1. Introduction
Tomato is native to South America, and it has a cultivation history of more than 100 years in China. It is one of the most popular vegetables, with health effects of lowering blood pressure, slowing down aging, increased slimming, and vitamin supplementation [
1].
Due to the wide planting area, high yield, and short maturity, tomato is difficult to store. The picking of tomato is a labor-intensive and time-consuming operation. Therefore, the development of an automatic picking robot for tomato is particularly important. The technology of object detection based on image processing is the most basic and important link in the research of the picking robot. It is a typical object recognition task that detecting the key organs (flower and fruit) of tomato from images of plants. Data from the Internet shows that immature green tomato contains alkaloids, which may cause poisoning after eating, while mature red tomato does not contain alkaloids. Therefore, it is significantly important to detect the key organs (tomato flower, immature green tomato, and mature red tomato) accurately and immediately. This will provide a theoretical basis for the detection of pests and diseases, targeted pesticide application systems, and the development of the picking robot [
2].
Traditional tomato recognition methods mostly extract information on color, shape, and some shallow features (the visual features of the bottom layer, such as texture features and the colors and shapes mentioned earlier), then classifiers are used to detect and recognize the tomato. Zhao et al. [
3] used the combination of Harr features (a Haar feature is a kind of feature that reflects the change of gray level of the image, and the pixel difference is calculated by the module [
4]) and an Adaboost classifier, to identify tomatoes. The recognition rate of mature tomato in the test set was 93.3%, but it was easy to misidentify tomatoes in the scene of illumination conversion; Jiang et al. [
5] utilized the difference of color characteristics between mature tomatoes and background to identify red mature tomatoes by threshold segmentation. However, the recognition rate of immature green tomatoes in which the color is similar to the leaf, is not high; Zhang et al. [
6] used gray transformation to extract the edge features of the background region, then segmented the tomato from the background by a fitting curve, and obtained the three-dimensional coordinates of the target by using the principle of stereo vision imaging; Yamamoto et al. [
7] extracted the color characteristics of leaves, stems, and backgrounds, then constructed a decision tree through a regression tree classifier, and extracted the pixels of tomato fruits by blob pixel segmentation, to identify tomatoes. However, this method had a poor identification rate under the complex backgrounds.
At present, most traditional object recognition and detection methods are based on shallow feature extraction to detect and identify tomato organs. The overlapping and occlusion problems between tomatoes under a complex background cannot be easily solved, and the time cost for feature extraction is relatively expensive, and the applicability is not strong.
In recent years, with the emergence of deep learning, convolutional neural networks (CNN) can extract hierarchical features by using unsupervised or semi-supervised feature learning, which has stronger generalization than artificial features. It can not only learn shallow semantic information, but also learn deep abstract information [
8]. In the field of generalized recognition (such as object classification [
9], object detection [
10] and segmentation [
11]), Faster R-CNN (faster regions with convolutional neural network features) [
12] and YOLO (you only look once) [
13] models have been widely used, and have achieved good results. Bargoti et al. [
14] constructed an image segmentation processing framework by using orchard image data. Multi-scale multilayer perceptron (MLP) and convolutional neural network were include in the framework. The image data captured from the network was extended by context information, as well as some of the appearance changes and category distributions that are observed in the data. Finally, Watershed Segmentation (WS) and Circular Hough Transform (CHT) processing algorithms were used for fruit detection and counting. However, this method was more complicated; Sa et al. [
15] constructed the Faster R-CNN model by pixel level superposition of RGB and near-infrared images, then the model was used for fruit detection by migration learning, but the number of model parameters was too large and was not suitable for real-time detection; Zhou [
16] proposed a Fast R-CNN model that is based on double convolutional chains. The feature extraction network based on vgg16 was trained by fusing RGB and grayscale feature images of the tomato, and then Fast R-CNN was initialized with the parameters to identify flowers, fruits, and stems of the tomato. However, this method did not solve the problem of occlusion of tomatoes by stems and leaves. The above literature proves that CNN can not only extract the shallow texture and color of key organs of tomato automatically, but it can also learn deeper abstract features. This will improve the detection accuracy of tomato flowers and fruits, and reduce the cost of feature extraction, which is more robust to detection and identification in a complex environment. Thus, it is feasible to use deep learning methods to detect and identify tomato organs. However, the accuracy of these models is not high under the conditions of overlap and occlusion, because there will be overlap and occlusion between the tomatoes, and the stems and leaves of the tomato will also cover the fruit. Additionally, the anchor size used in the above method was set artificially by the target in the VOC 2007 (Pascal Visual Object Classes Challenge 2007) dataset, without updating according to the actual size of the key organs of tomato, which will have a certain impact on the recognition accuracy.
Due to the fixed anchor size, overlap, and occlusion of the stems and leaves acting on the fruit, the recognition rate of tomato is low. Thus, an improved Faster R-CNN model was proposed in this paper. Firstly, the K-means clustering was used to obtain the anchor size that was suitable for the key organs of tomato. Secondly, residual blocks were used to replace the basic feature extraction network of the original model in order to improve the detection and recognition accuracy of tomato key organs. Finally, Soft-NMS (soft-non maximum suppression) was used to attenuate the bounding boxes of the tomato organ instead of completely removing them, which can solve the above problems to a certain extent.
2. Materials and Methods
2.1. Data Sources
A total of 5624 RGB images of tomato flowers, mature red tomatoes, and immature green tomatoes were collected from the agricultural digital greenhouse of Jiangsu University with a high-definition camera (Dataset A). These pictures were taken at 9:00 a.m., 12:00 a.m., and 3:00 p.m., July–August, 2018. The camera is a CMOS (Complementary Metal Oxide Semiconductor) sensor, which comes with the Honor 9 mobile phone. All images were 1080 × 1920 pixels and have a resolution of 96 dpi. In order to prevent the poor performance of the model caused by insufficient diversity of training samples, the following measures were taken during the process of image acquisition: considering the difference in imaging results caused by different greenhouse ambient light conditions, images were collected in sunny weather and cloudy days, respectively; in the process of sampling, different forms and occlusions of tomato organs were taken into account, and fruits with different maturity were photographed from multiple angles to increase the diversity of samples. In this paper, labelImg software (this can be obtained from this website [
17]) was used to label the tomato flowers, green tomatoes, and red tomatoes in the dataset. After each image was annotated, a corresponding xml file containing the category and location information of the target, similar to the dataset format of the PASCAL visual object classes challenge 2007 [
18], was generated. A large amount of Internet information showed that a lot of data was required to train the models by using deep learning methods. Combined with the instruction manual of the deep learning framework keras, a Python script was used to augment a small number of sample maps, including random flip (horizontal, vertical), transform angle (0~180), random scaling of the original image scaling factor (1~1.5) etc. [
19]. The total number of expanded samples was 8929 (Dataset B, as is shown in
Figure 1), and then the expanded set was randomly divided into 4:1 ratios between the training set and the test set. The expanded training set was used to train the model. All parameter settings and discussions in this paper only pertain to Dataset B.
2.2. Structure of the Detection Model
CNN includes the convolutional layer, pooling layer, and fully connected layer. The convolutional layer uses semi-supervised feature learning and a hierarchical feature extraction efficient algorithm to extract image abstract features. It can automatically extract and reduce the dimension of input images, and it has stronger generalization than the human-set features. The fully connected layer mainly performs image classification based on the extracted features. The neurons in the convolutional layer extract the primary visual features of the image by using a local receptive field, and they reduce the network parameters by sharing the weights. The pooling layer not only reduces the dimension of the features, but also realizes the invariance of displacement, scaling and distortion. The convolutional layer and pooling layer in CNN usually appear alternately, and the activation unit is set to realize the nonlinear transformation, which accelerates the convergence rate of the network.
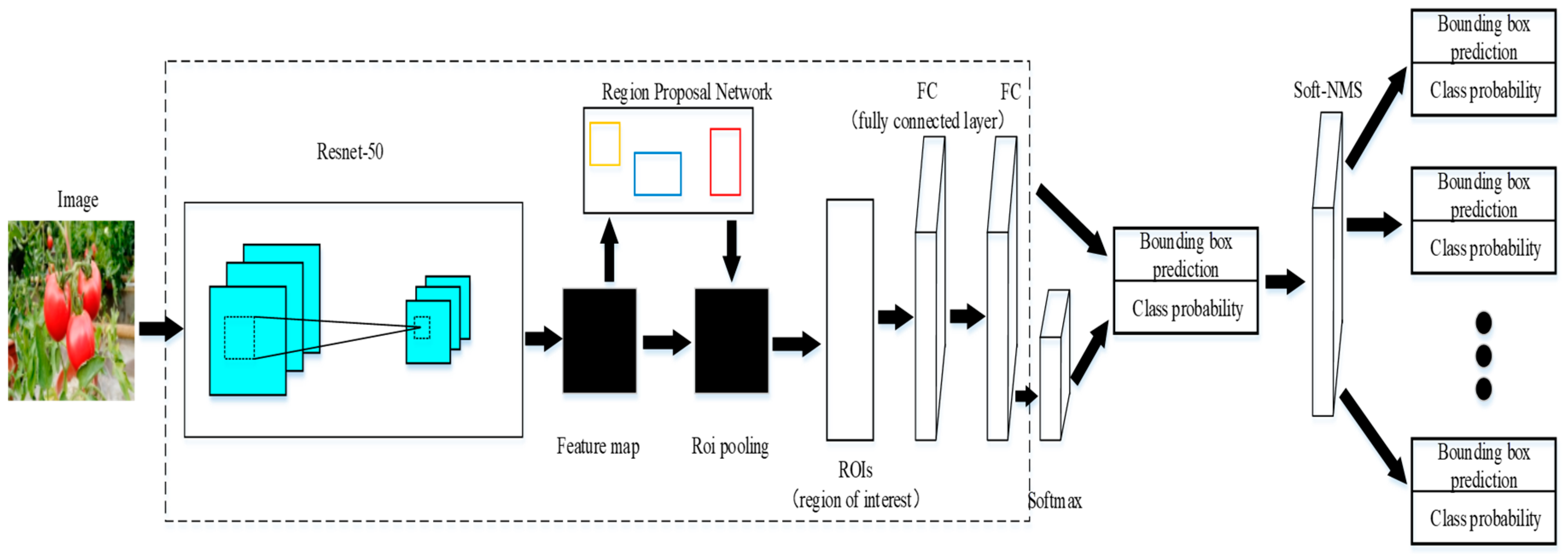
The traditional Faster R-CNN object detection algorithm can be divided into two parts. One is the feature extraction layer and the other is the region proposal network (RPN). Vgg16 was selected as the basic feature extraction network for image feature extraction and classification. The network consists of eight convolutional layers, five maximum pooling layers, and three fully connected layers, and Re LU (Rectified Linear Unit) was used as the activation function. In RPN, an arbitrary scale image is taken as input and outputs a series of object proposals, and each proposal has an object score. In order to generate region proposals, a slide is made on the feature map of the last convolutional layer of vgg16, then some ROIs (region of interests) are generated and multiple region proposals are predicted at the same time in each sliding window position [
20].
2.3. An Improved Feature Extraction Network
Deep convolutional neural network has made great progress in image recognition compared with traditional methods. As the number of network layers deepens, the convolutional layer can learn deeper abstract features, and the related research also shows that the extracted features can be enriched by increasing the number of network layers. Simon et al. [
21] demonstrated that the accuracy of recognition rises with the increase of the depth of the network. However, the simple stacked convolutional layer cannot train the network smoothly, due to the gradient explosion when propagating backward. Although the relevant literature has shown that the deep network can be trained through batch normalization [
22] and dropout [
23], the problem of precision decline after a certain iteration remains. In order to break through the problems of the precision degradation of the deep network, and the limitation of network depth, He et al. proposed a deep residual resnet model by using the concept of identity mapping. This method solved the degradation problem by fitting a residual map with a multi-layer network [
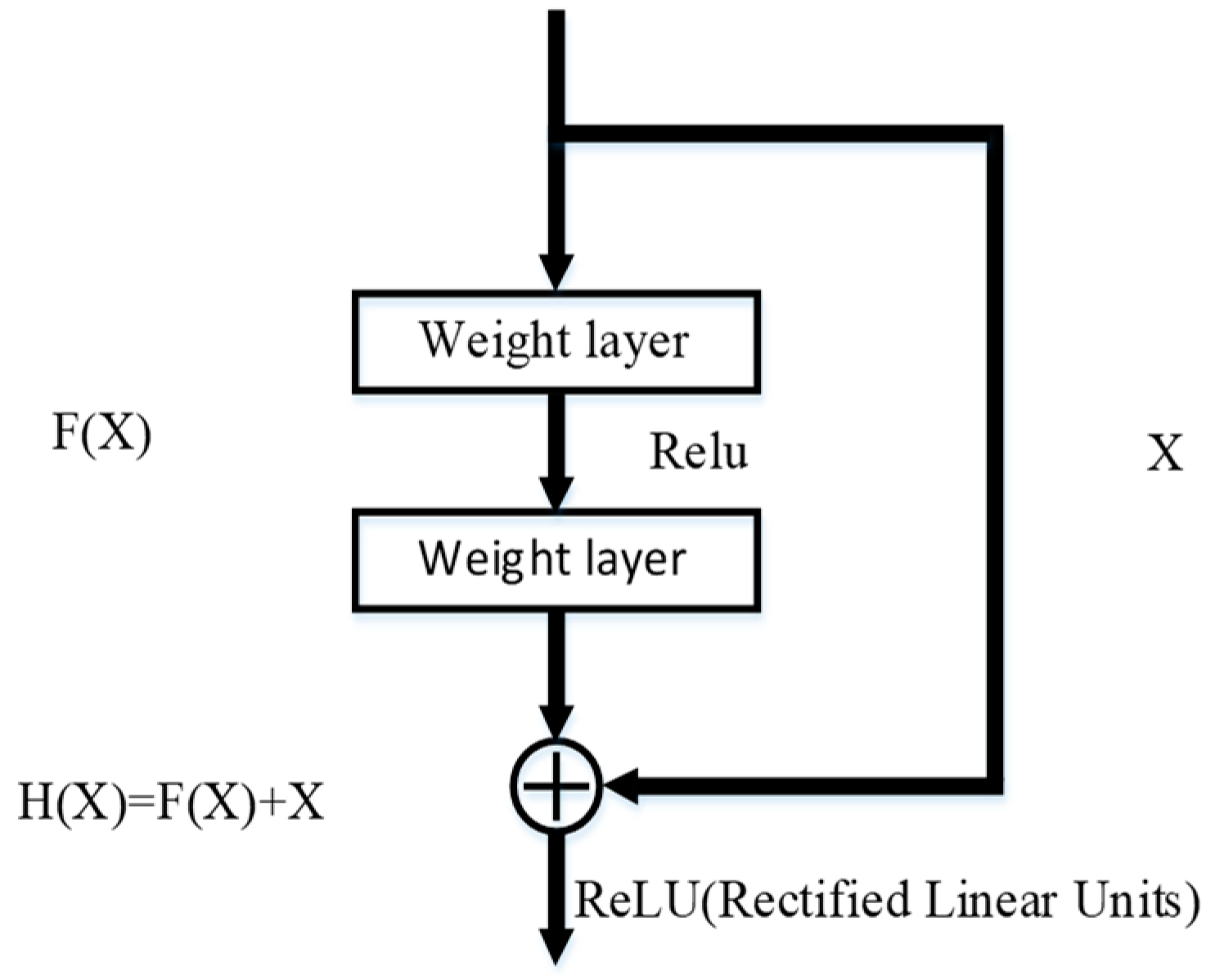
24]. For a stacked layer structure (stacked by several layers), if the residual is zero, then the stacked layer only makes an identity map, but the network performance will not decrease. However, in fact, the residual is not zero, which can enable the stacked layers to learn new features based on the input characteristics, thus having better performance. The basic idea is as follows (as shown in
Figure 2):
At this point, the original optimal solution mapping H
can be equivalent to
, that is, the fast connection implementation in the feed-forward network that is shown in
Figure 2. The method of quick connection can be expressed by Formula (1):
In Formula (1), X represents the input vector of the module, Y represents the output vector of the module, represents the weighting layer parameters, and a linear projection is needed to match the dimensions to ensure the consistency of the input and output dimensions.
ResNet-50 consists of 50 modules with the same structure, as shown in
Figure 2. In this paper, the vgg16 feature extraction model was replaced by the 50-layer residual network ResNet-50, to improve the classical Faster R-CNN depth learning model, and the improved detection framework was displayed in
Figure 3. Since the time cost of pre-training a resnet model from imagenet is expensive, and the feature extraction performance of ResNet-50 can achieve a good result, the resnet model using 101 layers and 152 layers will not be discussed in this paper.
2.4. Use K-Means to Cluster the Appropriate Anchor Size
The purpose of the clustering algorithm (K-Means) is to divide objects into different clusters, according to their respective attributes, so that the similarity of each object in the cluster is as high as possible, and the similarity between clusters is as small as possible. The criterion function that is used for evaluating similarity is the sum of squared errors. The network can learn to properly adjust the box, but if better priors are chosen, it can make the network easier to learn predictive detection. Instead of manually selecting priors, the k-means clustering algorithm is used to traverse the training set bounding box and automatically find good priors.
The original Faster R-CNN used nine kinds of anchor size; thus, the value of
k must be set to 9 to cluster, in order to obtain the same number for the new anchor size. Since the convolutional neural network has translation invariance and the positions of the anchor boxes are fixed by each grid, it is only necessary to calculate the widths and heights of the anchor boxes by the k-means. If a standard k-means with Euclidean distance is used, a larger box will produce more errors than the smaller box. However, the most important thing is to be able to obtain priors that lead to good IOU (Intersection over Union) scores, which are independent of the size of the box. Therefore, the new formula below is used to measure the distance:
In the above formula, IOU represents the coincidence of the prediction box and the label box. When the anchor boxes are calculated, the abscissa and ordinates of the center points of all boxes will be set to zero. Thus, all the boxes are in the same position, which is convenient for calculating the similarity between boxes by the new distance formula. As a k-means algorithm was used to traverse the label information of all marked tomato key organs, the more appropriate anchor sizes suitable for the dataset were obtained according to the sizes of the manually labeled bounding boxes. When the clustering algorithm was run, new anchor sizes were generated (sizes from 69 pixels to 247 pixels), and the original anchor sizes, 8 × 16, 16 × 16, 32 × 16 pixels were updated to 4 × 16, 8 × 16, 16 × 16 pixels, respectively. Thus, RPN could better detect some smaller sized targets when generating region proposals. This can avoid missing detection and improve recognition accuracy. For a more detailed description, please refer to [
25].
2.5. Region Proposal Network
The core idea of RPN is to directly generate region proposals by using CNN, which is essentially a sliding window [
26]. At the center of the sliding window, a total of nine kinds of anchors are generated, corresponding to three basic scales (8, 16, 32) and three aspect ratios (0.5, 1, 2) of the input image. Then the predicted region proposals are sent to two fully connected layers: cls layer and reg layer, which are used for classification and box regression, respectively. Finally, the top 300 region proposals are selected as inputs of Fast R-CNN after sorting according to the score of region proposals.
2.6. Soft-NMS
Non-maximum suppression (NMS) is used to suppress elements that are not the maxima, searching for local maxima. This local area represents a neighborhood with two variable parameters: one is the dimension of the neighborhood, and the other is the size of the neighborhood. Non-maximum suppression is an important part of the object detection process, which generates the detection box based on the object detection score. The detection box with the highest score is selected, while other detection boxes with obvious overlap with the selected detection box are suppressed. This process is continuously recursively applied to the remaining detection boxes [
27]. For example, in pedestrian detection, each window will obtain a score after feature extraction and classifier recognition, but the sliding window will also cause many windows to overlap with other windows, so that NMS is needed to select the detection box with the highest score in the neighborhood, and suppress those boxes with low scores.
Soft-NMS has the same algorithmic complexity as traditional NMS. It only needs to make simple changes to the traditional NMS algorithm without adding additional parameters and training, and it can be easily integrated into any object detection process with high efficiency and easy implementation.
The score reset function of the traditional NMS (rescoring function) is calculated as follows:
In the above Formula (3), a threshold is used in NMS to determine whether adjacent detection frames are reserved. Among them, is the bounding box with the highest current score, is the adjacent detection box, is the score of detection box, and is the threshold. When the iou of the and is less than the threshold , will not change, otherwise, will be set to zero.
The score reset function of the Soft-NMS (rescoring function) is calculated as follows:
The score of the adjacent detection box that overlaps with the detection box by attenuation is an effective improvement to the NMS algorithm. When the iou of the and is less than the threshold , will not change; otherwise, equals . The higher the overlap of is, the more serious the fractional attenuation may be. When the degree of overlap between the adjacent detection box and exceeds the threshold , the detection score of the detection box is linearly attenuated. In this case, the algorithm attenuates the detection score of the non-maximum detection box instead of completely removing it, and it does not attenuate the original detection score of the detection box without overlapping. Therefore, the non-maximum detection box of the tomato under overlapping and occlusion is retained, and the detection precision is improved.
6. Conclusions
In this paper, CNN was used to detect and identify the key organs of tomato. The original Faster R-CNN model based on the vgg16 feature extraction network was improved, and the resnet-50 with residual structure was used to replace the vgg16 network. Additionally, K-means clustering was adopted to fit the anchor size of the dataset in this paper, avoiding the problem of recognition accuracy reduction caused by artificial setting. Compared with the original Faster R-CNN model, this model used Soft-NMS to retain the generated detection boxes, which solved the problem of low detection accuracy of key tomato organs under overlapping and occlusion, to a certain extent.
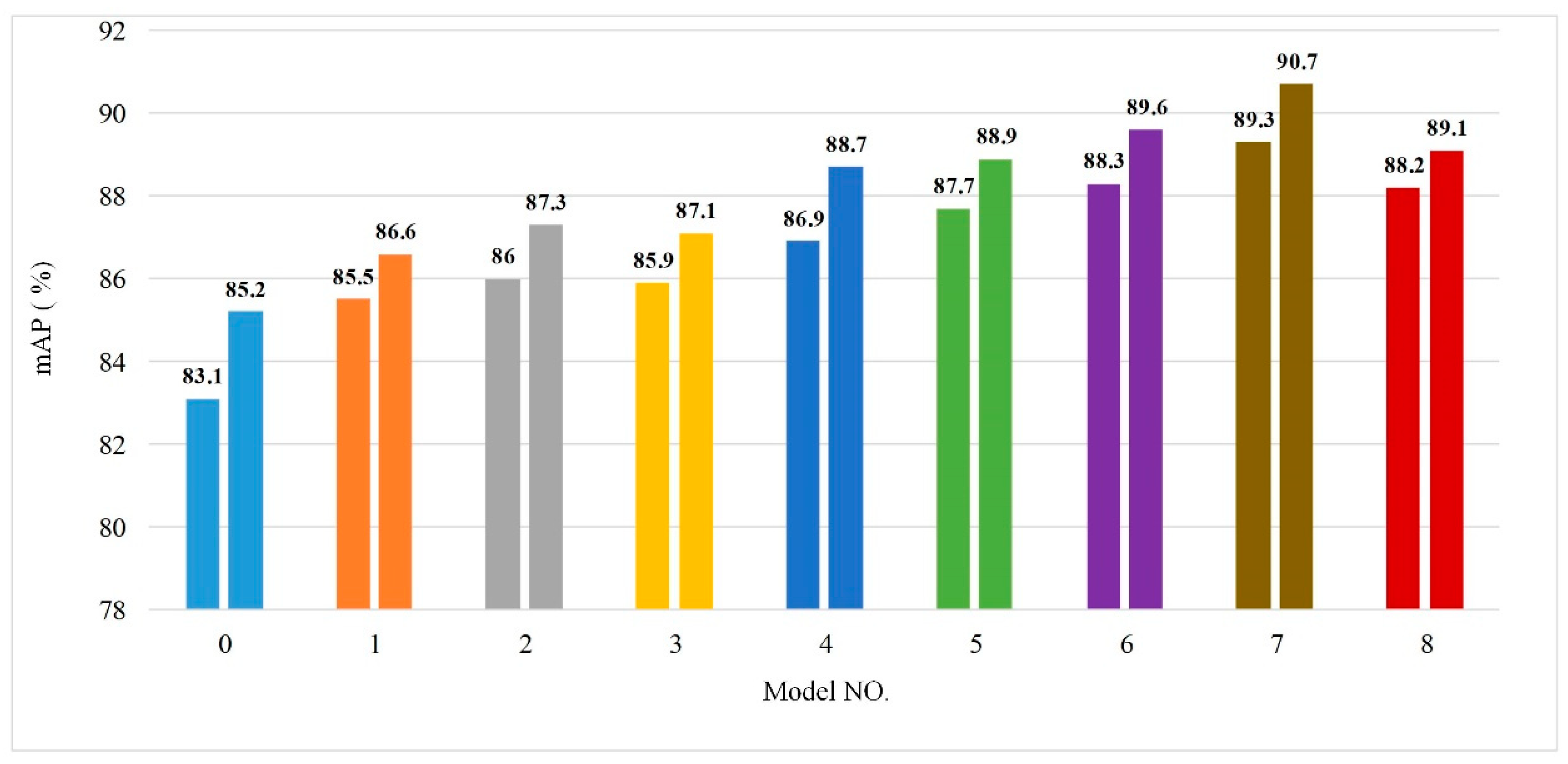
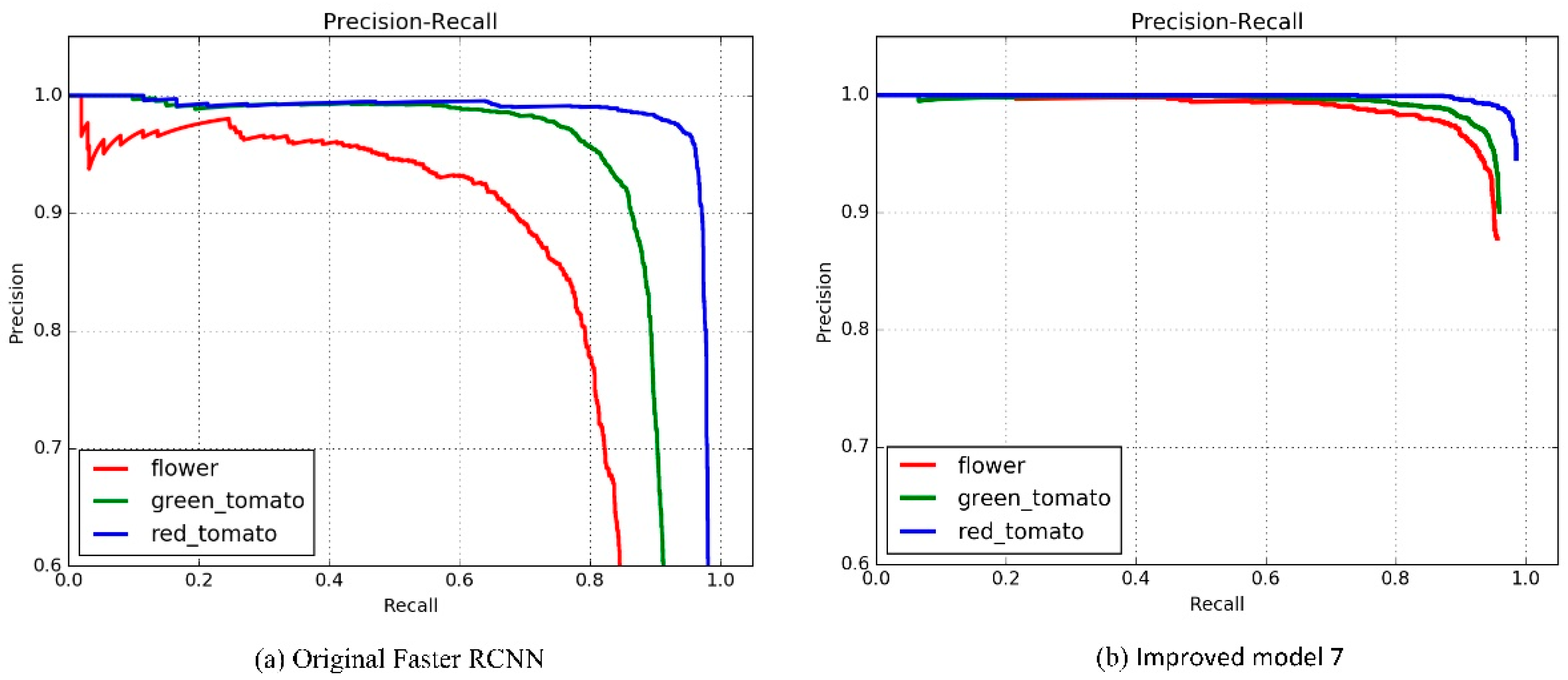
The results shows that the APs of tomato flowers, immature green tomatoes, and mature red tomatoes were increased from 76.8%, 88.4%, 90.4% to 90.5%, 90.8%, 90.9%, respectively. Additionally, the memory required by the model was reduced from 546.9 MB to 115.9 MB. The average detection time was shortened from 0.095 S/sheet to 0.073 S/sheet. The mAP was increased from 85.2% to 90.7%, and the performance of the model was greatly improved.
The training model can be transplanted to the embedded system in the future, which lays a theoretical foundation for the development of a precise pesticide targeting application system, and an automatic tomato picking robot device.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}