1. Introduction
The black soil area of Northeast China is an important producer of cereals such as corn and rice. However, soil acidification and soil erosion of varying degrees have been caused by irrational fertilization and the long-term removal of straw from fields [
1,
2]. This not only affects China’s food security but also poses a serious threat to the environment [
3]. Therefore, the conservation and sustainable utilization of black soil resources is a major challenge worldwide. Straw return conservation tillage is a modern tillage technology system that utilizes crop straw return, as well as no-till or less-till sowing, as its main method [
4]. It is the simplest and most effective technical measure to increase soil carbon sinks, improve soil structure, fertilize the land, and reduce wind erosion [
5]. To encourage farmers in straw return and expedite the adoption of conservation tillage in the black soil of Northeast China, the four northeastern provinces have introduced a subsidy policy for straw return. Therefore, accurate and efficient straw return detection is an important part of straw return subsidy work, and it is also of great significance in guiding the implementation of conservation tillage and realizing sustainable agriculture.
The Ministry of Agriculture and Rural Affairs issued the Technical Guidelines for the 2021 Northeast Blackland Conservation Tillage Action Plan to standardize conservation tillage technology. In addition, they formulated a detailed description of complete and partial straw cover, which can be divided into whole straw cover, root stubble cover, residue stubble cover, and crushed cover according to the cover forms used [
6,
7]. According to the cover rate, these methods can be divided into complete cover and partial cover approaches. Crop straw or stubble covering more than 70% (inclusive) of the ground surface is recognized as a complete cover approach. Crop straw or stubble covering more than 30% (inclusive) of the ground surface is recognized as partial straw cover [
8]. The core of straw return subsidy work is to calculate the areas of complete, partial, and non-straw return plots according to the above instructions. The traditional method for the vast area of the Northeast is performed via visual inspection and rope pulling, but this has the disadvantages of poor efficiency and the use of subjective factors [
9].
With the development of computer science and technology, information-based detection methods have gradually emerged. Liu et al. [
10], Daughtry et al. [
11], and Memon et al. [
12] used the remote sensing satellite Sentinel-1 and the multi-spectral satellites LANDSAT-8 and WORLDVIEW-3 to evaluate crop residual cover. However, satellite remote sensing has the disadvantages of being susceptible to weather, having long revisit periods, and having low spatial–temporal resolution, which makes it difficult to obtain higher resolutions. In studies based on agricultural RGB images, traditional machine vision detection methods [
13,
14,
15,
16] and deep learning methods [
17,
18] have been applied for the purposes of detecting the extent of straw return to the field. However, although this method can accurately calculate the straw cover rate by dividing the surface straw and determining the straw return grade of the plots, this method has been mainly adapted to the straw crush form. Moreover, there are certain limitations in the detection of complex straw return forms, and large-scale calculations have also shown that it slows down the detection process to a certain extent. Yu et al. [
19] detected winter wheat straw based on UVA images; their method determines the full straw return grade by incorporating ground survey information and visually interpreting information such as plot texture and color in the UVA images. This method avoids extensive straw coverage rate detection and can further accelerate the straw return process. In the same way, we can judge the straw return status of the plots according to the corn straw return cover types in the UVA images, which can realize rapid detection from the source. However, one of the drawbacks of this method is that it requires personnel with specialized knowledge to participate in the determination, which represents a great waste of manpower and time. Therefore, it is imperative to seek an information-based detection method that is founded on the classification and segmentation of plots by straw cover type.
Currently, traditional machine learning-based methods perform well in segmenting regular plots [
20,
21,
22,
23,
24]; however, for more complex farmland shapes, deep learning solutions usually outperform traditional machine learning methods. Aung et al. [
25] used a spatio-temporal U-Net approach for segmenting farmland regions, and the pre-trained models achieved a 0.81 Dice score and 0.83 accuracy. Feng et al. [
26] used an improved U-Net for the classification and extraction of crop plots. A U-Net incorporating spatial–coordinated attention achieved better results on a multi-crop dataset, with an accuracy of 92.20%. Huang et al. [
27] used an improved OCRNet to detect zucchini intercropped with sunflowers in unmanned aerial vehicle (UVA) visible-light images, and the improved model possessed significant advantages in crop classification and intercrop recognition.
At present, the identification and segmentation of agricultural remote sensing images from high-resolution UAVs have been widely studied and applied. However, these kinds of images contain a large spatial range and more pixel information, which requires more computing resources to process and analyze the data; thus, these features are not conducive to the efficient operation of the model. Therefore, it is necessary to lighten the model and reduce its consumption of computing resources, memory, and storage space. In addition, since different sizes of straw returns have size diversity and morphological complexity in images, the model should be able to effectively extract multi-scale features from the different forms of corn straw return plots, which enables the model to capture various levels of features, from texture details to the overall structure, and to improve segmentation accuracy. Finally, shallow features are enriched with spatial details and local texture information, which are crucial for capturing small-scale structures and achieving accurate edge localization. We used an optimized Sh-DeepLabv3+ model (Shallow-DeepLabv3+, Sh-DeepLabv3+) for classification based on straw cover form plots to ensure the performance of the model in terms of multi-scale feature extraction and shallow feature capture. A fast method for straw return detection based on the combination of a deep learning Sh-DeepLabv3+ model and the threshold segmentation DE-AS-MOGWO method can realize efficient and intelligent straw return detection.
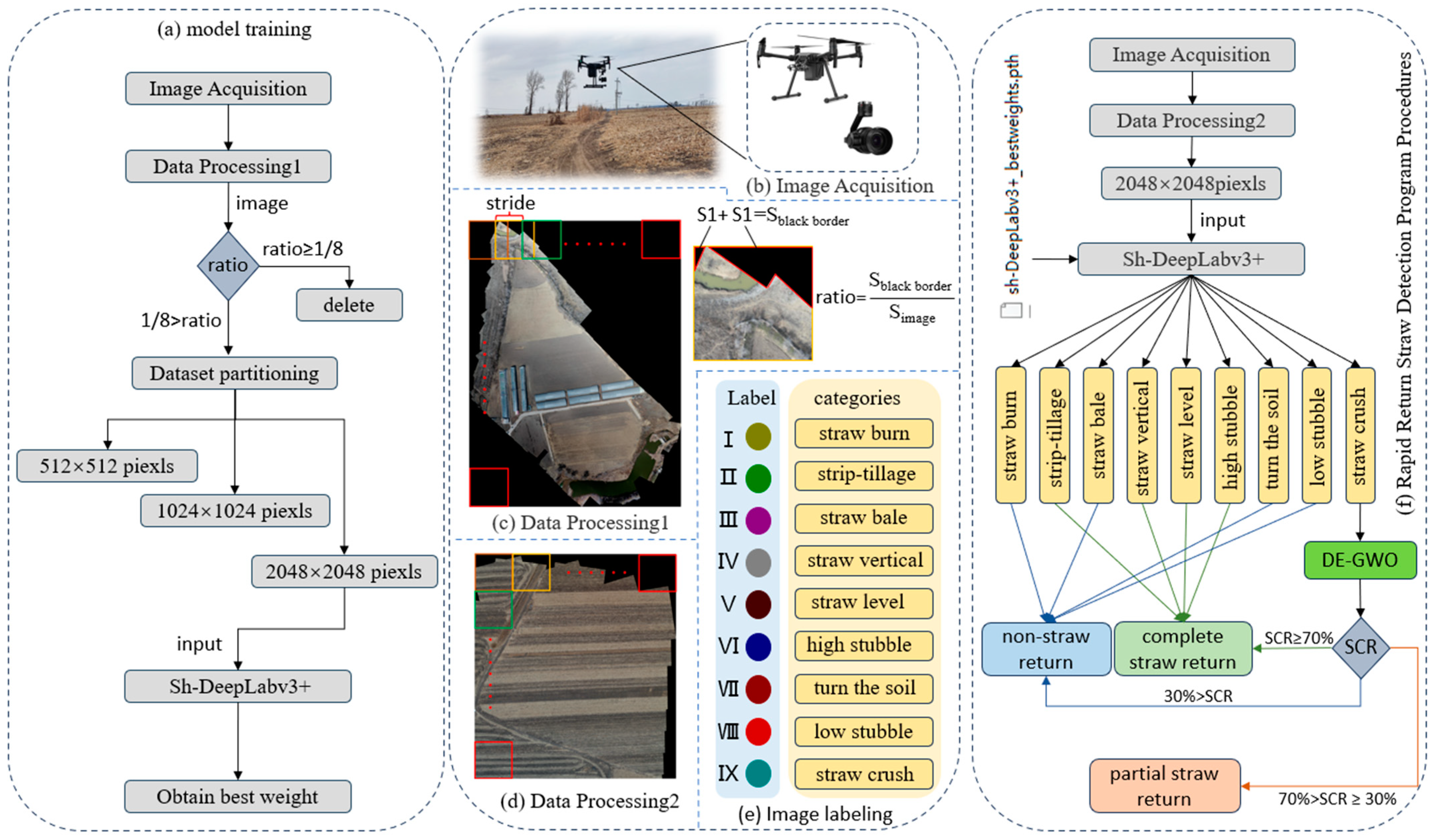
2. Materials and Methods
In this paper, Jilin Province was taken as the study area, and the relationship between corn straw return cover forms and straw return status was explored through field research and expert appraisal. In addition, a mapping relationship between the straw return forms and straw return grades was proposed. Nine types of straw return form images obtained in the field study are shown in
Figure 1.
A fast straw return detection method was proposed by combining the two defining criteria of the straw coverage form and straw coverage rate (SCR): Firstly, the Sh-DeepLabv3+ model was used to classify and segment the fields with different straw coverage forms in the farmland. According to the mapping relationship, the plots were assigned as belonging to the total straw return grade when straw vertical, straw level, and high stubble forms were detected. When straw burn, straw bale, turn soil, and low stubble forms were detected, the plots were understood as belonging to the non-straw return grade. When detected as straw crush, we extracted the corresponding plots in the original map according to the predicted image. Secondly, we calculated the SCR for each straw crush form plot with the threshold segmentation algorithm DE-AS-MOGWO [
15]. We classified the plots as follows: the plot was of a total straw return grade when the SCR was found to be greater than or equal to 70%; the plot was of a partial straw return grade when the SCR was greater than or equal to 30% and less than 70%; and the plot was of a non-straw return grade when the SCR was less than 30%. Finally, the number of pixels corresponding to the three straw return grades was counted. The corresponding areas of the three straw return grades were calculated according to the ground sampling distance (GSD). This method eliminates the need to calculate large-scale SCRs, and it also speeds up the straw return detection process. The flowchart of the rapid straw return detection method is shown in
Figure 2f.
2.1. Data Acquisition
The images used for model training in this paper were collected from four farmlands in Changchun, Yushu, Dewei, and Jilin Province (125.3893342° E, 43.8168784° N; 125.5002287° E, 43.8670143° N; 125.6564316° E, 44.5830458° N; and 126.2287119° E, 45.0979541° N, respectively), and they were acquired via a DJI Matrice 200 V2 UVA equipped with a Zenmuse X5S gimbal camera to take aerial photographs at a distance of 50 or 60 m from the ground (
Figure 2b). Acquisition took place between 8:00 am and 4:00 pm when the weather was sunny or cloudy. During aerial photography, the lens was aimed vertically downward with an 80% overlap on both the side and heading directions, and the raw images were stored in JPG format with a resolution of 5280 × 2970 pixels.
2.2. Dataset Production
We implemented photometric and color standardization at the image preprocessing stage to reduce the differences between the images when subjected to different lighting conditions, which involved white balance adjustments and exposure compensation of the images to ensure image consistency. Stitching multiple images into one large image and then segmenting them was performed to reduce the large sizes of the UVA aerial images. This method can effectively reduce the image size required for inputting neural networks, decrease memory consumption, and increase training efficiency. In this study, we used Microsoft Image Composite Editor software (v 2.0.3.0) for image stitching. The stitched Images I~IV are shown in
Figure 1.
Nine types of straw cover forms in four of the stitched image plots were manually labeled with the labeling tool LableMe [
28]. In addition, the labeled images were single-channel with a depth of 8 bits, in which Label Color I represents other features, Label Color II represents the straw burn form, Label Color III represents the strip tillage form, Label Color IV represents the straw bale form, Label Color V represents the straw vertical form, Label Color VI represents the straw level form, Label Color VII represents the high stubble form, Label Color VIII represents the turn soil form, Label Color IX represents the low stubble form, and Label Color X represents the straw crush form (
Figure 2e).
The stitched and labeled images were cropped at the scales of 512 × 512 pixels, 1024 × 1024 pixels, and 2048 × 2048 pixels, with cropping steps of 250 pixels, 500 pixels, and 700 pixels, respectively. After deleting the images that had black borders occupying more than 1/8 of the images (
Figure 2c), the remaining images were then filtered and randomly selected. There was a total of 16,070 images in the final dataset at each scale. The three datasets were divided into training, validation, and test sets in the ratio of 7:2:1, and they were produced as Pascal VOC 2007 format datasets.
2.3. Using the Sh-Deeplabv3+ Model in the Identification and Segmentation of Plots with Different Straw Cover Forms
2.3.1. The Network Architecture
The DeepLab series is a pixel-level-based semantic segmentation model that was proposed by Chen et al. [
29,
30,
31,
32]. Since the initial DeepLabv1, the aforementioned model has seen its ability to capture valid information continuously improved by the introduction of atrous convolution and pyramid pooling modules. DeepLabv3+ was chosen as the base network architecture for this study due to its excellent segmentation accuracy. However, due to the large number of DeepLabv3+ parameters, it is currently unable to meet the lightweight application requirements of straw return detection. In addition, important features such as the texture and color of plots with different straw cover forms need to be extracted from the shallow layer of the network. Moreover, DeepLabv3+ has a weak ability to extract shallow feature information, and although the fusion of multi-scale information was performed through the Atrous Spatial Pyramid Pooling (ASPP) module, the shallow feature extraction still has certain limitations compared to the deep feature one. Therefore, making the model lightweight while strengthening the feature extraction capability is still a challenge for the straw return detection task.
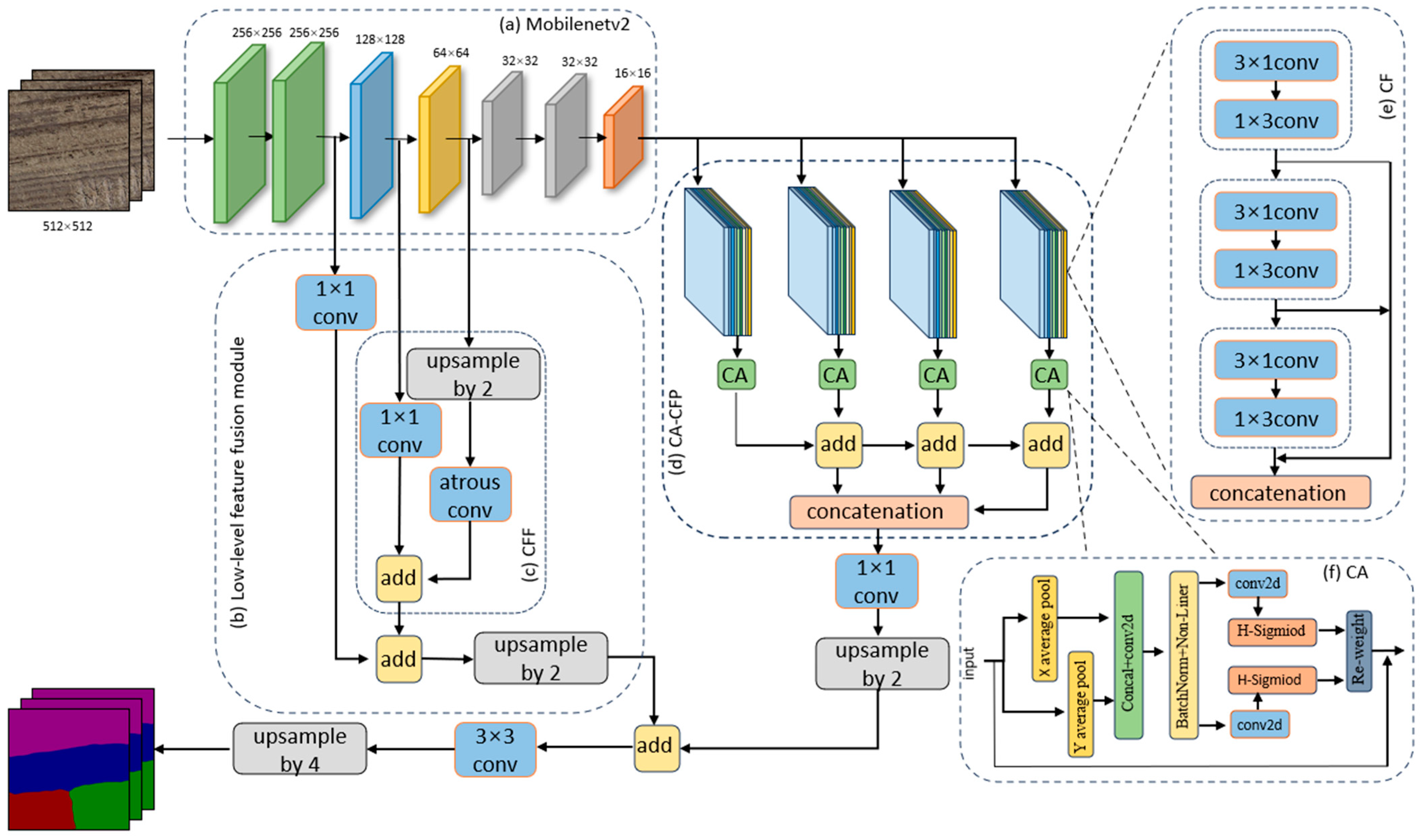
In this study, we named the optimized DeepLabv3+ model Sh-Deeplabv3+ (
Figure 3). We introduced the lightweight network MobileNetv2 [
33] in the backbone feature network, which reduced the model inference time and effectively improved the expressive power of feature extraction, to improve the model recognition accuracy while reducing the model parameters. We also replaced the ASPP module with CA-CFP, which can extract the contextual information of straw return images of various scales sizes and can make the models focus on the semantics of different straw cover forms. The LLFF module fuses the shallow information extracted in the front part of the backbone network to further reduce the loss of bottom-dimensional features. In addition, a composite loss function was utilized to address the error due to the imbalance in the sample size of the dataset.
2.3.2. CFP Module Based on the CA Attention Mechanism (CA-CFP Module)
The original ASPP structure in the DeepLabv3+ model expands the sensory field by connecting the feature maps that are formed via atrous convolutions with different dilation rates such that the feature maps contain information at multiple scales. However, in the straw return detection task, the model is better trained for large-scale data due to the discontinuity of the plots in each input image; as such, it is usually necessary for the image to have a large resolution to keep the training image content intact. Therefore, ASPP requires a large dilation ratio to adapt to large-scale high-resolution images. Additionally, as the expansion rate increases, the expansion convolution becomes increasingly ineffective, thereby leading to a gradual loss in its modeling ability. To address this situation, we used the introduction of CA-CFP (
Figure 3d).
The CFP [
34] contains 4 channels, and each channel consists of an asymmetric convolutional FP module which uses the idea of factorization. (
Figure 3e). Additionally, the 3 asymmetric convolutional blocks in the FP have dimensions of M/16, M/16, and M/8. Jointly forming the 4 FP channels into a parallel structure with an expansion rate of {r1 = 1, r2 = 2, r3 = 4, r4 = 8} can reduce the channel parameters by allowing the module to learn features from a range of sizes in the receptive fields. Finally, the hierarchical feature fusion method was used to total up all the channel outputs in order to mitigate the mesh artifacts generated during the feature fusion, as well as to compensate for the lack of feature information generated via atrous convolution. Therefore, the CFP module does not require an excessive expansion ratio; instead, the efficient extraction of features of different straw cover forms and multi-scale feature aggregation can be achieved by multi-level convolution and a channel feature pyramid structure. This, in turn, effectively avoids the ineffective modeling that occurs when using expansion convolution in the ASPP module without affecting the performance.
As the spatial distribution of the straw return plots in the farmland was relatively regular, and as different categories of straw return forms have strong normality (such as the strip tillage form category), the width of the strip was set according to the parameters of the strip tillage machinery and the local common row spacing. In addition, the intervals between them were relatively regular. Moreover, the straw crush form plots usually used mechanical equipment for straw cover, the straw cover was uniform and regular, and the form and distribution of the straw were also relatively uniform. To capture these obvious and important characteristics, the overall network attention should be focused on capturing the correlation and differences between the straw cover forms. In this paper, the CA attention mechanism [
35] (
Figure 3f) was added after the CF module to ensure that the model focuses on the key features that characterize different straw cover forms. This helps to reduce the interference of other background information, such as roads and weeds, to the model, thus improving the accuracy and reliability of the model’s identification.
2.3.3. Low-Level Feature Fusion Module
The DeepLabv3+ decoder mainly improves the segmentation accuracy by fusing shallow and deep features [
36]. Shallow features refer to the features that are extracted from the first few layers of the backbone network, which mainly contain important features such as color, edge texture, and other information. However, the shallow features are only extracted with 1 × 1 conv, and the main factor affecting the performance is when the semantic information extraction ability is weak and there is more noise in the features [
37]. In the task of identifying different straw return forms in different plots, the main measurements for distinguishing different straw return forms are found in the low-level features such as texture and color, which are formed by the straw or soil on the ground. In the original network, the low-level features are processed by 1 × 1 conv, which is an approach that fuses and splices the shallow features with the deep features at 1/2 the size of the original map. However, such an approach can likely lead to losing the low-level feature information [
38]. In this study, we used the LLFF module (
Figure 3b) to fuse the different scales of the underlying feature maps in the MobileNetv2 backbone network in order to improve the ability of the model to characterize the information.
Firstly, the original 1/8-size feature map and 1/16-size feature map that were extracted from the backbone network were used as inputs to the CFF module (
Figure 3c). Bilinear upsampling was performed on the 1/16th branch, and then a 3 × 3 atrous convolution with a dilation rate of 2 was passed to make the size and receptive field consistent with the 1/8-size branch. Next, the number of channels in the two branches was unified. Then, the fusion features were obtained by totaling up the features of the two branches. To further fuse the shallow features, we aggregated the original 1/2-size feature map and the fused features again to obtain the new fused features. Finally, the new fused features and the final features obtained in the coding layer were superimposed, and the superimposed features were then upsampled 4 times bilinearly in order to gradually recover the original image semantic information.
2.3.4. Loss Function
Cross entropy loss (CE loss) [
39] is a common loss function for image segmentation tasks. It is used to evaluate the difference between the predicted value and the true value of each pixel point. Its calculation formula is as follows:
where N represents the number of pixels; M represents the number of categories;
represents the sign function, which takes a value of 1 if the true category of sample i is equal to j and a value of 0 otherwise; and
represents the predicted probability that pixel i belongs to category j. However, as strip tillage is the main black soil conservation tillage technique used in Jilin Province, the number of pixels in the strip tillage forms category in the straw return dataset was found to be far more than the number of pixels in the straw vertical forms category, etc. Such an imbalance in the categories will lead to creating a bias in the model toward the strip tillage form category. Therefore, we introduced dice loss [
40], which is used to evaluate the similarity between the predicted segmentation image and the real segmentation image as an auxiliary loss function, to solve this problem. Dice loss is more robust to the unevenness of the category data in the straw return dataset than CE loss, and it can also effectively alleviate the impact of large differences in the number of pixels in each category. The formula for this is as follows:
where
represents the predicted value of the model for sample i,
represents the real label corresponding to sample i, and ε is the moderating factor. Based on the above considerations, we used the composite loss function
, which is composed of CE loss and Dice loss, to train the model. This composite function is computed as follows:
2.4. Experient Platform and Parameter Settings
The computing equipment used in this study was as follows: an AMD EPYC 7532 32-Core Processor (i.e., the central processor of the mainframe), an NVIDIA GeForce RTX 3090 with a 24 GB video memory graphics card, and the Ubuntu 18.04 operating system. We also used Python version 3.8 and Torch version 1.7.0 software. In addition, over the course of several trials, we chose stochastic gradient descent as the optimizer, with a momentum parameter of 0.9 and an initial learning rate of 7 × 10−3. The minimum learning rate of the model was 0.01 times that of the maximum learning rate, the learning rate descending mode was cos, and the weight decay coefficient was set to 1 × 10−4. The image resolution of the input network was set to 512 × 512 pixels, the model was trained for 100 epochs, and the batch size was set to 8. In addition, the number of threads was set to 16 in order to run the program efficiently.
2.5. Evaluation Indices
In this study, total parameters and FLOPs [
41] were selected as the evaluation metrics for evaluating the model’s complexity. Mean intersection over union (MIoU) [
41], mean average precision (mAP) [
42], and precision [
43] were used as the metrics for evaluating the segmentation accuracy. The formulas for the aforementioned metrics were calculated as follows:
where TP, FP, FN, and TN are the number of pixels for which the model correctly predicted the straw cover form, the number of pixels for which the model incorrectly predicted the samples of other straw cover forms as the correct straw cover form, the number of pixels for which the model incorrectly predicted the samples of the correct straw cover form as the other straw cover forms, and the number of pixels for which the model correctly predicted samples of other straw cover forms, respectively. In addition, c is the total number of categories.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}