We show that, by using cache misses, we are not only able to recover an AES 128 bit key using significantly fewer samples than previous approaches, but we can also recover the 256 bits of an AES key. To this end, we need to recover information about two consecutive rounds. As we explain below, we perform this attack in two steps. The first one targets the last round and the second one the penultimate round. A direct cache attack to the penultimate round key is not feasible, so we use the equivalences between encryption and decryption to transform our data and to be able to use cache misses to retrieve the key.
When describing the attacks, we use a nomenclature that is consistent with the terms used when describing AES. The iteration variables, subindexes and superindexes follow this rules:
The elements used in the algorithm are represented by capital letters.
3.3.1. Attack on AES-128
We assume that the attacker shares the cache with the victim, which means he can monitor accesses to the cache with line granularity. We also assume that the attacker has access to the ciphertext. The attacker needs to recover information from each of the four
T-tables. To do so, he can monitor one line of one table, one line of each
T-table or even try to monitor the 16 lines of each of the four tables at the same time (64 lines). The number of samples required to retrieve all the bits of the key will vary in each case as will the effect of the attack observed by the victim [
18]. The more lines monitored at a time, the more noticeable the attack will be. While a slight increase in the encryption time can be assumed to have been caused by other programs or virtual machines running on the same CPU, a higher increase in the encryption time would be quite suspicious.
For each of the evaluated techniques, i.e., Prime+Probe, Prime+Abort, Flush+Reload and Flush+Flush, we use a similar process to retrieve the desired information. The process followed during the attack involves three steps and is the same in all cases:
Setup: Prior to the attack, the attacker has to retrieve the necessary information about where the T-tables are located in memory; that is, their virtual addresses or the cache set in which they are going to be loaded. This way he ensures that the cache is in a known state, ready to perform the attack.
Measurement collection: In this step, the attacker monitors the desired tables, applying each technique between the requested encryptions and stores the gathered information together with the ciphertext. As explained in
Section 2.2, this step can be subdivided into three stages:
initialization,
waiting and
recovering.
Information processing: Finally, the attacker uses the information recovered in the previous steps and the information about the T-tables (the contents of the monitored line) to retrieve the secret key.
These main steps are equivalent to previous proposals [
36,
44]. Other proposals are also applicable to our non-access attack, such as the one suggested by Gülmezoglu et al. [
47], which aims to detect the bounds of the encryptions instead of triggering them. However, this approach also depends on the accuracy of the detection, which introduces a new variable to be considered when comparing the effectiveness of the attack approaches. In contrast, the aforementioned setup can be generalized for all the considered techniques, allowing a fair comparison.
In the following, we describe each of the steps for each of the considered algorithms and their particularities in our experimental setup. We consider two scenarios. In the first one, the attack is performed from a spy process running in the same OS as the victim. In the second one, the attacker runs in a VM and the victim runs in a different VM and they are both allocated in the same host.
Table 1 includes the details of the machine in which the experiments are performed. The steps are equal in the two considered scenarios.
Setup
The tasks required to perform Flush+Reload and Flush+Flush are different from those required for Prime+Probe and Prime+Abort. Since Flush+Something attacks rely on shared memory, an attacker wishing to exploit this feature needs to do some reverse engineering on the library used by the victim to retrieve the target virtual addresses. Note that the offset between the addresses of the beginning of the library and the target symbol (the table) is constant. Thus, once this offset is known, the attacker can easily get the target address by adding this offset to the virtual address where the library is loaded.
In contrast, Prime+Something attacks require the physical address of the target; more accurately, it is necessary to know the set and the slice in which the data will be loaded. This information can be extracted from the physical address. Part of the physical address can be directly inferred from the virtual address. Indeed, the bits of the address that points to the elements within a cache page are part of their physical address. For example, if the size of a cache page is 4 KB, the 12 lowest significant bits of the address will keep the same when translating it from virtual to physical. However, both virtual and physical addresses of the data that the victim is processing are unknown to the attacker. To overcome this difficulty, an attacker needs to create its own eviction set (a group of W elements that map exactly to one set) and profile the whole cache looking for accesses being carried out by the victim.
Instead of recovering the complex address function of our processor, we create the eviction sets dynamically using the technique summarized in the Algorithm 1 of the work of Liu et al. [
41]. We have also enabled
hugepages of 2 MB in our system to work with 21 known bits. Since the number of cores of our processor is a power of two, we only need to obtain the mapping of one of the sets for each slice (the function that determines the slice in which the data will be placed only uses the
tag bits). The remaining sets that will be used during the profiling phase and the attack itself can be constructed using this retrieved mapping.
Measurement collection
The measurement collection process is somehow similar for all the considered techniques. Algorithm 1 summarizes the general method employed to acquire the necessary information about the victim accesses to the tables. This information will be later used to obtain the full key.
| Algorithm 1 Generic attack algorithm for cache attacks against T-Table AES implementations. |
| Input:Address(Te),Address(Te),Address(Te),Address(Te) | ▹ Addresses of the T-Tables |
| Output: | ▹ Information about the accesses and ciphertext |
| 1: for to number_of_encryptions do |
| 2: for to 4 do | ▹ INITIALIZATION |
| 3: Evict from cache (Te); | ▹ The attacker prepares the cache for the attack |
| 4: end for |
| 5: | ▹ WAITING |
| 6: =encrypt(random plaintext); | ▹ The victim performs one encryption |
| 7: for to 4 do |
| 8: Infer victim accesses to((Te) | ▹ RECOVERING |
| 9: if hasAccessed((Te) then | ▹ The attacker Reloads, Flushes, Probes the target or gets the Abort |
| 10: | ▹ The attacker decides if the victim has used the data. |
| 11: else |
| 12: |
| 13: end if |
| 14: end for |
| 15: end for |
| 16: return ; |
In the initialization, the attacker has to evict the data of one line of each Te table from the cache. That is, the attacker ensures he knows the state of the cache before the victim uses it. Since each cache line holds 64 bytes, and each entry of the table has 4 bytes, it holds 16 of the 256 possible values of the table. Then, in the waiting stage, he triggers an encryption. Once it has finished, in the recovering stage, the attacker checks the state of the cache. If the cache state has changed, this means that it is likely that the victim had used the data of that T-Table. The different approaches considered in this work differ in the way they evict the data from the cache during the initialization and in the way they recover the information about utilization of the evicted table line.
In the initialization stage of Flush+Something, the target lines are evicted from the cache using the instruction available in Intel processors. In Prime+Something, the attacker evicts the target lines by accessing the data of the created eviction sets that map to the same region as the target lines. Intel implements a pseudo LRU eviction policy. As a result, accessing W elements that map to a set implies that any older data in the cache will be replaced with the attacker’s data. In Prime+Abort, this operation is performed inside a transactional region defined using the Intel TSX extension.
In the recovering stage of
Flush+Reload, the attacker accesses each of the evicted lines measuring the access times. If the time is below a threshold, it means the line was in the cache, so the algorithm must have accessed it in any of the rounds.
Flush+Flush decides if the data have been used by measuring the time it takes to flush the line again. The flushing time depends on the presence of the line on the cache; it takes longer to flush data that are located in the cache. The
Prime+Probe recovers information on access by accessing the data from the eviction set and measuring the access time. As recommended in previous works [
41], we access the data within the eviction set in reverse order in the Probe step. That is, the eviction set is read following a zigzag pattern. If the data of the table are used by the encryption process, part of the attacker’s data will be evicted; thus, the time it takes to “Probe” the set will be higher. In the
Prime+Abort, as the eviction set was accessed inside a transaction, any eviction of the attacker’s data from the cache causes an abort. The attacker defines a handler for this abort that evaluates its cause. There are different abort causes which are identified with an abort code [
48]. This abort code is loaded into the
register and it is read in the handler function to check if the abort was due to an eviction.
Figure 2 shows the distribution of the measured times during the Reload step (
Figure 2a) and during the Probe step (
Figure 2b). Note that it is easy to establish a threshold to distinguish between accesses and not-accesses to the monitored Te table.
Information Processing
This final step is common for all the attacks. In this stage, our approach differs from previous attack strategies. Traditional approaches for the considered attacks take into account if the data stored in the monitored cache line has been used by the victim. In contrast, we consider the opposite situation, i.e., the victim has not used that data. Our approach is based on the following observations:
- −
Whenever the retrieved information shows that the victim has used the considered data, they could have been used during the last round or during any of the remaining ones. Thus, whenever the data are used in a different round, this approach introduces “noise”. On the other hand, if a monitored cache line has not been accessed during the encryption, neither has it been accessed in the last round nor in any other round.
- −
Speculative execution of pieces of code, or prefetching of the data that the processor believes are going to be used in the near future, may involve that the attacker sees in the cache data that have not been used by the victim (false positive). Nonetheless, to obtain a false positive in the non-access approach, the data have to be used during the last round of the encryption and then flushed away by other process during the short period of time after the end of the encryption and before the recovering step.
- −
Each non-access sample reduces the key search space discarding up to key values (n equals to 16 table entries stored in the cache line, which are used to obtain 4 output bytes). Thus, we obtain information from each of the samples. In contrast, when considering accesses, only when one candidate value towers over the rest, the retrieved information is useful to retrieve the secret key.
- −
The information obtained this way is more likely to be applicable to all the rounds of an encryption, or at least to the penultimate round, as it refers to the whole encryption, so we can use this information to retrieve longer keys (192 or 256 bits).
We have seen in
Section 3.2 that each table
Te is accessed four times during each round. Therefore, the probability of not accessing a concrete cache line within an encryption is provided by Equation (
1), where
n represents the number of table entries a cache line can hold, and
the number of rounds of the algorithm. Particularly, in our case, where the size of a cache line is 64 bytes,
n is 16 (each entry of
Te has 32-bits) and the number of rounds (
) for AES-128 is 10. Consequently, the probability of not accessing the cache line is
. This means that one of each fourteen encryptions performed gives us useful information.
As stated before, we focus on the last round of the encryption process. This round includes
SubBytes,
ShiftRows and
AddRoundKey operations. Referred to the last round input state and the
T-tables, we can express an output element by
Te. When a cache line has not been used during the encryption, we can discard all the key values which, given an output byte, would have had to access any of the Te-table entries hold in the mentioned cache line. For example, given a ciphertext byte “0F” and a cache line holding “01”, “AF”, “B4”, and “29”, if this line remains unused after performing the encryption, we discard the key byte values 0F⊕01, 0F⊕AF, 0F⊕B4 and 0F⊕29. As shown in
Section 3.2, the same table is used to obtain all the elements of the row of the output state. This means each
Te table also discards the
values with the same
i value independently of the
j index.
A general description of the key recovery algorithm for the last round key is provided in Algorithm 2. Key bytes of the last round,
, are recovered from the output state
(ciphertext) and the information about the accesses to each table
Te, which is stored in
and recovered using Algorithm 1. The output state (
) is obtained by arranging the known ciphertext vector as a matrix, as indicated in
Section 3.1. The algorithm first initializes an array of 256 elements for each of the 16 bytes of the key (
). This array (CK
) will contain the discarding votes for each key byte candidate. The candidate with less negative votes is the value of the secret key.
| Algorithm 2 Recovery algorithm for key byte . |
| Input: | ▹ Information about the accesses and ciphertext collected in the previous step. |
| Output:K | ▹ Secret key values |
| 1: for to 256 do |
| 2: CK; | ▹ Initialization of the candidates array |
| 3: end for |
| 4: for to number_of_encryptions do |
| 5: if then |
| 6: for to n do | ▹ n stands for the number of entries that a cache line holds |
| 7: CK; | ▹ Vote for discard key candidate |
| 8: end for |
| 9: end if |
| 10: end for |
| 11: return argmin(CK); | ▹ The candidate with the fewest votes for discard is the secret key. |
Figure 3 shows the values of one of the 16 CK
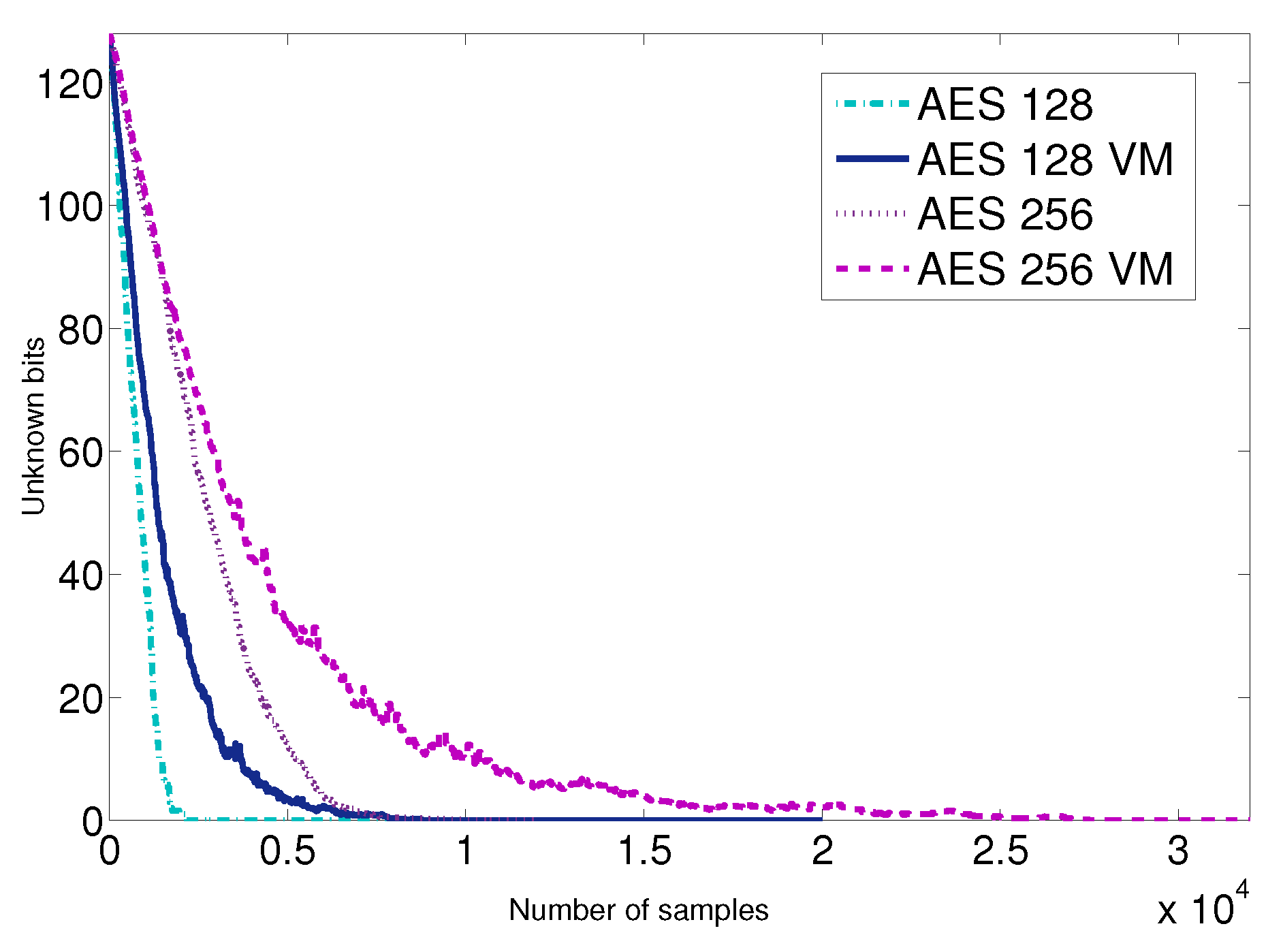
array, which contains the discarding votes each possible key value has received during the attack for a concrete byte of the key. The x-axis represents each possible key value, and the y-axis the number of times each option has been discarded. The minimum is well distinguishable from the rest of possible key values and is highlighted in red. The index with the minimum score represents the secret key. This approach allows recovering the 128 bits of the key with fewer than 3000 encryptions on average in the best case. We present further results and provide further details in
Section 4.
3.3.2. Attack on AES-256
The attack against AES-256 comes as an extension of the previously explained attack on the last round of an encryption. There are no further assumptions than in the previous case. The setup and measurement collection steps are exactly the same for both attacks, and only the information processing phase is different since it includes an extra step. We retrieve 128 bits of the key using Algorithm 2 and use the guessed 128 bits of the key and the same information that has already been used (non-accesses and ciphertext) to derive the remaining 128 unknown bits of the key. We similarly use information about the non-used cache lines to discard key values until we obtain the key. This is possible because this information refers to the whole encryption and, as previously stated, if a cache line has not been accessed within an encryption, it has not been accessed in any of its rounds.
Note that the probability of non-accessing one line when performing an AES-256 encryption, which is a function of the number of rounds, and is given by Equation (
1), is 2.69% (14 rounds). Consequently, the attack on AES-256 would require more samples to successfully guess the whole key. In this case, about 1 out of 37 samples carries useful information. This means we need to collect at least the same number of useful samples than in the previous case.
The key to understand the attack is to understand the equivalence between encryption and decryption. Using the decryption algorithm, we transform the data referring to the encryption process in a way that it is possible to easily derive the round key discarding its possible values. For this reason, we call this approach encryption-by-decryption attack (EBD).
If we analyze the AES encryption process, we see that the output of each round is used as an index to access the T-tables in the next round after a ShiftRows operation. Taking into account the valuable information of the unused cache lines, it is possible to figure out which are the state values that are not possible before the penultimate round, . That is, if a cache line has not been accessed, all the state values that would have forced an access to this line can be discarded.
Once we know the last round key, it is straightforward to obtain the input to that round () only taking into the account the encryption function. However, because of the MixColumns operation which is performed in all the previous rounds (except for the initial one), the certainty about the non-usage of a cache line of one table and the knowledge of the encryption function are not enough to obtain information about the key of these rounds. However, if we use the decryption function and take into the account the equivalence between encryption and decryption, we can transform our data so we can derive information about a state of the decryption function, which is equivalent to the state in the encryption function.
Figure 4 shows with dotted lines the instants where equivalent decryption and encryption algorithms have the same values. According to the figure, we establish a bidirectional relation between an encryption state
and a decryption state
using
SubBytes and
ShiftRows steps. The relations are defined in Equations (
2a) and (
2b). These relations and the knowledge of the values which are not possible in the state
give us the values which are not possible in the state
. Since the value of what we call intermediate value
IV can be easily obtained from the decryption function, our scenario is similar to the previous one (
).
Algorithm 3 shows how to obtain the correct candidates for the round key of decryption algorithm Round 1 (the second round). The key of the first decryption round is exactly the same as the key used in the last round of the encryption, previously obtained using the non-access cache attack and targeting the last round (Algorithm 2). As we know both input data (ciphertext) and round key, we can perform the first round of the decryption algorithm and obtain the state of round 1, D
. Applying the
Td-tables on the state, we calculate an intermediate value of Round 1,
IV. At this point, if we perform the
AddRoundKey, the next step of the decryption algorithm, the result would be
, which can be transformed into the encryption
state, as explained using Equation (
2b).
In the T-table implementation, the state (including
or
for AES256) is used as index to access the
Te tables. Note that not accessing a cache line holding one entry of the table also indicates which indexes of the table are not being used, which is similar to indicating which values of the state can be discarded. Then, we apply Equation (
2a) to transform the discarded values for state
to discarded values for state
. After this transformation, we have information on both sides of the
AddRoundKey in round 1 of the decryption sequence. We can vote to discard possible values of the decryption round key. We vote to those values, which, once the decryption state is transformed into the encryption state, would lead to a memory access on the unused lines.
The least voted value for each byte is the decryption round key. Both the encryption and decryption keys are related and one can be obtained from the other applying the InvMixColumns operation, or an equivalent operation depending on the direction of the conversion. As a result of this information processing, we know two consecutive round keys; that is, the full AES-256 key. This algorithm could be applied recursively for the whole encryption/decryption process, as the cache information is applicable to the whole encryption.
Using this encryption-by-decryption cache attack on AES-256, we obtain the key with fewer than 10,000 samples in the best scenario. We provide further details in
Section 4.
| Algorithm 3 Recovery algorithm for key byte Kd. |
| Input: and K | ▹ Information about the accesses, ciphertext and last round key. |
| Output:Kd | ▹ Secret decryption key values |
| 1: Kd = K |
| 2: for to 256 do |
| 3: CKd; | ▹ Initialization of the candidates array |
| 4: end for |
| 5: for to number_of_encryptions do |
| 6: if then |
| 7: D = ; |
| 8: DD Kd; |
| 9: for to 4 do |
| 10: IV=Td Td Td Td | ▹ Obtain intermediate value |
| 11: end for |
| 12: for to n do | ▹ n stands for the number of entries that a cache line holds |
| 13: CKd | ▹ Vote for discard key candidate |
| 14: end for |
| 15: end if |
| 16: end for |
| 17: return argmin(CKd); | ▹ The candidate with the fewest votes for discard is the secret key. |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}