
An Improved Mask RCNN Model for Segmentation of ‘Kyoho’ (Vitis labruscana) Grape Bunch and Detection of Its Maturity Level



Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Dataset
2.2. Mask RCNN Network Combined with Attention Mechanism Module
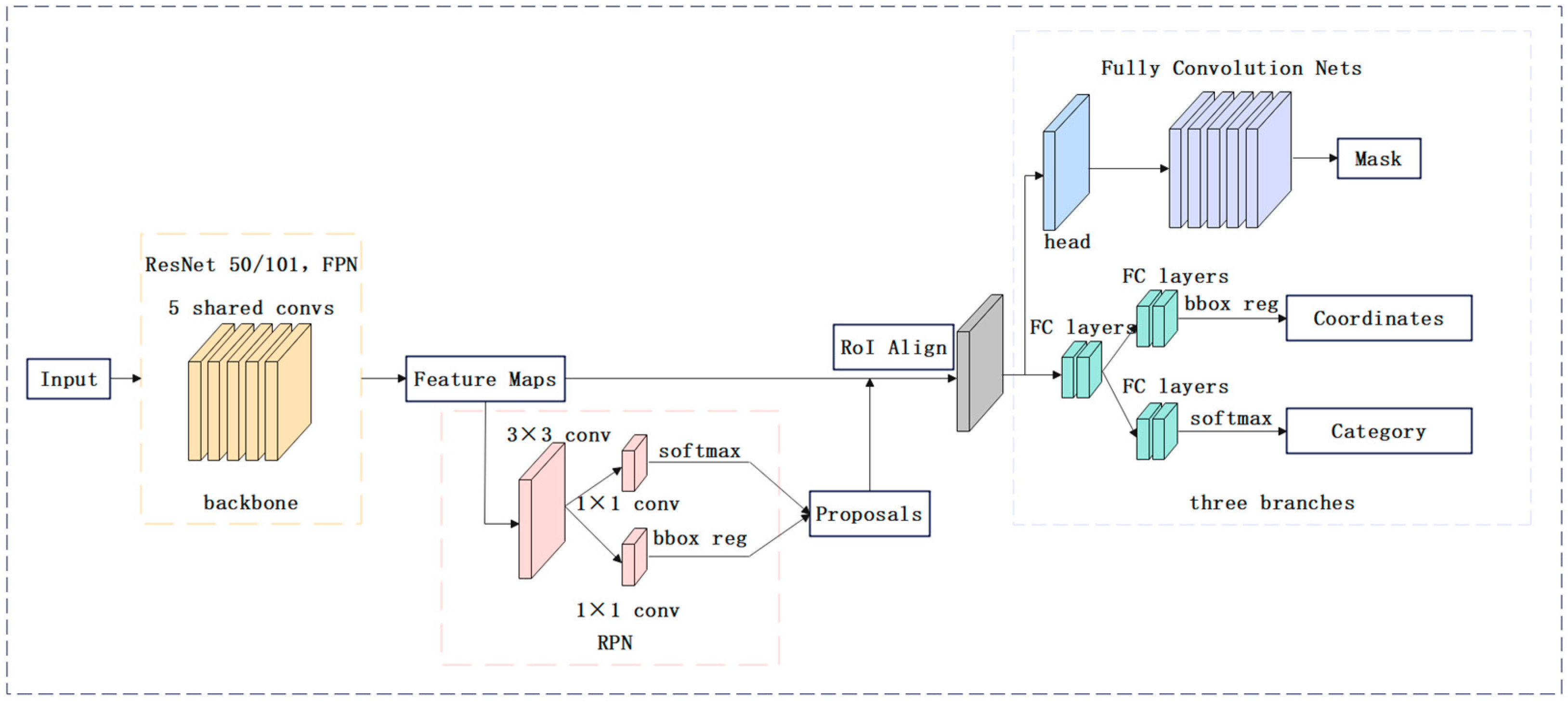
2.2.1. Mask RCNN Network
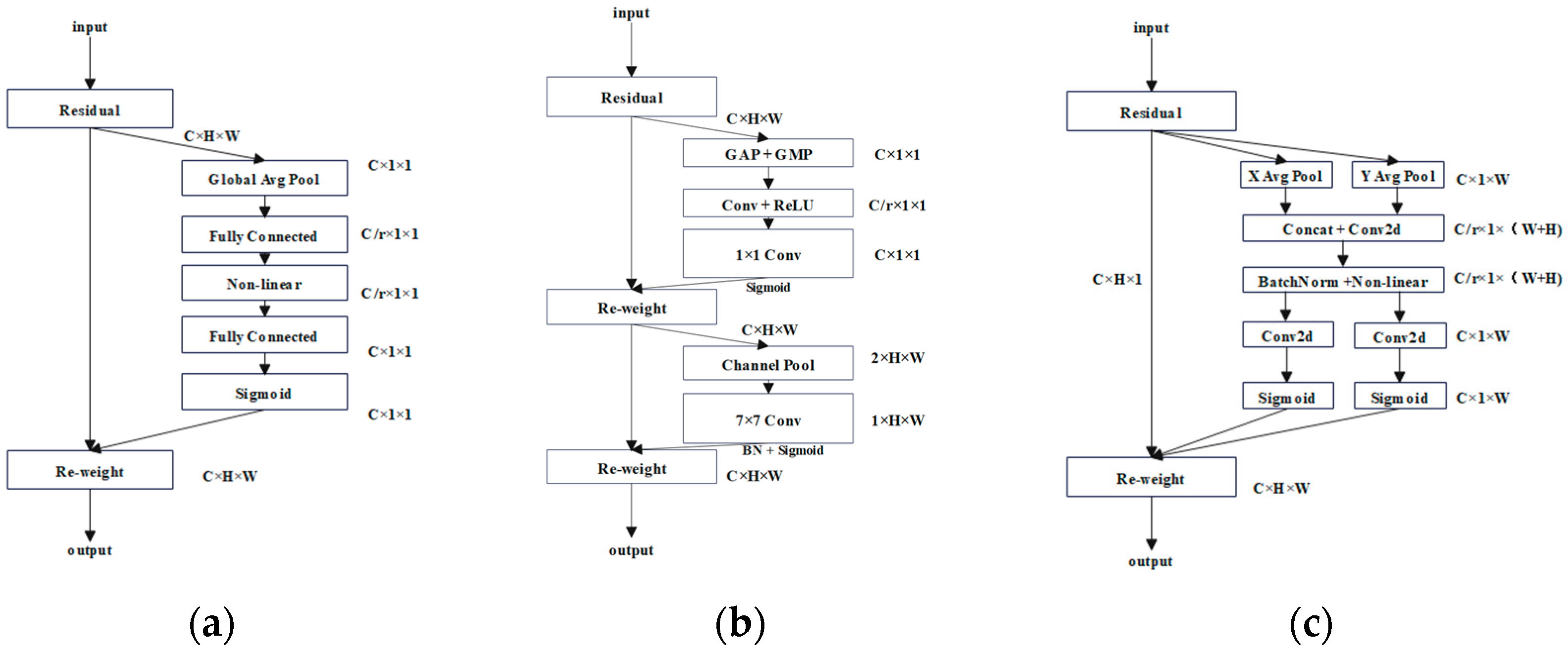
2.2.2. Squeeze-and-Excitation Attention (SE)
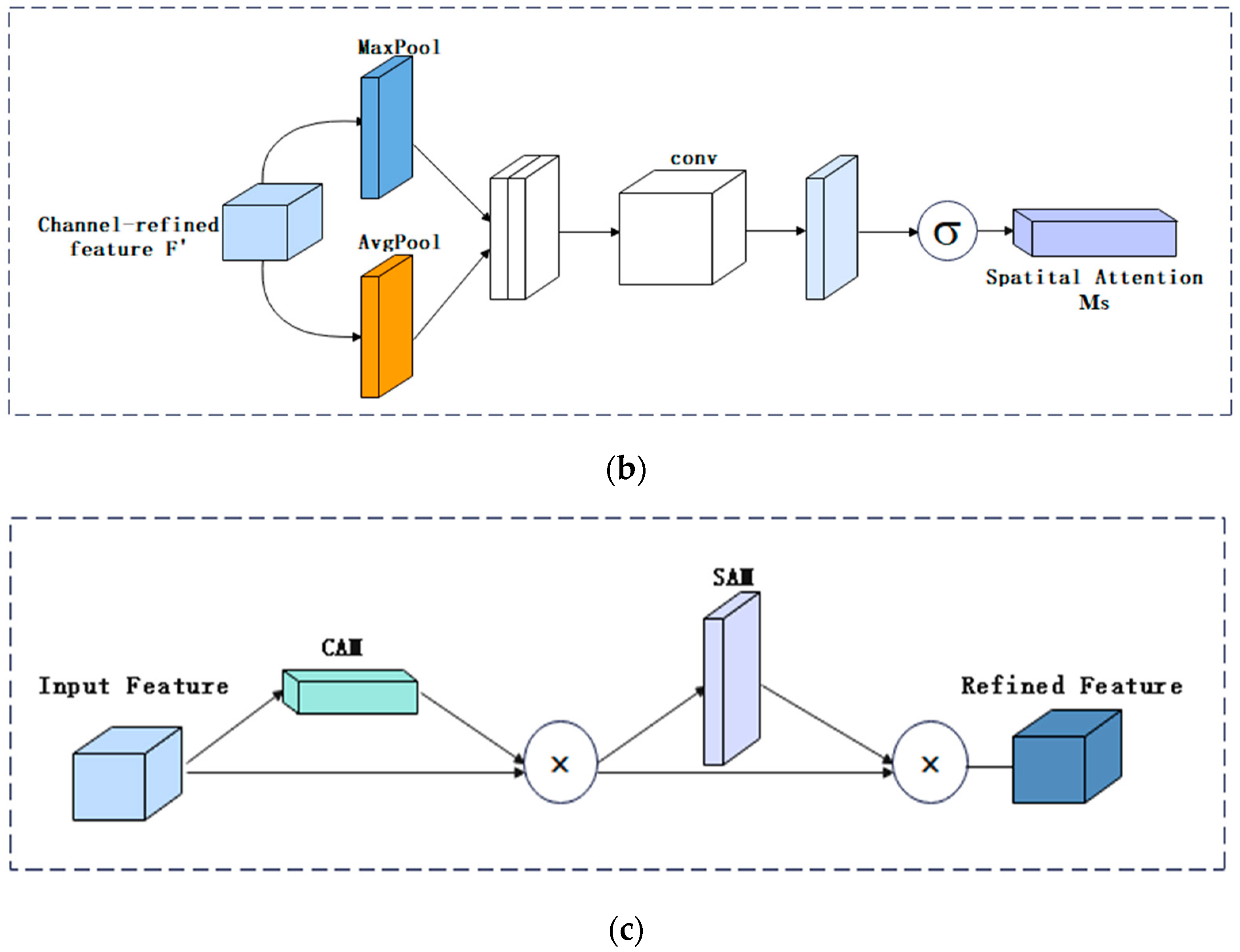
2.2.3. Convolutional Block Attention Module (CBAM)
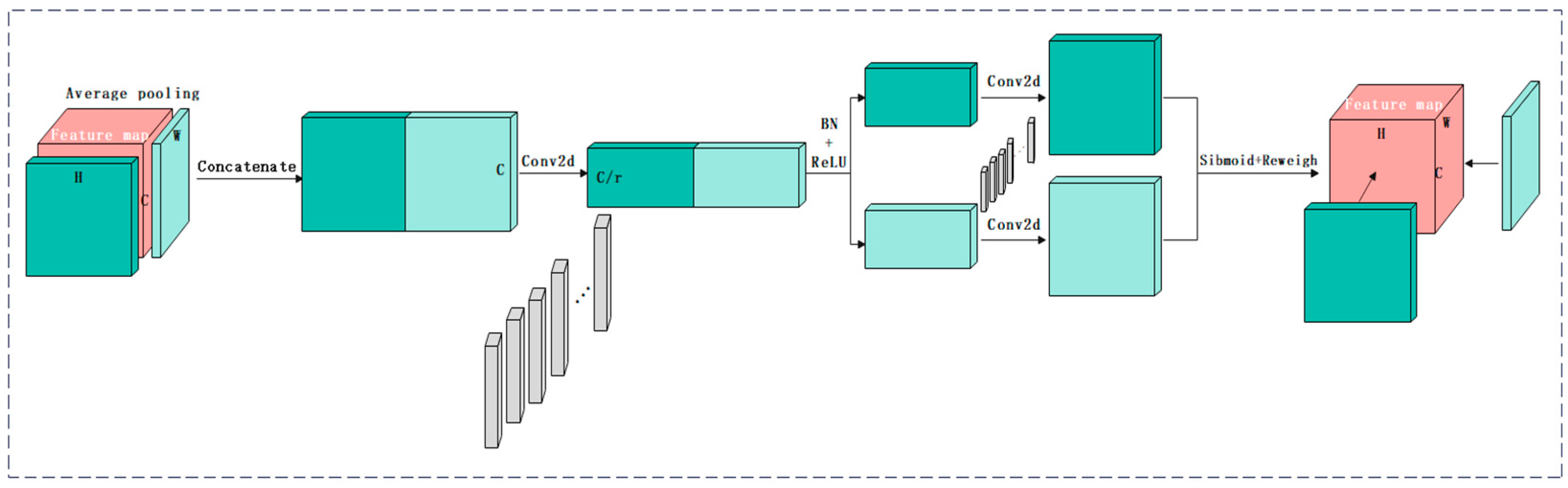
2.2.4. Coordinate Attention (CA)
2.2.5. Improved Mask RCNN Network Model
2.3. Evaluation Indexes for Model
3. Results
3.1. Experimental Environment and Parameter Settings
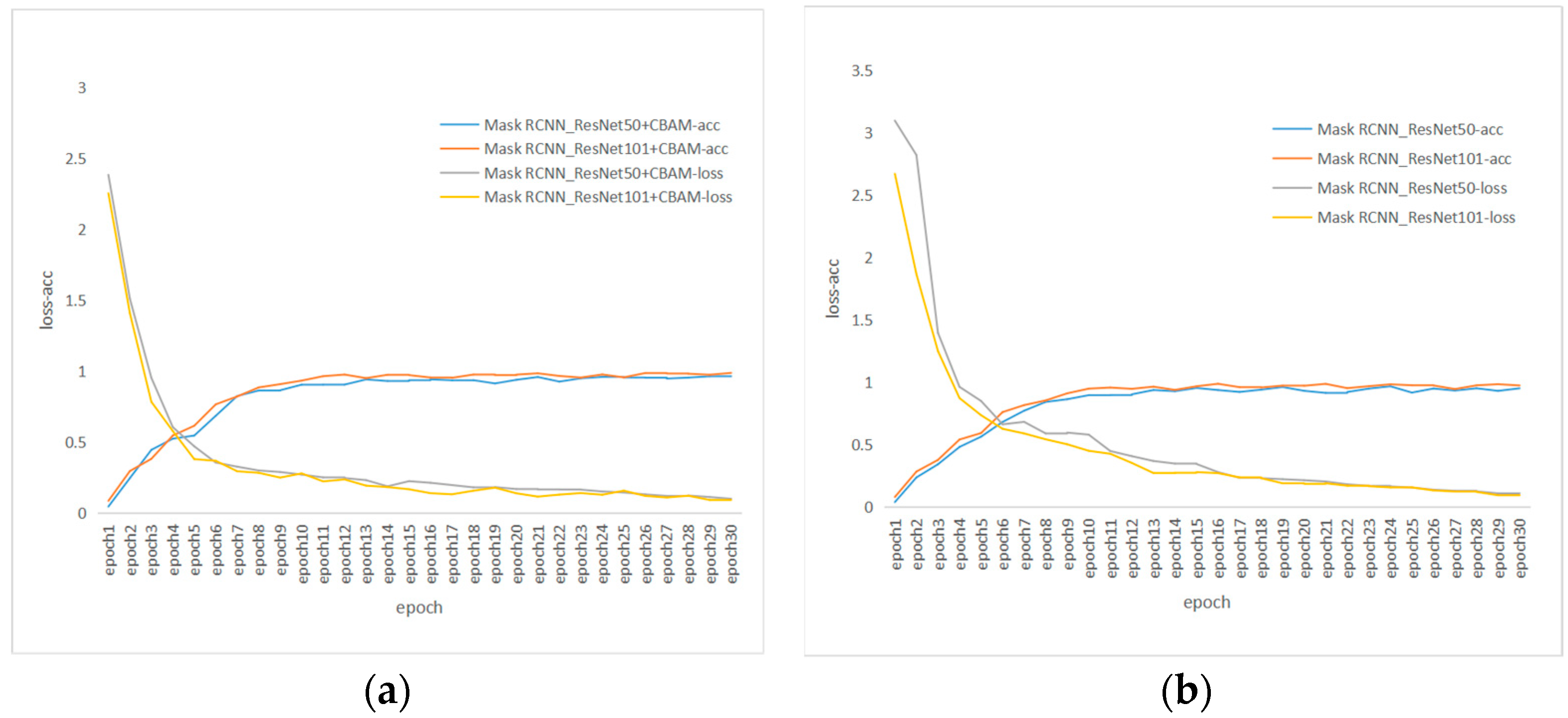
3.2. Performance Comparison between Models Established with Different CNN Networks
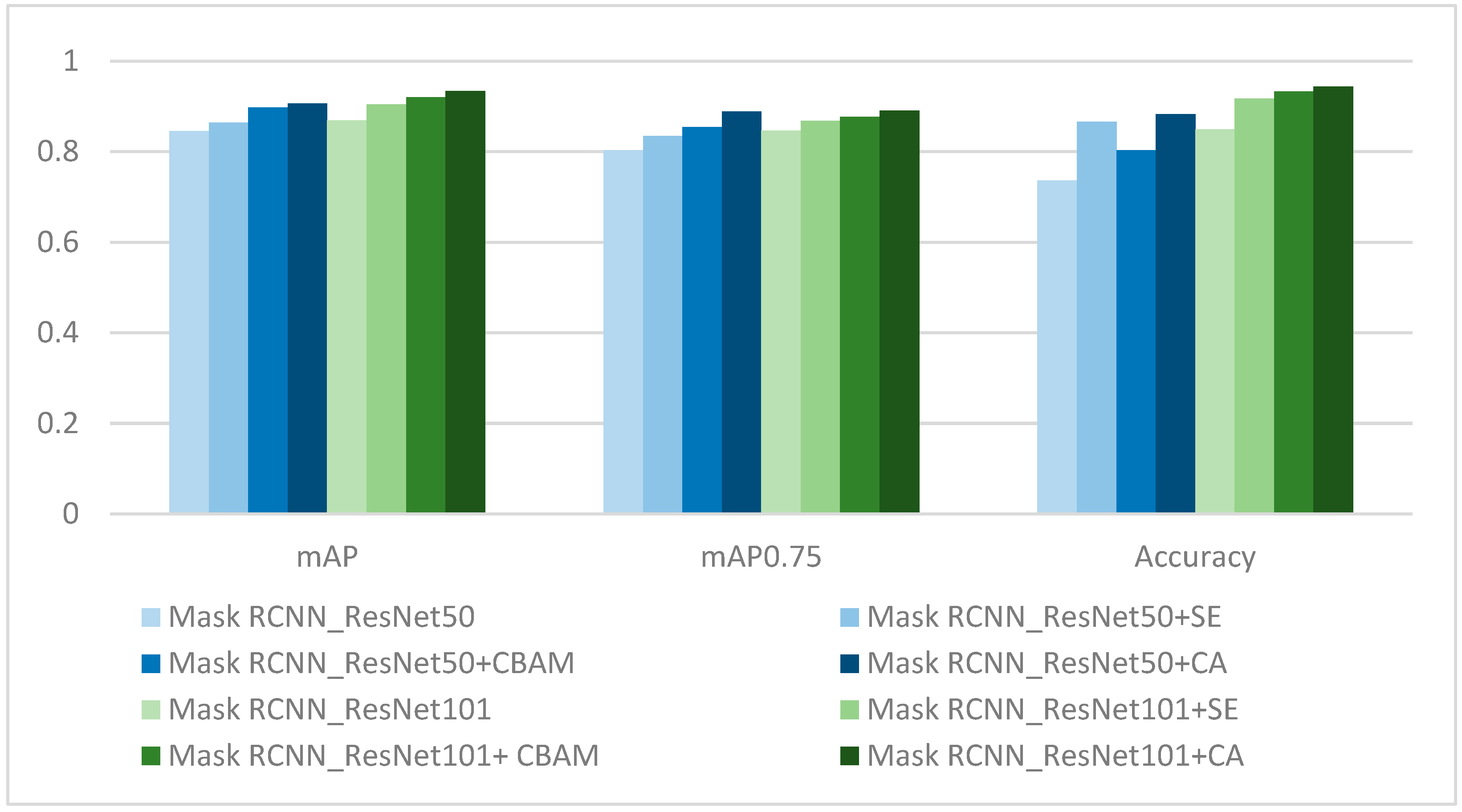
3.3. Performance Comparison of Models Established by Combining Mask RCNN with Different Attention Mechanisms
3.4. Feature Visualization
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Anderson, N.T.; Walsh, K.B.; Wulfsohn, D. Technologies for Forecasting Tree Fruit Load and Harvest Timing—From Ground, Sky and Time. Agronomy 2021, 11, 1409. [Google Scholar] [CrossRef]
- Yunling, L.; Tianyu, Z.; Ming, J.; Libo; Jianli, S. Research Progress of Grape Quality Nondestructive Testing Method Based on Machine Vision. Trans. Chin. Soc. Agric. Mach. 2022, 53, 299–308. [Google Scholar]
- Bellvert, J.; Mata, M.; Vallverdú, X.; Paris, C.; Marsal, J. Optimizing precision irrigation of a vineyard to improve water use efficiency and profitability by using a decision-oriented vine water consumption model. Precis. Agric. 2020, 22, 319–341. [Google Scholar] [CrossRef]
- Lu, S.; Liu, X.; He, Z.; Zhang, X.; Liu, W.; Karkee, M. Swin-Transformer-Yolov5 for Real-Time Wine Grape Bunch Detection. Remote Sens. 2022, 14, 5853. [Google Scholar] [CrossRef]
- Piazzolla, F.; Pati, S.; Amodio, M.L.; Colelli, G. Effect of Harvest Time on Table Grape Quality During on-Vine Storage. J. Sci. Food Agric. 2016, 96, 131–139. [Google Scholar] [CrossRef]
- Qiu, C.; Tian, G.; Zhao, J.; Liu, Q.; Xie, S.; Zheng, K. Grape Maturity Detection and Visual Pre-Positioning Based on Improved Yolov4. Electronics 2022, 11, 2677. [Google Scholar] [CrossRef]
- Lee, C.Y.; Bourne, M.C. Changes in Grape Firmness During Maturation. J. Texture Stud. 1980, 11, 163–172. [Google Scholar] [CrossRef]
- Herrera, J.; Guesalaga, A.; Agosin, E. Shortwave–near Infrared Spectroscopy for Non-Destructive Determination of Maturity of Wine Grapes. Meas. Sci. Technol. 2003, 14, 689. [Google Scholar] [CrossRef]
- Ben Ghozlen, N.; Cerovic, Z.G.; Germain, C.; Toutain, S.; Latouche, G. Non-Destructive Optical Monitoring of Grape Maturation by Proximal Sensing. Sensors 2010, 10, 10040–10068. [Google Scholar] [CrossRef]
- Bramley, R.; Le Moigne, M.; Evain, S.; Ouzman, J.; Florin, L.; Fadaili, E.M.; Hinze, C.; Cerovic, Z. On-the-Go Sensing of Grape Berry Anthocyanins During Commercial Harvest: Development and Prospects. Aust. J. Grape Wine Res. 2011, 17, 316–326. [Google Scholar] [CrossRef]
- Rahman, A.; Hellicar, A. Identification of Mature Grape Bunches Using Image Processing and Computational Intelligence Methods. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence for Multimedia, Signal and Vision Processing (CIMSIVP), Orlando, FL, USA, 9–12 December 2014. [Google Scholar]
- Pothen, Z.; Nuske, S. Automated Assessment and mAPping of Grape Quality through Image-Based Color Analysis. IFAC-PapersOnLine 2016, 49, 72–78. [Google Scholar] [CrossRef]
- Luo, L.; Tang, Y.; Lu, Q.; Chen, X.; Zhang, P.; Zou, X. A Vision Methodology for Harvesting Robot to Detect Cutting Points on Peduncles of Double Overlapping Grape Clusters in a Vineyard. Comput. Ind. 2018, 99, 130–139. [Google Scholar] [CrossRef]
- Liu, S.; Whitty, M. Automatic Grape Bunch Detection in Vineyards with an Svm Classifier. J. Appl. Log. 2015, 13, 643–653. [Google Scholar] [CrossRef]
- Pérez-Zavala, R.; Torres-Torriti, M.; Cheein, F.A.; Troni, G. A Pattern Recognition Strategy for Visual Grape Bunch Detection in Vineyards. Comput. Electron. Agric. 2018, 151, 136–149. [Google Scholar] [CrossRef]
- Aggarwal, S.; Gupta, S.; Gupta, D.; Gulzar, Y.; Juneja, S.; Alwan, A.A.; Nauman, A. An Artificial Intelligence-Based Stacked Ensemble Approach for Prediction of Protein Subcellular Localization in Confocal Microscopy Images. Sustainability 2023, 15, 1695. [Google Scholar] [CrossRef]
- Gulzar, Y. Fruit Image Classification Model Based on MobileNetV2 with Deep Transfer Learning Technique. Sustainability 2023, 15, 1906. [Google Scholar] [CrossRef]
- Yasir, H.; Sharyar, W.; Arjumand, B.S.; Ali, A.; Yonis, G. Smart seed classification system based on MobileNetV2 architecture. In Proceedings of the 2022 2nd International Conference on Computing and Information Technology (ICCIT), Tabuk, Saudi Arabia, 25–27 January 2022. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28, (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Grimm, J.; Herzog, K.; Rist, F.; Kicherer, A.; Töpfer, R.; Steinhage, V. An adaptable approach to automated visual detection of plant organs with applications in grapevine breeding. Biosyst. Eng. 2019, 183, 170–183. [Google Scholar] [CrossRef]
- Fu, L.; Majeed, Y.; Zhang, X.; Karkee, M.; Zhang, Q. Faster R–CNN–based apple detection in dense-foliage fruiting-wall trees using RGB and depth features for robotic harvesting. Biosyst. Eng. 2020, 197, 245–256. [Google Scholar] [CrossRef]
- Parvathi, S.; Selvi, S.T. Detection of maturity stages of coconuts in complex background using Faster R-CNN model. Biosyst. Eng. 2021, 202, 119–132. [Google Scholar] [CrossRef]
- Wan, S.; Goudos, S. Faster R-Cnn for Multi-Class Fruit Detection Using a Robotic Vision System. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Mai, X.; Zhang, H.; Jia, X.; Meng, M.Q.-H. Faster R-Cnn with Classifier Fusion for Automatic Detection of Small Fruits. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1555–1569. [Google Scholar] [CrossRef]
- Shen, L.; Su, J.; Huang, R.; Quan, W.; Song, Y.; Fang, Y.; Su, B. Fusing Attention Mechanism with Mask R-CNN for Instance Segmentation of Grape Cluster in the Field. Front. Plant Sci. 2022, 2528. [Google Scholar] [CrossRef]
- Jia, W.; Wei, J.; Zhang, Q.; Pan, N.; Niu, Y.; Yin, X.; Ding, Y.; Ge, X. Accurate Segmentation of Green Fruit Based on Optimized Mask Rcnn Application in Complex Orchard. Front. Plant Sci. 2022, 13, 955256. [Google Scholar] [CrossRef]
- Mamat, N.; Othman, M.F.; Abdulghafor, R.; Alwan, A.A.; Gulzar, Y. Enhancing Image Annotation Technique of Fruit Classification Using a Deep Learning Approach. Sustainability 2023, 15, 901. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:180402767. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic and Fast Instance Segmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 17721–17732. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-Time Instance Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolu-tional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20 June–25 July 2021; pp. 13713–13722. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:180403999. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Parameter | Parameter Value |
|---|---|
| Input picture size | 800 × 500 |
| Batch size | 2 |
| Epochs | 30 |
| Optimizer | SGD |
| Learning rate | 0.0025 |
| Weight Decay | 0.0001 |
| Momentum | 0.9 |
| Model | mAP | AP for Level 1 | AP for Level 2 | AP for Level 3 | AP for Level 4 |
|---|---|---|---|---|---|
| Solov2 | 0.739 | 0.809 | 0.659 | 0.709 | 0.777 |
| Yolov3 | 0.739 | 0.850 | 0.507 | 0.749 | 0.898 |
| Yolact | 0.799 | 0.895 | 0.689 | 0.716 | 0.897 |
| Mask RCNN_ResNet50 | 0.846 | 0.967 | 0.764 | 0.766 | 0.887 |
| Mask RCNN_ResNet101 | 0.869 | 0.947 | 0.754 | 0.818 | 0.956 |
| Model | mAP | mAP0.75 | Accuracy |
|---|---|---|---|
| Mask RCNN ResNet50 | 0.846 | 0.803 | 0.736 |
| Mask RCNN ResNet50 + SE | 0.864 | 0.835 | 0.866 |
| Mask RCNN ResNet50 + CBAM | 0.898 | 0.854 | 0.803 |
| Mask RCNN ResNet50 + CA | 0.907 | 0.889 | 0.883 |
| Model | mAP | mAP0.75 | Accuracy |
|---|---|---|---|
| Mask RCNN ResNet101 | 0.869 | 0.847 | 0.850 |
| Mask RCNN ResNet101 + SE | 0.905 | 0.868 | 0.917 |
| Mask RCNN ResNet101 + CBAM | 0.920 | 0.877 | 0.933 |
| Mask RCNN ResNet101 + CA | 0.934 | 0.891 | 0.944 |
| Model | mAP Variation | mAP0.75 Variation | Accuracy Variation |
|---|---|---|---|
| Mask RCNN ResNet50 | / | / | / |
| Mask RCNN ResNet50 + SE | 1.8% | 3.2% | 13% |
| Mask RCNN ResNet50 + CBAM | 5.2% | 5.1% | 6.7% |
| Mask RCNN ResNet50 + CA | 6.1% | 8.6% | 14.7% |
| Model | mAP Variation | mAP0.75 Variation | Accuracy Variation |
|---|---|---|---|
| Mask RCNN ResNet101 | / | / | / |
| Mask RCNN ResNet101 + SE | 3.6% | 2.1% | 6.7% |
| Mask RCNN ResNet101 + CBAM | 5.1% | 3.0% | 8.3% |
| Mask RCNN ResNet101 + CA | 6.5% | 4.4% | 9.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, Y.; Xu, D.; Zhang, J.; Wen, J. An Improved Mask RCNN Model for Segmentation of ‘Kyoho’ (Vitis labruscana) Grape Bunch and Detection of Its Maturity Level. Agriculture 2023, 13, 914. https://doi.org/10.3390/agriculture13040914
Li Y, Wang Y, Xu D, Zhang J, Wen J. An Improved Mask RCNN Model for Segmentation of ‘Kyoho’ (Vitis labruscana) Grape Bunch and Detection of Its Maturity Level. Agriculture. 2023; 13(4):914. https://doi.org/10.3390/agriculture13040914
Chicago/Turabian StyleLi, Yane, Ying Wang, Dayu Xu, Jiaojiao Zhang, and Jun Wen. 2023. "An Improved Mask RCNN Model for Segmentation of ‘Kyoho’ (Vitis labruscana) Grape Bunch and Detection of Its Maturity Level" Agriculture 13, no. 4: 914. https://doi.org/10.3390/agriculture13040914
APA StyleLi, Y., Wang, Y., Xu, D., Zhang, J., & Wen, J. (2023). An Improved Mask RCNN Model for Segmentation of ‘Kyoho’ (Vitis labruscana) Grape Bunch and Detection of Its Maturity Level. Agriculture, 13(4), 914. https://doi.org/10.3390/agriculture13040914