1. Introduction
Numerical simulation is the most popular method for studying engineering and physical problems, and the finite element method (FEM) is the most widely developed and mature method. However, the accuracy of FEM simulation results is dominated by the quality of the mesh. This is not only because the mesh is the basis of discretization, but also because of the poor condition of stiffness matrices caused by poor mesh. To obtain a high quality mesh, many mesh generation methods have been proposed [
1]. The original mesh generated by those improved methods then needs further optimization. Mesh clean-up and mesh smoothing are the two major categories of optimization. The former improves the mesh quality by changing the original topology [
2,
3], such as by encryption and reordering [
4]. Mesh smoothing, which relocates vertices to improve the mesh quality, is a simpler method and retains the mesh topology [
5,
6,
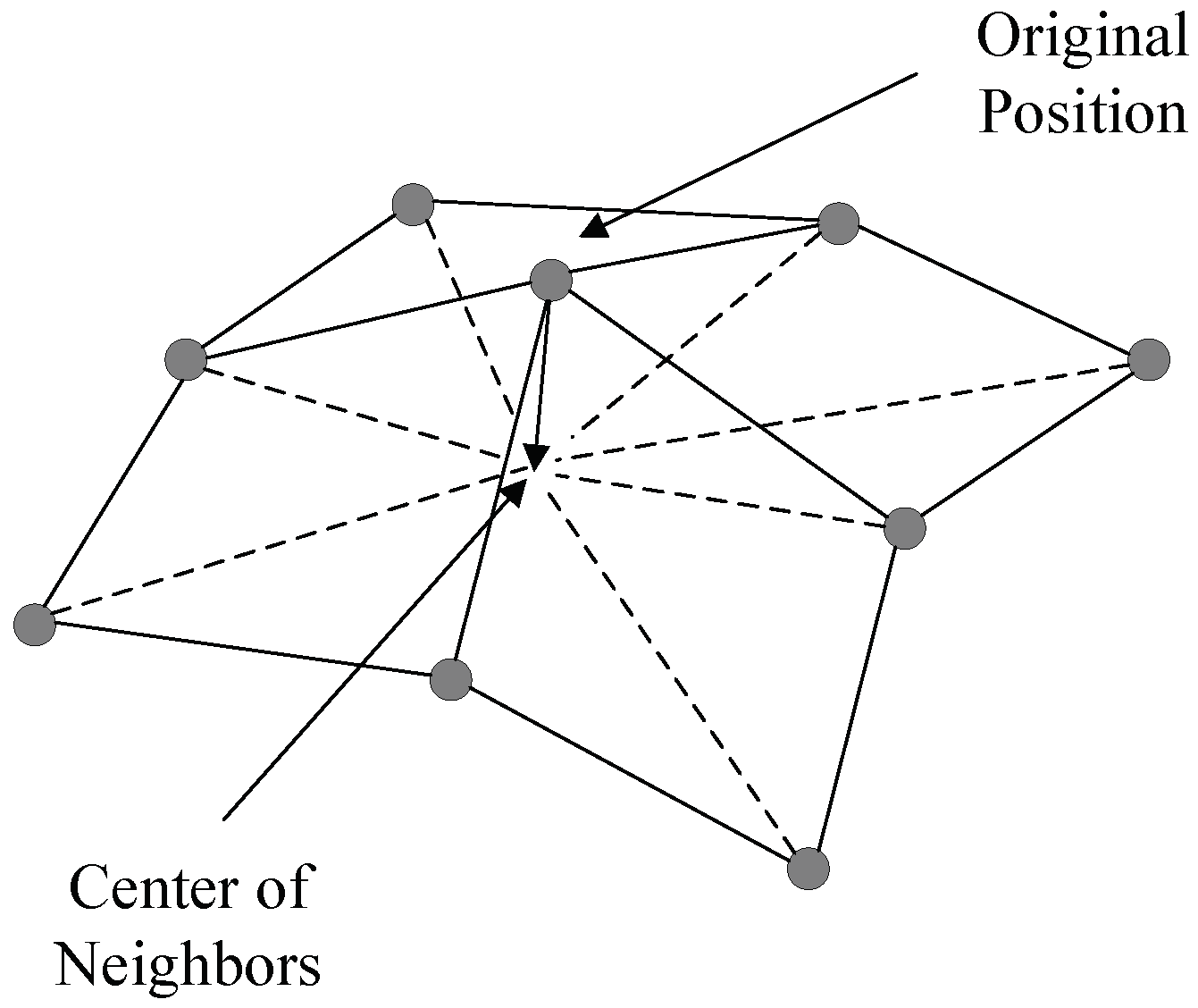
7]. Laplacian smoothing is a commonly used mesh smoothing methods that moves nodes in the mesh to the geometric center of the adjacent nodes [
8]. Laplacian smoothing is easy to implement and use because it does not require other complex operations. Various versions of Laplacian smoothing have been developed to improve the performance of the original form of Laplacian smoothing [
9,
10,
11].
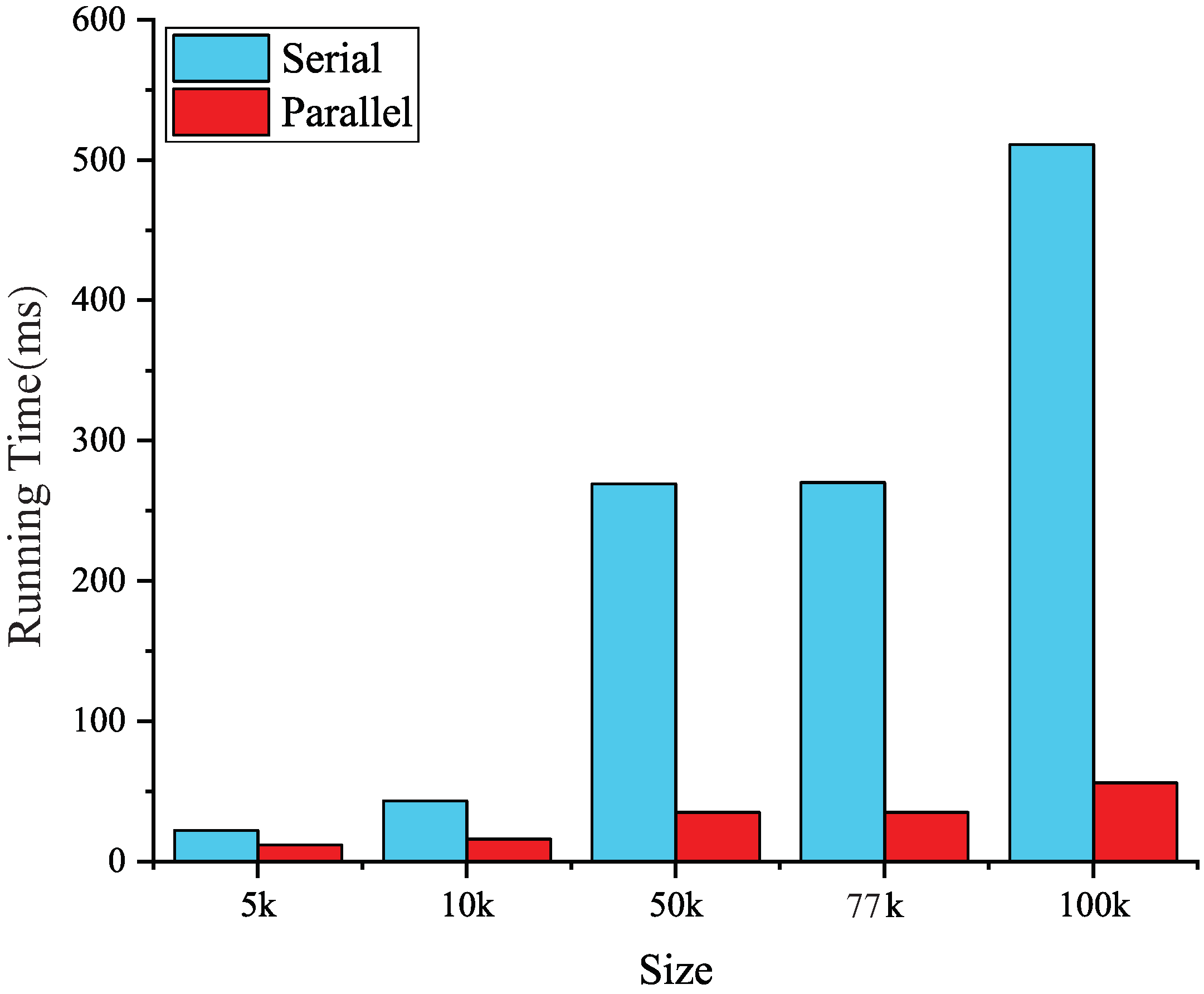
However, when dealing with complex meshes consisting of a large number of nodes and elements, the computation is usually expensive due to the iteration process. To improve the efficiency of smoothing, parallel computing is introduced as an effective strategy [
12]. The parallel implementation of Laplacian smoothing has been developed with the computational power of modern multi-core central processing unit (CPU) and GPU.
For example, Jiao et al. [
13] developed a parallel mesh smoothing algorithm for curved surface meshes that can retain the original features of the mesh. It was implemented on 128 processors of distributed storage computers. Sastry and Shontz [
14] proposed a new parallel method to untangle log-barrier meshes and improve their quality with the help of an open message passing interface (OpenMPI). The experimental results show that the execution time fluctuates within a certain range when the size of the mesh is proportional to the number of processors executing the algorithm. Cebrián et al. [
15] proposed an efficient code modernization strategies to 3-D Stencil-based applications while the use of aligned data layout and the dynamic parallel policy can significantly improve the performance. Titarenko and Hildyard [
16] presented a new approach for parallelisation of a finite difference code on a single processor. The rearranging of data structure can be a useful strategy in utilizing vectorisation. Sangeet Dahal and Timothy S. Newman [
17] developed an efficient smoothing method for 2D meshes on a GPU and the GPU algorithm has a speedup of 10 to 50 times. Benitez [
18] proposed a highly scalable algorithm for tetrahedral meshes derived from a sequential mesh optimization method. Hernández et al. [
19] analyze the programmability, performance and energy using a 3-D Finite Difference implementation to evaluate the efficiency of different massively parallel architectures. The benchmark tests results show the parallel implementation developed on Maxwell GPU is the most power efficient accelerator which provides the direction of future study. D’Amato and Venere [
20] proposed a heterogeneous computing method to optimize the quality of large-scale meshes. The algorithm first determines a possible moving position near the smooth node and then determines the optimal position by evaluating the quality of the moving mesh. By distributing the elements in multiple threads, it avoids the use of lock strategies and possible data access conflicts.
Most recently, Mei et al. [
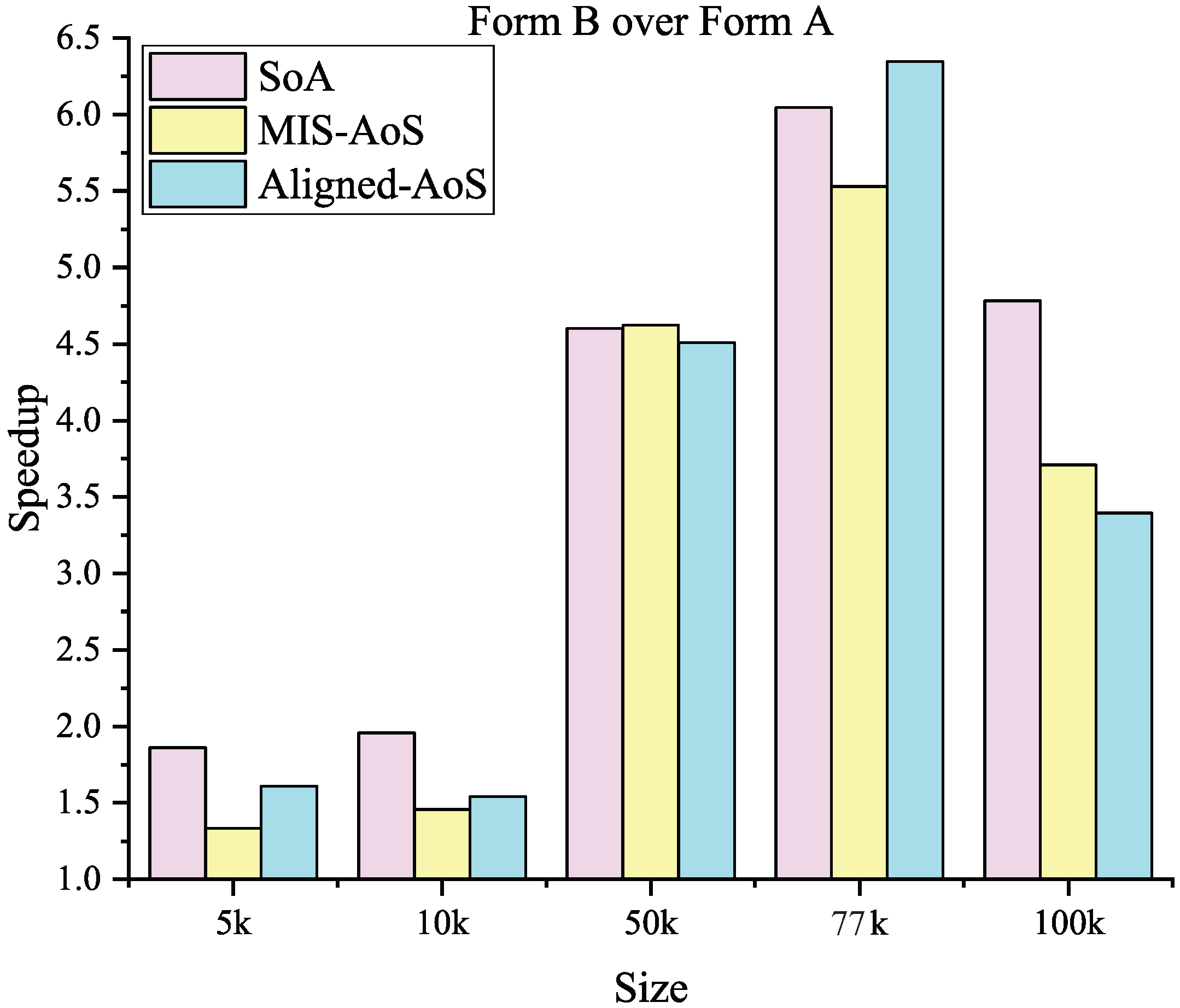
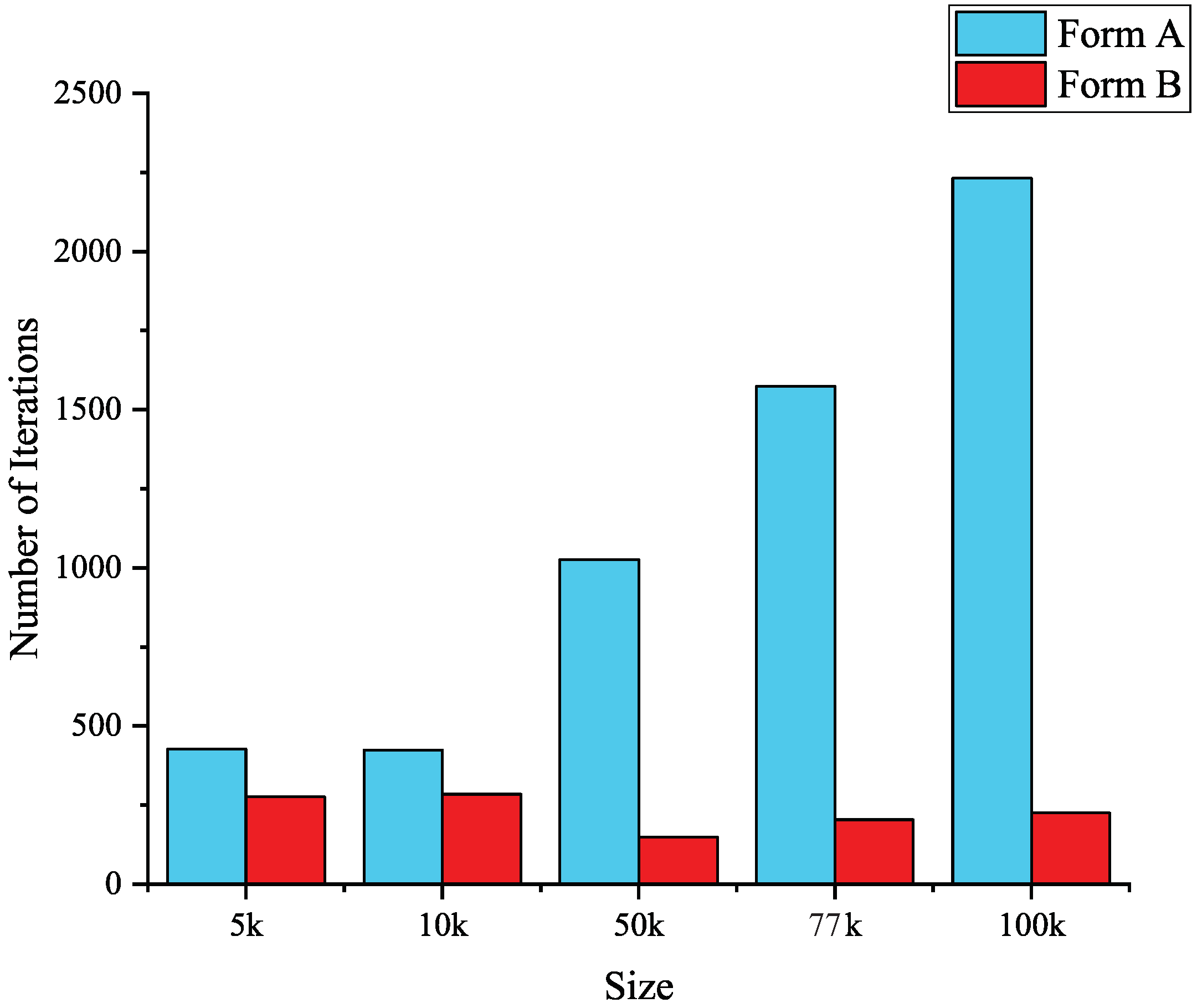
21] presented a more general paradigm for the two major iteration forms of Laplacian smoothing. Two special compute unified device architecture (CUDA) kernels were designed to solve the race condition in neighbor search and data dependence in smooth iteration. Experimental results have indicated that Form A, which needs to swap intermediate nodal coordinates is always slower than the form that does not swap data. Zhao et al. [
22] further optimized the smart Laplacian smoothing algorithm with the help of CUDA dynamic parallelism. This nested CUDA code can greatly simplify the comparison of mesh quality so that the iteration process can be optimized. However, because a parent core needs to call two subcores, the performance of parallel computing is not fully utilized, which results in this version being slightly faster than the original GPU version.
It is remarkable that most of the above studies focused on two dimensional cases. However, it is obvious that mesh composed of tetrahedrons or hexahedrons is more suitable for various kinds of numerical simulations. Therefore, a parallel solution for Laplacian smoothing in three dimensional applications is necessary.
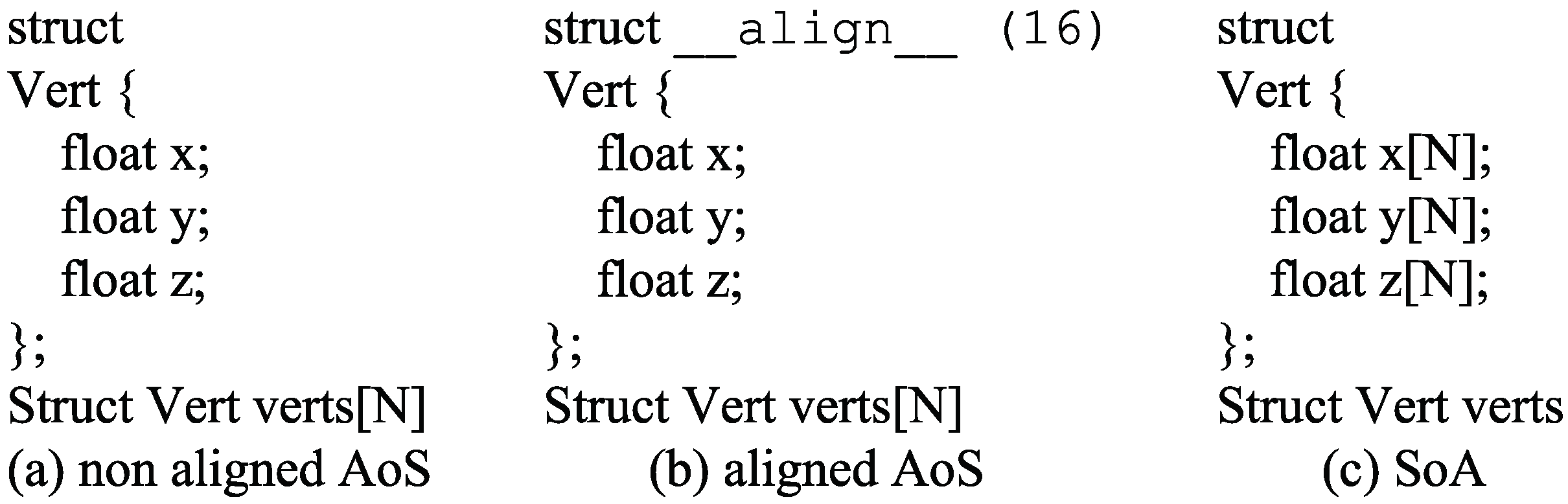
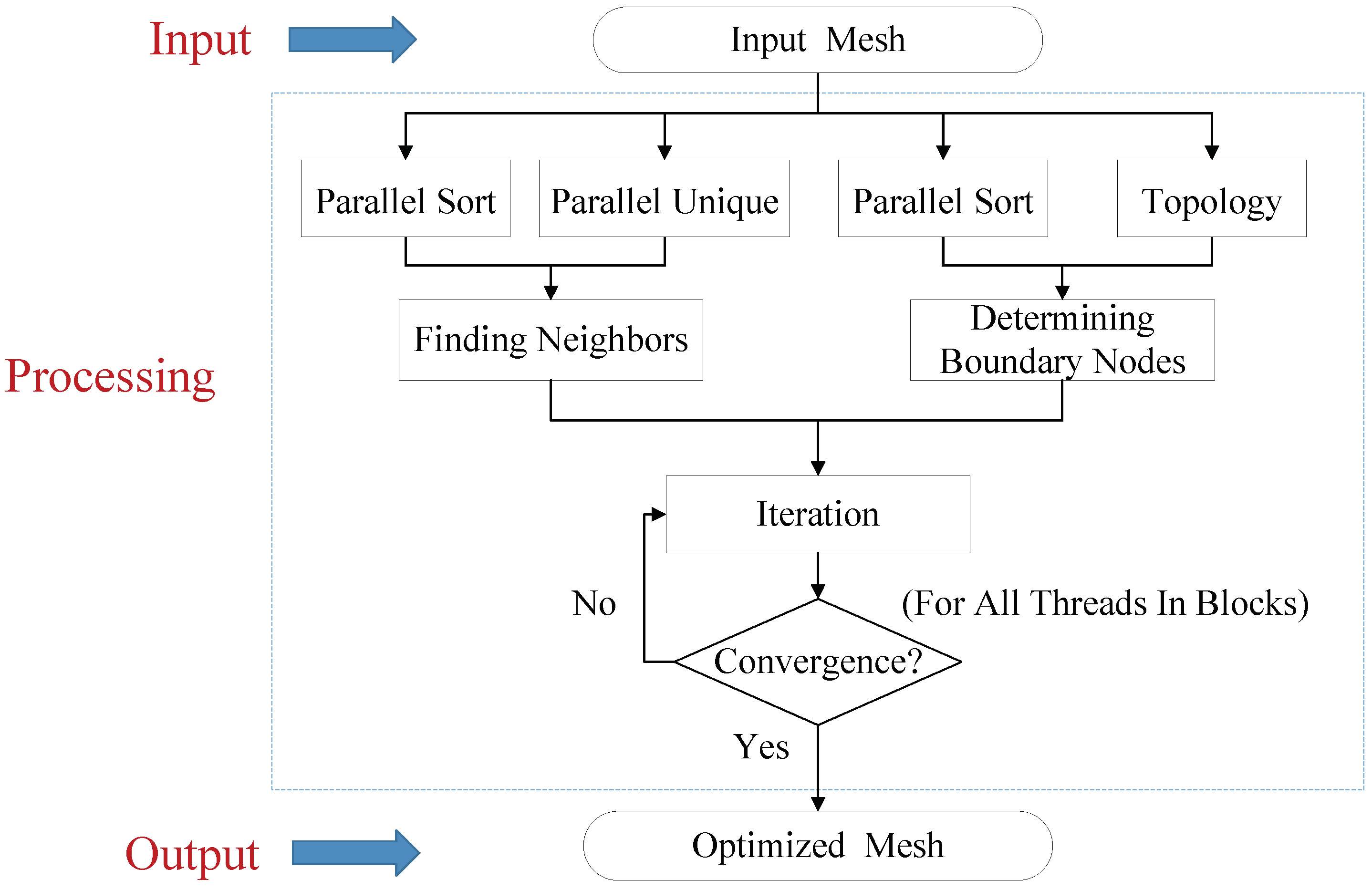
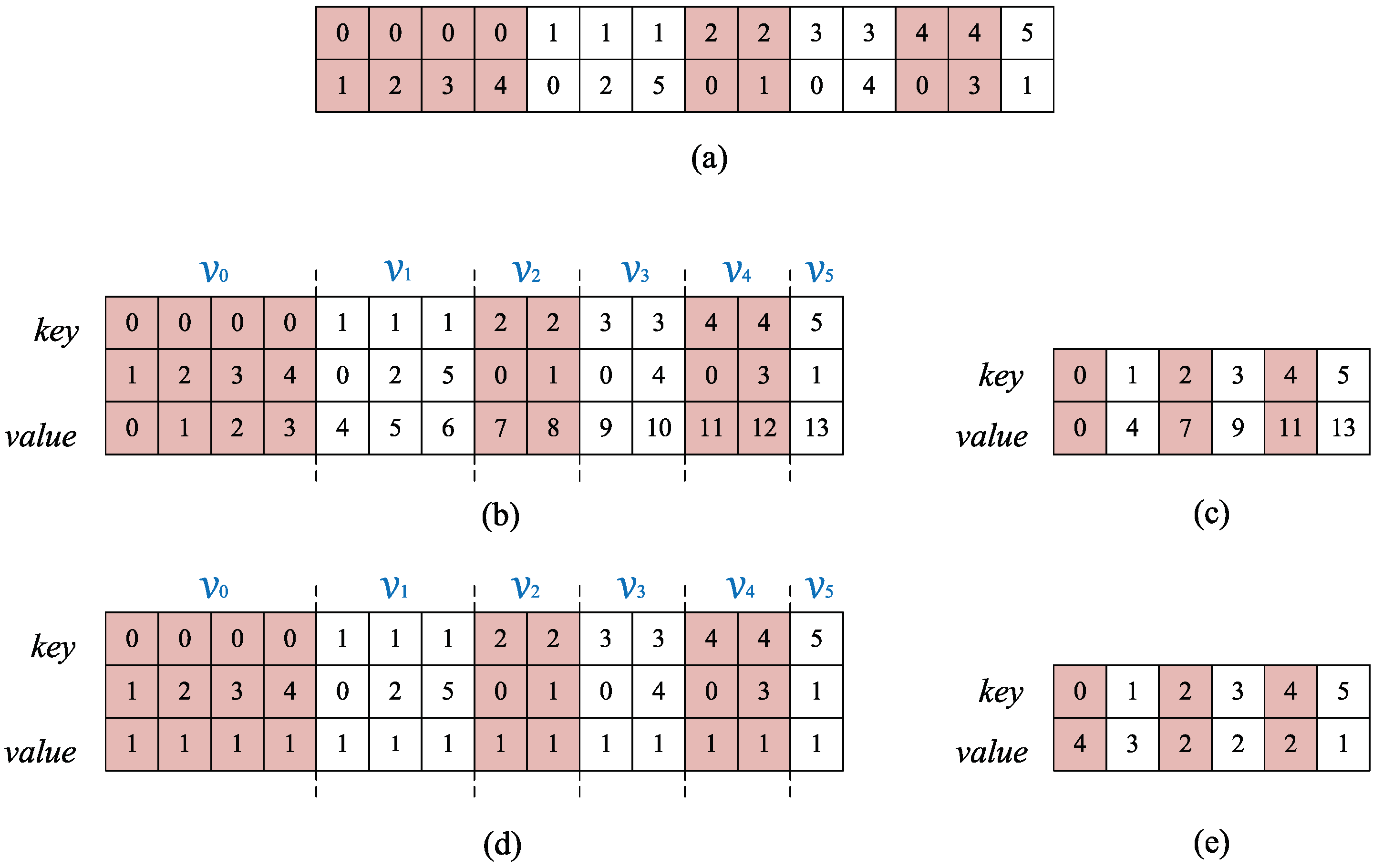
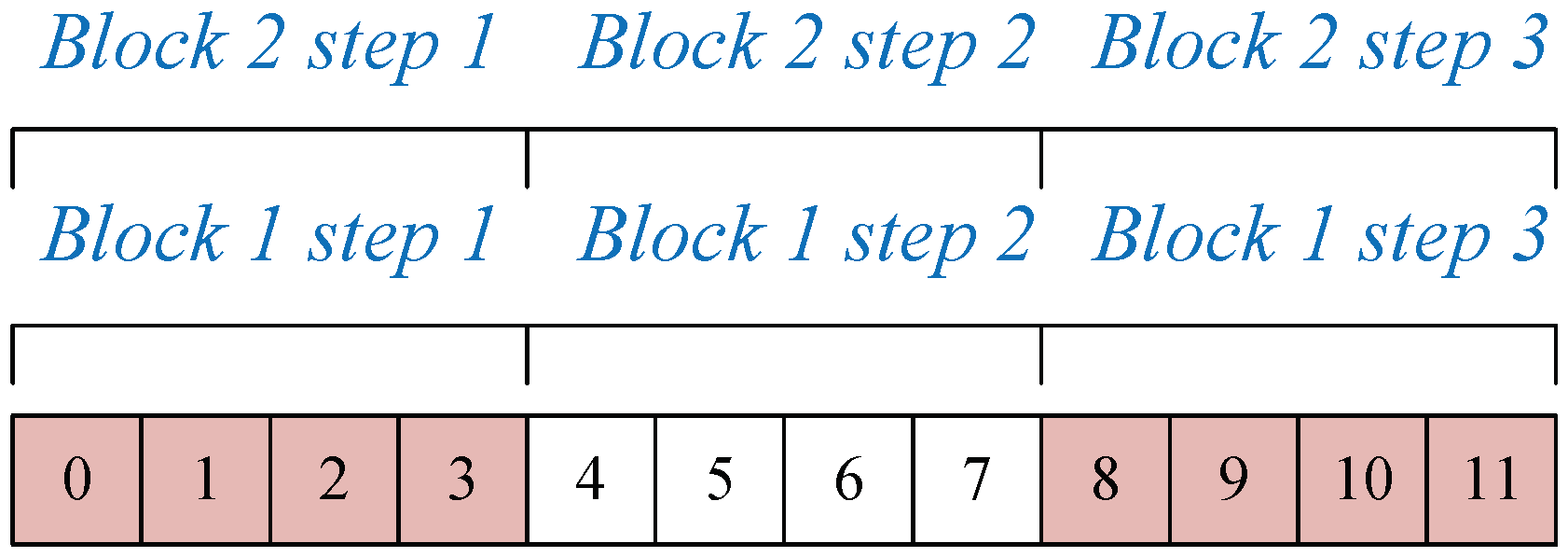
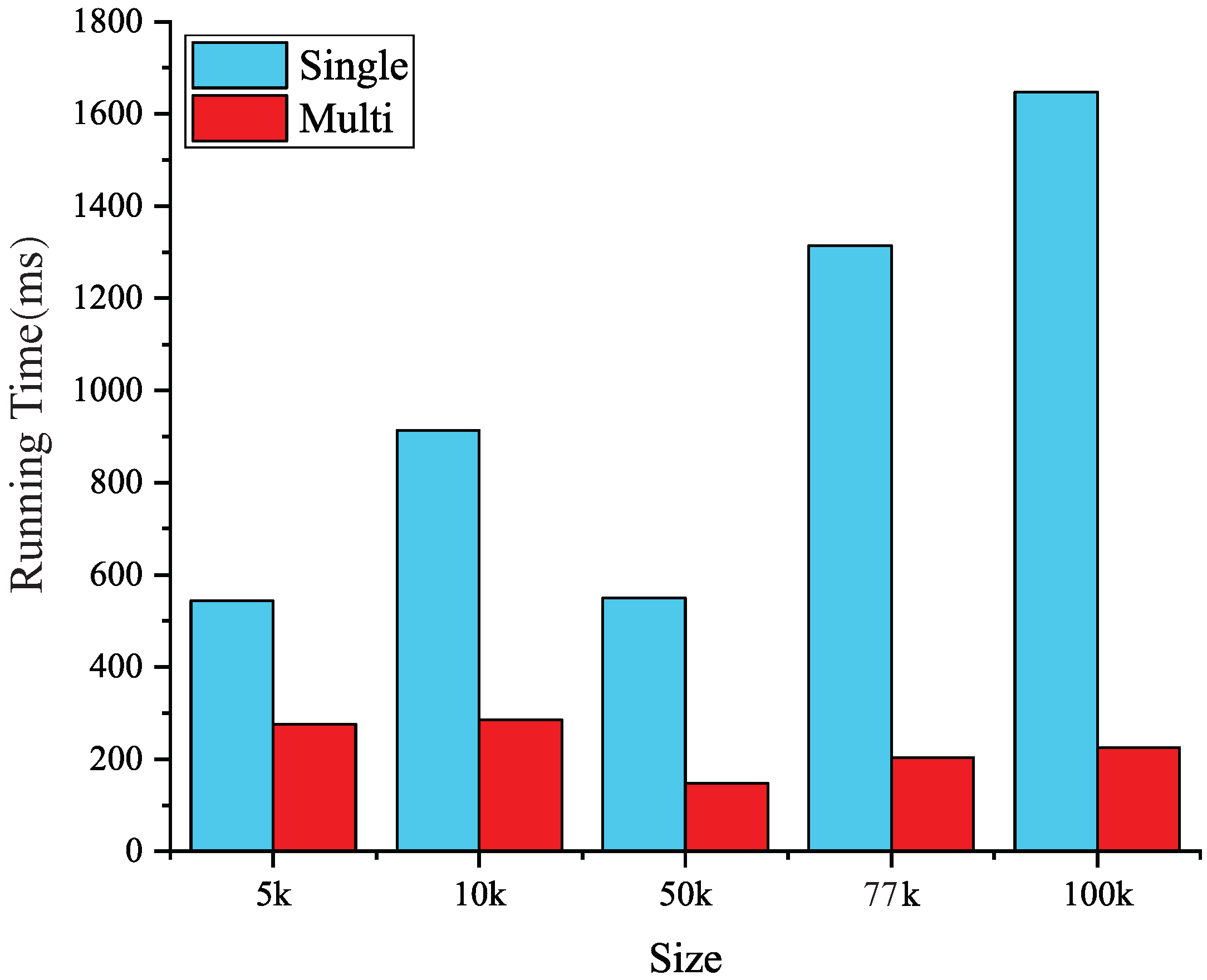
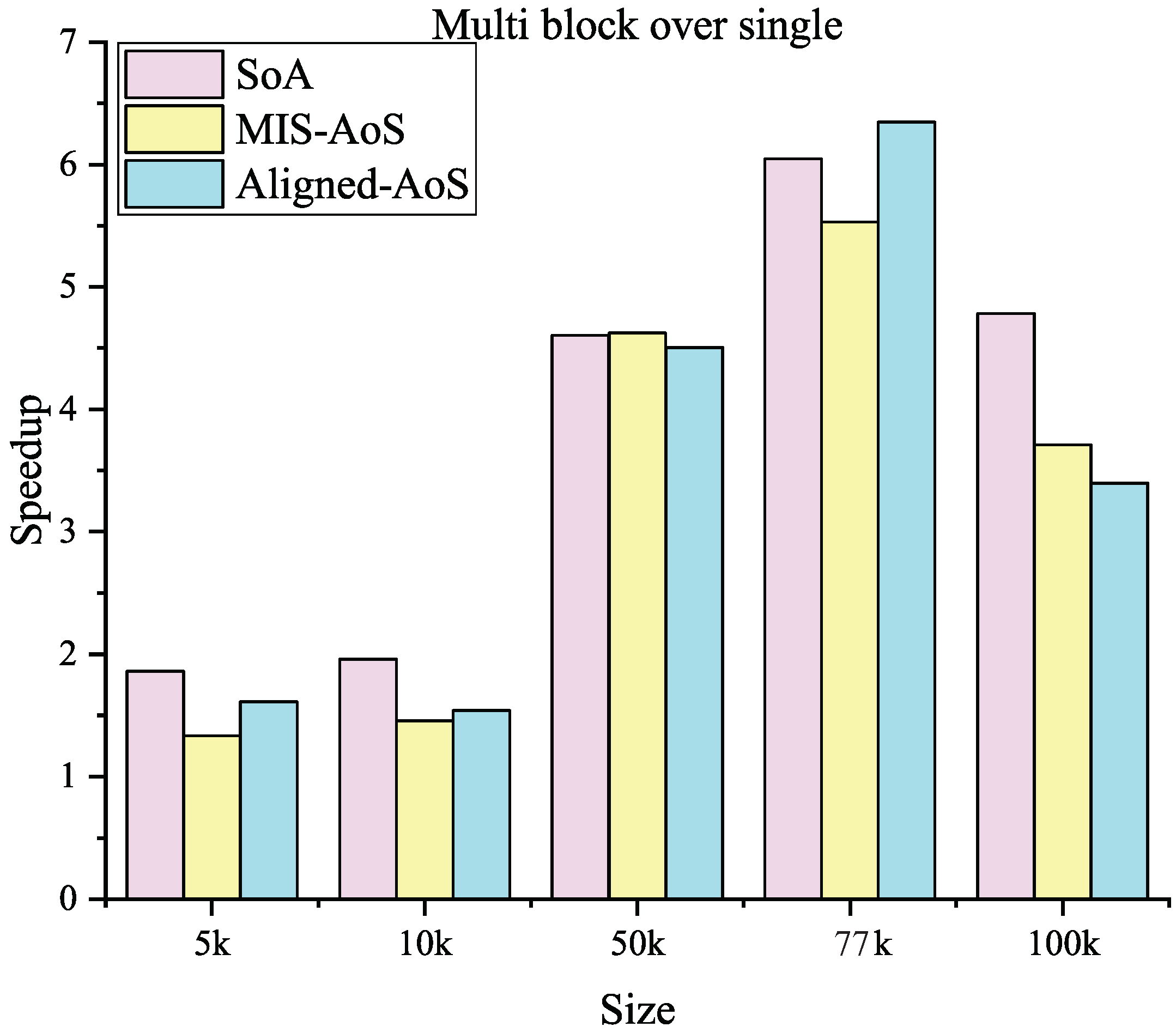
This paper presents an efficient three dimensional Laplacian smoothing based on GPU acceleration. With the help of parallel sort and unique, we search and store the first-order neighbors in the subarea to avoid conflicts. The effects of different data structures are also considered, including the array of non-aligned structures, array of aligned structures, and structure of arrays. In addition, new iteration kernels have been designed, which make full use of the power of the GPU and thus significantly reduce the number of iterations.
The rest of paper is organized as follows. Some basic concepts and principles of Laplacian smoothing and data layout is given in
Section 2. The next
Section 3 presents some key issue and implementation details of 3D parallel Laplacian Smoothing.
Section 4 and
Section 5 mainly elaborate on the results of several groups of experimental tests and the discussion of GPU acceleration performance of each part. Finally, in
Section 6 we present our conclusions.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
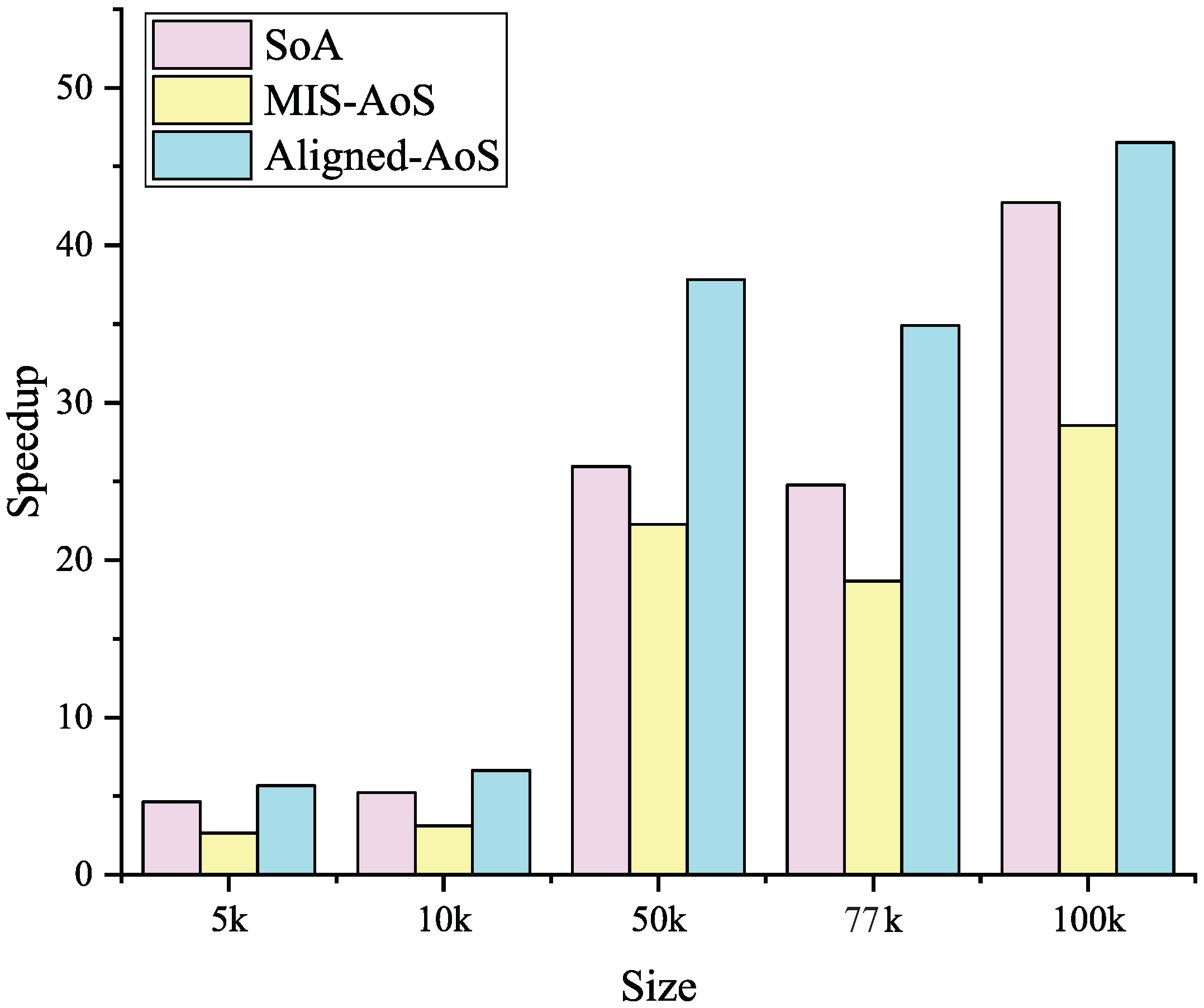{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}