
Sequence-to-Sequence Voice Reconstruction for Silent Speech in a Tonal Language

 , , ,
, , ,
Abstract
:1. Introduction
- 1.
- The paper proposes a Seq2Seq model, the first attempt to introduce a Seq2Seq model into the task. The model extracts duration information from the alignment between sEMG-based silent speech and vocal speech. The lengths of input sequences are adjusted to match the size of output sequences. Thus, our model can generate audios from neuromuscular activities using the Seq2Seq model.
- 2.
- The model in the paper generates audios from sEMG-based silent speech by considering both vocal sEMG reconstruction loss and toneme classification loss, and uses a state-of-the-art vocoder to achieve better quality and higher accuracy of the reconstructed audios.
- 3.
- We collect an sEMG-based silent speech dataset with Mandarin Chinese and conduct extensive experiments to demonstrate that the proposed model can decode neuromuscular signals in silent speech successfully in the tonal language.
2. Data Acquisition
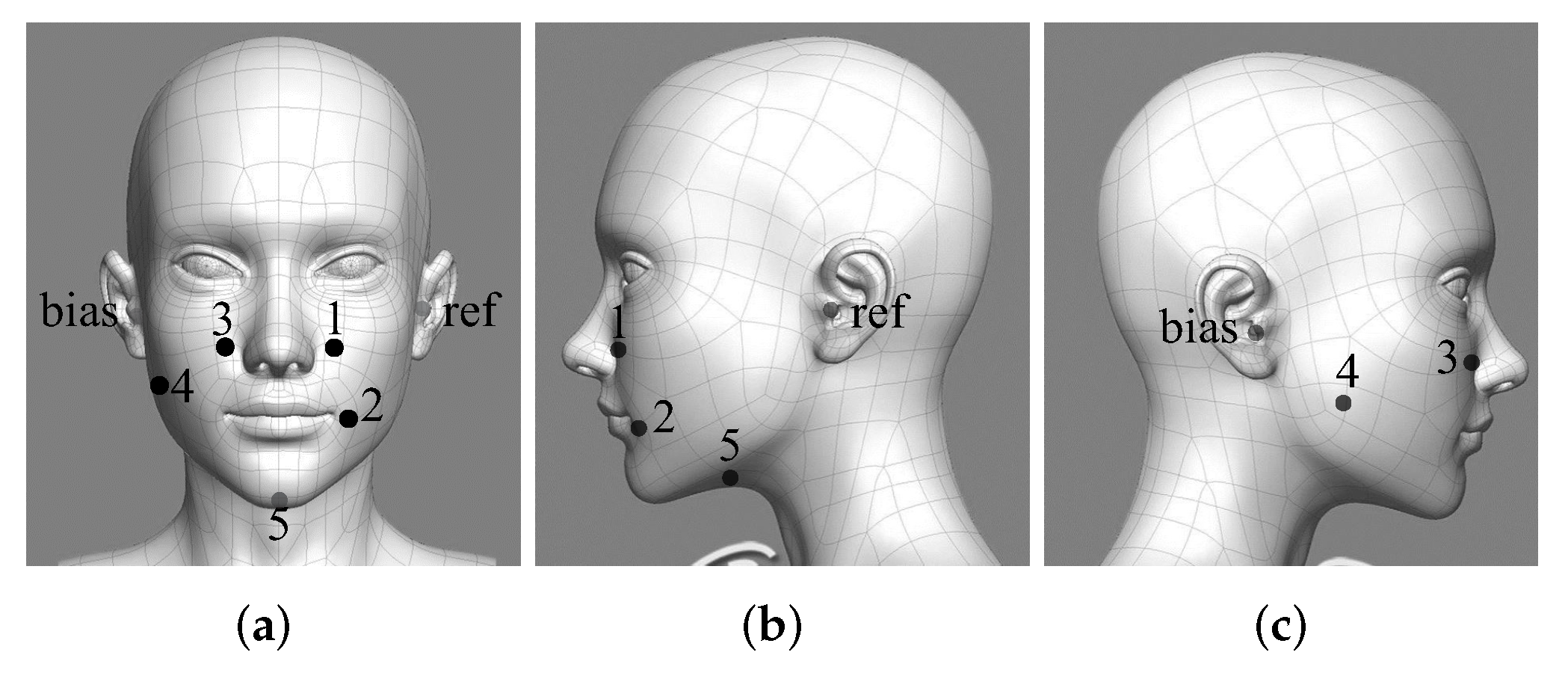
2.1. Recording Information
2.2. Dataset Information
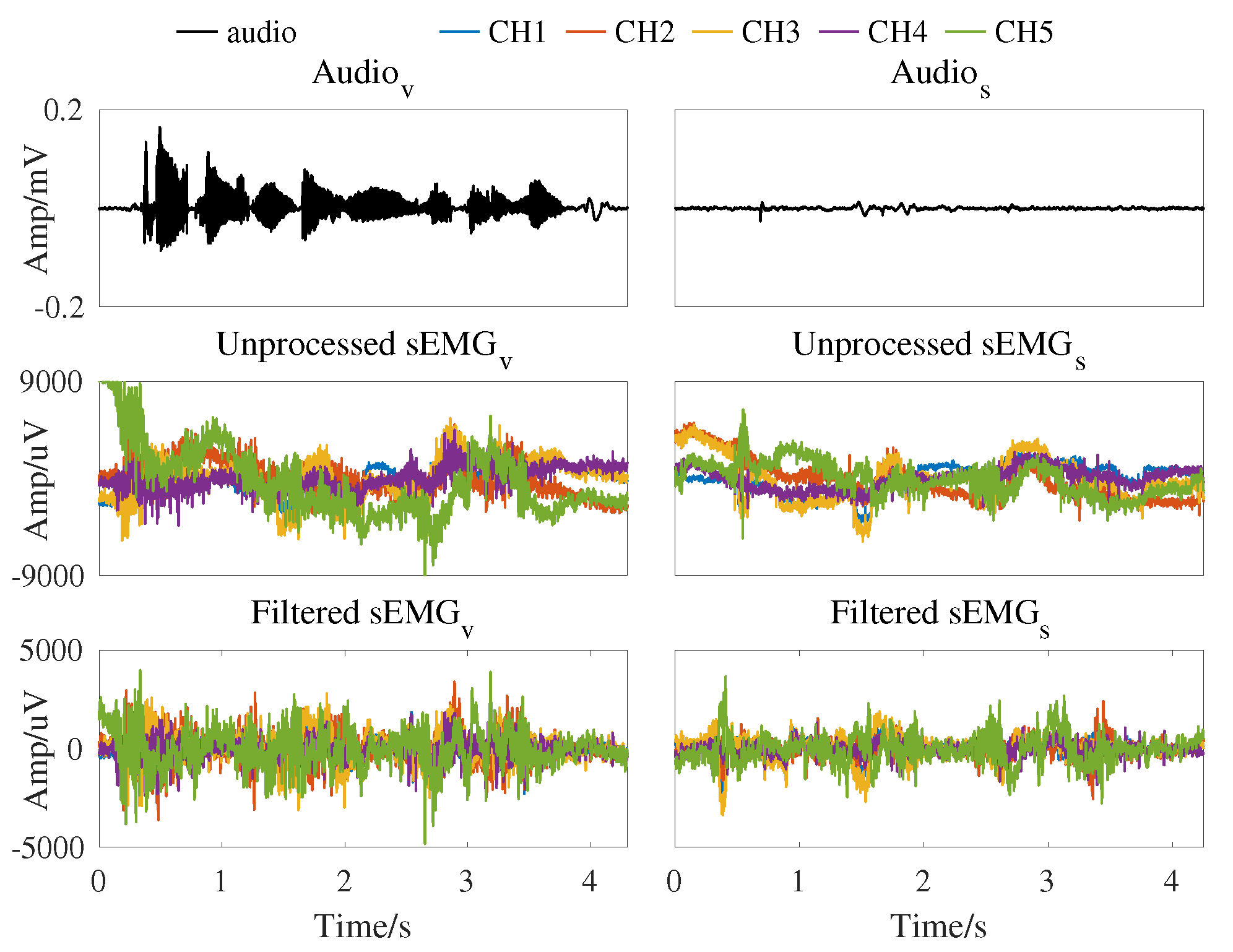
2.3. Signal Conditioning
2.4. Feature Extraction
3. The Proposed Methods
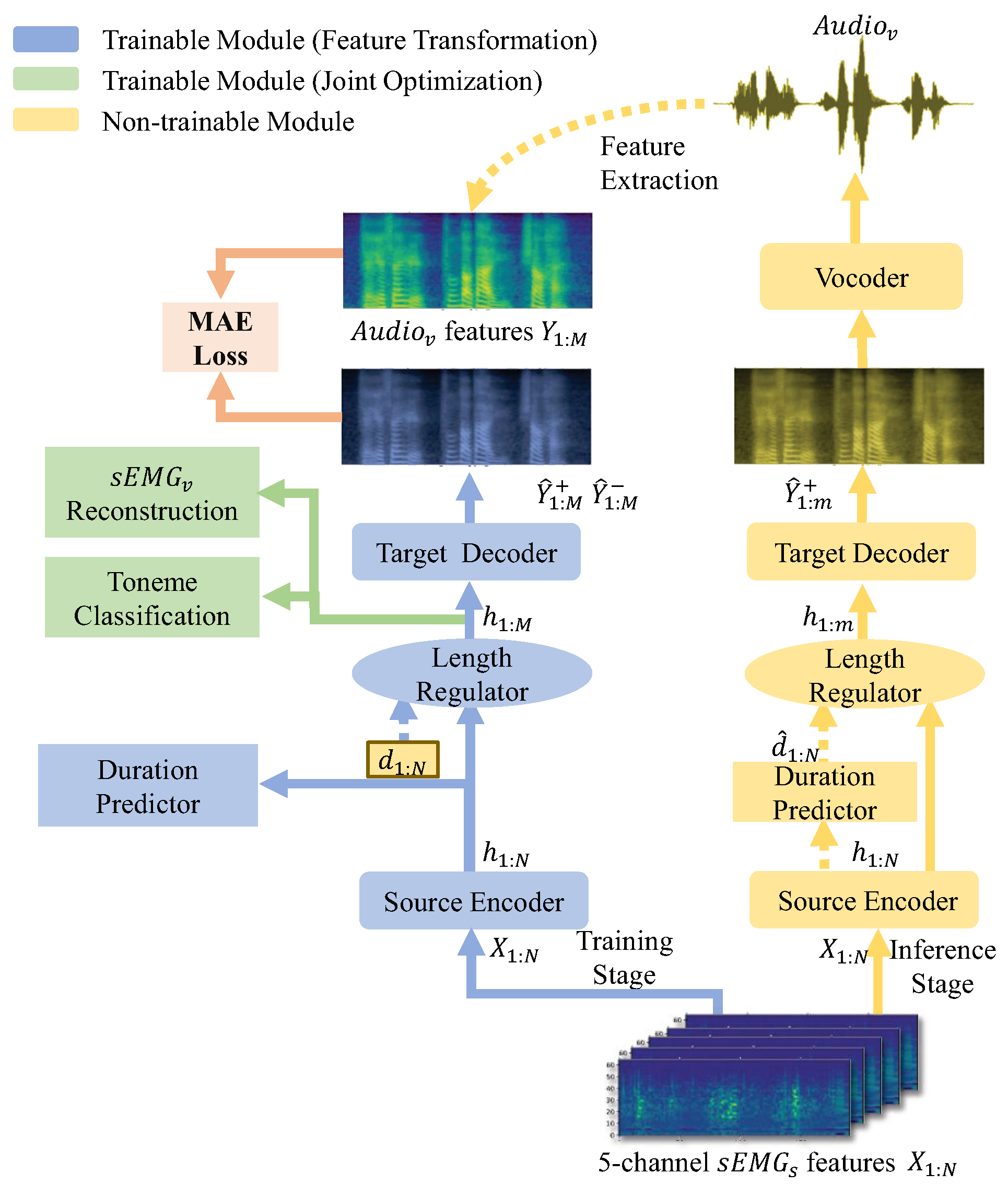
3.1. Overview
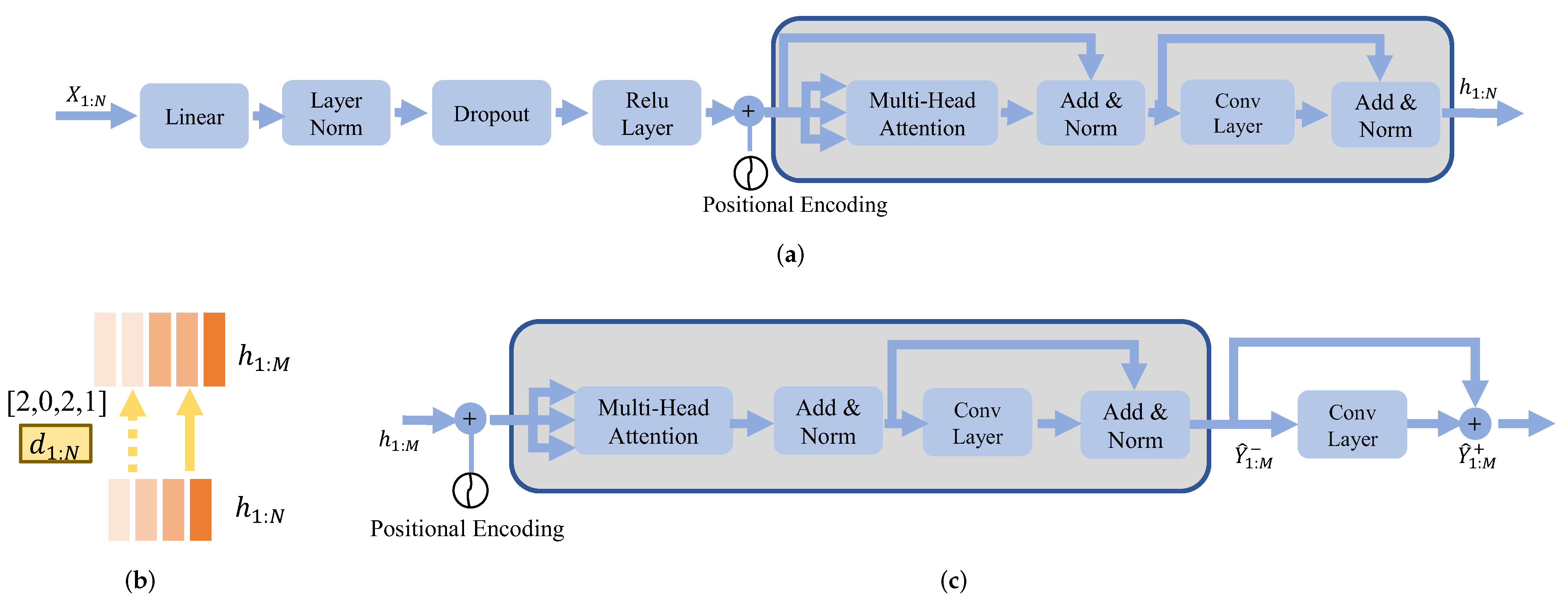
3.2. Feature Transformation
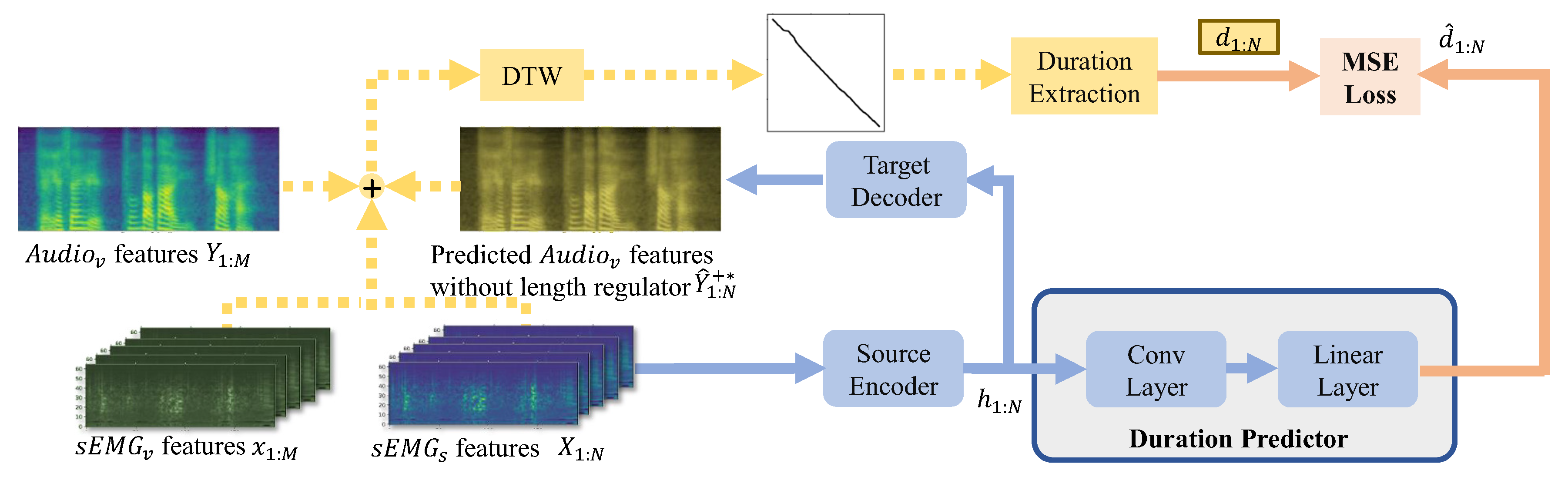
3.3. Duration Extractor
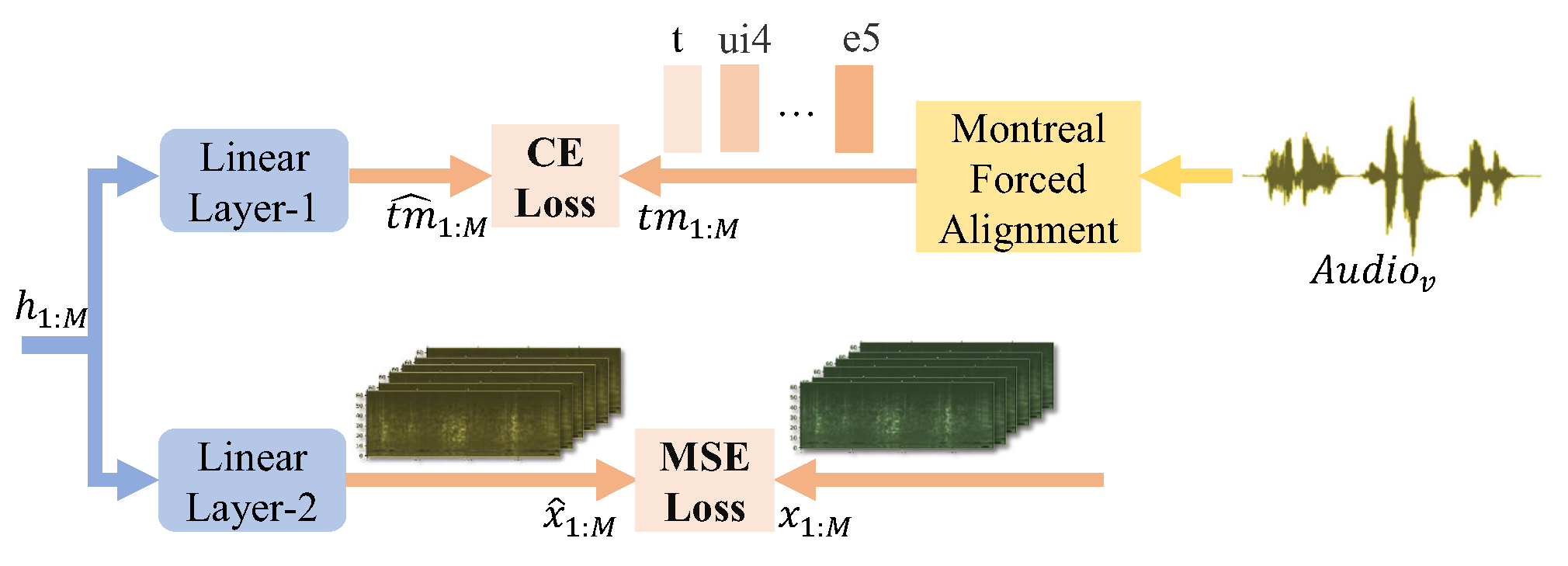
3.4. Joint Optimization with Toneme Prediction and Vocal sEMG Reconstuction
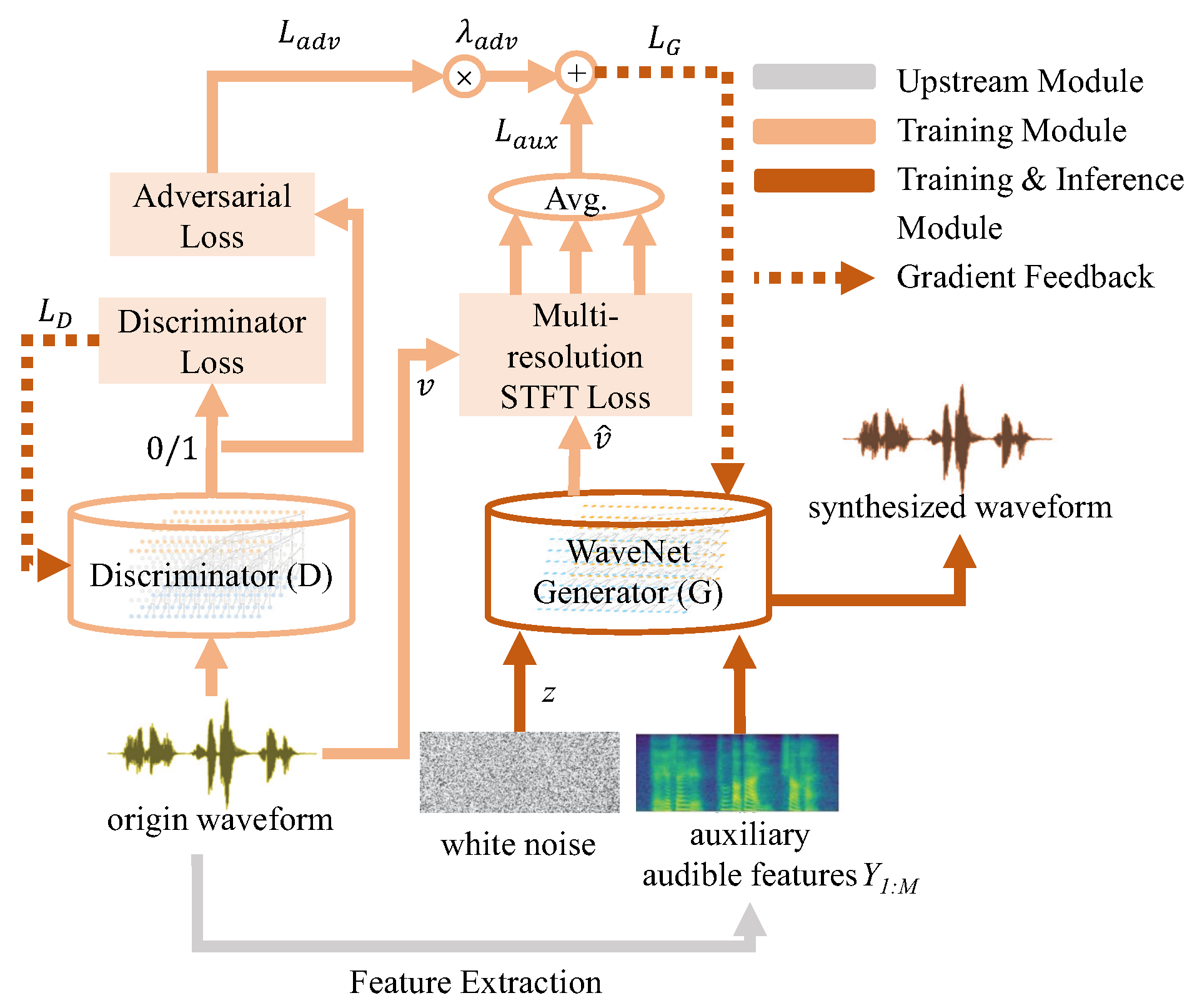
3.5. Vocoder
4. Experiments and Results
4.1. Experimental Setting
4.2. Model Performance on the Dataset
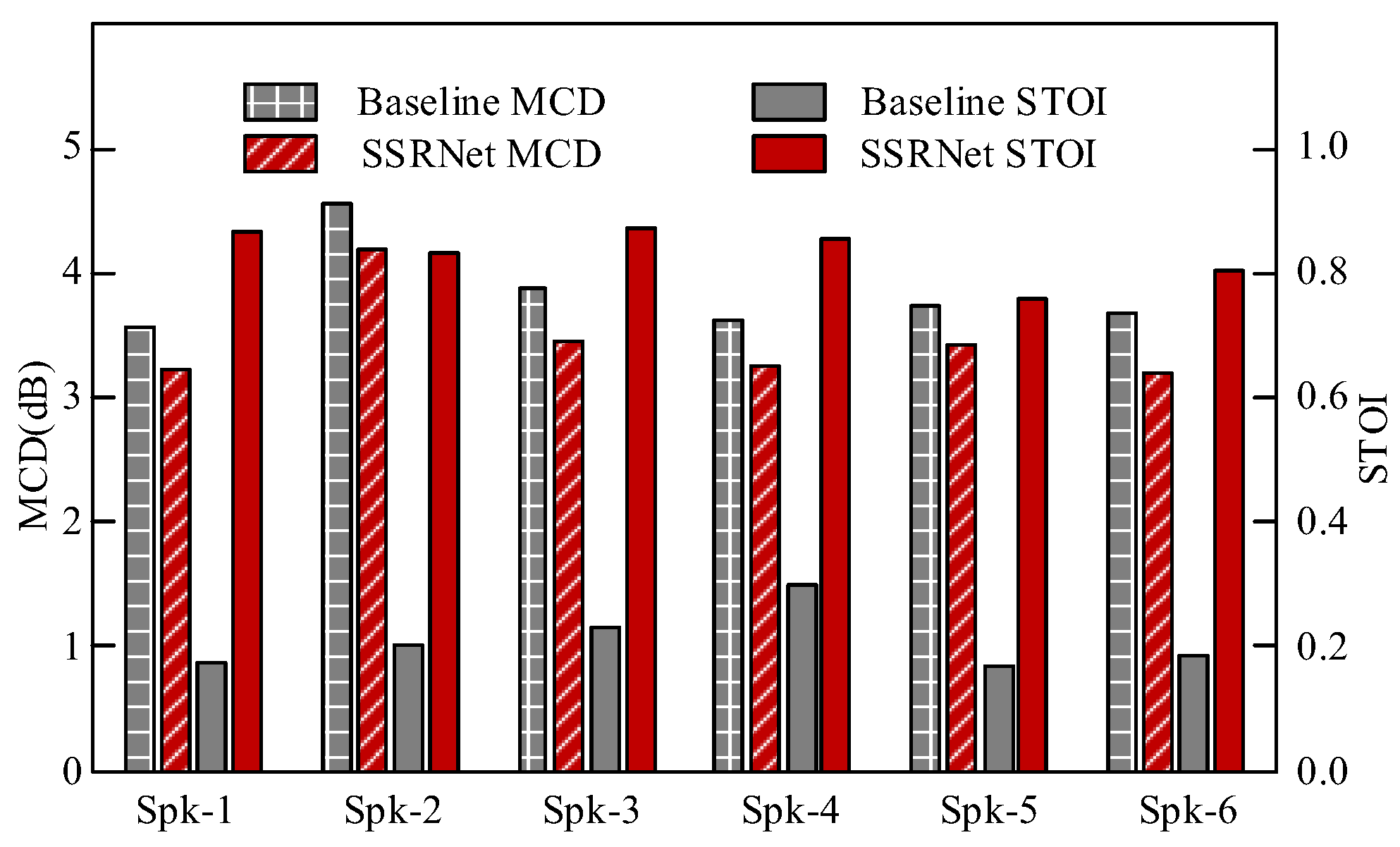
4.2.1. Objective Evaluation
4.2.2. Subjective Evaluation
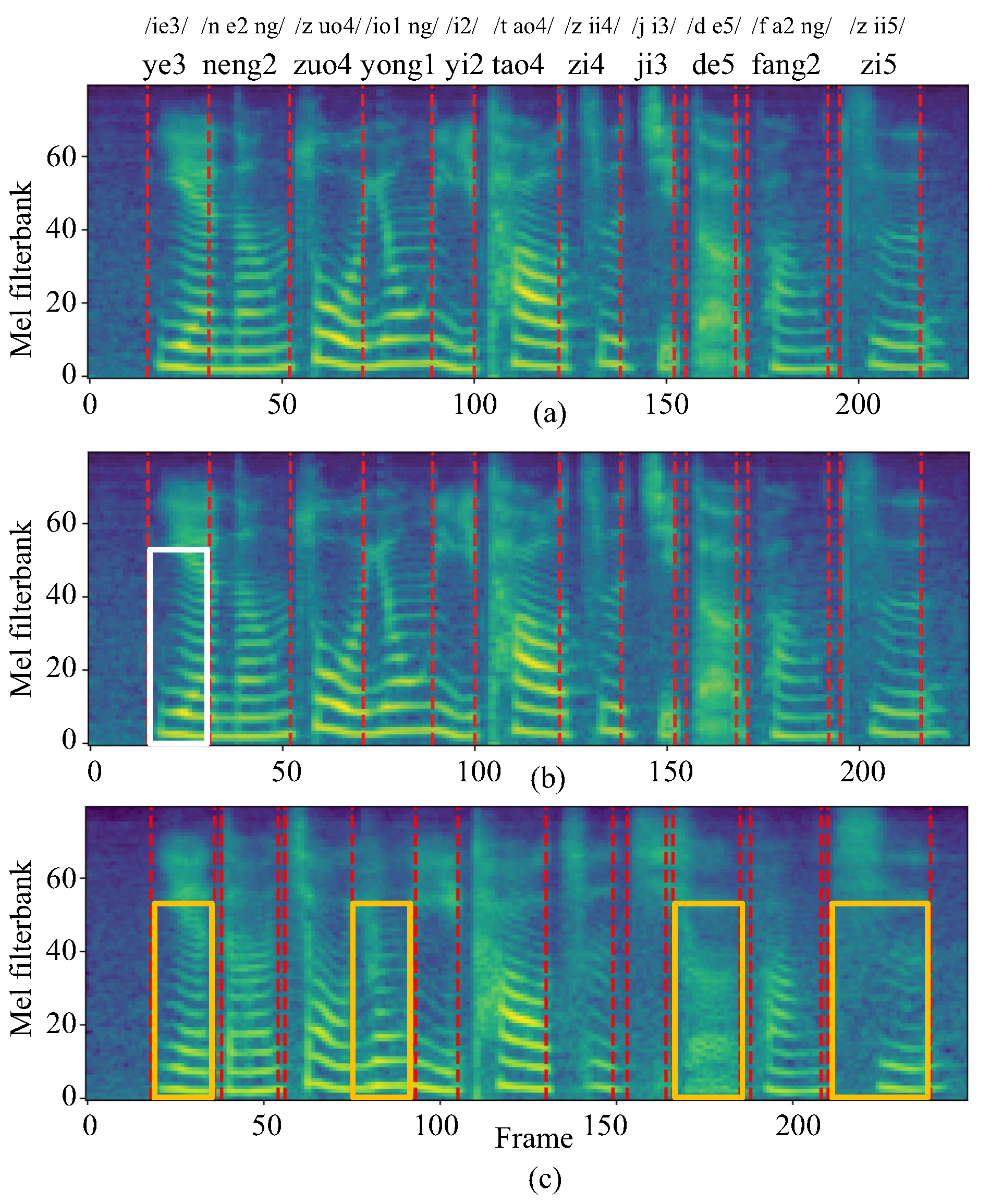
4.2.3. Mel-Spectrogram Comparison
4.3. Ablation Study
4.3.1. Joint Optimization
4.3.2. The Position of the Toneme Classification Module
4.3.3. Tone in Toneme Classification
4.3.4. Cost Function for DTW
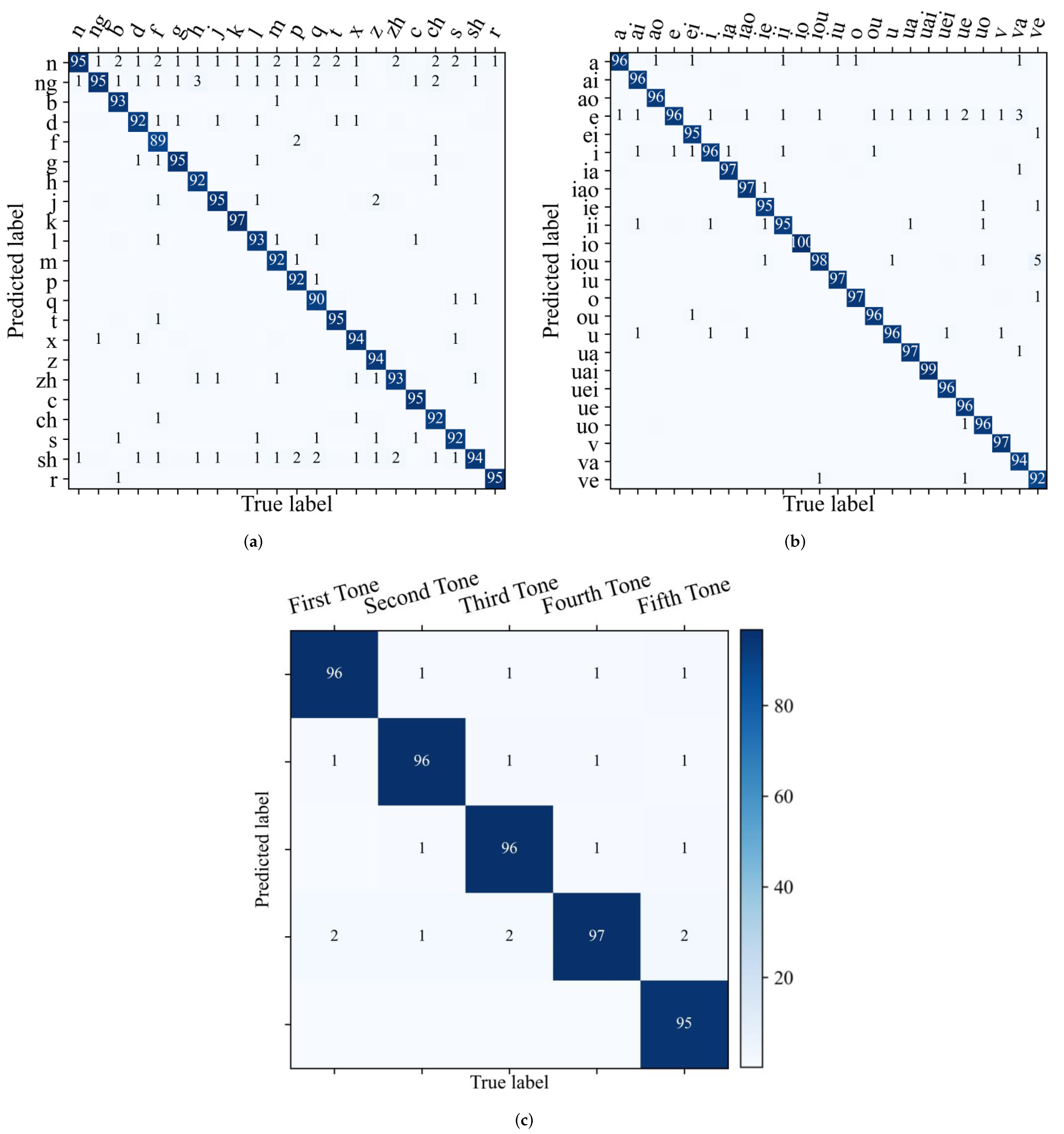
4.4. Frame-Based Toneme Classification Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Denby, B.; Schultz, T.; Honda, K.; Hueber, T.; Gilbert, J.M.; Brumberg, J.S. Silent speech interfaces. Speech Commun. 2010, 52, 270–287. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zhang, M.; Wu, R.; Gao, H.; Yang, M.; Luo, Z.; Li, G. Silent speech decoding using spectrogram features based on neuromuscular activities. Brain Sci. 2020, 10, 442. [Google Scholar] [CrossRef] [PubMed]
- Schultz, T.; Wand, M.; Hueber, T.; Krusienski, D.J.; Herff, C.; Brumberg, J.S. Biosignal-Based Spoken Communication: A Survey. IEEE ACM Trans. Audio Speech Lang. Process. 2017, 25, 2257–2271. [Google Scholar] [CrossRef]
- López, J.A.G.; Alanís, A.G.; Martín-Doñas, J.M.; Pérez-Córdoba, J.L.; Gomez, A.M. Silent Speech Interfaces for Speech Restoration: A Review. IEEE Access 2020, 8, 177995–178021. [Google Scholar] [CrossRef]
- Herff, C.; Heger, D.; de Pesters, A.; Telaar, D.; Brunner, P.; Schalk, G.; Schultz, T. Brain-to-text: Decoding spoken phrases from phone representations in the brain. Front. Neurosci. 2015, 9, 217. [Google Scholar] [CrossRef] [Green Version]
- Angrick, M.; Herff, C.; Johnson, G.D.; Shih, J.J.; Krusienski, D.J.; Schultz, T. Interpretation of convolutional neural networks for speech spectrogram regression from intracranial recordings. Neurocomputing 2019, 342, 145–151. [Google Scholar] [CrossRef]
- Angrick, M.; Herff, C.; Mugler, E.; Tate, M.C.; Slutzky, M.W.; Krusienski, D.J.; Schultz, T. Speech synthesis from ECoG using densely connected 3D convolutional neural networks. J. Neural Eng. 2019, 16, 036019. [Google Scholar] [CrossRef]
- Ramadan, R.A.; Vasilakos, A.V. Brain computer interface: Control signals review. Neurocomputing 2017, 223, 26–44. [Google Scholar] [CrossRef]
- Porbadnigk, A.; Wester, M.; Calliess, J.; Schultz, T. EEG-based Speech Recognition—Impact of Temporal Effects. In Proceedings of the International Conference on Bio-inspired Systems and Signal Processing, Porto, Portugal, 14–17 January 2009; pp. 376–381. [Google Scholar]
- Rolston, J.D.; Englot, D.J.; Cornes, S.; Chang, E.F. Major and minor complications in extraoperative electrocorticography: A review of a national database. Epilepsy Res. 2016, 122, 26–29. [Google Scholar] [CrossRef] [Green Version]
- Diener, L.; Janke, M.; Schultz, T. Direct conversion from facial myoelectric signals to speech using Deep Neural Networks. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–7. [Google Scholar]
- Wand, M.; Janke, M.; Schultz, T. Tackling Speaking Mode Varieties in EMG-Based Speech Recognition. IEEE Trans. Biomed. Eng. 2014, 61, 2515–2526. [Google Scholar] [CrossRef]
- Fagan, M.J.; Ell, S.R.; Gilbert, J.M.; Sarrazin, E.; Chapman, P.M. Development of a (silent) speech recognition system for patients following laryngectomy. Med. Eng. Phys. 2008, 30, 419–425. [Google Scholar] [CrossRef] [PubMed]
- Denby, B.; Stone, M. Speech synthesis from real time ultrasound images of the tongue. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; pp. 685–688. [Google Scholar]
- Janke, M.; Diener, L. EMG-to-Speech: Direct Generation of Speech From Facial Electromyographic Signals. IEEE ACM Trans. Audio Speech Lang. Process. 2017, 25, 2375–2385. [Google Scholar] [CrossRef] [Green Version]
- Gaddy, D.; Klein, D. Digital Voicing of Silent Speech. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 5521–5530. [Google Scholar]
- Meltzner, G.S.; Heaton, J.T.; Deng, Y.; Luca, G.D.; Roy, S.H.; Kline, J.C. Silent Speech Recognition as an Alternative Communication Device for Persons With Laryngectomy. IEEE ACM Trans. Audio Speech Lang. Process. 2017, 25, 2386–2398. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Wang, Y.; Zhang, W.; Yang, M.; Luo, Z.; Li, G. Inductive conformal prediction for silent speech recognition. J. Neural Eng. 2020, 17, 066019. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, M.; Wu, R.; Wang, H.; Luo, Z.; Li, G. Speech neuromuscular decoding based on spectrogram images using conformal predictors with Bi-LSTM. Neurocomputing 2021, 451, 25–34. [Google Scholar] [CrossRef]
- Li, Y.; Tang, C.; Lu, J.; Wu, J.; Chang, E.F. Human cortical encoding of pitch in tonal and non-tonal languages. Nat. Commun. 2021, 12, 1–12. [Google Scholar] [CrossRef]
- Kaan, E.; Wayland, R.; Keil, A. Changes in oscillatory brain networks after lexical tone training. Brain Sci. 2013, 3, 757–780. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Wong, L.L.; Chen, F. Just-Noticeable Differences of Fundamental Frequency Change in Mandarin-Speaking Children with Cochlear Implants. Brain Sci. 2022, 12, 443. [Google Scholar] [CrossRef]
- Chen, Y.; Gao, Y.; Xu, Y. Computational Modelling of Tone Perception Based on Direct Processing of f 0 Contours. Brain Sci. 2022, 12, 337. [Google Scholar] [CrossRef]
- Surendran, D.; Levow, G.; Xu, Y. Tone Recognition in Mandarin Using Focus. In Proceedings of the 9th European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; pp. 3301–3304. [Google Scholar]
- Yip, M. Tone; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Lei, X.; Ji, G.; Ng, T.; Bilmes, J.A.; Ostendorf, M. DBN-Based Multi-stream Models for Mandarin Toneme Recognition. In Proceedings of the (ICASSP ’05). IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23 March 2005; pp. 349–352. [Google Scholar]
- Trask, R.L. A Dictionary of Phonetics and Phonology; Routledge: London, UK, 2004. [Google Scholar]
- Schultz, T.; Schlippe, T. GlobalPhone: Pronunciation Dictionaries in 20 Languages. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; pp. 337–341. [Google Scholar]
- Roach, P.; Widdowson, H. Phonetics; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series. In Proceedings of the AAAIWS’94: Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Online, 31 May 1994; pp. 359–370. [Google Scholar]
- Hayashi, T.; Huang, W.; Kobayashi, K.; Toda, T. Non-Autoregressive Sequence-To-Sequence Voice Conversion. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Online, 6–11 June 2021; pp. 7068–7072. [Google Scholar]
- Ren, Y.; Ruan, Y.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T. FastSpeech: Fast, Robust and Controllable Text to Speech. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 3165–3174. [Google Scholar]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Kim, J.; Kim, S.; Kong, J.; Yoon, S. Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search. In Proceedings of the Annual Conference on Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Shi, Y.; Bu, H.; Xu, X.; Zhang, S.; Li, M. AISHELL-3: A Multi-speaker Mandarin TTS Corpus and the Baselines. arXiv 2020, arXiv:2010.11567. [Google Scholar]
- Benesty, J.; Makino, S.; Chen, J. Speech Enhancement; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Jou, S.C.; Schultz, T.; Walliczek, M.; Kraft, F.; Waibel, A. Towards continuous speech recognition using surface electromyography. In Proceedings of the Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Yamamoto, R.; Song, E.; Kim, J. Parallel Wavegan: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 6199–6203. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Huang, W.; Hayashi, T.; Wu, Y.; Kameoka, H.; Toda, T. Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining. In Proceedings of the 21st Annual Conference of the International Speech Communication Association, Shanghai, China, 25–29 October 2020; pp. 4676–4680. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Ryan, R.; et al. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech, and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar]
- Desai, S.; Raghavendra, E.V.; Yegnanarayana, B.; Black, A.W.; Prahallad, K. Voice conversion using Artificial Neural Networks. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech, and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 3893–3896. [Google Scholar]
- McAuliffe, M.; Socolof, M.; Mihuc, S.; Wagner, M.; Sonderegger, M. Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. In Proceedings of the 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 498–502. [Google Scholar]
- Wang, D.; Zhang, X. THCHS-30: A Free Chinese Speech Corpus. arXiv 2015, arXiv:1512.01882. [Google Scholar]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.W.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. In Proceedings of the 9th ISCA Speech Synthesis Workshop, Sunnyvale, CA, USA, 13–15 September 2016; p. 125. [Google Scholar]
- Prenger, R.; Valle, R.; Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 3617–3621. [Google Scholar]
- Peng, K.; Ping, W.; Song, Z.; Zhao, K. Non-Autoregressive Neural Text-to-Speech. In Proceedings of the 37th International Conference on Machine Learning, Online, 12–18 July 2020; Volume 119, pp. 7586–7598. [Google Scholar]
- Song, E.; Byun, K.; Kang, H.G. ExcitNet vocoder: A neural excitation model for parametric speech synthesis systems. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), La Coruña, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Soplin, N.E.Y.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-to-End Speech Processing Toolkit. In Proceedings of the 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 2207–2211. [Google Scholar]
- Navarro, G. A guided tour to approximate string matching. ACM Comput. Surv. 2001, 33, 31–88. [Google Scholar] [CrossRef]
- Errattahi, R.; Hannani, A.E.; Ouahmane, H. Automatic Speech Recognition Errors Detection and Correction: A Review. Procedia Comput. Sci. 2018, 128, 32–37. [Google Scholar] [CrossRef]
- Kubichek, R. Mel-cepstral distance measure for objective speech quality assessment. In Proceedings of the IEEE Pacific Rim Conference on Communications Computers and Signal Processing, Victoria, BC, Canada, 19–21 May 1993; Volume 1, pp. 125–128. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In Proceedings of the 35th International Conference on Acoustics, Speech, and Signal Processing, Dallas, TX, USA, 14–19 May 2010; pp. 4214–4217. [Google Scholar]
- Gaddy, D.; Klein, D. An Improved Model for Voicing Silent Speech. In Proceedings of the Association for Computational Linguistics (ACL) and Asian Federation of Natural Language Processing (AFNLP), Bangkok, Thailand, 1–6 August 2021; pp. 175–181. [Google Scholar]
- Freitas, J.; Teixeira, A.; Silva, S.; Oliveira, C.; Dias, M.S. Detecting Nasal Vowels in Speech Interfaces Based on Surface Electromyography. PLoS ONE 2015, 10, e0127040. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Electrode Index | Position |
|---|---|
| 1 | 1 cm right from the nose |
| 2 | 1 cm right from corners of the mouth |
| 3 | 1 cm left from the nose |
| 4 | left corner of chin |
| 5 | 4 cm behind the chin |
| Speaker Id | Sex | Silent Speech Time (Min) | Number of Utterances | ||||
|---|---|---|---|---|---|---|---|
| Train | Val | Test | Train | Val | Test | ||
| 1 | f | 52.59 | 6.68 | 6.49 | 680 | 85 | 85 |
| 2 | m | 52.65 | 6.70 | 6.26 | 516 | 64 | 64 |
| 3 | f | 56.60 | 7.11 | 6.99 | 716 | 89 | 89 |
| 4 | m | 40.77 | 5.11 | 5.01 | 800 | 100 | 100 |
| 5 | m | 40.49 | 5.06 | 5.09 | 600 | 75 | 75 |
| 6 | m | 34.85 | 4.29 | 4.40 | 600 | 75 | 75 |
| Total | 277.95 | 34.95 | 34.25 | 3912 | 488 | 488 | |
| Item | Details | |
|---|---|---|
| attention transformation dimensions | 384 | |
| heads for multi-head attention | 4 | |
| source encoder | FFT layers | 6 |
| hidden units | 1536 | |
| target decoder | FFT layers | 6 |
| hidden units | 1536 | |
| postnet | layers | 5 |
| filter channels | 256 | |
| filter size | 5 | |
| duration predictor | layers | 2 |
| filter channels | 384 | |
| kernel size | 3 | |
| Item | Objects and/or Details | |
|---|---|---|
| 4 | ||
| filter size | 3 | |
| batch size | 6 | |
| training audio length | 16,384 (1.024 s) | |
| WaveNet generator | 30-layer dilated residual convolution | |
| discriminator | 10-layer dilated residual convolution | |
| learning rate | generator | 1 |
| discriminator | 5 | |
| training steps | generator-only | 1 |
| jointly | 4 | |
| channel size | skip channels | 64 |
| residual channels | 64 | |
| optimizer | RAdam optimizer | = 1 |
| activation function | Leaky ReLU | |
| Spk-1 | Spk-2 | Spk-3 | Spk-4 | Spk-5 | Spk-6 | |
|---|---|---|---|---|---|---|
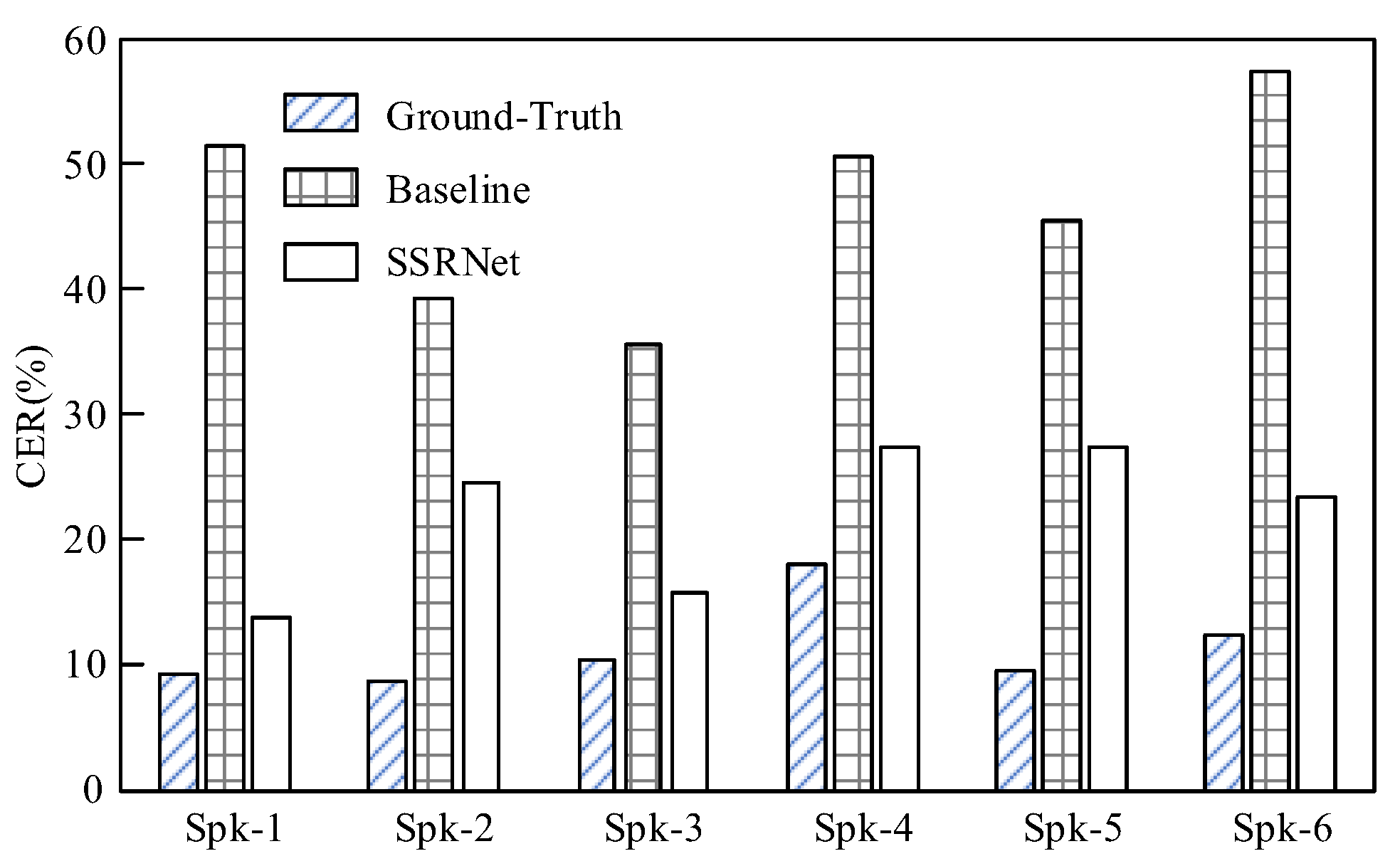
| Baseline CER (%) | 55.06 ± 41.62 | 17.72 ± 13.96 | 23.00 ± 2.71 | 53.37 ± 6.67 | 26.37 ± 21.18 | 63.05 ± 27.00 |
| SSRNet CER (%) | 1.70 ± 3.4 | 1.19 ± 1.46 | 2.31 ± 2.37 | 8.92 ± 5.77 | 20.67 ± 5.69 | 3.69 ± 3.05 |
| Baseline Naturalness | 44 ± 16 | 50 ± 14 | 51 ± 17 | 39 ± 13 | 51 ± 20 | 41 ± 18 |
| SSRNet Naturalness | 95 ± 7 | 71 ± 17 | 89 ± 5 | 64 ± 10 | 58 ± 11 | 77 ± 16 |
Reconstruction Module | Toneme Classification Module | Toneme Classification Module Position | Tones in Toneme Classification Module | Cost Function for DTW | CER (%) |
|---|---|---|---|---|---|
| ✔ ( = 0.5) | ✔ ( = 0.5) | Before Decoder | ✔ | = 10 | +0 |
| ✖ ( = 0) | ✔ ( = 0.5) | Before Decoder | ✔ | = 10 | +9.38 |
| ✔ ( = 0.5) | ✖ ( = 0) | - | ✔ | = 10 | +132.75 |
| ✔ ( = 0.5) | ✔ ( = 0.5) | After Decoder | ✔ | = 10 | +1.89 |
| ✔ ( = 0.5) | ✔ ( = 0.5) | Before Decoder | ✖ | = 10 | +6.51 |
| ✔ ( = 0.5) | ✔ ( = 0.5) | Before Decoder | ✔ | = 0 | +81.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Lin, H.; Wang, Y.; Wang, H.; Zhang, M.; Gao, H.; Ai, Q.; Luo, Z.; Li, G. Sequence-to-Sequence Voice Reconstruction for Silent Speech in a Tonal Language. Brain Sci. 2022, 12, 818. https://doi.org/10.3390/brainsci12070818
Li H, Lin H, Wang Y, Wang H, Zhang M, Gao H, Ai Q, Luo Z, Li G. Sequence-to-Sequence Voice Reconstruction for Silent Speech in a Tonal Language. Brain Sciences. 2022; 12(7):818. https://doi.org/10.3390/brainsci12070818
Chicago/Turabian StyleLi, Huiyan, Haohong Lin, You Wang, Hengyang Wang, Ming Zhang, Han Gao, Qing Ai, Zhiyuan Luo, and Guang Li. 2022. "Sequence-to-Sequence Voice Reconstruction for Silent Speech in a Tonal Language" Brain Sciences 12, no. 7: 818. https://doi.org/10.3390/brainsci12070818
APA StyleLi, H., Lin, H., Wang, Y., Wang, H., Zhang, M., Gao, H., Ai, Q., Luo, Z., & Li, G. (2022). Sequence-to-Sequence Voice Reconstruction for Silent Speech in a Tonal Language. Brain Sciences, 12(7), 818. https://doi.org/10.3390/brainsci12070818