
Isolating Action Prediction from Action Integration in the Perception of Social Interactions


Abstract
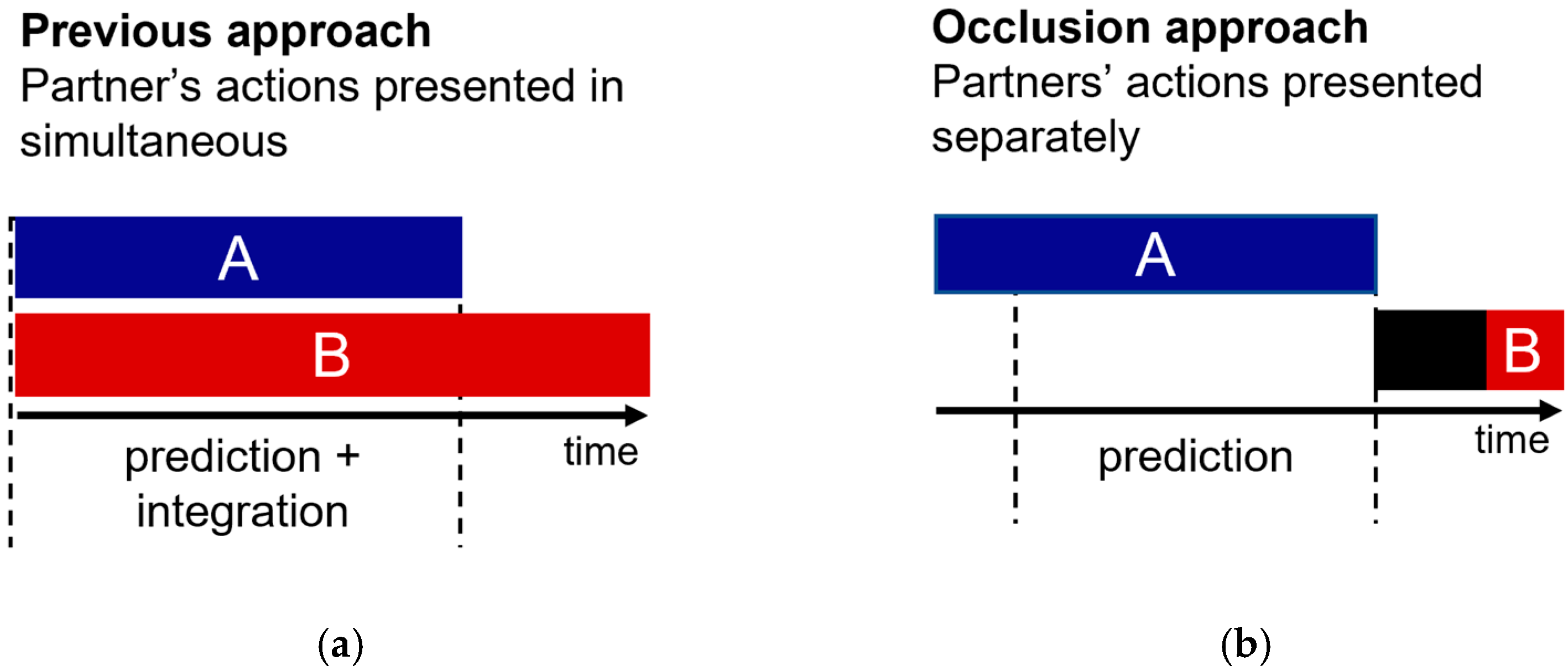
:1. Introduction
2. Methods
2.1. Participants
2.2. Stimuli
2.3. Experimental Design
2.4. Procedure
3. Analysis
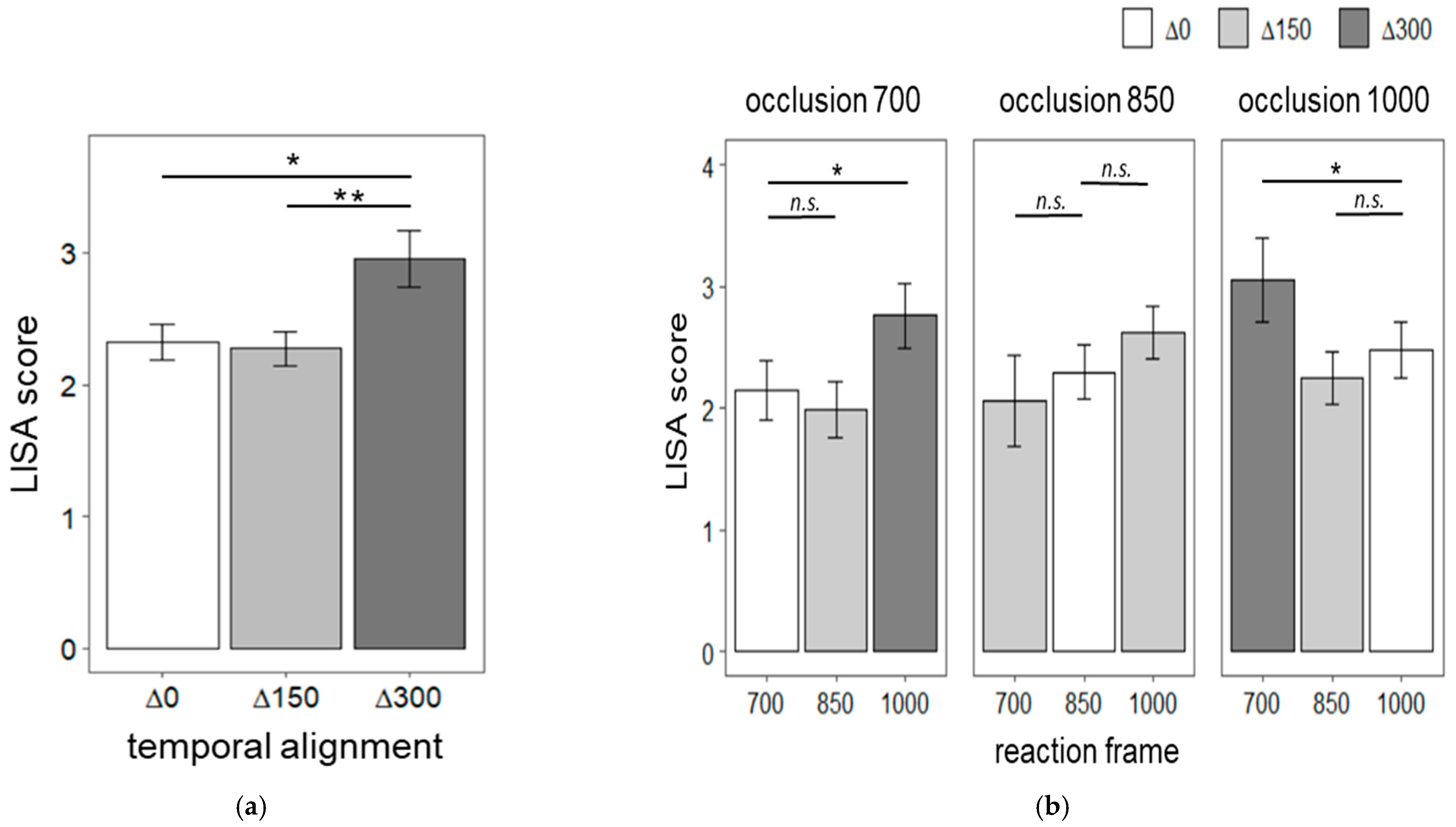
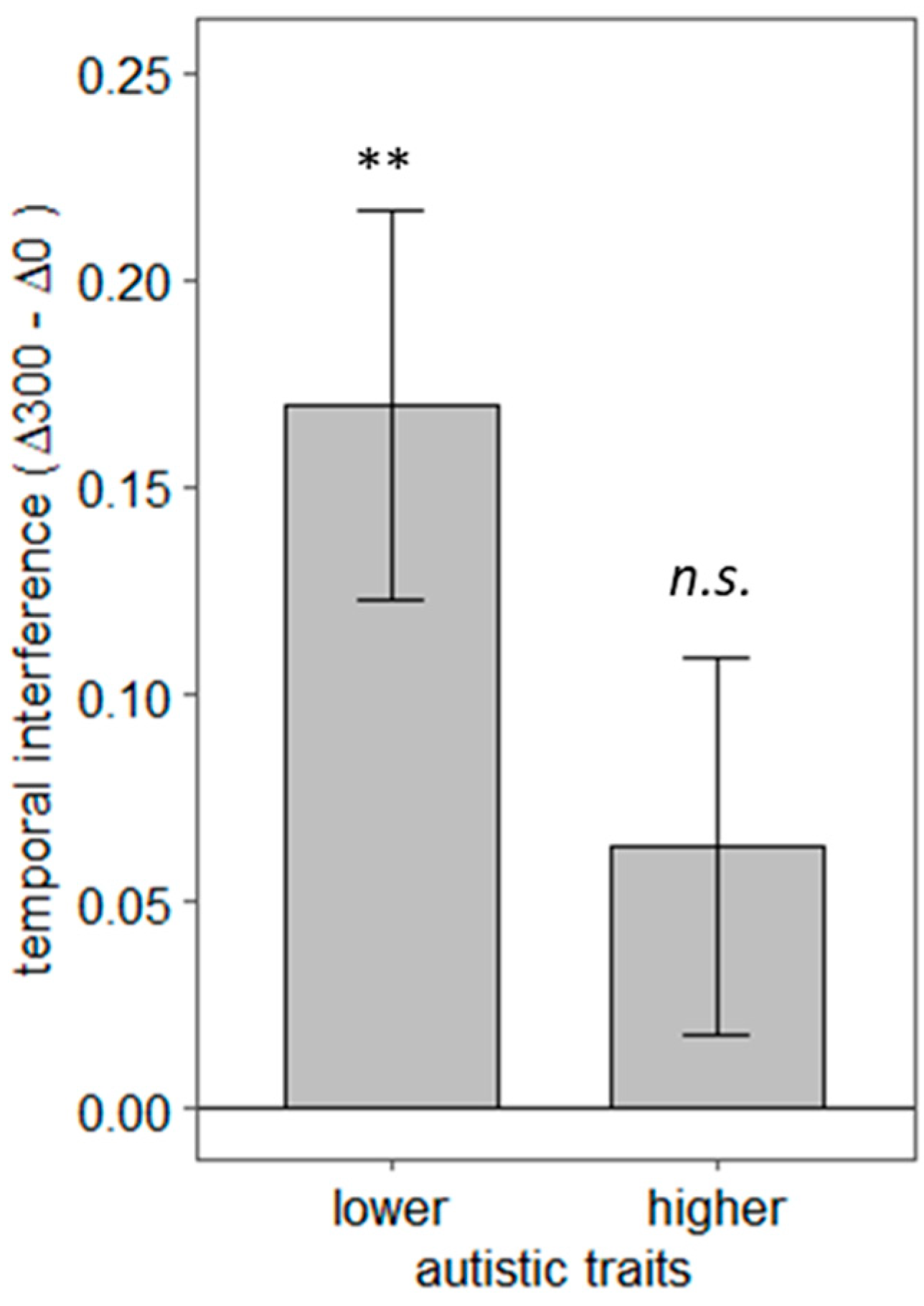
4. Results
5. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reaction (Red Actor) | ||
|---|---|---|
| Action (Blue Actor) | Congruent | Incongruent |
| Bends over in pain, looking for comfort | Reaches forward with the right hand | Leans forward while looking down |
| Extends hand for a handshake | Reaches forward with the right hand | Leans forward while looking down |
| Throws a ball towards someone’s feet | Leans forward while looking down | Reaches forward with the right hand |
| Points to direct someone’s attention | Leans forward while looking down | Reaches forward with the right hand |
| Reaction (Red Actor) | ||
|---|---|---|
| Action (Blue Actor) | Congruent | Incongruent |
| Reaches over for a hug | Opens both arms forward | Reaches forward with the right hand |
| Picks up an object and hands it over | Reaches forward with the right hand | Opens both arms forward |
| Expresses sadness | Opens both arms forward | Reaches forward with the right hand |
| Asks someone to indicate a choice betweentwo options | Reaches forward with the right hand | Opens both arms forward |
| Reaction (Red Actor) | ||
|---|---|---|
| Action (Blue Actor) | Congruent | Incongruent |
| Asks for help finding a lost object on the floor | Reaches down with the left hand | Jumps upwards in place |
| Throws over a ball | Jumps upwards in place | Reaches down with the left hand |
| Approaches to greet someone with a hi-5 | Jumps upwards in place | Reaches down with the left hand |
| Is seated on the floor and asks for help getting up | Reaches down with the left hand | Jumps upwards in place |
| Reaction (Red Actor) | ||
|---|---|---|
| Action (Blue Actor) | Congruent | Incongruent |
| Beckons someone over | Takes one step forward | Jumps upwards in place |
| Asks for help reaching something stored on a high location | Jumps upwards in place | Takes one step forward |
| Extends arm to offer an item | Takes one step forward | Jumps upwards in place |
| Convinces someone else to jump up | Jumps upwards in place | Takes one step forward |
| Reaction (Red Actor) | ||
|---|---|---|
| Action (Blue Actor) | Congruent | Incongruent |
| Asks someone to accept a gift | Opens both arms forward | Leans forward while looking down |
| Signals the need to see behind someone else | Leans forward while looking down | Opens both arms forward |
| Passes over a large object | Opens both arms forward | Leans forward while looking down |
| Bows over with respect | Leans forward while looking down | Opens both arms forward |
| Reaction (Red Actor) | ||
|---|---|---|
| Action (Blue Actor) | Congruent | Incongruent |
| Proposes by kneeling and offering a ring | Reaches down with the left hand | Takes one step forward |
| Performs a royal curtsy | Reaches down with the left hand | Takes one step forward |
| Expresses needing help | Takes one step forward | Reaches down with the left hand |
| Opens a door | Takes one step forward | Reaches down with the left hand |
References
- Pesquita, A.; Whitwell, R.L.; Enns, J.T. Predictive joint-action model: A hierarchical predictive approach to human cooperation. Psychon. Bull. Rev. 2017, 25, 1751–1769. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sebanz, N.; Knoblich, G. Prediction in Joint Action: What, When, and Where. Top. Cogn. Sci. 2009, 1, 353–367. [Google Scholar] [CrossRef] [PubMed]
- Manera, V.; Schouten, B.; Verfaillie, K.; Becchio, C. Time Will Show: Real Time Predictions during Interpersonal Action Perception. PLoS ONE 2013, 8, e54949. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- von der Lühe, T.; Manera, V.; Barisic, I.; Becchio, C.; Vogeley, K.; Schilbach, L. Interpersonal predictive coding, not action perception, is impaired in autism. Philos. Trans. R. Soc. B Biol. Sci. 2016, 371, 20150373. [Google Scholar] [CrossRef] [PubMed]
- Manera, V.; Becchio, C.; Schouten, B.; Bara, B.G.; Verfaillie, K. Communicative interactions improve visual detection of biological motion. PLoS ONE 2011, 6, e14594. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neri, P.; Luu, J.Y.; Levi, D.M. Meaningful interactions can enhance visual discrimination of human agents. Nat. Neurosci. 2006, 9, 1186–1192. [Google Scholar] [CrossRef]
- Manera, V.; Schouten, B.; Becchio, C.; Bara, B.G.; Verfaillie, K. Inferring intentions from biological motion: A stimulus set of point-light communicative interactions. Behav. Res. Methods 2010, 42, 168–178. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Manera, V.; Del Giudice, M.; Bara, B.G.; Verfaillie, K.; Becchio, C. The second-agent effect: Communicative gestures increase the likelihood of perceiving a second agent. PLoS ONE 2011, 6, e22650. [Google Scholar] [CrossRef] [Green Version]
- Abassi, E.; Papeo, L. The representation of two-body shapes in the human visual cortex. J. Neurosci. 2020, 40, 852–863. [Google Scholar] [CrossRef]
- Ding, X.; Gao, Z.; Shen, M. Two Equals One: Two Human Actions During Social Interaction Are Grouped as One Unit in Working Memory. Psychol. Sci. 2017, 28, 1311–1320. [Google Scholar] [CrossRef]
- Papeo, L. Twos in human visual perception. Cortex 2020, 132, 473–478. [Google Scholar] [CrossRef] [PubMed]
- Papeo, L.; Abassi, E. Seeing social events: The visual specialization for dyadic human-human interactions. J. Exp. Psychol. Hum. Percept. Perform. 2019, 45, 877–888. [Google Scholar] [CrossRef] [PubMed]
- Papeo, L.; Stein, T.; Soto-Faraco, S. The Two-Body Inversion Effect. Psychol. Sci. 2017, 28, 369–379. [Google Scholar] [CrossRef] [PubMed]
- Vestner, T.; Tipper, S.P.; Hartley, T.; Over, H.; Rueschemeyer, S.A. Bound together: Social binding leads to faster processing, spatial distortion, and enhanced memory of interacting partners. J. Exp. Psychol. Gen. 2019, 148, 1251–1268. [Google Scholar] [CrossRef] [PubMed]
- Pomerantz, J.R.; Portillo, M.C. Grouping and Emergent Features in Vision: Toward a Theory of Basic Gestalts. J. Exp. Psychol. Hum. Percept. Perform. 2011, 37, 1331–1349. [Google Scholar] [CrossRef] [PubMed]
- Wagemans, J.; Elder, J.H.; Kubovy, M.; Palmer, S.E.; Peterson, M.A.; Singh, M.; von der Heydt, R. A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure-ground organization. Psychol. Bull. 2012, 138, 1172–1217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Costa, T.L.; Wagemans, J. Gestalts at threshold could reveal Gestalts as predictions. Sci. Rep. 2021, 11, 18308. [Google Scholar] [CrossRef] [PubMed]
- Graf, M.; Reitzner, B.; Corves, C.; Casile, A.; Giese, M.; Prinz, W. Predicting point-light actions in real-time. Neuroimage 2007, 36, T22–T32. [Google Scholar] [CrossRef]
- Abassi, E.; Papeo, L. Behavioral and neural markers of social vision. bioRxiv 2021. [Google Scholar] [CrossRef]
- Baron-Cohen, S.; Wheelwright, S.; Skinner, R.; Martin, J.; Clubley, E. The Autism-Spectrum Quotient (AQ): Evidence from Asperger Syndrome/High-Functioning Autism, Males and Females, Scientists and Mathematicians. J. Autism Dev. Disord. 2001, 31, 5–17. [Google Scholar] [CrossRef]
- Vandierendonck, A. Further Tests of the Utility of Integrated Speed-Accuracy Measures in Task Switching. J. Cogn. 2018, 1, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liesefeld, H.R.; Janczyk, M. Combining speed and accuracy to control for speed-accuracy trade-offs(?). Behav. Res. Methods 2018, 51, 40–60. [Google Scholar] [CrossRef] [Green Version]
- Vandierendonck, A. A comparison of methods to combine speed and accuracy measures of performance: A rejoinder on the binning procedure. Behav. Res. Methods 2017, 49, 653–673. [Google Scholar] [CrossRef] [PubMed]
- Kwisthout, J.; Van Rooij, I. Free energy minimization and information gain: The devil is in the details. Cogn. Neurosci. 2015, 6, 216–218. [Google Scholar] [CrossRef] [PubMed]
- Jastorff, J.; Giese, M.A. Time-dependent hebbian rules for the learning of templates for visual motion recognition. In Dynamic Perception; Infix: Berlin, Germany, 2004; pp. 151–156. [Google Scholar]
- Wolpert, D.M.; Doya, K.; Kawato, M. A unifying computational framework for motor control and social interaction. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2003, 358, 593–602. [Google Scholar] [CrossRef] [Green Version]
- Isik, L.; Tacchetti, A.; Poggio, T.A. A fast, invariant representation for human action in the visual system. J. Neurophysiol. 2017, 119, 631–640. [Google Scholar] [CrossRef] [Green Version]
- Walbrin, J.; Downing, P.; Koldewyn, K. Neural responses to visually observed social interactions. Neuropsychologia 2018, 112, 31–39. [Google Scholar] [CrossRef]
- Walbrin, J.; Koldewyn, K. Dyadic interaction processing in the posterior temporal cortex. Neuroimage 2019, 198, 296. [Google Scholar] [CrossRef]
- Jellema, T.; Perrett, D.I. Cells in monkey STS responsive to articulated body motions and consequent static posture: A case of implied motion? Neuropsychologia 2003, 41, 1728–1737. [Google Scholar] [CrossRef]
- Sinha, P.; Kjelgaard, M.M.; Gandhi, T.K.; Tsourides, K.; Cardinaux, A.L.; Pantazis, D.; Diamond, S.P.; Held, R.M. Autism as a disorder of prediction. Proc. Natl. Acad. Sci. USA 2014, 111, 15220–15225. [Google Scholar] [CrossRef] [Green Version]
- De La Rosa, S.; Streuber, S.; Giese, M.; Bülthoff, H.H.; Curio, C. Putting actions in context: Visual action adaptation aftereffects are modulated by social contexts. PLoS ONE 2014, 9, e86502. [Google Scholar]
- Bellot, E.; Abassi, E.; Papeo, L. Moving Toward versus Away from Another: How Body Motion Direction Changes the Representation of Bodies and Actions in the Visual Cortex. Cereb. Cortex 2021, 31, 2670–2685. [Google Scholar] [CrossRef] [PubMed]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pesquita, A.; Bernardet, U.; Richards, B.E.; Jensen, O.; Shapiro, K. Isolating Action Prediction from Action Integration in the Perception of Social Interactions. Brain Sci. 2022, 12, 432. https://doi.org/10.3390/brainsci12040432
Pesquita A, Bernardet U, Richards BE, Jensen O, Shapiro K. Isolating Action Prediction from Action Integration in the Perception of Social Interactions. Brain Sciences. 2022; 12(4):432. https://doi.org/10.3390/brainsci12040432
Chicago/Turabian StylePesquita, Ana, Ulysses Bernardet, Bethany E. Richards, Ole Jensen, and Kimron Shapiro. 2022. "Isolating Action Prediction from Action Integration in the Perception of Social Interactions" Brain Sciences 12, no. 4: 432. https://doi.org/10.3390/brainsci12040432
APA StylePesquita, A., Bernardet, U., Richards, B. E., Jensen, O., & Shapiro, K. (2022). Isolating Action Prediction from Action Integration in the Perception of Social Interactions. Brain Sciences, 12(4), 432. https://doi.org/10.3390/brainsci12040432