Large-Scale Whale-Call Classification by Transfer Learning on Multi-Scale Waveforms and Time-Frequency Features


Abstract
:1. Introduction
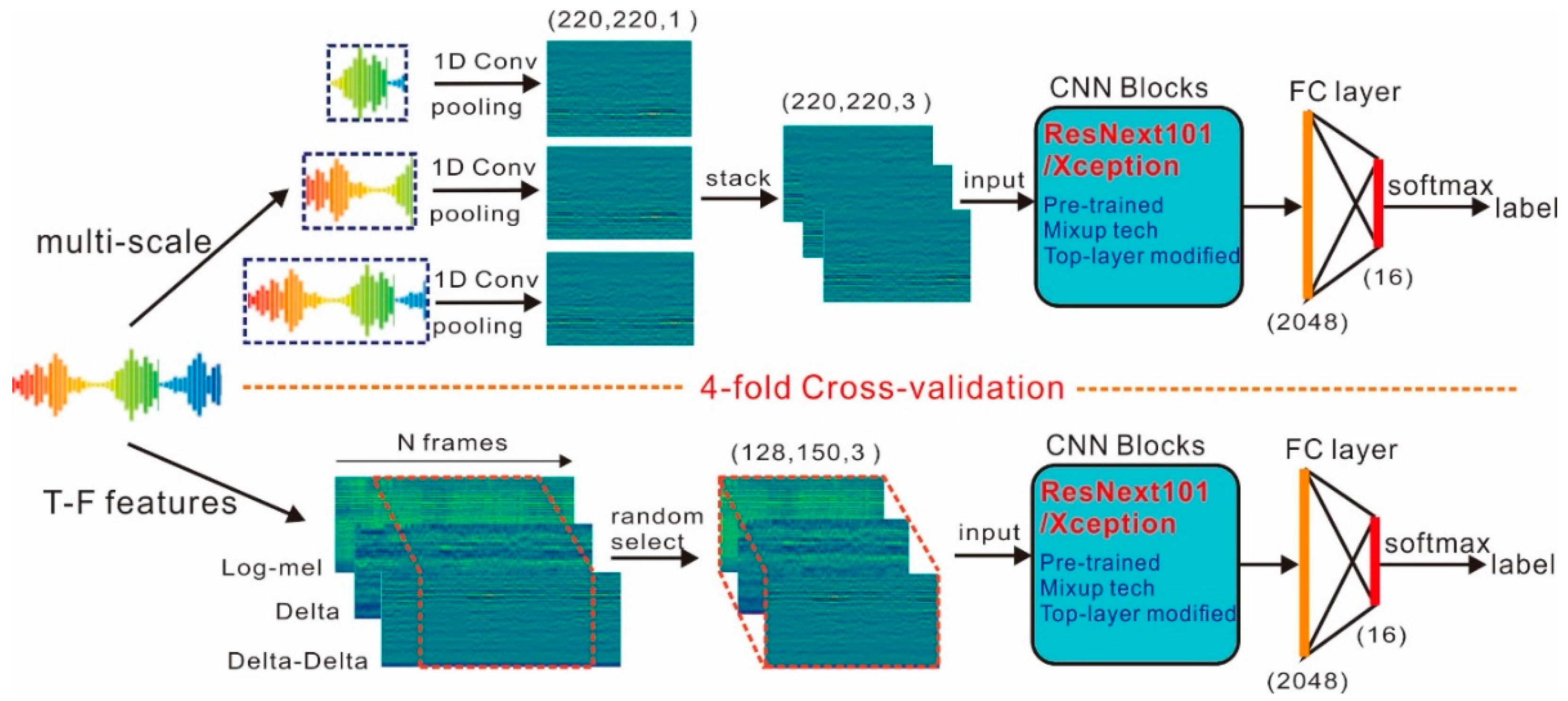
2. Methodology
2.1. Classification on Raw Waveforms
2.2. Classification on Log-Mel Features
2.3. Pre-Trained CNN Models
2.4. Mix-Up Data Augmentation
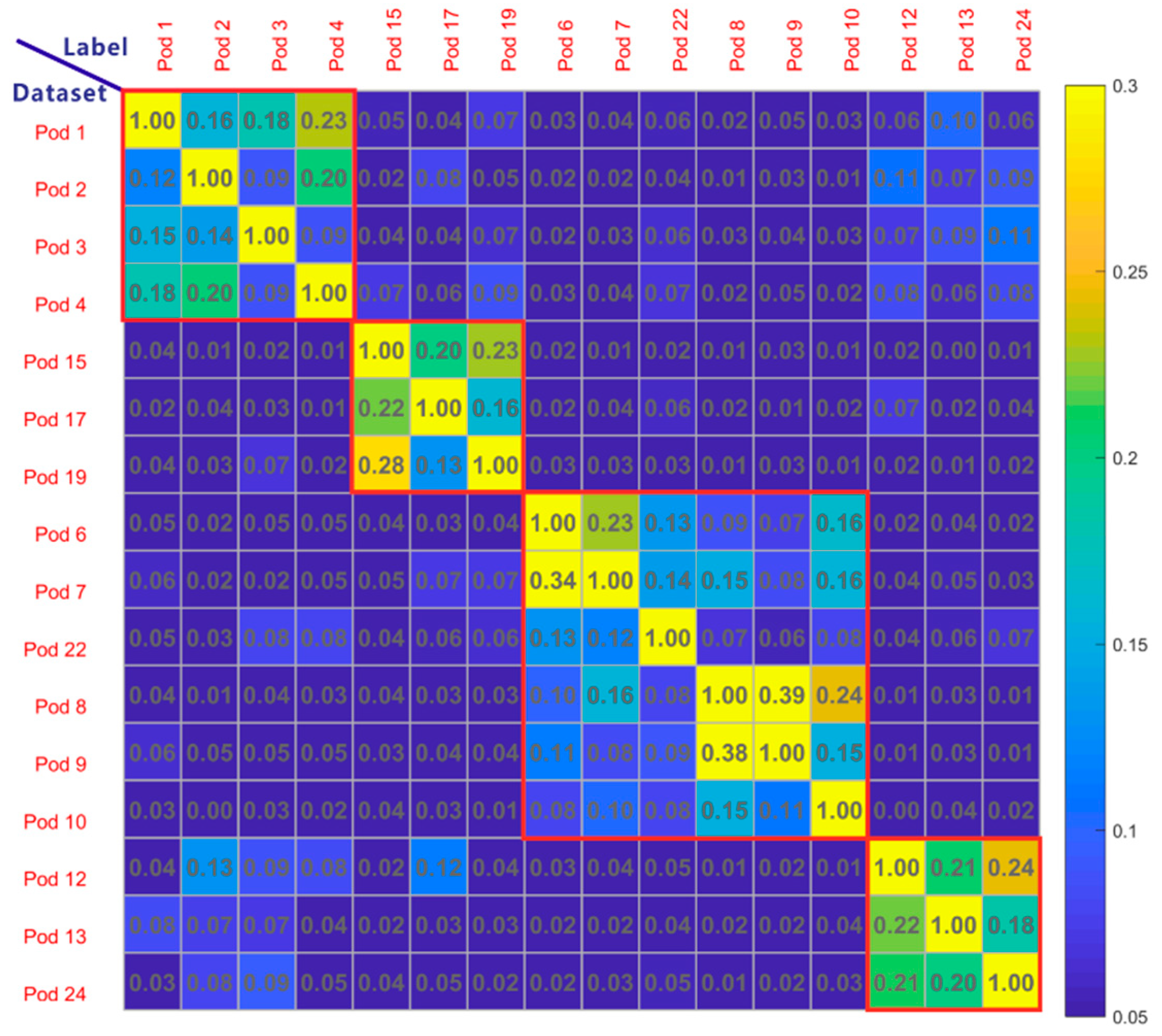
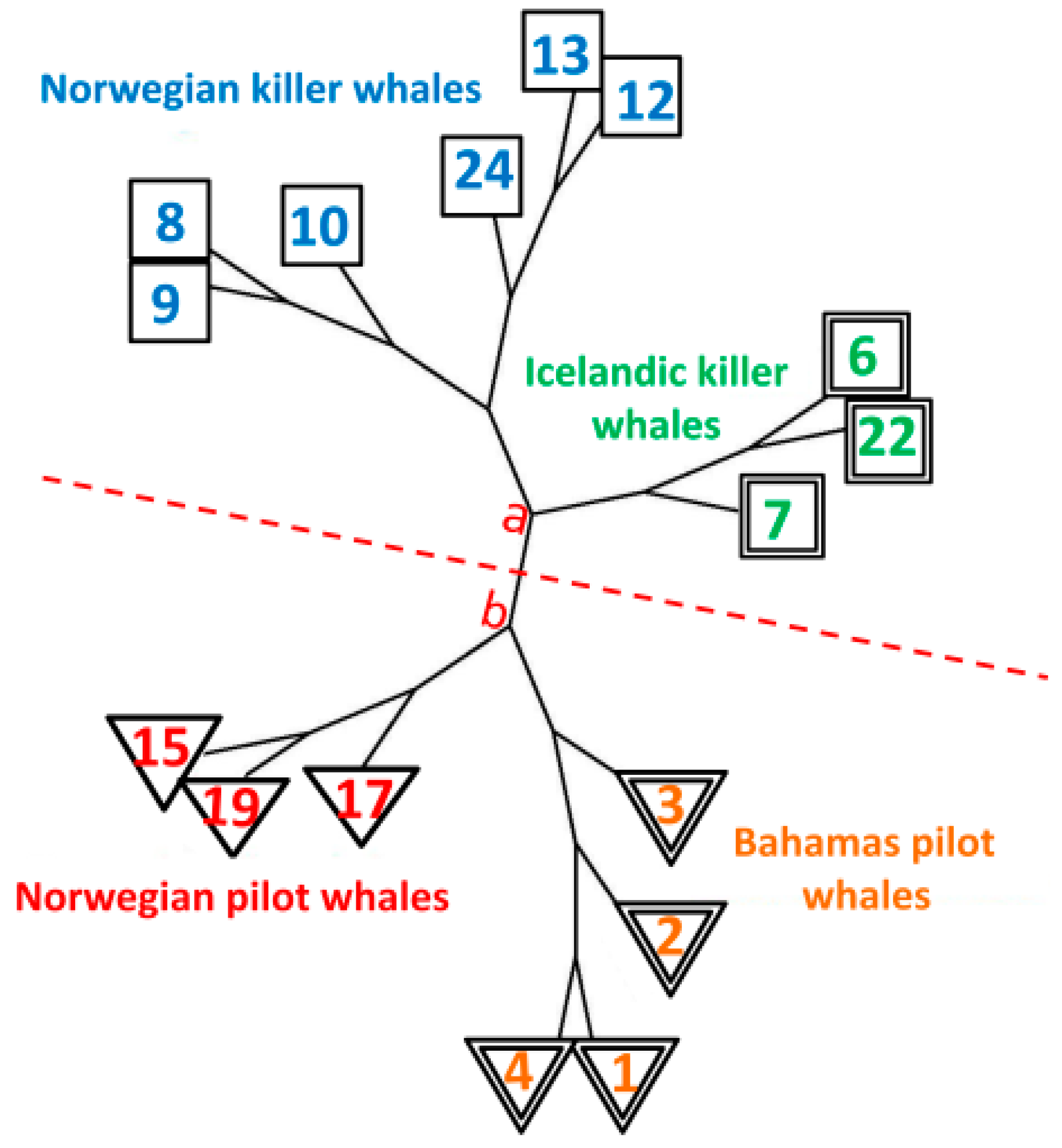
2.5. Similarity Analysis and the Phylogeny
3. Experiments
3.1. Data Preparation
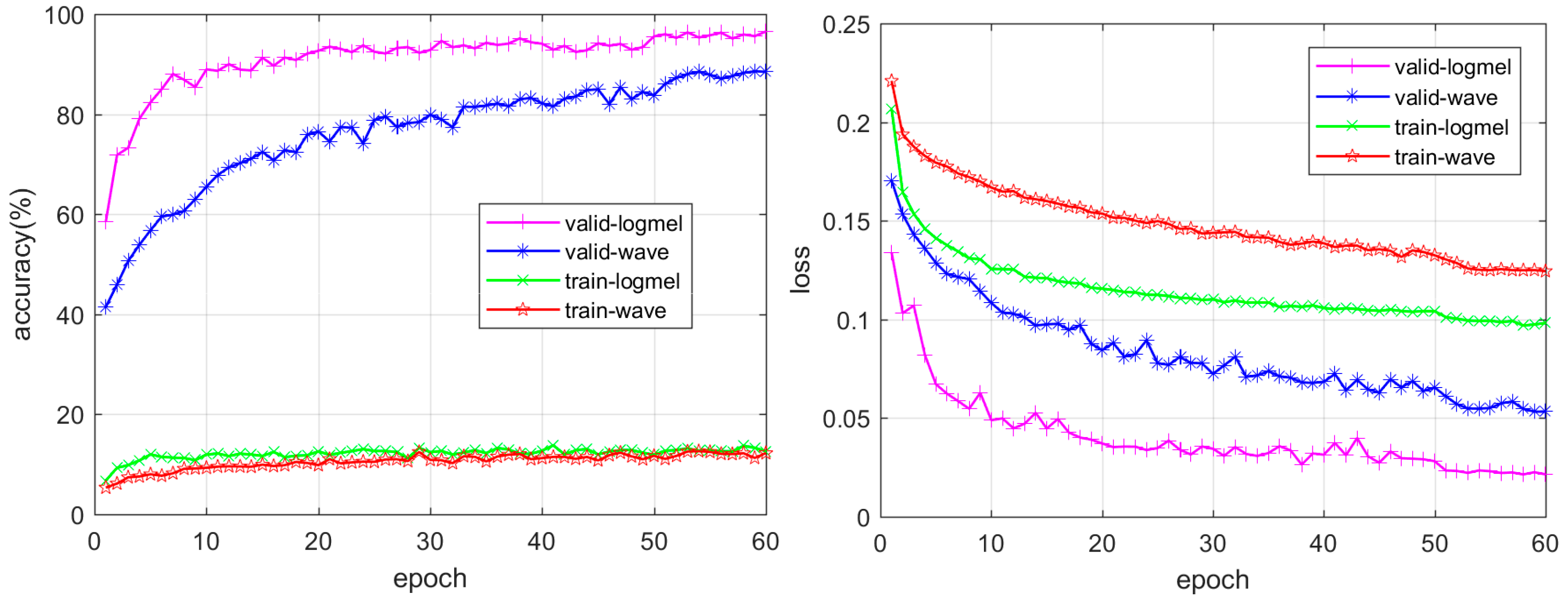
3.2. Model Training
4. Results
4.1. Classification of Whale-Call Data
4.2. Similarity and Phylogenic Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Schevill, W.E.; Watkins, W.A. Sound structure and directionality in Orcinus (killer whale). Zoologica 1966, 51, 71–76. [Google Scholar]
- Ford, J.K.B.; Ellis, G.M.; Balcomb, K.C. Killer Whales: The Natural History and Genealogy of Orinus orca in British Columbia and Washington; University of Washington Press: Washington, DC, USA, 2000. [Google Scholar]
- Ottensmeyer, C.A.; Whitehead, H. Behavioural evidence for social units in long-finned pilot whales. Can. J. Zool. 2003, 81, 1327–1338. [Google Scholar] [CrossRef]
- Miller, P.J.O.; Bain, D.E. Within-pod variation in the sound production of a pod of killer whales, Orcinus orca ☆. Anim. Behav. 2000, 60, 617–628. [Google Scholar] [CrossRef] [PubMed]
- Bahoura, M.; Simard, Y. Blue whale calls classification using short-time Fourier and wavelet packet transforms and artificial neural network. Digit. Signal Process. 2010, 20, 1256–1263. [Google Scholar] [CrossRef]
- Mathias, D.; Thode, A.; Blackwell, S.B.; Greene, C. Computer-aided classification of bowhead whale call categories for mitigation monitoring. In Proceedings of the New Trends for Environmental Monitoring Using Passive Systems, Hyeres, France, 14–17 October 2018; pp. 1–6. [Google Scholar]
- Tolkova, I.; Bauer, L.; Wilby, A.; Kastner, R.; Seger, K. Automatic classification of humpback whale social calls. J. Acoust. Soc. Am. 2017, 141, 3605. [Google Scholar] [CrossRef]
- Baumgartner, M.F.; Mussoline, S.E. A generalized baleen whale call detection and classification system. J. Acoust. Soc. Am. 2011, 129, 2889. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shamir, L.; Yerby, C.; Simpson, R.; von BendaBeckmann, A.M.; Tyack, P.; Samarra, F.; Miller, P.; Wallin, J. Classification of large acoustic datasets using machine learning and crowdsourcing: Application to whale calls. J. Acoust. Soc. Am. 2014, 135, 953–962. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Whale FM Project. Available online: https://whale.fm (accessed on 12 March 2019).
- Shamir, L.; Ling, S.M.; Jr, S.W.; Bos, A.; Orlov, N.; Macura, T.J.; Eckley, D.M.; Ferrucci, L.; Goldberg, I.G. Knee x-ray image analysis method for automated detection of osteoarthritis. IEEE Trans. Biomed. Eng. 2009, 56, 407–415. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional Neural Networks for Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Deng, L.; Abdel-Hamid, O.; Yu, D. A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6669–6673. [Google Scholar]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Salamon, J.; Bello, J. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2016, 24, 279–283. [Google Scholar] [CrossRef]
- Smirnov, E. North Atlantic Right Whale Call Detection with Convolutional Neural Networks. In Proceedings of the ICML 2013 Workshop on Machine Learning for Bioacoustics, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Dorian, C.; Lefort, R.; Bonnel, J.; Zarader, J.L.; Adam, O. Bi-class classification of humpback whale sound units against complex background noise with Deep Convolution Neural Network. Available online: https://arxiv.org/abs/1703.10887 (accessed on 12 March 2019).
- Huzaifah, M. Comparison of Time-Frequency Representations for Environmental Sound Classification using Convolutional Neural Networks. arXiv, 2016; arXiv:1706.07156. [Google Scholar]
- Cui, Z.; Chen, W.; Chen, Y. Multi-Scale Convolutional Neural Networks for Time Series Classification. arXiv, 2016; arXiv:1603.06995. [Google Scholar]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very Deep Convolutional Neural Networks for Complex Land Cover Mapping Using Multispectral Remote Sensing Imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef]
- Rezaee, M.; Mahdianpari, M.; Yun, Z.; Salehi, B. Deep Convolutional Neural Network for Complex Wetland Classification Using Optical Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3030–3039. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning? IEEE Trans. Med. Imaging 2017, 35, 1299. [Google Scholar] [CrossRef] [PubMed]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wei, D.; Metze, F.; Qu, S.; Das, S. A Comparison of deep learning methods for environmental sound. In Proceedings of the IEEE International Conference on Acoustics, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Amaral, T.; Kandaswamy, C.; Silva, L.M.; Alexandre, L.A.; Sá, J.M.D.; Santos, J.M. Improving Performance on Problems with Few Labelled Data by Reusing Stacked Auto-Encoders. In Proceedings of the International Conference on Machine Learning and Applications, Detroit, MI USA, 3–5 December 2014; pp. 367–372. [Google Scholar]
- Dan, C.C.; Meier, U.; Schmidhuber, J. Transfer learning for Latin and Chinese characters with Deep Neural Networks. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; Volume 20, pp. 1–6. [Google Scholar]
- Hitawala, S. Evaluating ResNeXt Model Architecture for Image Classification. arXiv, 2018; arXiv:1805.08700. [Google Scholar]
- Xu, K.; Zhu, B.; Wang, D.; Peng, Y. Meta Learning Based Audio Tagging. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE 2018), Surrey, UK, 19–20 November 2018. [Google Scholar]
- Wei, S.; Xu, K.; Wang, D.; Liao, F.; Wang, H.; Kong, Q. Sample Mixed-Based Data Augmentation For Domestic Audio Tagging. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 (DCASE 2018), Surrey, UK, 19–20 November 2018. [Google Scholar]
- Felsenstein, J. PHYLIP: Phylogeny Inference Package. Cladistics-Int. J. Willi Hennig Soc. 1989, 5, 164–166. [Google Scholar]
- Johnson, M.P.; Tyack, P.L. A digital acoustic recording tag for measuring the response of wild marine mammals to sound. IEEE J. Ocean. Eng. 2003, 28, 3–12. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.J.; Siegmund, D. A comparative study of ordinary cross-validation, v-fold cross-validation and the repeated learning-testing methods. Biometrika 1989, 76, 503–514. [Google Scholar]
- Frey, F. SPSS (Software). Available online: https://www.ibm.com/analytics/spss-statistics-software (accessed on 12 March 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | Location | Pods | Latitude | Longitude | Number of Samples | Sampling Rate |
|---|---|---|---|---|---|---|
| Short-finned pilot whales | Bahamas | 1 | 24 | −77 | 1526 | 22,050 |
| 2 | 24 | −77 | 303 | 22,050 | ||
| 3 | 24 | −77 | 1148 | 22,050 | ||
| 4 | 24 | −77 | 329 | 22,050 | ||
| Killer whales | Iceland | 6 | 63 | −20 | 215 | 32,000 |
| 7 | 63 | −20 | 116 | 48,000 | ||
| 22 | 63 | −20 | 976 | 32,000 | ||
| Killer whales | Norway | 8 | 68 | 16 | 823 | 32,000 |
| 9 | 68 | 16 | 598 | 32,000 | ||
| 10 | 68 | 16 | 288 | 32,000 | ||
| 12 | 68 | 16 | 610 | 32,000 | ||
| 13 | 68 | 16 | 357 | 32,000 | ||
| 24 | 68 | 16 | 200 | 32,000 | ||
| Long-finned pilot whales | Norway | 15 | 67 | 13 | 447 | 48,000 |
| 17 | 68 | 15 | 800 | 48,000 | ||
| 19 | 67 | 14 | 559 | 48,000 |
| Method | Input | Classifier | Classify to 2 Species | Classify to 4 Groups | Classification to 16 Pods |
|---|---|---|---|---|---|
| Wndchrm | spectrum | Polynomial decomposition & Fisher scores | 92% | × | 44~62% |
| ResN-wav | wave | ResNext101 | 99.5% | 97.7% | 91.6% |
| ResN-logm | logmel | ResNext101 | 99.7% | 99.2% | 97.6% |
| Xcep-wav | wave | Xception | 99.3% | 97.3% | 91.2% |
| Xcep-logm | logmel | Xception | 99.5% | 98.3% | 95.1% |
| ResN-wav * | wave | ResNext101 (no-pretrain) | 95.9% | 94.3% | 88.3% |
| ResN-logm * | logmel | ResNext101 (no-pretrain) | 97.2% | 96.8% | 94.2% |
| Xcep-wav * | wave | Xception (no-pretrain) | 95.3% | 93.9% | 87.9% |
| Xcep-logm * | logmel | Xception (no-pretrain) | 96.7% | 95.6% | 93.2% |
| Pods | ResN-wav | ResN-logm | Xcep-wav | Xcep-logm |
|---|---|---|---|---|
| Pod 1 | 91.2% | 98.7% | 92.0% | 97.7% |
| Pod 2 | 88.3% | 93.3% | 83.3% | 96.7% |
| Pod 3 | 94.3% | 98.3% | 91.7% | 96.1% |
| Pod 4 | 86.2% | 89.2% | 90.7% | 95.4% |
| Pod 15 | 83.1% | 95.5% | 86.5% | 92.1% |
| Pod 17 | 95.1% | 97.6% | 91.7% | 93.3% |
| Pod 19 | 75.9% | 93.8% | 71.4% | 89.2% |
| Pod 6 | 97.7% | 97.7% | 93.0% | 93.0% |
| Pod 7 | 87.0% | 91.3% | 91.3% | 91.3% |
| Pod 22 | 100% | 100% | 100% | 100% |
| Pod 8 | 99.4% | 100% | 100% | 100% |
| Pod 9 | 97.5% | 100% | 98.3% | 99.1% |
| Pod 10 | 63.2% | 100% | 73.6% | 100% |
| Pod 12 | 86.7% | 94.3% | 86.0% | 91.8% |
| Pod 13 | 93.0% | 98.6% | 93.0% | 97.2% |
| Pod 24 | 100% | 100% | 100% | 100% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Wang, D.; Bao, C.; Wang, Y.; Xu, K. Large-Scale Whale-Call Classification by Transfer Learning on Multi-Scale Waveforms and Time-Frequency Features. Appl. Sci. 2019, 9, 1020. https://doi.org/10.3390/app9051020
Zhang L, Wang D, Bao C, Wang Y, Xu K. Large-Scale Whale-Call Classification by Transfer Learning on Multi-Scale Waveforms and Time-Frequency Features. Applied Sciences. 2019; 9(5):1020. https://doi.org/10.3390/app9051020
Chicago/Turabian StyleZhang, Lilun, Dezhi Wang, Changchun Bao, Yongxian Wang, and Kele Xu. 2019. "Large-Scale Whale-Call Classification by Transfer Learning on Multi-Scale Waveforms and Time-Frequency Features" Applied Sciences 9, no. 5: 1020. https://doi.org/10.3390/app9051020
APA StyleZhang, L., Wang, D., Bao, C., Wang, Y., & Xu, K. (2019). Large-Scale Whale-Call Classification by Transfer Learning on Multi-Scale Waveforms and Time-Frequency Features. Applied Sciences, 9(5), 1020. https://doi.org/10.3390/app9051020