
Developing Visual-Assisted Decision Support Systems across Diverse Agricultural Use Cases

 , ,
, ,  ,
,  , and
, and
Abstract
:1. Introduction
1.1. Decision Support Systems in Precision Agriculture
1.2. Visual Analytic Components
1.2.1. Bar Chart and Histogram
1.2.2. Time Series
1.2.3. Scatter Plot
1.2.4. Radar Chart
1.2.5. Pie Chart
1.2.6. Choropleth Map
1.2.7. Farm Map
1.2.8. Parallel Coordinates
1.2.9. Progress Circle
1.2.10. Uncertainty Graph
1.2.11. Word Cloud
1.3. Interaction Framework
2. Materials and Methods
2.1. Use Cases
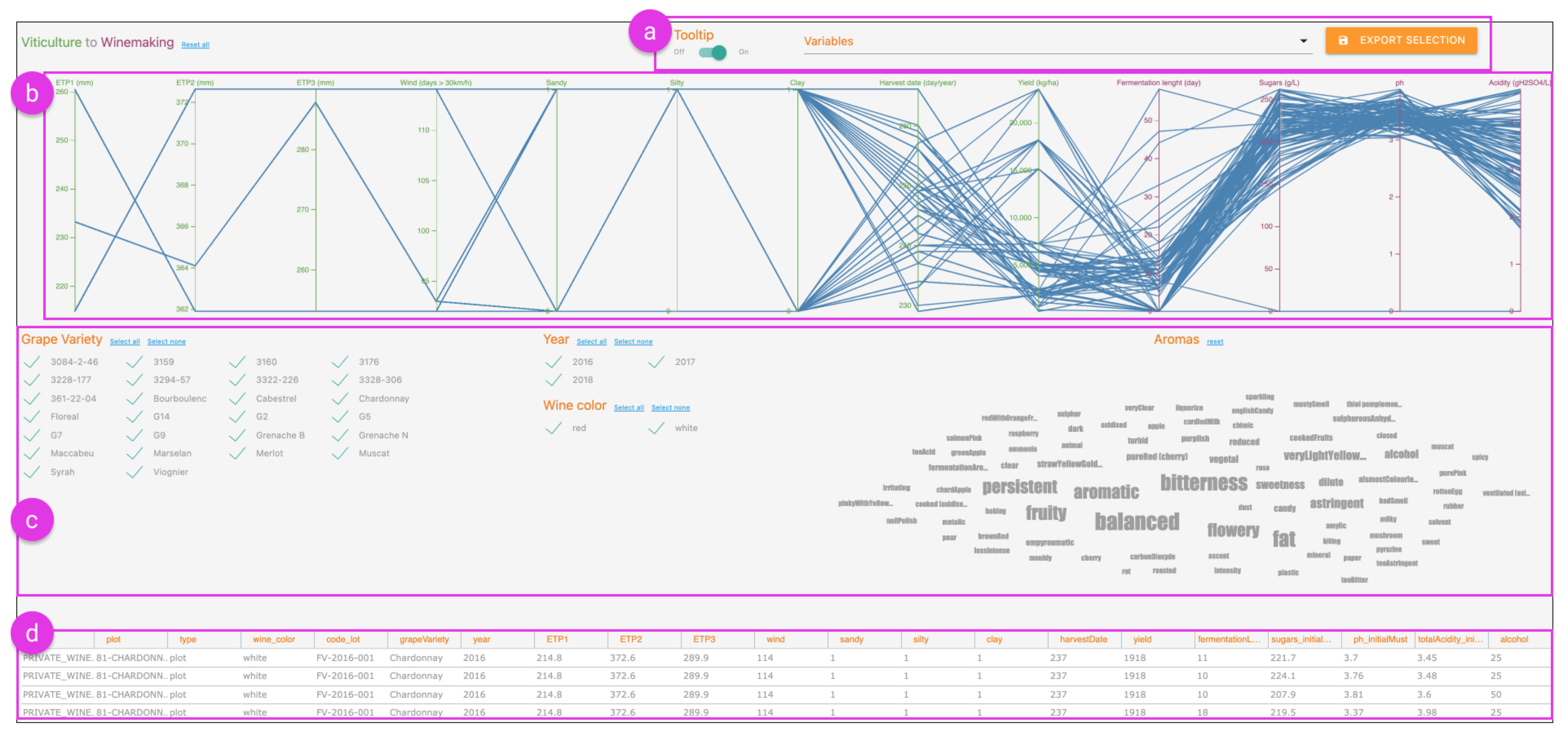
2.1.1. Correlation Analysis of Multivariate Data
2.1.2. Analysis of Plant Growth
2.1.3. Exploratory Analysis of Heterogeneous Data




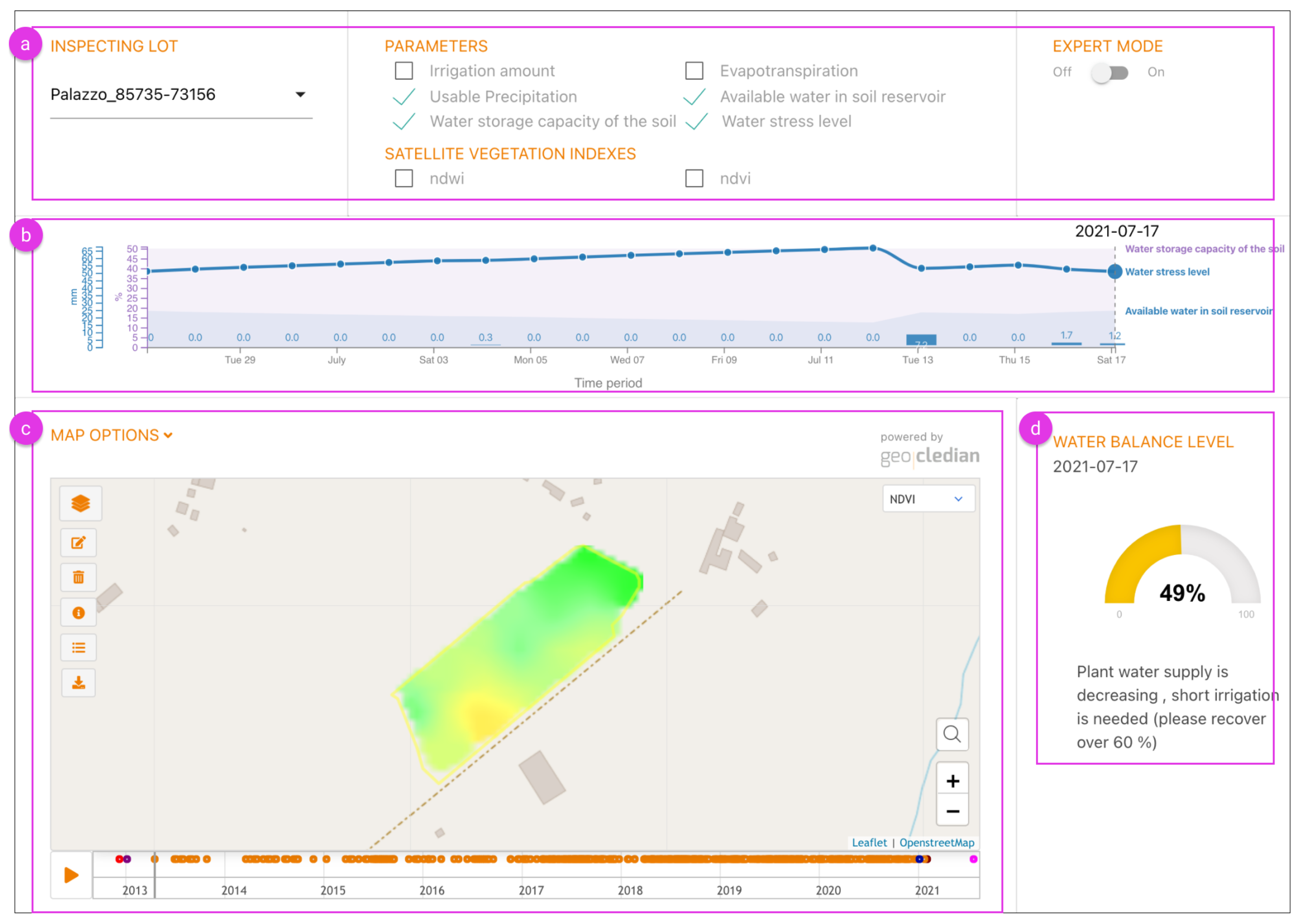
2.1.4. Analysis of Water Stress and Irrigation Requirements
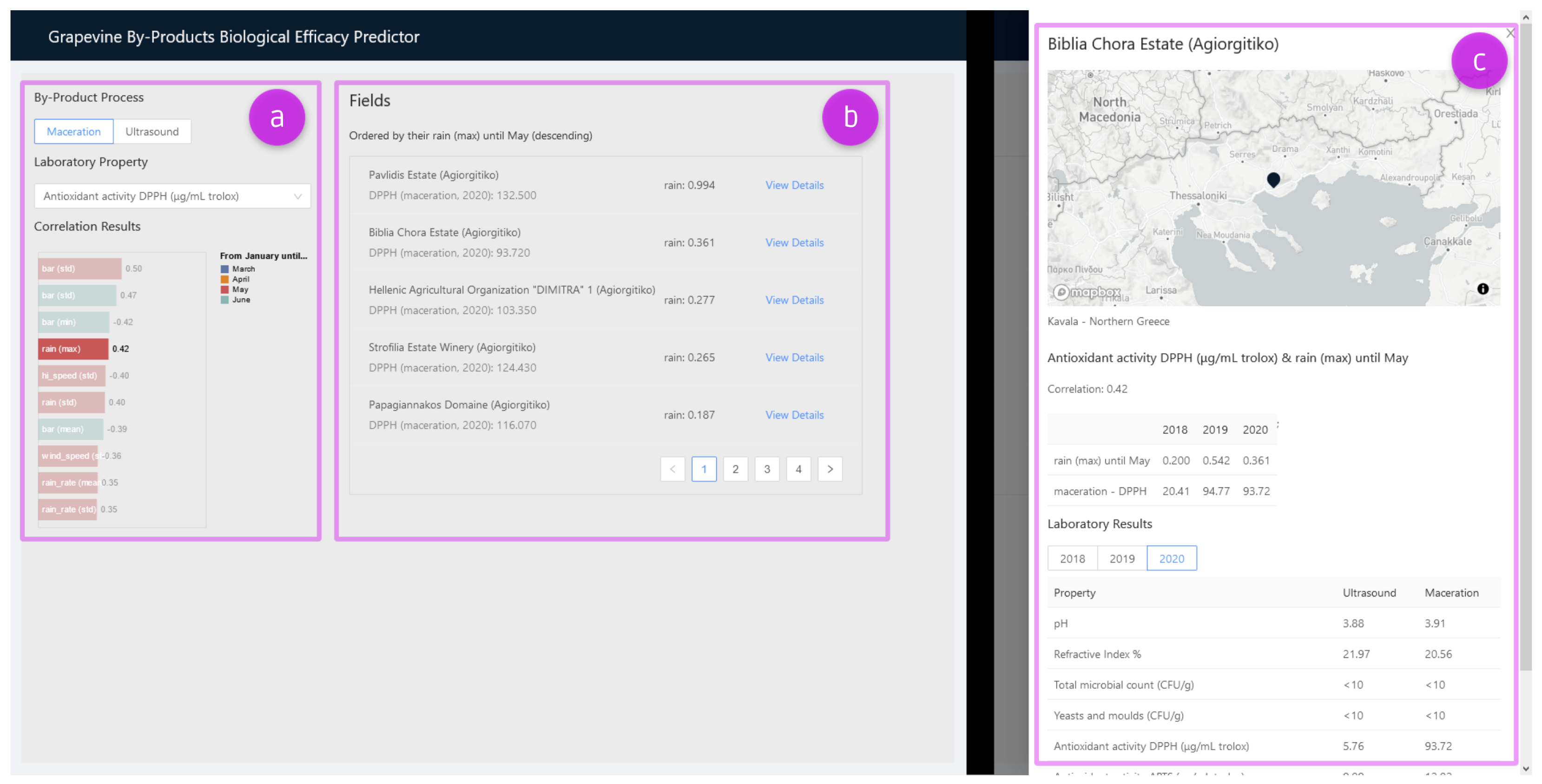
2.1.5. Analysis of Biological Efficacy in by-Products
2.1.6. Uncertainty-Aware Price Prediction
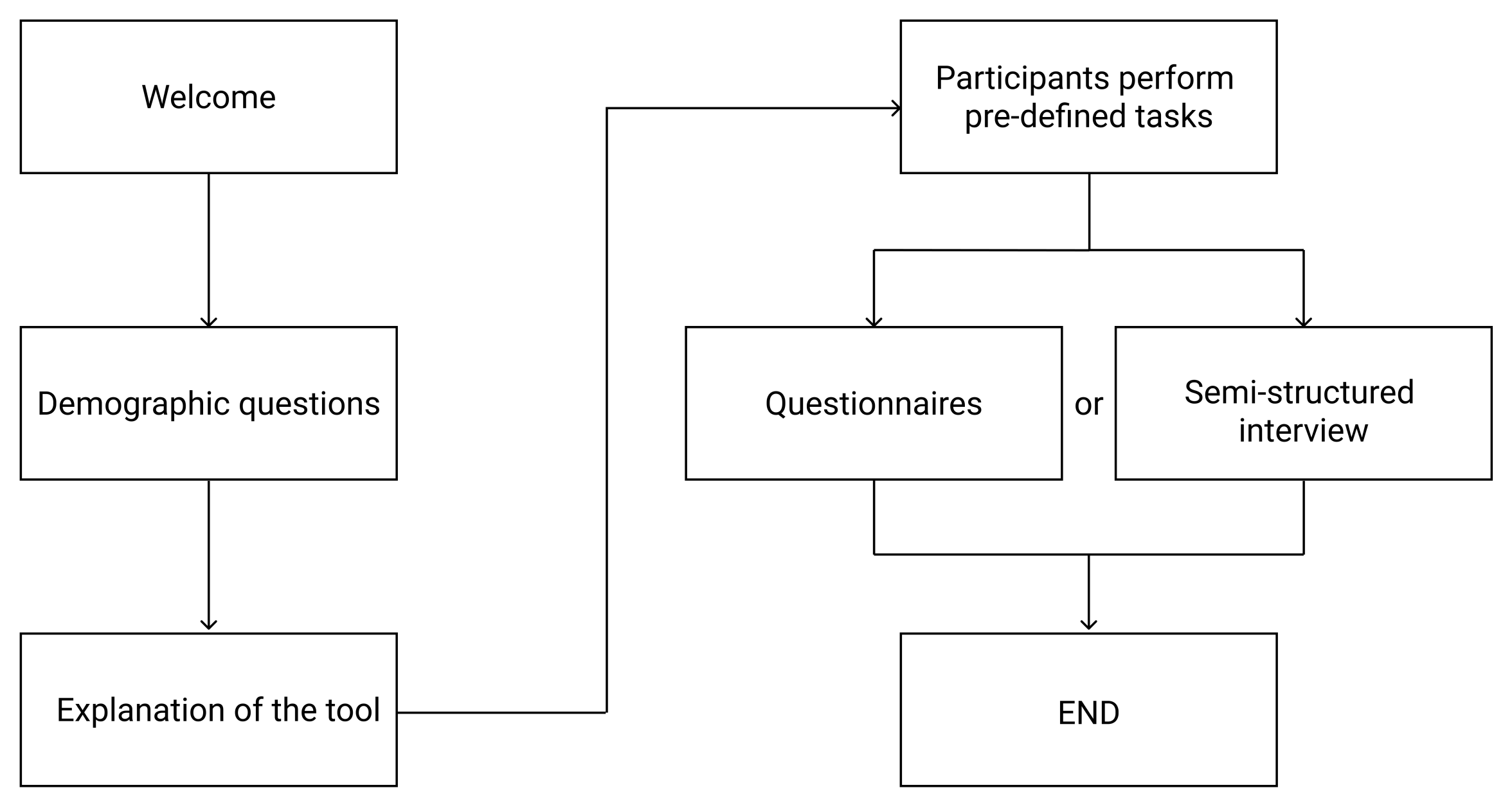
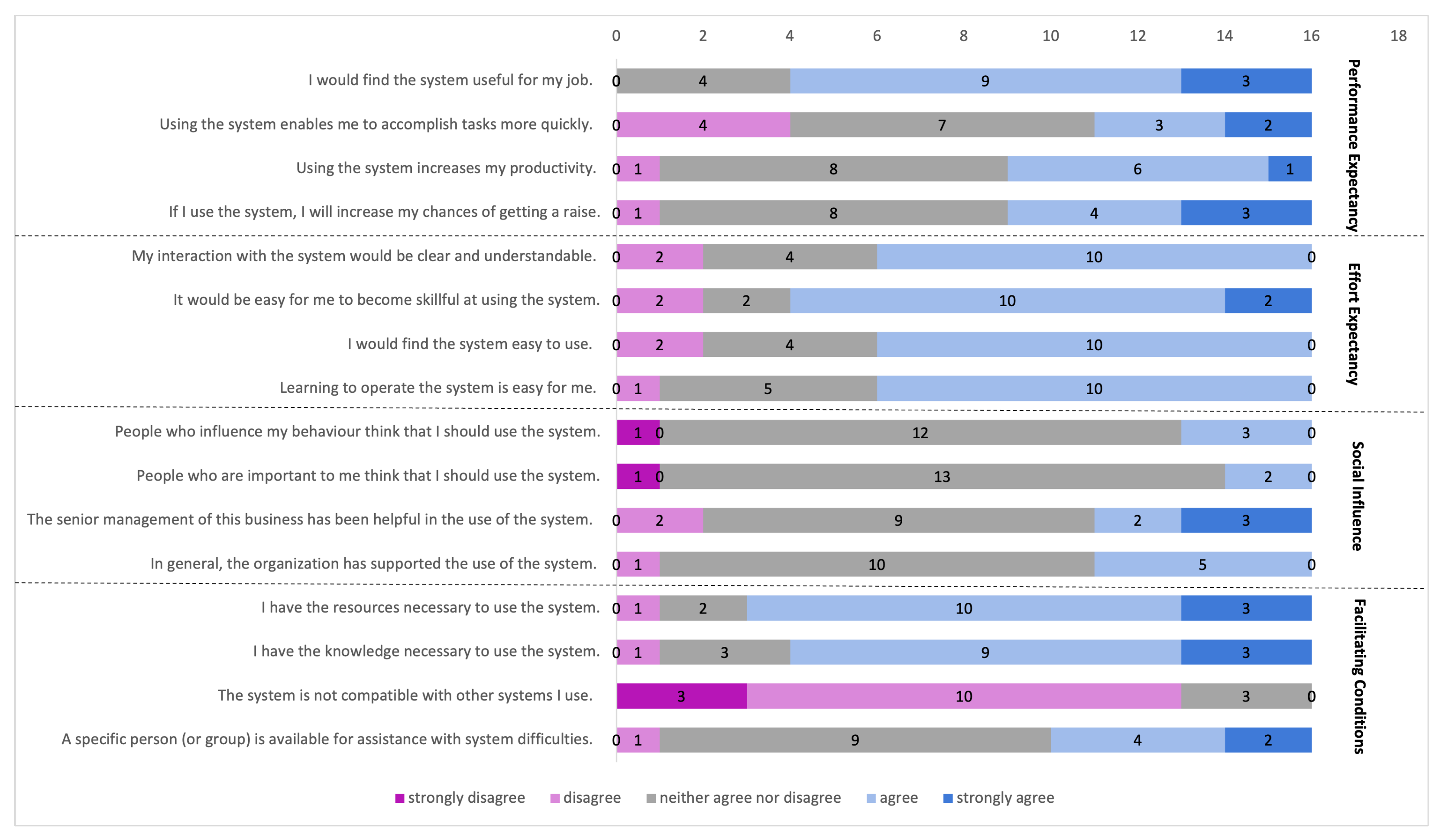
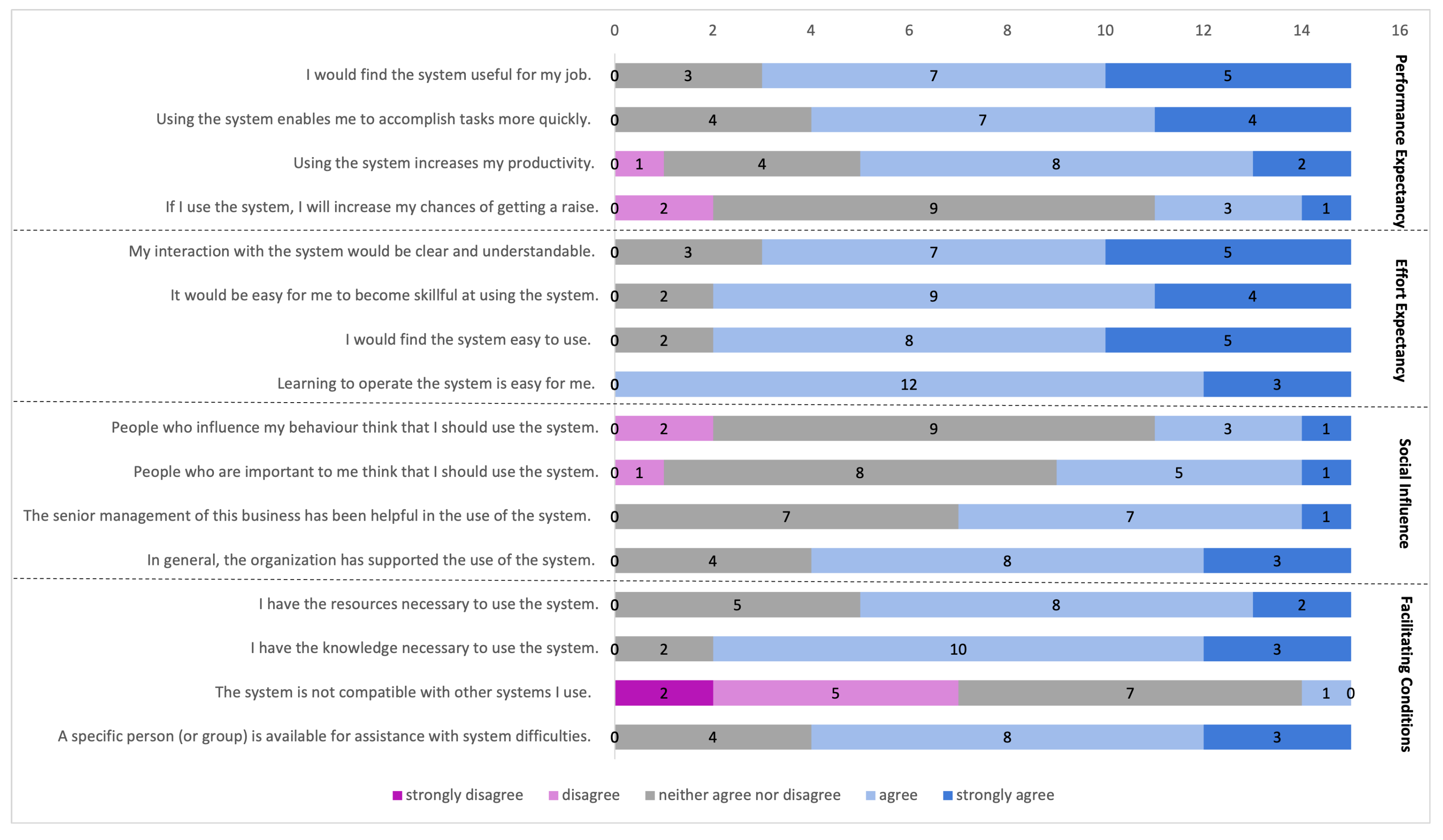
2.2. Evaluation Procedure
- What do you see while you are using the tool? What strikes you?
- Do you trust the prediction model? Which parts of the visualisation made you say that?
- Is it clear how the prediction model works? Which parts of the visualisation made you say that? Would you like to explore other things to get insights in the prediction model?
- Would you use this visualisation for your job activities? If no, do you think we can change the visualisation such that it would be more useful? If yes, does the visualisation contain enough information to fulfil these activities?
3. Results
3.1. Correlation Analysis of Multivariate Data
3.2. Analysis of Plant Growth
3.3. Exploratory Analysis of Heterogeneous Data
3.4. Analysis of Water Stress and Irrigation Requirements
3.5. Analysis of Biological Efficacy in by-Products
3.6. Uncertainty-Aware Price Prediction
3.6.1. A Useful and Generic Tool
3.6.2. Trust in Prediction Tools Is Multi-Faceted
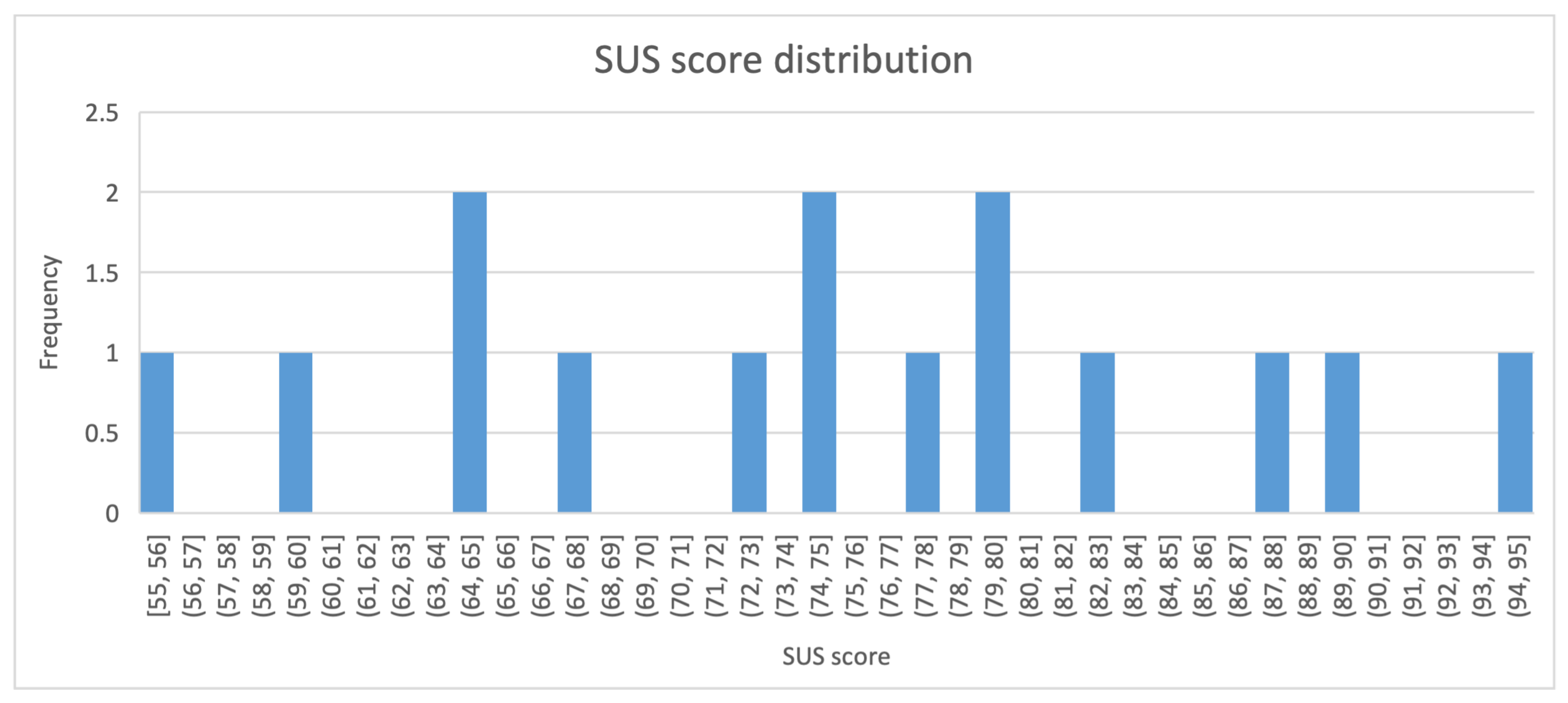
3.6.3. Usability
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nowak, B. Precision agriculture: Where do we stand? A review of the adoption of precision agriculture technologies on field crops farms in developed countries. Agric. Res. 2021, 10, 515–522. [Google Scholar] [CrossRef]
- Jedlička, K.; Charvát, K. Visualisation of big data in agriculture and rural development. In Proceedings of the IST-Africa Week Conference (IST-Africa), Gaborone, Botswana, 9–11 May 2018. [Google Scholar]
- Aslan, M.F.; Durdu, A.; Sabanci, K.; Ropelewska, E.; Gültekin, S.S. A Comprehensive Survey of the Recent Studies with UAV for Precision Agriculture in Open Fields and Greenhouses. Appl. Sci. 2022, 12, 1047. [Google Scholar] [CrossRef]
- Charvat, K.; Junior, K.C.; Reznik, T.; Lukas, V.; Jedlicka, K.; Palma, R.; Berzins, R. Advanced visualisation of big data for agriculture as part of databio development. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 415–418. [Google Scholar]
- Tey, Y.S.; Brindal, M. A meta-analysis of factors driving the adoption of precision agriculture. Precis. Agric. 2022, 23, 353–372. [Google Scholar] [CrossRef]
- Ruß, G.; Kruse, R.; Schneider, M.; Wagner, P. Visualization of agriculture data using self-organizing maps. In International Conference on Innovative Techniques and Applications of Artificial Intelligence; Springer: London, UK, 2008; pp. 47–60. [Google Scholar]
- Rind, A.; Wang, T.D.; Aigner, W.; Miksch, S.; Wongsuphasawat, K.; Plaisant, C.; Shneiderman, B. Interactive information visualization to explore and query electronic health records. Found. Trends Hum. Comput. Interact. 2013, 5, 207–298. [Google Scholar] [CrossRef]
- Frías, M.D.; Iturbide, M.; Manzanas, R.; Bedia, J.; Fernández, J.; Herrera, S.; Cofiño, A.S.; Gutiérrez, J.M. An R package to visualize and communicate uncertainty in seasonal climate prediction. Environ. Model. Softw. 2018, 99, 101–110. [Google Scholar] [CrossRef] [Green Version]
- Gutiérrez, F.; Htun, N.N.; Schlenz, F.; Kasimati, A.; Verbert, K. A review of visualisations in agricultural decision support systems: An HCI perspective. Comput. Electron. Agric. 2019, 163, 104844. [Google Scholar] [CrossRef] [Green Version]
- Wachowiak, M.P.; Walters, D.F.; Kovacs, J.M.; Wachowiak-Smolíková, R.; James, A.L. Visual analytics and remote sensing imagery to support community-based research for precision agriculture in emerging areas. Comput. Electron. Agric. 2017, 143, 149–164. [Google Scholar] [CrossRef]
- Cisternas, I.; Velásquez, I.; Caro, A.; Rodríguez, A. Systematic literature review of implementations of precision agriculture. Comput. Electron. Agric. 2020, 176, 105626. [Google Scholar] [CrossRef]
- Teniwut, W.; Hasyim, C. Decision support system in supply chain: A systematic literature review. Uncertain Supply Chain. Manag. 2020, 8, 131–148. [Google Scholar] [CrossRef]
- Parker, C. A user-centred design method for agricultural DSS. In Proceedings of the EFITA-99: Proceedings of the Second European Conference for Information Technology in Agriculture, Bonn, Germany, 27 September 1999; pp. 27–30. [Google Scholar]
- Grigera, J.; Garrido, A.; Zaraté, P.; Camilleri, G.; Fernández, A. A mixed usability evaluation on a multi criteria group decision support system in agriculture. In Proceedings of the XIX International Conference on Human Computer Interaction, Palma, Spain, 12–14 September 2018; pp. 1–4. [Google Scholar]
- Rossi, V.; Salinari, F.; Poni, S.; Caffi, T.; Bettati, T. Addressing the implementation problem in agricultural decision support systems: The example of vite. net ®. Comput. Electron. Agric. 2014, 100, 88–99. [Google Scholar] [CrossRef]
- Cabrera, V.E.; Breuer, N.E.; Hildebrand, P.E.; Letson, D. The dynamic North Florida dairy farm model: A user-friendly computerized tool for increasing profits while minimizing N leaching under varying climatic conditions. Comput. Electron. Agric. 2005, 49, 286–308. [Google Scholar] [CrossRef]
- Lorite, I.J.; García-Vila, M.; Santos, C.; Ruiz-Ramos, M.; Fereres, E. AquaData and AquaGIS: Two computer utilities for temporal and spatial simulations of water-limited yield with AquaCrop. Comput. Electron. Agric. 2013, 96, 227–237. [Google Scholar] [CrossRef] [Green Version]
- Thierry, H.; Vialatte, A.; Choisis, J.P.; Gaudou, B.; Parry, H.; Monteil, C. Simulating spatially-explicit crop dynamics of agricultural landscapes: The ATLAS simulator. Ecol. Inform. 2017, 40, 62–80. [Google Scholar] [CrossRef] [Green Version]
- McBratney, A.; Whelan, B.; Ancev, T.; Bouma, J. Future directions of precision agriculture. Precis. Agric. 2005, 6, 7–23. [Google Scholar] [CrossRef]
- Lundström, C.; Lindblom, J. Considering farmers’ situated knowledge of using agricultural decision support systems (AgriDSS) to Foster farming practices: The case of CropSAT. Agric. Syst. 2018, 159, 9–20. [Google Scholar] [CrossRef]
- Blauth, D.A.; Ducati, J.R. A Web-based system for vineyards management, relating inventory data, vectors and images. Comput. Electron. Agric. 2010, 71, 182–188. [Google Scholar] [CrossRef]
- Armstrong, L.J.; Nallan, S.A. Agricultural decision support framework for visualisation and prediction of Western Australian crop production. In Proceedings of the 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1907–1912. [Google Scholar]
- Byishimo, A.; Garba, A.A. Designing a farmer interface for smart irrigation in developing countries. In Proceedings of the 7th Annual Symposium on Computing for Development, Nairobi, Kenya, 18–20 November 2016; pp. 1–3. [Google Scholar]
- Friedman, S.P.; Communar, G.; Gamliel, A. DIDAS–User-friendly software package for assisting drip irrigation design and scheduling. Comput. Electron. Agric. 2016, 120, 36–52. [Google Scholar] [CrossRef]
- Bostock, M.; Ogievetsky, V.; Heer, J. D3 data-driven documents. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2301–2309. [Google Scholar] [CrossRef]
- Satyanarayan, A.; Russell, R.; Hoffswell, J.; Heer, J. Reactive vega: A streaming dataflow architecture for declarative interactive visualization. IEEE Trans. Vis. Comput. Graph. 2015, 22, 659–668. [Google Scholar] [CrossRef]
- Satyanarayan, A.; Moritz, D.; Wongsuphasawat, K.; Heer, J. Vega-Lite: A Grammar of Interactive Graphics. IEEE Trans. Vis. Comput. Graph. 2017, 23, 341–350. [Google Scholar] [CrossRef] [Green Version]
- Chart.js | Open Source HTML5 Charts for your Website. Available online: https://www.chartjs.org/ (accessed on 28 June 2021).
- Machwitz, M.; Hass, E.; Junk, J.; Udelhoven, T.; Schlerf, M. CropGIS–A web application for the spatial and temporal visualization of past, present and future crop biomass development. Comput. Electron. Agric. 2019, 161, 185–193. [Google Scholar] [CrossRef]
- Mirel, B. Interaction Design for Complex Problem Solving: Developing Useful and Usable Software; Morgan Kaufmann (Elsevier): Burlington, MA, USA, 2004. [Google Scholar]
- Gotz, D.; Zhou, M.X. Characterizing users’ visual analytic activity for insight provenance. Inf. Vis. 2009, 8, 42–55. [Google Scholar] [CrossRef]
- Yi, J.S.; ah Kang, Y.; Stasko, J.; Jacko, J.A. Toward a deeper understanding of the role of interaction in information visualization. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1224–1231. [Google Scholar] [CrossRef] [Green Version]
- Parr, J.; Papendick, R.; Hornick, S.; Meyer, R. Soil quality: Attributes and relationship to alternative and sustainable agriculture. Am. J. Altern. Agric. 1992, 7, 5–11. [Google Scholar] [CrossRef]
- Bisbis, M.B.; Gruda, N.; Blanke, M. Potential impacts of climate change on vegetable production and product quality–A review. J. Clean. Prod. 2018, 170, 1602–1620. [Google Scholar] [CrossRef]
- Gruda, N. Do soilless culture systems have an influence on product quality of vegetables? J. Appl. Bot. Food Qual. 2009, 82, 141–147. [Google Scholar] [CrossRef]
- Rojo, D.; Htun, N.N.; Verbert, K. GaCoVi: A Correlation Visualization to Support Interpretability-Aware Feature Selection for Regression Models. In EuroVis 2020—Short Papers; Kerren, A., Garth, C., Marai, G.E., Eds.; The Eurographics Association: Goslar, Germany, 2020. [Google Scholar] [CrossRef]
- Svelte Framework. Available online: https://svelte.dev/ (accessed on 28 June 2021).
- Carbon Components Svelte. Available online: https://carbon-svelte.vercel.app/ (accessed on 28 June 2021).
- Dowle, M.; Srinivasan, A. data.table: Extension of ‘data.frame’. R package version 1.14.0. Available online: https://rdatatable.gitlab.io/data.table/ (accessed on 28 June 2021).
- Hahsler, M.; Hornik, K.; Buchta, C. Getting things in order: An introduction to the R package seriation. J. Stat. Softw. 2008, 25, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Schloerke, B.; Allen, J. plumber: An API Generator for R. R package version 1.1.0. Available online: https://www.rplumber.io/ (accessed on 28 June 2021).
- Uddain, J.; Hossain, K.A.; Mostafa, M.; Rahman, M. Effect of different plant growth regulators on growth and yield of tomato. Int. J. Sustain. Agric. 2009, 1, 58–63. [Google Scholar]
- D3-tip. Available online: https://github.com/caged/d3-tip (accessed on 28 June 2021).
- Micromodal.js. Available online: https://micromodal.vercel.app/ (accessed on 28 June 2021).
- jQuery. Available online: https://jquery.com/ (accessed on 28 June 2021).
- Underscore.js. Available online: https://underscorejs.org/ (accessed on 28 June 2021).
- Asgarian, A.; Soffianian, A.; Pourmanafi, S. Crop type mapping in a highly fragmented and heterogeneous agricultural landscape: A case of central Iran using multi-temporal Landsat 8 imagery. Comput. Electron. Agric. 2016, 127, 531–540. [Google Scholar] [CrossRef]
- Zingaretti, L.M.; Renand, G.; Morgavi, D.P.; Ramayo-Caldas, Y. Link-HD: A versatile framework to explore and integrate heterogeneous microbial communities. Bioinformatics 2020, 36, 2298–2299. [Google Scholar] [CrossRef]
- Shneiderman, B. Dynamic queries for visual information seeking. IEEE Softw. 1994, 11, 70–77. [Google Scholar] [CrossRef] [Green Version]
- Inselberg, A.; Dimsdale, B. Parallel coordinates: A tool for visualizing multi-dimensional geometry. In Proceedings of the First IEEE Conference on Visualization: Visualization90, San Francisco, CA, USA, 23–26 October 1990; pp. 361–378. [Google Scholar]
- Martin, A.R.; Ward, M.O. High-Dimensional Brushing for Interactive Exploration of Multivariate Data. Master’s Thesis, Worcester Polytechnic Institute, Worcester, MA, USA, 1995. [Google Scholar]
- SlickGrid. Available online: https://slickgrid.net/ (accessed on 28 June 2021).
- parcoords-es. Available online: https://github.com/BigFatDog/parcoords-es (accessed on 28 June 2021).
- Materialize. Available online: https://materializecss.com/ (accessed on 28 June 2021).
- Navarro-Hellín, H.; Martinez-del Rincon, J.; Domingo-Miguel, R.; Soto-Valles, F.; Torres-Sánchez, R. A decision support system for managing irrigation in agriculture. Comput. Electron. Agric. 2016, 124, 121–131. [Google Scholar] [CrossRef] [Green Version]
- JustGage. Available online: https://toorshia.github.io/justgage/ (accessed on 28 June 2021).
- Muchovej, R.M.; Pacovsky, R. Future directions of by-products and wastes in agriculture. Agricultural Uses of By-Products and Wastes; ACS Publications: Washington, DC, USA, 1997; pp. 1–19. [Google Scholar]
- Ye, Z.; Harrison, R.; Cheng, V.; Bekhit, A. Wine making by-products. Valorization of Wine Making By-Products; CRC Press: Boca Raton, FL, USA, 2016; pp. 73–116. [Google Scholar]
- React. Available online: https://reactjs.org/ (accessed on 28 June 2021).
- React-map-gl. Available online: https://visgl.github.io/react-map-gl/ (accessed on 28 June 2021).
- Mapbox GL JS. Available online: https://www.mapbox.com/mapbox-gljs (accessed on 28 June 2021).
- Ant Design. Available online: https://ant.design/ (accessed on 28 June 2021).
- Kay, M.; Kola, T.; Hullman, J.R.; Munson, S.A. When (ish) is my bus? User-centered visualizations of uncertainty in everyday, mobile predictive systems. In Proceedings of the 2016 Chi Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 5092–5103. [Google Scholar]
- Potter, K.; Wilson, A.; Bremer, P.T.; Williams, D.; Doutriaux, C.; Pascucci, V.; Johnson, C.R. Ensemble-vis: A framework for the statistical visualization of ensemble data. In Proceedings of the International Conference on Data Mining Workshops, Sorrento, Italy, 17–20 November 2020; pp. 233–240. [Google Scholar]
- Boller, R.A.; Braun, S.A.; Miles, J.; Laidlaw, D.H. Application of uncertainty visualization methods to meteorological trajectories. Earth Sci. Inform. 2010, 3, 119–126. [Google Scholar] [CrossRef] [Green Version]
- Sanyal, J.; Zhang, S.; Dyer, J.; Mercer, A.; Amburn, P.; Moorhead, R. Noodles: A tool for visualization of numerical weather model ensemble uncertainty. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1421–1430. [Google Scholar] [CrossRef] [PubMed]
- Ristovski, G.; Preusser, T.; Hahn, H.K.; Linsen, L. Uncertainty in medical visualization: Towards a taxonomy. Comput. Graph. 2014, 39, 60–73. [Google Scholar] [CrossRef]
- Daradkeh, M.; Abul-Huda, B. Incorporating uncertainty into decision-making: An information visualisation approach. In Proceedings of the International Conference on Decision Support System Technology, Thessaloniki, Greece, 23–25 May 2022; pp. 74–87. [Google Scholar]
- Mchopa, A.; Ruoja, C.; Huka, H. Price fluctuation of agricultural products and its impact on small scale farmers development: Case analysis from Kilimanjaro Tanzania. Eur. J. Bus. Manag. 2014, 6, 155–160. [Google Scholar]
- Lazar, J.; Feng, J.H.; Hochheiser, H. Research Methods in Human-Computer Interaction; Morgan Kaufmann (Elsevier): Burlington, MA, USA, 2017. [Google Scholar]
- Bangor, A.; Kortum, P.T.; Miller, J.T. An Empirical Evaluation of the System Usability Scale. Int. J. Human Comput. Interact. 2008, 24, 574–594. [Google Scholar] [CrossRef]
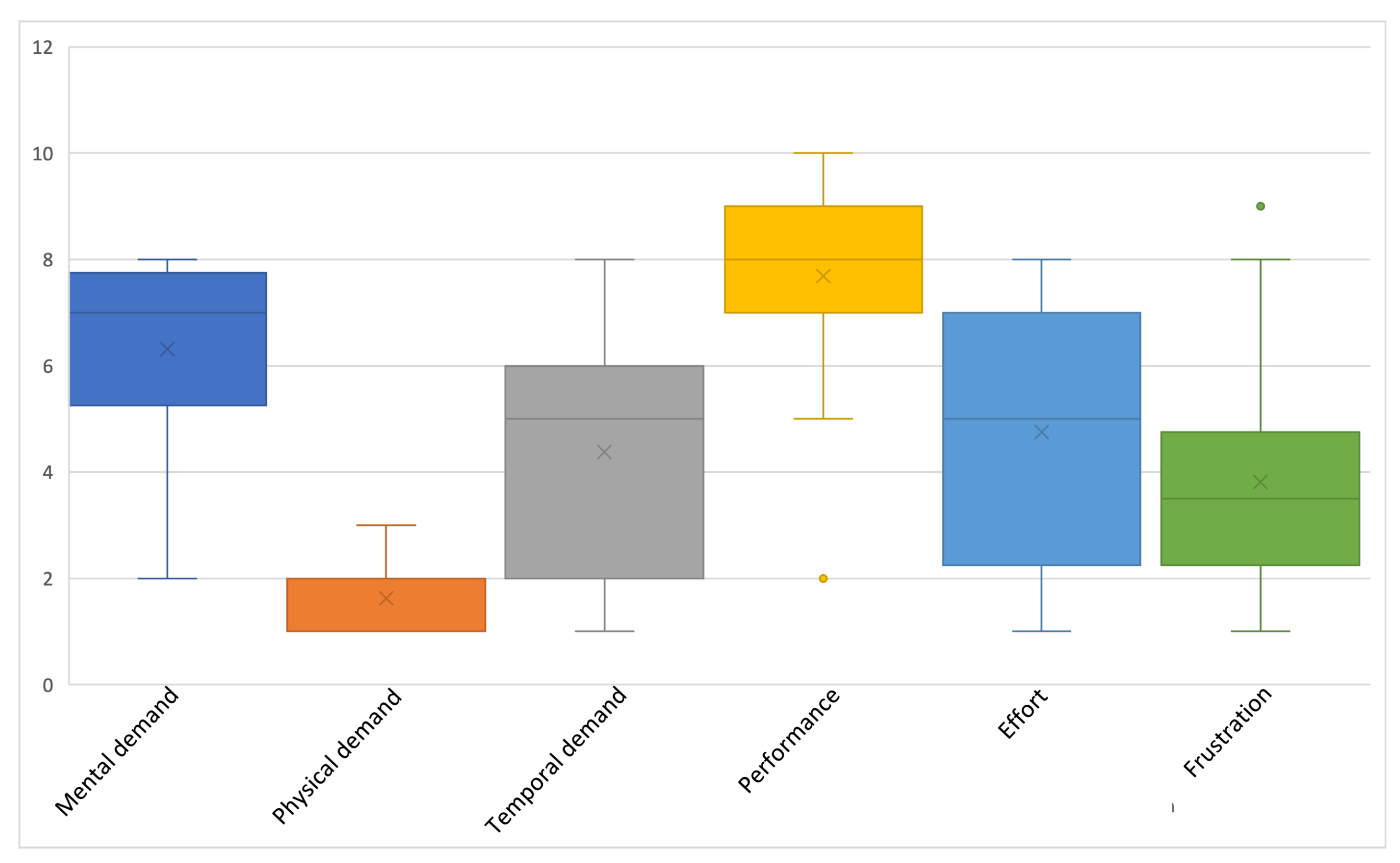
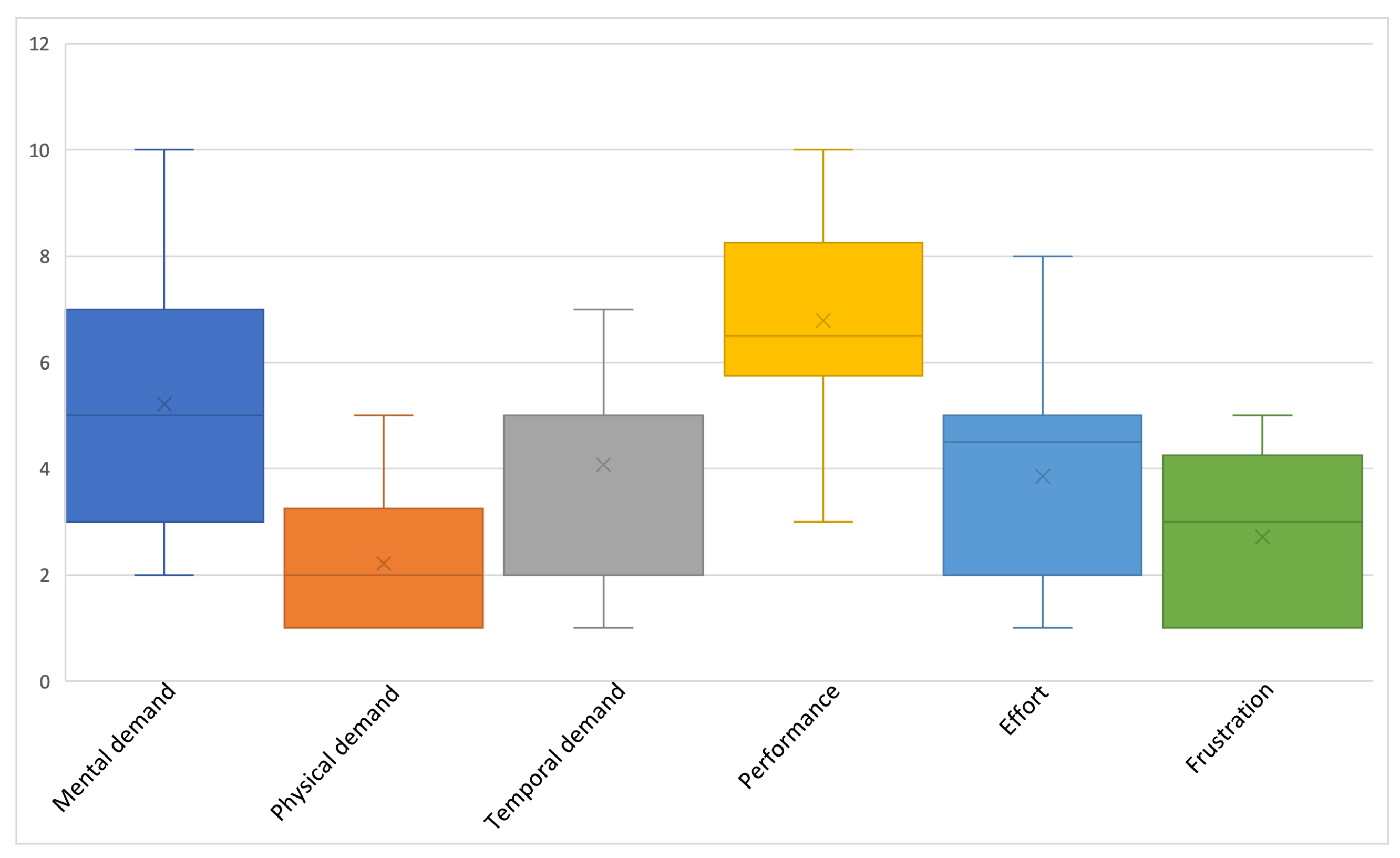
- Hart, S.G. NASA-task load index (NASA-TLX); 20 years later. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Los Angeles, CA, USA, 1 October 2006; Sage Publications: Southend Oaks, CA, USA, 2006; Volume 50, pp. 904–908. [Google Scholar]
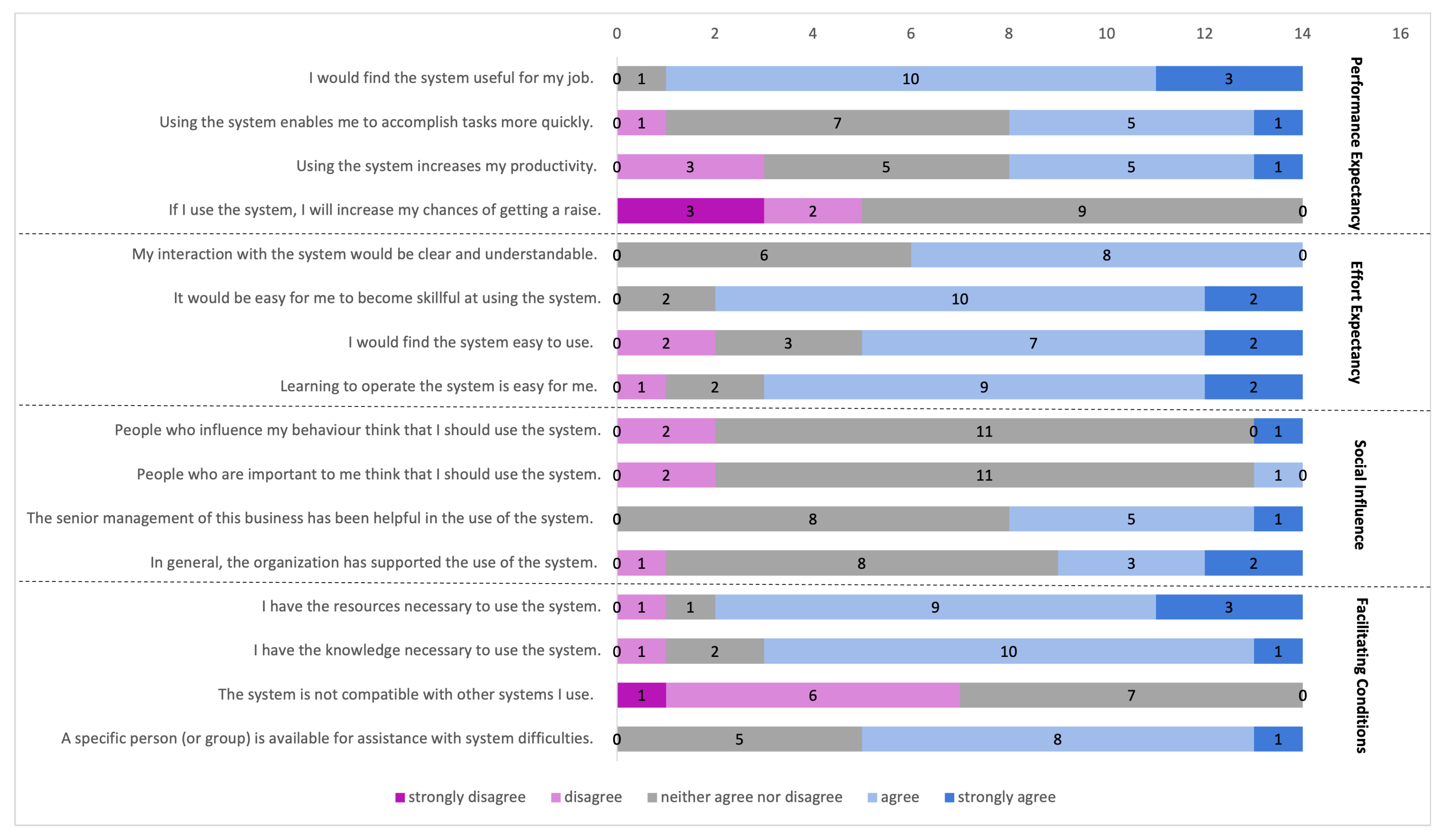
- Venkatesh, V.; Morris, M.G.; Davis, G.B.; Davis, F.D. User acceptance of information technology: Toward a unified view. MIS Q. 2003, 27, 425–478. [Google Scholar] [CrossRef] [Green Version]
- Brooke, J. SUS-A quick and dirty usability scale. Usability Eval. Ind. 1996, 189, 4–7. [Google Scholar]
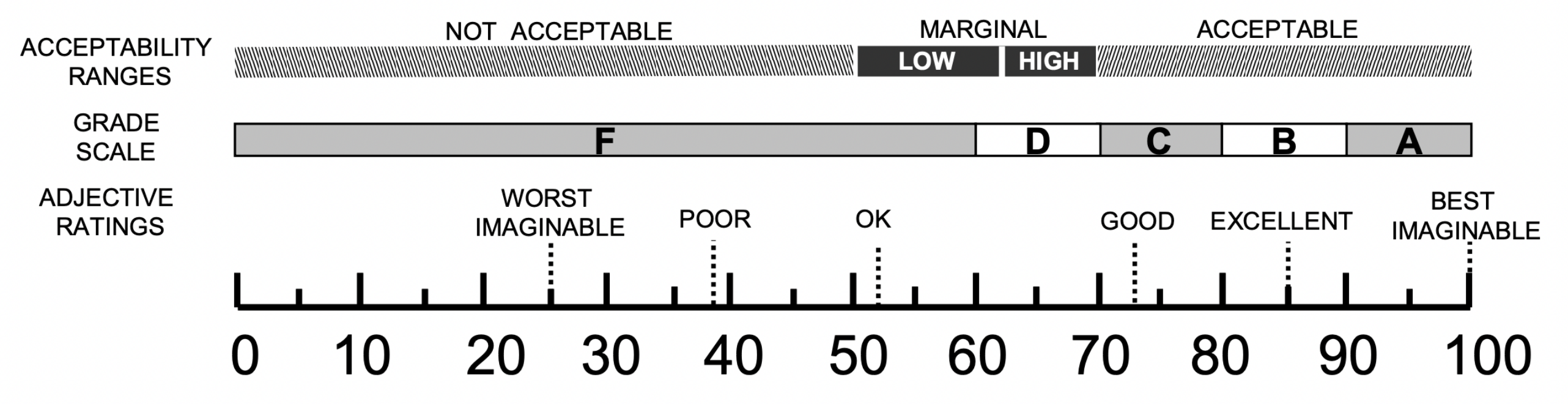
- Bangor, A.; Kortum, P.; Miller, J. Determining what individual SUS scores mean: Adding an adjective rating scale. J. Usability Stud. 2009, 4, 114–123. [Google Scholar]
- Brooke, J. SUS: A retrospective. J. Usability Stud. 2013, 8, 29–40. [Google Scholar]
- Sauro, J. A Practical Guide to the System Usability Scale: Background, Benchmarks & Best Practices; Measuring Usability LLC: Denver, CO, USA, 2011. [Google Scholar]
- Larman, C.; Basili, V.R. Iterative and incremental developments. a brief history. Computer 2003, 36, 47–56. [Google Scholar] [CrossRef]
- Spinuzzi, C. The methodology of participatory design. Tech. Commun. 2005, 52, 163–174. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Use Cases | Metrics |
|---|---|
| Correlation analysis of multivariate data | SUS, NASA-TLX and UTAUT |
| Analysis of plant growth | SUS, NASA-TLX and UTAUT |
| Exploratory analysis of heterogeneous data | SUS, NASA-TLX and UTAUT |
| Analysis of water stress and irrigation requirements | SUS, NASA-TLX and UTAUT |
| Analysis of biological efficacy in by-products | SUS, NASA-TLX and UTAUT |
| Uncertainty-aware price prediction | Semi-structured interview focusing on usability and trust |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Htun, N.-N.; Rojo, D.; Ooge, J.; De Croon, R.; Kasimati, A.; Verbert, K. Developing Visual-Assisted Decision Support Systems across Diverse Agricultural Use Cases. Agriculture 2022, 12, 1027. https://doi.org/10.3390/agriculture12071027
Htun N-N, Rojo D, Ooge J, De Croon R, Kasimati A, Verbert K. Developing Visual-Assisted Decision Support Systems across Diverse Agricultural Use Cases. Agriculture. 2022; 12(7):1027. https://doi.org/10.3390/agriculture12071027
Chicago/Turabian StyleHtun, Nyi-Nyi, Diego Rojo, Jeroen Ooge, Robin De Croon, Aikaterini Kasimati, and Katrien Verbert. 2022. "Developing Visual-Assisted Decision Support Systems across Diverse Agricultural Use Cases" Agriculture 12, no. 7: 1027. https://doi.org/10.3390/agriculture12071027
APA StyleHtun, N. -N., Rojo, D., Ooge, J., De Croon, R., Kasimati, A., & Verbert, K. (2022). Developing Visual-Assisted Decision Support Systems across Diverse Agricultural Use Cases. Agriculture, 12(7), 1027. https://doi.org/10.3390/agriculture12071027