An Accurate and Robust Method for Spike Sorting Based on Convolutional Neural Networks



Abstract
:1. Introduction
2. Materials and Methods
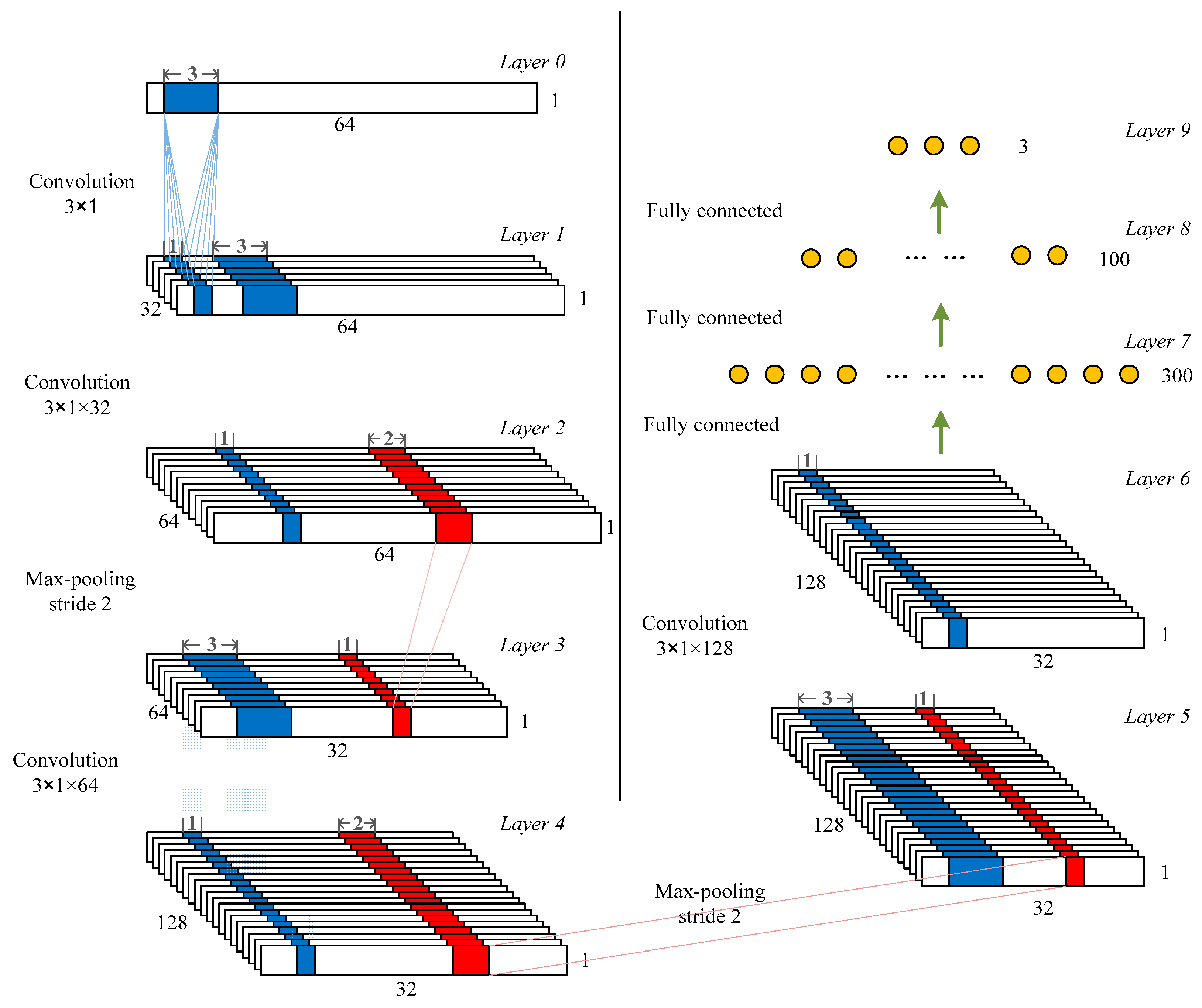
2.1. Architecture of the 1D-CNN Model
2.2. Simulated Database and Experimental Datasets
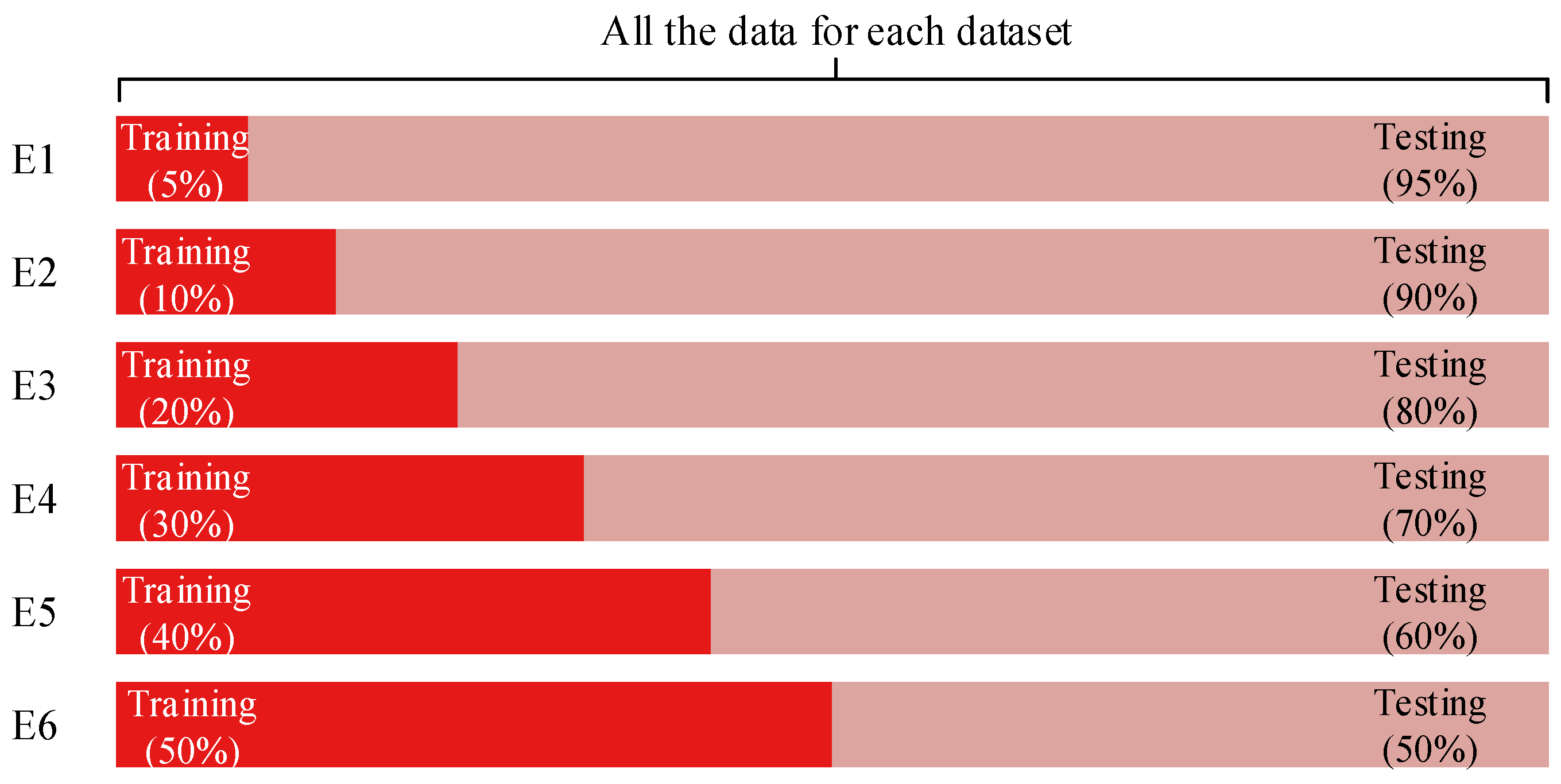
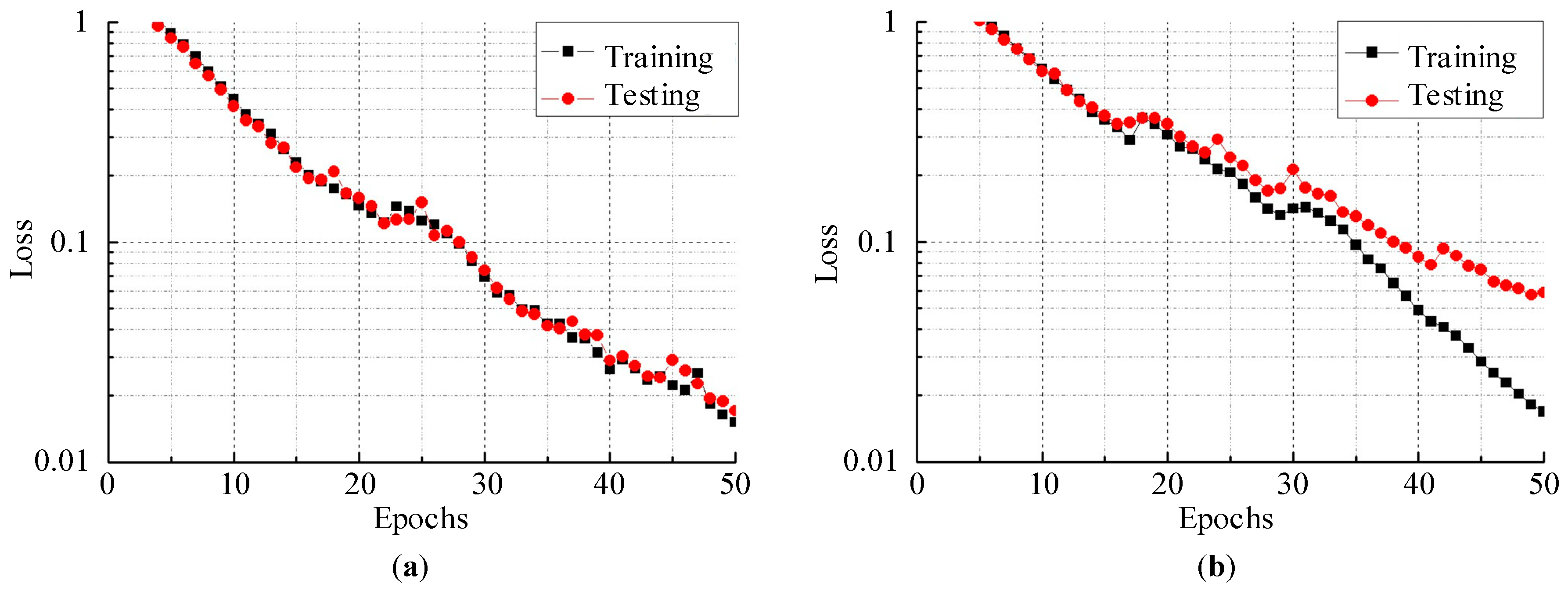
2.3. Training and Testing
3. Results
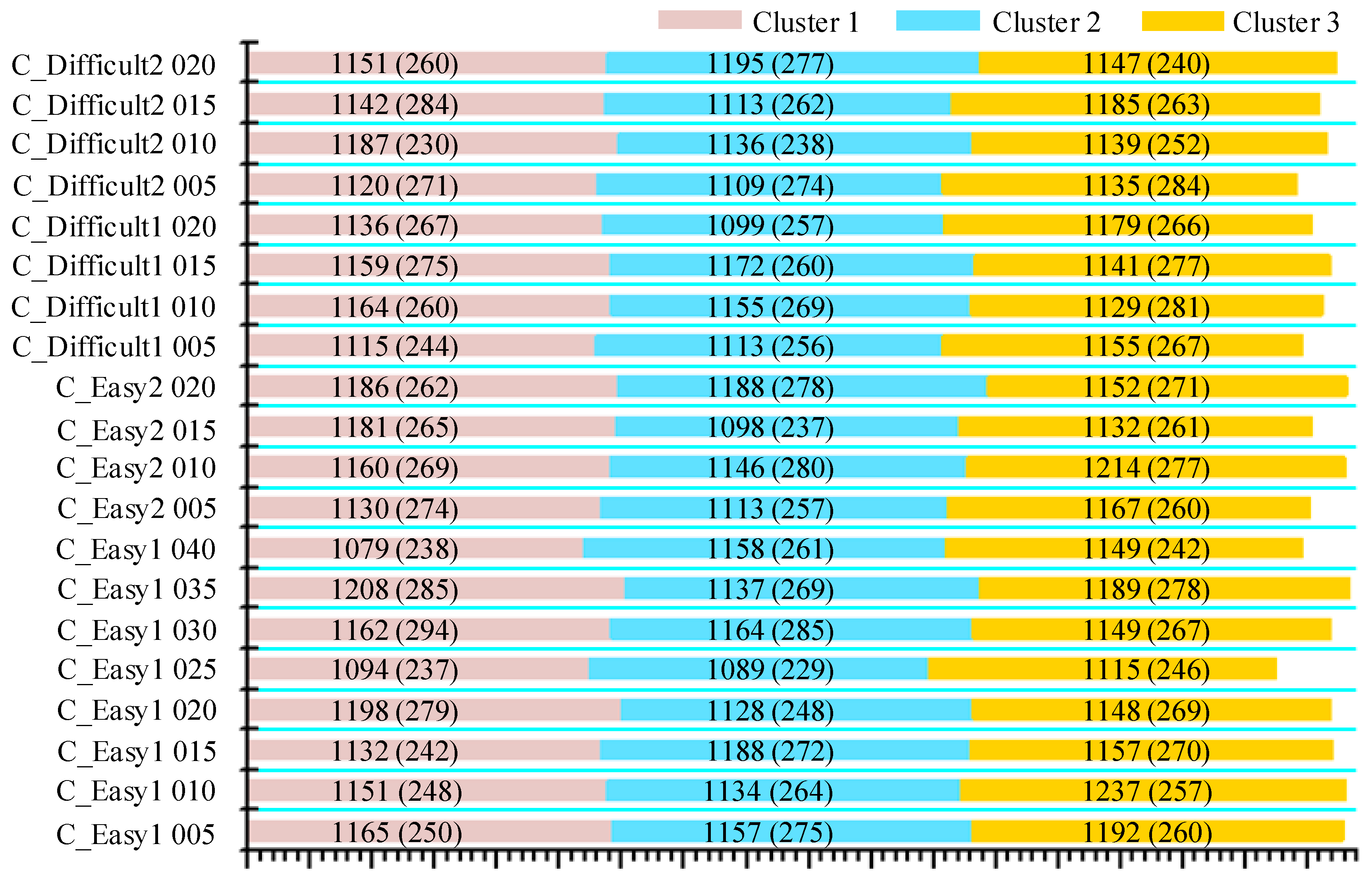
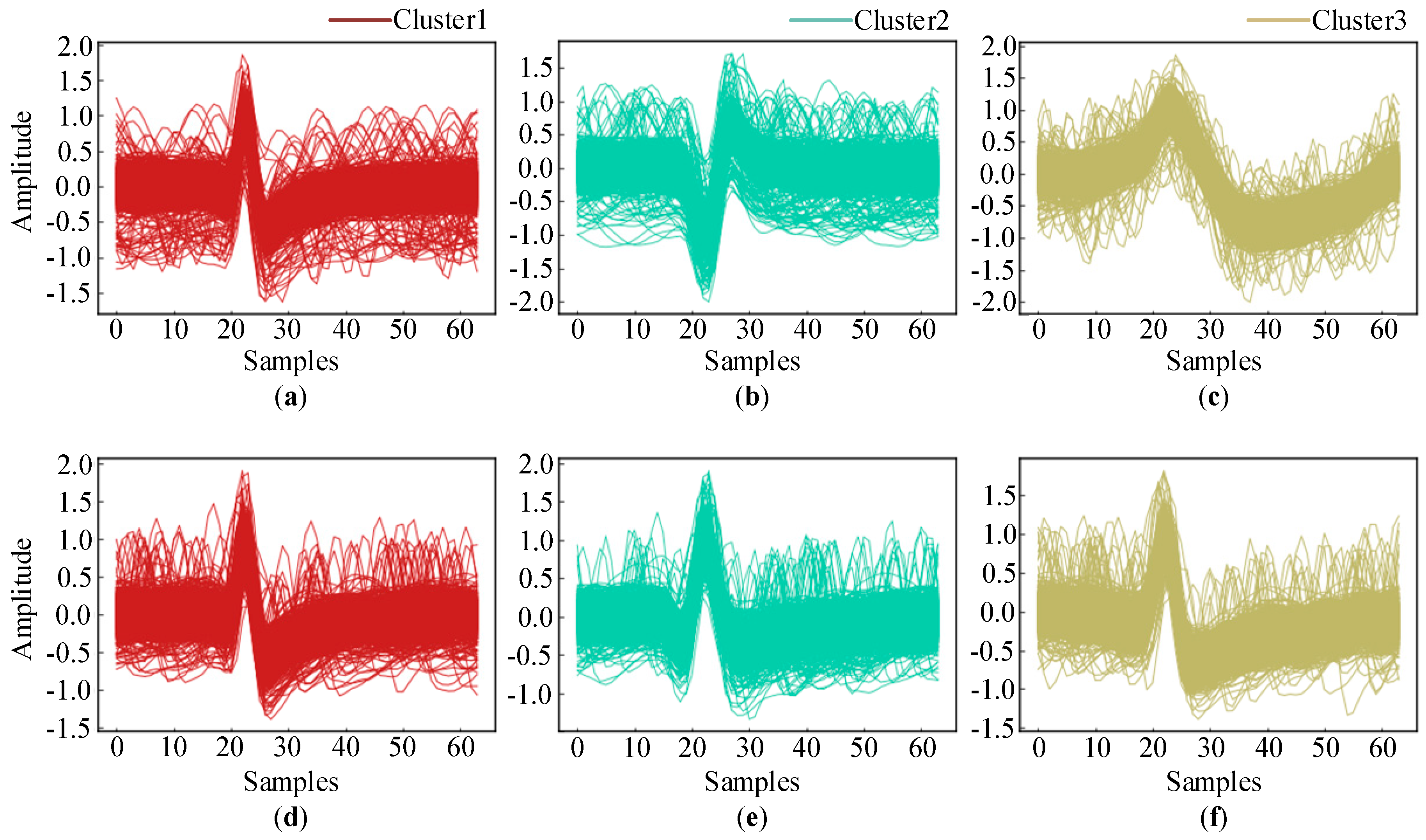
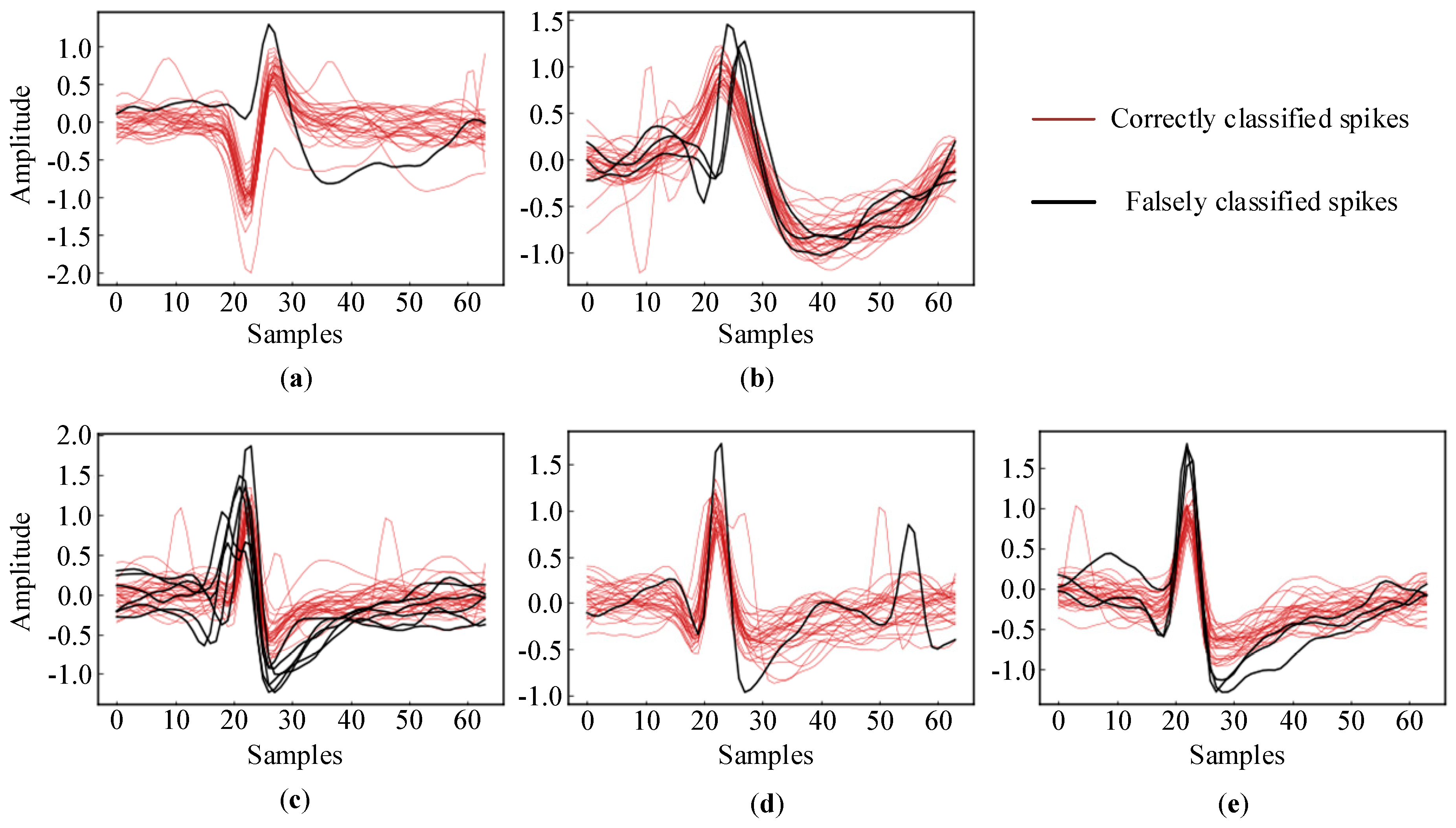
3.1. Simulated Database
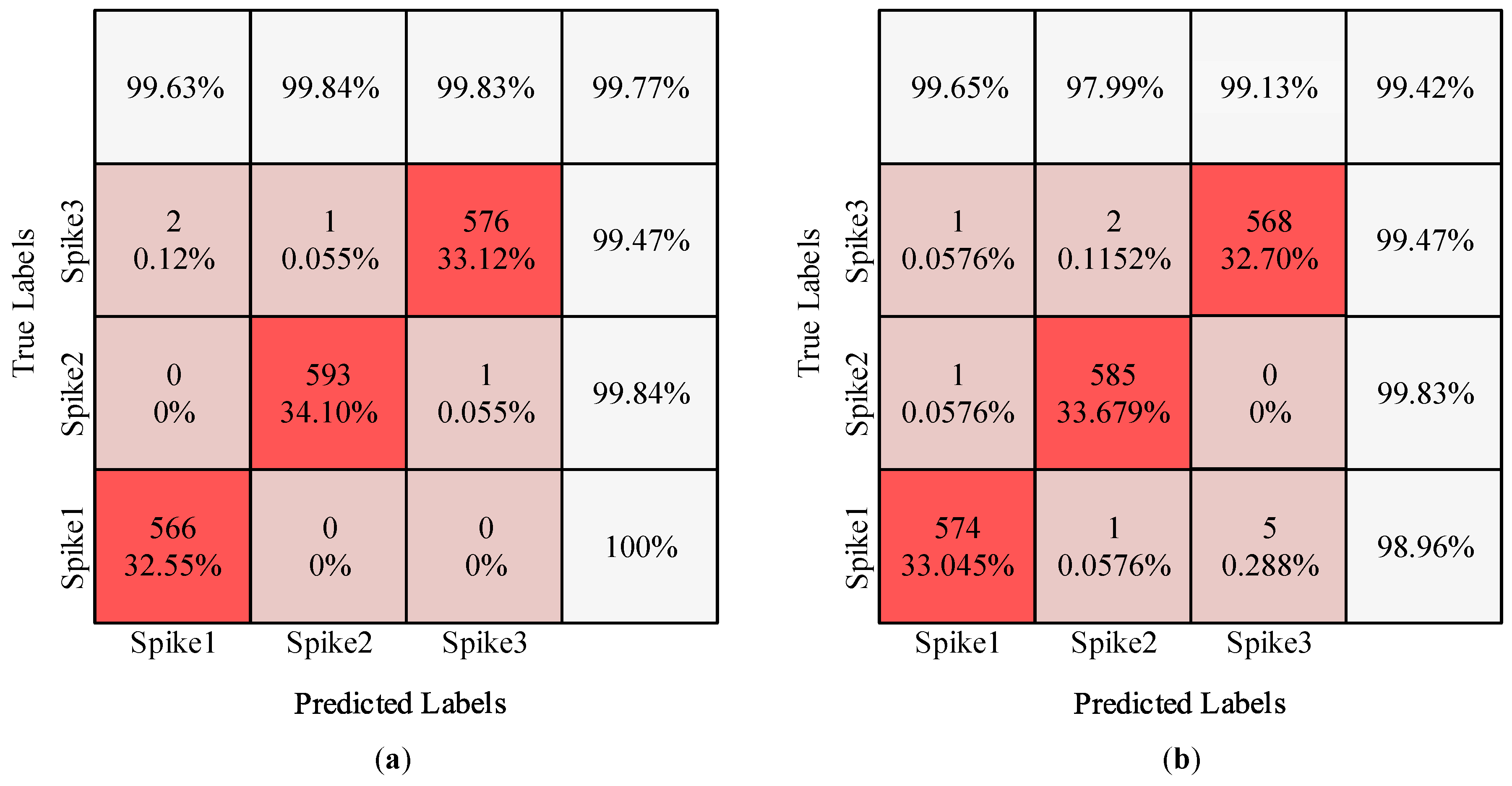
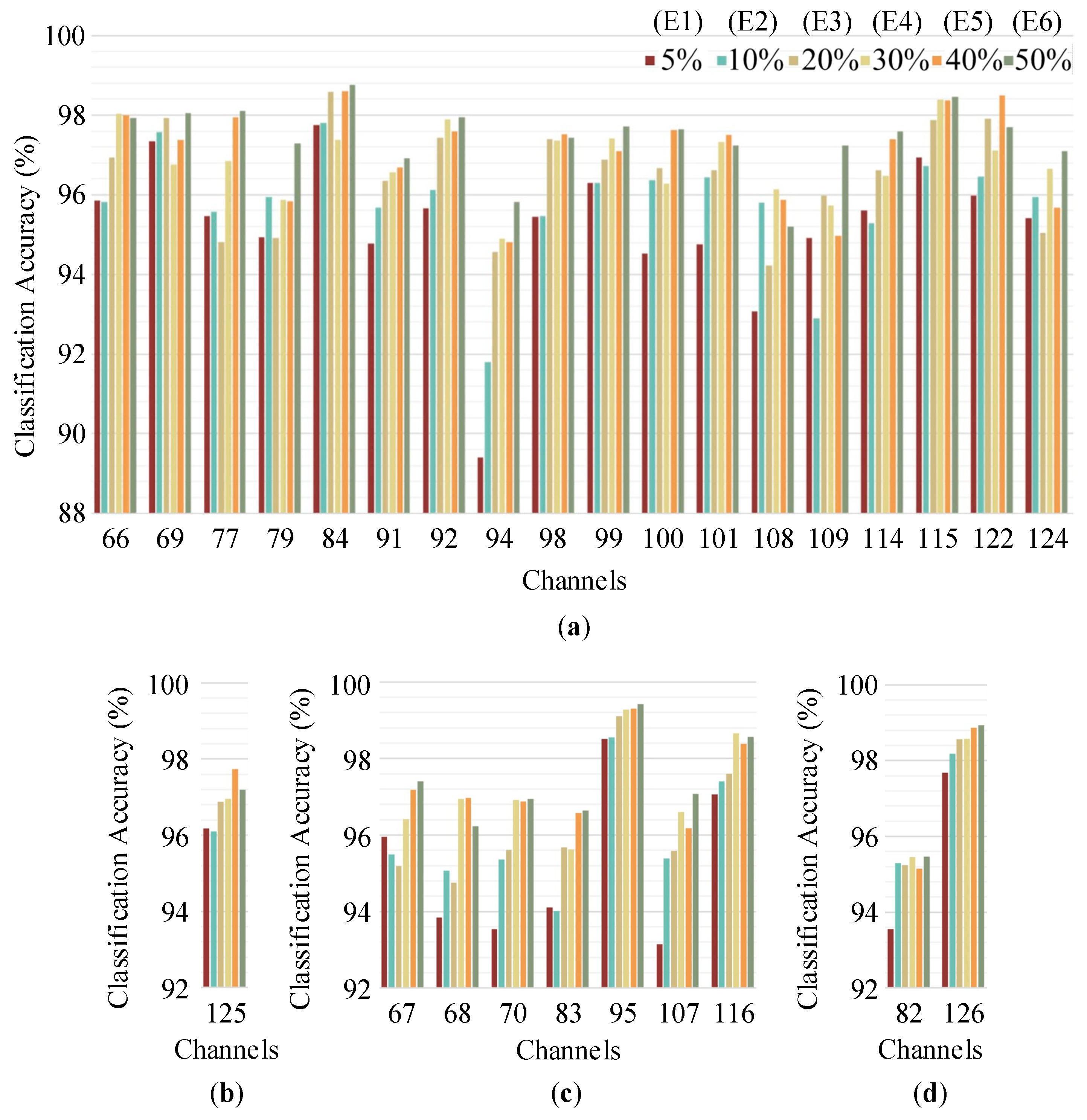
3.2. Experimental Datasets
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Arel, I.; Rose, D.C.; Karnowski, T.P. Deep machine learning-a new frontier in artificial intelligence research. IEEE Comput. Intell. Mag. 2010, 5, 13–18. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J.; Darzi, A.; Sanei, S. Extracellular spike detection from multiple electrode array using novel intelligent filter and ensemble fuzzy decision making. J. Neurosci. Methods 2015, 239, 129–138. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berenyi, A.; Somogyvari, Z.; Nagy, A.J.; Roux, L.; Long, J.D.; Fujisawa, S.; Stark, E.; Leonardo, A.; Harris, T.D.; Buzsaki, G. Large-scale, high-density (up to 512 channels) recording of local circuits in behaving animals. J. Neurophysiol. 2014, 111, 1132–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Obeid, I.; Wolf, P.D. Evaluation of spike-detection algorithms for a brain-machine interface application. IEEE Trans. Biomed. Eng. 2004, 51, 905–911. [Google Scholar] [CrossRef] [PubMed]
- Schmitzer-Torbert, N.; Jackson, J.; Henze, D.; Harris, K.D.; Redish, A.D. Quantitative measures of cluster quality for use in extracellular recordings. Neuroscience 2005, 131, 1–11. [Google Scholar] [CrossRef]
- Rey, H.G.; Pedreira, C.; Quian Quiroga, R. Past, present and future of spike sorting techniques. Brain Res. Bull. 2015, 119, 106–117. [Google Scholar] [CrossRef] [Green Version]
- Lefebvre, B.; Yger, P.; Marre, O. Recent progress in multi-electrode spike sorting methods. J. Physiol. Paris 2016, 110, 327–335. [Google Scholar] [CrossRef] [Green Version]
- Franke, F.; Jaeckel, D.; Dragas, J.; Müller, J.; Radivojevic, M.; Bakkum, D.; Hierlemann, A. High-density microelectrode array recordings and real-time spike sorting for closed-loop experiments: An emerging technology to study neural plasticity. Front. Neural Circuits 2012, 6, 105. [Google Scholar] [CrossRef] [Green Version]
- Buzsáki, G. Large-scale recording of neuronal ensembles. Nat. Neurosci. 2004, 7, 446–451. [Google Scholar] [CrossRef]
- Takekawa, T.; Isomura, Y.; Fukai, T. Accurate spike sorting for multi-unit recordings. Eur. J. Neurosci. 2010, 31, 263–272. [Google Scholar] [CrossRef]
- Quiroga, R.Q. Spike sorting. Curr. Biol. 2012, 22, 45–46. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sukiban, J.; Voges, N.; Dembek, T.A.; Pauli, R.; Visservandewalle, V.; Denker, M.; Weber, I.; Timmermann, L.; Grun, S. Evaluation of Spike Sorting Algorithms: Application to Human Subthalamic Nucleus Recordings and Simulations. Neuroscience 2019, 414, 168–185. [Google Scholar] [CrossRef] [PubMed]
- Gold, C.; Henze, D.A.; Koch, C.; Buzsaki, G. On the origin of the extracellular action potential waveform: A modeling study. J. Neurophysiol. 2006, 95, 3113–3128. [Google Scholar] [CrossRef] [PubMed]
- Quiroga, R.Q.; Nadasdy, Z.; Ben-Shaul, Y. Unsupervised spike detection and sorting with wavelets and superparamagnetic clustering. Neural Comput. 2004, 16, 1661–1687. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saif-Ur-Rehman, M.; Lienkamper, R.; Parpaley, Y.; Wellmer, J.; Liu, C.; Lee, B.; Kellis, S.; Andersen, R.; Iossifidis, I.; Glasmachers, T.; et al. SpikeDeeptector: A deep-learning based method for detection of neural spiking activity. JNEng 2019, 16, 056003. [Google Scholar] [CrossRef] [Green Version]
- Nenadic, Z.; Burdick, J.W. Spike detection using the continuous wavelet transform. IEEE Trans. Biomed. Eng. 2005, 52, 74–87. [Google Scholar] [CrossRef] [Green Version]
- Harris, K.D.; Henze, D.A.; Csicsvari, J.; Hirase, H.; Buzsaki, G. Accuracy of tetrode spike separation as determined by simultaneous intracellular and extracellular measurements. J. Neurophysiol. 2000, 84, 401–414. [Google Scholar] [CrossRef]
- Shoham, S.; Fellows, M.R.; Normann, R.A. Robust, automatic spike sorting using mixtures of multivariate t-distributions. J. Neurosci. Methods 2003, 127, 111–122. [Google Scholar] [CrossRef]
- Einevoll, G.T.; Franke, F.; Hagen, E.; Pouzat, C.; Harris, K.D. Towards reliable spike-train recordings from thousands of neurons with multielectrodes. Curr. Opin. Neurobiol. 2012, 22, 11–17. [Google Scholar] [CrossRef] [Green Version]
- Letelier, J.C.; Weber, P.P. Spike sorting based on discrete wavelet transform coefficients. J. Neurosci. Methods 2000, 101, 93–106. [Google Scholar] [CrossRef]
- Hulata, E.; Segev, R.; Ben-Jacob, E. A method for spike sorting and detection based on wavelet packets and Shannon’s mutual information. J. Neurosci. Methods 2002, 117, 1–12. [Google Scholar] [CrossRef]
- Chah, E.; Hok, V.; Della-Chiesa, A.; Miller, J.J.; O’Mara, S.M.; Reilly, R.B. Automated spike sorting algorithm based on Laplacian eigenmaps and k-means clustering. JNEng 2011, 8, 016006. [Google Scholar]
- Rossant, C.; Kadir, S.N.; Goodman, D.F.M.; Schulman, J.; Hunter, M.L.D.; Saleem, A.B.; Grosmark, A.; Belluscio, M.; Denfield, G.H.; Ecker, A.S.; et al. Spike sorting for large, dense electrode arrays. Nat. Neurosci. 2016, 19, 634–641. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kadir, S.N.; Goodman, D.F.; Harris, K.D. High-dimensional cluster analysis with the masked EM algorithm. Neural Comput. 2014, 26, 2379–2394. [Google Scholar] [CrossRef] [Green Version]
- Gibson, S.; Judy, J.W.; Markovic, D. Spike Sorting: The First Step in Decoding the Brain: The first step in decoding the brain. ISPM 2012, 29, 124–143. [Google Scholar] [CrossRef]
- Matthews, B.A.; Clements, M.A. Spike sorting by joint probabilistic modeling of neural spike trains and waveforms. Comput. Intell. Neurosci. 2014, 2014, 643059. [Google Scholar] [CrossRef]
- Tariq, T.; Satti, M.H.; Kamboh, H.M.; Saeed, M.; Kamboh, A.M. Computationally efficient fully-automatic online neural spike detection and sorting in presence of multi-unit activity for implantable circuits. Comput. Methods Programs Biomed. 2019, 179, 104986. [Google Scholar] [CrossRef]
- Chung, J.E.; Magland, J.F.; Barnett, A.H.; Tolosa, V.M.; Greengard, L.F. A Fully Automated Approach to Spike Sorting. Neuron 2017, 95, 1381–1394. [Google Scholar] [CrossRef] [Green Version]
- Horton, P.M.; Nicol, A.U.; Kendrick, K.M.; Feng, J.F. Spike sorting based upon machine learning algorithms (SOMA). J. Neurosci. Methods 2007, 160, 52–68. [Google Scholar] [CrossRef]
- Frey, U.; Egert, U.; Heer, F.; Hafizovic, S.; Hierlemann, A. Microelectronic system for high-resolution mapping of extracellular electric fields applied to brain slices. Biosens. Bioelectron. 2009, 24, 2191–2198. [Google Scholar] [CrossRef]
- Jun, J.J.; Steinmetz, N.A.; Siegle, J.H.; Denman, D.J.; Bauza, M.; Barbarits, B.; Lee, A.K.; Anastassiou, C.A.; Andrei, A.; Aydin, C.; et al. Fully integrated silicon probes for high-density recording of neural activity. Nature 2017, 551, 232–236. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spira, M.E.; Hai, A. Multi-electrode array technologies for neuroscience and cardiology. Nature Nanotechnol. 2013, 8, 83–94. [Google Scholar] [CrossRef] [PubMed]
- Harris, K.D.; Quiroga, R.Q.; Freeman, J.; Smith, S.L. Improving data quality in neuronal population recordings. Nat. Neurosci. 2016, 19, 1165–1174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huber, P.J. Robust Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2004; Volume 523. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Nadeem, M.W.; Ghamdi, M.A.A.; Hussain, M.; Khan, M.A.; Khan, K.M.; Almotiri, S.H.; Butt, S.A. Brain Tumor Analysis Empowered with Deep Learning: A Review, Taxonomy, and Future Challenges. Brain Sci. 2020, 10, 118. [Google Scholar] [CrossRef] [Green Version]
- Ali, M.B.; Gu, I.Y.; Berger, M.S.; Pallud, J.; Southwell, D.; Widhalm, G.; Roux, A.; Vecchio, T.G.; Jakola, A.S. Domain Mapping and Deep Learning from Multiple MRI Clinical Datasets for Prediction of Molecular Subtypes in Low Grade Gliomas. Brain Sci. 2020, 10, 463. [Google Scholar] [CrossRef]
- Ravì, D.; Wong, C.; Deligianni, F.; Berthelot, M.; Andreu-Perez, J.; Lo, B.; Yang, G.-Z. Deep learning for health informatics. IEEE J. Biomed. Health Inform. 2017, 21, 4–21. [Google Scholar] [CrossRef] [Green Version]
- Greenspan, H.; Van Ginneken, B.; Summers, R.M. Guest editorial deep learning in medical imaging: Overview and future promise of an exciting new technique. IEEE Trans. Med. Imaging 2016, 35, 1153–1159. [Google Scholar] [CrossRef]
- Fujita, H.; Cimr, D. Computer aided detection for fibrillations and flutters using deep convolutional neural network. Inf. Sci. 2019, 486, 231–239. [Google Scholar] [CrossRef]
- Yang, K.; Wu, H.; Zeng, Y. A Simple Deep Learning Method for Neuronal Spike Sorting. In Proceedings of the 2017 International Conference on Cloud Technology and Communication Engineering (CTCE2017), Guilin, China, 18–20 August 2017; p. 012062. [Google Scholar]
- Quiroga, R.Q. Wave_Clus: Unsupervised Spike Detection and Sorting. 2017. Available online: https://vis.caltech.edu/~rodri/Wave_clus/Wave_clus_home.htm (accessed on 10 November 2020).
- Huang, L.; Ling, B.W.; Cai, R.; Zeng, Y.; He, J.; Chen, Y. WMsorting: Wavelet Packets Decomposition and Mutual Information Based Spike Sorting Method. IEEE Trans. NanoBiosci. 2019, 18, 283–295. [Google Scholar] [CrossRef] [PubMed]
- Park, I.Y.; Eom, J.; Jang, H.; Kim, S.; Hwang, D. Deep Learning-Based Template Matching Spike Classification for Extracellular Recordings. Appl. Sci. 2019, 10, 301. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Wu, T.; Zhao, W.; Keefer, E.; Yang, Z. Deep compressive autoencoder for action potential compression in large-scale neural recording. JNEng 2018, 15, 6. [Google Scholar] [CrossRef] [Green Version]
- Chu, C.C.; Chien, P.F.; Hung, C.P. Multi-electrode recordings of ongoing activity and responses to parametric stimuli in macaque V1. CRCNS 2014, 61, 41–54. [Google Scholar] [CrossRef]
- Chu, C.C.; Chien, P.F.; Hung, C.P. Tuning dissimilarity explains short distance decline of spontaneous spike correlation in macaque V1. Vision Res. 2014, 96, 113–132. [Google Scholar] [CrossRef] [Green Version]
- Hou, Y.; Zhou, L.; Jia, S.; Lun, X. A novel approach of decoding EEG four-class motor imagery tasks via scout ESI and CNN. JNEng 2020, 17, 016048. [Google Scholar] [CrossRef]
- Özgür, A.; Özgür, L.; Güngör, T. Text categorization with class-based and corpus-based keyword selection. In International Symposium on Computer and Information Sciences; Springer: Berlin/Heidelberg, Germany, 2005; pp. 606–615. [Google Scholar]
- Rácz, M.; Liber, C.; Németh, E.; Fiáth, R.; Rokai, J.; Harmati, I.; Ulbert, I.; Márton, G. Spike detection and sorting with deep learning. J. Neural Eng. 2020, 17, 016038. [Google Scholar] [CrossRef]
- Saif-Ur-Rehman, M.; Ali, O.; Lienkaemper, R.; Dyck, S.; Metzler, M.; Parpaley, Y.; Wellmer, J.; Liu, C.; Lee, B.; Kellis, S. SpikeDeep-Classifier: A deep-learning based fully automatic offline spike sorting algorithm. arXiv 2019, arXiv:1912.10749. [Google Scholar] [CrossRef]
- Huang, G.; Song, S.; Gupta, J.N.D.; Wu, C. Semi-Supervised and Unsupervised Extreme Learning Machines. IEEE Trans. Cybern. 2017, 44, 2405–2417. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | NL 1 | WMsorting | 1D-CNN | Improvement | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| F 2 = 3 | F = 10 | E1 3 | E2 | E3 | E4 | E5 | E6 | |||
| C_Easy1 | 005 | 99.60 | 99.52 | 99.64 | 99.53 | 99.40 | 99.63 | 99.67 | 99.77 | 0.17 |
| 010 | 99.66 | 99.57 | 99.52 | 99.72 | 99.82 | 99.88 | 99.86 | 99.94 | 0.28 | |
| 015 | 99.71 | 99.63 | 99.61 | 99.49 | 99.82 | 99.84 | 99.81 | 99.77 | 0.13 | |
| 020 | 99.57 | 99.48 | 99.33 | 99.33 | 99.64 | 99.84 | 99.76 | 99.88 | 0.31 | |
| 025 | 99.45 | 99.42 | 99.55 | 99.56 | 99.81 | 99.74 | 99.85 | 99.70 | 0.40 | |
| 030 | 99.57 | 99.48 | 99.49 | 99.65 | 99.71 | 99.18 | 99.62 | 99.71 | 0.14 | |
| 035 | 99.43 | 99.38 | 99.49 | 99.43 | 99.65 | 99.56 | 99.20 | 99.60 | 0.22 | |
| 040 | 99.76 | 99.70 | 99.35 | 99.51 | 99.56 | 99.79 | 99.75 | 99.82 | 0.06 | |
| C_Easy2 | 005 | 99.50 | 99.41 | 99.72 | 99.64 | 99.71 | 99.66 | 99.66 | 99.88 | 0.38 |
| 010 | 99.52 | 99.40 | 99.58 | 99.62 | 99.75 | 99.76 | 99.91 | 99.83 | 0.39 | |
| 015 | 99.44 | 99.38 | 99.32 | 98.89 | 99.23 | 99.33 | 99.61 | 99.77 | 0.33 | |
| 020 | 99.29 | 99.35 | 99.19 | 99.69 | 99.33 | 99.55 | 99.62 | 99.66 | 0.31 | |
| C_Difficult1 | 005 | 94.47 | 95.00 | 98.07 | 99.21 | 99.11 | 99.11 | 98.97 | 99.05 | 4.21 |
| 010 | 92.89 | 93.76 | 98.99 | 99.00 | 99.09 | 99.46 | 99.66 | 99.83 | 6.07 | |
| 015 | 90.18 | 91.18 | 97.76 | 98.43 | 98.63 | 99.18 | 98.75 | 99.42 | 8.24 | |
| 020 | 85.38 | 86.45 | 95.16 | 98.54 | 99.01 | 98.83 | 98.73 | 98.83 | 12.38 | |
| C_Difficult2 | 005 | 99.23 | 99.44 | 99.22 | 98.88 | 99.48 | 99.66 | 99.85 | 99.82 | 0.41 |
| 010 | 98.93 | 99.51 | 99.48 | 99.78 | 99.78 | 99.84 | 99.99 | 99.94 | 0.48 | |
| 015 | 98.05 | 99.51 | 99.57 | 99.58 | 99.53 | 99.67 | 99.71 | 99.71 | 0.20 | |
| 020 | 95.99 | 99.66 | 99.58 | 99.75 | 99.61 | 99.75 | 99.67 | 99.83 | 0.17 | |
| Dataset | NL 1 | PCA + FCM | FSDE + K-means | CORR + FCM | Fusion + SVM | MLP | 1D-CNN | ||
|---|---|---|---|---|---|---|---|---|---|
| F 2 = 3 | F = 10 | F = 3 | F = 3 | F = 10 | F = 10 | E2 3 | |||
| C_Easy1 | 005 | 99.37 | 99.35 | 94.62 | 97.50 | 97.38 | 98.66 | 99.26 | 99.53 |
| 010 | 99.72 | 99.72 | 95.54 | 94.04 | 96.45 | 98.98 | 99.43 | 99.72 | |
| 015 | 99.25 | 99.28 | 94.45 | 90.54 | 94.94 | 98.22 | 99.25 | 99.49 | |
| 020 | 99.40 | 99.40 | 95.08 | 88.77 | 92.43 | 97.35 | 99.19 | 99.33 | |
| 025 | 99.24 | 99.24 | 84.41 | 86.84 | 95.45 | 99.56 | |||
| 030 | 98.73 | 98.59 | 81.50 | 80.83 | 88.66 | 99.65 | |||
| 035 | 97.76 | 95.16 | 77.02 | 73.80 | 83.22 | 99.43 | |||
| 040 | 96.49 | 68.54 | 75.58 | 64.62 | 78.12 | 99.51 | |||
| C_Easy2 | 005 | 98.48 | 98.68 | 94.81 | 93.20 | 96.04 | 92.23 | 98.68 | 99.64 |
| 010 | 97.16 | 98.24 | 94.83 | 86.02 | 82.19 | 92.93 | 98.49 | 99.62 | |
| 015 | 92.52 | 94.49 | 94.96 | 83.05 | 82.82 | 89.80 | 97.19 | 98.89 | |
| 020 | 85.20 | 88.60 | 92.71 | 79.81 | 78.22 | 86.24 | 95.20 | 99.69 | |
| C_Difficult1 | 005 | 95.86 | 72.54 | 94.50 | 83.48 | 86.08 | 97.58 | 98.78 | 99.21 |
| 010 | 89.56 | 66.11 | 94.78 | 65.69 | 71.55 | 94.81 | 98.93 | 99.00 | |
| 015 | 76.41 | 61.33 | 93.81 | 57.49 | 58.84 | 87.85 | 97.55 | 98.43 | |
| 020 | 63.03 | 54.05 | 90.60 | 53.72 | 53.81 | 78.59 | 96.62 | 98.54 | |
| C_Difficult2 | 005 | 98.69 | 98.81 | 94.38 | 91.50 | 94.50 | 87.40 | 98.49 | 98.88 |
| 010 | 98.64 | 98.76 | 94.48 | 90.96 | 96.33 | 88.07 | 94.66 | 99.78 | |
| 015 | 94.39 | 97.33 | 87.18 | 88.17 | 96.02 | 74.65 | 82.20 | 99.58 | |
| 020 | 84.63 | 83.37 | 81.71 | 84.77 | 95.48 | 67.25 | 51.55 | 99.75 | |
| Channels | Number of Clusters | WMsorting | 1D_CNN | Improvement | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| F 1 = 3 | F = 10 | E1 2 | E2 | E3 | E4 | E5 | E6 | |||
| 125 | 2 | 88.94 | 86.21 | 87.33 | 90.96 | 94.49 | 97.00 | 94.49 | 97.50 | 8.56 |
| 66 | 3 | 94.56 | 95.36 | 95.16 | 96.33 | 96.84 | 97.34 | 97.67 | 98.17 | 2.81 |
| 69 | 3 | 96.43 | 96.49 | 97.33 | 97.34 | 97.66 | 96.34 | 97.15 | 98.17 | 1.68 |
| 77 | 3 | 84.05 | 87.84 | 89.45 | 91.78 | 91.67 | 96.33 | 95.97 | 97.33 | 9.49 |
| 79 | 3 | 91.59 | 92.28 | 91.49 | 95.49 | 94.99 | 96.35 | 96.33 | 96.16 | 3.88 |
| 84 | 3 | 92.26 | 94.02 | 96.51 | 98.17 | 98.00 | 98.00 | 97.67 | 99.00 | 4.98 |
| 91 | 3 | 94.37 | 95.29 | 94.33 | 96.00 | 95.32 | 95.32 | 95.32 | 96.30 | 1.01 |
| 92 | 3 | 92.31 | 94.38 | 93.33 | 95.51 | 94.63 | 95.65 | 95.51 | 95.65 | 1.27 |
| 94 | 3 | 87.29 | 88.61 | 88.50 | 88.11 | 93.01 | 92.14 | 93.50 | 94.36 | 5.75 |
| 98 | 3 | 66.18 | 72.73 | 74.66 | 80.06 | 79.33 | 90.25 | 90.00 | 90.14 | 17.41 |
| 99 | 3 | 83.29 | 87.16 | 81.69 | 90.58 | 91.74 | 92.09 | 90.35 | 93.29 | 6.13 |
| 100 | 3 | 89.92 | 90.64 | 88.31 | 93.38 | 96.00 | 94.98 | 96.17 | 97.66 | 7.02 |
| 101 | 3 | 84.28 | 85.62 | 87.34 | 90.78 | 94.01 | 94.00 | 93.80 | 95.85 | 10.23 |
| 108 | 3 | 90.29 | 90.61 | 93.30 | 94.34 | 94.65 | 95.67 | 94.87 | 95.50 | 4.89 |
| 109 | 3 | 90.29 | 92.52 | 94.18 | 94.00 | 95.83 | 94.01 | 95.00 | 97.49 | 4.97 |
| 114 | 3 | 92.49 | 91.06 | 91.82 | 92.73 | 93.43 | 95.66 | 96.99 | 96.32 | 3.83 |
| 115 | 3 | 89.90 | 88.61 | 91.33 | 92.78 | 94.44 | 94.62 | 95.63 | 96.14 | 6.24 |
| 122 | 3 | 86.11 | 90.60 | 90.35 | 93.30 | 94.44 | 96.84 | 95.97 | 96.01 | 5.41 |
| 124 | 3 | 79.23 | 85.07 | 86.72 | 88.24 | 88.48 | 93.77 | 92.68 | 96.83 | 11.76 |
| 67 | 4 | 85.34 | 87.06 | 93.54 | 94.47 | 93.48 | 95.99 | 95.84 | 96.36 | 9.30 |
| 68 | 4 | 78.06 | 80.35 | 81.99 | 84.10 | 88.03 | 92.00 | 90.17 | 90.80 | 10.45 |
| 70 | 4 | 85.96 | 88.72 | 89.01 | 92.02 | 92.99 | 94.99 | 93.72 | 95.24 | 6.52 |
| 83 | 4 | 84.19 | 86.10 | 92.43 | 94.25 | 94.52 | 93.52 | 94.35 | 96.76 | 10.66 |
| 95 | 4 | 88.06 | 89.79 | 92.86 | 90.61 | 93.17 | 92.94 | 93.54 | 96.07 | 6.28 |
| 107 | 4 | 85.10 | 86.71 | 91.21 | 93.83 | 95.76 | 96.49 | 95.65 | 95.01 | 8.30 |
| 116 | 4 | 84.12 | 86.19 | 95.44 | 94.97 | 95.68 | 98.62 | 98.75 | 99.00 | 12.81 |
| 82 | 5 | 46.22 | 53.58 | 67.72 | 72.47 | 78.41 | 80.27 | 78.43 | 83.63 | 30.05 |
| 126 | 5 | 86.17 | 89.65 | 97.19 | 97.49 | 97.38 | 98.39 | 98.59 | 98.40 | 8.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Wang, Y.; Zhang, N.; Li, X. An Accurate and Robust Method for Spike Sorting Based on Convolutional Neural Networks. Brain Sci. 2020, 10, 835. https://doi.org/10.3390/brainsci10110835
Li Z, Wang Y, Zhang N, Li X. An Accurate and Robust Method for Spike Sorting Based on Convolutional Neural Networks. Brain Sciences. 2020; 10(11):835. https://doi.org/10.3390/brainsci10110835
Chicago/Turabian StyleLi, Zhaohui, Yongtian Wang, Nan Zhang, and Xiaoli Li. 2020. "An Accurate and Robust Method for Spike Sorting Based on Convolutional Neural Networks" Brain Sciences 10, no. 11: 835. https://doi.org/10.3390/brainsci10110835
APA StyleLi, Z., Wang, Y., Zhang, N., & Li, X. (2020). An Accurate and Robust Method for Spike Sorting Based on Convolutional Neural Networks. Brain Sciences, 10(11), 835. https://doi.org/10.3390/brainsci10110835