


LCA-Net: A Lightweight Cross-Stage Aggregated Neural Network for Fine-Grained Recognition of Crop Pests and Diseases

 ,
, 
 , ,
, ,
Abstract
:1. Introduction
- (1)
- In order to address the practical deployment challenges posed by the excessive number of model parameters and the inadequate real-time performance for mobile applications, we propose a lightweight optimization scheme to rebuild the CSPNet-based backbone network [8]. This scheme involves enhancing the efficiency of large-scale networks and introducing cross-level aggregation modules.
- (2)
- To overcome the limitations in mining fine-grained features and the subpar identification accuracy in real-world scenarios, we focus on enhancing the network’s feature extraction capability. Our approach includes constructing a pyramid structure with a maximum area response, incorporating a channel spatial attention mechanism, and effective data augmentation preprocessing. Finally, with the supervision of the adjusted loss function, the entire model improves the fine-grained identification accuracy and achieves a good balance between efficiency and parameter scale.
2. Related Works
2.1. Deep Learning Image Identification Technologies
2.2. Fine-Grained Visual Classification
2.3. Lightweight Modeling Optimization
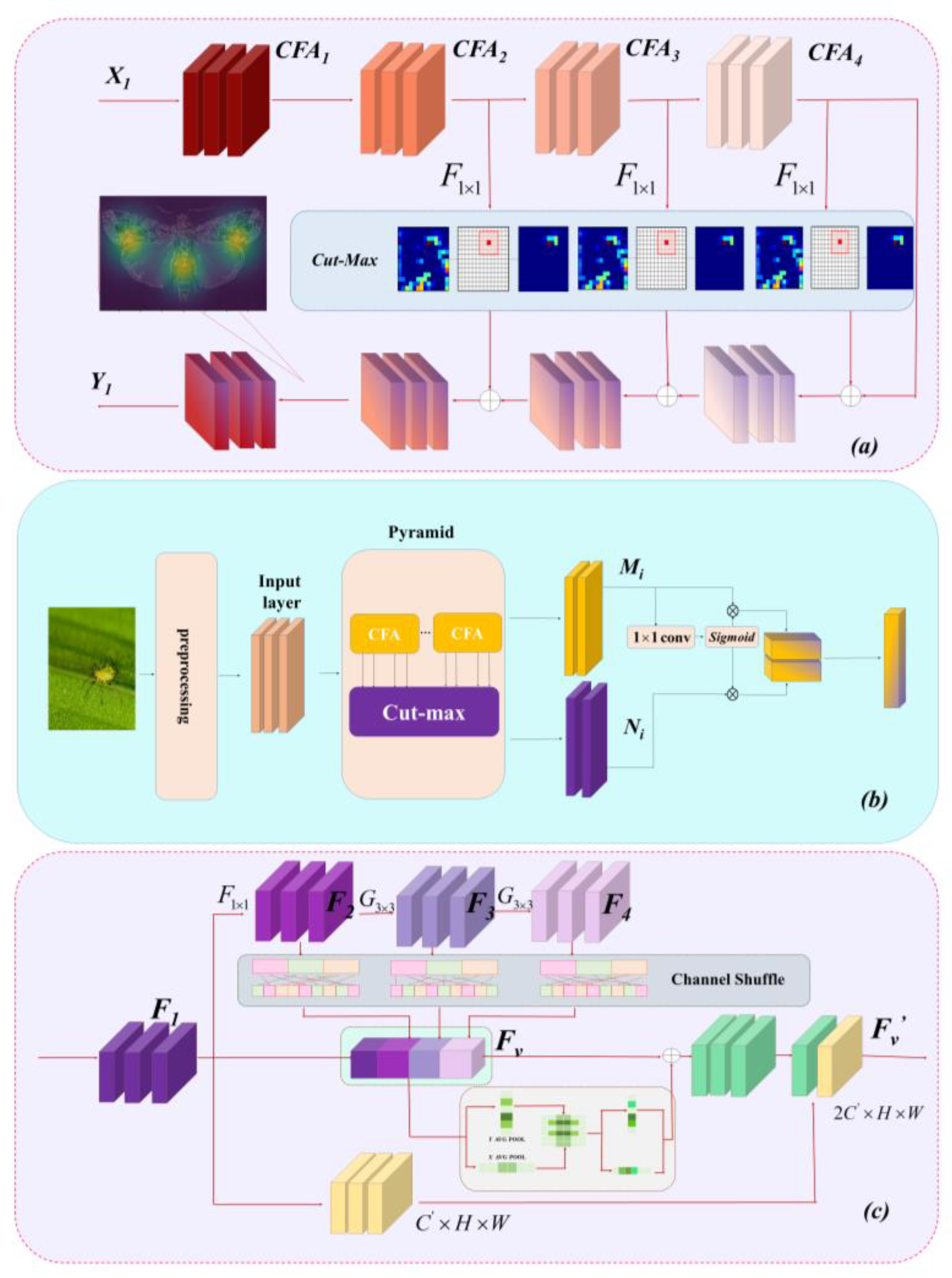
3. Materials and Methods
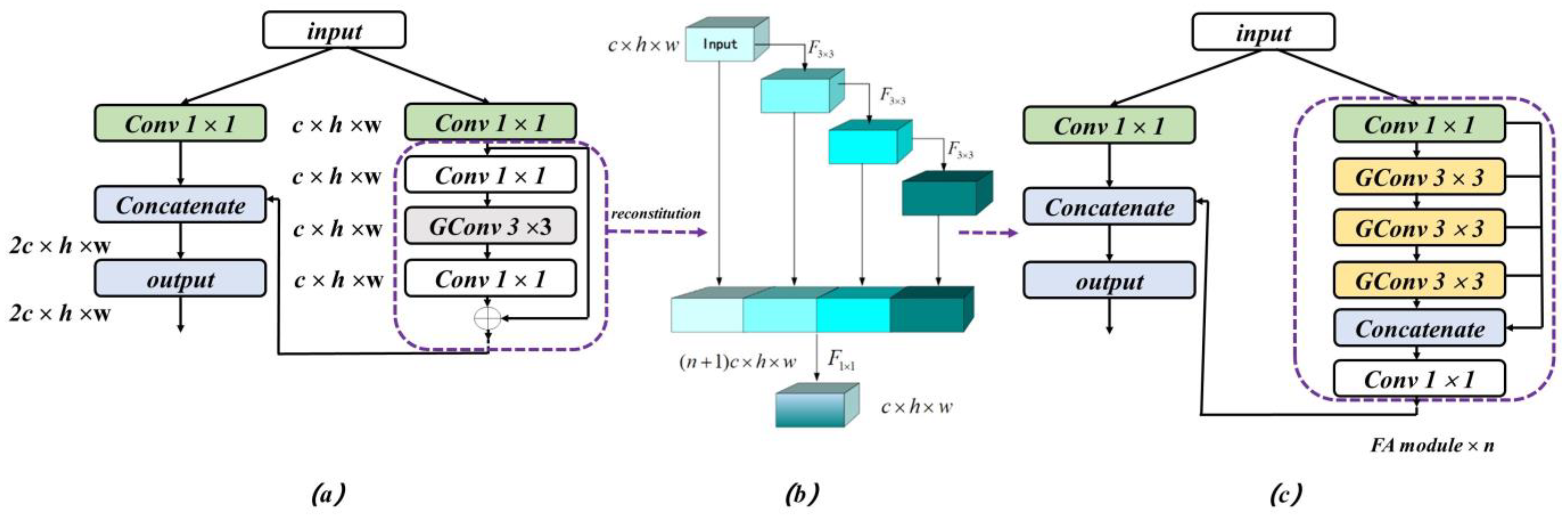
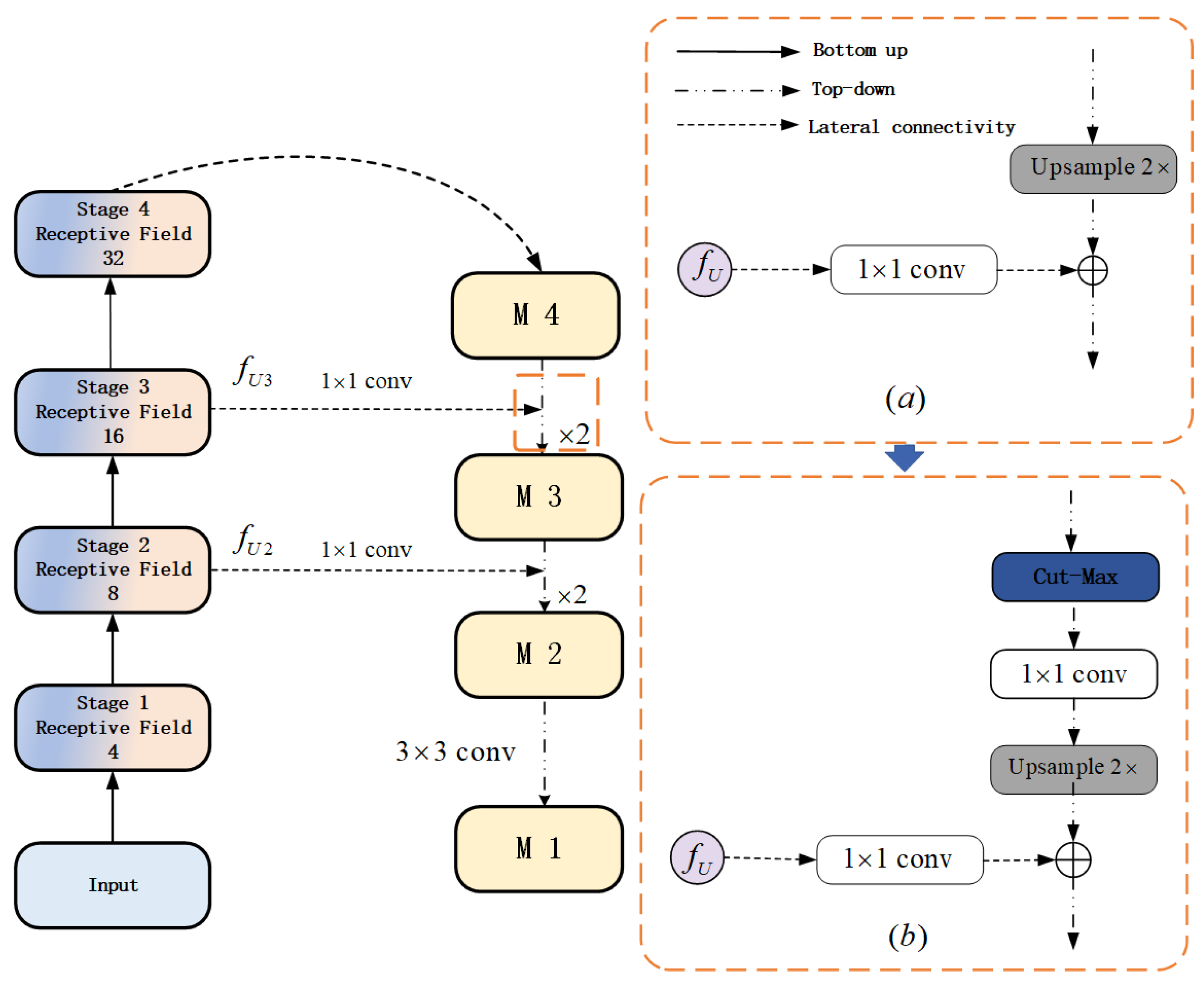
3.1. Lightweight Backbone Network Architecture
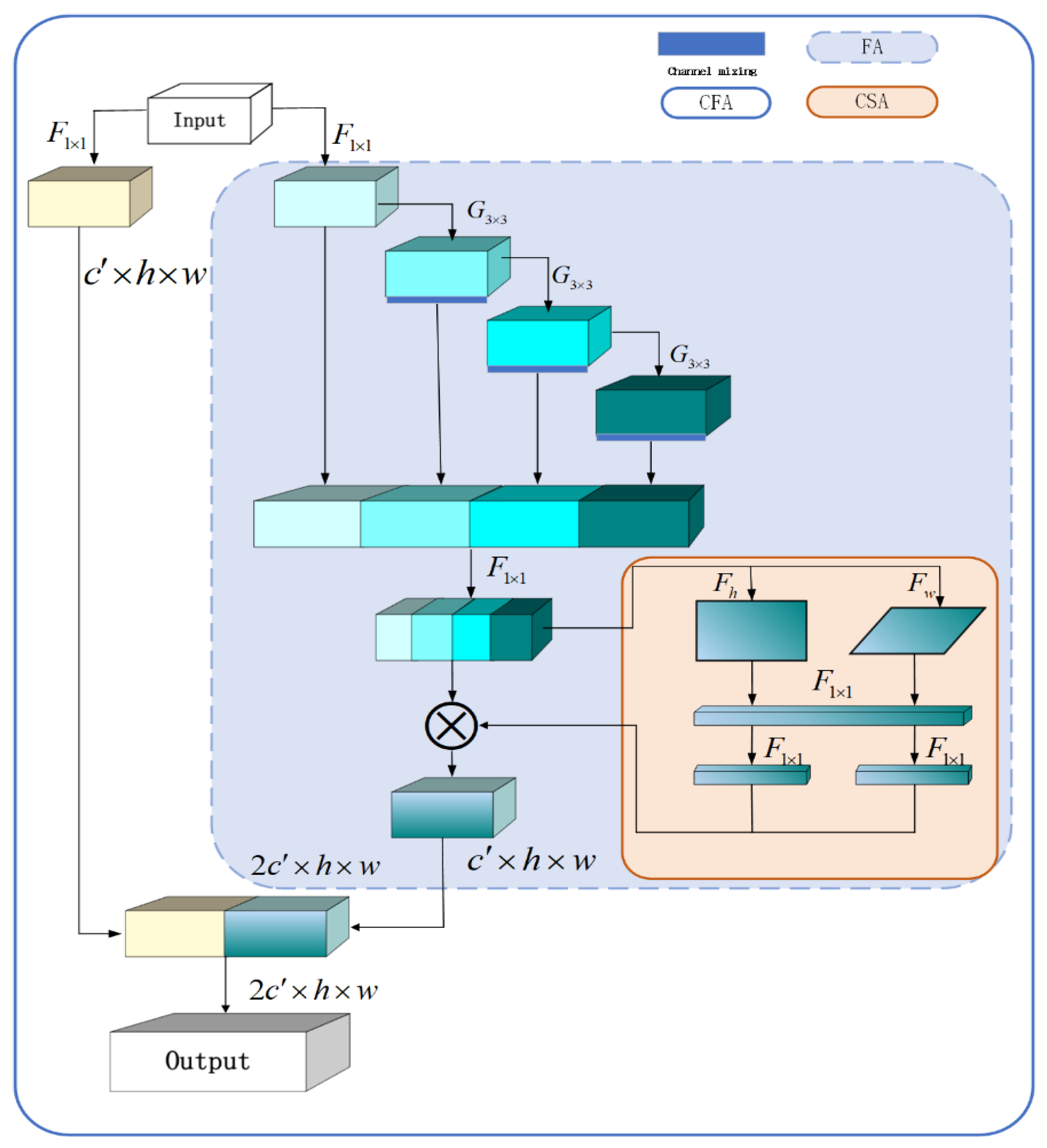
3.2. Channel–Spatial Cross-Attention Module
3.3. Maximum Cropping Feature Pyramid Module
3.4. Data Enhancement Preprocessing
- (1)
- First, all the sample images are resized to the square to fit the input size of the deep learning network;
- (2)
- Randomly flip the sample image horizontally and vertically with a probability of 0.5 to increase the diversity of the image and enhance the translation invariance of the image;
- (3)
- The sample image is cropped into a square image with a randomized region during the training phase. Conversely, during the testing phase, the sample image is cropped into a square image with the center region;
- (4)
- Randomly rotate all sample images within the range [−15°, 15°] to improve the distortion adaptation of the images;
- (5)
- The sample image undergoes adjustments in the HSV color space, specifically in the hue H, saturation S, and luminance V parameters. These adjustments are made based on a predetermined offset of 0.3. In other words, the values of H, S, and V are randomly set within the range of [70%, 130%] of the original image. This process aims to generate variations of the sample image under different lighting conditions;
- (6)
- For data regularization, the sample images undergo additional processing through the utilization of the CutMix method. CutMix involves cropping out a specific region from the image, but instead of replacing it with zero pixels, it is randomly filled with pixel values from the corresponding areas in other training data. The classification results are then distributed based on a predefined ratio. CutMix offers several advantages, including improved training efficiency by eliminating noninformative pixels, enhanced spatial localization ability of the model, and no extra computational overhead during the training and testing processes.
3.5. Loss Function Design
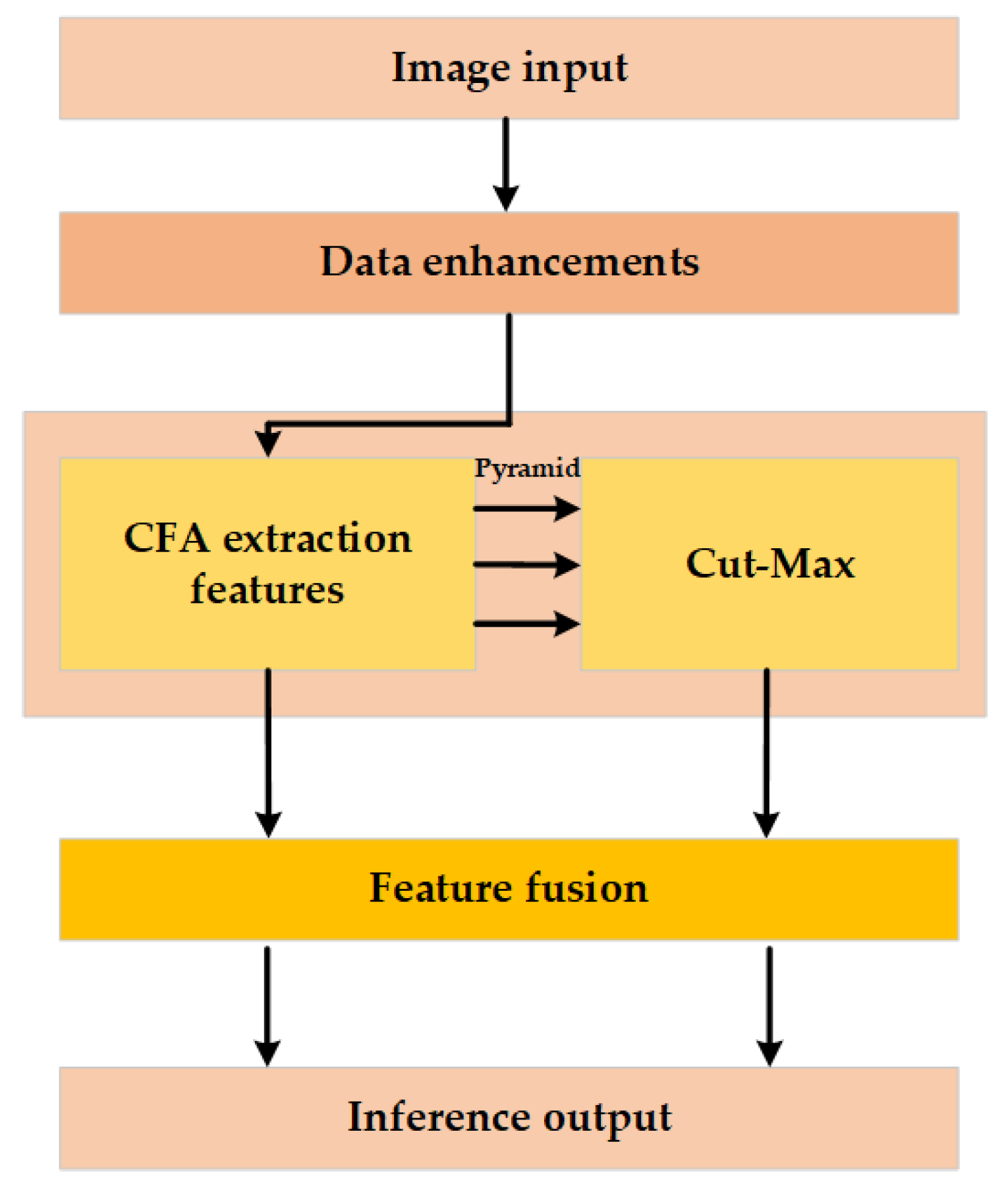
3.6. LCA-Net Process Illustration
| Algorithm 1: LCA-Net Process |
| 1: input: # Input feature atlas # CFA # Cut-max # Response Score Threshold 2: ← # Data Enhancement 3: for in do # Extract features 4: ← 5: return 6: for in do # Find the region of maximum response for each feature map 7: ← 8: for in do #Judging Response Scores 9: if then 10: 11: # Weighting of areas of key concern. 12: end |
| 13: end 14: return 15: end |
4. Results and Discussion
4.1. Experimental Dataset and Settings
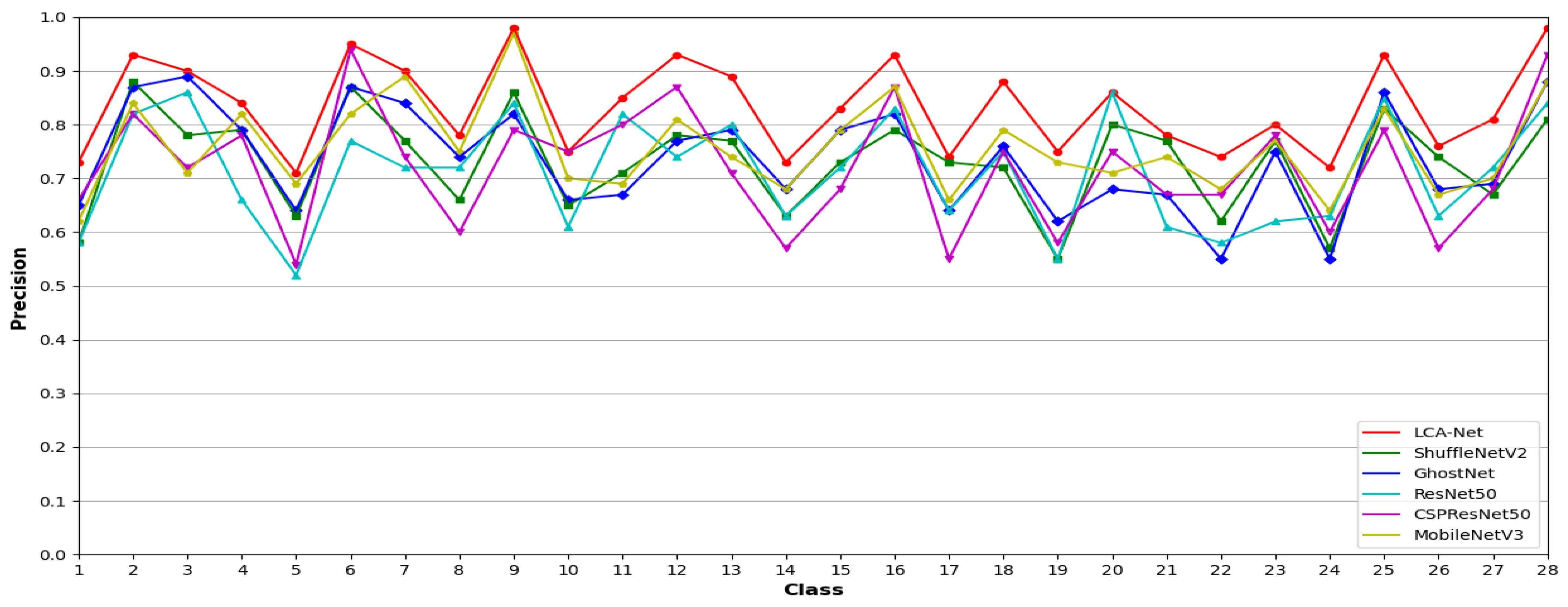
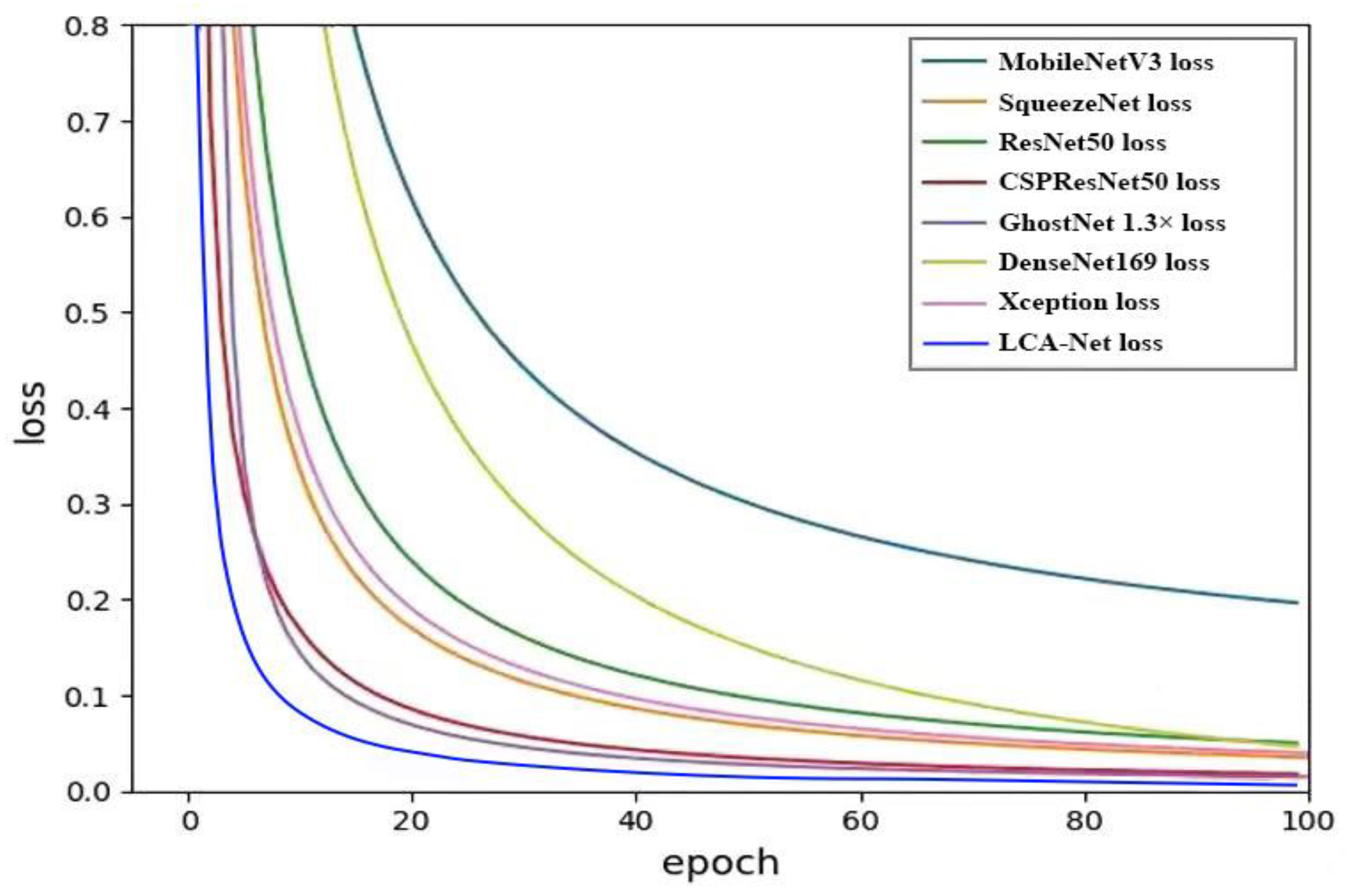
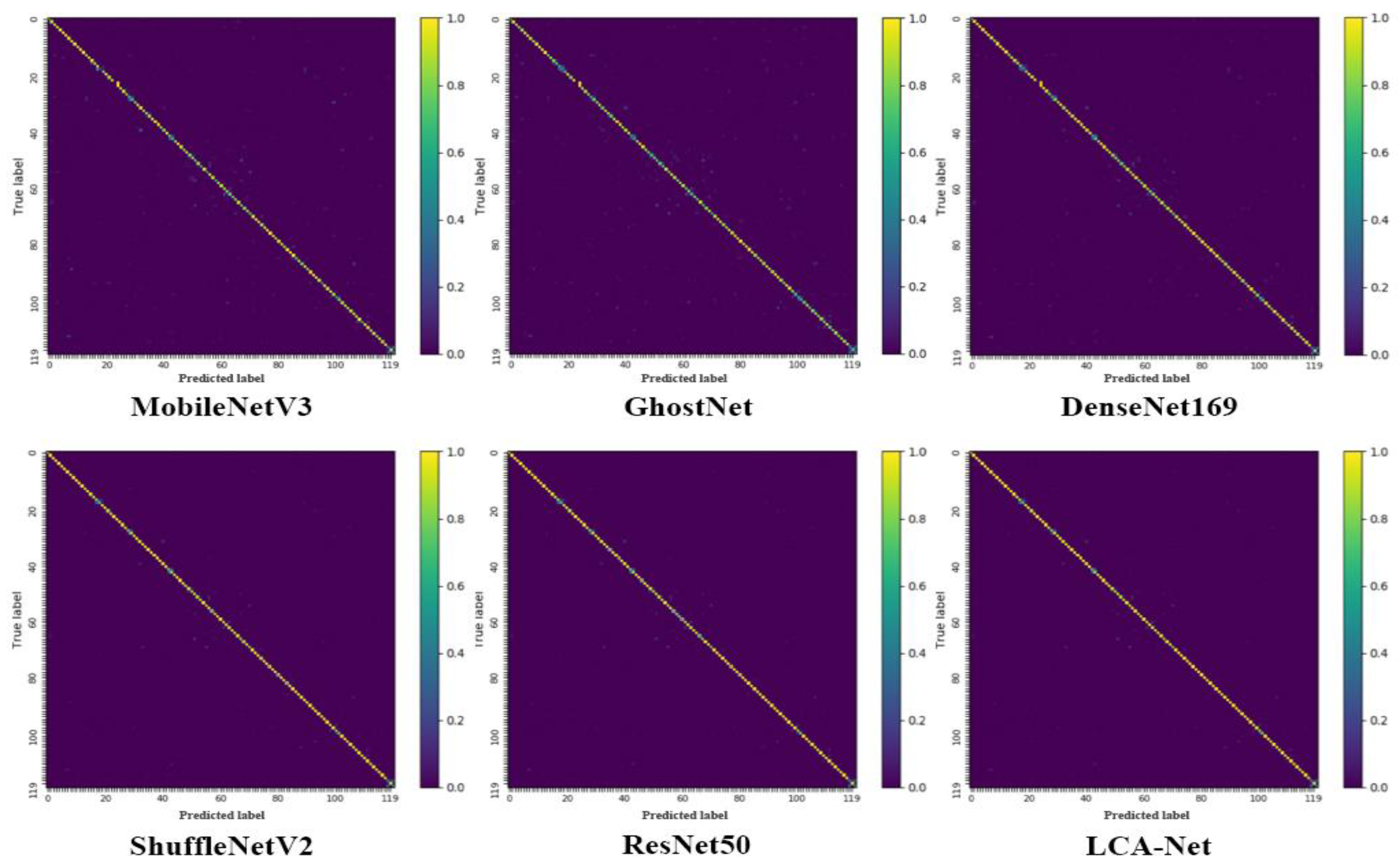
4.2. Comparative Experimental Results
4.3. Experimental Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, Y.-Y.; Kong, J.-L.; Jin, X.-B.; Wang, X.-Y.; Su, T.-L.; Zuo, M. CropDeep: The Crop Vision Dataset for Deep-Learning-Based Classification and Detection in Precision Agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X. Fine-grained pests & diseases recognition via Spatial Feature-enhanced attention architecture with high-order pooling representation for precision agriculture practice. Agriculture 2022, 2022, 1592804. [Google Scholar]
- Jin, X.-B.; Wang, Z.-Y.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L.; Ma, H.-J.; Chakrabarti, P. Deep Spatio-Temporal Graph Network with Self-Optimization for Air Quality Prediction. Entropy 2023, 25, 247. [Google Scholar] [CrossRef]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X. A spatial feature-enhanced attention neural network with high-order pooling representation for application in pest and disease recognition. Agriculture 2022, 12, 500. [Google Scholar] [CrossRef]
- Jin, X.-B.; Wang, Z.-Y.; Gong, W.-T.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L.; Ma, H.-J.; Chakrabarti, P. Variational Bayesian Network with Information Interpretability Filtering for Air Quality Forecasting. Mathematics 2023, 11, 837. [Google Scholar] [CrossRef]
- Kong, J.L.; Wang, H.X.; Wang, X.Y.; Jin, X.B.; Fang, X.; Lin, S. Multi-stream hybrid architecture based on cross-level fusion strategy for fine-grained crop species recognition in precision agriculture. Comput. Electron. Agric. 2021, 185, 106134. [Google Scholar] [CrossRef]
- Ye, M.; Ruiwen, N.; Chang, Z. A lightweight model of VGG-16 for remote sensing image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6916–6922. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Wei, D.; Chen, J.; Luo, T. Classification of crop pests based on multi-scale feature fusion. Comput. Electron. Agric. 2022, 194, 106736. [Google Scholar] [CrossRef]
- Xing, S.; Lee, H.J. Crop pests and diseases recognition using DANet with TLDP. Comput. Electron. Agric. 2022, 199, 107144. [Google Scholar] [CrossRef]
- Lin, T.L.; Chang, H.Y.; Chen, K.H. The pest and disease identification in the growth of sweet peppers using faster R-CNN and mask R-CNN. J. Internet Technol. 2020, 21, 605–614. [Google Scholar]
- Akhal, E.H.; Yahya, A.B.; Moussa, N. A novel approach for image-based olive leaf diseases classification using a deep hybrid model. Ecol. Inform. 2023, 77, 102276. [Google Scholar] [CrossRef]
- Singh, A.K.; Sreenivasu, S.V.N.; Mahalaxmi, U. Hybrid feature-based disease detection in plant leaf using convolutional neural network, bayesian optimized SVM, and random forest classifier. J. Food Qual. 2022, 2022, 2845320. [Google Scholar] [CrossRef]
- Kong, J.-L.; Fan, X.-M.; Jin, X.-B.; Su, T.-L.; Bai, Y.-T.; Ma, H.-J.; Zuo, M. BMAE-Net: A Data-Driven Weather Prediction Network for Smart Agriculture. Agronomy 2023, 13, 625. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2016; pp. 770–778. [Google Scholar]
- Ge, Z.; Bewley, A.; Mccool, C. Fine-grained classification via mixture of deep convolutional neural networks. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–6. [Google Scholar]
- Tiwari, V.; Joshi, R.C.; Dutta, M.K. Dense convolutional neural networks based multiclass plant disease detection and classification using leaf images. Ecol. Inform. 2021, 63, 101289. [Google Scholar] [CrossRef]
- Kang, G.; Hou, L.; Zhao, Z. Research on the Application of Convolutional Neural Network Based on YOLO Algorithm in Pest Small Target Detection. In Proceedings of the Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS), Shenyang, China, 24–26 February 2023; pp. 131–135. [Google Scholar]
- Li, Y.; Wang, H.; Dang, L.M. Crop pest recognition in natural scenes using convolutional neural networks. Comput. Electron. Agric. 2020, 169, 105174. [Google Scholar] [CrossRef]
- Istiak, M.A.; Syeed, M.M.M.; Hossain, M.S. Adoption of Unmanned Aerial Vehicle (UAV) imagery in agricultural management: A systematic literature review. Ecol. Inform. 2023. [Google Scholar] [CrossRef]
- Donahue, J.; Jia, Y.; Vinyals, O. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the International Conference on Machine Learning, PMLR, Bejing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Huang, S.; Xu, Z.; Tao, D. Part-stacked cnn for fine-grained visual categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1173–1182. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wei, X.S.; Xie, C.W.; Wu, J. Mask-CNN: Localizing parts and selecting descriptors for fine-grained bird species categorization. Pattern Recognit. 2018, 76, 704–714. [Google Scholar] [CrossRef]
- Zhao, B.; Wu, X.; Feng, J. Diversified visual attention networks for fine-grained object classification. IEEE Trans. Multimed. 2017, 19, 1245–1256. [Google Scholar] [CrossRef]
- Fu, J.; Zheng, H.; Mei, T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Zheng, H.; Fu, J.; Mei, T. Learning multi-attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5209–5217. [Google Scholar]
- Sun, M.; Yuan, Y.; Zhou, F. Multi-attention multi-class constraint for fine-grained image recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 805–821. [Google Scholar]
- Wang, Y.; Morariu, V.I.; Davis, L.S. Learning a discriminative filter bank within a cnn for fine-grained recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4148–4157. [Google Scholar]
- Yang, Z.; Luo, T.; Wang, D. Learning to navigate for fine-grained classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 420–435. [Google Scholar]
- Liang, J.; Guo, J.; Liu, X. Fine-grained image classification with Gaussian mixture layer. IEEE Access 2018, 6, 53356–53367. [Google Scholar] [CrossRef]
- Zhuang, P.; Wang, Y.; Qiao, Y. Learning Attentive Pairwise Interaction for Fine-Grained Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13130–13137. [Google Scholar]
- Iandola, F.N.; Hanm, S.; Moskewicz, M.W. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M. Searching for MobileNetV3. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Salt Lake City, UT, USA, 18–23 June 2018; pp. 116–131. [Google Scholar]
- Gao, H.; Wang, Z.; Cai, L. Channelnets: Compact and efficient convolutional neural networks via channel-wise convolutions. Adv. Neural Inf. Process. Syst. 2018, 43, 2570–2581. [Google Scholar] [CrossRef]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A real-time object detection system on mobile devices. arXiv 2018, arXiv:1804.06882. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Kong, J.; Fan, X.; Jin, X.; Lin, S.; Zuo, M. A Variational Bayesian Inference-Based En-Decoder Framework for Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2023. [Google Scholar] [CrossRef]
- Lu, J.; Tan, L.; Jiang, H. Review on Convolutional Neural Network (CNN) Applied to Plant Leaf Disease Classification. Agriculture 2021, 11, 707. [Google Scholar] [CrossRef]
- Jin, X.; Zhang, J.; Kong, J.; Su, T.; Bai, Y. A Reversible Automatic Selection Normalization (RASN) Deep Network for Predicting in the Smart Agriculture System. Agronomy 2022, 12, 591. [Google Scholar] [CrossRef]
- Mishra, P.; Polder, G.; Vilfan, N. Close range spectral imaging for disease detection in plants using autonomous platforms: A review on recent studies. Curr. Robot. Rep. 2020, 1, 43–48. [Google Scholar] [CrossRef]
- Wu, X.; Zhan, C.; Lai, Y.K. Ip102: A large-scale benchmark dataset for insect pest recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8787–8796. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q. GhostNet: More Features from Cheap Operations. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1577–1586. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
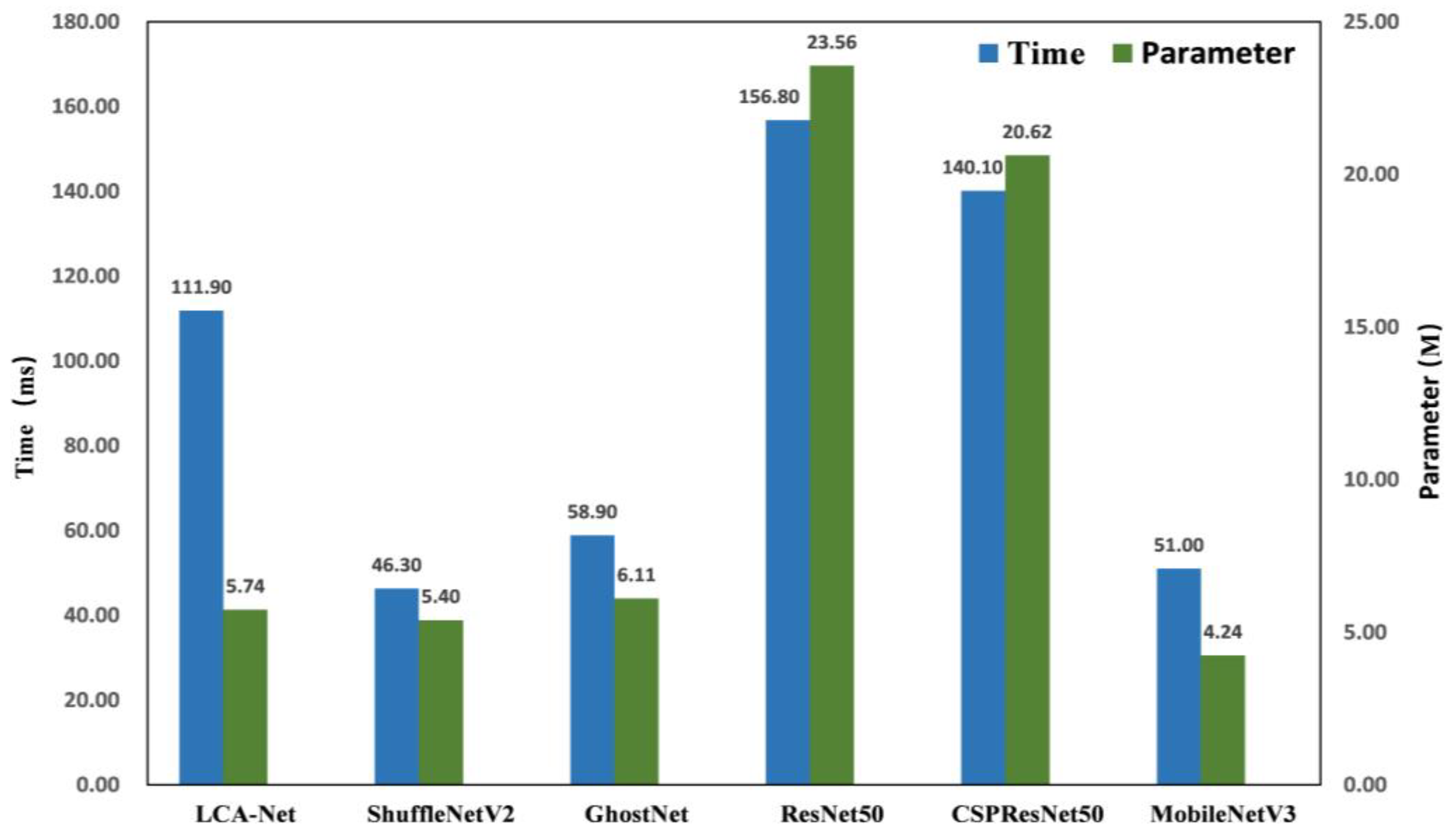
| Models | Accuracy Rate (%) | Number of Parameters (M) | Time (ms) |
|---|---|---|---|
| MobileNetV3 1.0× [36] | 64.8 | 4.24 | 51.0 |
| ShuffleNetV2 2.0× [38] | 66.3 | 5.4 | 46.3 |
| Xception [48] | 68.1 | 5.61 | 50.9 |
| SqueezeNet [34] | 70.2 | 5.81 | 53.6 |
| GhostNet 1.3× [49] | 71.8 | 6.11 | 58.9 |
| ResNet50 [16] | 73.2 | 23.56 | 156.8 |
| CSPResNet50 [8] | 75.3 | 20.62 | 140.1 |
| DenseNet169 [41] | 76.9 | 12.53 | 220.7 |
| LCA-Net | 83.8 | 5.74 | 111.9 |
| Models | Train:Test | ||
|---|---|---|---|
| 8:2 (Acc %) | 7:3 (Acc %) | 6:4 (Acc %) | |
| MobileNetV3 1.0× [36] | 64.8% | 63.1 | 61.2 |
| ShuffleNetV2 2.0× [38] | 66.3% | 64.2 | 62.4 |
| Xception [48] | 68.1 | 66.9 | 64.6 |
| SqueezeNet [34] | 70.2 | 68.6 | 66.4 |
| GhostNet 1.3× [49] | 71.8 | 70.4 | 69.2 |
| ResNet50 [16] | 73.2 | 70.3 | 67.8 |
| CSPResNet50 [8] | 75.3 | 74.1 | 72.9 |
| DenseNet169 [41] | 76.9 | 75.5 | 74.7 |
| LCA-Net | 83.8 | 83.2 | 82.5 |
| FA | CSA | Feature Pyramid | Cut-Max | Acc (%) |
|---|---|---|---|---|
| √ | 77.2 | |||
| √ | √ | 77.9 | ||
| √ | 78.1 | |||
| √ | √ | 80.2 | ||
| √ | √ | √ | 81.5 | |
| √ | √ | √ | 82.3 | |
| √ | √ | √ | √ | 83.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, J.; Xiao, Y.; Jin, X.; Cai, Y.; Ding, C.; Bai, Y. LCA-Net: A Lightweight Cross-Stage Aggregated Neural Network for Fine-Grained Recognition of Crop Pests and Diseases. Agriculture 2023, 13, 2080. https://doi.org/10.3390/agriculture13112080
Kong J, Xiao Y, Jin X, Cai Y, Ding C, Bai Y. LCA-Net: A Lightweight Cross-Stage Aggregated Neural Network for Fine-Grained Recognition of Crop Pests and Diseases. Agriculture. 2023; 13(11):2080. https://doi.org/10.3390/agriculture13112080
Chicago/Turabian StyleKong, Jianlei, Yang Xiao, Xuebo Jin, Yuanyuan Cai, Chao Ding, and Yuting Bai. 2023. "LCA-Net: A Lightweight Cross-Stage Aggregated Neural Network for Fine-Grained Recognition of Crop Pests and Diseases" Agriculture 13, no. 11: 2080. https://doi.org/10.3390/agriculture13112080
APA StyleKong, J., Xiao, Y., Jin, X., Cai, Y., Ding, C., & Bai, Y. (2023). LCA-Net: A Lightweight Cross-Stage Aggregated Neural Network for Fine-Grained Recognition of Crop Pests and Diseases. Agriculture, 13(11), 2080. https://doi.org/10.3390/agriculture13112080