1. Introduction
COVID-19, also known as new coronavirus disease, is a severe respiratory acute syndrome in humans caused by the positive strand RNA SARS-CoV-2 virus which belongs to the beta-coronavirus family (β-CoVs) and which became a severe epidemic, currently having taken more than a million lives and infected close to fifty one million people worldwide between December 2019 and November 2020 [
1]. The family of CoVs is a class of enveloped positive-sense single-stranded RNA viruses having an extensive range of natural origins. These viruses can cause respiratory, enteric, hepatic, and neurologic diseases.
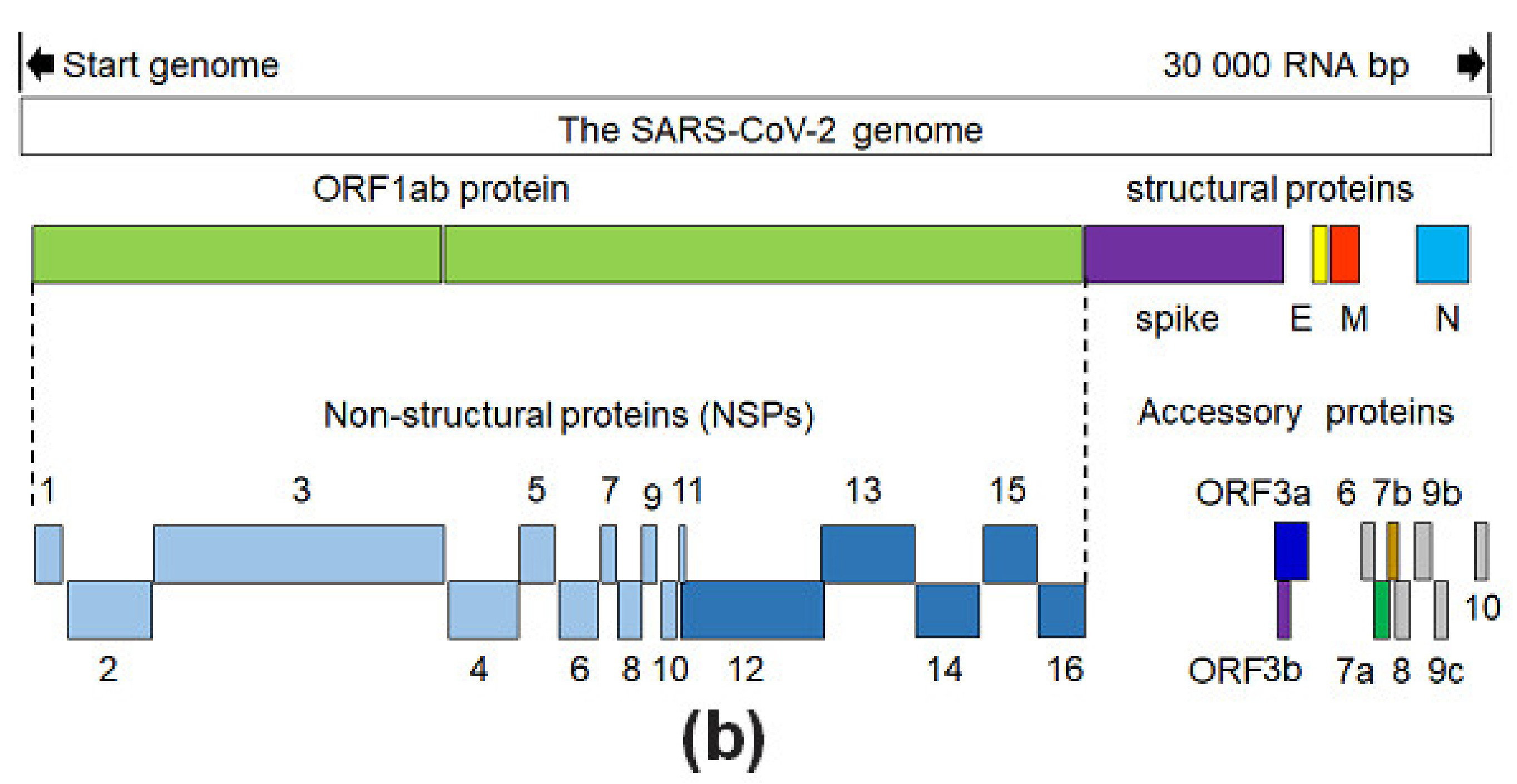
The SARS-CoV-2 is composed of a 30 kb genome coding for sixteen non-structural proteins (NSPs), four structural proteins (SPs) named S, E, M and N, as well as some accessory proteins (APs) under control of ten open reading frames (ORFs). Genome organization of SARS-CoV-2 is known as 5′-leader-UTR-replicase-S(Spike)-E(Envelope)-M(Membrane)-N(Nucleocapsid)-3′-UTR-poly(A) tail. Accessory genes are interspersed within the structural genes at the 3′-end of this genome. The first Wuhan (people’s republic of China) SARS-CoV-2 virus isolated was reported and stored under the National Center of Biotechnology Information (NCBI), U.S. National Library of Medicine, as the reference sequence coded NC_045512.2. Then, worldwide virus sequence isolates were reported including Brazil (EPI_ISL_412964 and EPI_ISL_412964), Italy (MT066156.1), and Colombia (EPI_ISL_417924) as being the eighth most infected nation in agreement with data from more than 180 countries. Population genetic evaluations of more than 100 SARS-CoV-2 genome sequences, shown that this virus family possess two major lineages known as S and L, the L being more prevalent than the S lineage.
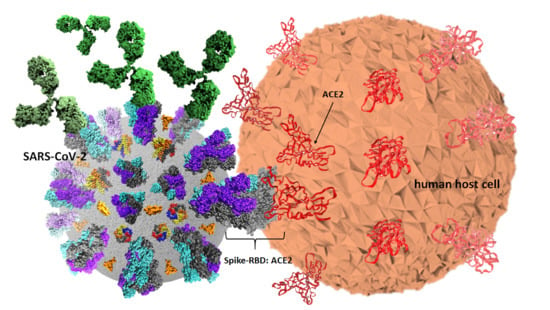
Among structural proteins, a capsid containing the positive single strand (ss) viral RNA anchor a protein termed spike (S) coded by the ORF2 which is a 1288 amino-acids protein of apparent molecular weight of 142 kDa (GeneID: 43740568) [
2]. Spike is composed of two S1 (700 amino-acids) and S2 (600 amino-acids) sub-units. S1 includes the receptor binding domain (RBD) from 333 to 527 position, which binds its human receptor to the angiotensin converting enzyme 2 (ACE2), a protein which is ubiquitously present in almost all human cells, tissues and organs including lungs, hearth, liver and kidneys. Three S1/S2 hetero dimers are assembled to form a trimer spike protruding from the viral envelope. The spike trimeric molecular arrangement on each single chain contains an ectodomain composed of sites 1 and 2 responsible for receptor binding and cell entry having a Kd of ~15 nM [
3,
4]. Interestingly, a highly conserved cryptic epitope on the spike RBD was identified [
5]. Recently, evidence demonstrating that SARS-CoV-2 cell entry through ACE2 can be inhibited by specific compounds was reported [
6].
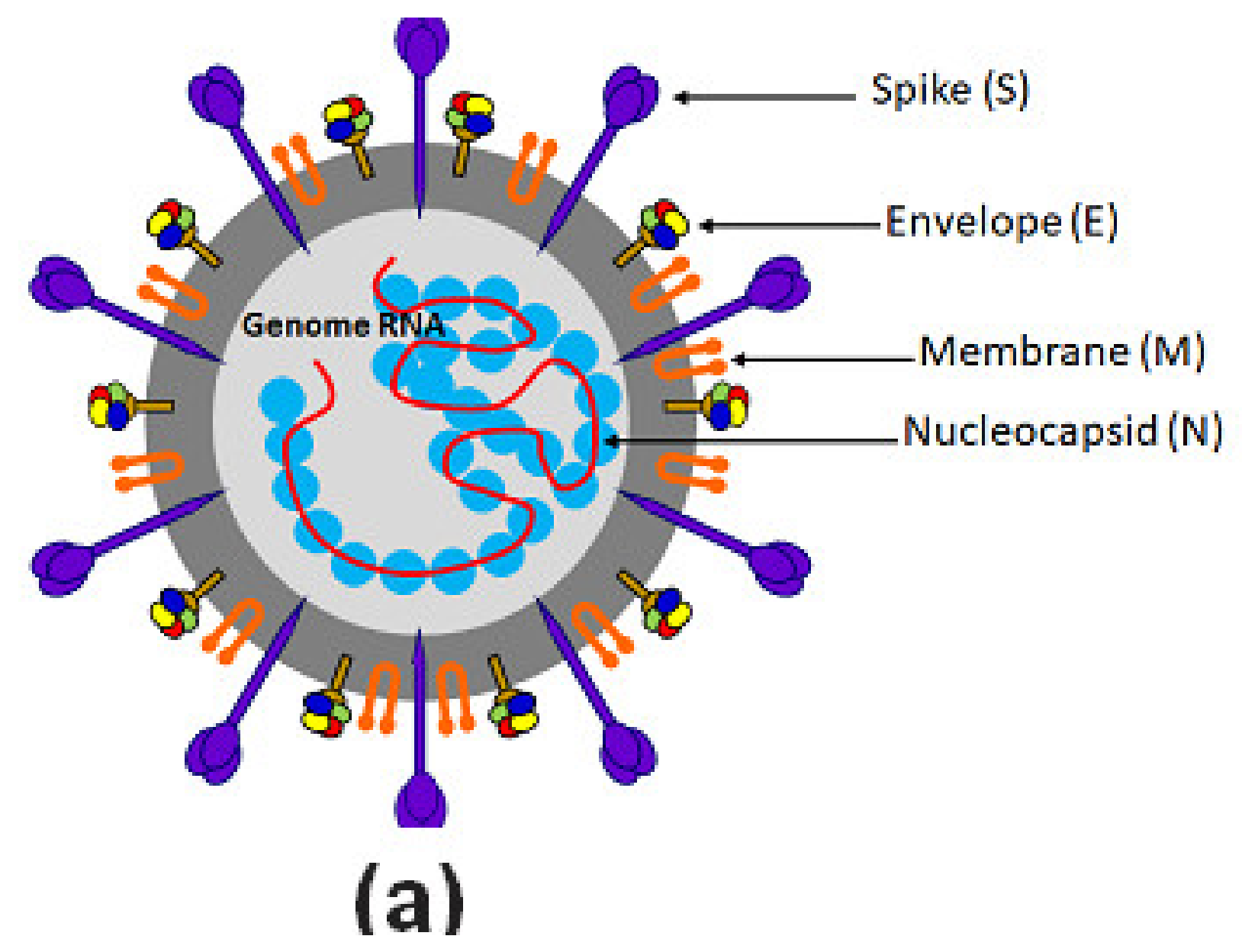
It is known that the virus unit ranges between 60~100 nm of apparent diameter and appears round shaped. A simple scheme for genome and structure organization for the SARS-CoV-2 can be observed in
Figure 1a. The virus harbors 10 open reading frames (ORFs) coding for all structural, non-structural, and accessory proteins as described in
Figure 1b.
The S protein of SARS-CoV-2 belongs to a transmembrane glycoprotein family having a predicted size of 1255 amino-acids possessing a leader sequence from residues 1 to 14, an ectodomain from residues 15 to 1190, a transmembrane domain from 1191 to 1227 residue, and a short intracellular tail from 1227 to 1255 residue, as described elsewhere. Interestingly, the trimeric spike structure conformation possesses both a closed and an open form as recently published [
7]. Structure coordinate files for both the open and closed spike protein-states were stored under codes 6vsb and 6vxx, respectively, in the protein data bank (PDB). The spike RBD- ACEII 3D structure-complex was deeply studied and filed with the 6m0j PDB code [
8,
9].
Likewise, an envelope E gene is coded by the ORF4. E protein is a small polypeptide (76–109 amino acids) of apparently 10 kDa molecular weight and a pI of 8.57 and contains a single alpha-helical transmembrane domain. It is arranged as a pentamer protein on the virus capsid surface and has been identified as YP_009724392.1 (GeneID: 43740570) and its 3D structure coordinates were stored (PDB code 5x29) [
9]. The E gene expression medium size polypeptide product is known as a non-glycosylated small transmembrane protein, and it appears to act as a molecular engine promoting the SARS-CoV-2 assembling in the host cytosolic compartments such as Golgi complex and the endoplasmic reticulum [
10].
A virus matrix named M protein, is coded by the ORF5, and identified as YP_009724393.1 (GeneID: 43740571), is a glycoprotein of 25–30 kDa and is highly abundant on the virus surface. It is known that M interacts with E protein, and so it seems to be relevant for the SARS-CoV-2 maturation, as such M becomes a key piece for the virus assembling. To date, the M protein 3D structure properties have not been reported to the PDB.
On the other hand, a nucleocapsid phospho-protein known as N is coded by the ORF9 (GeneID: 43740575). This gene’s expression product has a molecular weight between 45 and 50 kDa (YP_009724397.2). It is known that N is the most conserved among all structure proteins of coronaviruses, it appears to be required in virus RNA encapsidation, and it seems to be relevant for the virus replication. Protein dimers of N are assembled in hexamers and such complexes’ 3D structure coordinates have been stored under PDB codes 6m3m and 6 wkp, respectively [
9].
The membrane proteins S, E and M are inserted into the intermediate compartment of the virus capsid while the viral RNA undergoes replication as being assembled in the N protein. This RNA-protein complex is associated with the endoplasmic reticulum membrane-inserted M protein, allowing the virus to assemble and migrate to the Golgi complex and an eventual virus release from the host cell can occur by exocytosis.
Additionally, 16 non-structural proteins (NSPs) are coded by ORF1a/1b and actively participate in the virus RNA replication. Some accessory proteins of non-well understood functions are coded by genes from ORF3a, 3b, 6, 7a, 7b, 8, 9b, 9c and 10. All SARS-Cov-2 protein 3D structures were revised from their primary sources [
11].
On the other hand, a global effort started with more than 140 vaccine candidate proposals for a SARS-CoV-2 vaccine but only two have been currently approved despite lacking safety information thereof. The most promising 37 vaccine candidates were focused on approaches based on non-replicating RNA virus vectors and inactivated virus, and a few of them are viral inserts on double-stranded foreign DNA, and others presented as recombinant protein sub-units, most of them based on the spike protein structure [
12]. To date, most of these vaccine candidates are enrolled on Phases I/II/III clinical trials evidencing encouraging results. However, these candidates’ safety and potency become a real concern for the scientific community [
13,
14]. Due to the importance of having vaccine candidates able to be used in large human populations, synthetic strategies emerged as an alternative pathway towards specific, safe and efficient vaccine candidates. In addition, animal models and ex vivo SARS-CoV-2 virus neutralization tests for assaying COVID-19 vaccine candidate stimulated antibodies are relevant matters which are undergoing testing world-wide.
In the present work, we present evidence of antigenic activity of synthetic site-directed designed components based on SARS-CoV-2-structure when faced with the antibodies of patients with COVID-19, revealing the potential of an envisioned strategy towards infection detection, and virus vaccine candidate selection. Evidence of long-lasting antibody immunity is briefly discussed.
2. Materials and Methods
2.1. Virus Genome, Amino-Acid Sequence Analyses and Target Epitopes Designing
Worldwide, SARS-CoV-2 reported genomes were the basis for designing and obtaining the main amino-acid sequences and peptides reported in the present work. Therefore, genome data to isolate the SARS-CoV-2 virus and sequencing information was downloaded from NCBI and GISAID databases [
11,
15].
A second step, consisting of a multiple sequence alignment of mostly SARS-CoV-2 reported genomes was performed using the Clustal omega tool of EMBL-EBI, Wellcome Genome Campus, Hinxton, Cambridgeshire, UK and led to the establishment of a ≥ 96% identity value among all compared sequences. Hence, a Basic Local Alignment Search Tool (BLAST) from the NCBI National Center for Biotechnology Information, U.S.A, led to the performance of sequence analyses for all ORFs coding for structural, non-structural and accessory SARS-CoV-2 proteins.
Subsequent in silico analyses consisted of submitting each ORF coding sequence to identify the presence of possible LB epitopes, including the presence of proteasome cleavage sequence sites, HLA-I and HLA-II different length binding epitope sequences regarding endosomal and phagosome-lysosome protease cleavage sites, by accessing remote servers for B-cell epitope prediction, also known as B lymphocyte epitopes as linear arrangements thereof or Linear B (LB) epitope prediction with LBtope and ABCpred main page bearing a threshold: 0.51. Other bioinformatics tools used were used for B-cell epitope prediction [
16,
17,
18].
For predicting proteasome cleavage, the IEDB server was employed [
19]. HLA-I binding motifs were analyzed with netMHCpan v4.0 and NetMHCpan-2.3 servers. HLA-II binding motifs from SARS-CoV-2 were analyzed with the netMHCpan v3.2 and a IEDB tool were also employed. To identify phagosome-lysosome protease cleavage sites the PROSPER server was used [
20,
21,
22,
23,
24].
For obtaining target sequences to be synthesized, more than 100 amino-acid sequences in a range from 10 to 23 residues in length passed the first design filter, and some selection criteria were then considered, including those potential epitopes showing binding scores from 50 to 100 nM. Those sequences which had simultaneously identified both proteasome cleavage sites, LB epitopes and HLA-I binding sequences were pre-selected. Among preliminary sequences from this filter, those matching HLA-II binding sequences, proteasome including potential phagosome-lysosome cleavage sites, were regarded for a further selection step. A molecular map consisting of all the preliminary sequences from each SARS-CoV-2 consensus ORFs was built and those coincidences among susceptible and resistant infection HLA-I and HLA-II were assessed as inclusion criteria to be considered in the selection list. Considerations regarding HLA haplotype global distribution and their impact on resistance and sensitivity to SARS-CoV-2 infection led us to define the candidate proposal among all sequence candidates. The non-polymorphic-screened unique sequences were regarded as the source of a final preliminary antigen list consisting of 15 different epitope-peptides to be synthesized by solid phase peptide synthesis by standard Fmoc (9-methyl fluorenylmethoxycarbonyl) procedures based on literature reported elsewhere [
25].
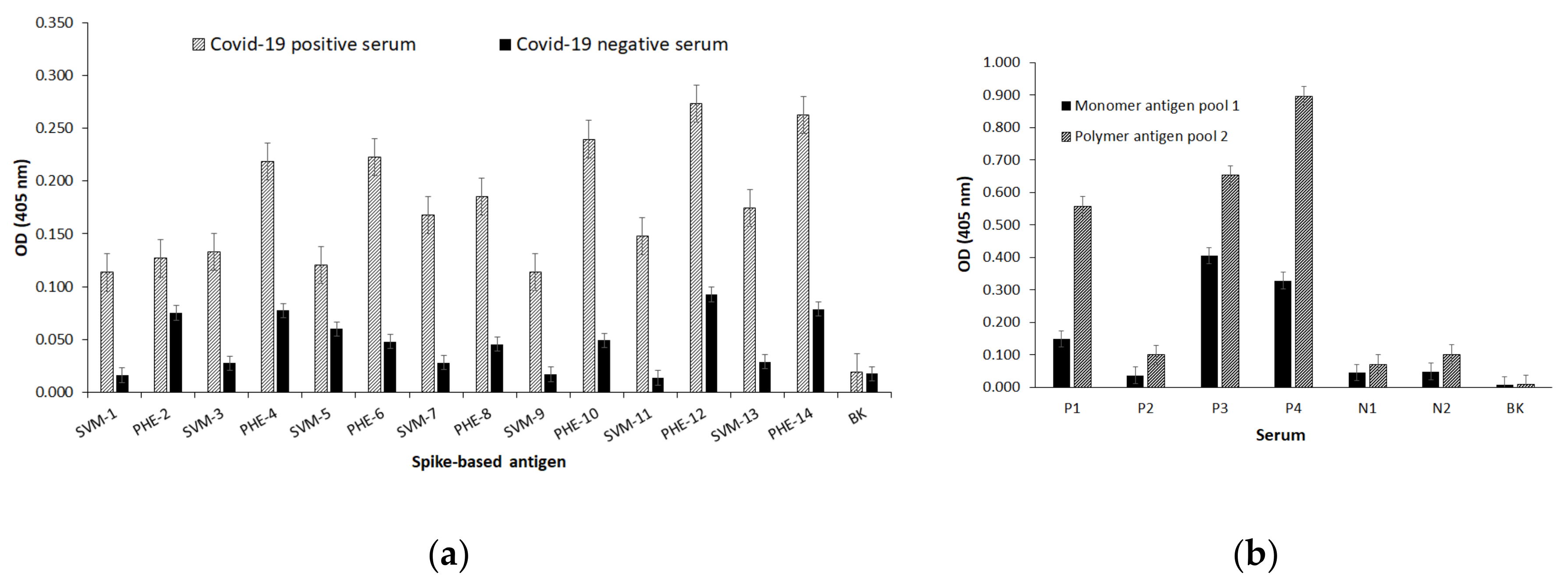
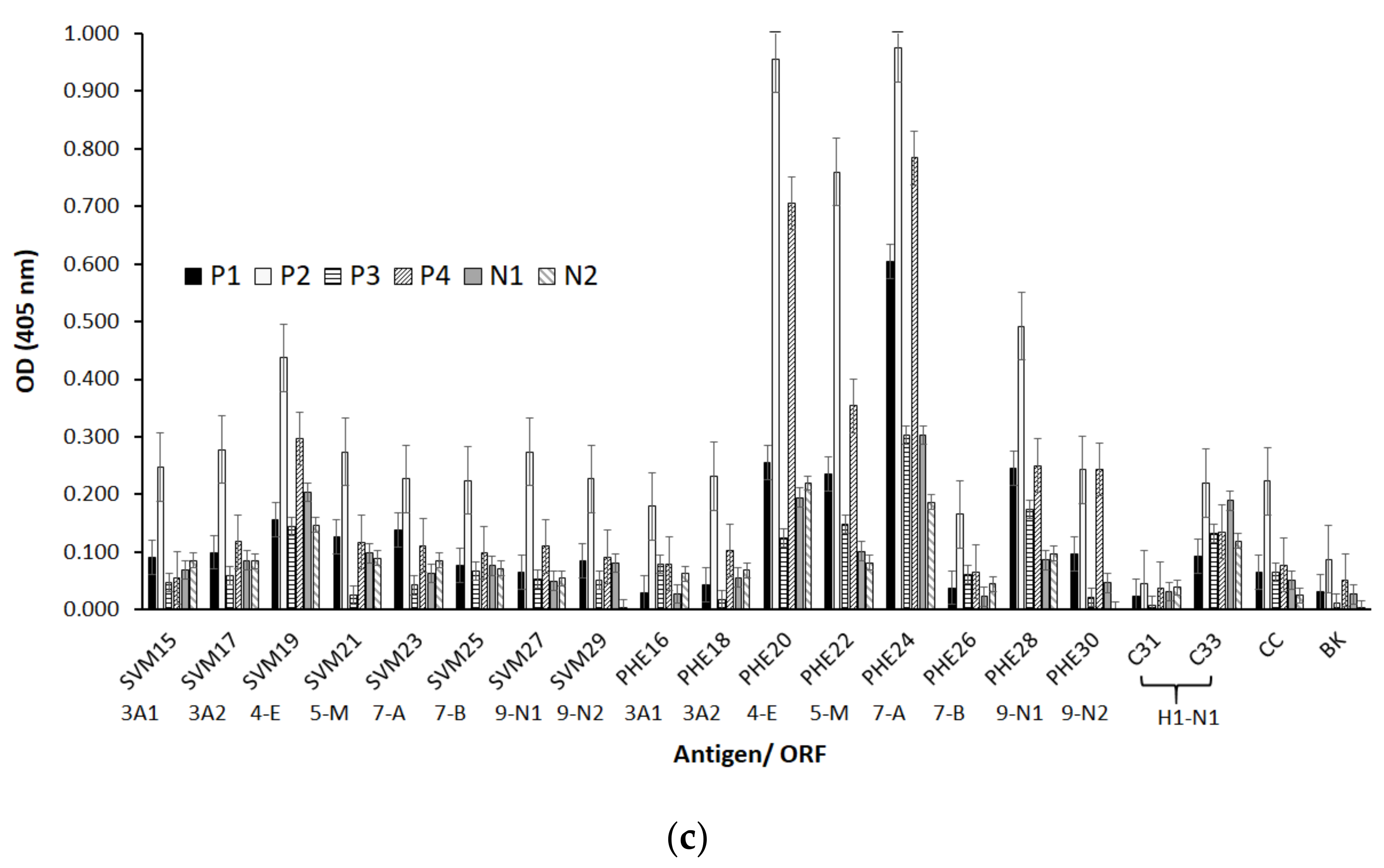
Representative peptides from structural and accessory ORFs-expressed proteins of SARS-CoV-2 were then modified by some amino-acid substitutions at given residue positions. Thus, different length peptides ranging from 10 to 23 residues from ORFs 2, 3a, 3b, 4, 5, 7a, 7b and 9, including accessory and structural S, E, M and N proteins, were selected as the target sequences of this work. Therefore, peptide sequences presented as single monomer and polymer forms were designed. Monomer peptide sequences are represented by the single-viral-motif (SVM) code beside an odd number and their polymer peptide forms are represented by the polymer-hybrid-element (PHE) code besides a pair number. Thus, a single sequence will be named in agreement with its molecular state, the monomer having an odd number and its polymer form with a consecutive even number.
2.2. Synthesis of Monomer and Polymer Forms for Each Epitope-Sequence
Fifteen epitope-sequences were obtained by solid phase synthesis by 9-fluorenylmethoxycarbonyl (Fmoc) strategy as monomer and polymers form for a total of 30 polypeptides. Solvents and soluble reagents were removed by filtration. Washings between deprotection, couplings and subsequent deprotection steps were carried out with N,N′-dimethylformamide (DMF) (5 × 1 min), dichloromethane (DCM) (4 × 1 min), isopropyl alcohol (IPA) (2 × 1 min) and DCM (2 × 1 min) using 1.5 mL of solvent/50 mg of resin each time. The Fmoc group was removed from the resin by two treatments of 15 min with piperidine-DMF (25:75 v/v). Couplings were performed at 20 °C and monitored using standard Kaiser tests for solid-phase synthesis.
For the synthesis of monomer forms, after Fmoc removal of the commercially available Rink amide resin (50 mg, 0.46 mmol/g), the first Fmoc-amino-acid (0.115 mmol, 5.0 equiv.) was added with 1-hydroxybenzotriazole (HOBt) (18.2 mg, 0.115 mmol; 5.0 equiv.) and N,N′-dicyclohexylcarbodiimide (DCC) (23.7 mg; 5.0 equiv.) as coupling reagents dissolved in DMF/DCM (7:3, v/v) and the coupling reaction was stirred for 2 h. Next, the Fmoc group was removed, and a second Fmoc-amino-acid was incorporated in the resin using the same conditions. The Fmoc removal and the coupling reactions of the rest of the Fmoc-amino-acids were carried out under the same conditions using 5 equiv./coupling. Finally, monomer peptide was Fmoc deprotected and cleaved from the resin by treatment with a mixture of trifluoroacetic acid- water- triisopropylsilane (TFA/H2O/TIS) (95.0:2.5:2.5) for 6 h followed by filtration and precipitation with cold diethyl ether (Et2O). Crude products were then triturated 3 times with cold Et2O, dissolved in the system water-acetonitrile (H2O:CH3CN) (9:1 v/v) and then lyophilized.
Synthesis of polymer forms was carried out on 150 mg of Rink-amide resin. In order to further obtain a molecule of high molecular weight represented by a polymer, an active cysteine residue was incorporated at both N- and C- sequence ends. The synthesis of polymer forms was carried out under the same strategy and conditions used for their corresponding monomers (5 equiv./coupling).
Synthesized Cys-peptides were Fmoc deprotected and cleaved from the resin by treatment with a cleavage mixture including ethanedithiol (EDT) in the system TFA/H
2O/TIS/EDT (94.0:2.5:1.0:2.5) for 6 h followed by filtration and precipitation with cold Et
2O. These crude products were then triturated 3 times with cold Et
2O and dissolved in H
2O:CH
3CN (9:1
v/
v) and lyophilized as before. Finally, cysteinyl peptides were submitted to disulfide bridge oxidation to obtain the target polymeric molecular forms. Oxidation was carried out from a peptide solution in water (4 mg/mL, pH 7.0) by an oxygen stream under stirring for 16 h. Polymer peptides obtained were dialyzed in water for 24 h using a 500 Da cellulose acetate membrane and further lyophilized as previously published [
26]. Monomer and polymer SARS-CoV-2 sequences were employed for serological tests with human sera samples, as well as for further biological assays.
2.3. Peptide Characterization
All SARS-CoV-2-based peptide antigen monomer and polymer forms were characterized by analytical reverse phase-high performance liquid chromatograph (RP-HPLC) and analyzed by matrix-assisted laser desorption/ionization- time-of-flight (MALDI-TOF) mass spectrometry. Analytical RP-HPLC was performed using an Agilent 1200 series chromatography system (Agilent Technologies, Inc., Santa Clara, CA, USA). Analyses were performed on a Zorbax® HPLC C18 column (4.6 × 50 mm, 5 µm) (Merck KGaA, Darmstadt, Germany), 1 mL/min rate flow, mobile phase system was A: H2O/TFA (99.9:0.1 v/v); and B: CH3CN/TFA (99.9:0.06 v/v), on a 5% to 95% of B linear gradient during 5 min at a 25 °C temperature and the UV detector was adjusted to 220 nm. A MALDI-TOF mass spectrometry was carried out to the external service to identify a molecular ion of each peptide. Fmoc-Rink Amide MBHA resin and Fmoc-amino-acids were purchased from Iris Biotech GmbH (Marktredwitz, Germany); DCC and HOBt from AAPPTec (Louisville, KY, USA); piperidine, EDT, TIS and TFA were purchased from Sigma–Aldrich (Steinheim, Germany) and Et2O, DMF, DCM, IPA, CH3CN, from Merck KGaA (Darmstadt, Germany). All commercially available reagents and solvents were used as received without further purification. Distilled and deionized water was used for the preparation of all solutions and chromatography eluents.
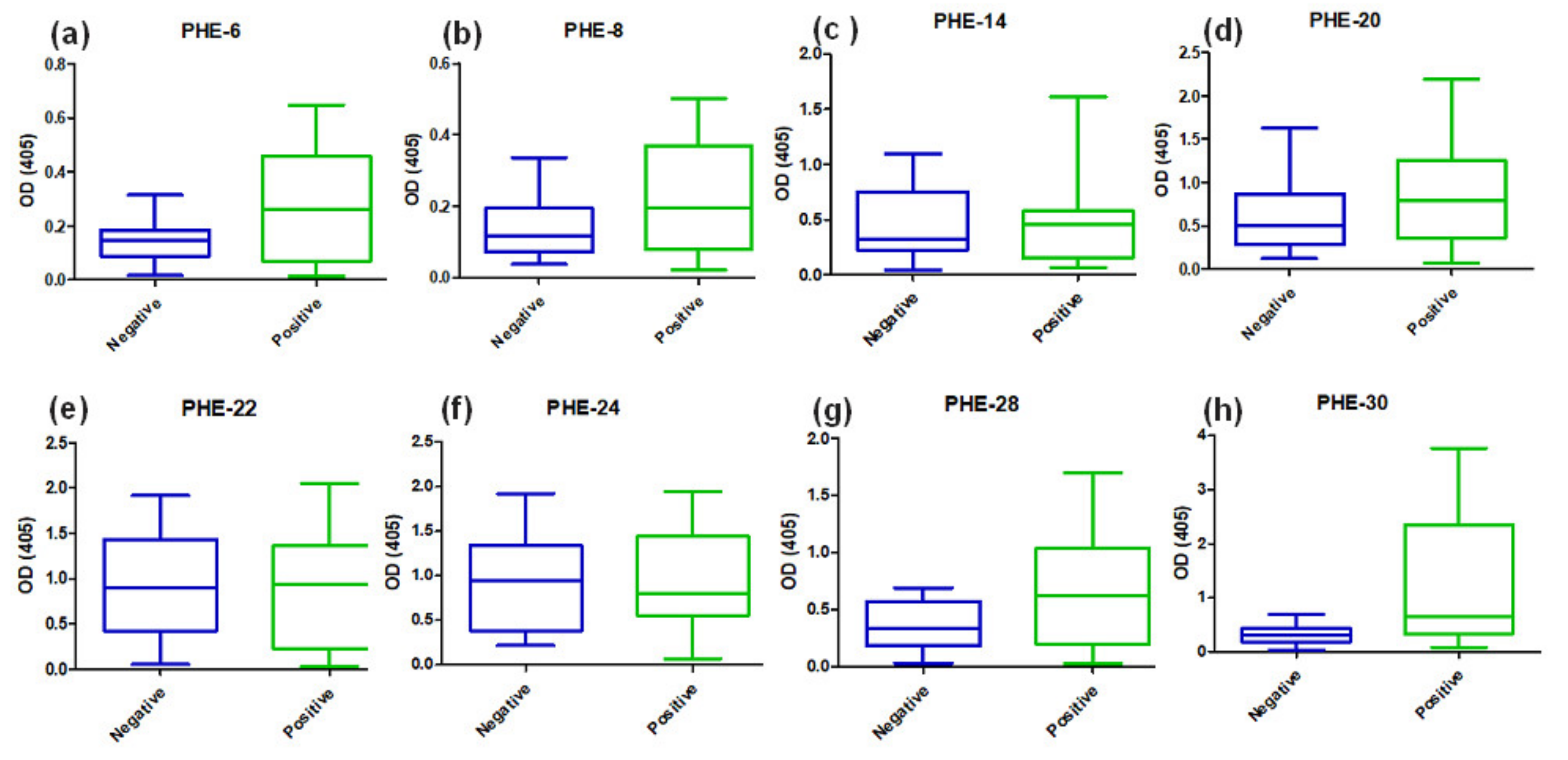
2.4. Serological Test and Statistical Analysis
ELISA standard assays were performed for the detection of antibodies to SARS-CoV-2 from sera samples of humans with COVID-19. Polystyrene 96-flat bottom plates (Thermo Fisher Scientific, Waltham, MA, USA) were immobilized overnight with representative amounts of each synthetic antigen ranging from 5 µg/mL to 40 µg/mL in a carbonates/bicarbonate buffer at a pH of 9.6 at 4 °C. Following washings and non-specific binding blocking steps with a solution of 1–5% of skimmed-milk in 0.15 M (phosphate buffered solution) PBS- 0.05% (
v/
v) tween-20, different dilutions of human sera samples were poured onto peptide-ELISA plate wells and incubated for 1 to 3 h at 37 °C. Then a goat alkaline phosphatase anti human-Ig-conjugate was poured at different dilutions on PBS-Tween-20 and incubated for one-hour at 37 °C to bind specific human antibodies to SARS-CoV-2 epitopes. After performing standard washings, the test was developed with a 1 mg/mL p-nitrophenylphosphate solution in 0.1 M diethanolamine, pH 9.8 to reveal those antibodies’ specific binding to designed virus epitopes by a yellow color appearance which was then detected on a microplate-reader (Multiscan EX
®, Thermo Fisher Scientific, Waltham, MA, USA) adjusted at 405 nm. When necessary, enzyme activity was stopped by adding a 3 N NaOH solution before absorbance reading. Human sera samples were collected under Colombian and international ethical regulations (Presidency of the Republic of Colombia, decree number 266, 2006), in agreement to the world medical association WMA- Declaration of Helsinki of ethical principles for medical research involving human subjects, from either symptomatic or asymptomatic patients with COVID-19, were tested by a standard PCR for a positive viral charge and informed previous blood sampling as reported [
27]. A follow-up for serum antibody conversion was accorded with patients involved in the present research. GraphPad Prism 7 software was used for statistical analyses.
2.5. SARS-CoV-2 Protein Structure Analysis
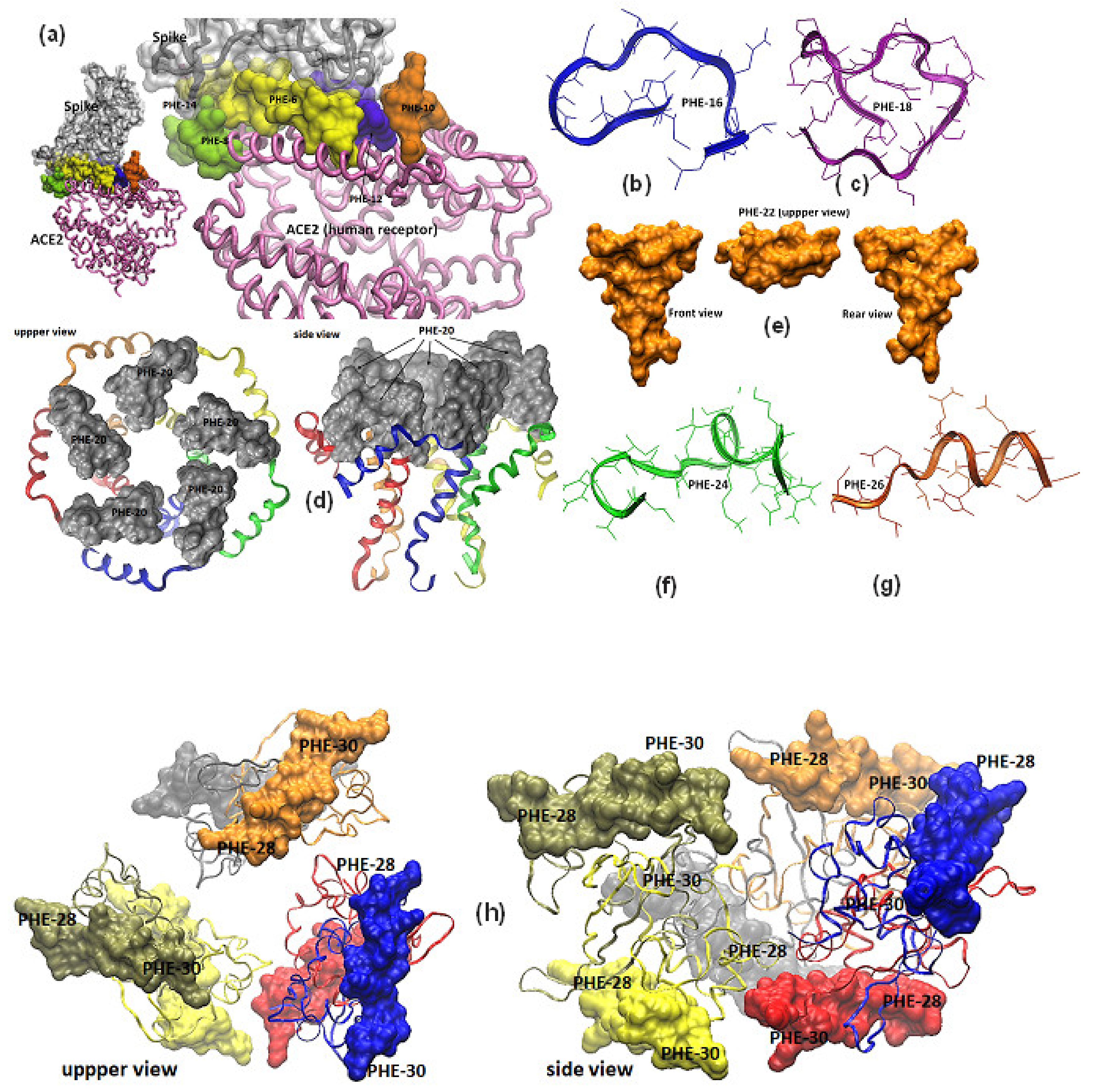
Information of the SARS-CoV-2 ORF gen coding for those 3D structure resolved proteins was obtained [
11], and PDB coordinate files were downloaded from the protein data bank site (PDB) [
10] as mentioned above. Protein molecular modeling and personalization was performed using downloaded available protein coordinate files whose PDD code files were, for S (open and close states 6vsb and 6vxx), S-RBD-ACE II (6m0j), E (5 × 29), M (not yet reported) and N (6m3m and 6 wkp), respectively. For those proteins whose 3D structure has not been reported yet to the PDB, molecular modeling was carried out by submitting epitope-sequences to remote servers to obtain predicted structure- homology models in coordinate files, being the PepFold structure-prediction server selected to fulfill this aim [
28,
29]. Thus, PDB files for representative epitope-peptides and their modified versions for ORF3a, ORF5 (M protein), ORF7a and ORF7b were achieved, all fulfilling the Ramachandran plot structure requirements, as well as the geometrical constraints and restraints parameters for a valid protein structure. Finally, personalized molecular modeling for displaying all PDB 3D structure coordinate files, were allowed by using the VMD 1.9.3 version software, from the NIH Biomedical Research Center for Macromolecular Modeling and Bioinformatics, University of Illinois [
30].
4. Discussion
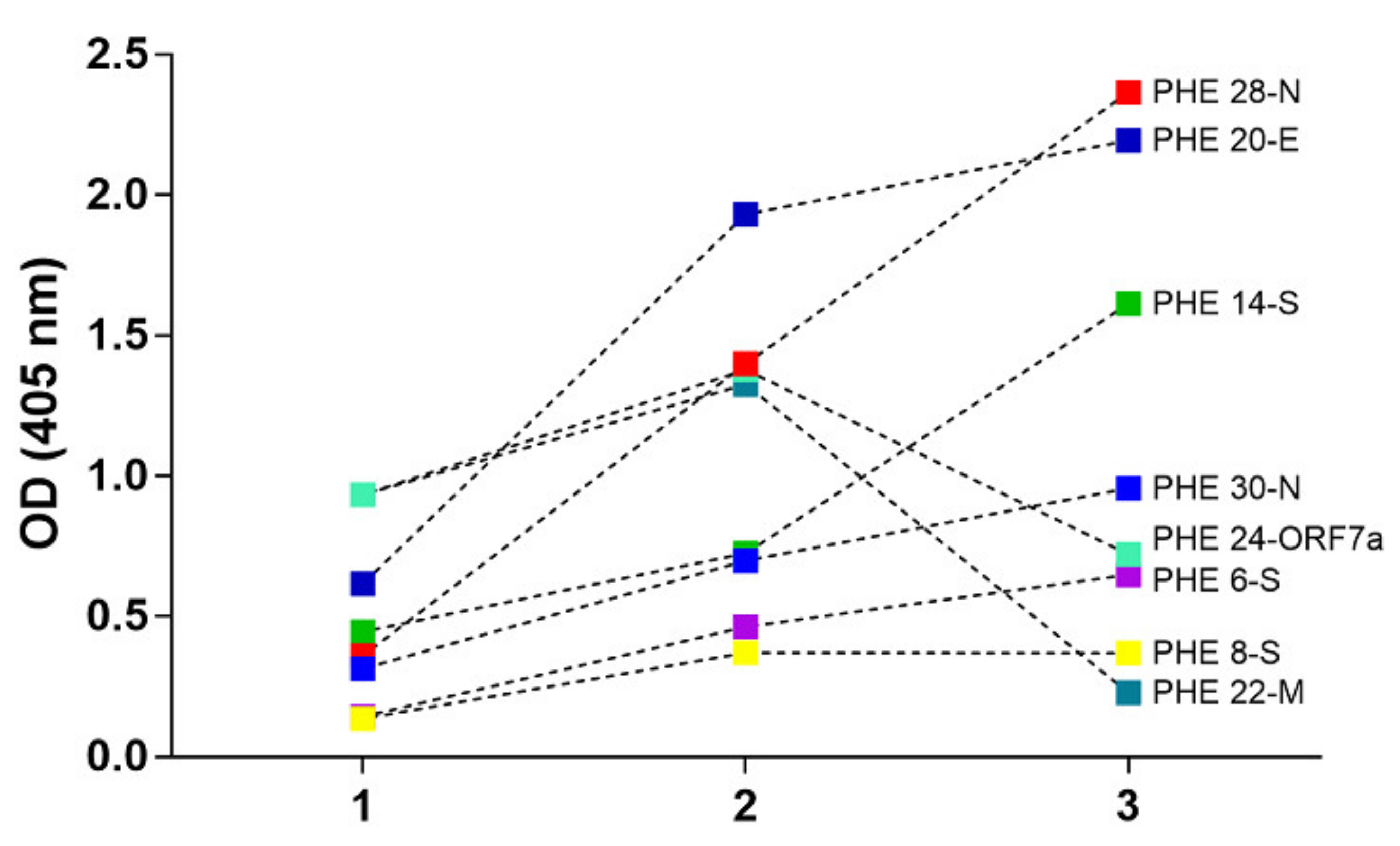
A molecular design aimed to propose some epitope-peptides was conducted considering multiple factors associated with the SARS-CoV-2 virus that is most representative world-wide reported genomes for obtaining a representative virus set of epitopes. Molecular designing steps were built to fulfill hypotheses regarding a proper selection including reasoned on antigen presentation in the classes I and II contexts, as well as proteasome and phagosome-lysosome cleavage preferences and frequencies bearing world populations sensitive and resistant to the virus infection. Bioinformatics tools were useful for this aim, but knowledge and experience in immunogenic molecules design were key pieces for this complex molecular puzzle fixing, which is still in progress beyond this work. A number of sequences higher than one hundred were regarded as key epitope-peptides representative of S, E, M and N proteins as well as expression products from ORFs 3a, 7a, lead to identify 15 target sequences which were then obtained and characterized as being monomer forms herein identified as single-viral-motifs (SVMs), as well as their polymerized forms denoted as polymer-hybrid-elements (PHEs). Interestingly, PHEs were more highly recognized by human antibodies than their monomer counterparts, probably due to the high conformer number of a given sequence presented as a polymer.
Serum samples from COVID-19 diagnosed Colombian patients, assessed by the standard SARS-CoV-2 PCR- based methodology, among those asymptomatic and symptomatic at different clinical conditions, were assessed in seroprevalence studies regarding those selected SARS-CoV-2 epitope-peptides. As observed, antibodies from sera samples were able to differentially recognize the most representative designed epitope-peptides, evidencing in some particular cases a long-lasting immune response to specific epitopes from N, S and E, while the opposite effect can be seen for epitope-peptides from M and ORF7a, this being a controversial matter that should be assessed in further assays, as well as specific B cell clones’ stimulation by given epitopes. Experiments to evaluate antibody-stimulation under controlled vaccination schemes, safety and human adjuvant system formulations of the herein reported epitope-peptides on animal models are undergoing processes in our research group. Increasing the number of individuals from different world regions, ethnicity, gender, age and different clinical status should be further considering as an important step towards finding universal answers to the current COVID-19 pandemic.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






