1. Introduction
Biological invasion is a global environmental change phenomenon, often leading to disruptions of ecosystem goods and services. Biological invasion begins with the introduction of organisms from their native range into a new environment followed by periods of sequential adjustments of colonisation/extinction/recolonisation, establishment and naturalisation [
1,
2,
3,
4,
5]. Where conditions are favourable the exotic species will increase dramatically in abundance and geographical distribution to become invaders with significant impact on nature conservation and agriculture. In Australia, like most regions around the world ~30,000 species have been introduced of which ~10% have become invaders [
2,
5]. One of such invaders, with its origin in the Americas, is the annual plant, (
Parthenium hysterophorus L.) (henceforth referred to as parthenium weed).
In Australia, parthenium weed grows as an annual, herbaceous/shrubby invasive species plant of national significance [
1,
2]. Parthenium weed has a deep-penetrating taproot system and an erect shoot system [
1]. Young plants form a rosette of leaves close to the soil surface. Mature stems are greenish and longitudinally grooved, covered in small stiff hairs (hirsute), and become much-branched at maturity. The alternately arranged leaves are simple with stalks (petioles) up to 2 cm long and form a basal rosette during the early stages of growth. The lower leaves are relatively large (3–30 cm long and 2–12 cm wide) and are deeply divided (bi-pinnatifid or bi-pinnatisect) [
3]. Leaves on the upper branches decrease in size and are also less divided than the lower leaves. As parthenium weed matures, the plant develops many branches on its upper half, and may eventually grow up to two metres. With sufficient rainfall and warm temperature, parthenium weed has the ability to germinate and establish at any time of the year. Flowering usually commences 4–6 weeks after germination and soil moisture seems to be the major contributing factor to flowering [
3]. Parthenium weed is a prolific seed producer and a fully grown plant can produce up to 157,000 seeds in its lifetime, though the majority of plants produce less than 4000 seeds [
3]. Seeds persist and remain viable in the soil for reasonably long periods. The prolonged longevity of seeds of parthenium weed in the soil, coupled with allelopathy effect of varying growth stages of the plant on native plants, efficient dispersal via water (especially during flood) contribute to its spread and hence high invasiveness [
2,
4,
5]. Parthenium weed has an economic impact on Australia’s agriculture and landscape of ~A
$129 million a year [
1]. This includes control costs and production losses to the agricultural sector. Control options such as pasture management, use of biological control agents, and herbicides exist for managing the weed [
6]. However, many of these tactics are limited by their potential environmental impact and the sheer scale of the infestations [
1,
7]. Blanket herbicide spraying has been shown to adversely affect non-target plant species, and can reduce soil fertility; such chemicals also have the potential to migrate into the surrounding environment, impacting animal species and disrupting food chains [
7]. This method of control is also economically unfeasible. Site-specific weed management (SSWM) options using Unmanned Aerial Vehicle (UAV) imagery for weed detection and control have been shown to reduce herbicide use by 14 to 39.2% in Maize fields when compared to conventional uniform blanket spraying [
8]. In this example, an accurate weed map was necessary for efficient SSWM which highlights the importance of an accurate and robust detection method. Autonomous detection methods using red, green, blue (RGB), and hyperspectral imagery (HSI) for weed detection have shown very promising results in both crop and pastoral environments [
9,
10,
11,
12,
13].
Attaining significant accuracy in automated weed recognition is challenging, but is gaining wide currency [
9,
10,
11,
12]. Some work has been done and reported on automated parthenium weed identification and mapping in natural and agricultural settings. In South Africa, at the landscape level, the spatial and temporal distribution of parthenium weed in response to rainfall using multi-year SPOT (Satellite Pour l’Observation de la Terre) data and random forest classification algorithm (one of several machine learning approaches) was explored with the general finding that the satellite images should be combined with UAV to provide higher spatial resolution data for improved detection accuracy [
10]. The use and importance of TPOT (Tree-Based Pipeline Optimization Tool) and other Convolutional Neural Network (CNN) as effective machine learning tools for selecting and fine-tuning algorithms for parthenium weed discrimination and monitoring in pastoral field has also been demonstrated [
9]. Similarly, the use of hyperspectral data for identification of optimal wavelength that are sensitive to discrimination of parthenium weed have been explored [
9,
10]. In most of the above cited cases, overall identification and classification accuracies varied between 68–86%, implying that approaches that may yield higher classification accuracies are still necessary [see also 9] for parthenium weed. In addition, there are no reported studies that have attempted to use machine learning to identify and classify the discernable growth stages (seedling, rosette, and reproductive adults) of parthenium weed.
RGB imagery, captured using a digital camera, imitates the way the human eye perceives colour [
14]. A typical digital single-lens reflex (DSLR) camera is equipped with a Bayer filter system consisting of a mosaic of red, green, and blue filters embedded on the image sensor [
15]. Spatial resolution is another important factor for RGB imagery, particularly for object identification, and refers to the area where individual measurements can be made [
11]. This is measured by ground sampling distance (GSD) which is the area in the real reference plane that is covered by a single pixel in the image. By combining an image sensor with a high number of pixels and a small scene size (often in millimeters), several features of interest can be easily discerned [
16].
Object detection is the procedure of determining the instance of the class to which the object belongs and estimating the location of the object by outputting the bounding box around the object [
17]. This means an object detector needs to distinguish objects of certain target classes from backgrounds in the image with precise localization and correct categorical label prediction to each object instance [
18]. Convolutional Neural Networks (CNNs) have the capacity to learn very complex functions from data with minimal domain knowledge. Combined with large-scale labeled data and graphic processing units (GPUs) with high computational capacity, CNNs have been particularly successful for object detection [
19].
Hyperspectral imaging is an analytical technique based on the study of the chemical and physical behaviour of the reflected or scattered light coming from a specific surface [
20]. This type of imaging goes beyond the conventional image processing and spectroscopy because of its capability to obtain spatially resolved spectra from an object [
21].
The objective of image classification is to recognize and characterize the classes, as a unique colour or gray level, which represents some features. These dissimilar colour classes can also be used to show the spectral characteristics of every unique pixel within the class [
22]. This analysis obtains a colour map that distinguishes materials with different spectral profiles.
In this study, deep-learning algorithms and decision-tree-based protocols are applied to the challenges of automated detection and growth stage classification of invasive alien plants, in our case, to parthenium weed. In this context, we explore the viability of RGB and HSI data of parthenium weed captured in a control environment to aid in its field mapping procedure. Thus, our aim is to provide a platform for more efficient and accurate detection and mapping of parthenium weed using its captured images (in various growth stages: seedlings, rosettes, and reproductive adults) and subjected them to artificial intelligence (AI) algorithms. If the trial is successful, it will lead potentially to the optimisation of management protocols as the weed control cost can be minimised and efficacy improved simultaneously. The findings also have application potential in more complicated pasture and cropping environments where parthenium weed (and other invasive alien plants) are causing significant problems.
2. Materials and Methods
2.1. Preamble
It is hypothesized that deep-learning algorithm of Yolov4 (You Only Look Once version 4) and decision-tree machine learning of XGBoost (Extreme Gradient Boosting version 1.3.3) protocols when applied to their respective data types (RBG and HIS, respectively) will allow for highly accurate detection and growth stage classification of parthenium weed in a controlled environment, and that if successful each technique has the potential to extend to farm-scale and landscape scenarios. In this context, parthenium weed of different growth stages and non-parthenium plants (grasses) were imaged using RGB and HSI cameras. Non-parthenium plants that occur naturally with the weed in the field, including mature kangaroo grass (Themeda triandra Forssk.), and desert bluegrass (Bothriochloa ewartiana (Domin) C.E. Hubb.) were either interspersed with weed and photographed (RGB case) or photographed individually and interspersed digitally (HSI case). Plants were interspersed in this way to simulate how these images would look if captured in the field. There were 665 unique RGB images captured in this process, and these images were labeled with a class (a unique designation for a group of objects) for parthenium plants and a class for parthenium flowers. The combined HSI image was generated and digitally combined to create a combined image, and this was labeled with six classes (so as to separate unique materials)—three for the parthenium weed growth stages of seedling, rosette, and flowering adult, one for the non-parthenium plants (grasses), and two classes for the soil in the pots and concrete ground the pots sat on. Respective datasets were then used to train a Yolov4 detector and an XGBoost classifier (a decision-tree-based ensemble machine learning algorithm that uses a gradient boosting framework). The procedures for the capture and analysis of the RBG and HSI datasets are given below.
2.2. RGB Dataset Preparation
The RGB dataset was created with the aim of simulating what is obtainable in a pastoral environment as closely as possible. Plants were grown from seeds inside a secure temperature-controlled (27/22 ± 2 °C, day/night) glasshouse at the Ecosciences Precinct, Dutton Park (ESP), Brisbane, Australia by Biosecurity Queensland (BQ) staff of the Queensland Department of Agriculture and Fisheries. The plants included parthenium weed at three distinct growth stages, and control plants consisting of several growth stages of kangaroo grass (
Themeda triandra), and desert bluegrass (
Bothriochloa ewartiana). The parthenium weed growth stages used were seedling (<1-month-old), rosette (1–2 months old), and flowering (2–4 months old; see
Figure 1). Seedlings are parthenium weed plants that had not developed the rosette structure, rosette included established parthenium weeds without flowers, and flowering plants included established reproductive parthenium weeds with flowers and/or seeds. In total 8 seedling plants, 6 rosette plants, and 12 flowering plants made up the dataset as well as the 12 individual plants of the grass species mentioned above.
On 4 March 2021, a 1.5 m × 2.25 m area was set up with direct sun exposure outside the glass-house area of ESP, Dutton Park, Brisbane, Australia. Images were captured using a Nikon D2 with a 24–70 mm lens and a focal length of 70 mm. Seedling and rosette plants were imaged first, beginning with no plants in the arrangement and gradually increasing up to five plants per growth stage for imaging. This step was then repeated, first with two non-parthenium or control plants (grasses) up to five control plants. This process was then repeated for flowering plants and finally for a combination of seedlings, rosettes, and flowering plants of the parthenium weed. After these structured arrangements were captured, more complicated arrangements with higher numbers of parthenium weeds of each growth stage and higher numbers of non-parthenium plants were imaged. These complicated arrangements also included high plant occlusion to mimic overlapping which is common in pastoral environments. The resulting dataset contained 665 unique images with parthenium weed and non-parthenium plants in unique arrangements. On 18 March the same process as above was used again to capture another RGB dataset that is completely unique to the training and validation dataset. This resulted in a unique test dataset of 94 images.
2.3. RGB Image Processing
Processing of the RGB images first required the images to be accurately labeled. Labeling was applied to only parthenium weeds with control plants remaining unlabeled. The label convention used was one that grouped flowering and non-flowering parthenium weeds into a single class and a second class for individual flowers. Plants of each growth stage were combined in this way due to their visually similar characteristics while the flower class was used to detect the presence of flowers which was then used to classify flowering and non-flowering plants. Parthenium seedlings remained unlabeled due to their visually indistinct features and very small size (see
Figure 1).
Once labeled, the images were tiled or broken up into smaller images of 1024 × 1024 pixels so they could be used to train a Yolov4 detection network. This size was chosen to reduce the effect of down-sampling done by the detection network whilst ensuring the largest objects could still be represented in a single image, as shown in
Figure 2. Consecutive rows and columns, seen below (
Figure 2b), also have a 50% overlap. This was done so that each plant would be more likely to fall towards the center of the tile and so entire plants could be represented with a single bounding box. This also allowed for the removal of bounding boxes that fall on small fractions of a plant as a result of the tiling process.
After tiling each image, all tiles were checked to remove any inaccurate labels created during the tiling process. Augmentation- a technique of alternating the existing data to create more, unique data for the model training process- was implemented as it provides two benefits in the training stage: (1) it reduces overfitting probabilities by increasing the variability of the features used to make detections; and (2) it increases the size of the training dataset and hence the number of unique objects labeled. Geometric and radiometric augmentations (techniques that can be used to artificially expand the size of a training dataset by creating modified versions of images in the dataset) were applied randomly within predetermined bounds so that all augmented images do not misrepresent how the parthenium weed plants naturally occurs. The augmentation parameters and examples can be seen in
Table 1 and
Figure 3, respectively. The tiling process resulted in a dataset of 27,230 images. This set of images was randomly split using a ratio of 8:2 resulting in a training set of 21,784 images and a validation set of 5446 images. The training set of 21,784 images was then augmented which doubled the size of the training set to 43,568 images. This gives a training to validation ratio of 0.875:0.125, respectively. The second set of independent RBG images taken two weeks after the initial image capture (see above, i.e.,
RBG data preparation section) served as the test dataset (a total of 4230 once the images were tiled) and were used to benchmark the performance of the trained detector using images the detector has never seen before.
2.4. Yolov4 Modelling
To test the performance of current state-of-the-art (SOTA) detectors, several benchmark datasets have been created. Of these, the Microsoft common objects in context (MS COCO) dataset was designed for the detection and segmentation of objects occurring in their natural context [
23]. Yolov4 is a single-stage detector that boasts a mean average precision (mAP) of 65.7% at a detection speed of ~65 frames per second (FPS) when benchmarked on the MS COCO dataset [
24]. Yolov4 is one of the few high-performing detectors capable of real-time object detection which is above 20fps and hence was used in this study [
18].
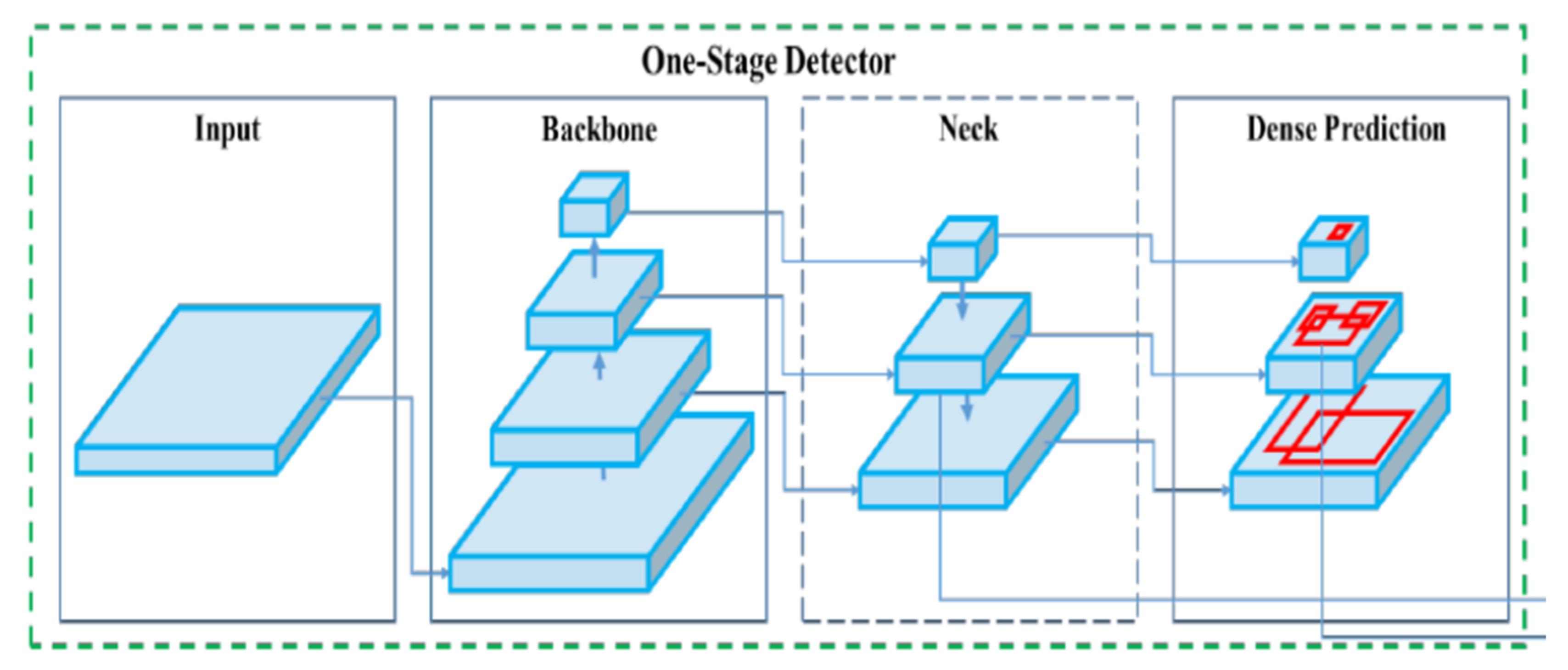
YOLOv4 is a one-stage detector consisting of a CSPDarknet53 backbone, SPP additional block, and PANet path-aggregation neck with YOLOv3 dense predictor for the head as its architecture [
24]. The structure of Yolov4 can be seen below in
Figure 4.
The CSPDarknet53 backbone involves applying a cross-stage partial network of Wang et al. on the Darknet-53 network developed by Redmon & Farhadi [
25,
26]. Darknet-53 performed on par or even better in terms of accuracy, took fewer floating-point operations to train, and performed faster when compared to ResNet-101 and ResNet-153. CSPNet reduced computations by up to 20% with equivalent or higher accuracies when applied to backbones such as ResNet, ResNeXt, and DenseNet.
For the neck, the spatial pyramid pooling (SPP) additional block developed by He et al. eliminates the need for a fixed-size input image [
27]. It does this by computing feature maps from entire images once and generating fixed-length representations for training. SPP has been shown to improve the accuracy of detection networks such as R-CNN and vastly improve processing speed when generating detections. The other part of the Yolov4 neck is PANet path-aggregation developed by Liu et al. [
28]. This works by shortening the information path between lower layers and topmost feature levels. It does this by linking feature grids and all feature levels to make useful information in each level propagate directly to following proposal subnetworks. PANet path-aggregation boasts higher mean average precisions than Mask R-CNN on COCO datasets and ResNet-50 on the MVD dataset.
Finally, the head or dense predictor uses Yolov3 to produce bounding boxes based on dimension clusters as anchor boxes and thus predicts four coordinates for each box [
26]. These predicted bounding boxes are compared to the ground truth bounding boxes and the sum of the squared error loss is used to determine the gradient for regression. Using logistic regression, the predicted bounding box that overlaps with the ground truth the most is chosen. Classes are then predicted using independent logistic classifiers and binary cross-entropy loss. This allows for more accurate class predictions when objects of different classes overlap. Three different scales are used when predicting bounding boxes so that features at different scales can be extracted and combined for a robust feature map. This approach allows for more meaningful semantic information from unsampled features and finer-grained information from earlier feature maps. Lastly, Darknet-53, consisting of 53 convolutional layers is used for the feature extractor. The convolutional layers are successive 3 × 3 and 1 × 1 layers with shortcut connections.
2.5. HSI Dataset Preparation
For the present study, a Headwall Nano-Hyperspec visible and near-infrared (VNIR) image sensor which is a type of push-broom or line scanner, optimized for UAVs, was used. With this scanner, the hyperspectral information is obtained from contiguous lines of the sample by relative movement between the sample and the scanner [
21]. From this, hyperspectral reflectance information is obtained and can be used to determine the structural and biochemical properties of the sample [
29]. The scanner machine was set up inside the ESP glasshouse with some filtering of ultraviolet light (UV) and a bright light source on one side of the scanner to increase the light available to the scanner. The same parthenium weed and non-parthenium plants (grasses) from the RGB dataset were used to create this hyperspectral dataset as well as another monocot (Navua sedge—
Cyperus aromaticus (Ridley) Mattf. & Kukenth) that was not included in the RGB dataset. One or two parthenium weed plants of the same growth stage were scanned at a time until all individual parthenium weed of each growth stage had been scanned (
Figure 5). Each control plant (bluegrass [
B. ewartiana], kangaroo grass [
T. triandra] or Navua sedge [
C. aromaticus]) was also scanned individually.
2.6. HSI Image Processing
The hypercubes generated from the line scanner include 274 spectral bands from 395.794 nm to 1002.02 nm. The first processing step was to convert the raw pixel radiance values to reflectance. This is necessary to account for variations in available/reflective/impinging/absorbed light when capturing the hyperspectral image [
30]. This is done by including a material with a known reflectance in the hypercube and using this to generate a ratio between the illuminating light power and the reflected light power (
Figure 5). This can then be applied to the spectral measurements of each pixel in the hypercube following the equation.
where
is the reflectance at wavelength
for the location
,
is the reflected light power from the object, and
is the illuminating light power.
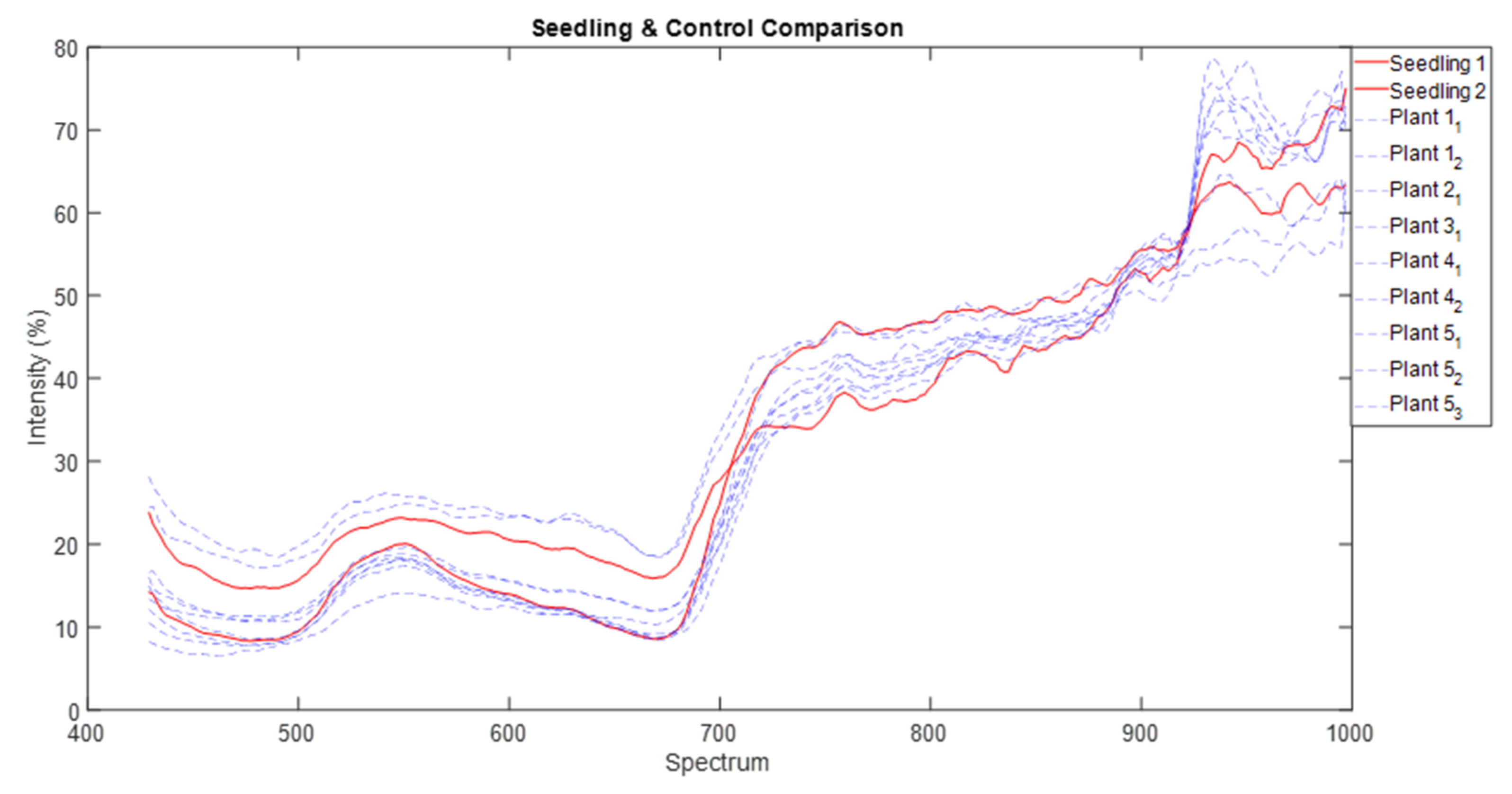
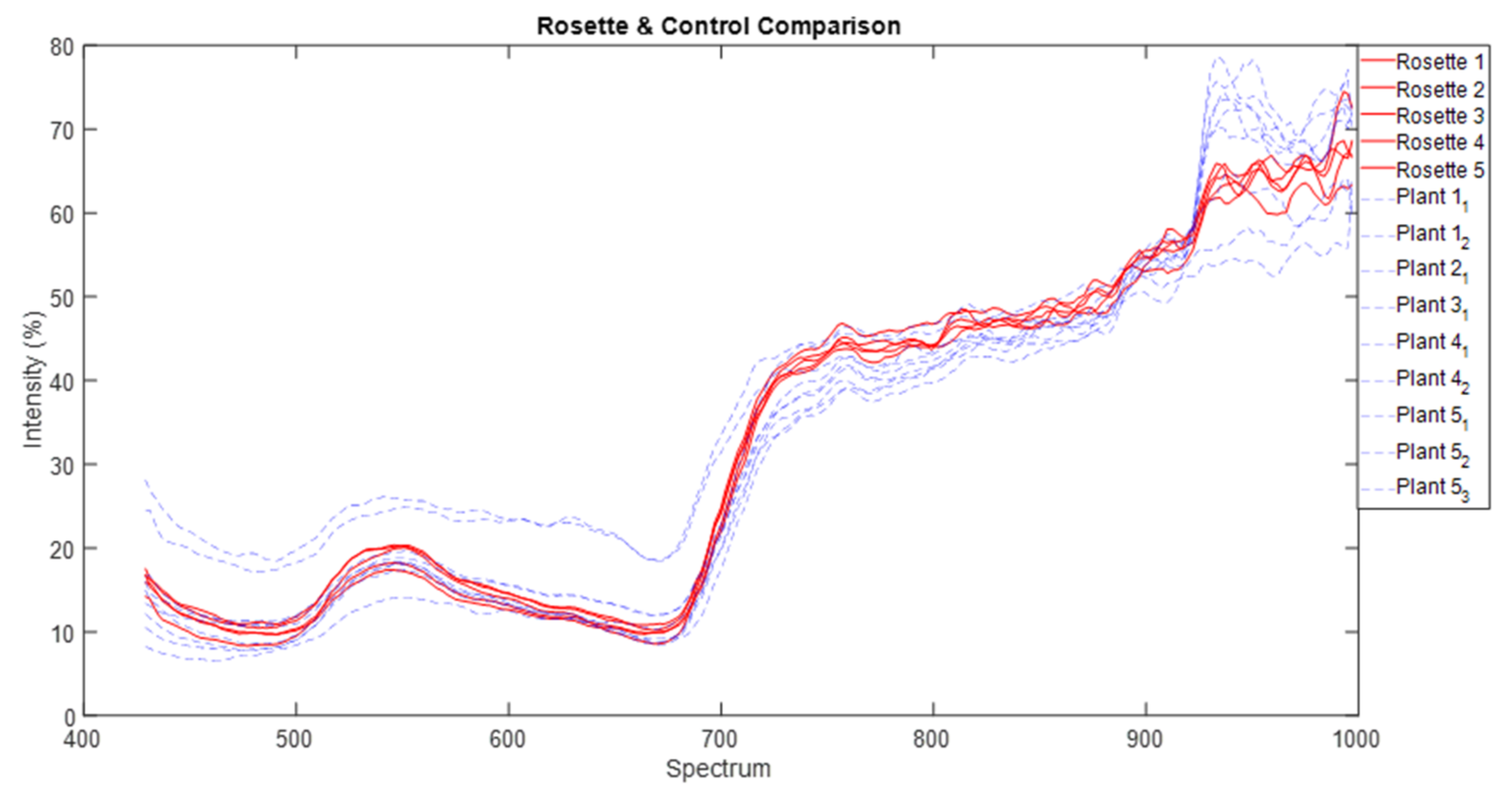
Upon inspection, there were some bands that included significant noise, so it was necessary to remove these bands to ensure these bands did not degrade the analysis of the hypercube. These bands included 395.794–426.883 nm and 999.798–1002.02 nm. The hypercubes were then reduced to their regions of interest (ROI) which correspond with the plants in those images. This adjustment procedure eliminates unnecessary pixels that do not include plant samples, reducing the size of the hypercube file and unnecessary complexity. Filtering was performed to remove unwanted noise and generate a more accurate spectral measurement. Filtering methods include Savitzky-Golay spectral filtering with a window length of 25, a polynomial order of 9, and Gaussian filtering with a kernel size of 61. Spectral measurements are represented in the OKLAB colour space. Some examples of the filtered ROIs of parthenium weed plants are seen in
Figure 6.
Using custom python code developed by one of the authors (Juan Sandino), the filtered and reduced hypercubes of parthenium weed plants and non-parthenium plants were combined into a larger image in a similar way that the RGB images were manually combined. Non-parthenium plants made up the background of these combined images and the parthenium weeds were superimposed on top. This means that there is no natural plant occlusion which impacts how closely these images mimic a real field. A combined image can be seen in
Figure 7.
RGB representations of the combined hypercubes were then generated so that label masks could be made. These masks provided the classifier with training and validation data so that it could generate a trained model. This process involved creating an individual colour mask for each material in the hypercube. Six distinct colour masks were created consisting of flowering (red), rosette (cyan), seedling (magenta), background grass (yellow), concrete (blue), and soil (grey). Effort was made to label as little as possible whilst achieving accurate pixel classifications so that significant test pixels were available to demonstrate classifier performance. The labeled counterpart of
Figure 7 can be seen in
Figure 8. At this point, the XGBoost classifier could be trained and evaluated.
2.7. XGBoost Modelling
Many different classification methods have been applied to hyperspectral image (HSI) classification with very good results, e.g., [
31,
32,
33]. XGBoost (version 1.3.3), developed by Chen & Guestrin, is a scalable tree boosting system that boasts impressive performance in many machine learning benchmarking competitions [
34]. Based on tree boosting, which has been shown to give state of the art (SOTA) results on many classification benchmarks, XGBoost’s scalability allows it to be applied to large datasets without significant computer hardware [
35].
This is made possible by XGBoost’s unified approach to gradient tree boosting, exploiting several well-developed and novel systems to fit a variety of problem types. These include a novel tree learning algorithm for handling sparse data, a weighted quantile sketch procedure for handling instance weights in approximate tree learning, parallel and distributed computing, enabling quicker model exploration and out-of-core computation allowing hundreds of millions of examples to be processed efficiently [
35].
2.8. Performance Metrics
The metrics used to evaluate the performance of the Yolov4 algorithm include true positives (TP), false positives (FP), true negative (TN), false negatives (FN), precision, recall, F1-score, and accuracy. True negatives are excluded as a performance metric for parthenium weed detection as they are not relevant in object detection problems; however, they are relevant for the classification of the flowering/non-flowering and so have been included in the latter. As for the XGBoost classifier, precision, recall and F1-score are the metrics used.
True positives are simply the number of correct detections; similarly, false positives are incorrect detections. False negatives are the number of objects not detected; however true negatives are unique. True negatives apply when an object, for example, a detected parthenium weed can either be one class or another; in this case flowering or not flowering. True negatives do not apply to object detection as this includes location information and so becomes infinite. They do apply to classification which is the case when determining flowering and non-flowering status as the location of the parthenium weed plants has already been determined. In this case, a true negative is a plant correctly identified as non-flowering, or having no flowers detected, and a true positive is a flowering plant with detected flowers.
“Precision” describes the proportion of positive identifications that are correct. A high precision value says that of the detections made, very few of them are wrong. If all detections made were correct the precision score would be 1.0. “Recall” describes the proportion of actual objects, in this case parthenium weed plants, that were identified. A high recall value suggests that of the detectable parthenium weed plants in the data, almost all of them were identified. If all parthenium weed plants in the dataset were detected, the recall score would be 1.0. “F-1 score” is the harmonic mean of precision and recall; it is a good measure of accuracy as it describes the relationship between precision and recall. If one is high and the other is low, the F-1 score will be negatively impacted. A high F-1 score implies high precision and recall scores, which suggest there are high TP and TN and low FP and FN. Lastly, accuracy represents the number of correctly classified or detected objects over the total number of correct and incorrect detections/classifications. The equations for each of these metrics can be seen in
Table 2.
2.9. Ordination
Another method of analysis used specifically for the hyperspectral data is ordination [
36,
37,
38]. The primary purpose of this technique is the reduction of a high number of variables (in this case, the spectra bands) that could differentiate parthenium weed from co-occurring plant species; these reduced but unique set of variables represent as many characteristics as possible of the phenomenon analysed in some latent variables [
38]. This occurs through a linear transformation of the variables that projects the original ones into a new Cartesian system in which the variables are sorted in decreasing order of variance: therefore, the variable with the greatest variance is projected on the first axis, the second greatest variance on the second axis, and so on. The reduction of complexity occurs by limiting itself to analysing the main (by variance) new variables. Unlike other (linear) transformations of variables practiced in the field of statistics, in this ordination technique it is the same data that determine the transformation vectors [
36].
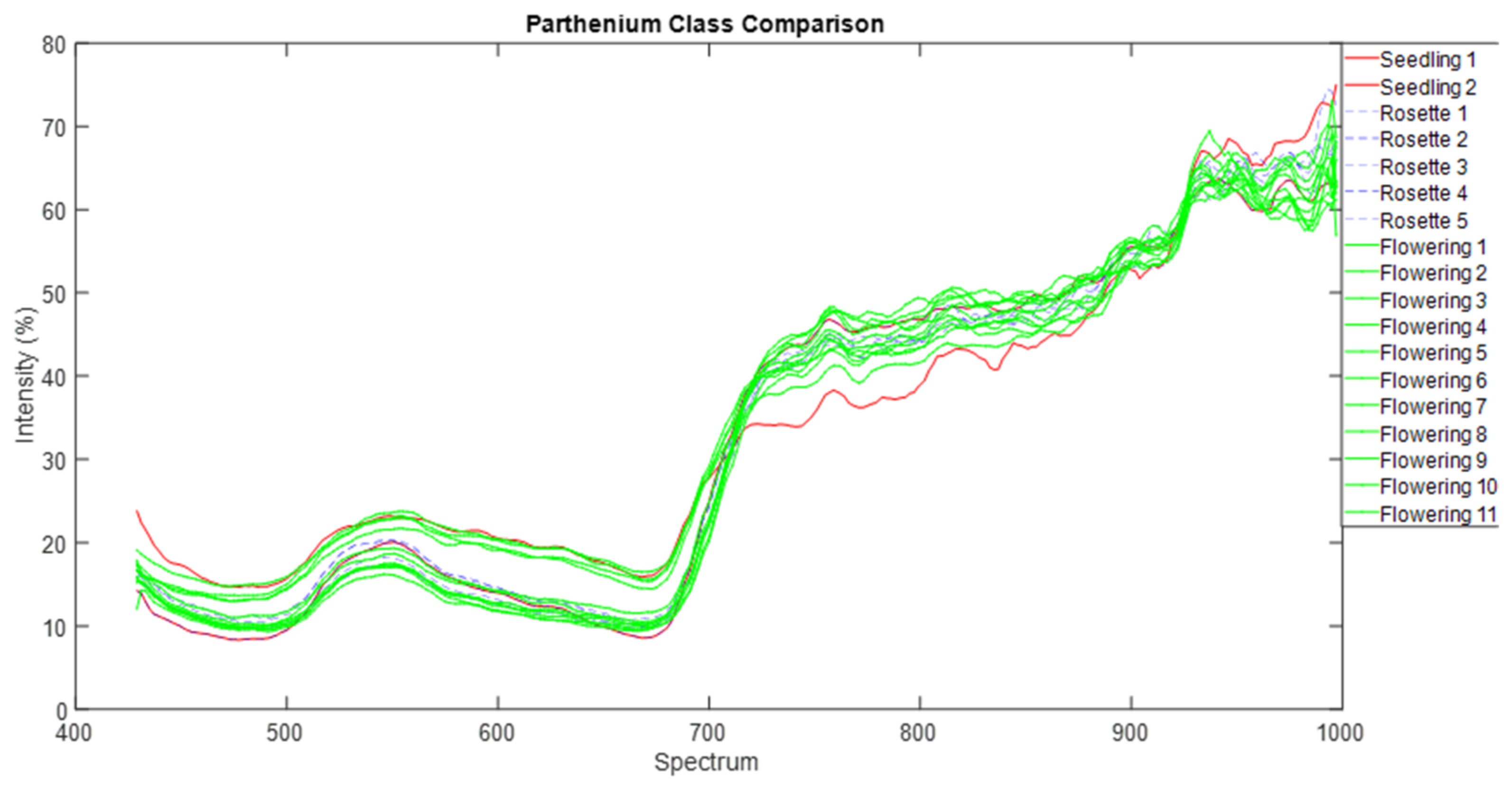
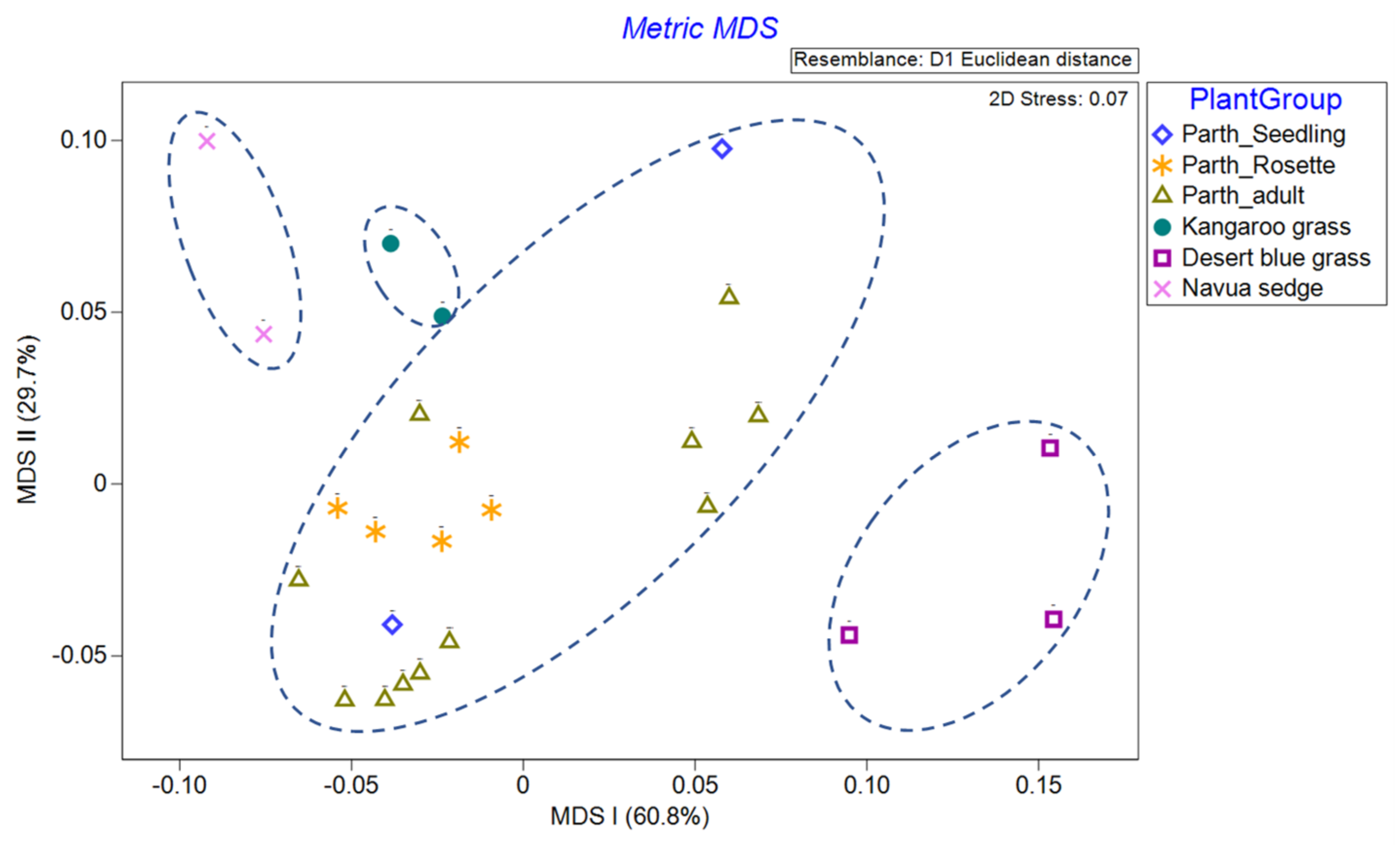
We normalised that spectra data and used common parametric analyses (ANOVA and generalised linear modelling) and multivariate ordination technique of metric multidimensional scaling (MDS) to detect differences in individual and mean spectra signature of each of the three parthenium weed growth stages and non-parthenium (control) plant species (Navua sedge, kangaroo grass and desert bluegrass). For mean spectral signatures, data were grouped into bands of blue (400–500 nm), green (501–600 nm), red (601–700 nm), near infra-red (700–900 nm) and infrared (>900 nm) bands. All ordination analyses were performed on PRIMER version 7.0. software (PRIMER-E Ltd., Plymouth, UK).
4. Discussion
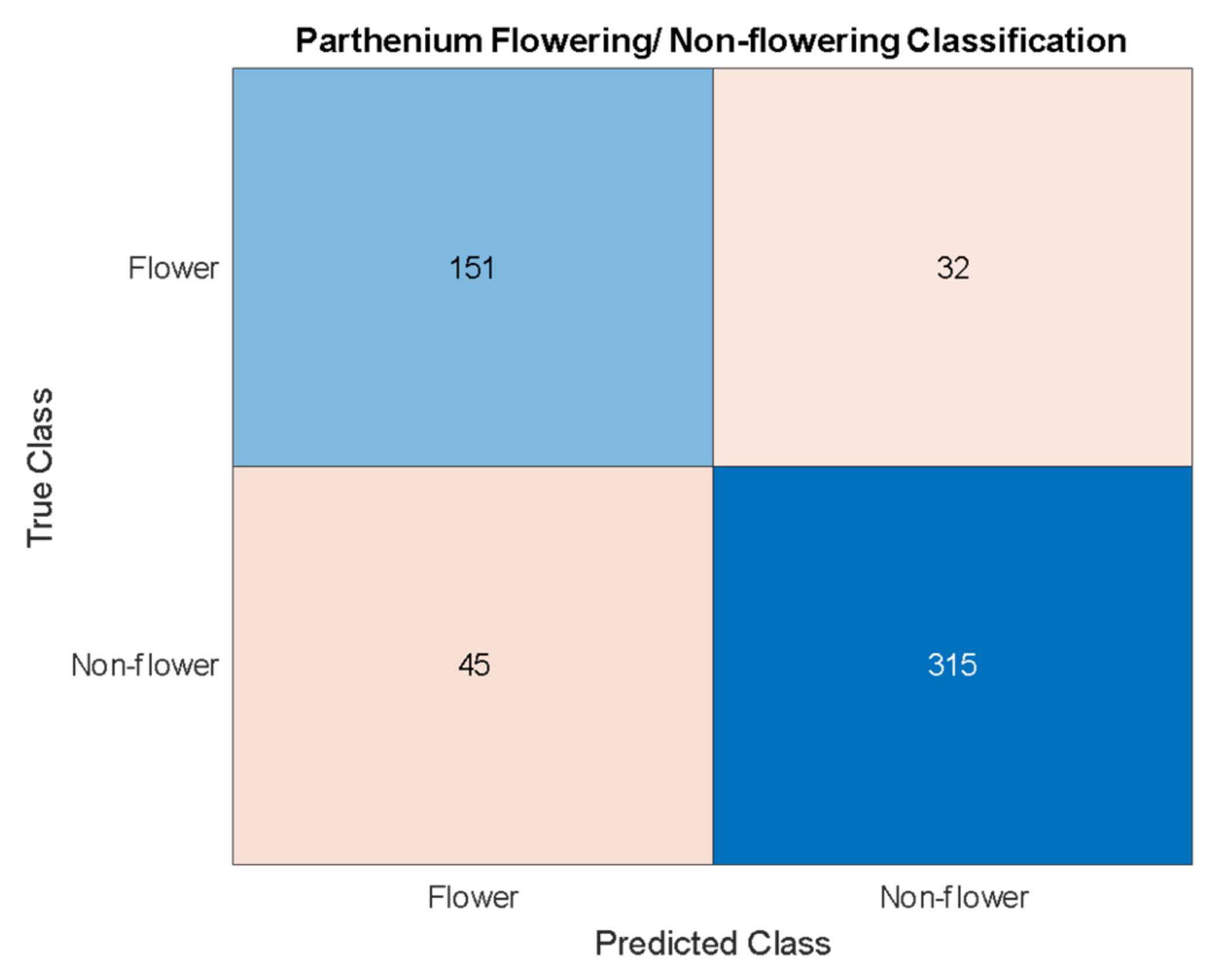
The findings from the current study suggest that machine learning techniques can be applied effectively and efficiently to invasive weed detection in managed and pastoral environments. We have used hyperspectral and RGB imaging techniques to create two distinct datasets with the same sample plants, and hence estimate the effectiveness of two machine learning algorithms. Object detection using Yolov4 was applied to the RGB dataset, while pixel classification using XGBoost was applied to the hyperspectral dataset. Yolov4 achieved a detection accuracy for the invasive parthenium weed of 95% and was able to classify flowering and non-flowering growth stages of the weed with an accuracy of 86%. XGBoost achieved a pixel classification accuracy of 99% with 100% of the seedling, rosette, and flowering plants being identified with a colour mask over the body of the plant.
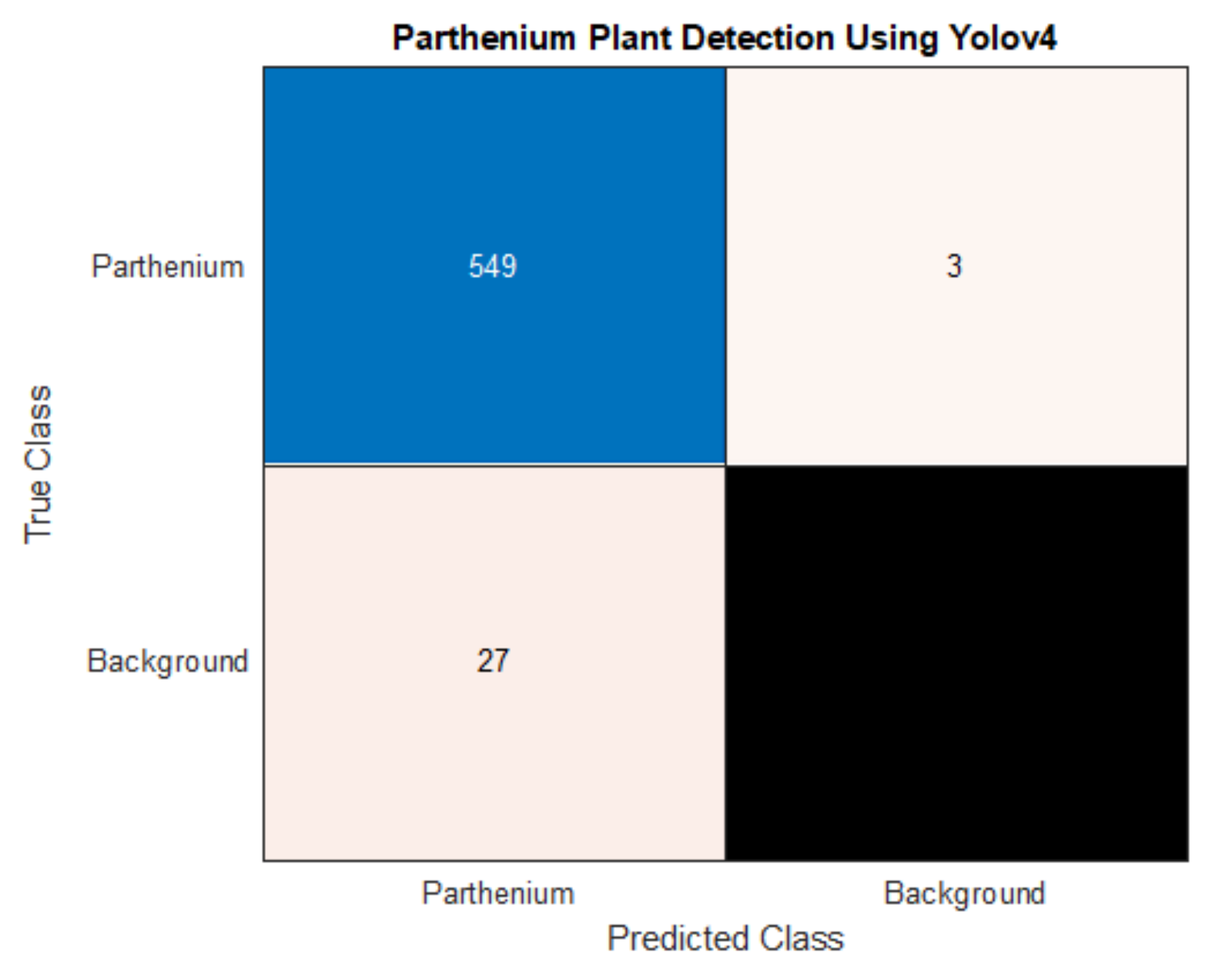
As well as a detection accuracy of 95%, seen in
Table 3, the precision and recall for parthenium weed detection is 95% and 99%, respectively. While both scores are high, a very high recall suggests that there are very few false negatives which is the case with only three false negatives in the test dataset. In this case, a high recall is very desirable as false negatives mean undetected and potentially uncontrolled plants that may remain in an affected area targeted for local eradication, reach reproductive maturity and continue to add to the parthenium weed seed bank [
1,
39]. Low numbers of false positives, whilst also desirable, are comparatively less so. False positives (4.7% in this study) may trigger parthenium weed control methods to be applied when in reality, it is not necessary, though this may be a reasonable compromise when eradication of the weed is the goal (see Regan et al. (2011) and Panetta (2015). for in-depth analysis of this treatise [
40,
41]).
The precision and recall for flowering/non-flowering classification (83%) are lower than the actual parthenium weed detection (95%), but this is also a more difficult problem. The approach taken for this classification is centered around object detection with the objects being parthenium weed flowers. A single flower detection on a parthenium weed is enough to classify that parthenium weed as a flowering plant. Thus, the problem is one of both classification and object detection. Because flowers still need to be detected by the Yolov4 algorithm they need to be treated as a unique class like the parthenium weed class. However, the flowers are much smaller and so have much less information from which the algorithm can extract relationships. An accuracy score of 86% reported in this work is not insignificant but does not achieve the goal of a very accurate flowering/non-flowering differentiation. The results do suggest that this higher accuracy is achievable, and this will likely be done with data of a lower GSD, affording this class much more detail from which to extract relationships. This would also improve the parthenium weed detection ability.
Precision and recall scores achieved by XGBoost for classes in the hyperspectral dataset are all between 98% and 100% (
Table 4). These are for pixel classification, not for object detection; however, if all the pixels of an object are classified in the correct class, then the object is effectively detected. The colour masks achieved by XGBoost for each object are also more useful than a bounding box as it gives the true size and structure of the plant. What XGBoost does particularly well is to differentiate all three growth stages of parthenium weed- seedling, rosette, and flowering plants. Growth stages were differentiated in the RGB dataset using the presence of flowers. However, Yolov4 could not determine enough of a difference when flowering, rosette, and seedling plants were split into unique classes; there just wasn’t enough unique relationships in the RGB data. XGBoost on the other hand looks at the spectral signatures of each growth stage and has reliably determined unique relationships between each stage. It was interesting to note that using metric MDS ordination, though Axis I captured the majority of the variation in the spectra dataset, however the distribution along this axis of the three parthenium weed growth stages was wide (i.e., scattered) rather than concentrated, especially for flowering parthenium weed plants and the seedlings. While we lack enough replicates for the seedlings (only two individuals were scanned), and as such it is safe to remove/discount this growth stage from our analyses for lack of power, the display of two discrete groups seen for the flowering (adult) plant stage might not be unexpected. Flowering parthenium weed plants (adults) that we used are probably in different phenological stages of reproduction and/or leaf retention/shedding, and this might have led to the variation in spectral signature captured and seen. Hyperspectral reflectance curves are often affected by plant phenological stage [
42,
43]. We are left with the rosette growth stage having consistent spectral signature, suggesting that this growth stage might have the greatest utility in terms of differentiation (i.e., maximum separability) from other plants (be it native or other weeds) under field conditions.
In sum, the comparatively better results using hyperspectral data were not unexpected, but our findings will suggest this method is preferred to achieve the best accuracy. Note however that the XGBoost method is limited by the much more expensive equipment necessary to capture this kind of data, thus likely putting it out of reach of the average consumer.
Machine learning techniques are increasingly being effectively applied to weed detection in row-cropping and pastoral environments (e.g., [
12,
44,
45,
46,
47,
48]). This present investigation further strengthens the latter body of work, especially for Parthenium weed in the field (see also [
49,
50,
51]). No doubt natural environments can be protected if weed populations are reduced through proper weed management options [
52]. Often proper weed management involves significant inputs of herbicides, but its use can be dramatically reduced if herbicide applications are optimized using SSWM techniques, including the use of aerial imagery to map weed distribution at varying scales that will assist in management optimization [
53]. This paper provides a preliminary indication that the above machine learning methods can detect parthenium weed to a significant accuracy in pastoral environments and thus can be used for SSWM. This work reported herein also further strengthens the potential of using Yolov4 (including its more recent versions of Yolov7) and XGBoost for identification and classification of weed
Caveats
The data used for this study was developed in a controlled (glasshouse) environment to model pasture field environments as closely as possible. Thus, the methods have not been applied to real-world environments and so any generalization to real-world environments must be tentative and treated with caution. Parthenium weed was the only weed investigated in this study and while efficient management of this weed alone would be of significant benefit, it cannot be said that the same methods could be applied successfully to other species of weeds (but see [
54]). Problems were also encountered when trying to detect parthenium weed in its seedling stage using RGB images and during object detection; consequently, it is likely to be difficult to detect weeds of this size in real field environments. This same problem was somewhat encountered in the hyperspectral data, albeit to a lesser extent. This may be due, in part to the quality of data capture technology used, pre- and post-processing methods utilized, and training hardware employed, all of which could be improved further upon. Yolov4 was the only machine learning method used for each data type, and while this method answers the question posed for this study, our investigation does not determine that these methods are the only methods or the best methods. Several other machine learning algorithms, including Region-based CNN, single-shot-Detection (SSD), random forest (RF), support vector machine (SVM) and k-nearest neighbours (KNN), might need to be comparatively tested [
55,
56].
Data quality is consistently an issue for the task reported in this work. Previous attempts to train RGB detectors in the field have yielded very limited performance and detection accuracy (P. Trotter, Osunkoya OO, pers. Observation and Communication). These attempts involved capturing data in the field using a drone (UAV) and following pre-processing and training protocols similar to what was done in this investigation. The main difference between our reported work (in a control environment and which gave high accuracy (95%) and the previous ones (in pastoral fields, which gave lower accuracy of 35%) is the quality of the data. Previous attempts involved data with GSDs that are far greater than what was used herein, amplified and complicated by the fact that the previous work used data derived from the field which, by nature, is a more heterogeneous environment of fast changing atmospheric condition (especially solar illumination, cloud, and shadow), with notable variation in terrain (slope and aspect) and soil quality. Hence, field image data captured via UAV can be less reliable and more challenging for training [
57,
58]. This highlights the importance of data quality, specifically the GSD of the images.
Despite these field challenges, this study provides strong evidence that parthenium weed can potentially be detected in both RGB and hyperspectral imagery using machine learning methods in a real pastoral environment. Because the simulated environment used in this study was developed to imitate natural/human-made landscapes as closely as possible, our promising findings suggest that with further work and refinements, these methods might be applicable to field environments. Future work should also expand the list of target weeds to determine how broad and applicable our techniques and findings are. There are many more machine learning algorithms that exist other than the ones involved in this study (e.g., RF, SVN, and KNN), and so increasing the number of AI algorithms should be encouraged in future research to potentially provide a greater number of solutions and detection accuracy [
55,
56]. Lastly, with time better hardware and software technology will evolve in the AI environment and should be used to improve detection success.
5. Conclusions
The present work adds to the growing literature on machine learning towards optimising the discrimination, mapping, and monitoring of invasive alien plants [
9,
10,
47,
51,
54,
59]. We have shown that RGB images of Parthenium weed obtained in simulated pastoral environments can be processed successfully with a YOLOv4-CNN classification protocol- achieving an overall accuracy of 95% for detection, and 86% for differentiation of flowering and non-flowering stages of the weed. Using an XGBoost classifier for the pixel classification of the hyperspectral dataset, we achieved a classification accuracy of 99% for parthenium weed growth stages. Our ordination of the hyperspectral signatures suggested that the wavelengths responsible for major differentiation of parthenium weed from co-occurring control plants (grasses and sedges) are mainly in the blue (400–500 nm) and the infrared (>900 nm) ranges- a finding similar to that reported by Ullah et al. (2021) for the same weed in Pakistan [
51]. It is worthwhile noting that ML discrimination of growth stages of the focal weed has rarely been reported, but the work reported herein indicates that it is achievable.
For scalability of our findings to the field, improvements need to be made in use of UAV and deployment of high specification (e.g., HS/MS) cameras that can achieve low ground sampling distances (GSDs) while maintaining flight heights; this will allow a more efficient, high resolution spatial image capture [
59]. A detector must also be trained on data that are captured in the field. The performance of this detector in terms of training and testing vastly depends on the capability of available computer system; thus, in future applications, computer systems specifically designed for object detection and AI should be used. Image and data augmentation techniques for generation of training data could be optimised as this may also likely improve performance. Better image annotation techniques, such as Semantic Segmentation [
59], should be used because in natural fields, established Parthenium weed and co-occurring plants present a much more complicated scenarios that can make bounding box annotations inefficient and limit performance. Lastly, and overall, with further improvement in image processing (e.g., using Mask/faster R-CNN) and ML protocols (e.g., transitioning from YOLOv4 [the version available in the course of this work] to more recent YOLOv7 or even YOLO-R [You Only Learn One Representation]), the findings reported herein have the potential for extension and application in real-world pastoral and cropping environments to manage better many more weeds and revolutionize how people deal with the ever-growing problem of invasive alien species (see [
60]).



 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}