2. Artificial Intelligence
2.3. Machine Learning
2.4. Reinforcement Learning
2.5. Q-Learning
2.6. Vehicle Detector
2.7. Traffic Simulation System
3. Traffic Light Cycle Recommendation Methods
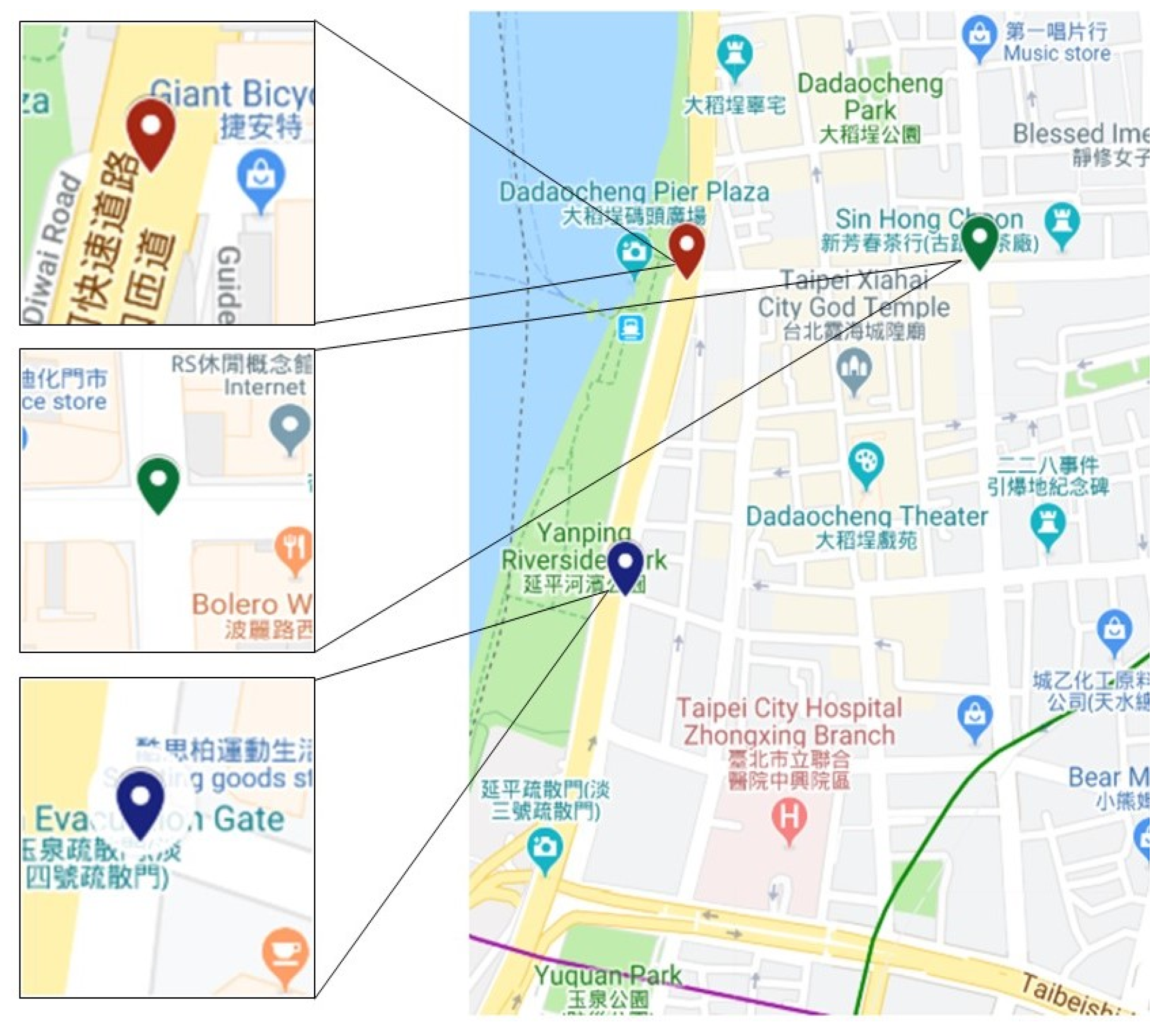
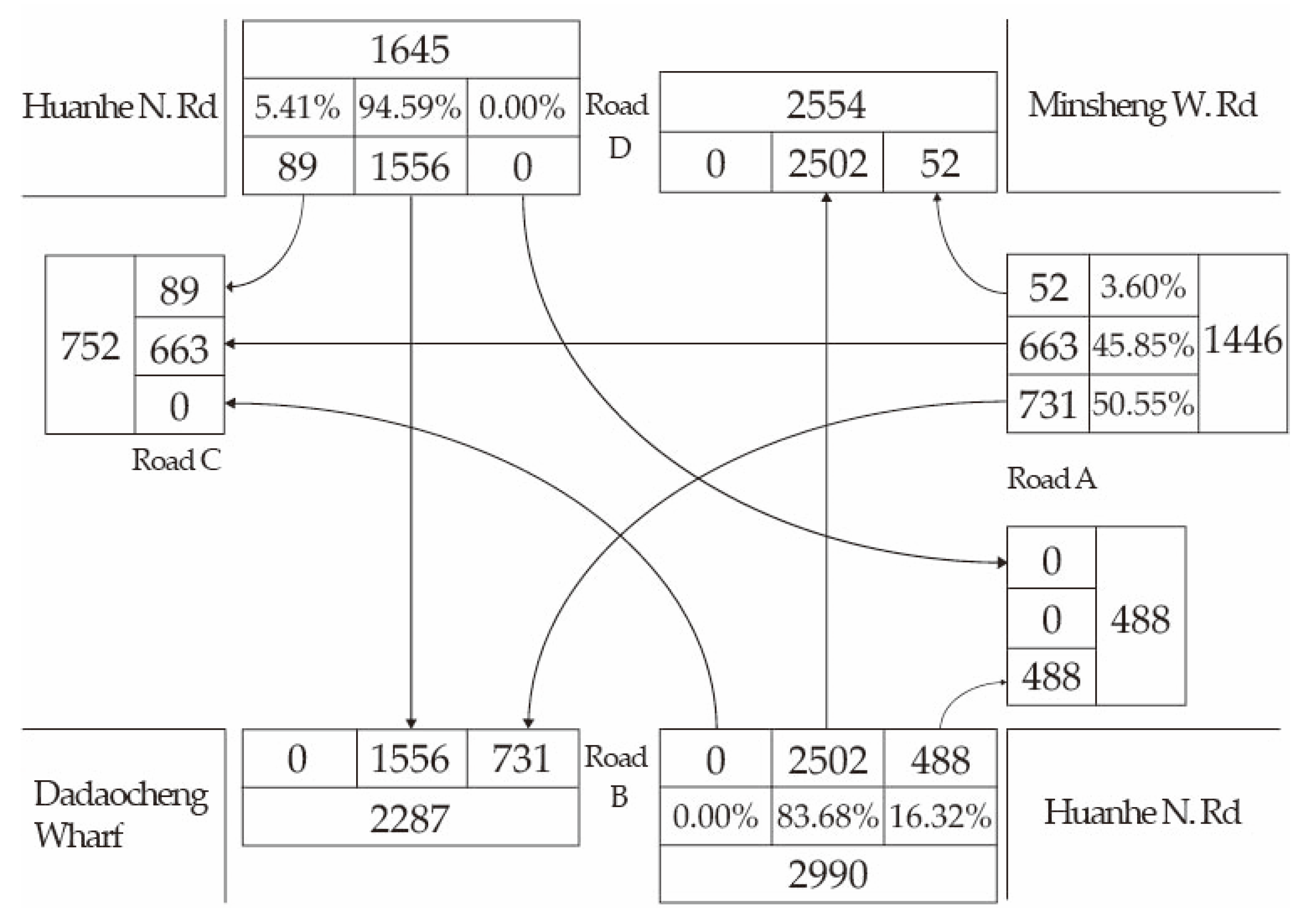
3.1. Road Traffic Indicator
3.2. Exhaustive Search Method
3.3. Q-Learning
| Algorithm 1. Q-learning. |
| Algorithm parameters: Step size , small |
| Initialize , for all , , arbitrarily except that (terminal, ·) = 0 |
| Loop for each episode: |
| Initialize S |
| Loop for each step of episode: |
| Choose from using policy derived from (e.g., -greedy) |
| Take action , observe , |
| until is terminal |
3.4. Modified Q-Learning
- 1
- Initialize Q-table, new average vehicle delay time (New-AVDT) and best average vehicle delay time (Best-AVDT).
- 2
- While (Best-AVDT > New-AVDT):
- 2.1
- Starting the search from the current best state and randomly select the action of the maximum reward.
- 2.2
- Determining whether the selected action value is zero.
- 2.2.1
- If the action value is zero, then calculate whether New-AVDT is better than Best-AVDT before.
- 2.2.2
- If the New-AVDT is better than the Best-AVDT, update the best state and jump back to step (2); otherwise give a negative reward.
- 2.2.3
- If the action value is not zero, the agent randomly selects the new state and jumps to step (2.1).
- 2.3
- If the agent continues to find no better average vehicle delay time, the output is the best state.
- 3
- Agent recommends the best state cycle configuration.
| Algorithm 2. Modified Q-learning. |
| Algorithm parameters: Step size , small |
| let be the traffic light cycle time of the previous time period |
| let be the negative average delay time of the original traffic light cycle |
| Loop for each episode: |
| Initialize , for all , , arbitrarily, except that (terminal, ·) = |
| Loop for each step of episode: |
| Choose from using policy derived from (e.g., -greedy) |
| Take action , observe , |
| If then |
| until is terminal |
4. Experimental Result
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018; pp. 1–13. [Google Scholar]
- Wei, S.; Zou, Y.; Zhang, T.; Zhang, X.; Wang, W. Design and Experimental Validation of a Cooperative Adaptive Cruise Control System Based on Supervised Reinforcement Learning. Appl. Sci. 2018, 8, 1014. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Alsrehin, N.O.; Klaib, A.F.; Magableh, A. Intelligent Transportation and Control Systems Using Data Mining and Machine Learning Techniques: A Comprehensive Study. IEEE Access 2019, 7, 49830–49857. [Google Scholar] [CrossRef]
- Chen, J.; Li, D.; Zhang, G.; Zhang, X. Localized Space-Time Autoregressive Parameters Estimation for Traffic Flow Prediction in Urban Road Networks. Appl. Sci. 2018, 8, 277. [Google Scholar] [CrossRef]
- Qin, P.; Zhang, Y.; Wang, B.; Hu, Y. Grassmann Manifold Based State Analysis Method of Traffic Surveillance Video. Appl. Sci. 2019, 9, 1319. [Google Scholar] [CrossRef]
- Gupte, S.; Masoud, O.; Martin, R.F.; Papanikolopoulos, N.P. Detection and classification of vehicles. IEEE Trans. Intell. Transp. Syst. 2002, 3, 37–47. [Google Scholar] [CrossRef] [Green Version]
- Zaid, A.A.; Suhweil, Y.; Yaman, M.A. Smart controlling for traffic light time. In Proceedings of the IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies, Aqaba, Jordan, 11–13 October 2017. [Google Scholar]
- Nuss, D.; Thom, M.; Danzer, A.; Dietmayer, K. Fusion of laser and monocular camera data in object grid maps for vehicle environment perception. In Proceedings of the 17th International Conference on Information Fusion (FUSION), Salamanca, Spain, 7–10 July 2014. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Yu, F.R.; Wang, Y.; Ning, B. Big Data Analytics in Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2019, 20, 383–398. [Google Scholar] [CrossRef]
- Qi, L.; Zhou, M.; Luan, W. Emergency Traffic-Light Control System Design for Intersections Subject to Accidents. IEEE Trans. Intell. Transp. Syst. 2016, 17, 170–183. [Google Scholar] [CrossRef]
- Chen, D. Research on traffic flow prediction in the big data environment based on the improved RBF neural network. IEEE Trans. Ind. Inform. 2017, 13, 2000–2008. [Google Scholar] [CrossRef]
- Li, H.; Wang, P.; Shen, C. Toward End-to-End Car License Plate Detection and Recognition with Deep Neural Networks. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1126–1136. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, L.; Wang, Y.; Xue, G.; Xu, Y. Intelligent travel and parking guidance system based on Internet of vehicle. In Proceedings of the IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 25–26 March 2017. [Google Scholar]
- Rekabdar, B.; Mousas, C. Dilated Convolutional Neural Network for Predicting Driver’s Activity. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Singh, J. Experimental study for Gurmukhi Handwritten Character Recognition. In Proceedings of the 4th International Conference on Internet of Things: Smart Innovation and Usages (IoT-SIU), Ghaziabad, India, 18–19 April 2019. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Mao, X.; Chang, S.; Shi, J.; Li, F.; Shi, R. Sentiment-Aware Word Embedding for Emotion Classification. Appl. Sci. 2019, 9, 1334. [Google Scholar] [CrossRef]
- Lucas, S.M. Game AI Research with Fast Planet Wars Variants. In Proceedings of the IEEE Conference on Computational Intelligence and Games (CIG), Maastricht, The Netherlands, 14–17 August 2018. [Google Scholar]
- Angarita-Zapata, J.S.; Masegosa, A.D.; Triguero, I. A Taxonomy of Traffic Forecasting Regression Problems from a Supervised Learning Perspective. IEEE Access 2019, 7, 68185–68205. [Google Scholar] [CrossRef]
- Dike, H.U.; Zhou, Y.; Deveerasetty, K.K.; Wu, Q. Unsupervised Learning Based On Artificial Neural Network: A Review. In Proceedings of the IEEE International Conference on Cyborg and Bionic Systems (CBS), Shenzhen, China, 25–27 October 2018. [Google Scholar]
- Kochenderfer, M.J.; Monath, N. Compression of Optimal Value Functions for Markov Decision Processes. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 20–22 March 2013. [Google Scholar]
- Sun, C. Fundamental Q-learning Algorithm in Finding Optimal Policy. In Proceedings of the International Conference on Smart Grid and Electrical Automation (ICSGEA), Changsha, China, 27–28 May 2017. [Google Scholar]
- Schilperoort, J.; Mak, I.; Drugan, M.M.; Wiering, M.A. Learning to Play Pac-Xon with Q-Learning and Two Double Q-Learning Variants. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018. [Google Scholar]
- Lu, K.; Xu, J.M.; Li, Y.S. An optimization method for single intersection’s signal timing based on SARSA(λ) algorithm. In Proceedings of the Chinese Control and Decision Conference, Yantai, China, 2–4 July 2008. [Google Scholar]
- Cheng, Q.; Wang, X.; Yang, J.; Shen, L. Automated Enemy Avoidance of Unmanned Aerial Vehicles Based on Reinforcement Learning. Appl. Sci. 2019, 9, 669. [Google Scholar] [CrossRef]
- Cao, X.R. A basic formula for online policy gradient algorithms. IEEE Trans. Autom. Control. 2005, 50, 696–699. [Google Scholar]
- Sehnke, F.; Osendorfer, C.; Rückstieß, T.; Gravesa, A.; Peters, J.; Schmidhuber, J. Parameter-exploring Policy Gradients. J. Neural Netw. 2010, 23, 511–559. [Google Scholar] [CrossRef] [PubMed]
- Taipei City Government Department of Transportation. Available online: https://www.dot.gov.taipei/ (accessed on 30 July 2019).
- Taiwan Highway Capacity Software. Available online: https://thcs.iot.gov.tw/WebForm2.aspx (accessed on 26 October 2019).
- Vukmirović, S.; Čapko, Z.; Babić, A. The Exhaustive Search Algorithm in the Transport network optimization on the example of Urban Agglomeration Rijeka. In Proceedings of the International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019. [Google Scholar]
- Taiwan Road Capacity Manual. Available online: https://thcs.iot.gov.tw/WebForm3.aspx (accessed on 26 October 2019).
- Road Traffic Sign Marking Line Setting Plan. Available online: https://law.moj.gov.tw/LawClass/LawAll.aspx?pcode=K0040014 (accessed on 26 October 2019).
- Combinatorial Explosion. Available online: http://pespmc1.vub.ac.be/ASC/COMBIN_EXPLO.html (accessed on 30 July 2019).
- Luo, B.; Liu, D.; Huang, T.; Wang, D. Model-Free Optimal Tracking Control via Critic-Only Q-Learning. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 2134–2144. [Google Scholar] [CrossRef] [PubMed]
- Katoh, M.; Shimotani, R.; Tokushige, K. Integrated Multiagent Course Search to Goal by Epsilon-Greedy Learning Strategy: Dual-Probability Approximation Searching. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Kowloon, China, 9–12 October 2015. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Average Vehicle Delay Time(s) |
|---|---|
| A | 0 ≤ AVDT < 15 |
| B | 15 ≤ AVDT < 30 |
| C | 30 ≤ AVDT < 45 |
| D | 45 ≤ AVDT < 60 |
| E | 60 ≤ AVDT < 80 |
| F | 80 ≤ AVDT |
| Method Time Periods | Exhaustive Search | Modified Q-Learning | Comparison | ||||
|---|---|---|---|---|---|---|---|
| Delay (S) | Steps | Avg. Delay (S) | Avg. Steps | E | I | ||
| Huanhe N. Rd. & Minsheng W. Rd. | 8:00–9:00 a.m. | 27.0 | 361 | 29.1 | 29.1 | 7.8% | 1141% |
| 5:00–6:00 p.m. | 68.0 | 71.1 | 26.1 | 4.6% | 1283% | ||
| Huanhe N. Rd. & Nanjing W. Rd. | 8:00–9:00 a.m. | 31.3 | 34.1 | 33.1 | 8.9% | 991% | |
| 5:00–6:00 p.m. | 6.9 | 7.05 | 29.6 | 2.2% | 1120% | ||
| Yanping N. Rd. & Minsheng W. Rd. | 8:00–9:00 a.m. | 9.9 | 9.90 | 26.4 | 0.0% | 1267% | |
| 5:00–6:00 p.m. | 7.7 | 7.7 | 25.4 | 0.0% | 1321% | ||
| Average | 25.13 | 361 | 26.49 | 28.28 | 5.4% | 1176% | |
| Cycle Direction | East-West Cycle (S) | North-South Cycle (S) | E | |
|---|---|---|---|---|
| Time Periods | ||||
| Huanhe N. Rd. & Minsheng W. Rd. | 8:00–9:00 a.m. | 35 | 80 | 7.8% |
| 5:00–6:00 p.m. | 100 | 70 | 4.6% | |
| Huanhe N. Rd. & Nanjing W. Rd. | 8:00–9:00 a.m. | 120 | 30 | 8.9% |
| 5:00–6:00 p.m. | 45 | 30 | 2.2% | |
| Yanping N. Rd. & Minsheng W. Rd. | 8:00–9:00 a.m. | 30 | 45 | 0.0% |
| 5:00–6:00 p.m. | 30 | 35 | 0.0% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, H.-C.; Liao, Y.-X.; Chang, L.-h.; Lee, Y.-H. Traffic Light Cycle Configuration of Single Intersection Based on Modified Q-Learning. Appl. Sci. 2019, 9, 4558. https://doi.org/10.3390/app9214558
Chu H-C, Liao Y-X, Chang L-h, Lee Y-H. Traffic Light Cycle Configuration of Single Intersection Based on Modified Q-Learning. Applied Sciences. 2019; 9(21):4558. https://doi.org/10.3390/app9214558
Chicago/Turabian StyleChu, Hung-Chi, Yi-Xiang Liao, Lin-huang Chang, and Yen-Hsi Lee. 2019. "Traffic Light Cycle Configuration of Single Intersection Based on Modified Q-Learning" Applied Sciences 9, no. 21: 4558. https://doi.org/10.3390/app9214558
APA StyleChu, H. -C., Liao, Y. -X., Chang, L. -h., & Lee, Y. -H. (2019). Traffic Light Cycle Configuration of Single Intersection Based on Modified Q-Learning. Applied Sciences, 9(21), 4558. https://doi.org/10.3390/app9214558