

Rice Yield Estimation Using Multi-Temporal Remote Sensing Data and Machine Learning: A Case Study of Jiangsu, China

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Sources
2.3. Methodology
2.3.1. Regression Algorithms
2.3.2. Validation Metrics
2.3.3. Spatial Analysis
3. Results
3.1. Accuracy of Different Regression Algorithms for Rice Yield Estimation
3.2. Optimal Predictors for Rice Yield Estimation
3.3. Spatial Analysis
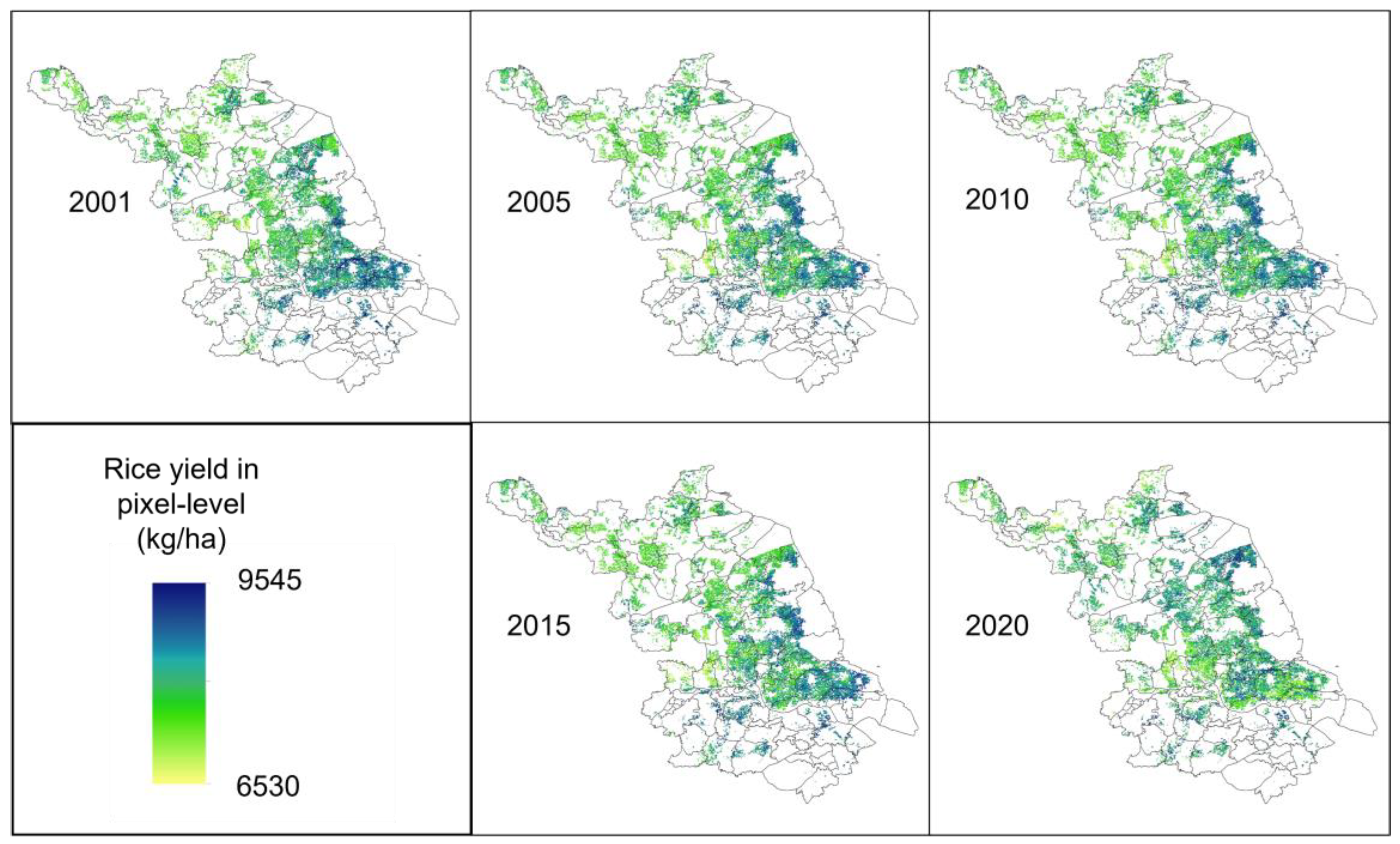
3.4. Pixel-Level Rice Yield Mapping
4. Discussion
4.1. Comparation of Different Machine-Learning Algorithms
4.2. The Influence from the Model Inputs
4.3. The Spatial Applicability of Proposed Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Di, Y.; Gao, M.; Feng, F.; Li, Q.; Zhang, H. A New Framework for Winter Wheat Yield Prediction Integrating Deep Learning and Bayesian Optimization. Agronomy 2022, 12, 3194. [Google Scholar] [CrossRef]
- Kuenzer, C.; Knauer, K. Remote sensing of rice crop areas. Int. J. Remote Sens. 2013, 34, 2101–2139. [Google Scholar] [CrossRef]
- Gumma, M.K.; Mohanty, S.; Nelson, A.; Arnel, R.; Mohammed, I.A.; Das, S.R. Remote sensing based change analysis of rice environments in Odisha, India. J. Environ. Manag. 2015, 148, 31–41. [Google Scholar] [CrossRef]
- Li, L.; Wang, B.; Feng, P.; Wang, H.; He, Q.; Wang, Y.; Liu, D.L.; Li, Y.; He, J.; Feng, H.; et al. Crop yield forecasting and associated optimum lead time analysis based on multi-source environmental data across China. Agric. For. Meteorol. 2021, 308–309, 108558. [Google Scholar] [CrossRef]
- Fernandez-Ordoñez, Y.M.; Soria-Ruiz, J. (Eds.) Maize crop yield estimation with remote sensing and empirical models. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Pettorelli, N.; Vik, J.O.; Mysterud, A.; Gaillard, J.-M.; Tucker, C.J.; Stenseth, N.C. Using the satellite-derived NDVI to assess ecological responses to environmental change. Trends Ecol. Evol. 2005, 20, 503–510. [Google Scholar] [CrossRef]
- Kogan, F.N. Application of vegetation index and brightness temperature for drought detection. Adv. Space Res. 1995, 15, 91–100. [Google Scholar] [CrossRef]
- Quiring, S.M.; Ganesh, S. Evaluating the utility of the Vegetation Condition Index (VCI) for monitoring meteorological drought in Texas. Agric. For. Meteorol. 2010, 150, 330–339. [Google Scholar] [CrossRef]
- Hu, X.; Ren, H.; Tansey, K.; Zheng, Y.; Ghent, D.; Liu, X.; Yan, L. Agricultural drought monitoring using European Space Agency Sentinel 3A land surface temperature and normalized difference vegetation index imageries. Agric. For. Meteorol. 2019, 279, 107707. [Google Scholar] [CrossRef]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
- Cheng, M.; Jiao, X.; Shi, L.; Penuelas, J.; Kumar, L.; Nie, C.; Wu, T.; Liu, K.; Wu, W.; Jin, X. High-resolution crop yield and water productivity dataset generated using random forest and remote sensing. Sci. Data 2022, 9, 641. [Google Scholar] [CrossRef]
- Cheng, M.; Penuelas, J.; McCabe, M.F.; Atzberger, C.; Jiao, X.; Wu, W.; Jin, X. Combining multi-indicators with machine-learning algorithms for maize yield early prediction at the county-level in China. Agric. For. Meteorol. 2022, 323, 109057. [Google Scholar] [CrossRef]
- Cheng, M.; Jiao, X.; Liu, Y.; Shao, M.; Yu, X.; Bai, Y.; Wang, Z.; Wang, S.; Tuohuti, N.; Liu, S.; et al. Estimation of soil moisture content under high maize canopy coverage from UAV multimodal data and machine learning. Agric. Water Manag. 2022, 264, 107530. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, X.; Liang, S.; Yao, Y.; Jia, K.; Jia, A. Estimating Surface Downward Shortwave Radiation over China Based on the Gradient Boosting Decision Tree Method. Remote Sens. 2018, 10, 185. [Google Scholar] [CrossRef]
- Mojaddadi, H.; Pradhan, B.; Nampak, H.; Ahmad, N.; Ghazali, A.H.b. Ensemble machine-learning-based geospatial approach for flood risk assessment using multi-sensor remote-sensing data and GIS. Geomat. Nat. Hazards Risk 2017, 8, 1080–1102. [Google Scholar] [CrossRef]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Luo, Y.; Zhang, L.; Zhang, J.; Li, Z.; Tao, F. Wheat yield predictions at a county and field scale with deep learning, machine learning, and google earth engine. Eur. J. Agron. 2021, 123, 126204. [Google Scholar]
- Huang, M. The decreasing area of hybrid rice production in China: Causes and potential effects on Chinese rice self-sufficiency. Food Secur. 2022, 14, 267–272. [Google Scholar] [CrossRef]
- Normile, D. Variety Spices Up Chinese Rice Yields. Science 2000, 289, 1122–1123. [Google Scholar] [CrossRef]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J.; Davidson, A.; Bédard, F. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 2016, 218–219, 74–84. [Google Scholar] [CrossRef]
- Jiang, Z.; Huete, A.R.; Chen, J.; Chen, Y.; Li, J.; Yan, G.; Zhang, X. Analysis of NDVI and scaled difference vegetation index retrievals of vegetation fraction. Remote Sens. Environ. 2006, 101, 366–378. [Google Scholar]
- Chen, J.; Jönsson, P.; Tamura, M.; Gu, Z.; Matsushita, B.; Eklundh, L. A simple method for reconstructing a high-quality NDVI time-series data set based on the Savitzky–Golay filter. Remote Sens. Environ. 2004, 91, 332–344. [Google Scholar]
- Luo, Y.; Zhang, Z.; Chen, Y.; Li, Z.; Tao, F. ChinaCropPhen1km: A high-resolution crop phenological dataset for three staple crops in China during 2000–2015 based on leaf area index (LAI) products. Earth Syst. Sci. Data 2020, 12, 197–214. [Google Scholar]
- Cheng, M.; Li, B.; Jiao, X.; Huang, X.; Fan, H.; Lin, R.; Liu, K. Using multimodal remote sensing data to estimate regional-scale soil moisture content: A case study of Beijing, China. Agric. Water Manag. 2022, 260, 107298. [Google Scholar] [CrossRef]
- Peralta, N.R.; Assefa, Y.; Du, J.; Barden, C.J.; Ciampitti, I.A. Mid-Season High-Resolution Satellite Imagery for Forecasting Site-Specific Corn Yield. Remote Sens. 2016, 8, 848. [Google Scholar] [CrossRef]
- Imran, M.; Stein, A.; Zurita-Milla, R. Using geographically weighted regression kriging for crop yield mapping in West Africa. Int. J. Geogr. Inf. Sci. 2015, 29, 234–257. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, B.; Wang, J.; Li, Y.; Yuan, Y. Winter Wheat Yield Estimation Based on Multi-Temporal and Multi-Sensor Remote Sensing Data Fusion. Agriculture 2023, 13, 2190. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Zhou, S.; Xu, L.; Chen, N. Rice Yield Prediction in Hubei Province Based on Deep Learning and the Effect of Spatial Heterogeneity. Remote Sens. 2023, 15, 1361. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J. MODIS NDVI optimization to fit the AVHRR data series—Spectral considerations. Remote Sens. Environ. 1998, 66, 343–350. [Google Scholar]
- Gu, Y.; Wylie, B.K.; Howard, D.M.; Phuyal, K.P.; Ji, L. NDVI saturation adjustment: A new approach for improving cropland performance estimates in the Greater Platte River Basin, USA. Ecol. Indic. 2013, 30, 1–6. [Google Scholar]
- Garroutte, E.L.; Hansen, A.J.; Lawrence, R.L. Using NDVI and EVI to map spatiotemporal variation in the biomass and quality of forage for migratory elk in the Greater Yellowstone Ecosystem. Remote Sens. 2016, 8, 404. [Google Scholar] [CrossRef]
- Cao, R.; Chen, Y.; Shen, M.; Chen, J.; Zhou, J.; Wang, C.; Yang, W. A simple method to improve the quality of NDVI time-series data by integrating spatiotemporal information with the Savitzky-Golay filter. Remote Sens. Environ. 2018, 217, 244–257. [Google Scholar]
- Chen, Y.; Cao, R.; Chen, J.; Liu, L.; Matsushita, B. A practical approach to reconstruct high-quality Landsat NDVI time-series data by gap filling and the Savitzky–Golay filter. ISPRS J. Photogramm. Remote Sens. 2021, 180, 174–190. [Google Scholar]
- Ray, S.S.; Dadhwal, V.K. Estimation of crop evapotranspiration of irrigation command area using remote sensing and GIS. Agric. Water Manag. 2001, 49, 239–249. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Ju, H.; Ma, Q.; Sun, C.; Lv, Y.; Liu, K.; Wu, T.; Cheng, M. Rice Yield Estimation Using Multi-Temporal Remote Sensing Data and Machine Learning: A Case Study of Jiangsu, China. Agriculture 2024, 14, 638. https://doi.org/10.3390/agriculture14040638
Liu Z, Ju H, Ma Q, Sun C, Lv Y, Liu K, Wu T, Cheng M. Rice Yield Estimation Using Multi-Temporal Remote Sensing Data and Machine Learning: A Case Study of Jiangsu, China. Agriculture. 2024; 14(4):638. https://doi.org/10.3390/agriculture14040638
Chicago/Turabian StyleLiu, Zhangxin, Haoran Ju, Qiyun Ma, Chengming Sun, Yuping Lv, Kaihua Liu, Tianao Wu, and Minghan Cheng. 2024. "Rice Yield Estimation Using Multi-Temporal Remote Sensing Data and Machine Learning: A Case Study of Jiangsu, China" Agriculture 14, no. 4: 638. https://doi.org/10.3390/agriculture14040638
APA StyleLiu, Z., Ju, H., Ma, Q., Sun, C., Lv, Y., Liu, K., Wu, T., & Cheng, M. (2024). Rice Yield Estimation Using Multi-Temporal Remote Sensing Data and Machine Learning: A Case Study of Jiangsu, China. Agriculture, 14(4), 638. https://doi.org/10.3390/agriculture14040638