1. Introduction
The Industry 4.0 concept opens opportunities to digitize industrial machines, processes, and assets; providing new insights and efficiently countering various current challenges [
1]. Radio frequency identification (RFID) is a key Industry 4.0 enabling technology, and has been widely used throughout manufacturing and supply chains. RFID transfers data between readers and movable tagged objects and has been applied to many diverse areas, including tracking and managing assets in healthcare [
2,
3,
4], reducing misplaced inventory throughout supply chains [
5], measuring soil erosion [
6], and improving just-in-time operation for automotive logistics [
7]. The technology has also provided significant advantages for bee monitoring [
8], tracking ship pipes [
9], customer purchase behavior analysis [
10], inventory management [
11], indoor robot patrol [
12], etc.
For warehouse management systems (WMSs), RFID can monitor tagged products moving through a gate and subsequently loaded for delivery to other supply chain partners. However, RFID cannot distinguish tagged products that move through the gate or those that enter the reading range accidentally. Tags within reader range but not moved through the gate are called false positive, whereas tagged products moved through the gate and loaded are called true positive readings. These accidental reads occur when the range of the antenna might be extended by metallic objects. Consequently, tags assumed to be clearly out of range can be unexpectedly read by the reader. In addition, false positives can also be due to the tags that are located within the nominal read range but are read accidentally. Since WMSs should correctly calculate the total amount of tagged products loaded, detecting and filtering false positives is critical to ensure the correct delivered product records are retained.
Received signal strength (RSS) is the relative quality of a received signal for a device, which is related to the distance between the tags and antenna for RFID, and has been previously utilized for indoor localization systems (ILSs) [
13,
14,
15,
16], indoor mapping and navigation in retail stores [
17], indoor tracking system for elderly [
18], and gesture recognition [
19]. Previous studies confirm RSS approaches to be suitable to detect false positives [
20,
21,
22], where static and moved tags were classified as false positive and true positive readings, respectively. Machine learning models have also been utilized to successfully detect false positives using RSS based features as inputs. However, some retail store-based studies showed that tag movement close to the gate and through the gate were classified as false positive and true positive readings, respectively [
23,
24]. Therefore, false positive classification must consider other tag movement types, such as tag movement close to the gate, as well as static tags for WMSs.
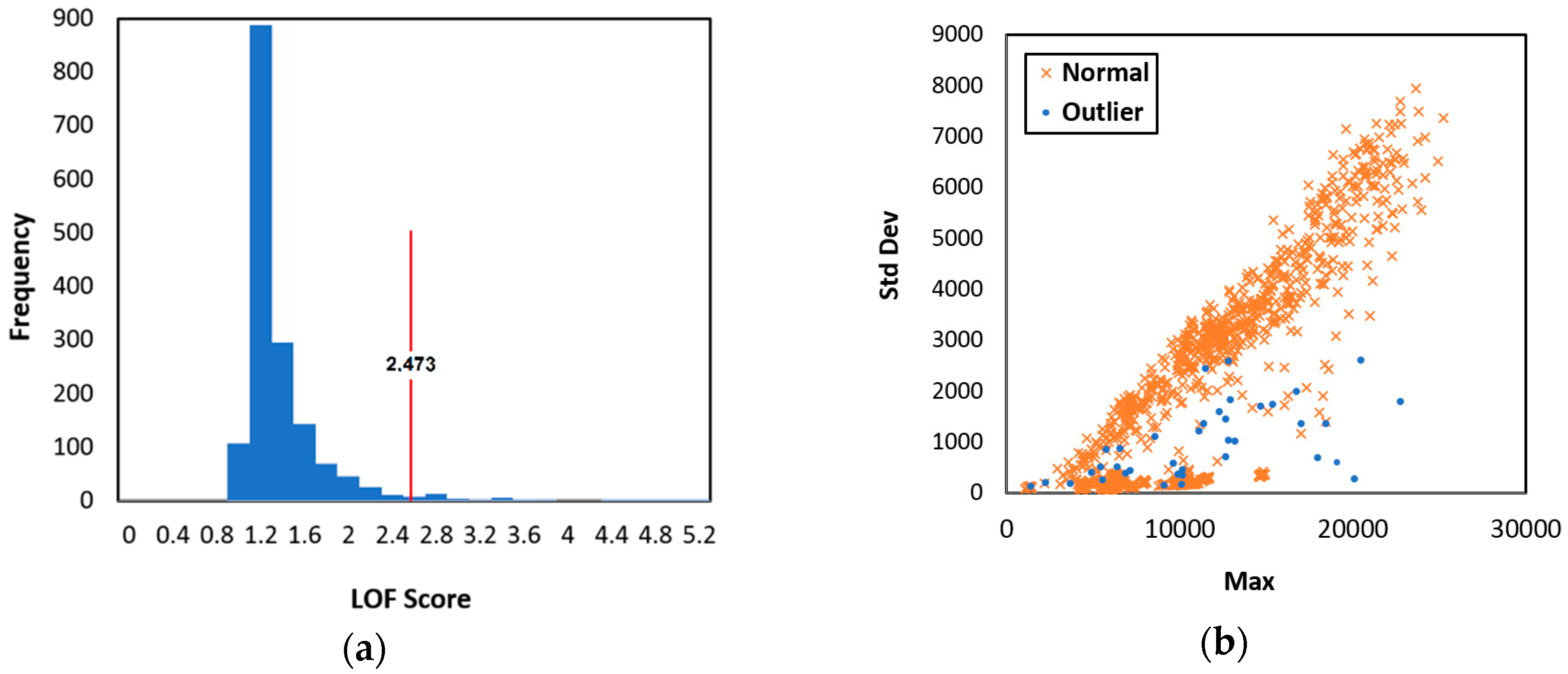
Collected data commonly includes outliers, due to environmental interference and imperfect sensing, and various outlier detection methods have been proposed to detect and remove them. The local outlier factor (LOF) has been applied for several application areas to detect outliers in data streams [
25], fault detection in medical [
26] and process monitoring [
27,
28], and activity recognition [
29]. Interquartile range (IQR) has shown significant outlier detection capability for residential building energy usage [
30], groundwater data [
31], and health care insurance fraud [
32]. LOF and IQR have both been implemented to predict electricity consumption, providing good performance detecting true outliers [
33]. Thus, outlier detection helps improve classification model performance.
The present study investigated machine learning model performance to detect false positives based on tag RSS. To represent complex warehouse situation, we considered false positives for not only static but moving tags close to the gate. Incorporating outlier detection models within the machine learning algorithms significantly improved false positive prediction performance. We also demonstrated that the proposed classification model could be integrated into real-time monitoring systems (RTMSs), ensuring false positives were filtered and hence not stored in the database.
The remainder of this paper is organized as follows.
Section 2 discusses related works on false positive detection, machine learning, and outlier detection models.
Section 3 presents the collected dataset and feature selection, and
Section 4 presents the proposed classification and outlier detection models.
Section 5 provides and discusses the results and
Section 6 summarizes and concludes the paper.
3. Dataset and Feature Extraction
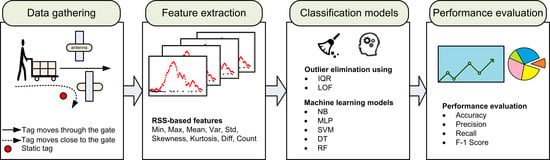
Figure 1 shows the structure employed to detect false positives using machine learning models. Data was collected for different tag movements and tag RSSs was recorded. Statistical features were then extracted for each tag, and outlier detection applied. After cleaning the data (i.e., removing the identified outliers), several machine learning algorithms were applied and compared.
Several pallet movement scenarios were identified to investigate false positives.
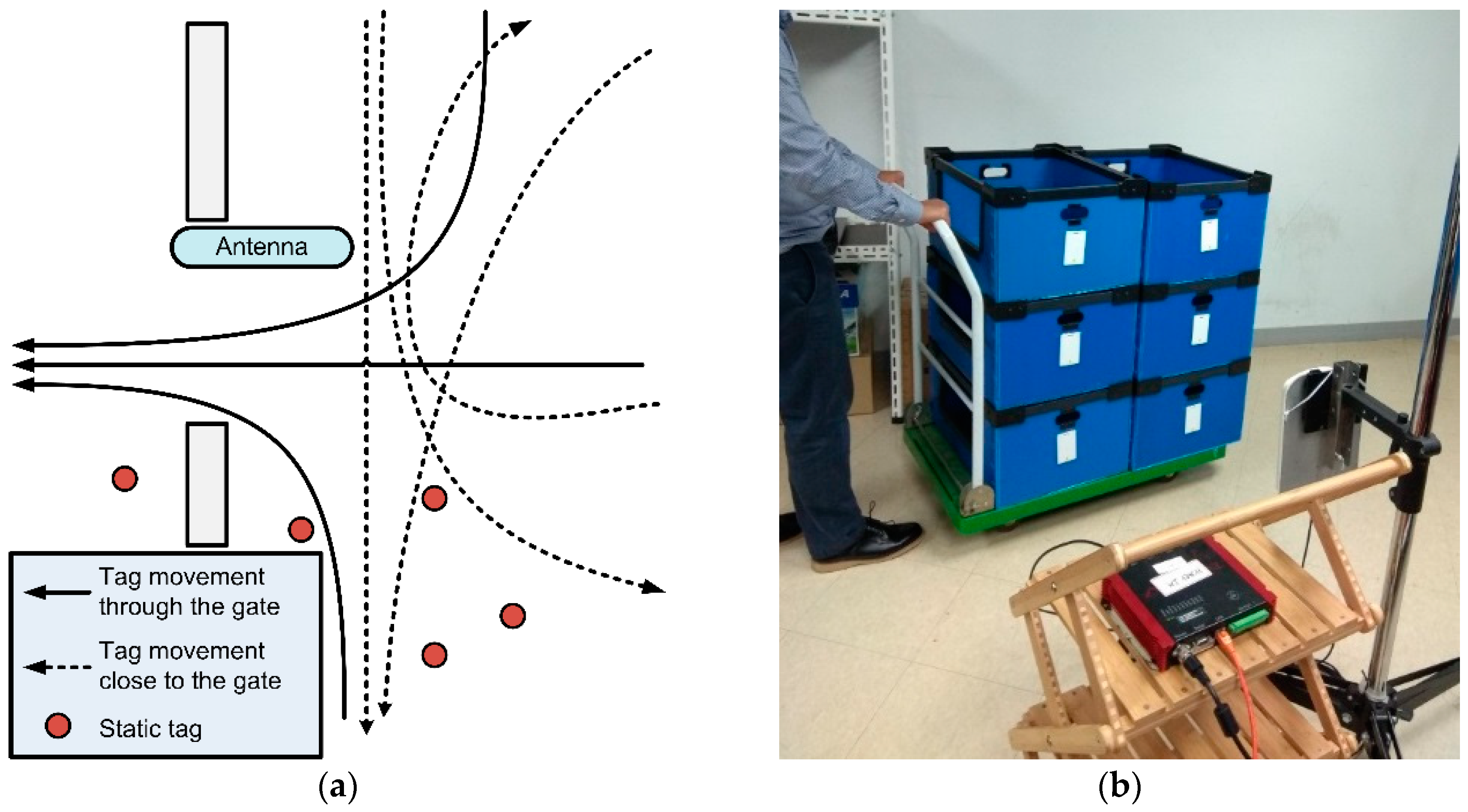
Figure 2a shows static and movement RFID tag examples that feasibly occur in actual warehouses. The RFID reader and antenna were installed in the warehouse exit gate before products were loaded in the vehicle. The main system purpose is to accurately record only those tags moved through the gate and subsequently loaded in the vehicle. However, the RFID reader could potentially read moved or static tags, where the moved tags could pass through the gate or close to the gate.
This study considered true positive and false positive RFID readings. True positive readings were defined as the tags read when the pallets were moved through the gate and loaded onto the vehicle; whereas false positives were where pallets were moved close to the gate and the tags were read, but were not loaded onto the vehicle, or pallets were stationary within the reading range of the RFID reader. These accidental reads occur when the tags are located within the nominal read range or the range can be extended accidentally by metal objects within the field [
21]. The purpose of the proposed classification model was to identify false positive tags based on extracted RSS information.
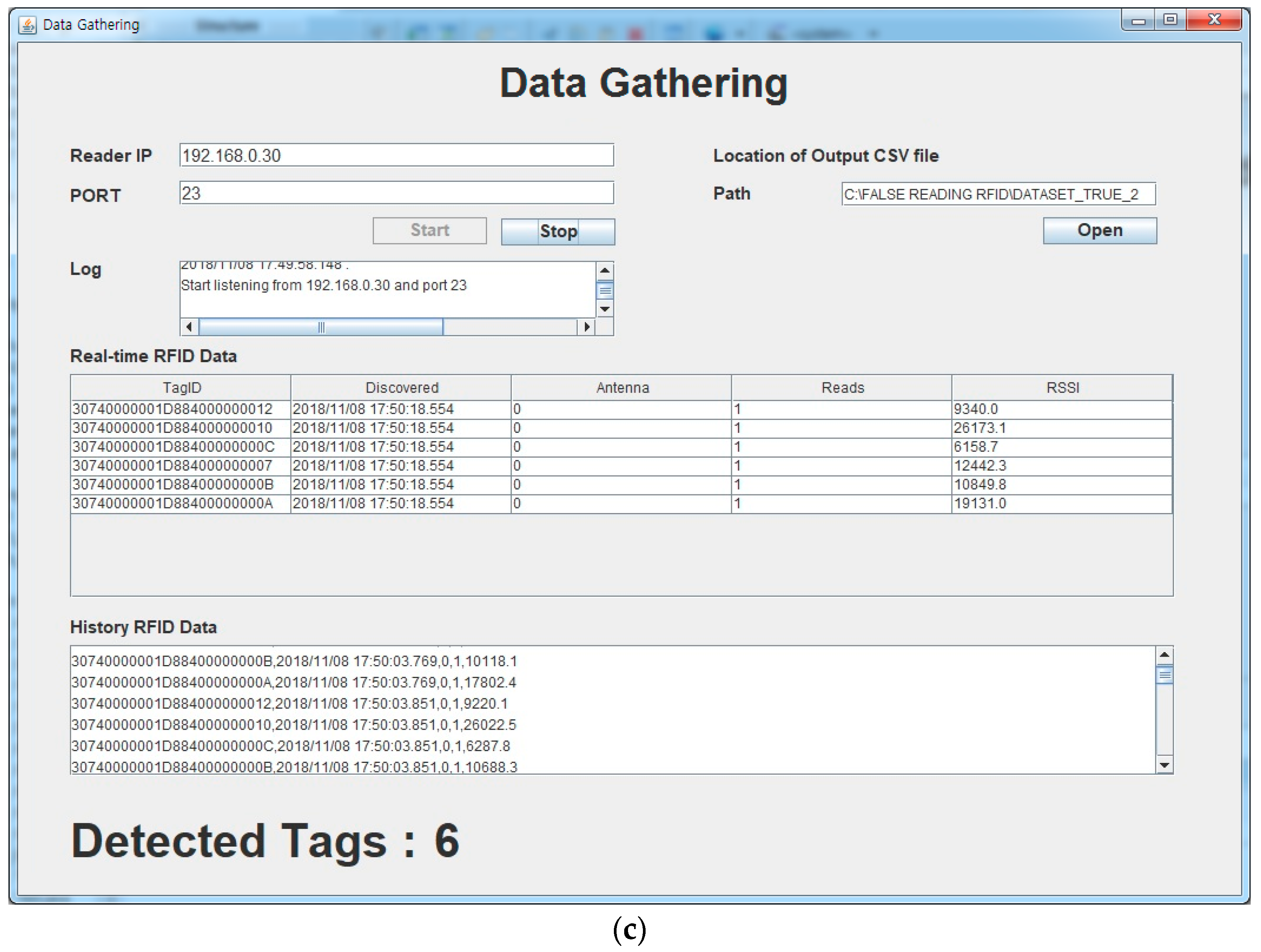
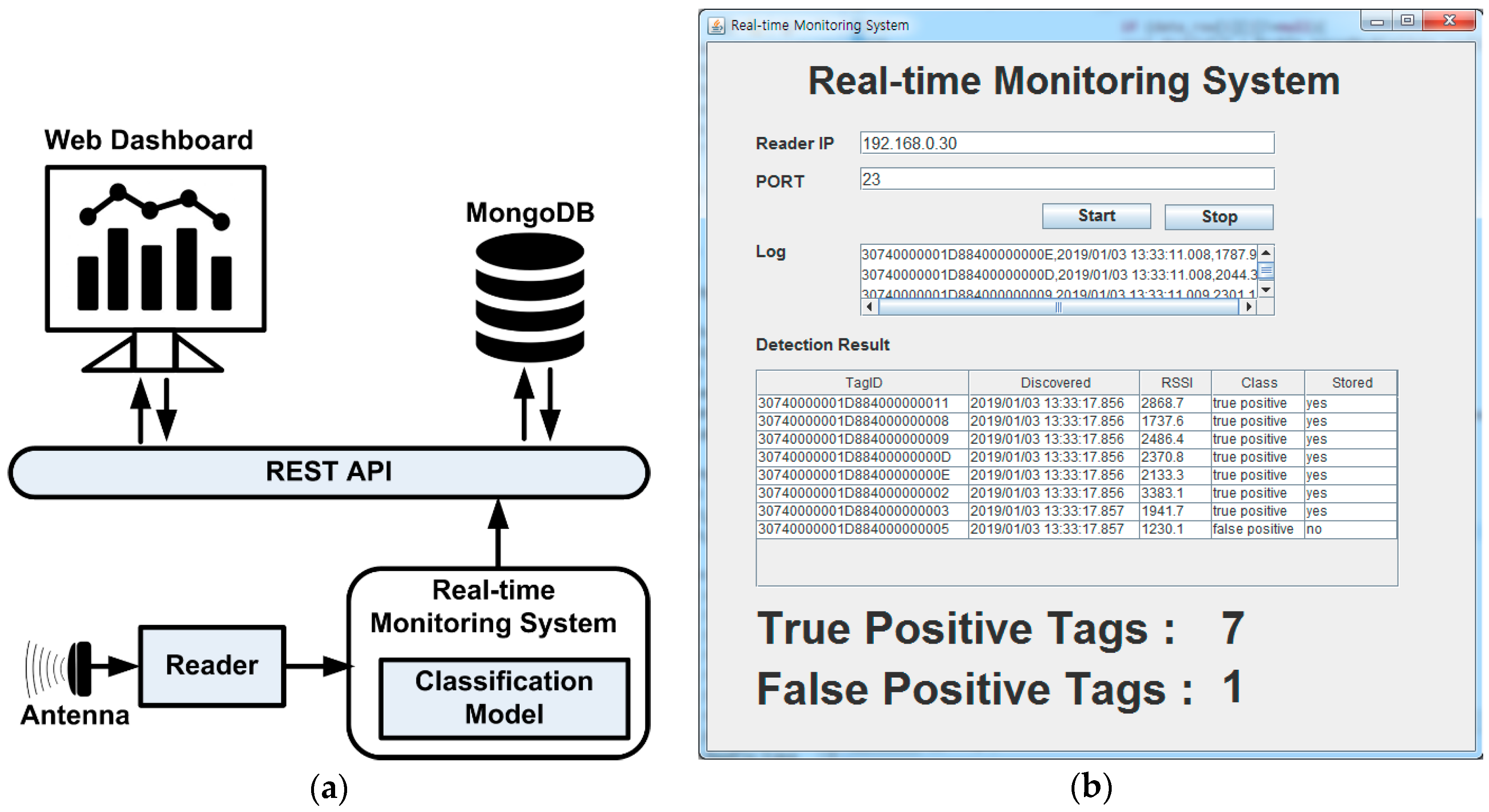
Figure 2b shows a typical case where tagged products are moved through the gate. The tags read by the RFID reader through the antenna, and the tag data is forwarded to the client computer through wired connection. We developed the data gathering program to receive and present tag information as well as RSS data in real-time, as shown in
Figure 2c. It took approximately 5 s to move the trolley through the gate, and the real-time tags and corresponding RSS details were presented on the screen (
Figure 2c) and recorded during this gathering session.
We used 86 × 54 × 1.8 mm card type passive RFID tags for this trial, with the tags attached to the boxes and the trolley moved through the gate at different paths and speeds. The ultra high frequency (UHF) passive RFID tag model was 9662 with frequency 860–960 MHz. The IC type was Alien H3 while protocol was EPC Class1 Gen2 (ISO 18000-6C). The tag was packed with PVC material into a card-type passive tag. In addition, single reader ALR-9900+ from Alien Technology and linear antenna ALR-9610-AL with 5.90 dbi Gain were utilized in this experiment. The operating frequency of the reader was 902–928 MHz and supported EPC Class1 Gen2 (18000-6C). The ALR-9900+ is an enterprise reader, allowing users to monitor or read multiple tags as well as gather RSS data simultaneously at large distances. The Alien reader provides inventory command, a full-featured system for discerning the IDs of multiple tags in the field at the same time. In order to achieve good inventory performance, the reader can dynamically adjust the Q parameter to cause more or fewer tags to respond at any given time. The reader provides several modulation modes available with the Gen2 protocol, such as FM0, M4 (Miller 4), and the default RF mode value is 25M4 [
46,
47]. To simplify the experiment process, we used default parameters provided by the reader. The reader provided a standard development kit incorporating several languages (Java, Net, Ruby), which allowed relatively simple integration into the developed data gathering program.
During the gathering session, different tags movement paths and speeds through the gate were implemented and performed, and the reading data labelled as true positive. Various other tag movements close to the gate were also conducted and labelled as false positive, and random static tags were placed within the configured read range and also labelled as false positive. In total, 1624 unique data readings were collected, with 1130 false positives and the remainder true positive. Each reading consisted of tag id, date and time, and RSS value. The minimum, maximum, and average number of tags read during a data gathering session where 17, 240, and 69.23, respectively.
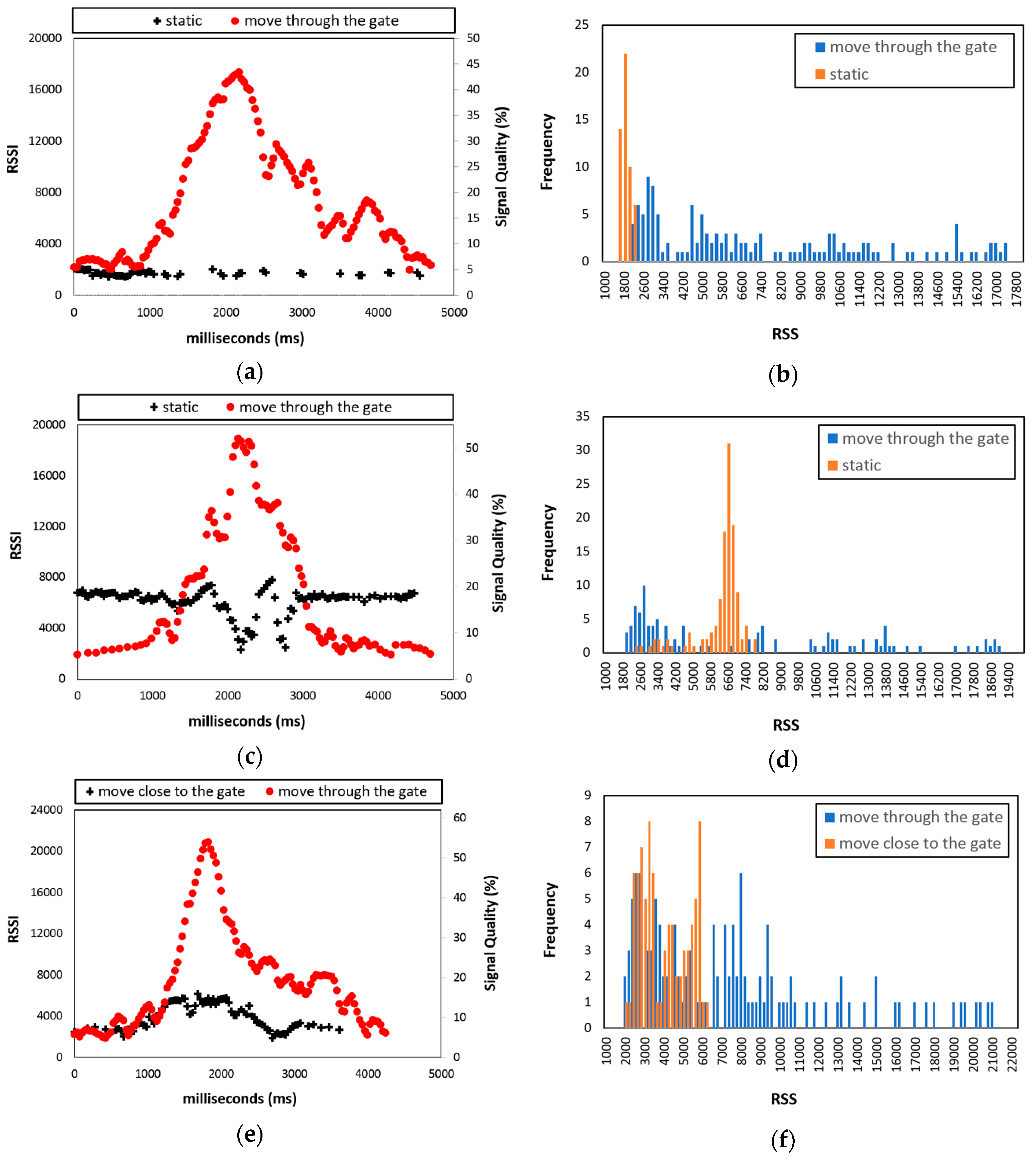
Figure 3 shows RSS readings for a typical data gathering session. The ALR-9900+ reader does not provide the unit of measure for the RSSI; therefore, we have presented signal quality (%) as secondary y-axis. First, we investigated the minimum as well as maximum values of RSSI during our experiment, they were 432 and 37,131, respectively. Based on this information, the real value of RSSI was then converted into signal quality (%). The maximum RSS for tags moved through the gate was larger than for static tags (
Figure 3a). RSS increased when tags passed through the gate, achieving maximum when the tags were closest to the antenna. In contrast, static tags had relatively constant RSS, since the distance between the antenna and static tag was fixed. This particular case shows a static tag located relatively distant from the reader, hence RSS was low.
Figure 3b shows RSS histograms for typical static tags and those moved through the gate. Static tags tended to have small variance, whereas tags moved through the gate tag tended to exhibit heavy-tailed distribution.
Figure 3c shows the case for a static tag located a relatively close distance to the RFID reader. The static tag generated a non-constant RSS, being relatively stable but reducing when other products being moved through the gate blocked the antenna signal (the worker as well as the boxes). Once the worker and boxes complete passing the gate, the static tag RSS became stable again. Consequently, closer static tags tended to generate histograms with higher variance and maximum RSS values compared to more distant tags (
Figure 3b), as shown in
Figure 3d. However, closer static tags still tended to have lower variance and light-tailed distributions compared with tags moved through the gate.
Figure 3e shows a typical RSS distribution for a tag moved close to the gate, which is quite similar to that for tags moved through the gate. For both tags, RSS increased as they moved closer to the antenna, then decreased as the distance increased. However, maximum RSS for tags moved close to the gate was lower than for tags moved through the gate, since the antenna did not directly face the tags moved close to the gate.
Figure 3f compares typical histograms for tags moved close to and through the gate. Although the histograms are similar, tags moved through the gate tag exhibited higher variance and more heavy-tailed distributions compared to tags moved close to the gate.
Since RSS depends on the distance between the antenna and tag, closer tags generated larger RSS. Therefore, RSS attributes provide important data to classify RFID readings, and have been utilized in previous studies to identify RFID readings with high performance accuracy [
20,
21,
22].
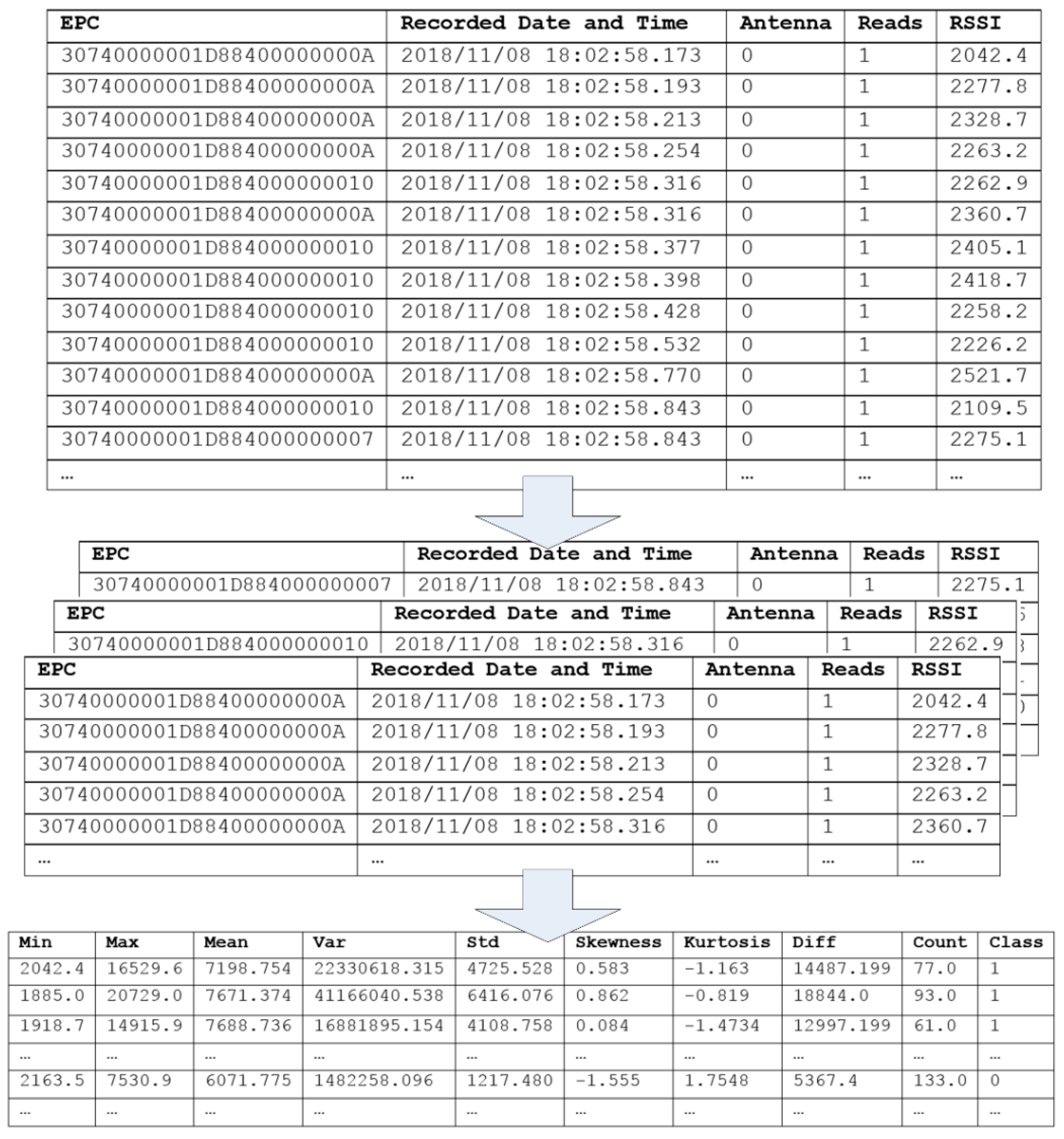
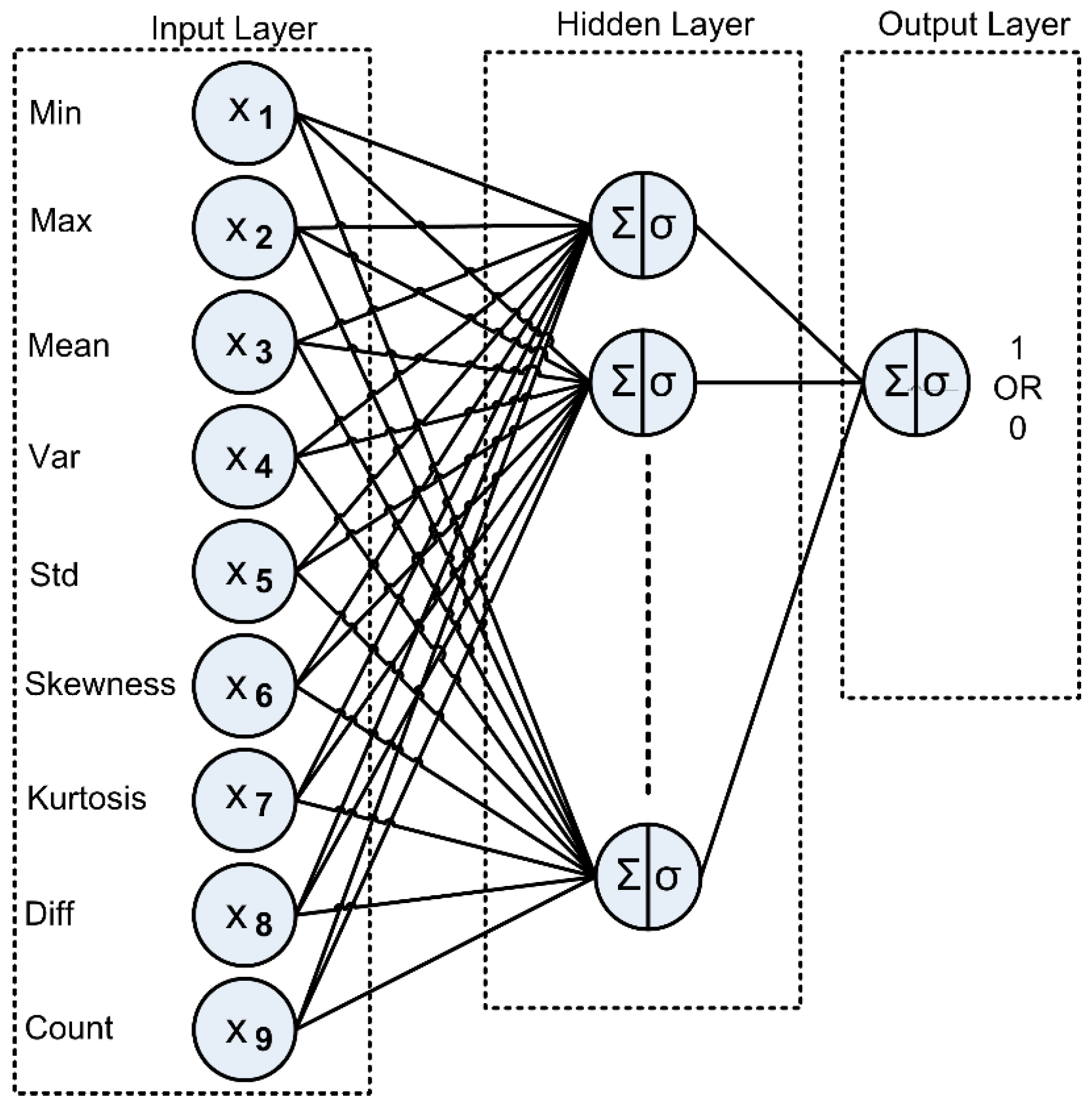
Table 1 shows the nine relevant statistical features extracted from RSS to help distinguish between true and false positives.
During data gathering, the worker loaded several boxes with attached tags on the trolley and performed different RFID readings (i.e., true and false positives) (
Figure 2b). To generate a complex dataset, the worker followed different speeds and paths. The data gathering program (
Figure 2c), received RSS for each tag through the gathering session, and the raw data was stored as a CSV file. For true positive readings, the worker performed multiple gathering sessions, moving the tags through the gate, and RSS values for static tags located within read range were also collected to generate false positives. Different movement paths and speeds were also performed for tags moved close to the gate.
Table 2 showed the detail execution parameters for gathering the true positive readings (tag movements through the gate), such as number of boxes/tags and the speed and movement pattern of trolley. During gathering session, different numbers of boxes were loaded on the trolley and different numbers of movements through the gate were conducted. In addition, different speeds and paths of the trolleys moving through the gate were considered for data gathering. Based on
Table 2, most of the experiments were performed with four tagged boxes on the trolley, with the speed between 0.5–0.99 m/s, and moves straight ahead. In our experiment, the distance between start point (when the tag is first read) and end point (last occurrence of tag) was approximately 4 m.
Figure 4 shows that the raw RFID data, recorded for each gathering session, consisted of the electronic product code (i.e., the tag ID), date and time, antenna information, read time, and RSS. Each raw RFID dataset was then divided based on the tag ID, statistical features to represent data characteristics, and class attributes, labelled as either true positive (1) or false positive (0).
Table 3 compares classification accuracy for individual features based on decision stumps (decision trees with single input features). Although each feature can identify true and false positives, none of the features achieved accuracy >90% individually. Thus, a single predictor could not achieve a satisfactory result. However, we expect that combining multiple predictors using machine learning models would significantly improve the prediction performance.
6. Conclusions and Future Work
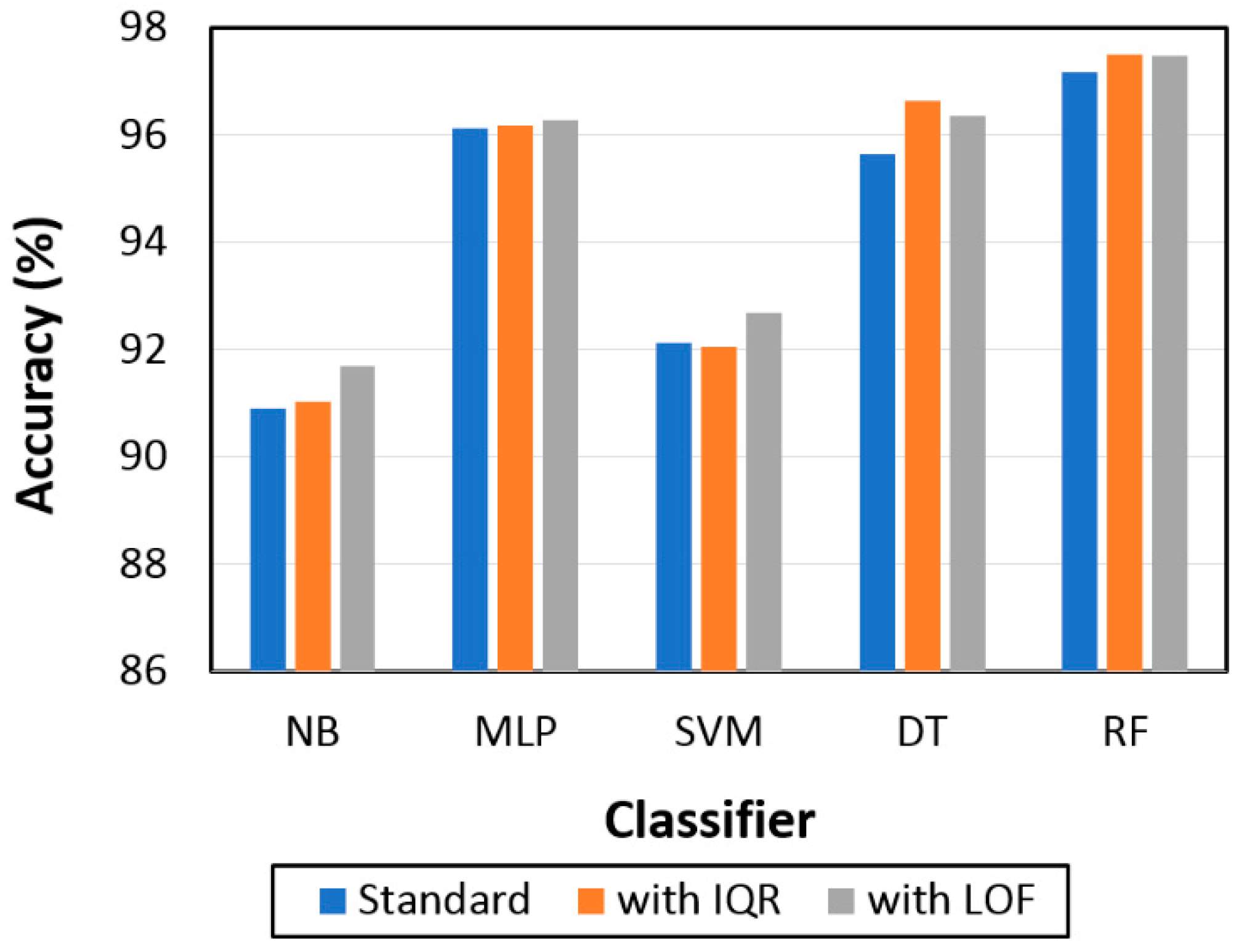
Detecting and filtering false positives will improve WMS monitoring accuracy for product delivery to supply chain partners. This study used machine learning to predict false positives based on tag RSS. Different tag movement paths and speeds were considered, and statistical features were extracted from tag RSSs. Outlier detection methods were implemented to filter outliers from the collected dataset, and machine learning models were applied to detect static tags and movement close to the gate as false positives. Experimental results showed that integrating outlier detection with machine learning improved classification accuracy. The most accurate classification (97.5%) was achieved by combining LOF or IQR with RF, and was significantly superior to the other combinations and models considered.
We demonstrated the proposed classification model integrated into a prototype real-time monitoring system, comprising a client program to receive tag information from the reader and a REST API to store the information in the cloud. The client program also filtered false positives to ensure only correct product details (i.e., true positive tag readings), and were forwarded to the REST API and stored in the database. Thus, managers could monitor products delivered to supply chain partners in real-time using the prototype web-based monitoring system.
Future study should consider different parameters as addition to RSSI, such as phase and doppler, as well as utilizing multiple readers or antennas. The datasets that better represent complex real situations, such as by considering different tag orientations and tag movement directions, need to be gathered in the near future. Furthermore, extending the comparison with other classification models, as well as applying machine learning models to identify other problems that occur during RFID readings, such as false negative readings or miss-reads, could be presented in the near future.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}