
Interpretable Machine Learning Models for Three-Way Classification of Cognitive Workload Levels for Eye-Tracking Features


Abstract
:1. Introduction
- Performing a multiclass subject-independent classification of cognitive workload levels,
- Examine both classification on the complete feature set and with the application of interpretable machine learning models for feature selection,
- Carrying out a deeper analysis of the features related to the classification of particular levels of cognitive workload.
2. Related Work
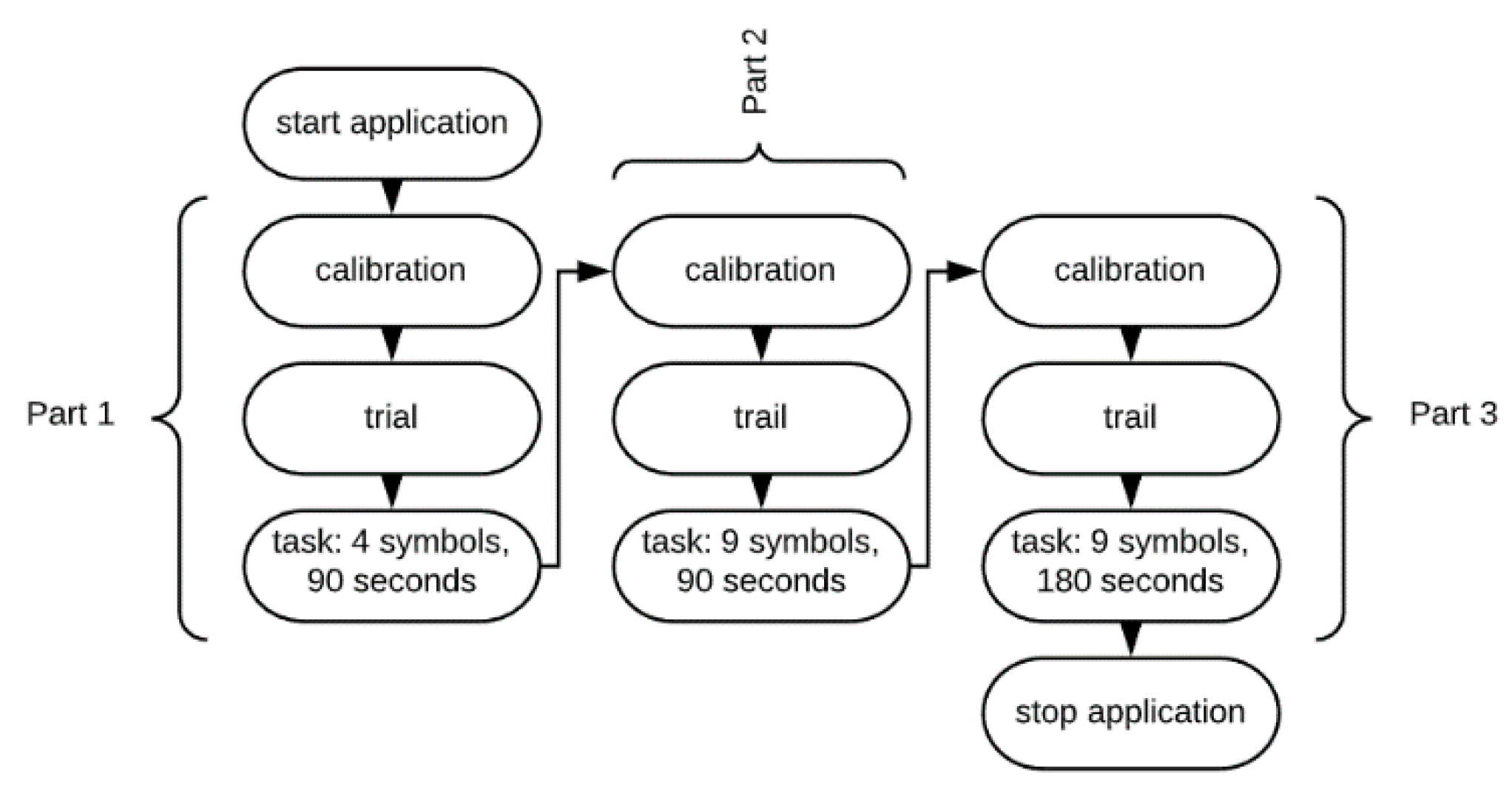
3. The Research Procedure
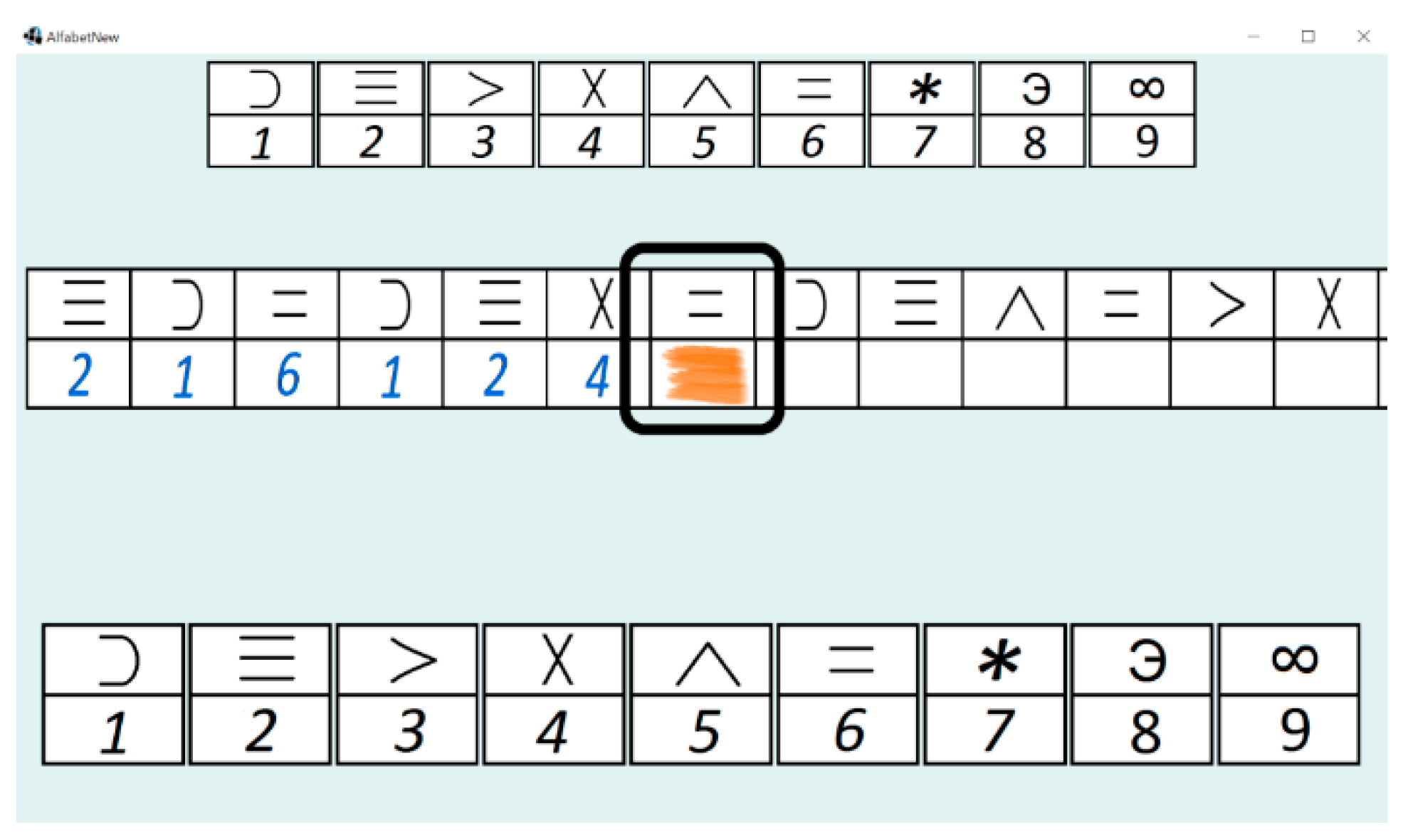
3.1. The Computer Application
- Part 1—low-level cognitive workload: four different symbols to choose from, 90 s test length;
- Part 2—medium-level cognitive workload: nine different symbols to choose from, 90 s test length;
- Part 3—hard-level cognitive workload: nine different symbols to choose from, 180 s test length.
3.2. Setup and Equipment
- Blinks derived as zero data embedded in two saccadic events.
- Pupillary response understood as pupil size. The Tobii Studio applies the dark pupil eye-tracking method.
3.3. Experiment
3.4. Dataset
- Fixation-related features: fixation number (total number of fixations), mean duration of fixation, standard deviation of fixation duration, maximum fixation duration, minimum fixation duration.
- Saccade-related features: saccade number (total number of saccades), mean duration of saccades, mean amplitude of saccades, standard deviation of saccades amplitude, maximum saccade amplitude, minimum saccade amplitude.
- Blink-related features: blink number (total number of blinks), mean of blink duration.
- Pupillary response features: mean of left pupil diameter, mean of right pupil diameter, standard deviation of left pupil diameter, standard deviation of right pupil diameter.
- DSST test results-related features: number of errors (total number of errors), mean response time, response number (total number of responses).
4. Methods Applied
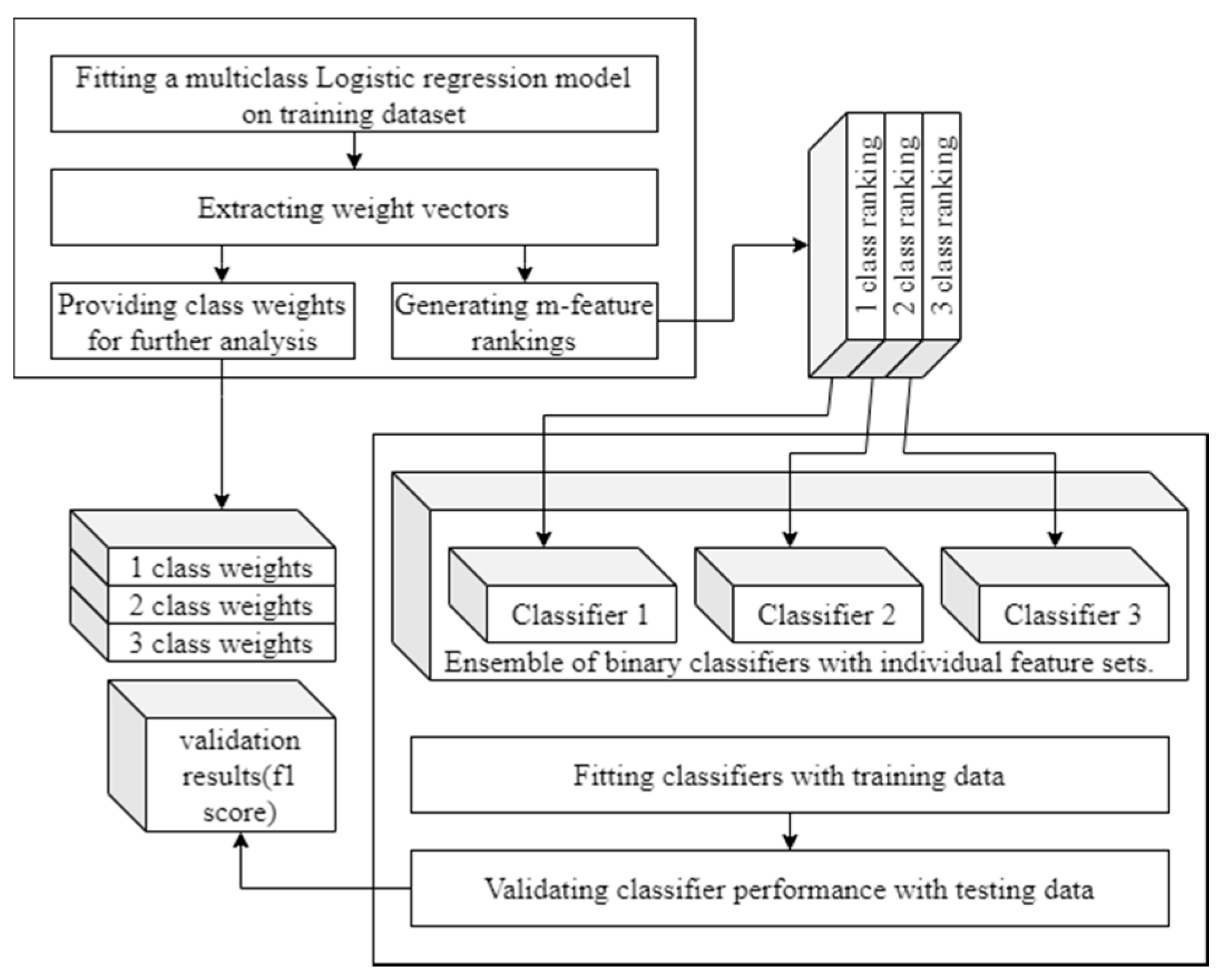
4.1. Data Processing
- Data acquisition
- Data synchronisation
- Feature extraction
- Feature normalisation
- Feature selection
- Training and testing classification models.
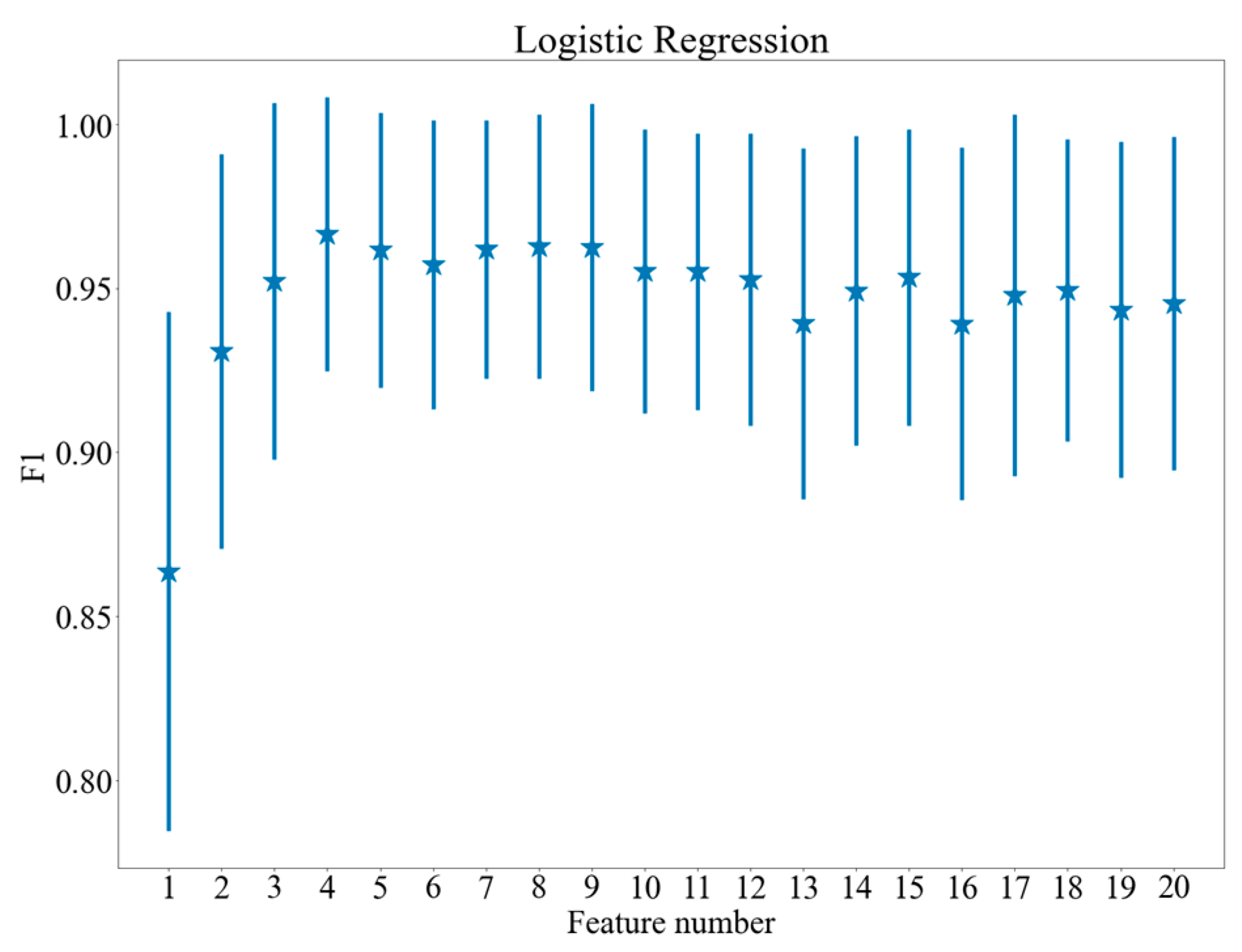
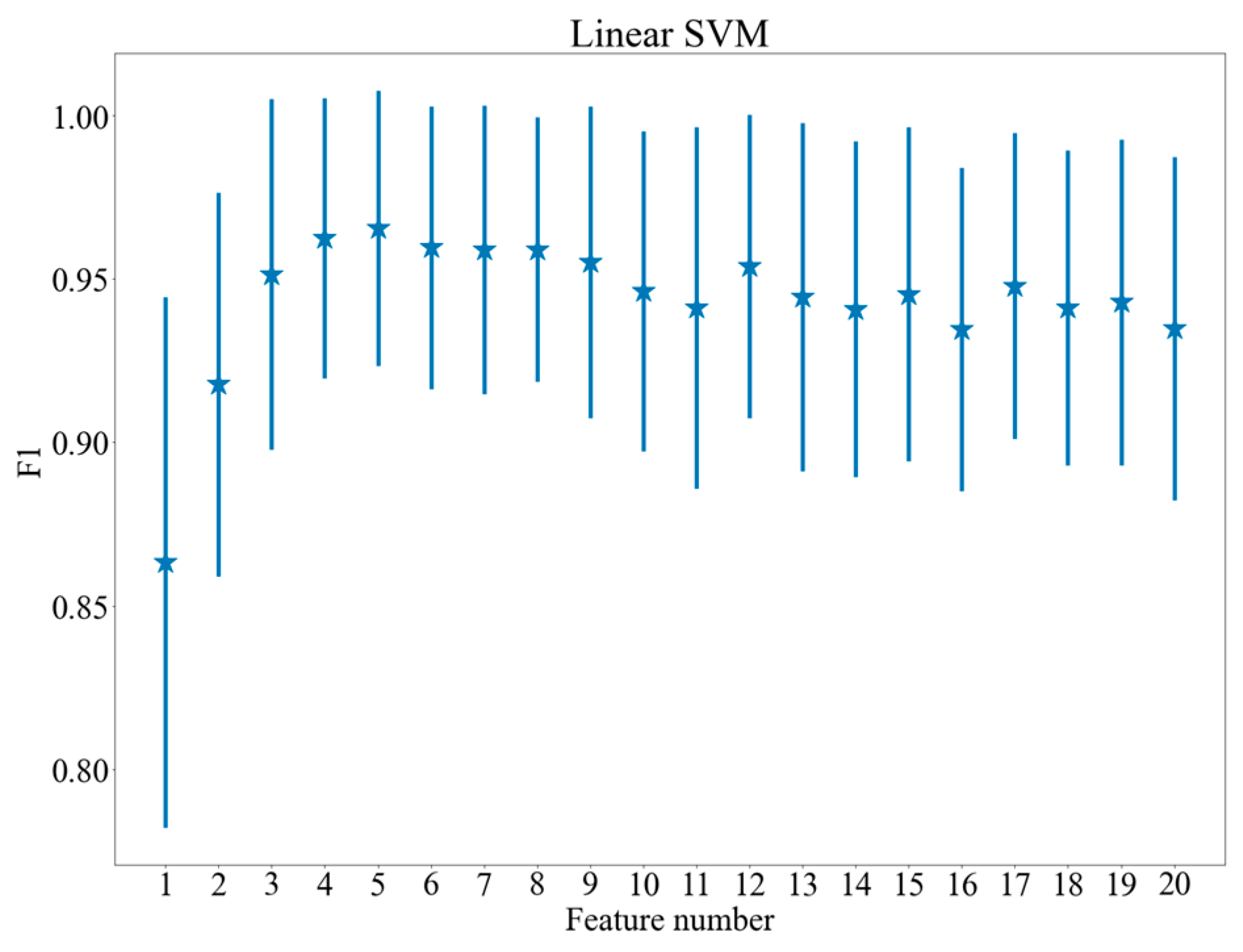
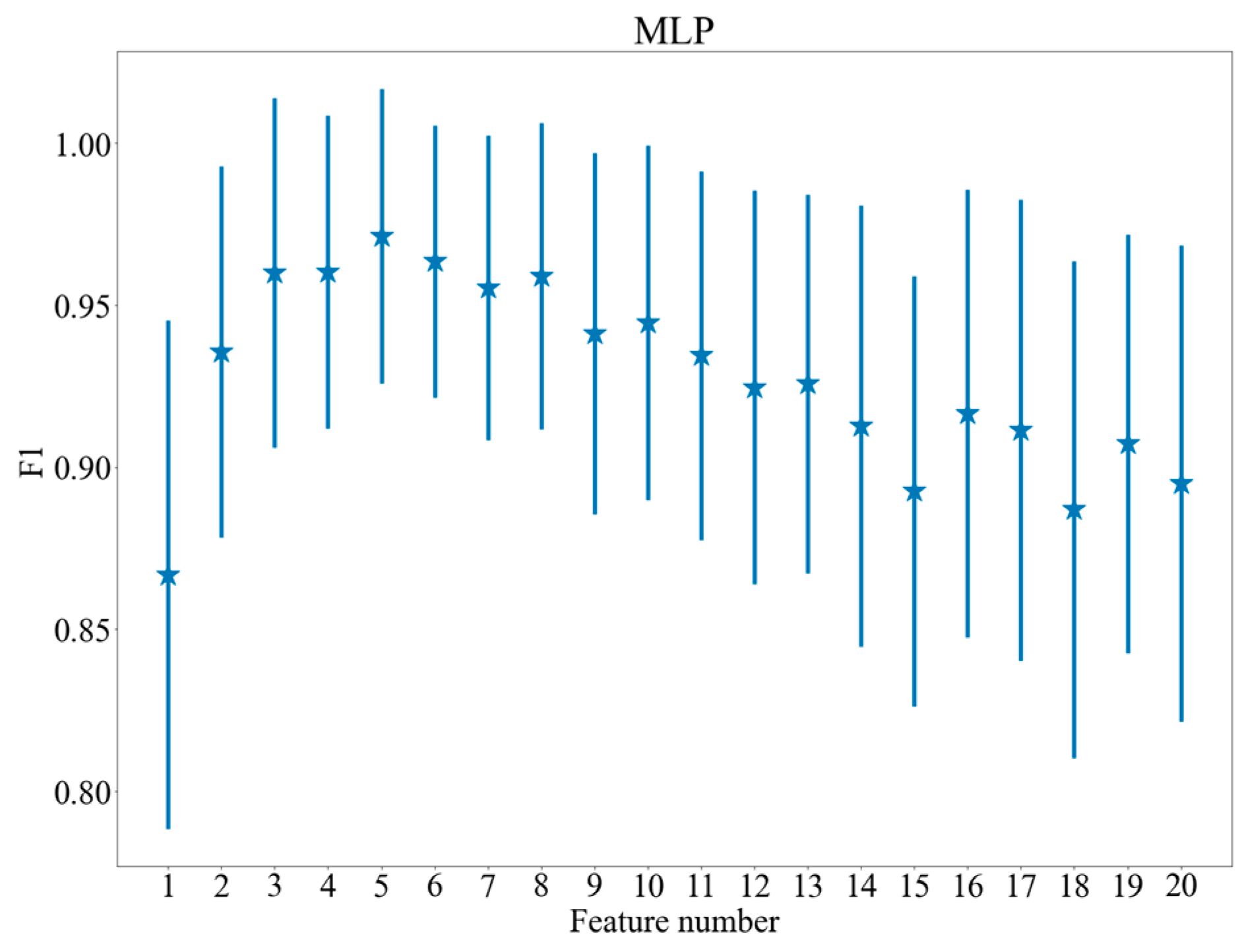
4.2. Feature Selection
- is the probability of the fact that the classified sample belongs to the positive class,
- is the order number of the feature,
- , is the weight of the -th feature; the lower the absolute value, the less important the feature, and conversely, higher absolute values of the weights correspond to the features producing great influence on the model’s decisions,
- is the bias,
4.3. Classification
- Class 1—observations with low level of cognitive workload
- Class 2—observations with moderate level of cognitive workload
- Class 3—observations with high level of cognitive workload
- kNN—nearest neighbour number: 5
- Random Forest—tree number: 100
- MLP—two hidden layers: 32 and 16 neurons; optimiser: Adam; learning rate: 0.0001; activation function: relu (rectifier linear unit)
4.4. Statistical Analysis
5. Results
5.1. Classification Results
5.2. Statistical Results
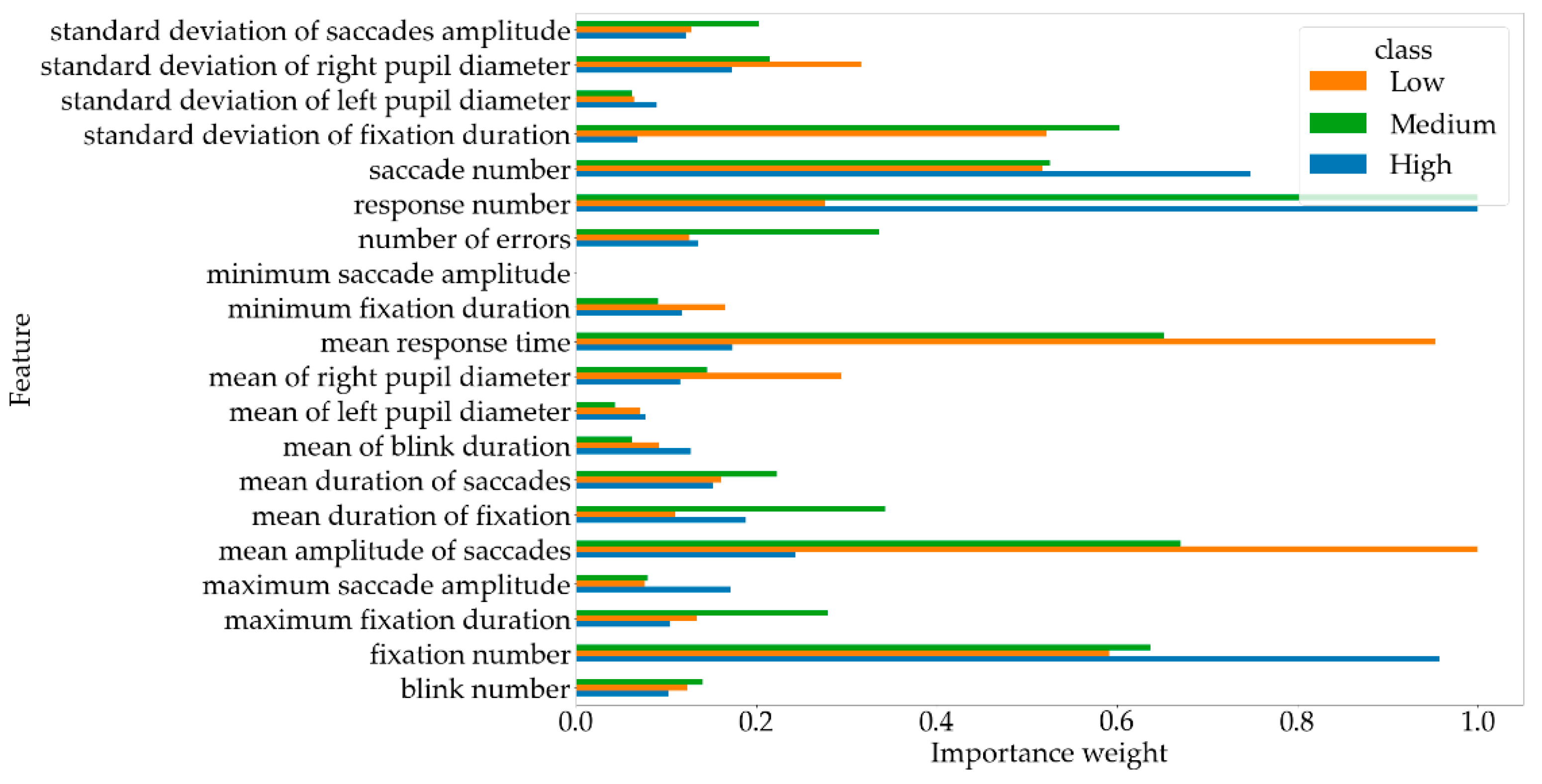
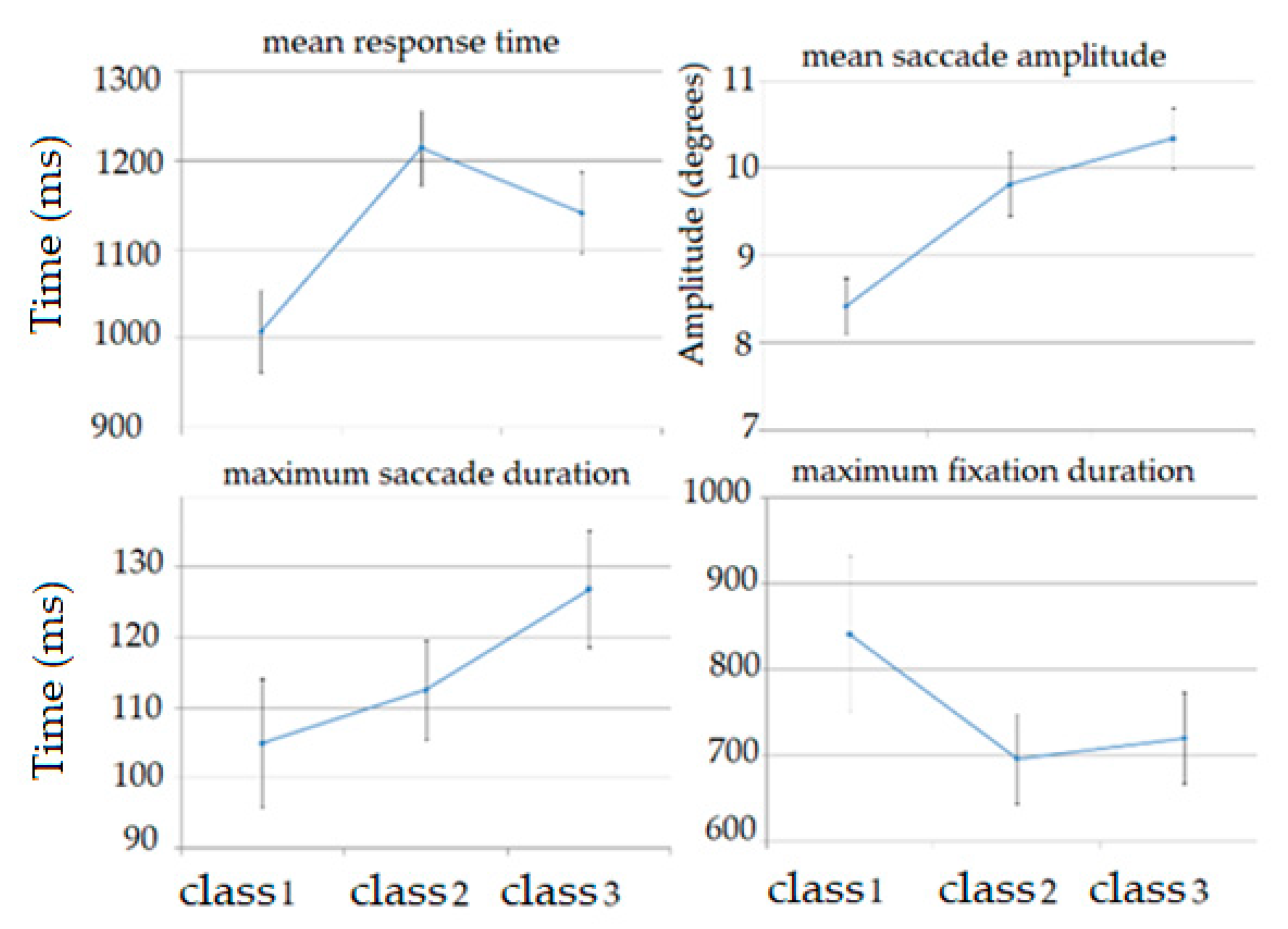
5.3. Cognitive Factors Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gevins, A.; Smith, M.E.; McEvoy, L.; Yu, D. High-resolution EEG mapping of cortical activation related to working memory: Effects of task difficulty, type of processing, and practice. Cereb. Cortex 1997, 7, 374–385. [Google Scholar] [CrossRef] [Green Version]
- Qi, P.; Ru, H.; Sun, Y.; Zhang, X.; Zhou, T.; Tian, Y.; Thakor, N.; Bezerianos, A.; Li, J.; Sun, Y. Neural Mechanisms of Mental Fatigue Revisited: New Insights from the Brain Connectome. Engineering 2019, 5, 276–286. [Google Scholar] [CrossRef]
- Gavelin, H.M.; Neely, A.S.; Dunås, T.; Eskilsson, T.; Järvholm, L.S.; Boraxbekk, C.-J. Mental fatigue in stress-related exhaustion disorder: Structural brain correlates, clinical characteristics and relations with cognitive functioning. NeuroImage Clin. 2020, 27, 102337. [Google Scholar] [CrossRef]
- Grier, R.A.; Warm, J.S.; Dember, W.N.; Matthews, G.; Galinsky, T.L.; Szalma, J.L.; Parasuraman, R. The Vigilance Decrement Reflects Limitations in Effortful Attention, Not Mindlessness. Hum. Factors J. Hum. Factors Ergon. Soc. 2003, 45, 349–359. [Google Scholar] [CrossRef] [Green Version]
- Van der Linden, D.; Eling, P. Mental fatigue disturbs local processing more than global processing. Psychol. Research 2006, 70, 395–402. [Google Scholar] [CrossRef] [PubMed]
- Mackworth, N.H. The Breakdown of Vigilance during Prolonged Visual Search. Q. J. Exp. Psychol. 1948, 1, 6–21. [Google Scholar] [CrossRef]
- Marquart, G.; Cabrall, C.; de Winter, J. Review of eye-related measures of drivers’ mental workload. Proc. Manuf. 2015, 3, 2854–2861. [Google Scholar] [CrossRef] [Green Version]
- Miller, S. Workload Measures. National Advanced Driving Simulator; University of Iowa Press: Iowa City, IA, USA, 2001. [Google Scholar]
- Thummar, S.; Kalariya, V. A real time driver fatigue system based on eye gaze detection. Int. J. Eng. Res. Gen. Sci. 2015, 3, 105–110. [Google Scholar]
- Wobrock, D.; Frey, J.; Graeff, D.; De La Rivière, J.-B.; Castet, J.; Lotte, F. Continuous Mental Effort Evaluation During 3D Object Manipulation Tasks Based on Brain and Physiological Signals. In Proceedings of the IFIP Conference on Human-Computer Interaction, Bamberg, Germany, 14–18 September 2015; Springer Nature: Cham, Switzerland, 2015; Volume 9296, pp. 472–487. [Google Scholar]
- Son, J.; Oh, H.; Park, M. Identification of driver cognitive workload using support vector machines with driving performance, physiology and eye movement in a driving simulator. Int. J. Precis. Eng. Manuf. 2013, 14, 1321–1327. [Google Scholar] [CrossRef]
- Matthews, G.; Reinerman-Jones, L.E.; Barber, D.J.; Abich IV, J. The psychometrics of mental workload: Multiple measures are sensitive but divergent. Hum. Factors 2015, 57, 125–143. [Google Scholar] [CrossRef] [PubMed]
- Henderson, J.M.; Shinkareva, S.V.; Wang, J.; Luke, S.G.; Olejarczyk, J. Predicting Cognitive State from Eye Movements. PLoS ONE 2013, 8, e64937. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benfatto, M.N.; Öqvist Seimyr, G.; Ygge, J.; Pansell, T.; Rydberg, A.; Jacobson, C. Screening for Dyslexia Using Eye Tracking during Reading. PLoS ONE 2016, 11, e0165508. [Google Scholar] [CrossRef]
- Mark, J.; Curtin, A.; Kraft, A.; Sands, T.; Casebeer, W.D.; Ziegler, M.; Ayaz, H. Eye Tracking-Based Workload and Performance Assessment for Skill Acquisition. In Advances in Intelligent Systems and Computing; Springer Nature: Cham, Switzerland, 2019; Volume 953, pp. 129–141. [Google Scholar]
- Coco, M.I.; Keller, F. Classification of visual and linguistic tasks using eye-movement features. J. Vis. 2014, 14, 11. [Google Scholar] [CrossRef]
- Lobo, J.L.; Del Ser, J.; De Simone, F.; Presta, R.; Collina, S.; Moravek, Z. Cognitive workload classification using eye-tracking and EEG data. In Proceedings of the International Conference on Human-Computer Interaction in Aerospace, ACM 2016, Paris, France, 14–16 September 2016; pp. 1–8. [Google Scholar]
- Chen, J.; Wang, H.; Wang, Q.; Hua, C. Exploring the fatigue affecting electroencephalography based functional brain networks during real driving in young males. J. Neuropsychol. 2019, 129, 200–211. [Google Scholar] [CrossRef] [PubMed]
- Nuamah, J.K.; Seong, Y. Support vector machine (SVM) classification of cognitive tasks based on electroencephalography (EEG) engagement index. Br. Comput. Interf. 2017, 5, 1–12. [Google Scholar] [CrossRef]
- Chen, L.-L.; Zhao, Y.; Ye, P.-F.; Zhang, J.; Zou, J.-Z. Detecting driving stress in physiological signals based on multimodal feature analysis and kernel classifiers. Expert Syst. Appl. 2017, 85, 279–291. [Google Scholar] [CrossRef]
- Khushaba, R.N.; Kodagoda, S.; Lal, S.; Dissanayake, G. Driver Drowsiness Classification Using Fuzzy Wavelet-Packet-Based Feature-Extraction Algorithm. IEEE Trans. Biomed. Eng. 2011, 58, 121–131. [Google Scholar] [CrossRef] [Green Version]
- Atasoy, H.; Yildirim, E. Classification of Verbal and Quantitative Mental Tasks Using Phase Locking Values between EEG Signals. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 383–390. [Google Scholar] [CrossRef]
- Zarjam, P.; Epps, J.; Lovell, N.H. Beyond Subjective Self-Rating: EEG Signal Classification of Cognitive Workload. IEEE Trans. Auton. Ment. Dev. 2015, 7, 301–310. [Google Scholar] [CrossRef]
- Magnusdottir, E.H.; Johannsdottir, K.R.; Bean, C.; Olafsson, B.; Gudnason, J. Cognitive workload classification using cardi-ovascular measures and dynamic features. In Proceedings of the 8th IEEE International Conference on Cognitive Infocommunications (CogInfo-Com), Debrecen, Hungary, 11–14 September 2017; pp. 351–356. [Google Scholar]
- Spüler, M.; Walter, C.; Rosenstiel, W.; Gerjets, P.; Moeller, K.; Klein, E. EEG-based prediction of cognitive workload induced by arithmetic: A step towards online adaptation in numerical learning. ZDM 2016, 48, 267–278. [Google Scholar] [CrossRef]
- Laine, T.; Bauer, K.; Lanning, J.; Russell, C.; Wilson, G. Selection of input features across subjects for classifying crewmember workload using artificial neural networks. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2002, 32, 691–704. [Google Scholar] [CrossRef]
- Wang, Z.; Hope, R.M.; Wang, Z.; Ji, Z.; Gray, W.D. Cross-subject workload classification with a hierarchical Bayes model. NeuroImage 2012, 59, 64–69. [Google Scholar] [CrossRef]
- Walter, C.; Wolter, P.; Rosenstiel, W.; Bogdan, M.; Spüler, M. Towards cross-subject workload prediction. In Proceedings of the 6th International Brain-Computer Interface Conference, Graz, Austria, 16–19 September 2014. [Google Scholar]
- Fazli, S.; Mehnert, J.; Steinbrink, J.; Curio, G.; Villringer, A.; Müller, K.-R.; Blankertz, B. Enhanced performance by a hybrid NIRS–EEG brain computer interface. NeuroImage 2012, 59, 519–529. [Google Scholar] [CrossRef]
- Thodoroff, P.; Pineau, J.; Lim, A. Learning robust features using deep learning for automatic seizure detection. In Proceedings of the Machine Learning for Healthcare Conference, Los Angeles, CA, USA, 19–20 August 2016; pp. 178–190. [Google Scholar]
- Boake, C. From the Binet–Simon to the Wechsler–Bellevue: Tracing the History of Intelligence Testing. J. Clin. Exp. Neuropsychol. 2002, 24, 383–405. [Google Scholar] [CrossRef]
- Sicard, V.; Moore, R.D.; Ellemberg, D. Sensitivity of the Cogstate Test Battery for Detecting Prolonged Cognitive Alterations Stemming From Sport-Related Concussions. Clin. J. Sport Med. 2019, 29, 62–68. [Google Scholar] [CrossRef]
- Cook, N.; Kim, J.U.; Pasha, Y.; Crossey, M.M.; Schembri, A.J.; Harel, B.T.; Kimhofer, T.; Taylor-Robinson, S.D. A pilot evaluation of a computer-based psychometric test battery designed to detect impairment in patients with cirrhosis. Int. J. Gen. Med. 2017, 10, 281–289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jaeger, J. Digit symbol substitution test: The case for sensitivity over specificity in neuropsychological testing. J. Clin. Psychopharm. 2018, 38, 513. [Google Scholar] [CrossRef]
- McKendrick, R.; Feest, B.; Harwood, A.; Falcone, B. Theories and Methods for Labeling Cognitive Workload: Classification and Transfer Learning. Front. Hum. Neurosci. 2019, 13, 295. [Google Scholar] [CrossRef] [PubMed]
- Işbilir, E.; Çakır, M.P.; Acartürk, C.; Tekerek, A. Şimşek Towards a Multimodal Model of Cognitive Workload Through Synchronous Optical Brain Imaging and Eye Tracking Measures. Front. Hum. Neurosci. 2019, 13, 375. [Google Scholar] [CrossRef] [PubMed]
- Ziegler, M.D.; Kraft, A.; Krein, M.; Lo, L.-C.; Hatfield, B.; Casebeer, W.; Russell, B. Sensing and Assessing Cognitive Workload Across Multiple Tasks. In Proceedings of the International Conference on Augmented Cognition, Toronto, ON, Canada, 17–22 July 2016; Springer Nature: Chan, Switzerland, 2016; pp. 440–450. [Google Scholar]
- Almogbel, M.A.; Dang, A.H.; Kameyama, W. EEG-signals based cognitive workload detection of vehicle driver using deep learning. In Proceedings of the 2018 20th International Conference on Advanced Communication Technology (ICACT), Chuncheon, Korea, 11–14 February 2018; pp. 256–259. [Google Scholar]
- Almogbel, M.A.; Dang, A.H.; Kameyama, W. Cognitive Workload Detection from Raw EEG-Signals of Vehicle Driver using Deep Learning. In Proceedings of the 2019 21st International Conference on Advanced Communication Technology (ICACT), PyeongChang, Korea, 17–20 February 2019; pp. 1–6. [Google Scholar]
- Hefron, R.; Borghetti, B.J.; Kabban, C.M.S.; Christensen, J.C.; Estepp, J. Cross-Participant EEG-Based Assessment of Cognitive Workload Using Multi-Path Convolutional Recurrent Neural Networks. Sensors 2018, 18, 1339. [Google Scholar] [CrossRef] [Green Version]
- Zarjam, P.; Epps, J.; Chen, F.; Lovell, N.H. Estimating cognitive workload using wavelet entropy-based features during an arithmetic task. Comput. Biol. Med. 2013, 43, 2186–2195. [Google Scholar] [CrossRef]
- Appel, T.; Scharinger, C.; Gerjets, P.; Kasneci, E. Cross-subject workload classification using pupil-related measures. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, Warsaw, Poland, 14–17 June 2018; pp. 1–8. [Google Scholar]
- Hajinoroozi, M.; Mao, Z.; Jung, T.P.; Lin, C.T.; Huang, Y. EEG-based prediction of driver’s cognitive performance by deep convolutional neural network. Signal Proc. Imag. Commun. 2016, 47, 549–555. [Google Scholar] [CrossRef]
- Bozkir, E.; Geisler, D.; Kasneci, E. Person Independent, Privacy Preserving, and Real Time Assessment of Cognitive Load using Eye Tracking in a Virtual Reality Setup. In Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, 23–27 March 2019; pp. 1834–1837. [Google Scholar]
- Fridman, L.; Reimer, B.; Mehler, B.; Freeman, W.T. Cognitive Load Estimation in the Wild. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; p. 652. [Google Scholar]
- Yamada, Y.; Kobayashi, M. Detecting mental fatigue from eye-tracking data gathered while watching video: Evaluation in younger and older adults. Artif. Intell. Med. 2018, 91, 39–48. [Google Scholar] [CrossRef]
- Jimenez-Guarneros, M.; Gómez-Gil, P. Cross-subject classification of cognitive loads using a recurrent-residual deep network. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Appel, T.; Sevcenko, N.; Wortha, F.; Tsarava, K.; Moeller, K.; Ninaus, M.; Kasneci, E.; Gerjets, P. Predicting Cognitive Load in an Emergency Simulation Based on Behavioral and Physiological Measures. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, Jiangsu, China, 14–18 October 2019; pp. 154–163. [Google Scholar]
- Jimnez-Guarneros, M.; Gomez-Gil, P. Custom Domain Adaptation: A new method for cross-subject, EEG-based cognitive load recognition. IEEE Sign. Proc. Let. 2020, 27, 750–754. [Google Scholar] [CrossRef]
- Chen, S.; Epps, J.; Ruiz, N.; Chen, F. Eye activity as a measure of human mental effort in HCI. In Proceedings of the 16th international conference on Intelligent user interfaces, Palo Alto, CA, USA, 13–16 February 2011; pp. 315–318. [Google Scholar]
- Tokuda, S.; Obinata, G.; Palmer, E.; Chaparro, A. Estimation of mental workload using saccadic eye movements in a free-viewing task. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 4523–4529. [Google Scholar]
- Tobii AB. Tobii Studio User’s Manual. Available online: https://www.tobiipro.com/siteassets/tobii-pro/user-manuals/tobii-pro-studio-user-manual.pdf (accessed on 7 October 2020).
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychol. Bull. 1998, 124, 372–422. [Google Scholar] [CrossRef] [PubMed]
- Hessels, R.S.; Niehorster, D.C.; Nyström, M.; Andersson, R.; Hooge, I.T.C. Is the eye-movement field confused about fixations and saccades? A survey among 124 researchers. R. Soc. Open Sci. 2018, 5, 180502. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salvucci, D.D.; Goldberg, J.H. Identifying fixations and saccades in eye-tracking protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 71–78. [Google Scholar]
- Barbato, G.; Ficca, G.; Muscettola, G.; Fichele, M.; Beatrice, M.; Rinaldi, F. Diurnal variation in spontaneous eye-blink rate. Psychiatry Res. 2000, 93, 145–151. [Google Scholar] [CrossRef]
- Shishido, E.; Ogawa, S.; Miyata, S.; Yamamoto, M.; Inada, T.; Ozaki, N. Application of eye trackers for understanding mental disorders: Cases for schizophrenia and autism spectrum disorder. Neuropsychopharmacol. Rep. 2019, 39, 72–77. [Google Scholar] [CrossRef]
- Olsen, A.; Matos, R. Identifying parameter values for an I-VT fixation filter suitable for handling data sampled with various sampling frequencies. In Proceedings of the Symposium on Eye Tracking Research and Applications, Santa Barbara, CA, USA, 28–30 March 2012; p. 317. [Google Scholar]
- Kardan, O.; Berman, M.G.; Yourganov, G.; Schmidt, J.; Henderson, J.M. Classifying mental states from eye movements during scene viewing. J. Exp. Psychol. Hum. Percept. Perform. 2015, 41, 1502–1514. [Google Scholar] [CrossRef]
- Dowiasch, S.; Marx, S.; Einhäuser, W.; Bremmer, F. Effects of aging on eye movements in the real world. Front. Hum. Neurosci 2015, 9, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Mould, M.S.; Foster, D.H.; Amano, K.; Oakley, J.P. A simple nonparametric method for classifying eye fixations. Vis. Res. 2012, 57, 18–25. [Google Scholar] [CrossRef]
- Ryu, K.; Myung, R. Evaluation of mental workload with a combined measure based on physiological indices during a dual task of tracking and mental arithmetic. Int. J. Ind. Ergon. 2005, 35, 991–1009. [Google Scholar] [CrossRef]
- Rozado, D.; Duenser, A.; Howell, B. Improving the Performance of an EEG-Based Motor Imagery Brain Computer Interface Using Task Evoked Changes in Pupil Diameter. PLoS ONE 2015, 10, e0121262. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Partala, T.; Jokiniemi, M.; Surakka, V. Pupillary responses to emotionally provocative stimuli. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 123–129. [Google Scholar]
- Tuszyńska-Bogucka, W.; Kwiatkowski, B.; Chmielewska, M.; Dzieńkowski, M.; Kocki, W.; Pełka, J.; Przesmycka, N.; Bogucki, J.; Galkowski, D. The effects of interior design on wellness—Eye tracking analysis in determining emotional experience of architectural space. A survey on a group of volunteers from the Lublin Region, Eastern Poland. Ann. Agric. Environ. Med. 2020, 27, 113–122. [Google Scholar] [CrossRef]
- Mathôt, S.; Fabius, J.; Van Heusden, E.; Van Der Stigchel, S. Safe and sensible preprocessing and baseline correction of pupil-size data. Behav. Res. Methods 2018, 50, 94–106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Du, M.; Liu, N.; Hu, X. Techniques for interpretable machine learning. Commun. ACM 2019, 63, 68–77. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Number of Participants | Number of Cognitive Workload Levels | Classifier Model | Result | Approach (sd/si) | |
|---|---|---|---|---|---|---|
| [35] | 34 | 3 | difficulty split | Random forest | 0.51 (AUC) | si |
| Rash model | 0.81 (AUC) | |||||
| stress–strain model | 0.67 (AUC) | |||||
| [17] | 21 | 3, difficulty split | kNN, | 0.332 (F score) | si | |
| [36] | 14 | 2, difficulty split | LDA | 0.91 (ACC) | si | |
| [37] | 35 | 2, difficulty split | SVM | 0.52 (ACC) | si | |
| [38] | 1 (24 recordings) | 2, difficulty split | Convolutional deep neural networks | 0.95 (ACC) | sd | |
| [39] | 1 (24 h of recordings) | 2, difficulty split | Convolutional deep neural network | 0.934 (ACC) | sd | |
| 3, difficulty split | 0.976 (ACC) | |||||
| 6, difficulty split | 0.945 (ACC) | |||||
| [40] | 8 | 2 | Deep neural network | 0.868 (ACC) | si | |
| [41] | 12 | 7, difficulty split | Artificial Neural Network | 0.4–0.98 (ACC) | si | |
| [42] | 25 | 2, difficulty split | Extra Trees | 0.768 (ACC) | si | |
| 0.824 (ACC) | sd | |||||
| 3, difficulty split | 0.467 (ACC) | si | ||||
| 0.637 (ACC) | sd | |||||
| [43] | 37 | 2, difficulty split | Convolutional deep neural network | 0.767 (ACC) | si | |
| 0.861 (AUC) | sd | |||||
| [44] | 16 | 2, difficulty split | SVM | 0.81 (AUC) | si | |
| [45] | 92 | 3, difficulty split | Convolutional deep neural network 3D | 0.86 (AUC) | si | |
| [46] | 12 | 2, difficulty split | SVM | 0.92 (AUC) | si | |
| [47] | 13 | 4, difficulty split | Deep neural network | 0.907 (ACC) 0.896 (F score) | si | |
| [48] | 47 | 2, difficulty split | Forest of Extremely Randomised Trees | 0.72 (ACC) | si | |
| [49] | 13 | 4, difficulty split | Deep neural network | 0.98 (AUC) | si | |
| Classifier | Recall | Precision | F1 Score | Accuracy | ROC AUC |
|---|---|---|---|---|---|
| SVM linear | 0.94 ± 0.05 | 0.95 ± 0.05 | 0.94 ± 0.05 | 0.94 ± 0.05 | 0.99 ± 0.02 |
| SVM quadratic | 0.71 ± 0.10 | 0.77 ± 0.10 | 0.71 ± 0.10 | 0.71 ± 0.10 | 0.85 ± 0.07 |
| SVM cubic | 0.90 ± 0.07 | 0.92 ± 0.06 | 0.90 ± 0.07 | 0.90 ± 0.07 | 0.98 ± 0.03 |
| Log regression | 0.95 ± 0.05 | 0.96 ± 0.04 | 0.95 ± 0.05 | 0.95 ± 0.05 | 0.99 ± 0.02 |
| kNN | 0.88 ± 0.07 | 0.90 ± 0.06 | 0.88 ± 0.07 | 0.88 ± 0.07 | 0.96 ± 0.04 |
| Decision Tree | 0.89 ± 0.07 | 0.92 ± 0.05 | 0.89 ± 0.07 | 0.89 ± 0.07 | 0.95 ± 0.04 |
| Random Forest | 0.95 ± 0.05 | 0.96 ± 0.04 | 0.95 ± 0.05 | 0.95 ± 0.05 | 0.99 ± 0.02 |
| MLP | 0.90 ± 0.07 | 0.92 ± 0.06 | 0.90 ± 0.07 | 0.90 ± 0.07 | 0.98 ± 0.03 |
| Classifier | Recall | Precision | F1 Score | Accuracy | ROC AUC |
|---|---|---|---|---|---|
| SVM linear | 0.97 ± 0.04 (5) | 0.97 ± 0.03 (5) | 0.97 ± 0.04 (5) | 0.97 ± 0.04 (5) | 0.99 ± 0.02 (5) |
| SVM quadratic | 0.92 ± 0.06 (8) | 0.93 ± 0.05 (8) | 0.92 ± 0.07 (8) | 0.92 ± 0.06 (8) | 0.98 ± 0.03 (8) |
| SVM cubic | 0.94 ± 0.05 (8) | 0.96 ± 0.04 (8) | 0.94 ± 0.05 (8) | 0.94 ± 0.05 (8) | 0.99 ± 0.02 (6) |
| Log regression | 0.97 ± 0.04 (4) | 0.97 ± 0.04 (4) | 0.97 ± 0.04 (4) | 0.97 ± 0.04 (4) | 0.99 ± 0.01 (4) |
| kNN | 0.96 ± 0.05 (8) | 0.96 ± 0.04 (8) | 0.96 ± 0.05 (8) | 0.96 ± 0.05 (8) | 0.99 ± 0.02 (5) |
| Decision Tree | 0.90 ± 0.07 (5) | 0.92 ± 0.05 (5) | 0.90 ± 0.07 (5) | 0.90 ± 0.07 (5) | 0.95 ± 0.05 (8) |
| Random Forest | 0.95 ± 0.05 (7) | 0.96 ± 0.03 (7) | 0.95 ± 0.04 (7) | 0.95 ± 0.05 (7) | 0.99 ± 0.02 (7) |
| MLP | 0.97 ± 0.05 (5) | 0.98 ± 0.04 (5) | 0.97 ± 0.05 (5) | 0.97 ± 0.05 (5) | 0.99 ± 0.01 (5) |
| No. | Low | Medium | High |
|---|---|---|---|
| 1 | mean amplitude of saccades | mean response time | response number |
| 2 | mean response time | response number | fixation number |
| 3 | standard deviation of fixation duration | mean amplitude of saccades | saccade number |
| 4 | fixation number | standard deviation of fixation duration | mean amplitude of saccades |
| 5 | standard deviation of right pupil diameter | fixation number | mean duration of fixation |
| 6 | saccade number | number of errors | maximum saccade amplitude |
| 7 | number of errors | mean duration of fixation | mean response time |
| 8 | mean of right pupil diameter | saccade number | standard deviation of right pupil diameter |
| 9 | mean duration of fixation | mean duration of saccades | mean duration of saccades |
| 10 | mean duration of saccades | standard deviation of right pupil diameter | maximum fixation duration |
| 11 | mean of blink duration | mean of right pupil diameter | number of errors |
| 12 | minimum fixation duration | maximum fixation duration | mean of right pupil diameter |
| 13 | response number | maximum saccade amplitude | blink number |
| 14 | standard deviation of saccades amplitude | minimum fixation duration | mean of blink duration |
| 15 | mean of left pupil diameter | standard deviation of saccades amplitude | standard deviation of left pupil diameter |
| 16 | standard deviation of left pupil diameter | mean of left pupil diameter | standard deviation of fixation duration |
| 17 | maximum fixation duration | blink number | standard deviation of saccades amplitude |
| 18 | maximum saccade amplitude | mean of blink duration | minimum fixation duration |
| 19 | blink number | standard deviation of left pupil diameter | mean of left pupil diameter |
| 20 | minimum saccade amplitude | minimum saccade amplitude | minimum saccade amplitude |
| True | ||||
|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | ||
| Predicted | Class 1 | 5.62 | 0.38 | 0 |
| Class 2 | 0.23 | 5.77 | 0 | |
| Class 3 | 0 | 0.005 | 5.995 | |
| True | ||||
|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | ||
| Predicted | Class 1 | 5.64 | 0.36 | 0 |
| Class 2 | 0.22 | 5.78 | 0 | |
| Class 3 | 0 | 0.005 | 5.995 | |
| True | ||||
|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | ||
| Predicted | Class 1 | 5.64 | 0.36 | 0 |
| Class 2 | 0.16 | 5.84 | 0 | |
| Class 3 | 0 | 0 | 6 | |
| ANOVA | Post-hoc Test | |||
|---|---|---|---|---|
| Features | p-Value | p-Value Class 1–Class 2 | p-Value Class 1–Class 3 | p-Value Class 2–Class 3 |
| mean response time | <0.001 | <0.001 | <0.001 | 0.069 |
| standard deviation of fixation duration | 0.002 | 0.003 | 0.008 | 0.947 |
| maximum fixation duration | 0.009 | 0.011 | 0.04 | 0.877 |
| maximum saccade amplitude | 0.002 | 0.411 | 0.001 | 0.046 |
| mean saccade amplitude | <0.001 | <0.001 | <0.001 | 0.088 |
| standard deviation of left pupil diameter | 0.006 | 0.016 | 0.011 | 0.993 |
| standard deviation of right pupil diameter | 0.023 | 0.069 | 0.029 | 0.934 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaczorowska, M.; Plechawska-Wójcik, M.; Tokovarov, M. Interpretable Machine Learning Models for Three-Way Classification of Cognitive Workload Levels for Eye-Tracking Features. Brain Sci. 2021, 11, 210. https://doi.org/10.3390/brainsci11020210
Kaczorowska M, Plechawska-Wójcik M, Tokovarov M. Interpretable Machine Learning Models for Three-Way Classification of Cognitive Workload Levels for Eye-Tracking Features. Brain Sciences. 2021; 11(2):210. https://doi.org/10.3390/brainsci11020210
Chicago/Turabian StyleKaczorowska, Monika, Małgorzata Plechawska-Wójcik, and Mikhail Tokovarov. 2021. "Interpretable Machine Learning Models for Three-Way Classification of Cognitive Workload Levels for Eye-Tracking Features" Brain Sciences 11, no. 2: 210. https://doi.org/10.3390/brainsci11020210
APA StyleKaczorowska, M., Plechawska-Wójcik, M., & Tokovarov, M. (2021). Interpretable Machine Learning Models for Three-Way Classification of Cognitive Workload Levels for Eye-Tracking Features. Brain Sciences, 11(2), 210. https://doi.org/10.3390/brainsci11020210