MEWS++: Enhancing the Prediction of Clinical Deterioration in Admitted Patients through a Machine Learning Model


 , , and
, , and
Abstract
:1. Introduction
2. Patients and Methods
2.1. Phenotyping of Patient Deterioration
2.2. Algorithms Evaluated
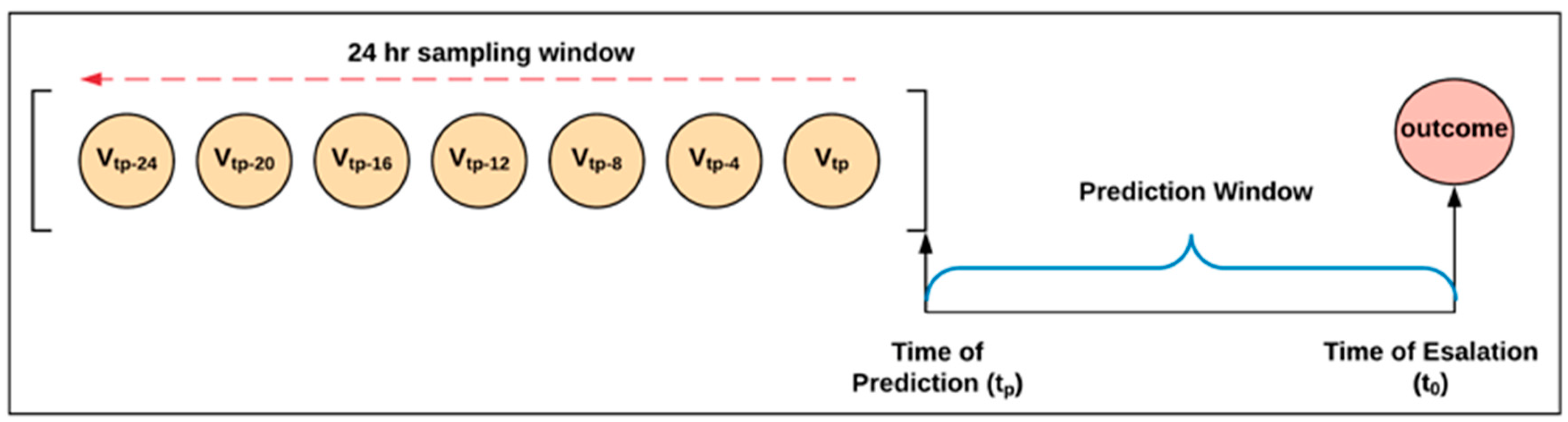
2.3. Defining Optimal Prediction Time
2.4. Data Encoding and Scaling
2.5. Resampling
2.6. Calculation of MEWS Score
3. Model Development
3.1. Feature Selection
3.2. Model Training
3.3. External Model Testing
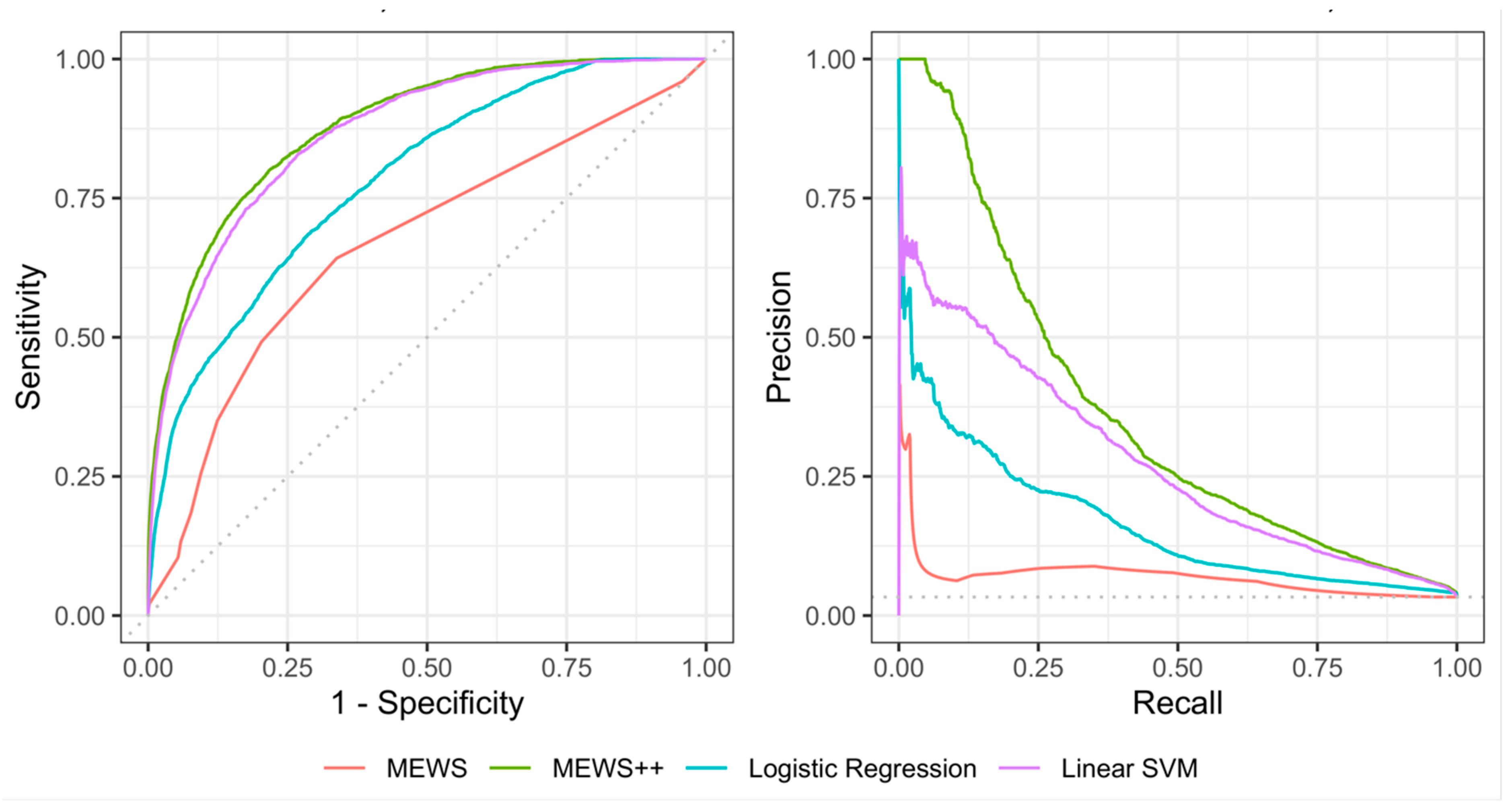
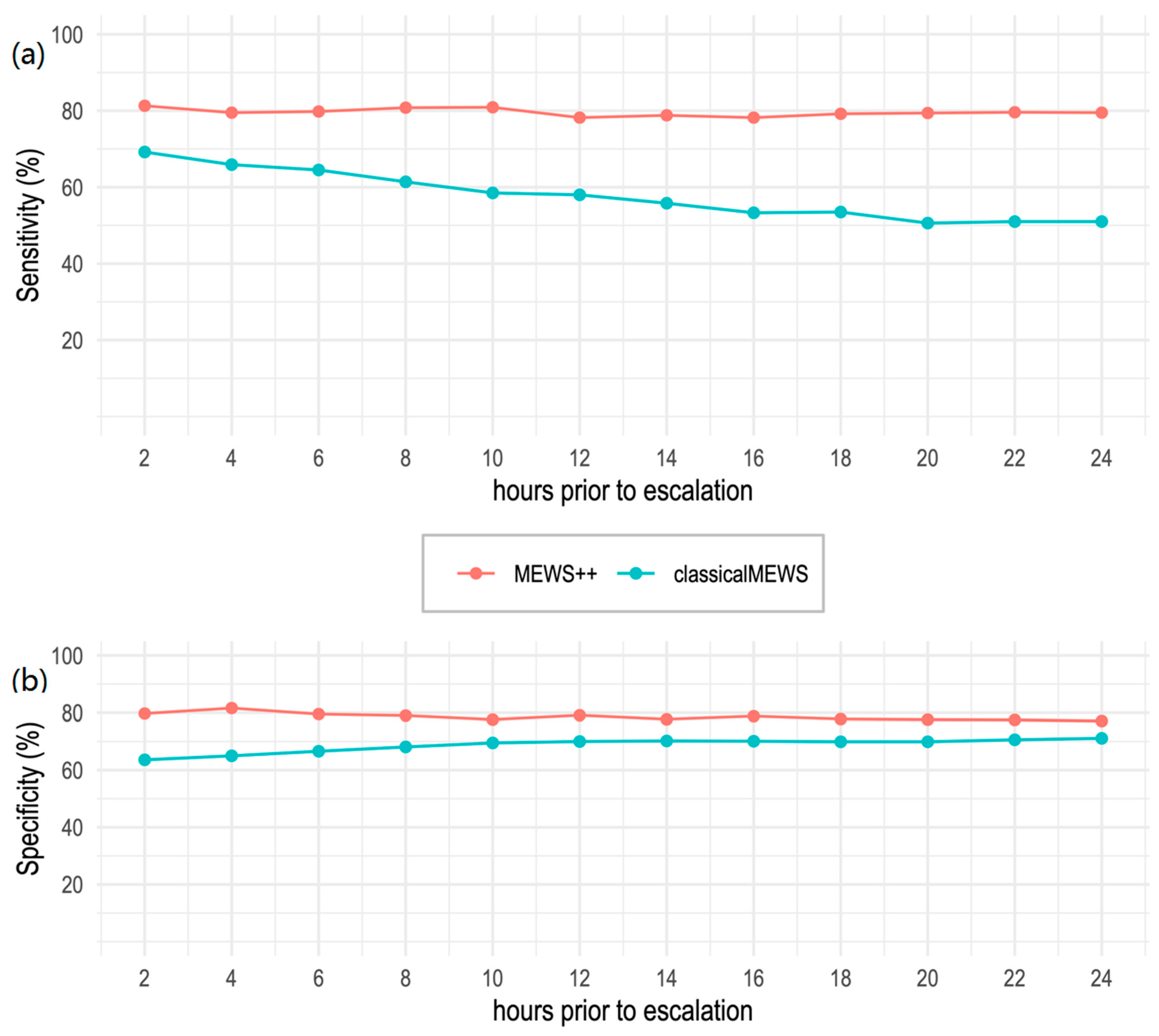
4. Results
Performance of Machine Learning Models at 6 h Prior to Escalation
5. Discussion
Limitations
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Alam, N.; Hobbelink, E.L.; van Tienhoven, A.J.; van de Ven, P.M.; Jansma, E.P.; Nanayakkara, P.W. The impact of the use of the Early Warning Score (EWS) on patient outcomes: A systematic review. Resuscitation 2014, 85, 587–594. [Google Scholar] [CrossRef]
- Brown, H.; Terrence, J.; Vasquez, P.; Bates, D.W.; Zimlichman, E. Continuous monitoring in an inpatient medical-surgical unit: A controlled clinical trial. Am. J. Med. 2014, 127, 226–232. [Google Scholar] [CrossRef]
- Buist, M.; Bernard, S.; Nguyen, T.V.; Moore, G.; Anderson, J. Association between clinically abnormal observations and subsequent in-hospital mortality: A prospective study. Resuscitation 2004, 62, 137–141. [Google Scholar] [CrossRef]
- Hillman, K.M.; Bristow, P.J.; Chey, T.; Daffurn, K.; Jacques, T.; Norman, S.L.; Bishop, G.F.; Simmons, G. Antecedents to hospital deaths. Intern. Med. J. 2001, 31, 343–348. [Google Scholar] [CrossRef]
- McNeill, G.; Bryden, D. Do either early warning systems or emergency response teams improve hospital patient survival? A systematic review. Resuscitation 2013, 84, 1652–1667. [Google Scholar] [CrossRef]
- Subbe, C.P.; Kruger, M.; Rutherford, P.; Gemmel, L. Validation of a modified Early Warning Score in medical admissions. QJM 2001, 94, 521–526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tarassenko, L.; Hann, A.; Young, D. Integrated monitoring and analysis for early warning of patient deterioration. Br. J. Anaesth. 2006, 97, 64–68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rothman, M.J.; Rothman, S.I.; Beals, J. Development and validation of a continuous measure of patient condition using the Electronic Medical Record. J. Biomed. Inform. 2013, 46, 837–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bliss, J.P.; Gilson, R.D.; Deaton, J.E. Human probability matching behaviour in response to alarms of varying reliability. Ergonomics 1995, 38, 2300–2312. [Google Scholar] [CrossRef] [PubMed]
- Cvach, M. Monitor alarm fatigue: An integrative review. Biomed. Instrum. Technol. 2012, 46, 268–277. [Google Scholar] [CrossRef] [Green Version]
- Fleischman, W.; Ciliberto, B.; Rozanski, N.; Parwani, V.; Bernstein, S.L. Emergency department monitor alarms rarely change clinical management: An observational study. Am. J. Emerg. Med. 2019, 158370. [Google Scholar] [CrossRef] [PubMed]
- Bonafide, C.P.; Lin, R.; Zander, M.; Graham, C.S.; Paine, C.W.; Rock, W.; Rich, A.; Roberts, K.E.; Fortino, M.; Nadkarni, V.M.; et al. Association between exposure to nonactionable physiologic monitor alarms and response time in a children’s hospital. J. Hosp. Med. 2015, 10, 345–351. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bedoya, A.D.; Clement, M.E.; Phelan, M.; Steorts, R.C.; O’brien, C.; Goldstein, B.A. Minimal Impact of Implemented Early Warning Score and Best Practice Alert for Patient Deterioration. Crit. Care Med. 2019, 47, 49–55. [Google Scholar] [CrossRef] [PubMed]
- Hu, S.B.; Wong, D.J.L.; Correa, A.; Li, N.; Deng, J.C. Prediction of Clinical Deterioration in Hospitalized Adult Patients with Hematologic Malignancies Using a Neural Network Model. PLoS ONE 2016, 11, e0161401. [Google Scholar] [CrossRef] [Green Version]
- Rubin, J.; Potes, C.; Xu-Wilson, M.; Dong, J.; Rahman, A.; Nguyen, H.; Moromisato, D. An ensemble boosting model for predicting transfer to the pediatric intensive care unit. Int. J. Med. Inform. 2018, 112, 15–20. [Google Scholar] [CrossRef] [Green Version]
- Wikipedia contributors: Major Diagnostic Category. Wikipedia, the Free Encyclopedia. 2017. Available online: https://en.wikipedia.org/w/index.php?title=Major_Diagnostic_Category&oldid=793887852 (accessed on 22 March 2019).
- Mathukia, C.; Fan, W.; Vadyak, K.; Biege, C.; Krishnamurthy, M. Modified Early Warning System improves patient safety and clinical outcomes in an academic community hospital. J. Community Hosp. Intern. Med. Perspect. 2015, 5. [Google Scholar] [CrossRef]
- Ludikhuize, J.; de Jonge, E.; Goossens, A. Measuring adherence among nurses one year after training in applying the Modified Early Warning Score and Situation-Background-Assessment-Recommendation instruments. Resuscitation 2011, 82, 1428–1433. [Google Scholar] [CrossRef]
- Yu, S.; Ma, Y.; Gronsbell, J.; Cai, T.; Ananthakrishnan, A.N.; Gainer, V.S.; Churchill, S.E.; Szolovits, P.; Murphy, S.N.; Kohane, I.S.; et al. Enabling phenotypic big data with PheNorm. J. Am. Med. Inform. Assoc. 2018, 25, 54–60. [Google Scholar] [CrossRef]
- Hastie, T.; Tibsharani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Science+Business Media: New York, NY, USA, 2009; Available online: http://www.springerlink.com/index/D7X7KX6772HQ2135.pdf (accessed on 15 May 2018).
- Hsieh, C.-J.; Chang, K.-W.; Lin, C.-J.; Keerthi, S.S.; Sundararajan, S. A Dual Coordinate Descent Method for Large-Scale Linear SVM. In Proceedings of the 25th International Conference on Machine Learning—ICML ’08, July 2008; pp. 408–415. Available online: http://portal.acm.org/citation.cfm?doid=1390156.1390208 (accessed on 15 May 2018).
- Fan, R.-E.; Chang, K.-W.; Hsieh, C.-J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A Library for Large Linear Classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Maniruzzaman, M.; Rahman, M.J.; Al-MehediHasan, M.; Suri, H.S.; Abedin, M.M.; El-Baz, A.; Suri, J.S. Accurate Diabetes Risk Stratification Using Machine Learning: Role of Missing Value and Outliers. J. Med. Syst. 2018, 42, 92. [Google Scholar] [CrossRef] [Green Version]
- Spark 2.4.0 ScalaDoc—MinMaxScaler. Available online: http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.ml.feature.MinMaxScaler (accessed on 28 November 2018).
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- The Apache Software Foundation: MLlib: Main Guide—Spark 2.3.0 Documentation. spark.apache.org 2018. Available online: https://spark.apache.org/docs/latest/ml-guide.html (accessed on 22 March 2019).
- Yin, Z.; Zhang, J. Operator functional state classification using least-square support vector machine based recursive feature elimination technique. Comput. Methods Programs Biomed. 2014, 113, 101–115. [Google Scholar] [CrossRef] [PubMed]
- Wheeler, D.S. Is the “golden age” of the “golden hour” in sepsis over? Crit. Care 2015, 19, 10–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ebinger, M.; Kunz, A.; Wendt, M.; Rozanski, M.; Winter, B.; Waldschmidt, C.; Weber, J.; Villringer, K.; Fiebach, J.B.; Audebert, H.J. Effects of golden hour thrombolysis: A Prehospital Acute Neurological Treatment and Optimization of Medical Care in Stroke (PHANTOM-S) substudy. JAMA Neurol. 2015, 72, 25–30. [Google Scholar] [CrossRef]
- Clark, D.E. RA Cowley, the “Golden Hour”, the “Momentary Pause”, and the “Third Space”. Am. Surg. 2007, 83, 1401–1406. [Google Scholar]
- Beam, A.L.; Kohane, I.S. Big data and machine learning in health care. J. Am. Med. Assoc. 2018, 319, 1317–1318. [Google Scholar] [CrossRef]
- Elshawi, R.; Al-Mallah, M.H.; Sakr, S. On the interpretability of machine learning-based model for predicting hypertension. BMC Med. Inform. Decis. Mak. 2019, 19, 146. [Google Scholar] [CrossRef] [Green Version]
- Palczewska, A.; Palczewski, J.; Robinson, R.M.; Neagu, D. Interpreting random forest models using a feature contribution method. In Proceedings of the IEEE Conference on Information Reuse and Integration, San Francisco, CA, USA, 14–16 August 2013; pp. 112–119. Available online: https://ieeexplore.ieee.org/document/6642461 (accessed on 15 May 2018).
- Couronné, R.; Probst, P.; Boulesteix, A.L. Random forest versus logistic regression: A large-scale benchmark experiment. BMC Bioinform. 2018, 19, 270. [Google Scholar] [CrossRef]
- Clifton, L.; Clifton, D.A.; Watkinson, P.J.; Tarassenko, L. Identification of patient deterioration in vital-sign data using one-class support vector machines. In Proceedings of the 2011 Federated Conference on Computer Science and Information Systems, Szczecin, Poland, 18–21 September 2011; pp. 125–131. [Google Scholar]
- Tarassenko, L.; Clifton, D.A.; Pinsky, M.R.; Hravnak, M.T.; Woods, J.R.; Watkinson, P.J. Centile-based early warning scores derived from statistical distributions of vital signs. Resuscitation 2011, 82, 1013–1018. [Google Scholar] [CrossRef]
- Bai, Y.; Do, D.H.; Harris, P.R.E.; Schindler, D.; Boyle, N.G.; Drew, B.J.; Hu, X. Integrating monitor alarms with laboratory test results to enhance patient deterioration prediction. J. Biomed. Inform. 2015, 53, 81–92. [Google Scholar] [CrossRef] [Green Version]
- Escobar, G.J.; Laguardia, J.C.; Turk, B.J.; Ragins, A.; Kipnis, P.; Draper, D. Early detection of impending physiologic deterioration among patients who are not in intensive care: Development of predictive models using data from an automated electronic medical record. J. Hosp. Med. 2012, 7, 388–395. [Google Scholar] [CrossRef] [PubMed]
- Touw, W.G.; Bayjanov, J.R.; Overmars, L.; Backus, L.; Boekhorst, J.; Wels, M.; van Hijum, S.A. Data mining in the Life Sciences with Random Forest: A walk in the park or lost in the jungle? Brief. Bioinform. 2013, 14, 315–326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, K.H.; Kohane, I.S. Framing the challenges of artificial intelligence in medicine. BMJ Qual. Saf. 2019, 28, 238–241. [Google Scholar] [CrossRef] [PubMed]
- Baker, T.; Gerdin, M. The clinical usefulness of prognostic prediction models in critical illness. Eur. J. Intern. Med. 2017, 45, 37–40. [Google Scholar] [CrossRef]
- Steyerberg, E.W.; Vickers, A.J.; Cook, N.R.; Gerds, T.; Gonen, M.; Obuchowski, N.; Kattan, M.W. Assessing the Performance of Prediction Models. Epidemiology (Cambridge Massachusetts) 2010, 21, 128–138. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Total N (%) | Training (%) | Test (%) | p-Value | ||
|---|---|---|---|---|---|
| Bed movements | 117,884 | 15,818 | 102,066 | ||
| Bed movements per encounter | 1.67 ± 1.15 | 1.33 ± 0.76 | 1.59 ± 0.99 | ||
| Unique Patients * | 63,100 | 13,168 | 58,742 | ||
| Age | 18–45 | 19,422 (16.5) | 2107 (13.3) | 17,315 (17.0) | <0.001 |
| 45–65 | 40,942 (34.7) | 5060 (32.0) | 35,882 (35.2) | ||
| 65–80 | 37,596 (31.9) | 5266 (33.3) | 32,330 (31.7) | ||
| >80 | 19,924 (16.9) | 3385 (21.4) | 16,539 (16.2) | ||
| Gender | Female | 58,345 (49.5) | 7760 (49.1) | 50,585 (49.6) | 0.5 |
| Male | 59,532 (50.5) | 8057 (50.9) | 51,475 (50.4) | ||
| Other | 7 (0.0) | 1 (0.0) | 6 (0.0) | ||
| Major Diagnostic Category (MDC) | Circulatory system | 29,904 (25.4) | 3930 (24.8) | 25,974 (25.4) | <0.001 |
| Musculoskeletal system & connective tissue | 12,521 (10.6) | 1291 (8.2) | 11,230 (11.0) | ||
| Nervous system | 8767 (7.4) | 1329 (8.4) | 7438 (7.3) | ||
| Hepatobiliary/pancreas | 7368 (6.3) | 1223 (7.7) | 6145 (6.0) | ||
| Respiratory system | 7094 (6.0) | 1190 (7.5) | 5904 (5.8) | ||
| Infectious & parasitic | 5762 (4.9) | 1327 (8.4) | 4435 (4.3) | ||
| Kidney & urinary tract | 5474 (4.6) | 723 (4.6) | 4751 (4.7) | ||
| Endocrine/nutrition/metabolic | 4207 (3.6) | 513 (3.2) | 3694 (3.6) | ||
| Ear, nose, mouth, and throat | 2859 (2.4) | 319 (2.0) | 2540 (2.5) | ||
| Female reproductive system | 2809 (2.4) | 259 (1.6) | 2550 (2.5) | ||
| Skin, subcutaneous tissue, breast | 2459 (2.1) | 236 (1.5) | 2223 (2.2) | ||
| Other (MDCs with ≤ 2% occurrence) | 28,660 (24.3) | 3478 (22) | 25,182 (24.7) | ||
| Overall length of stay at hospital | ≤5 days | 52,087 (44.2) | 5410 (34.2) | 46,677 (45.7) | <0.001 |
| 5–12 days | 35,210 (29.9) | 4876 (30.8) | 30,334 (29.7) | ||
| 12–42 days | 26,753 (22.7) | 4482 (28.3) | 22,271 (21.8) | ||
| >42 days | 3834 (3.3) | 1050 (6.6) | 2784 (2.7) | ||
| Length of stay by hospital unit | ≤24 h | 52,932 (44.9) | 6699 (42.4) | 46,233 (45.3) | <0.001 |
| 1–3 days | 35,748 (30.3) | 4865 (30.8) | 30,883 (30.3) | ||
| 3–7 days | 20,916 (17.7) | 2833 (17.9) | 18,083 (17.7) | ||
| >7 days | 8288 (7.0) | 1421 (9.0) | 6867 (6.7) | ||
| Length of stay in the ICU | ≤24 h | 2805(28.8) | 198 (27.1) | 2607 (29.0) | 0.36 |
| 1–3 days | 4048 (41.6) | 322 (44.1) | 3726 (41.4) | ||
| 3–7 days | 1928 (19.8) | 134 (18.4) | 1794 (19.9) | ||
| >7 days | 947 (9.7) | 76 (10.4) | 871 (9.7) |
| Model | Sensitivity, % (95% CI) | Specificity, % (95% CI) | Accuracy, % (95% CI) | PPV, % (95% CI) | F1 Score | ROC (95% CI) | AUC PR (95% CI) | p-Value * |
|---|---|---|---|---|---|---|---|---|
| Random Forest (MEWS++) | 78.9 (77.6–80.1) | 79.1 (78.9–79.3) | 79.1 (78.9–79.3) | 11.5 (11.1–11.9) | 0.2 | 87.9 (87.4–88.4) | 36.2 (34.7–37.7) | <0.0001 |
| Linear SVM | 79.0 (77.6–80.3) | 77.9 (77.6–78.1) | 77.9 (77.7–78.2) | 11.0 (10.6–11.4) | 0.19 | 87.3 (86.8–87.9) | 28.7 (27.2–30.2) | <0.00010.16 ** |
| LR | 61.4 (59.8–63.0) | 78.5 (78.3–78.8) | 77.9 (77.7–78.2) | 9.0 (8.6–9.4) | 0.16 | 79.1 (78.4–79.8) | 17.2 (16.0–18.5) | <0.0001 |
| MEWS Score | 64.2 (62.7–65.7) | 66.2 (66.0–66.5) | 66.2 (65.9–66.4) | 6.1 (5.9–6.4) | 0.11 | 66.7 (65.9–67.6) | 7.0 (6.2–7.8) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kia, A.; Timsina, P.; Joshi, H.N.; Klang, E.; Gupta, R.R.; Freeman, R.M.; Reich, D.L.; Tomlinson, M.S.; Dudley, J.T.; Kohli-Seth, R.; et al. MEWS++: Enhancing the Prediction of Clinical Deterioration in Admitted Patients through a Machine Learning Model. J. Clin. Med. 2020, 9, 343. https://doi.org/10.3390/jcm9020343
Kia A, Timsina P, Joshi HN, Klang E, Gupta RR, Freeman RM, Reich DL, Tomlinson MS, Dudley JT, Kohli-Seth R, et al. MEWS++: Enhancing the Prediction of Clinical Deterioration in Admitted Patients through a Machine Learning Model. Journal of Clinical Medicine. 2020; 9(2):343. https://doi.org/10.3390/jcm9020343
Chicago/Turabian StyleKia, Arash, Prem Timsina, Himanshu N. Joshi, Eyal Klang, Rohit R. Gupta, Robert M. Freeman, David L Reich, Max S Tomlinson, Joel T Dudley, Roopa Kohli-Seth, and et al. 2020. "MEWS++: Enhancing the Prediction of Clinical Deterioration in Admitted Patients through a Machine Learning Model" Journal of Clinical Medicine 9, no. 2: 343. https://doi.org/10.3390/jcm9020343
APA StyleKia, A., Timsina, P., Joshi, H. N., Klang, E., Gupta, R. R., Freeman, R. M., Reich, D. L., Tomlinson, M. S., Dudley, J. T., Kohli-Seth, R., Mazumdar, M., & Levin, M. A. (2020). MEWS++: Enhancing the Prediction of Clinical Deterioration in Admitted Patients through a Machine Learning Model. Journal of Clinical Medicine, 9(2), 343. https://doi.org/10.3390/jcm9020343