Landslide Susceptibility Mapping Combining Information Gain Ratio and Support Vector Machines: A Case Study from Wushan Segment in the Three Gorges Reservoir Area, China


Abstract
:1. Introduction
2. Materials and Methods
2.1. Description of the Study Area
2.2. Methodology
2.2.1. Information Gain Ratio
2.2.2. Support Vector Machines
2.2.3. Artificial Neural Networks
2.2.4. Classification and Regression Tree
2.2.5. Logistic Regression
2.3. Data Preparation and Analysis
2.3.1. Landslide Inventory Map
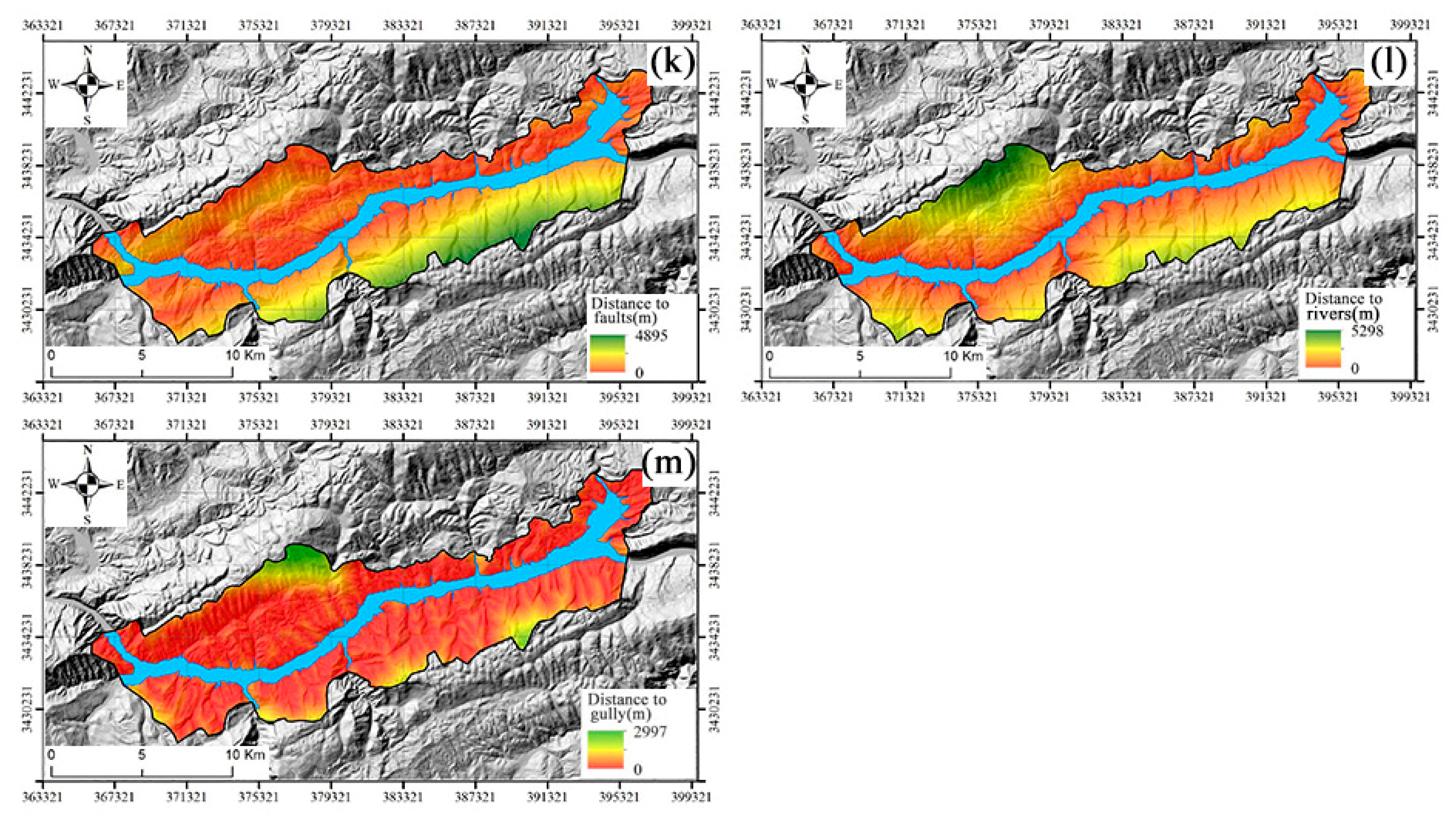
2.3.2. Landslide Causal Factors
2.4. Landslide Causal Factors Selection
2.4.1. Multicollinearity Analysis
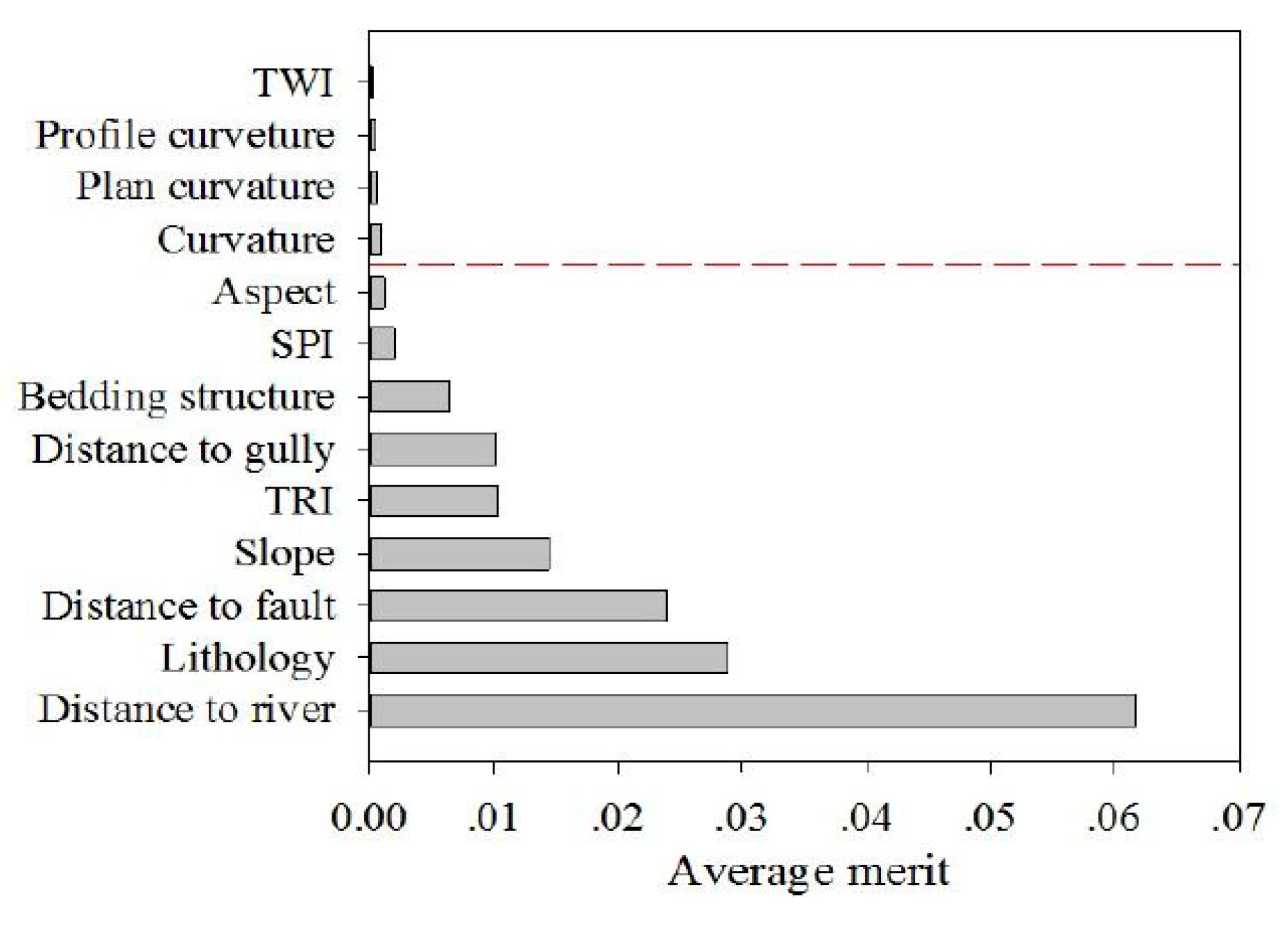
2.4.2. Factor Selection Using Information Gain Ratio
3. Results and Accuracy Analysis
3.1. Landslide Susceptibility Modelling
3.2. Accuracy Statistic
3.3. Using ROC Curve
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yu, M.; Huang, Y.; Zhou, J.; Mao, L. Modeling of landslide topography based on micro-unmanned aerial vehicle photography and structure-from-motion. Environ. Earth Sci. 2017, 76, 520. [Google Scholar] [CrossRef]
- Avelar, A.S.; Netto, A.L.C.; Lacerda, W.A.; Becker, L.B.; Mendonça, M.B. Mechanisms of the Recent Catastrophic Landslides in the Mountainous Range of Rio de Janeiro, Brazil; Springer: Berlin/Heidelberg, Germany, 2013; pp. 265–270. [Google Scholar]
- Fan, X.; Xu, Q.; Scaringi, G.; Dai, L.; Li, W.; Dong, X.; Zhu, X.; Pei, X.; Dai, K.; Havenith, H.-B. Failure mechanism and kinematics of the deadly June 24th 2017 Xinmo landslide, Maoxian, Sichuan, China. Landslides 2017, 14, 2129–2146. [Google Scholar] [CrossRef]
- Cui, P.; Zhou, G.G.D.; Zhu, X.H.; Zhang, J.Q. Scale amplification of natural debris flows caused by cascading landslide dam failures. Geomorphology 2013, 182, 173–189. [Google Scholar] [CrossRef]
- National Geological Disaster Bulletin. Available online: http://www.cigem.cgs.gov.cn/gzdt_4839/dwdt_4861/201904/t20190417_479382.html (accessed on 17 April 2019).
- Wang, F.; Zhang, Y.M.; Huo, Z.T.; Peng, X.M.; Wang, S.M.; Yamasaki, S. Mechanism for the rapid motion of the Qianjiangping landslide during reactivation by the first impoundment of the Three Gorges Dam reservoir, China. Landslides 2008, 5, 379–386. [Google Scholar] [CrossRef]
- Xu, G.L.; Li, W.N.; Yu, Z.; Ma, X.H.; Yu, Z.Z. The 2 September 2014 Shanshucao landslide, Three Gorges Reservoir, China. Landslides 2015, 12, 1169–1178. [Google Scholar] [CrossRef]
- Cascini, L. Applicability of landslide susceptibility and hazard zoning at different scales. Eng. Geol. 2008, 102, 164–177. [Google Scholar] [CrossRef]
- Corominas, J.; van Westen, C.; Frattini, P.; Cascini, L.; Malet, J.P.; Fotopoulou, S.; Catani, F.; Van Den Eeckhaut, M.; Mavrouli, O.; Agliardi, F.; et al. Recommendations for the quantitative analysis of landslide risk. Bull. Eng. Geol. Environ. 2014, 73, 209–263. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Yin, K.L.; Yan, T.Z. Statistical prediction models for slope instability of metamorphosed rocks. In Proceedings of the Landslides, Vols 1-3, Rotterdam, The Netherlands, 10–15 July 1988; pp. 1269–1272. [Google Scholar]
- Zhu, C.H.; Wang, X.P.; Soc, I.C. Landslide Susceptibility Mapping: A Comparison of Information and Weights-Of-Evidence Methods in Three Gorges Area; IEEE Computer Society: Los Alamitos, CA, USA, 2009; pp. 342–346. [Google Scholar]
- Ayalew, L.; Yamagishi, H. The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko Mountains, Central Japan. Geomorphology 2005, 65, 15–31. [Google Scholar] [CrossRef]
- Kawabata, D.; Bandibas, J. Landslide susceptibility mapping using geological data, a DEM from ASTER images and an Artificial Neural Network (ANN). Geomorphology 2009, 113, 97–109. [Google Scholar] [CrossRef]
- Ermini, L.; Catani, F.; Casagli, N. Artificial Neural Networks applied to landslide susceptibility assessment. Geomorphology 2005, 66, 327–343. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Landslide susceptibility assessment and factor effect analysis: Backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ. Modell. Softw. 2010, 25, 747–759. [Google Scholar] [CrossRef]
- Xu, C.; Dai, F.C.; Xu, X.W.; Lee, Y.H. GIS-based support vector machine modeling of earthquake-triggered landslide susceptibility in the Jianjiang River watershed, China. Geomorphology 2012, 145, 70–80. [Google Scholar] [CrossRef]
- Peng, L.; Niu, R.Q.; Huang, B.; Wu, X.L.; Zhao, Y.N.; Ye, R.Q. Landslide susceptibility mapping based on rough set theory and support vector machines: A case of the Three Gorges area, China. Geomorphology 2014, 204, 287–301. [Google Scholar] [CrossRef]
- Yao, X.; Tham, L.G.; Dai, F.C. Landslide susceptibility mapping based on Support Vector Machine: A case study on natural slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Marjanovic, M.; Kovacevic, M.; Bajat, B.; Vozenilek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Everitt, B.S. Classification and Regression Trees. In Encyclopedia of Statistics in Behavioral Science; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2005. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Regional landslide susceptibility analysis using back-propagation neural network model at Cameron Highland, Malaysia. Landslides 2010, 7, 13–30. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Dholakia, M.B.; Prakash, I.; Pham, H.V.; Mehmood, K.; Le, H.Q. A novel ensemble classifier of rotation forest and Naive Bayer for landslide susceptibility assessment at the Luc Yen district, Yen Bai Province (Viet Nam) using GIS. Geomat. Nat. Hazards Risk 2017, 8, 649–671. [Google Scholar] [CrossRef]
- Shigeo, A. Support Vector Machines for Pattern Classification. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 15–19 July 2001; Volume 36, pp. 7535–7543. [Google Scholar]
- Tian, Y.Y.; Xu, C.; Hong, H.Y.; Zhou, Q.; Wang, D. Mapping earthquake-triggered landslide susceptibility by use of artificial neural network (ANN) models: An example of the 2013 Minxian (China) Mw 5.9 event. Geomat. Nat. Hazards Risk 2019, 10, 1–25. [Google Scholar] [CrossRef]
- Kalantar, B.; Pradhan, B.; Naghibi, S.A.; Motevalli, A.; Mansor, S. Assessment of the effects of training data selection on the landslide susceptibility mapping: A comparison between support vector machine (SVM), logistic regression (LR) and artificial neural networks (ANN). Geomat. Nat. Hazards Risk 2018, 9, 49–69. [Google Scholar] [CrossRef]
- Budimir, M.E.A.; Atkinson, P.M.; Lewis, H.G. A systematic review of landslide probability mapping using logistic regression. Landslides 2015, 12, 419–436. [Google Scholar] [CrossRef] [Green Version]
- Sestras, P.; Bilasco, S.; Rosca, S.; Nas, S.; Bondrea, M.V.; Galgau, R.; Veres, I.; Salagean, T.; Spalevic, V.; Cimpeanu, S.M. Landslides Susceptibility Assessment Based on GIS Statistical Bivariate Analysis in the Hills Surrounding a Metropolitan Area. Sustainability 2019, 11, 23. [Google Scholar] [CrossRef]
- Bai, S.B.; Wang, J.; Lu, G.N.; Zhou, P.G.; Hou, S.S.; Xu, S.N. GIS-based logistic regression for landslide susceptibility mapping of the Zhongxian segment in the Three Gorges area, China. Geomorphology 2010, 115, 23–31. [Google Scholar] [CrossRef]
- Chen, W.T.; Li, X.J.; Wang, Y.X.; Liu, S.W. Landslide susceptibility mapping using LiDAR and DMC data: A case study in the Three Gorges area, China. Environ. Earth Sci. 2013, 70, 673–685. [Google Scholar] [CrossRef]
- Wu, X.L.; Niu, R.Q.; Ren, F.; Peng, L. Landslide susceptibility mapping using rough sets and back-propagation neural networks in the Three Gorges, China. Environ. Earth Sci. 2013, 70, 1307–1318. [Google Scholar] [CrossRef]
- Zhou, C.; Yin, K.L.; Cao, Y.; Ahmed, B.; Li, Y.Y.; Catani, F.; Pourghasemi, H.R. Landslide susceptibility modeling applying machine learning methods: A case study from Longju in the Three Gorges Reservoir area, China. Comput. Geosci. 2018, 112, 23–37. [Google Scholar] [CrossRef] [Green Version]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Technical Requirements for Investigation and Evaluation of Collapse, Landslide, Debris Flow. Available online: http://www.mnr.gov.cn/gk/bzgf/201004/t20100406_1971713.html (accessed on 6 April 2010).
- Bui, D.T.; Lofman, O.; Revhaug, I.; Dick, O. Landslide susceptibility analysis in the Hoa Binh province of Vietnam using statistical index and logistic regression. Natural Hazards 2011, 59, 1413–1444. [Google Scholar] [CrossRef]
- Hanley, J.A.; McNeil, B.J. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 1983, 148, 839–843. [Google Scholar] [CrossRef]
- Miao, H.; Wang, G.; Yin, K.; Kamai, T.; Li, Y. Mechanism of the slow-moving landslides in Jurassic red-strata in the Three Gorges Reservoir, China. Eng. Geol. 2014, 171, 59–69. [Google Scholar] [CrossRef] [Green Version]
- An, K.; Niu, R. Landslide Susceptibility Assessment Using Support Vector Machine Based on Weighted-information Model. J. Yangtze River Sci. Res. Inst. 2016, 33, 47–51. [Google Scholar]
- Marjanovic, M.; Bajat, B.; Kovacevic, M. Landslide Susceptibility Assessment with Machine Learning Algorithms; IEEE: New York, NY, USA, 2009; pp. 273–278. [Google Scholar]
- Chen, W.; Pourghasemi, H.R.; Panahi, M.; Kornejady, A.; Wang, J.L.; Xie, X.S.; Cao, S.B. Spatial prediction of landslide susceptibility using an adaptive neuro-fuzzy inference system combined with frequency ratio, generalized additive model, and support vector machine techniques. Geomorphology 2017, 297, 69–85. [Google Scholar] [CrossRef]
- Bilasco, S.; Horvath, C.; Cocean, P.; Sorocovschi, V.; Oncu, M. Implementation of the usle model using gis techniques. case study the somesean plateau. Carpath. J. Earth Environ. Sci. 2009, 4, 123–132. [Google Scholar]
- Zhou, C.; Yin, K.; Cao, Y.; Ahmed, B. Application of time series analysis and PSO–SVM model in predicting the Bazimen landslide in the Three Gorges Reservoir, China. Eng. Geol. 2016, 204, 108–120. [Google Scholar] [CrossRef]
- Zhou, C.; Yin, K.; Cao, Y.; Intrieri, E.; Ahmed, B.; Catani, F. Displacement prediction of step-like landslide by applying a novel kernel extreme learning machine method. Landslides 2018, 15, 2211–2225. [Google Scholar] [CrossRef] [Green Version]
- Tang, H.; Wasowski, J.; Juang, C.H. Geohazards in the three Gorges Reservoir Area, China–Lessons learned from decades of research. Eng. Geol. 2019, 261, 105267. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Causal Factor | Category | Pixels in Landslide | Pixels in TD | Proportion of LTL | Proportion of DTD | IV | NC |
|---|---|---|---|---|---|---|---|
| Altitude (m) | <300 | 17,324 | 81,071 | 68.71 | 20.41 | 1.752 | 0.990 |
| 300–450 | 6049 | 86,452 | 23.99 | 21.76 | 0.141 | 0.663 | |
| 450–750 | 1839 | 113,518 | 7.29 | 28.57 | −1.970 | 0.337 | |
| >750 | 0 | 116,248 | 0 | 29.26 | −∞ | 0.01 | |
| Slope (°) | <6 | 538 | 8342 | 2.13 | 2.10 | 0.023 | 0.598 |
| 6–15 | 4196 | 30,806 | 16.64 | 7.75 | 1.102 | 0.99 | |
| 15–24 | 9711 | 102,948 | 38.52 | 25.91 | 0.572 | 0.794 | |
| 24–33 | 7608 | 129,123 | 30.18 | 32.50 | −0.107 | 0.402 | |
| 33–51 | 3153 | 118,589 | 12.51 | 29.85 | −1.255 | 0.206 | |
| 51–75 | 6 | 7481 | 0.02 | 1.88 | −6.306 | 0.01 | |
| Aspect (°) | 0–45 | 3427 | 45,388 | 13.59 | 11.42 | 0.251 | 0.849 |
| 45–90 | 2363 | 39,597 | 9.37 | 9.97 | −0.089 | 0.283 | |
| 90–135 | 3380 | 43,368 | 13.41 | 10.92 | 0.296 | 0.99 | |
| 135–180 | 4067 | 60,128 | 16.13 | 15.13 | 0.092 | 0.707 | |
| 180–225 | 2058 | 44,740 | 8.16 | 11.26 | −0.464 | 0.01 | |
| 225–270 | 1750 | 33,824 | 6.94 | 8.51 | −0.295 | 0.141 | |
| 270–315 | 3180 | 50,727 | 12.61 | 12.77 | −0.018 | 0.424 | |
| 315–360 | 4987 | 79,517 | 19.78 | 20.01 | −0.017 | 0.566 | |
| Curvature | −24 to −1 | 3254 | 369,402 | 12.91 | 92.98 | −2.849 | 0.01 |
| −1 to 3 | 21,577 | 26,749 | 85.58 | 6.73 | 3.668 | 0.99 | |
| 3–7 | 372 | 993 | 1.48 | 0.25 | 2.562 | 0.663 | |
| 7–27 | 9 | 145 | 0.04 | 0.04 | −0.032 | 0.337 | |
| Plan curvature | −13 to −1.5 | 562 | 13,106 | 2.23 | 3.30 | −0.566 | 0.5 |
| −1.5 to 1.5 | 24,231 | 372,725 | 96.11 | 93.82 | 0.035 | 0.99 | |
| 1.5–10.5 | 419 | 11,458 | 1.66 | 2.88 | −0.795 | 0.01 | |
| Profile curvature | −18 to −2 | 397 | 11,732 | 1.57 | 2.95 | −0.907 | 0.01 |
| −2 to 2 | 24,319 | 372,535 | 96.46 | 93.77 | 0.041 | 0.99 | |
| 2–18 | 496 | 13,022 | 1.97 | 3.28 | −0.736 | 0.5 | |
| Stream power index (SPI) | 0–2 | 13,724 | 180,391 | 54.43 | 45.41 | 0.262 | 0.99 |
| 2–4 | 4304 | 68,746 | 17.07 | 17.30 | −0.020 | 0.663 | |
| 4–8 | 3196 | 63,159 | 12.68 | 15.90 | −0.327 | 0.337 | |
| >8 | 3988 | 84,993 | 15.82 | 21.39 | −0.436 | 0.01 | |
| Topographic wetness index (TWI) | 0–4.5 | 18,990 | 289,614 | 75.32 | 72.90 | 0.047 | 0.663 |
| 4.5–6.5 | 4856 | 85,391 | 19.26 | 21.49 | −0.158 | 0.337 | |
| 6.5–8.5 | 954 | 14,335 | 3.78 | 3.61 | 0.069 | 0.99 | |
| >8.5 | 412 | 7949 | 1.63 | 2.00 | −0.292 | 0.01 | |
| Terrain roughness index (TRI) | 1–1.2 | 22,324 | 278,274 | 88.55 | 70.04 | 0.338 | 0.99 |
| 1.2–1.4 | 2645 | 93,562 | 10.49 | 23.55 | −1.167 | 0.663 | |
| 1.4–1.6 | 239 | 18,431 | 0.95 | 4.64 | −2.291 | 0.337 | |
| Distance to rivers (m) | >1.6 | 4 | 7022 | 0.02 | 1.77 | −6.800 | 0.01 |
| 0–150 | 9958 | 41,767 | 39.50 | 10.51 | 1.910 | 0.99 | |
| 150–300 | 5659 | 35,396 | 22.45 | 8.91 | 1.333 | 0.794 | |
| 300–650 | 5047 | 67,801 | 20.02 | 17.07 | 0.230 | 0.598 | |
| 650–950 | 2259 | 47,096 | 8.96 | 11.85 | −0.404 | 0.402 | |
| 950–1550 | 1808 | 69,776 | 7.17 | 17.56 | −1.292 | 0.206 | |
| >1550 | 481 | 135,453 | 1.91 | 34.09 | −4.160 | 0.01 | |
| Distance to gully (m) | 0–150 | 15,036 | 194,536 | 59.64 | 48.97 | 0.284 | 0.99 |
| 150–350 | 7653 | 106,289 | 30.35 | 26.75 | 0.182 | 0.75 | |
| 350–500 | 1553 | 30,901 | 6.16 | 7.78 | −0.337 | 0.5 | |
| 500–900 | 962 | 36,022 | 3.82 | 9.07 | −1.249 | 0.26 | |
| >900 | 8 | 29,541 | 0.03 | 7.44 | −7.872 | 0.01 | |
| Distance to faults (m) | 0–450 | 14,652 | 154,959 | 58.12 | 39.00 | 0.575 | 0.99 |
| 450–900 | 7121 | 77,607 | 28.24 | 19.53 | 0.532 | 0.663 | |
| 900–1750 | 3155 | 75,914 | 12.51 | 19.11 | −0.611 | 0.337 | |
| >1750 | 284 | 88,809 | 1.13 | 22.35 | −4.311 | 0.01 | |
| Lithology (L) | L1 | 3890 | 47,612 | 15.43 | 11.98 | 0.365 | 0.598 |
| L2 | 15,126 | 132,299 | 60.00 | 33.30 | 0.849 | 0.794 | |
| L3 | 1316 | 20,209 | 5.22 | 5.09 | 0.037 | 0.402 | |
| L4 | 2003 | 16,307 | 7.94 | 4.10 | 0.953 | 0.99 | |
| L5 | 0 | 11,826 | 0.00 | 2.98 | −∞ | 0.01 | |
| L6 | 2877 | 168,880 | 11.41 | 42.51 | −1.897 | 0.206 | |
| L7 | 0 | 156 | 0.00 | 0.04 | −∞ | 0.01 | |
| Bedding structure (BS) | BS1 | 206 | 509 | 0.82 | 0.13 | 2.673 | 0.99 |
| BS2 | 1423 | 34,200 | 5.64 | 8.61 | −0.609 | 0.173 | |
| BS4 | 3204 | 87,211 | 12.71 | 21.95 | −0.789 | 0.337 | |
| BS5 | 4695 | 87,741 | 18.62 | 22.08 | −0.246 | 0.01 | |
| BS6 | 8549 | 113,523 | 33.91 | 28.57 | 0.247 | 0.5 | |
| BS7 | 3721 | 39,376 | 14.76 | 9.91 | 0.574 | 0.663 | |
| BS8 | 3414 | 34,729 | 13.54 | 8.74 | 0.631 | 0.827 |
| Category | Main Lithology | Geologic Group |
|---|---|---|
| A | Siltstone, silty mudstone | T2b2 |
| B | Siltstone, muddy limestone, dolostone with mudstone | T2b3, T2b4 |
| C | Mudstone, muddy limestone | T2b1 |
| D | Sandstone, silty shale | T3xj1, T3e |
| E | Muddy limestone with limestone | T1d1, T1d2, T1d3, T1d4 |
| F | Limestone with dolostone, muddy limestone, dolomitic limestone | T1j1, T1j2, T1j3, T1j4 |
| G | Limestone, silty shale with coal seam | P3w, P3d |
| Category | |
|---|---|
| BS1 | |
| BS2 | |
| BS3 | |
| BS4 | |
| BS5 | |
| BS6 | |
| BS7 | |
| BS8 |
| Factor | Original Factor System | New Factor System | ||
|---|---|---|---|---|
| Tolerances | VIF | Tolerances | VIF | |
| Altitude | 0.176 | 5.687 | / | / |
| Slope | 0.535 | 1.870 | 0.536 | 1.867 |
| Aspect | 0.979 | 1.021 | 0.980 | 1.021 |
| Curvature | 0.846 | 1.183 | 0.849 | 1.178 |
| Plan curvature | 0.926 | 1.080 | 0.927 | 1.079 |
| Profile curvature | 0.876 | 1.142 | 0.876 | 1.142 |
| TRI | 0.522 | 1.916 | 0.522 | 1.914 |
| Lithology | 0.489 | 2.044 | 0.544 | 1.837 |
| Bedding structure | 0.939 | 1.065 | 0.941 | 1.063 |
| Distance to faults | 0.603 | 1.658 | 0.627 | 1.595 |
| Distance to rivers | 0.235 | 4.259 | 0.751 | 1.332 |
| Distance to gully | 0.769 | 1.300 | 0.802 | 1.247 |
| Model | Eliminating Less Important Factors | Accuracy |
|---|---|---|
| Model 1 | Without eliminating any factor | 0.918 |
| Model 2 | TWI | 0.918 |
| Model 3 | TWI, profile curvature | 0.920 |
| Model 4 | TWI, profile curvature, plan curvature | 0.919 |
| Model 5 | TWI, profile curvature, plan curvature, curvature | 0.922 |
| Model 6 | TWI, profile curvature, plan curvature, curvature, aspect | 0.908 |
| Models | Parameters | Notes |
|---|---|---|
| SVM | c = 20, γ = 1.3 | c is the penalty factor, γ is the parameter of the kernel function |
| ANN | n = 5, α = 0.9 | n is the neurons number, α is the momentum |
| Susceptibility Level | Pixels in Landslide | Pixels in Domain | Proportion of LD | Proportion of LTL | Proportion of DTD | Frequency Ratios |
|---|---|---|---|---|---|---|
| SVM | ||||||
| Very low | 6 | 154,275 | 0.00% | 0.02% | 38.83% | 0.001 |
| Low | 210 | 83,697 | 0.25% | 0.83% | 21.07% | 0.040 |
| Moderate | 2636 | 79,817 | 3.30% | 10.46% | 20.09% | 0.520 |
| High | 22,360 | 79,500 | 28.13% | 88.69% | 20.01% | 4.432 |
| ANN | ||||||
| Very low | 409 | 160,378 | 0.26% | 1.62% | 40.37% | 0.040 |
| Low | 1741 | 79,155 | 2.20% | 6.91% | 19.92% | 0.347 |
| Moderate | 5479 | 78,975 | 6.94% | 21.73% | 19.88% | 1.093 |
| High | 17,583 | 78,781 | 22.32% | 69.79% | 19.83% | 3.517 |
| LR | ||||||
| Very low | 393 | 161,746 | 0.24% | 1.56% | 40.71% | 0.038 |
| Low | 1838 | 79,127 | 2.32% | 7.29% | 19.92% | 0.366 |
| Moderate | 5640 | 78,411 | 7.19% | 22.37% | 19.74% | 1.133 |
| High | 17,341 | 78,005 | 22.23% | 68.78% | 19.63% | 3.503 |
| CART | ||||||
| Very low | 491 | 160,378 | 0.31% | 1.95% | 40.37% | 0.048 |
| Low | 1341 | 79,419 | 1.69% | 5.32% | 19.99% | 0.266 |
| Moderate | 7621 | 82,440 | 9.24% | 30.23% | 20.75% | 1.457 |
| High | 15,759 | 75,052 | 21.00% | 62.51% | 18.89% | 3.309 |
| Models | Area Under the ROC Curve (AUC) | Standard Error | 95% Confidence Interval | |
|---|---|---|---|---|
| Lower Limit | Upper Limit | |||
| Training group | ||||
| SVM | 0.927 | 0.002 | 0.923 | 0.930 |
| ANN | 0.866 | 0.002 | 0.962 | 0.871 |
| LR | 0.860 | 0.002 | 0.855 | 0.864 |
| CART | 0.842 | 0.003 | 0.837 | 0.847 |
| Prediction group | ||||
| SVM | 0.922 | 0.001 | 0.920 | 0.923 |
| ANN | 0.875 | 0.001 | 0.873 | 0.877 |
| LR | 0.863 | 0.001 | 0.860 | 0.865 |
| CART | 0.837 | 0.001 | 0.835 | 0.840 |
| Authors | Study Area | Accuracy of SVM |
|---|---|---|
| An et al. [38] | The Wangzhou segment of the TGRA | 0.814 |
| Marjanovic et al. [20] | The Fruška Gora Mountain (Serbia) | 0.842 |
| Marjanovic et al. [39] | NW (Northwest) slopes of Fruška Gora Mountain, Serbia | 0.880 |
| Chen et al. [40] | Hanyuan county, China | 0.875 |
| Bui et al. [10] | The Son La hydropower basin (Vietnam) | 0.887 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Cao, Y.; Zhou, C.; Wang, Y.; Huo, Z. Landslide Susceptibility Mapping Combining Information Gain Ratio and Support Vector Machines: A Case Study from Wushan Segment in the Three Gorges Reservoir Area, China. Appl. Sci. 2019, 9, 4756. https://doi.org/10.3390/app9224756
Yu L, Cao Y, Zhou C, Wang Y, Huo Z. Landslide Susceptibility Mapping Combining Information Gain Ratio and Support Vector Machines: A Case Study from Wushan Segment in the Three Gorges Reservoir Area, China. Applied Sciences. 2019; 9(22):4756. https://doi.org/10.3390/app9224756
Chicago/Turabian StyleYu, Lanbing, Ying Cao, Chao Zhou, Yang Wang, and Zhitao Huo. 2019. "Landslide Susceptibility Mapping Combining Information Gain Ratio and Support Vector Machines: A Case Study from Wushan Segment in the Three Gorges Reservoir Area, China" Applied Sciences 9, no. 22: 4756. https://doi.org/10.3390/app9224756
APA StyleYu, L., Cao, Y., Zhou, C., Wang, Y., & Huo, Z. (2019). Landslide Susceptibility Mapping Combining Information Gain Ratio and Support Vector Machines: A Case Study from Wushan Segment in the Three Gorges Reservoir Area, China. Applied Sciences, 9(22), 4756. https://doi.org/10.3390/app9224756