Domain Mapping and Deep Learning from Multiple MRI Clinical Datasets for Prediction of Molecular Subtypes in Low Grade Gliomas

 ,
,  , ,
, ,
Abstract
:1. Introduction
Related Work
- Propose a domain adaptation method based on unpaired-CycleGAN that maps several small datasets into a common one while preserving molecular biomarker information of brain tumors.
- Propose to enlarge the training dataset after mapping, using deep convolutional GAN (DCGAN) to produce augmented multi-modality MRIs (T1 weighted with contrast enhanced (T1ce), FLAIR).
- to tackle the crucial and time consuming task of accurate tumor segmentation which needs time and anatomical expertise to put soft tissue boundaries, a rectangular tight bounding box is used instead.
- Propose a multi-stream convolutional autoencoders (CAEs) and feature fusion scheme for deep learning of molecular-level information from MRIs in the mapped domain, where pre-training is applied on GAN augmented MRIs, while refined training is applied on MRIs from mapped domain.
- Extensive empirical tests and performance evaluation on the effectiveness of the proposed scheme and comparison with some state-of-the-art methods.
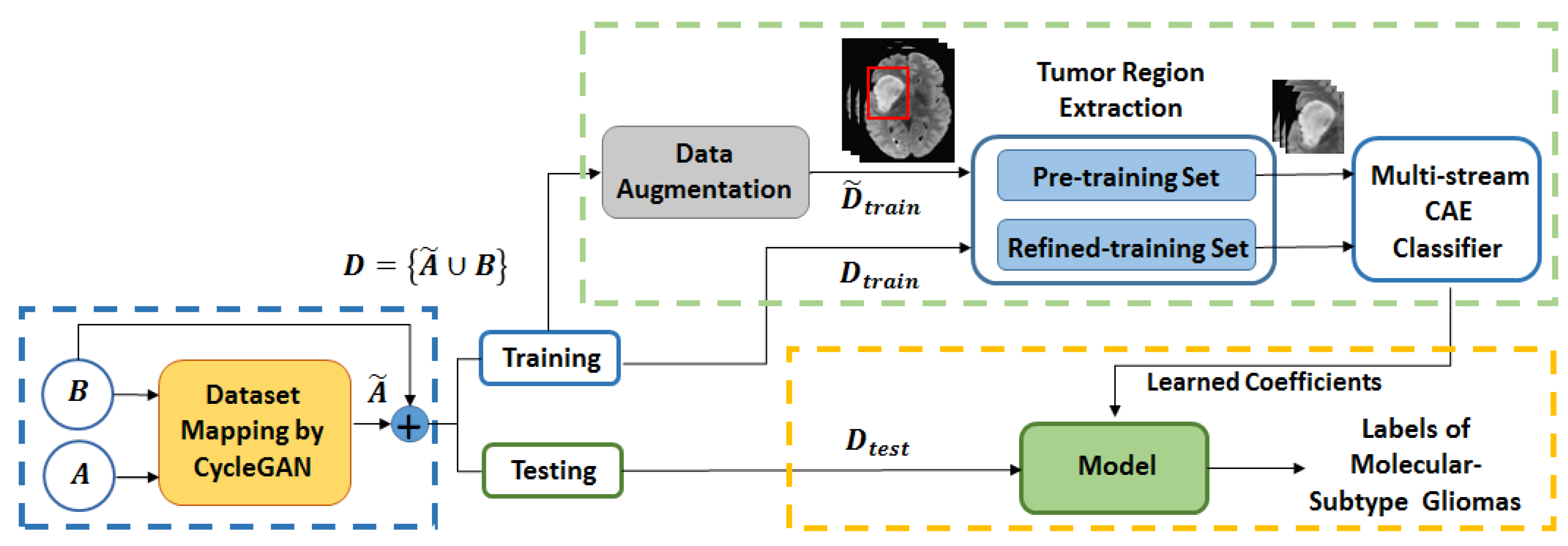
2. Overview of the Proposed Method
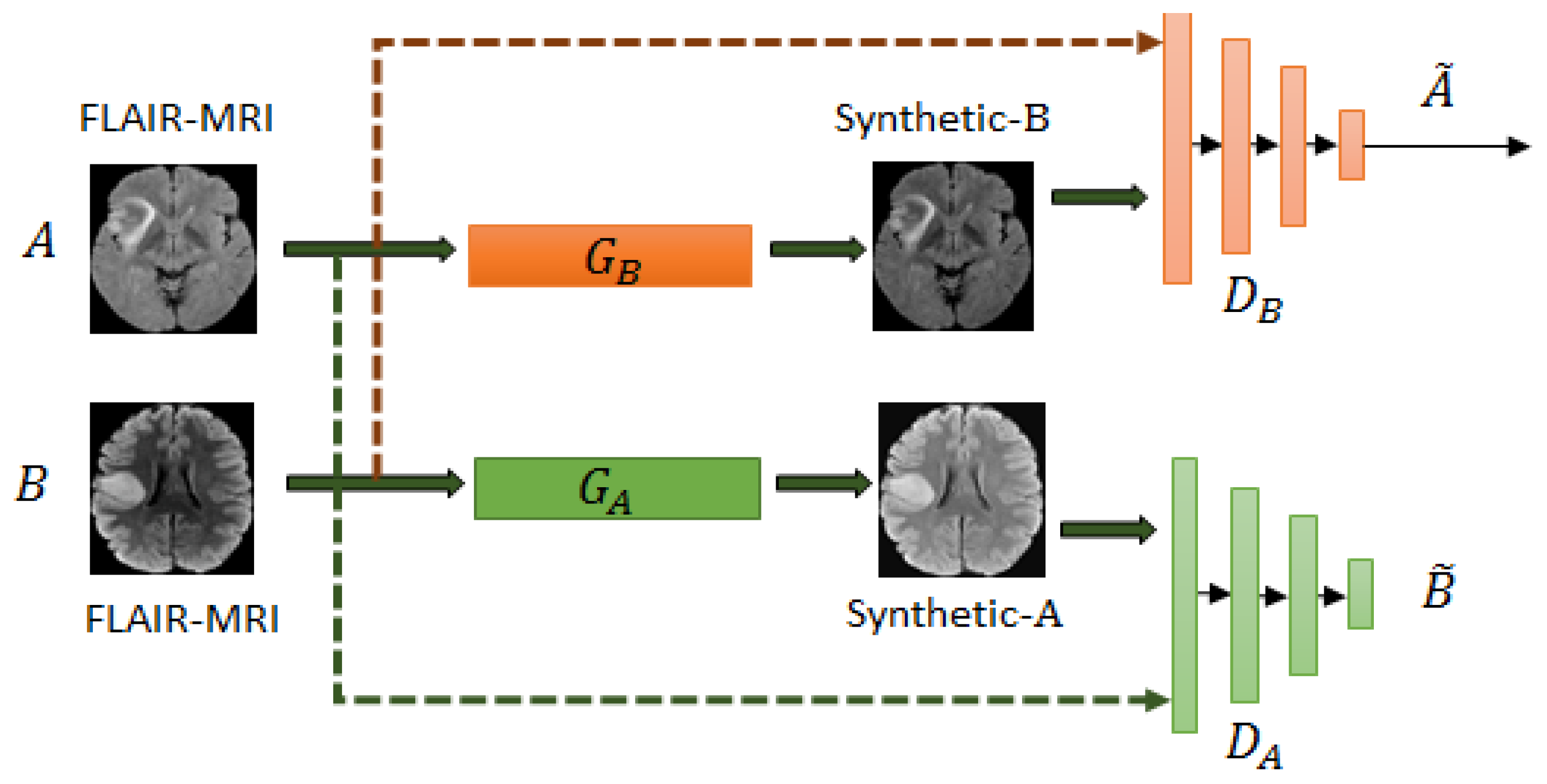
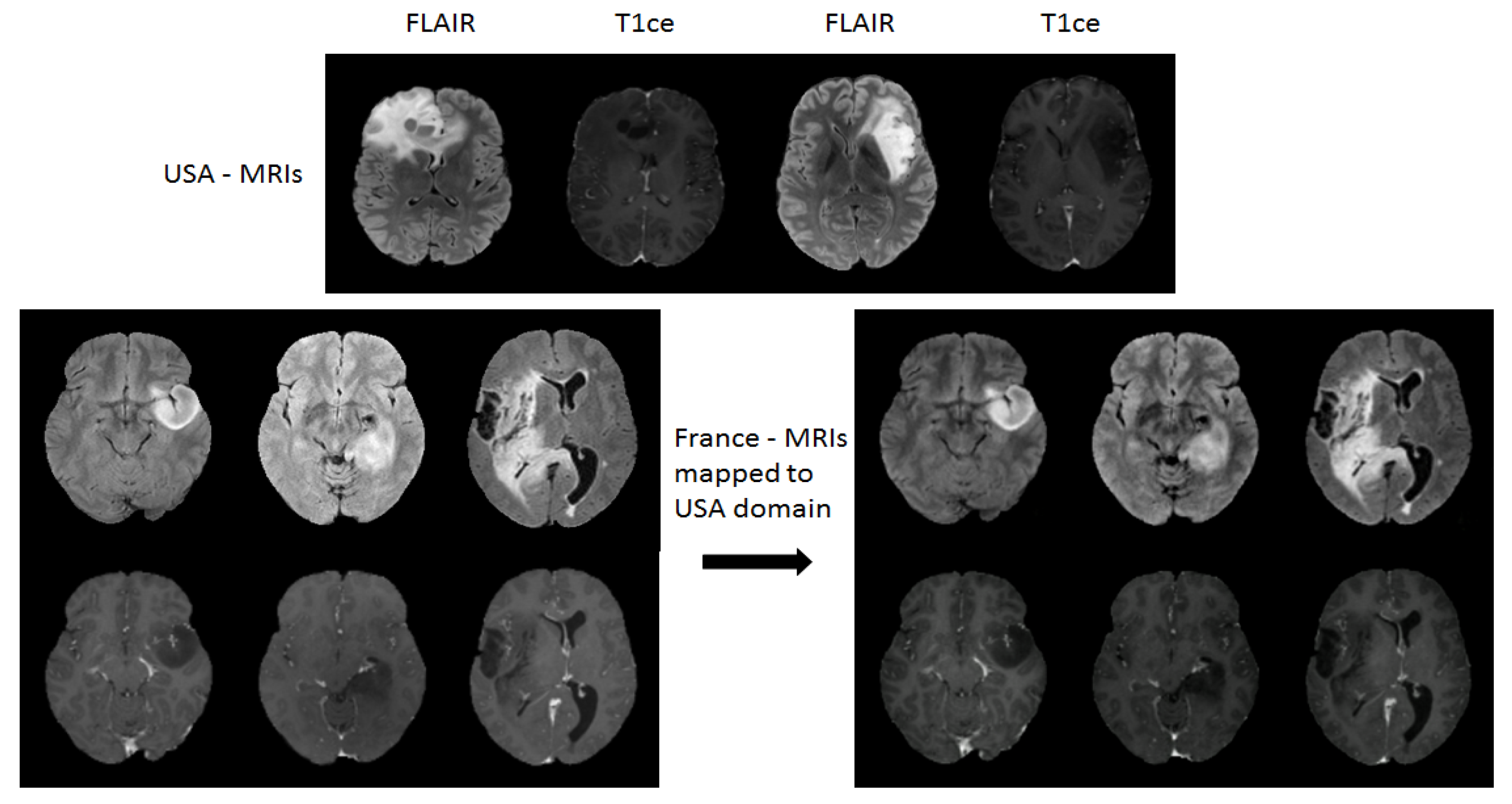
2.1. Unpaired Cyclegan for Domain Mapping
2.1.1. Formulation of the Unpaired Cyclegan
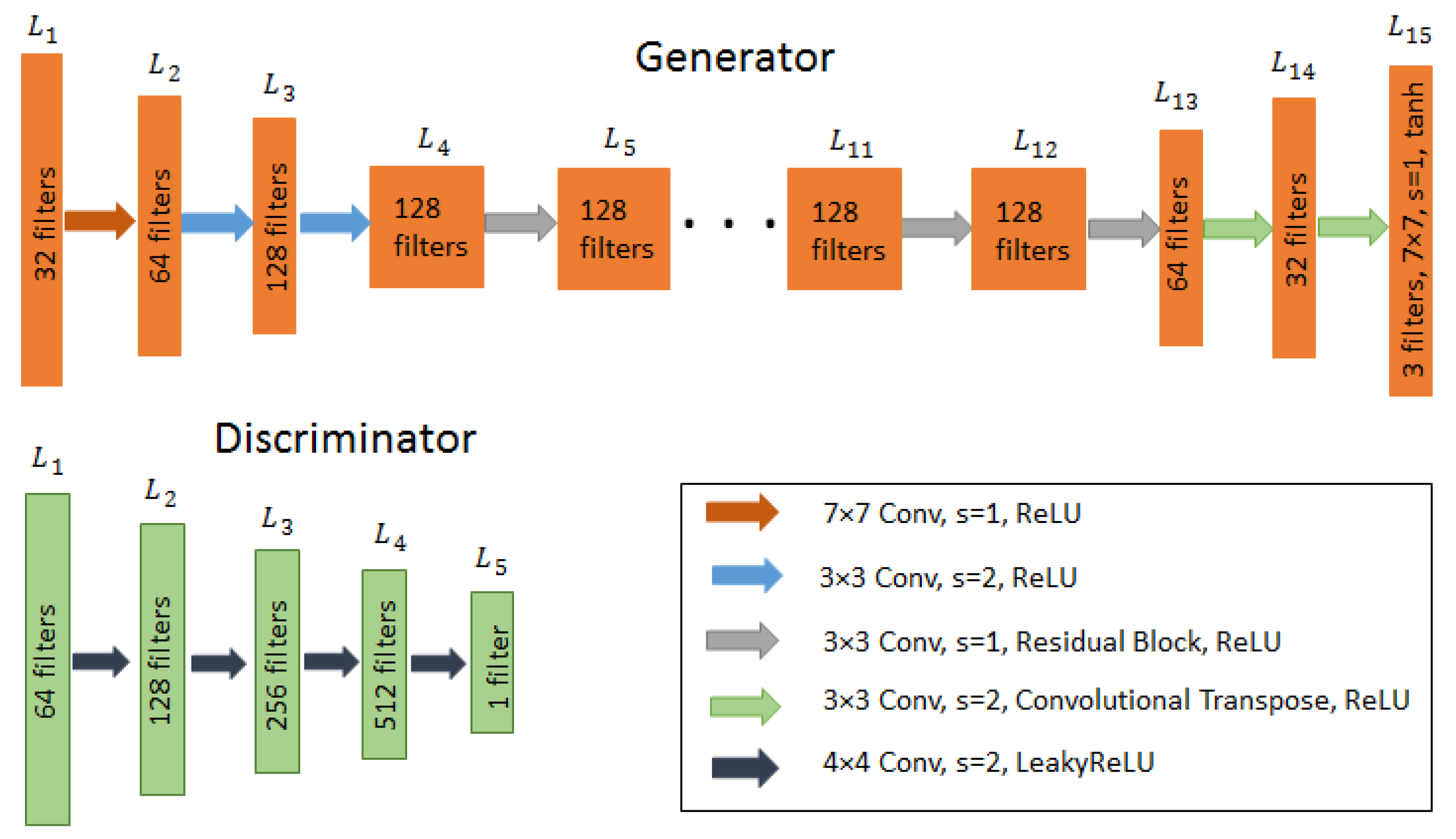
2.1.2. Architecture of Unpaired Cyclegan
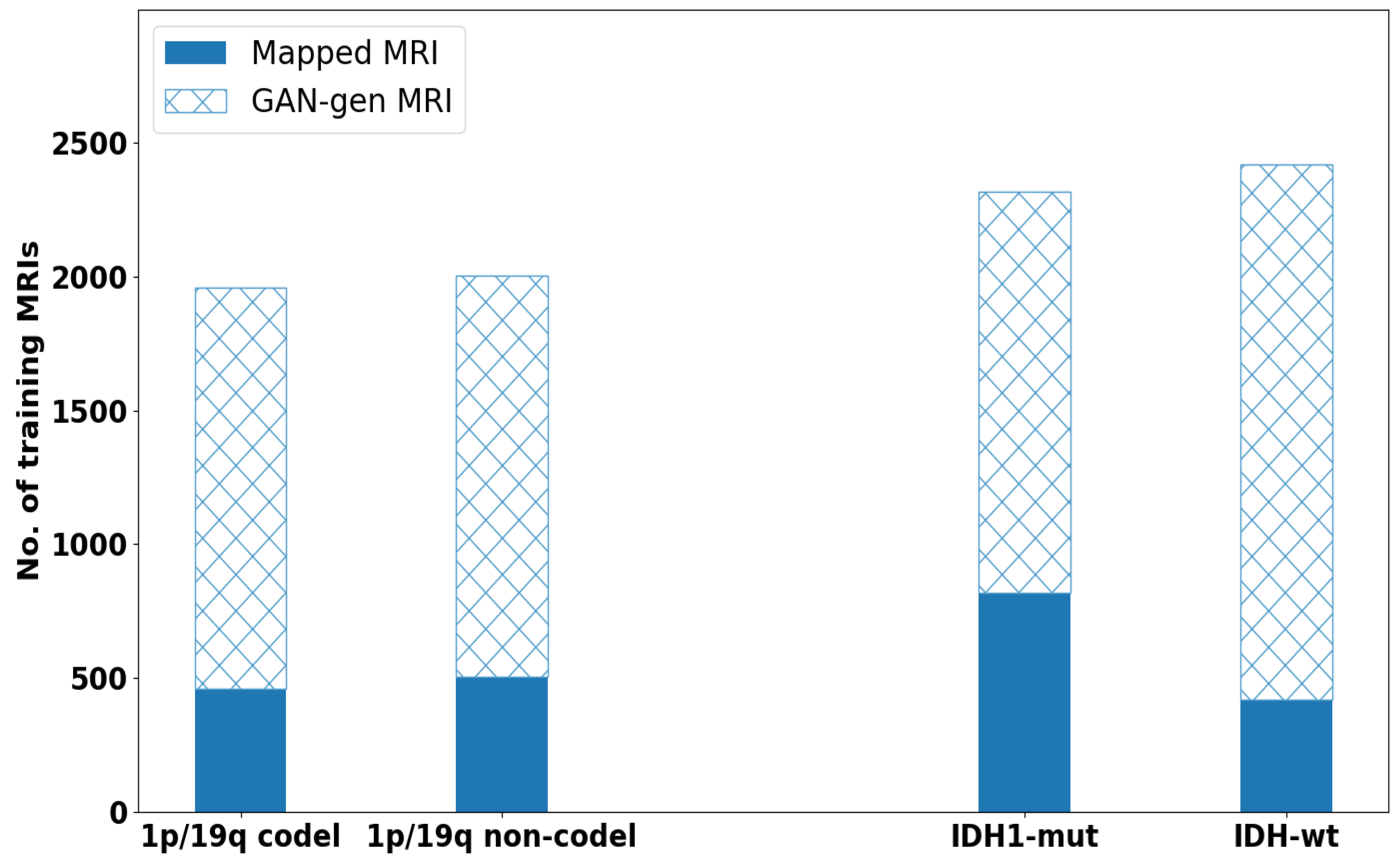
2.2. Data Augmentation by Deep Convolutional GAN
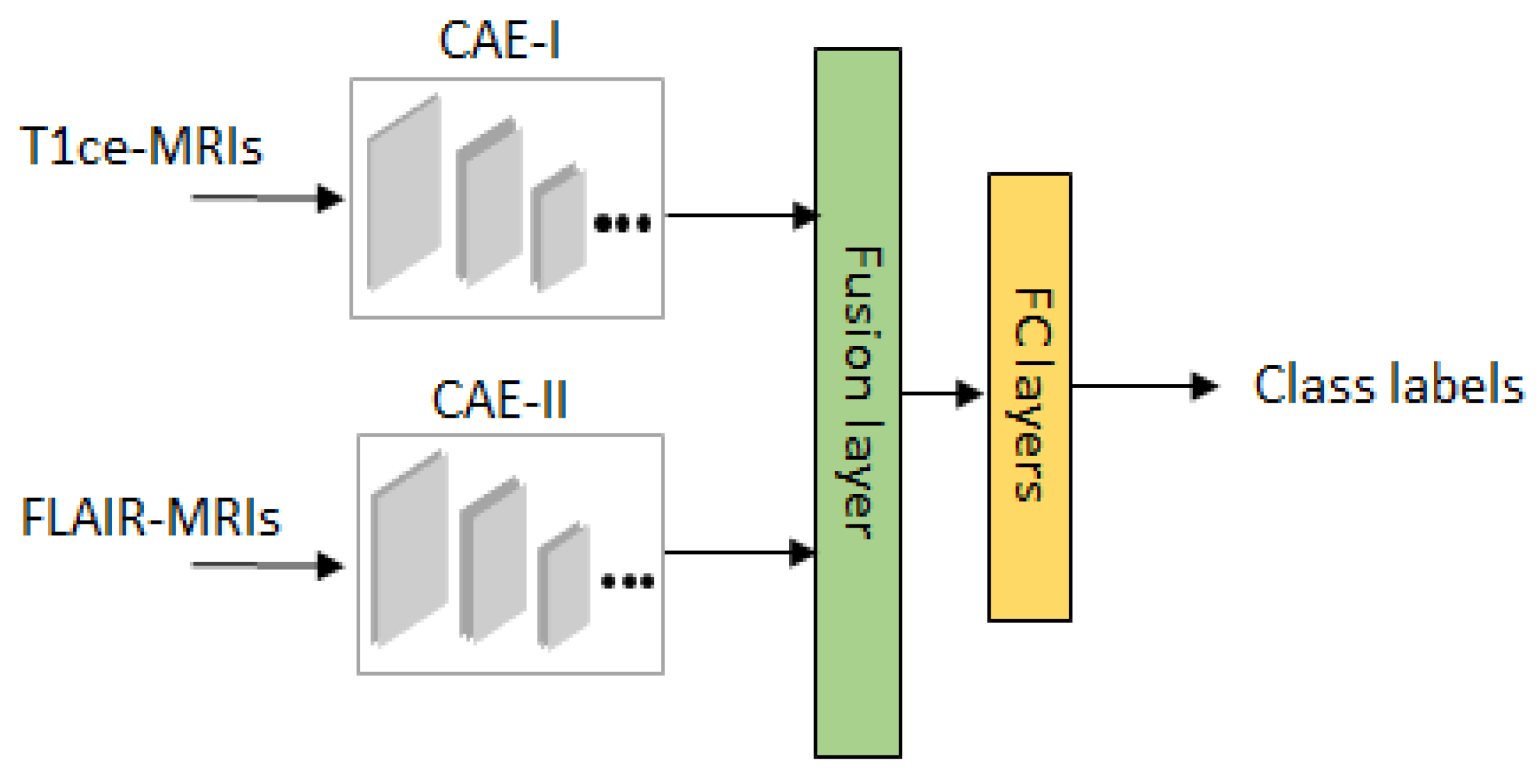
2.3. Review of Multi-Stream Convolutional Autoencoder and Feature Fusion
3. Experimental Results
3.1. Setup, Datasets, Metrics
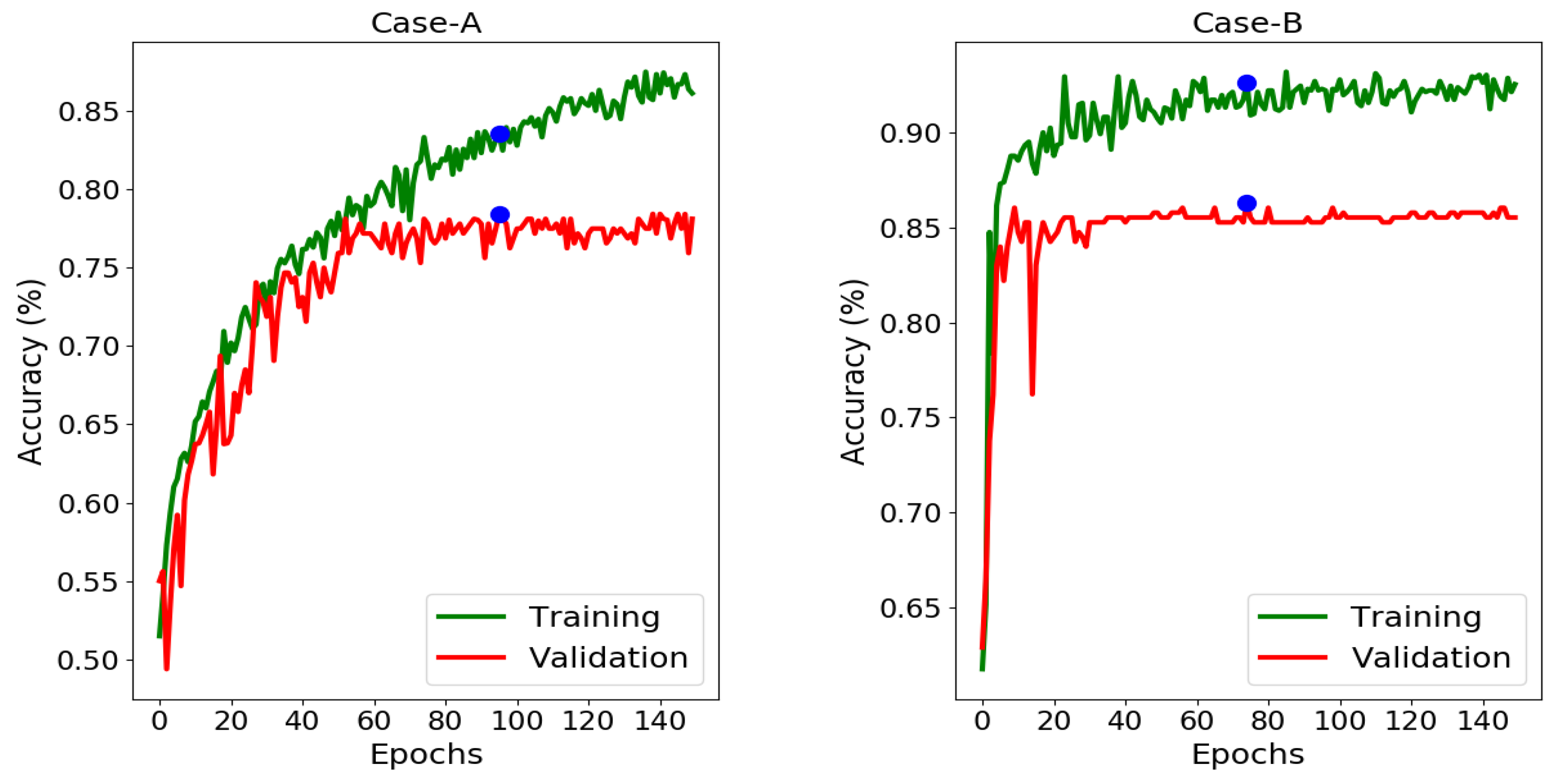
3.1.1. Setup
3.1.2. Datasets
3.1.3. Metrics for Performance Evaluation
- True positive (TP): the 1p/19q codeletion/IDH mutation gliomas, and were correctly classified as 1p/19q codeltion/IDH mutation.
- False positive (FP): the 1p/19q non-codeletion/IDH wild-type gliomas, but were incorrectly classified as 1p/19q codeltion/IDH mutation.
- True negative (TN): the 1p/19q non-codeletion/IDH wild-type gliomas, and were correctly classified as 1p/19q non-codeltion/IDH wild-type.
- False negative (FN): the 1p/19q codeletion/IDH mutation gliomas, but were incorrectly classified as 1p/19q non-codeletion/IDH wild-type.
3.2. Pre-Processing and Tumor Bounding Box
3.2.1. Pre-Processing
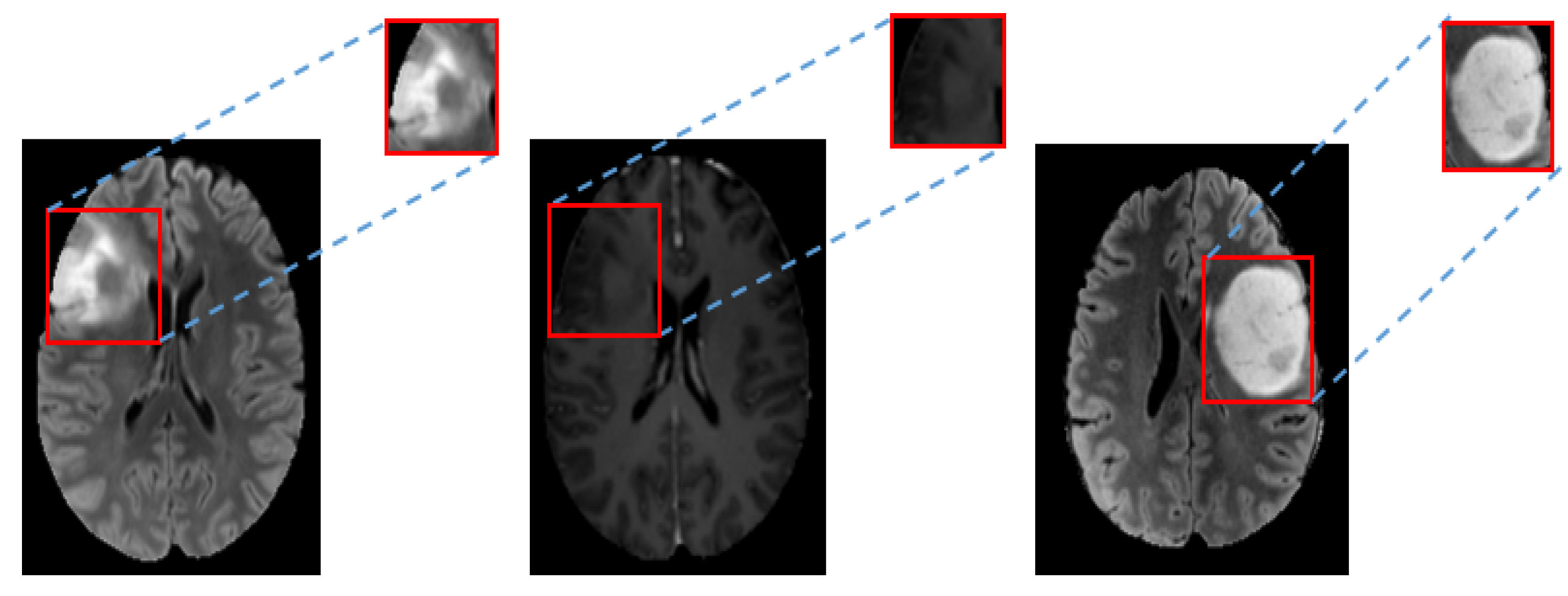
3.2.2. Tumor Bounding Box
3.3. Results and Discussions
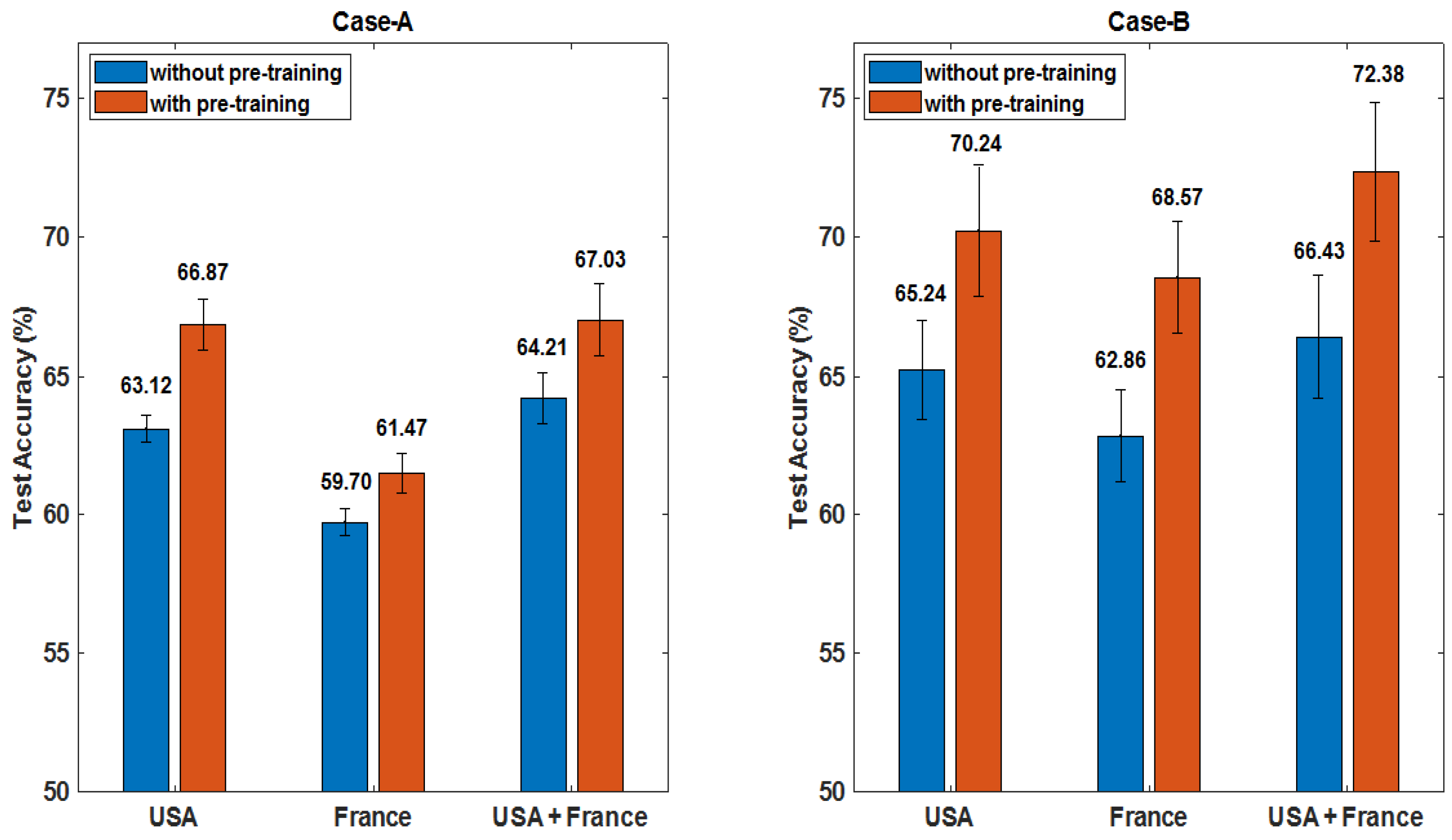
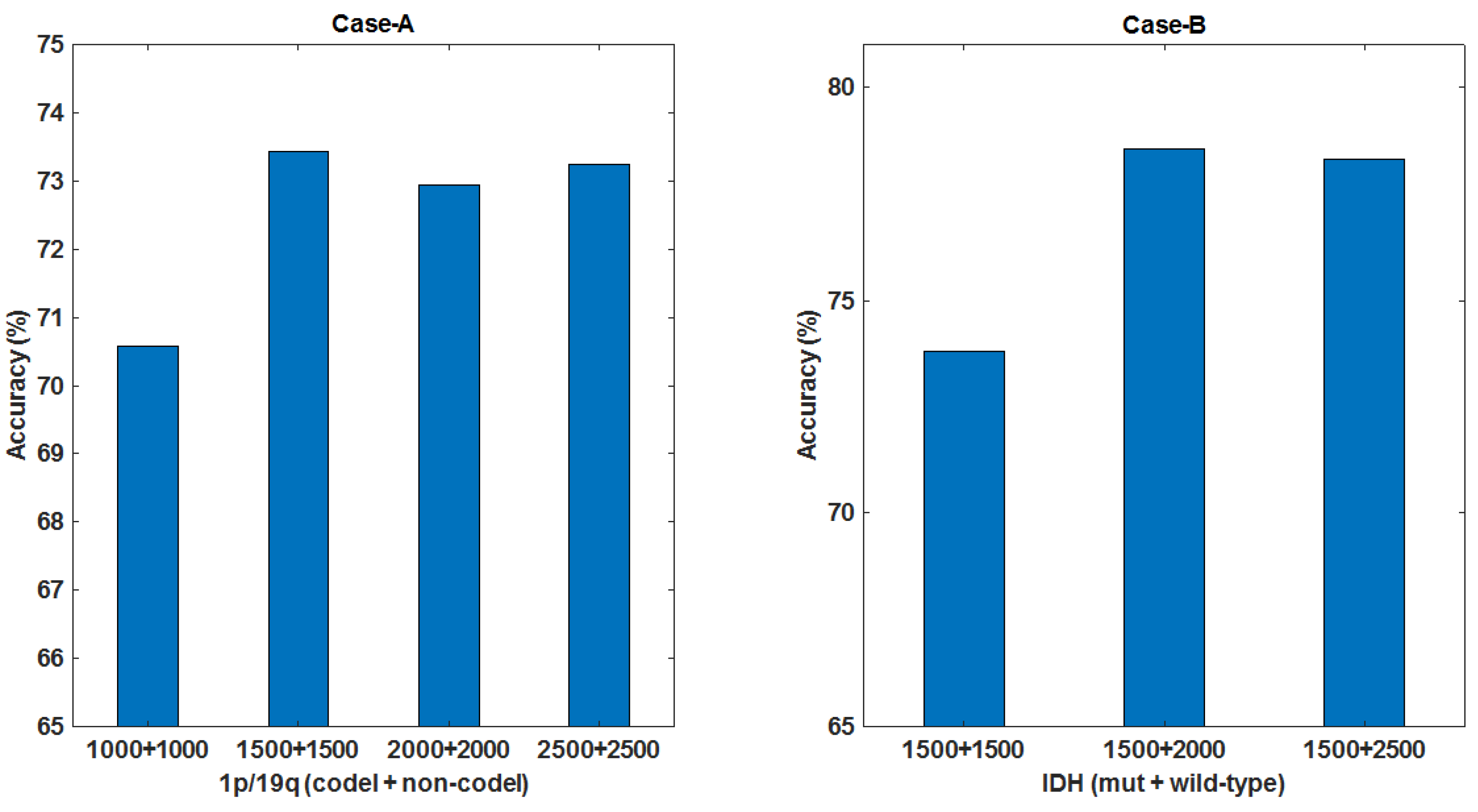
3.3.1. Performance Evaluation on the Impact of Individual Parts
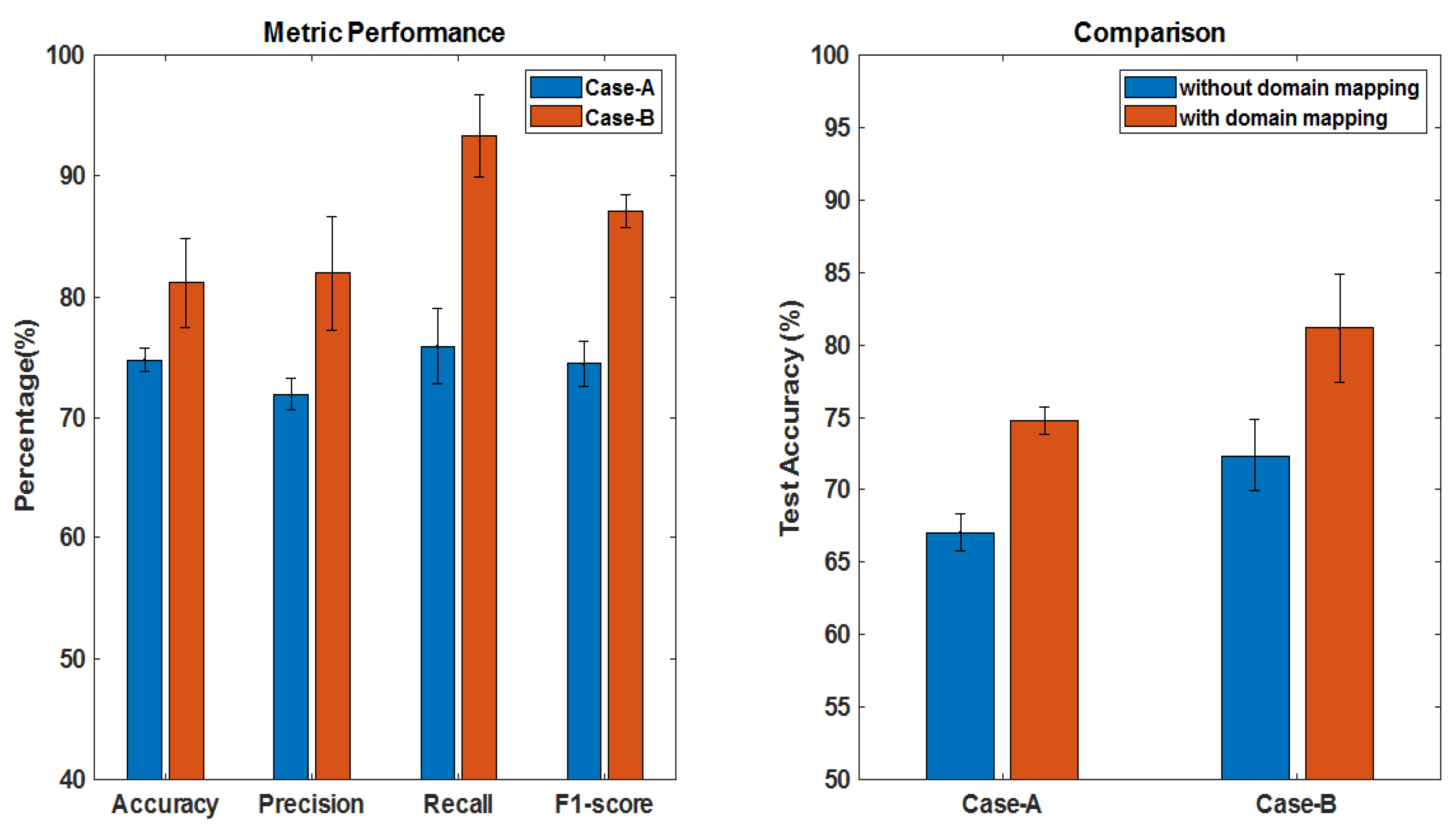
3.3.2. Overall Performance of the Proposed Scheme
3.4. Comparison with State-of-the-Art and Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Louis, D.N.; Perry, A.; Reifenberger, G.; von Deimling, A.; Figarella-Branger, D.; Cavenee, W.K.; Ohgaki, H.; Wiestler, O.D.; Kleihues, P.; Ellison, D.W. The 2016 World Health Organization Classification of Tumors of the Central Nervous System: A summary. Acta Neuropathol. 2016, 131, 803–820. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fuller, C.E.; Perry, A. Molecular diagnostics in central nervous system tumors. Adv. Anatom. Pathol. 2005, 12, 180–194. [Google Scholar] [CrossRef] [PubMed]
- Wijnenga, M.M.; van der Voort, S.R.; French, P.J.; Klein, S.; Dubbink, H.J.; Dinjens, W.N.; Atmodimedjo, P.N.; de Groot, M.; Kros, J.M.; Schouten, J.W.; et al. Differences in spatial distribution between WHO 2016 low-grade glioma molecular subgroups. Neuro-Oncol. Adv. 2019. [Google Scholar] [CrossRef] [Green Version]
- Delev, D.; Heiland, D.H.; Franco, P.; Reinacher, P.; Mader, I.; Staszewski, O.; Lassmann, S.; Grau, S.; Schnell, O. Surgical management of lower-grade glioma in the spotlight of the 2016 WHO classification system. J. Neurooncol. 2019, 141, 223–233. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Xie, Z.; Zang, Y.; Zhang, S.; Gu, D.; Zhou, M.; Gevaert, O.; Wei, J.; Li, C.; Chen, H.; et al. Non-invasive genotype prediction of chromosome 1p/19q co-deletion by development and validation of an MRI-based radiomics signature in lower-grade gliomas. J. Neurooncol. 2018, 140, 297–306. [Google Scholar] [CrossRef]
- Matsui, Y.; Maruyama, T.; Nitta, M.; Saito, T.; Tsuzuki, S.; Tamura, M.; Kusuda, K.; Fukuya, Y.; Asano, H.; Kawamata, T.; et al. Prediction of lower-grade glioma molecular subtypes using deep learning. J. Neuro-Oncol. 2020, 146, 321–327. [Google Scholar] [CrossRef]
- Zhou, H.; Chang, K.; Bai, H.X.; Xiao, B.; Su, C.; Bi, W.L.; Zhang, P.J.; Senders, J.T.; Vallières, M.; Kavouridis, V.K.; et al. Machine learning reveals multimodal MRI patterns predictive of isocitrate dehydrogenase and 1p/19q status in diffuse low-and high-grade gliomas. J. Neurooncol. 2019, 142, 299–307. [Google Scholar] [CrossRef]
- Akkus, Z.; Ali, I.; Sedlář, J.; Agrawal, J.P.; Parney, I.F.; Giannini, C.; Erickson, B.J. Predicting deletion of chromosomal arms 1p/19q in low-grade gliomas from MR images using machine intelligence. J. Digit. Imaging 2017. [Google Scholar] [CrossRef] [Green Version]
- Kang, Y.; Choi, S.H.; Kim, Y.J.; Kim, K.G.; Sohn, C.H.; Kim, J.H.; Yun, T.J.; Chang, K.H. Gliomas: Histogram analysis of apparent diffusion coefficient maps with standard-or high-b-value diffusion-weighted MR imaging—Correlation with tumor grade. Radiology 2011, 261, 882–890. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.; Shi, Z.; Lian, Y.; Li, Z.; Liu, T.; Gao, Y.; Wang, Y.; Chen, L.; Mao, Y. Noninvasive IDH1 mutation estimation based on a quantitative radiomics approach for grade II glioma. Eur. Radiol. 2017, 27, 3509–3522. [Google Scholar] [CrossRef]
- Van der Voort, S.R.; Incekara, F.; Wijnenga, M.M.; Kapas, G.; Gardeniers, M.; Schouten, J.W.; Starmans, M.P.; Tewarie, R.N.; Lycklama, G.J.; French, P.J.; et al. Predicting the 1p/19q Codeletion Status of Presumed Low-Grade Glioma with an Externally Validated Machine Learning Algorithm. Clin. Cancer Res. 2019, 25, 7455–7462. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Tian, Q.; Wang, L.; Liu, Y.; Li, B.; Liang, Z.; Gao, P.; Zheng, K.; Zhao, B.; Lu, H. Radiomics strategy for molecular subtype stratification of lower-grade glioma: Detecting IDH and TP53 mutations based on multimodal MRI. J. Magn. Reson. Imaging 2018, 48, 916–926. [Google Scholar] [CrossRef] [PubMed]
- Mehmood, A.; Maqsood, M.; Bashir, M.; Shuyuan, Y. A Deep Siamese Convolution Neural Network for Multi-Class Classification of Alzheimer Disease. Brain Sci. 2020, 10, 84. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taheri Gorji, H.; Kaabouch, N. A Deep Learning approach for Diagnosis of Mild Cognitive Impairment Based on MRI Images. Brain Sci. 2019, 9, 217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nadeem, M.W.; Ghamdi, M.A.A.; Hussain, M.; Khan, M.A.; Khan, K.M.; Almotiri, S.H.; Butt, S.A. Brain tumor analysis empowered with deep learning: A review, taxonomy, and future challenges. Brain Sci. 2020, 10, 118. [Google Scholar] [CrossRef] [Green Version]
- Liang, S.; Zhang, R.; Liang, D.; Song, T.; Ai, T.; Xia, C.; Xia, L.; Wang, Y. Multimodal 3D DenseNet for IDH genotype prediction in gliomas. Genes 2018, 9, 382. [Google Scholar] [CrossRef] [Green Version]
- Martinez-Murcia, F.J.; Ortiz, A.; Gorriz, J.M.; Ramirez, J.; Castillo-Barnes, D. Studying the manifold structure of Alzheimer’s Disease: A deep learning approach using convolutional autoencoders. IEEE J. Biomed. Health Inform. 2019, 24, 17–26. [Google Scholar] [CrossRef]
- Kohlbrenner, M.; Hofmann, R.; Ahmmed, S.; Kashef, Y. Pre-Training Cnns Using Convolutional Autoencoders. 2017. Available online: https://www.ni.tu-berlin.de/fileadmin/fg215/teaching/nnproject/cnn_pre_trainin_paper.pdf (accessed on 12 July 2020).
- Wagner, R.; Thom, M.; Schweiger, R.; Palm, G.; Rothermel, A. Learning convolutional neural networks from few samples. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–7. [Google Scholar]
- Wiens, J.; Guttag, J.; Horvitz, E. A study in transfer learning: Leveraging data from multiple hospitals to enhance hospital-specific predictions. J. Am. Med. Inform. Assoc. 2014, 21, 699–706. [Google Scholar] [CrossRef] [Green Version]
- Lee, G.; Rubinfeld, I.; Syed, Z. Adapting surgical models to individual hospitals using transfer learning. In Proceedings of the IEEE 12th International Conference on Data Mining Workshops, Brussels, Belgium, 10 December 2012. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. 2014. Available online: https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf (accessed on 12 July 2020).
- Costa, P.; Galdran, A.; Meyer, M.I.; Abràmoff, M.D.; Niemeijer, M.; Mendonça, A.M.; Campilho, A. Towards adversarial retinal image synthesis. arXiv 2017, arXiv:1701.08974. [Google Scholar]
- Ben-Cohen, A.; Klang, E.; Raskin, S.P.; Amitai, M.M.; Greenspan, H. Virtual PET images from CT data using deep convolutional networks: Initial results. arXiv 2017, arXiv:1707.09585. [Google Scholar]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. Segan: Adversarial network with multi-scale l 1 loss for medical image segmentation. arXiv 2018, arXiv:1706.01805. [Google Scholar] [CrossRef] [Green Version]
- Welander, P.; Karlsson, S.; Eklund, A. Generative adversarial networks for image-to-image translation on multi-contrast MR images-A comparison of CycleGAN and UNIT. arXiv 2018, arXiv:1806.07777. [Google Scholar]
- Yoon, J.; Jordon, J.; van der Schaar, M. RadialGAN: Leveraging multiple datasets to improve target-specific predictive models using Generative Adversarial Networks. arXiv 2018, arXiv:1802.06403. [Google Scholar]
- Nyúl, L.G.; Udupa, J.K.; Zhang, X. New variants of a method of MRI scale standardization. IEEE Trans. Med. Imaging 2000, 19, 143–150. [Google Scholar] [CrossRef] [PubMed]
- Collewet, G.; Strzelecki, M.; Mariette, F. Influence of MRI acquisition protocols and image intensity normalization methods on texture classification. Magn. Reson. Imaging 2004, 22, 81–91. [Google Scholar] [CrossRef] [PubMed]
- Jäger, F.; Deuerling-Zheng, Y.; Frericks, B.; Wacker, F.; Hornegger, J. A New Method for MRI Intensity Standardization with Application to Lesion Detection in the Brain. 2006. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.638.8032&rep=rep1&type=pdf (accessed on 12 July 2020).
- Dzyubachyk, O.; Staring, M.; Reijnierse, M.; Lelieveldt, B.P.; van der Geest, R.J. Inter-station intensity standardization for whole-body MR data. Magn. Reson. Med. 2017, 77, 422–433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, Y.; Liu, Y.; Wang, Y.; Shi, Z.; Yu, J. a universal intensity standardization method based on a many-to-one weak-paired cycle generative adversarial network for magnetic resonance images. IEEE Trans. Med. Imaging 2019, 38, 2059–2069. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ali, M.B.; Gu, I.Y.H.; Jakola, A.S. Multi-stream Convolutional Autoencoder and 2D Generative Adversarial Network for Glioma Classification. In Proceedings of the 18th International Conference, CAIP 2019, Salerno, Italy, 3–5 September 2019. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. arXiv 2016, arXiv:1604.04382. [Google Scholar]
- Diba, A.; Sharma, V.; Van Gool, L. Deep temporal linear encoding networks. arXiv 2017, arXiv:1611.06678. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 12 July 2020).
- Jenkinson, M.; Beckmann, C.F.; Behrens, T.E.; Woolrich, M.W.; Smith, S.M. FSL. NeuroImage 2012. [Google Scholar] [CrossRef] [Green Version]
- Avants, B.B.; Tustison, N.J.; Song, G.; Cook, P.A.; Klein, A.; Gee, J.C. A reproducible evaluation of ANTs similarity metric performance in brain image registration. Neuroimage 2011, 54, 2033–2044. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Erickson, B.; Akkus, Z.; Sedlar, J.; Kofiatis, P. Data from LGG-1p19qDeletion. Cancer Imaging Arch. 2017. Available online: https://wiki.cancerimagingarchive.net/display/Public/LGG-1p19qDeletion (accessed on 12 July 2020).
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.; Freymann, J.; Farahani, K.; Davatzikos, C. Segmentation labels and radiomic features for the pre-operative scans of the TCGA-LGG collection. Cancer Imaging Arch. 2017, 286. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Filters | Output Size |
|---|---|---|
| Discriminator D: | ||
| Conv-1 + stride 2 + BN + LeakyReLU(0.2) | ||
| Conv-2 + stride 2 + BN + LeakyReLU(0.2) | ||
| Conv-3 + stride 2 + BN + LeakyReLU(0.2) | ||
| Conv-4 + stride 2 + BN + LeakyReLU(0.2) | ||
| Dense + sigmoid | - | 1 |
| Generator G: | ||
| Dense + ReLU + reshape | 2,662,144 | |
| ConvTranspose-1 + stride 2 + BN + ReLU | ||
| ConvTranspose-2 + stride 2 + BN + ReLU | ||
| ConvTranspose-3 + stride 2 + BN + ReLU | ||
| Conv-5 + Tanh |
| Layer | Filters | Output Size |
|---|---|---|
| Encoder layer: | ||
| Conv-1 + BN + ReLU | ||
| Conv-2 + Maxpool + BN + ReLU | ||
| Conv-3 + Maxpool + BN + ReLU | ||
| Conv-4 + BN + ReLU | ||
| Conv-5 + Maxpool + BN + ReLU | ||
| Conv-6 + BN + ReLU | ||
| Decoder layer: | ||
| Upsample + Conv-7 + BN + ReLU | ||
| Conv-8 + BN + ReLU | ||
| Upsample + Conv-9 + BN + ReLU | ||
| Upsample + Conv-10 + BN + ReLU | ||
| Conv-11 + BN + ReLU |
| Dataset | #3D Scans in T1ce | #3D Scans in FLAIR | # of Patients Selected |
|---|---|---|---|
| USA | 85 | 79 | 79 |
| France | 82 | 84 | 82 |
| Case-A: 1p/19q Codeletion Information | ||||
| USA Dataset | France Dataset | # Patients | # 2D Slices T1ce/FLAIR | |
| 1p/19q codeletion | 44 | 33 | 77 | |
| 1p/19q non-codeletion | 35 | 49 | 84 | |
| Case-B: IDH genotype information | ||||
| IDH mutation | 68 | 69 | 137 | |
| IDH wild-type | 11 | 13 | 24 | |
| Case-A: 1p/19q Codeletion/Non-Codeletion | |||||||
| Run | Dataset | T1ce | FLAIR | 2-Modality | 2-Modality | 2-Modality | 2-Modality |
| Acc. (%) | Acc.(%) | Acc. (%) | Precision (%) | Recall(%) | F1-Score(%) | ||
| 1 | 69.37 | 72.19 | 75.16 | 70.67 | 80.33 | 75.19 | |
| 2 | USA | 70.63 | 71.56 | 76.09 | 72.48 | 79.00 | 75.60 |
| 3 | + | 69.69 | 73.44 | 73.44 | 70.57 | 74.33 | 72.39 |
| 4 | France | 69.69 | 72.81 | 75.47 | 74.07 | 73.33 | 77.00 |
| 5 | 70.00 | 73.13 | 73.91 | 71.95 | 72.67 | 72.31 | |
| Mean ± | 69.87 ± 0.43 | 72.63 ± 0.67 | 74.81 ± 0.98 | 71.95 ± 1.29 | 75.93 ± 3.12 | 74.50 ± 1.85 | |
| Case-B: IDH mutation/wild-type | |||||||
| 1 | 71.67 | 75.24 | 81.43 | 79.81 | 95.18 | 86.82 | |
| 2 | USA | 73.33 | 78.57 | 85.71 | 86.21 | 92.59 | 89.28 |
| 3 | + | 69.05 | 74.76 | 78.57 | 76.47 | 96.29 | 85.24 |
| 4 | France | 75.00 | 71.90 | 75.71 | 78.66 | 95.56 | 86.28 |
| 5 | 73.81 | 72.62 | 84.52 | 88.68 | 87.03 | 87.85 | |
| Mean ± | 72.57 ± 2.06 | 74.62 ± 2.34 | 81.19 ± 3.70 | 81.96 ± 4.67 | 93.33 ± 3.39 | 87.09 ± 1.38 | |
| Case Study | Method | # of Patients | Test Accuracy (%) |
|---|---|---|---|
| Case-A | Zhou [7] | 281 | 71.60 |
| Han [5] | 277 | 72.00 | |
| Van der Voort [11] | 413 | 72.30 | |
| Matsui[6] | 217 | 75.10 | |
| Proposed Scheme | 161 | 74.81 | |
| Case-B | Yu [10] | 140 | 80.00 |
| Zhang [12] | 103 | 80.00 | |
| Matsui[6] | 217 | 82.90 | |
| Proposed Scheme | 161 | 81.19 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, M.B.; Gu, I.Y.-H.; Berger, M.S.; Pallud, J.; Southwell, D.; Widhalm, G.; Roux, A.; Vecchio, T.G.; Jakola, A.S. Domain Mapping and Deep Learning from Multiple MRI Clinical Datasets for Prediction of Molecular Subtypes in Low Grade Gliomas. Brain Sci. 2020, 10, 463. https://doi.org/10.3390/brainsci10070463
Ali MB, Gu IY-H, Berger MS, Pallud J, Southwell D, Widhalm G, Roux A, Vecchio TG, Jakola AS. Domain Mapping and Deep Learning from Multiple MRI Clinical Datasets for Prediction of Molecular Subtypes in Low Grade Gliomas. Brain Sciences. 2020; 10(7):463. https://doi.org/10.3390/brainsci10070463
Chicago/Turabian StyleAli, Muhaddisa Barat, Irene Yu-Hua Gu, Mitchel S. Berger, Johan Pallud, Derek Southwell, Georg Widhalm, Alexandre Roux, Tomás Gomez Vecchio, and Asgeir Store Jakola. 2020. "Domain Mapping and Deep Learning from Multiple MRI Clinical Datasets for Prediction of Molecular Subtypes in Low Grade Gliomas" Brain Sciences 10, no. 7: 463. https://doi.org/10.3390/brainsci10070463
APA StyleAli, M. B., Gu, I. Y. -H., Berger, M. S., Pallud, J., Southwell, D., Widhalm, G., Roux, A., Vecchio, T. G., & Jakola, A. S. (2020). Domain Mapping and Deep Learning from Multiple MRI Clinical Datasets for Prediction of Molecular Subtypes in Low Grade Gliomas. Brain Sciences, 10(7), 463. https://doi.org/10.3390/brainsci10070463