Alzheimer’s Disease Early Diagnosis Using Manifold-Based Semi-Supervised Learning


Abstract
:1. Introduction
2. Theoretical Backgrounds
2.1. Random Walk on a Graph
2.2. Semi-Supervised Learning
- if two members of the dataset are located in a dense region and are close to each other in the feature space, their labels will also be close to each other.
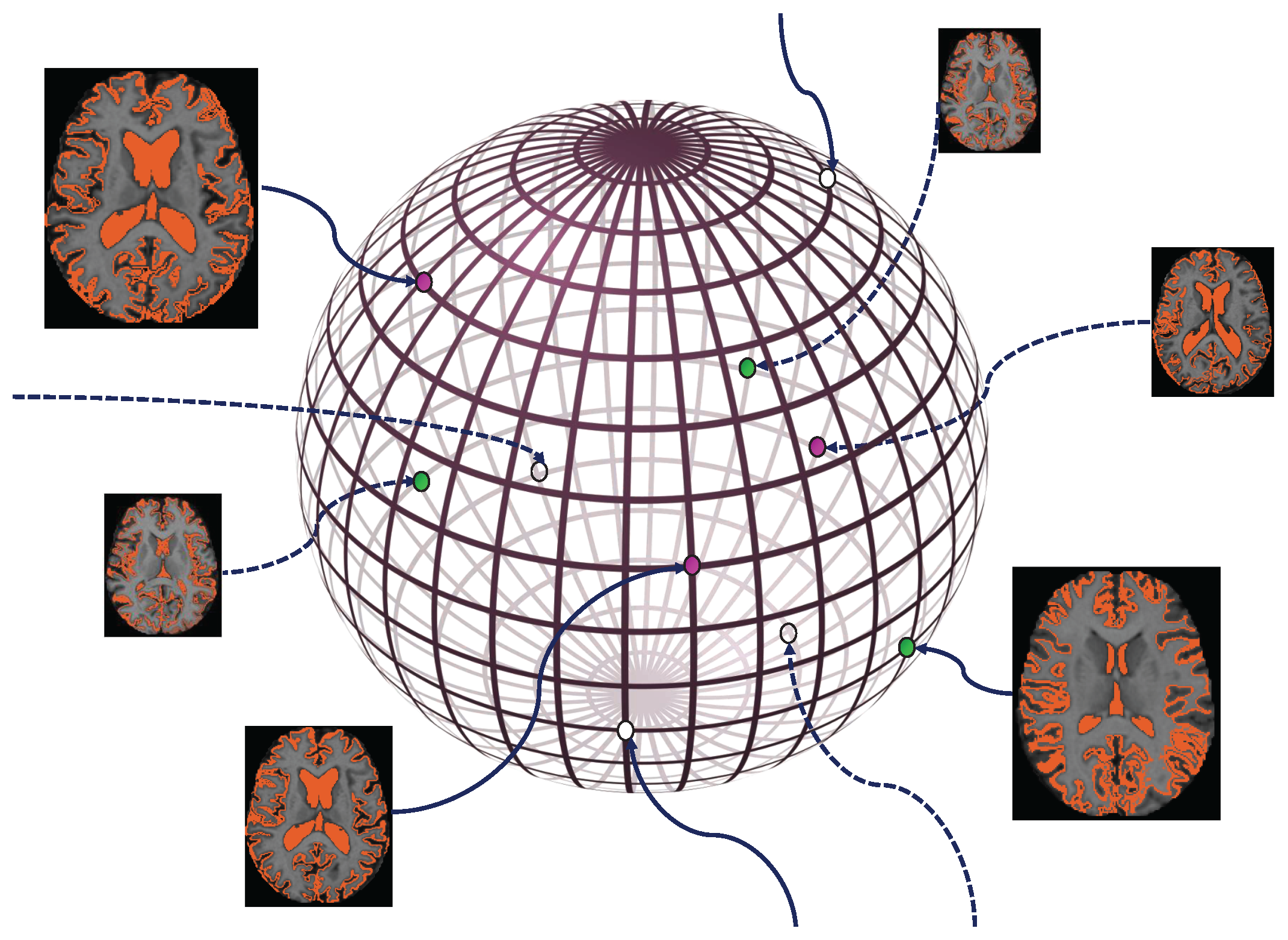
2.3. Manifold Learning
- Considering the fundamental assumption mentioned in the previous section, in a semi-supervised algorithm similar to the one we are aiming to apply to our problem, we will need to compute the distance between different data. Noticing that the data are now located on a manifold, it can be explicitly recognized that for a more effective result, rather than computing the Euclidean distance, we will need to define the forenamed distance on the manifold itself. This means calculating the geodesic distance which is the number of edges in the shortest path connecting them.Since in machine learning problems, we often possess only a limited number of training and test data, it is usually not possible to solve the manifold equation precisely. As a result, a graph is built up of an existing dataset as an approximation for the original manifold. After this graph is formed, considering k-nearest neighbor graphs corresponding to each node, we can assume that the Euclidean distance between two nodes connected with an edge approximately equals their geodesic distance. Also, regarding nodes which are not directly connected with an edge, the length of the minimum distance between them in the graph is a fair approximation of their geodesic distance.
- Moreover, keeping in mind that the fundamental assumption about semi-supervised algorithms also applies on this manifold, it can easily be concluded that the items of data which are located in dense areas on the manifold have similar labels. This implies that if a path exists between two members of the dataset which completely passes through the most probable and dense regions of the manifold, they will certainly have very close labels.Therefore, when using a graph as an approximation for such a manifold, it needs to have properties that also meet the above condition.
2.4. Labeling Based on Manifold Learning
Random Walk-Based Labeling Approaches
3. Methods and Materials
3.1. Dataset
3.2. Method
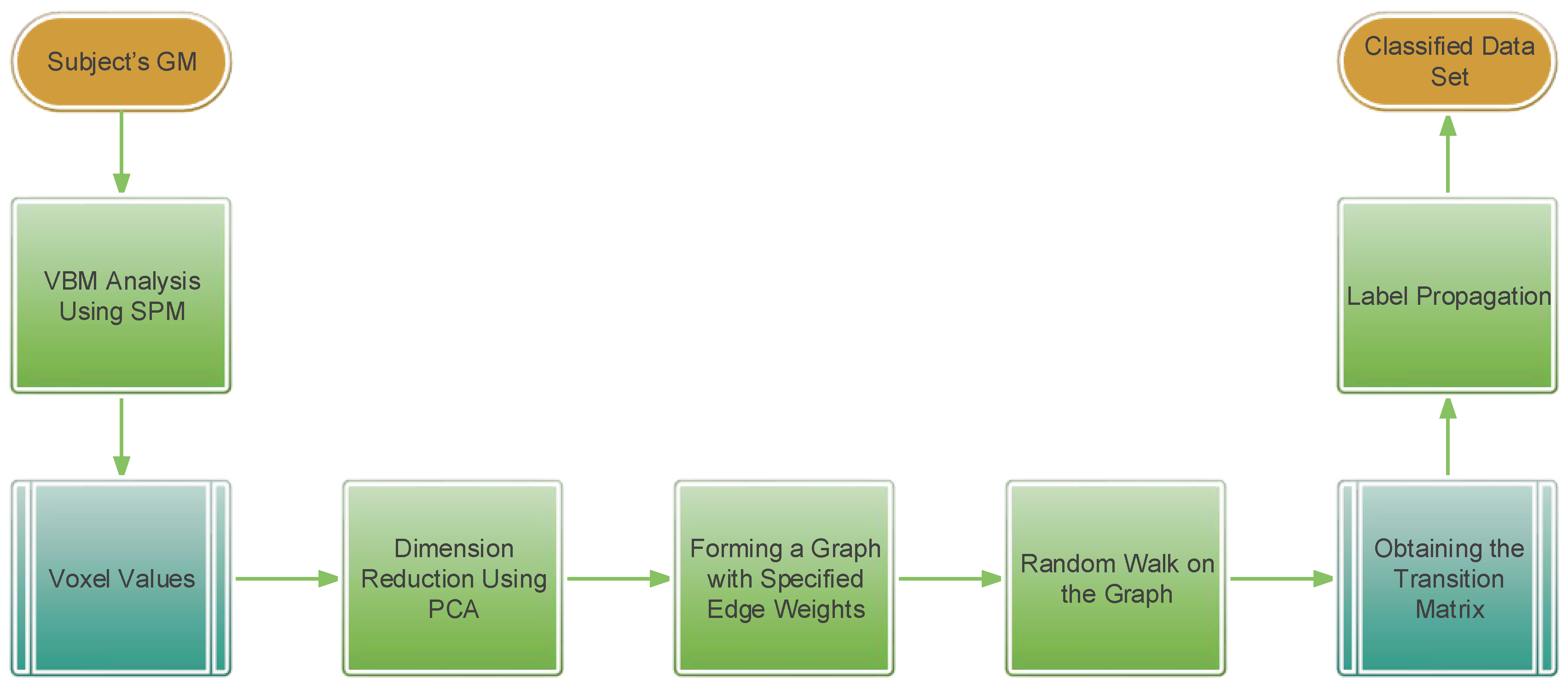
3.2.1. Summary of the Method
3.2.2. Image Processing and Feature Extraction
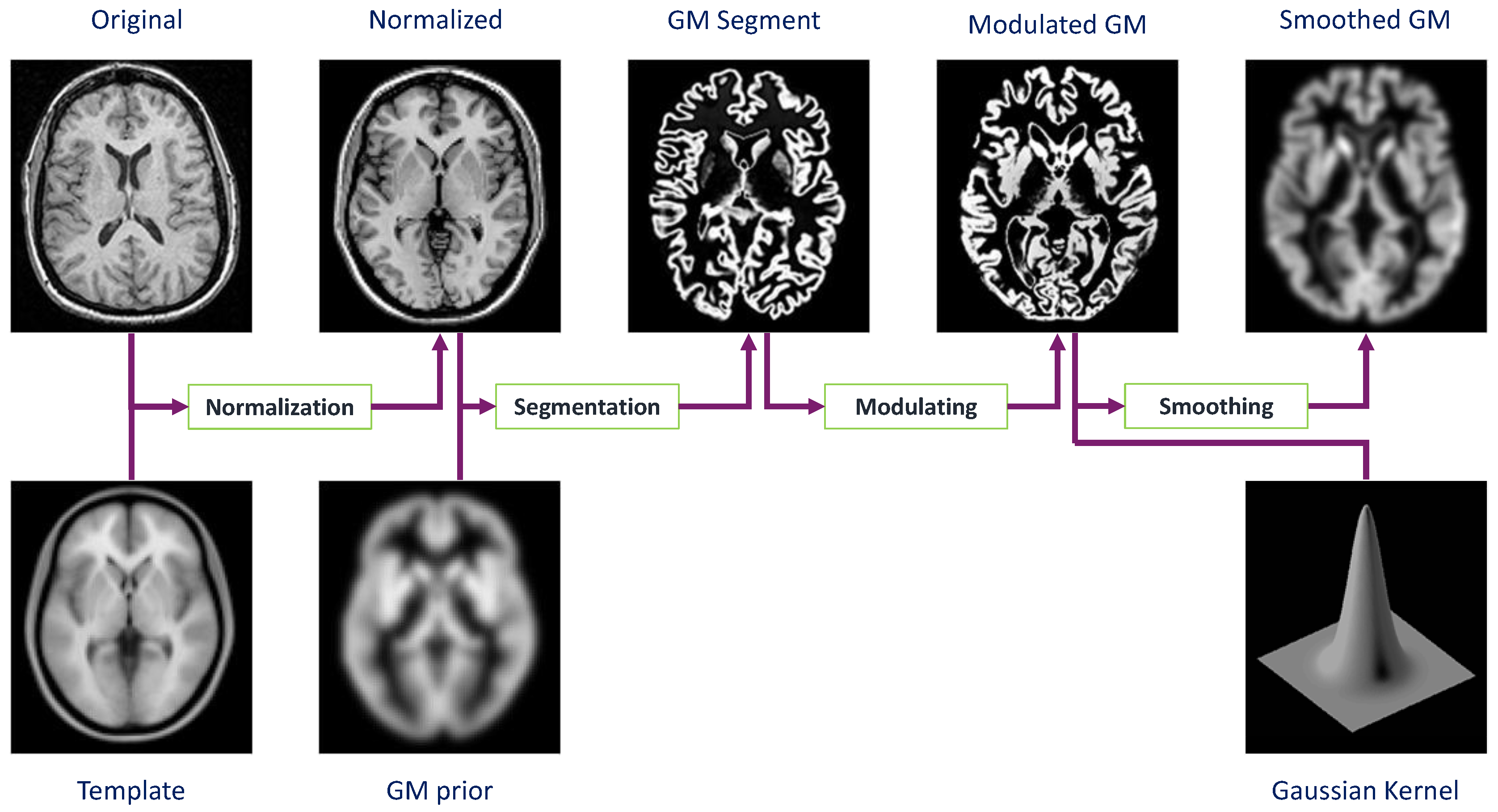
3.2.3. Voxel-based Morphometry (VBM)
3.2.4. Image Processing and VBM in the OASIS Database
3.2.5. Dimension Reduction Using Principal Component Analysis (PCA)
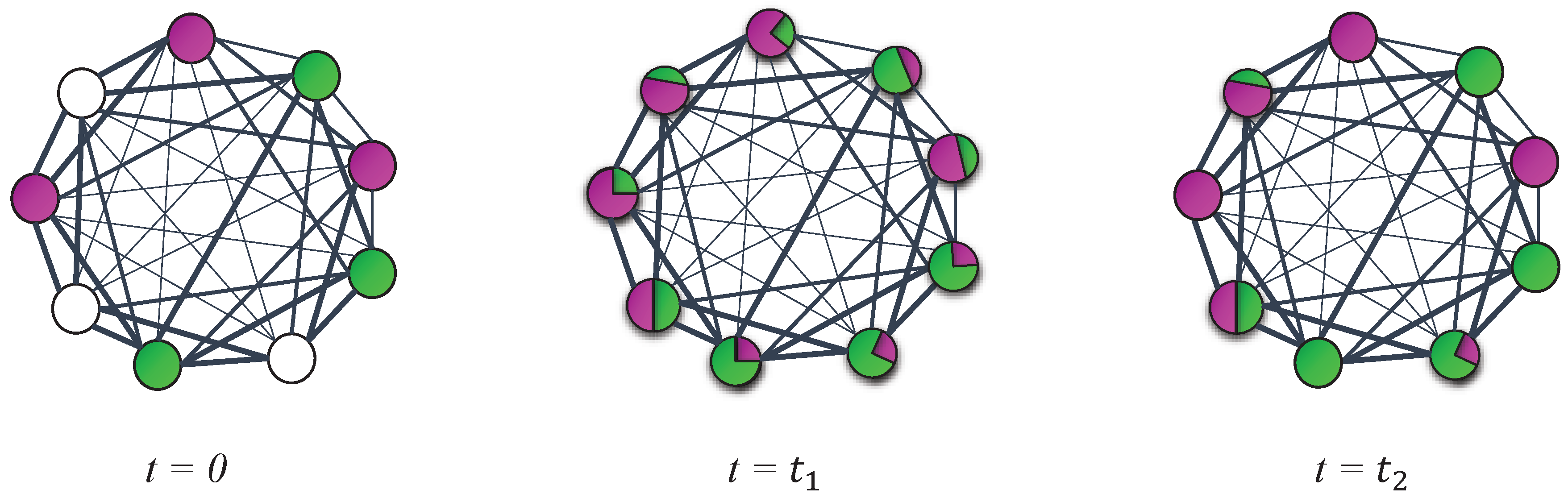
3.2.6. Label Propagation
- Construct matrix and repeat the next three steps until converges.
- Replace matrix with .
- Normalize the rows of so that the sum of each row equals 1.
- In the end of each iteration, update matrix such that for every row i, where , replace 1 in the column corresponding to the class of labeled data and the rest of the elements in these rows will be equal to zero.
4. Results and Discussion
4.1. Competing Methods
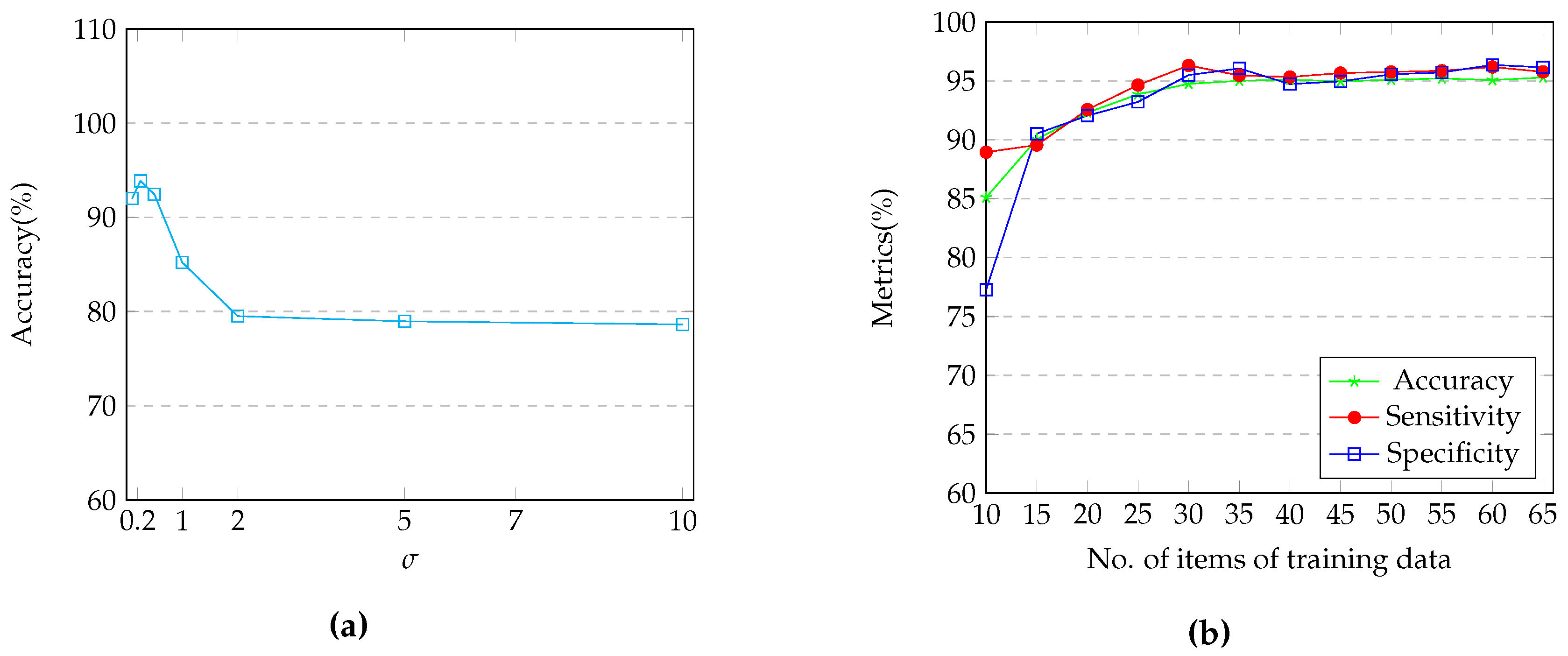
4.2. Parameter Tunning
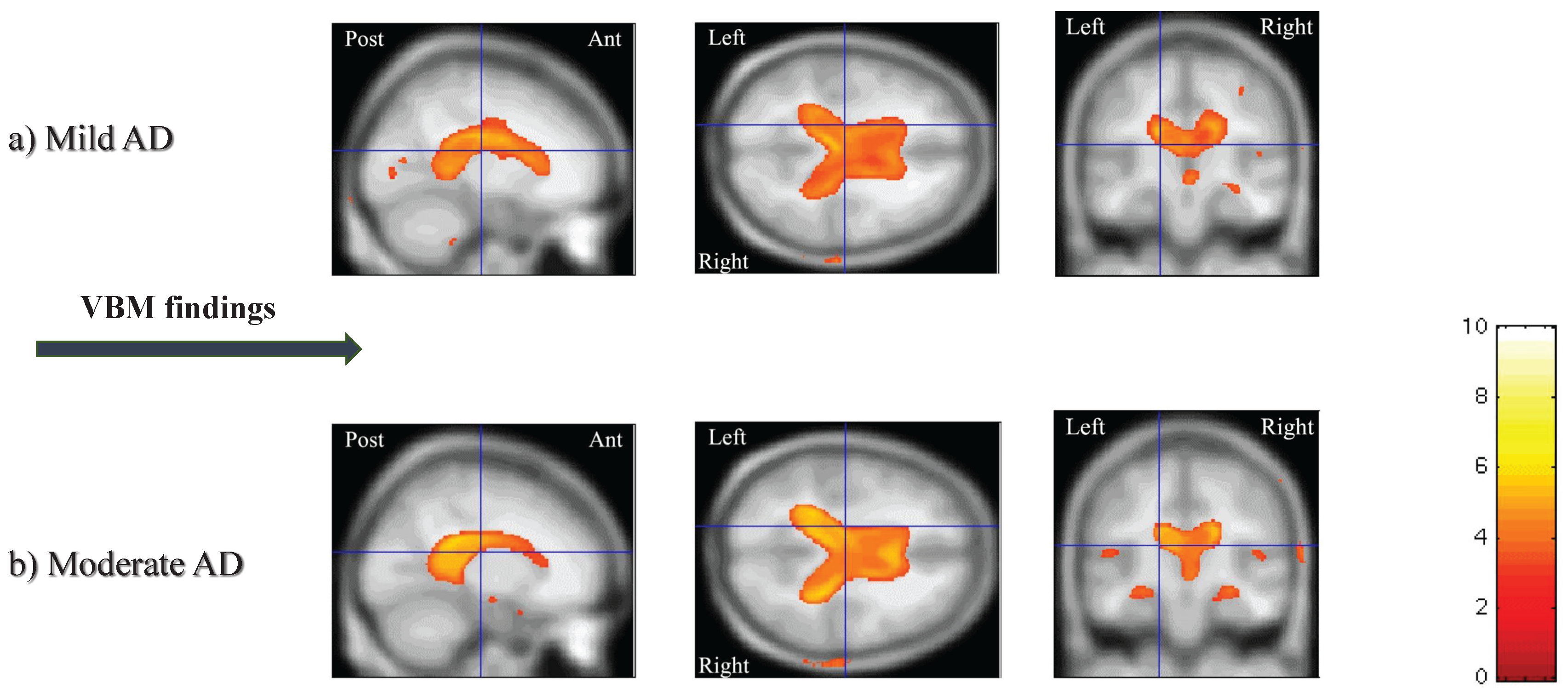
4.3. Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Alzheimer’s Association. 2014 Alzheimer’s disease facts and figures. Alzheimer’s Dement. 2014, 10, e47–e92. [Google Scholar]
- Suk, H.I.; Shen, D. Deep learning-based feature representation for AD/MCI classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Nagoya, Japan, 22–26 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 583–590. [Google Scholar]
- Suk, H.I.; Lee, S.W.; Shen, D.; The Alzheimer’s Disease Neuroimaging Initiative. Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis. NeuroImage 2014, 101, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Sarraf, S.; Anderson, J.; Tofighi, G. DeepAD: Alzheimer’s Disease Classification via Deep Convolutional Neural Networks using MRI and fMRI. bioRxiv 2016, 070441. [Google Scholar] [CrossRef]
- Liu, S.; Liu, S.; Cai, W.; Che, H.; Pujol, S.; Kikinis, R.; Feng, D.; Fulham, M.J.; ADNI. Multimodal neuroimaging feature learning for multiclass diagnosis of Alzheimer’s disease. IEEE Trans. Biomed. Eng. 2015, 62, 1132–1140. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Tran, L.; Thung, K.H.; Ji, S.; Shen, D.; Li, J. A robust deep model for improved classification of AD/MCI patients. IEEE J. Biomed. Health Inf. 2015, 19, 1610–1616. [Google Scholar] [CrossRef] [PubMed]
- Klöppel, S.; Stonnington, C.M.; Chu, C.; Draganski, B.; Scahill, R.I.; Rohrer, J.D.; Fox, N.C.; Jack, C.R.; Ashburner, J.; Frackowiak, R.S. Automatic classification of MR scans in Alzheimer’s disease. Brain 2008, 131, 681–689. [Google Scholar] [CrossRef] [PubMed]
- Dessouky, M.M.; Elrashidy, M.A.; Abdelkader, H.M. Selecting and extracting effective features for automated diagnosis of Alzheimer’s disease. Int. J. Comput. Appl. 2013, 81, 17–28. [Google Scholar]
- Payan, A.; Montana, G. Predicting Alzheimer’s disease: A neuroimaging study with 3D convolutional neural networks. arXiv 2015, arXiv:1502.02506. [Google Scholar]
- Hosseini-Asl, E.; Keynton, R.; El-Baz, A. Alzheimer’s disease diagnostics by adaptation of 3D convolutional network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 126–130. [Google Scholar]
- Chyzhyk, D.; Savio, A. Feature Extraction from Structural MRI Images Based on VBM: Data from OASIS Database; University of the Basque Country, Internal Research Publication: Basque, Spain, 2010. [Google Scholar]
- Statistical Parametric Mapping Software Package. Available online: http://www.fil.ion.ucl.ac.uk/spm (accessed on 10 July 2017).
- Jolliffe, I. Principal Component Analysis; Wiley Online Library: Hoboken, USA, 2002. [Google Scholar]
- Zhu, X.; Ghahramani, Z. Learning from Labeled and Unlabeled Data with Label Propagation. 2002. Available online: https://www.researchgate.net/publication/2475534_Learning_from_Labeled_and_Unlabeled_Data_with_Label_Propagation (accessed on 19 August 2017).
- Zhou, D.; Bousquet, O.; Lal, T.N.; Weston, J.; Schölkopf, B. Learning with local and global consistency. In Advances in Neural Information Processing Systems (NIPS); Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2003; Volume 16, pp. 321–328. [Google Scholar]
- Adaszewski, S.; Dukart, J.; Kherif, F.; Frackowiak, R.; Draganski, B.; Alzheimer’s Disease Neuroimaging Initiative. How early can we predict Alzheimer’s disease using computational anatomy? Neurobiol. Aging 2013, 34, 2815–2826. [Google Scholar] [CrossRef] [PubMed]
- Bron, E.E.; Smits, M.; Van Der Flier, W.M.; Vrenken, H.; Barkhof, F.; Scheltens, P.; Papma, J.M.; Steketee, R.M.; Orellana, C.M.; Meijboom, R.; et al. Standardized evaluation of algorithms for computer-aided diagnosis of dementia based on structural MRI: The CADDementia challenge. NeuroImage 2015, 111, 562–579. [Google Scholar] [CrossRef] [PubMed]
- Van Ginneken, B.; Schaefer-Prokop, C.M.; Prokop, M. Computer-aided diagnosis: How to move from the laboratory to the clinic. Radiology 2011, 261, 719–732. [Google Scholar] [CrossRef] [PubMed]
- Doi, K. Computer-aided diagnosis in medical imaging: Historical review, current status and future potential. Comput. Med. Imaging Gr. 2007, 31, 198–211. [Google Scholar] [CrossRef] [PubMed]
- Doi, K. Diagnostic imaging over the last 50 years: Research and development in medical imaging science and technology. Phys. Med. Biol. 2006, 51, R5. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Goldberg, A.B.; Van Gael, J.; Andrzejewski, D. Improving diversity in ranking using absorbing random walks. 2007. Available online: http://citeseerx.ist.psu.edu/showciting?doi=10.1.1.111.251 (accessed on 19 August 2017).
- Newman, M.E. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 2006, 74, 036104. [Google Scholar] [CrossRef] [PubMed]
- Yen, L.; Vanvyve, D.; Wouters, F.; Fouss, F.; Verleysen, M.; Saerens, M. Clustering Using a Random Walk Based Distance Measure. 2005. Available online: https://www.semanticscholar.org/paper/Clustering-Using-a-Random-Walk-Based-Distance-Meas-Yen-Vanvyve/3fa3a1d519e7a40176b1d2e4e34655181e2a8391 (accessed on 19 August 2017).
- Wang, H.; Li, Q.; D’Agostino, G.; Havlin, S.; Stanley, H.E.; Van Mieghem, P. Effect of the interconnected network structure on the epidemic threshold. Phys. Rev. E 2013, 88, 022801. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Zhou, T. Epidemic spreading in weighted networks: An edge-based mean-field solution. Phys. Rev. E 2012, 85, 056106. [Google Scholar] [CrossRef] [PubMed]
- Skardal, P.S.; Taylor, D.; Sun, J. Optimal synchronization of complex networks. Phys. Rev. Lett. 2014, 113, 144101. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Motter, A.E.; Kurths, J. Universality in the synchronization of weighted random networks. Phys. Rev. Lett. 2006, 96, 034101. [Google Scholar] [CrossRef] [PubMed]
- Kohavi, R.; Provost, F. Glossary of terms. Mach. Learn. 1998, 30, 271–274. [Google Scholar]
- Belkin, M. Problems of Learning on Manifolds. Ph.D. Thesis, The University of Chicago, Illinois, IL, USA, 2003. [Google Scholar]
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Marcus, D.S.; Wang, T.H.; Parker, J.; Csernansky, J.G.; Morris, J.C.; Buckner, R.L. Open Access Series of Imaging Studies (OASIS): Cross-sectional MRI data in young, middle aged, nondemented, and demented older adults. J. Cogn. Neurosci. 2007, 19, 1498–1507. [Google Scholar] [CrossRef] [PubMed]
- Savio, A.; García-Sebastián, M.; Hernández, C.; Graña, M.; Villanúa, J. Classification results of artificial neural networks for Alzheimer’s disease detection. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Burgos, Spain, 23–26 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 641–648. [Google Scholar]
- García-Sebastián, M.; Savio, A.; Graña, M.; Villanúa, J. On the use of morphometry based features for Alzheimer’s disease detection on MRI. In Proceedings of the International Work-Conference on Artificial Neural Networks, Salamanca, Spain, 10–12 June 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 957–964. [Google Scholar]
- Savio, A.; García-Sebastián, M.; Graña, M.; Villanúa, J. Results of an adaboost approach on Alzheimer’s disease detection on MRI. In Bioinspired Applications in Artificial and Natural Computation, Proceedings of the Third International Work-Conference on the Interplay Between Natural and Artificial Computation (IWINAC), Santiago de Compostela, Spain, 22–26 June 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 114–123. [Google Scholar]
- Ashburner, J.; Friston, K.J. Voxel-based morphometry—The methods. Neuroimage 2000, 11, 805–821. [Google Scholar] [CrossRef] [PubMed]
- Busatto, G.F.; Garrido, G.E.; Almeida, O.P.; Castro, C.C.; Camargo, C.H.; Cid, C.G.; Buchpiguel, C.A.; Furuie, S.; Bottino, C.M. A voxel-based morphometry study of temporal lobe gray matter reductions in Alzheimer’s disease. Neurobiol. Aging 2003, 24, 221–231. [Google Scholar] [CrossRef]
- Frisoni, G.; Testa, C.; Zorzan, A.; Sabattoli, F.; Beltramello, A.; Soininen, H.; Laakso, M. Detection of grey matter loss in mild Alzheimer’s disease with voxel based morphometry. J. Neurol. Neurosurg. Psychiatry 2002, 73, 657–664. [Google Scholar] [CrossRef] [PubMed]
- Koerts, J.; Abrahamse, A.P.J. On the Theory and Application of the General Linear Model; Rotterdam University Press: Rotterdam, The Netherlands, 1969. [Google Scholar]
- Friston, K.J.; Holmes, A.P.; Worsley, K.J.; Poline, J.P.; Frith, C.D.; Frackowiak, R.S. Statistical parametric maps in functional imaging: A general linear approach. Human Brain Mapp. 1994, 2, 189–210. [Google Scholar] [CrossRef]
- Brett, M.; Penny, W.; Kiebel, S. Introduction to random field theory. Human Brain Funct. 2003, 2, 867–879. [Google Scholar]
- Cao, J.; Worsley, K. Applications of random fields in human brain mapping. In Lecture Notes in Statistics; Springer: New York, NY, USA, 2001; pp. 169–182. [Google Scholar]
- Zu, C.; Jie, B.; Liu, M.; Chen, S.; Shen, D.; Zhang, D.; The Alzheimer’s Disease Neuroimaging Initiative. Label-aligned multi-task feature learning for multimodal classification of Alzheimer’s disease and mild cognitive impairment. Brain Imaging Behav. 2016, 10, 1148–1159. [Google Scholar] [CrossRef] [PubMed]
- Moradi, E.; Pepe, A.; Gaser, C.; Huttunen, H.; Tohka, J.; The Alzheimer’s Disease Neuroimaging Initiative. Machine learning framework for early MRI-based Alzheimer’s conversion prediction in MCI subjects. Neuroimage 2015, 104, 398–412. [Google Scholar] [CrossRef] [PubMed]
- Casanova, R.; Hsu, F.C.; Sink, K.M.; Rapp, S.R.; Williamson, J.D.; Resnick, S.M.; Espeland, M.A.; The Alzheimer’s Disease Neuroimaging Initiative. Alzheimer’s disease risk assessment using large-scale machine learning methods. PLoS ONE 2013, 8, e77949. [Google Scholar] [CrossRef] [PubMed]
- Chyzhyk, D.; Graña, M.; Savio, A.; Maiora, J. Hybrid dendritic computing with kernel-LICA applied to Alzheimer’s disease detection in MRI. Neurocomputing 2012, 75, 72–77. [Google Scholar] [CrossRef]
- Coupé, P.; Eskildsen, S.F.; Manjón, J.V.; Fonov, V.S.; Collins, D.L.; The Alzheimer’s Disease Neuroimaging Initiative. Simultaneous segmentation and grading of anatomical structures for patient’s classification: Application to Alzheimer’s disease. NeuroImage 2012, 59, 3736–3747. [Google Scholar]
- Cho, Y.; Seong, J.K.; Jeong, Y.; Shin, S.Y.; The Alzheimer’s Disease Neuroimaging Initiative. Individual subject classification for Alzheimer’s disease based on incremental learning using a spatial frequency representation of cortical thickness data. Neuroimage 2012, 59, 2217–2230. [Google Scholar] [CrossRef] [PubMed]
- Cheng, B.; Zhang, D.; Shen, D. Domain transfer learning for MCI conversion prediction. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2012, Proceedings of the 15th International Conference on Medical Image Computing and Computer-Assisted Intervention, Nice, France, 1–5 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 82–90. [Google Scholar]
- Savio, A.; Grańa, M.; Villanúa, J. Deformation based features for Alzheimer’s disease detection with linear SVM. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Wrocław, Poland, 23–25 May 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 336–343. [Google Scholar]
- Westman, E.; Simmons, A.; Muehlboeck, J.S.; Mecocci, P.; Vellas, B.; Tsolaki, M.; Kłoszewska, I.; Soininen, H.; Weiner, M.W.; Lovestone, S.; et al. AddNeuroMed and ADNI: Similar patterns of Alzheimer’s atrophy and automated MRI classification accuracy in Europe and North America. Neuroimage 2011, 58, 818–828. [Google Scholar] [CrossRef] [PubMed]
- Chyzhyk, D.; Graña, M. Optimal hyperbox shrinking in dendritic computing applied to Alzheimer’s disease detection in MRI. In Soft Computing Models in Industrial and Environmental Applications, 6th International Conference SOCO 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 543–550. [Google Scholar]
- Chupin, M.; Gérardin, E.; Cuingnet, R.; Boutet, C.; Lemieux, L.; Lehéricy, S.; Benali, H.; Garnero, L.; Colliot, O.; The Alzheimer’s Disease Neuroimaging Initiative. Fully automatic hippocampus segmentation and classification in Alzheimer’s disease and mild cognitive impairment applied on data from ADNI. Hippocampus 2009, 19, 579. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | MP-RAGE |
|---|---|
| TR (ms) | 9.7 |
| TE ( ms) | 4 |
| Flip Angle (°) | 10 |
| TI (ms) | 20 |
| TD (ms) | 200 |
| Orientation | Sagittal |
| Thickness, gap (mm) | 1.25, 0 |
| Slice No. | 128 |
| Resolution | 256 × 256 |
| Condition | No. | Gender | Education | Socioeconomic Status | Age | CDR | MMSE | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Range | Mean | 0 | 0.5 | 1 | 2 | Range | Mean | |||||
| Very mild to mild AD | 49 | Both | 2.63 | 2.94 | 66–96 | 78.08 | 0 | 31 | 17 | 1 | 15–30 | 24 |
| Normal condition | 49 | Both | 2.87 | 2.88 | 65–94 | 77.77 | 49 | 0 | 0 | 0 | 26–30 | 28.96 |
| Approach | Year | Dataset | Modalities | Validation Method | Metric | ||
|---|---|---|---|---|---|---|---|
| Accuracy (%) | Sensitivity (%) | Specificity (%) | |||||
| Our Method | 2017 | OASIS | MRI | semi-supervised method using 25% of the whole data set as training data ★ | 93.86 | 94.65 | 93.22 |
| Hosseini-Asl et al. [10] | 2016 | ADNI | MRI | 10-fold cross-validation | 90.8 | n/a | n/a |
| Zu et al. [42] | 2016 | ADNI | PET+MRI | 10-fold cross-validation | 80.26 | 84.95 | 70.77 |
| Moradi et al. [43] | 2015 | ADNI | MRI | 10-fold cross-validation | 82 | 87 | 74 |
| Liu et al. [5] | 2015 | ADNI | MRI | 10-fold cross-validation | 71.98 | 49.52 | 84.31 |
| Suk et al. [3] | 2014 | ADNI | PET+MRI | 10-fold cross-validation | 85.7 | 99.58 | 53.79 |
| Casanova et al. [44] | 2013 | ADNI | Only cognitive measures | 10-fold cross-validation | 65 | 58 | 70 |
| Chyzhyk et al. [45] | 2012 | OASIS | MRI | 10-fold cross-validation | 74.25 | 96 | 52.5 |
| Coupé et al. [46] | 2012 | ADNI | MRI | Leave-one-out cross-validation | 74 | 73 | 74 |
| Cho et al. [47] | 2012 | ADNI | MRI | Independent test set | 71 | 63 | 76 |
| Cheng et al. [48] | 2012 | ADNI | MRI | 10-fold cross-validation | 69.4 | 64.3 | 73.5 |
| Savio et al. [49] | 2011 | OASIS | MRI | 10-fold cross-validation | 84 | 90 | 77 |
| Westman et al. [50] | 2011 | ADNI | MRI | 10-fold cross-validation | 59 | 74 | 56 |
| Chyzhyk et al. [51] | 2011 | OASIS | MRI | 10-fold cross-validation | 69 | 81 | 56 |
| Savio et al. [32] | 2009 | OASIS | MRI | 10-fold cross-validation | 83 | 74 | 92 |
| Chupin et al. [52] | 2009 | ADNI | MRI | Independent test set | 64 | 60 | 65 |
| García-Sebastián et al. [33] | 2009 | OASIS | MRI | Independent test set | 80.61 | 89 | 75 |
| Savio et al. [34] | 2009 | OASIS | MRI | 10-fold cross-validation | 85 | 78 | 92 |
| Feature vector size | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | 100 | 200 | 1000 |
| Accuracy(%) | 92.33 | 93.15 | 93.37 | 93.42 | 93.75 | 93.86 | 93.84 | 93.75 | 93.77 | 93.70 | 93.63 | 93.77 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khajehnejad, M.; Saatlou, F.H.; Mohammadzade, H. Alzheimer’s Disease Early Diagnosis Using Manifold-Based Semi-Supervised Learning. Brain Sci. 2017, 7, 109. https://doi.org/10.3390/brainsci7080109
Khajehnejad M, Saatlou FH, Mohammadzade H. Alzheimer’s Disease Early Diagnosis Using Manifold-Based Semi-Supervised Learning. Brain Sciences. 2017; 7(8):109. https://doi.org/10.3390/brainsci7080109
Chicago/Turabian StyleKhajehnejad, Moein, Forough Habibollahi Saatlou, and Hoda Mohammadzade. 2017. "Alzheimer’s Disease Early Diagnosis Using Manifold-Based Semi-Supervised Learning" Brain Sciences 7, no. 8: 109. https://doi.org/10.3390/brainsci7080109
APA StyleKhajehnejad, M., Saatlou, F. H., & Mohammadzade, H. (2017). Alzheimer’s Disease Early Diagnosis Using Manifold-Based Semi-Supervised Learning. Brain Sciences, 7(8), 109. https://doi.org/10.3390/brainsci7080109