Use of Farmer Knowledge in the Delineation of Potential Management Zones in Precision Agriculture: A Case Study in Maize (Zea mays L.)




Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Plot Characteristics
2.2. Methodological Approach
2.3. Remote Sensing Data—Sentinel-2 Imagery: Acquisition, Processing, and Vegetation Indices
2.4. Apparent Electrical Conductivity and Elevation Data
2.5. Clustering Procedure to Delineate Potential Management Zones
2.6. Validation of Potential Management Zones
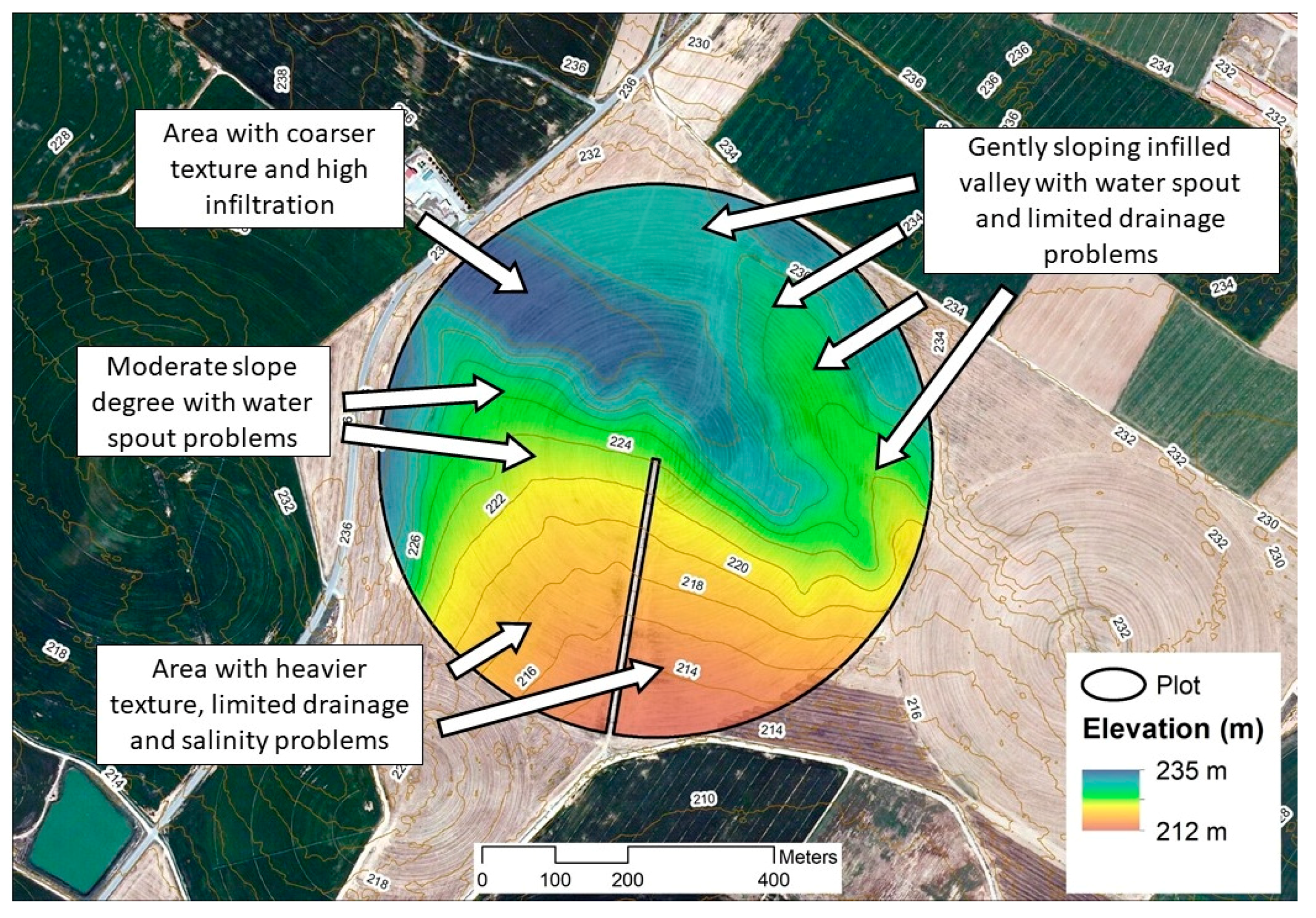
2.7. Refinement of Potential Management Zones: Adding Farmer’s Expert Knowledge
3. Results
3.1. Accumulated NDVI, ECa and Yield Maps
3.2. Clustering to Discriminate Areas of Different Yield Potential
3.3. Final Delineation of PMZ According to the Farmer’s Expert Knowledge
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mulla, D.J. Twenty-five years of remote sensing in precision agriculture: Key advances and remaining knowledge gaps. Biosyst. Eng. 2013, 114, 358–371. [Google Scholar] [CrossRef]
- Crookston, R.K. A top 10 list of developments and issues impacting crop management and ecology during the past 50 years. Crop Sci. 2006, 46, 2253–2262. [Google Scholar] [CrossRef]
- Pavón-Pulido, N.; López-Riquelme, J.A.; Torres, R.; Morais, R.; Pastor, J.A. New trends in precision agriculture: A novel cloud-based system for enabling data storage and agricultural task planning and automation. Precis. Agric. 2017, 18, 1038. [Google Scholar] [CrossRef]
- Bansod, B.; Singh, R.; Thakur, R.; Singhal, G. A comparison between satellite based and drone based remote sensing technology to achieve sustainable development: A review. J. Agric. Environ. Int. Dev. 2017, 111, 383–407. [Google Scholar] [CrossRef]
- Peralta, N.R.; Costa, J.L. Delineation of management zones with soil apparent electrical conductivity to improve nutrient management. Comput. Electron. Agric. 2013, 99, 218–226. [Google Scholar] [CrossRef] [Green Version]
- Castrignanò, A.; Buttafuoco, G.; Quarto, R.; Vitti, C.; Langella, G.; Terribile, F.; Venezia, A. A combined approach of sensor data fusion and multivariate geostatistics for delineation of homogeneous zones in an agricultural field. Sensors 2017, 17, 2794. [Google Scholar] [CrossRef] [PubMed]
- Arnó, J.; Martínez-Casasnovas, J.A.; Ribes, M.; Rosell, J.R. Review. Precision viticulture. Research topics, challenges and opportunities in site-specific vineyard management. Span. J. Agric. Res. 2009, 7, 779–790. [Google Scholar] [CrossRef]
- Gavioli, A.; Godoy de Souza, E.; Bazzi, C.L.; Carvalho Guedes, L.P.; Schenatto, K. Optimization of management zone delineation by using spatial principal components. Comput. Electron. Agric. 2016, 127, 302–310. [Google Scholar] [CrossRef]
- Uribeetxebarria, A.; Daniele, E.; Escolà, A.; Arnó, J.; Martínez-Casasnovas, J.A. Spatial variability in orchards after land transformation: Consequences for precision agriculture practices. Sci. Total Environ. 2018, 635, 343–352. [Google Scholar] [CrossRef] [PubMed]
- Corwin, D.L.; Lesch, S.M. Apparent soil electrical conductivity measurements in agriculture. Comput. Electron. Agric. 2005, 46, 11–43. [Google Scholar] [CrossRef]
- Arno, J.; Martinez-Casasnovas, J.A.; Ribes-Dasi, M.; Rosell, J.R. Clustering of grape yield maps to delineate site-specific management zones. Span. J. Agric. Res. 2011, 9, 721–729. [Google Scholar] [CrossRef]
- Fraisse, C.W.; Sudduth, K.A.; Kitchen, N.R. Delineation of site-specific management zones by unsupervised classification of topographic attributes and soil electrical conductivity. Trans. ASABE 2001, 44, 155–166. [Google Scholar] [CrossRef]
- Tagarakis, A.; Liakos, V.; Fountas, S.; Koundouras, S.; Gemtos, T.A. Management zones delineation using fuzzy clustering techniques in grapevines. Precis. Agric. 2013, 14, 18. [Google Scholar] [CrossRef]
- Taylor, J.A.; McBratney, A.B.; Whelan, B.M. Establishing management classes for broadacre agricultural production. Agron. J. 2007, 99, 1366–1376. [Google Scholar] [CrossRef]
- Moral, F.J.; Terrón, J.M.; Marques da Silva, J.R. Delineation of management zones using mobile measurements of soil apparent electrical conductivity and multivariate geostatistical techniques. Soil Tillage Res. 2009, 106, 335–343. [Google Scholar] [CrossRef]
- Jensen, J.R. Introductory Digital Image Processing: Remote Sensing Perspective, 2nd ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1996. [Google Scholar]
- Fridgen, J.J.; Kitchen, N.R.; Sudduth, K.A.; Drummond, S.T.; Wiebold, W.J.; Fraisse, C.W. Management zone analyst (MZA). Agron. J. 2004, 96, 100–108. [Google Scholar] [CrossRef]
- Jin, Z.; Prasad, R.; Shriver, J.; Zhuang, Q. Crop model- and satellite imagery-based recommendation tool for variable rate N fertilizer application for the US Corn system. Precis. Agric. 2017, 18, 779. [Google Scholar] [CrossRef]
- Maresma, A.; Lloveras, J.; Martínez-Casasnovas, J.A. Use of multispectral airborne images to improve in-season nitrogen management, predict grain yield and estimate economic return of maize in irrigated high yielding environments. Remote Sens. 2018, 10, 543. [Google Scholar] [CrossRef]
- Corwin, D.L.; Plant, R.E. Applications of apparent soil electrical conductivity in precision agriculture. Comput. Electron. Agric. 2005, 46, 1–10. [Google Scholar] [CrossRef]
- Tremblay, N.; Bouroubi, M.Y.; Panneton, B.; Guillaume, S.; Vigneault, P.; Bélec, C. Development and validation of fuzzy logic inference to determine optimum rates of N for corn on the basis of field and crop features. Precis. Agric. 2010, 11, 621–635. [Google Scholar] [CrossRef]
- Schepers, A.R.; Shanahan, J.F.; Liebig, M.A.; Schepers, J.S.; Johnson, S.H.; Luchiari, A. Appropriateness of management zones for characterizing spatial variability of soil properties and irrigated corn yields across years. Agron. J. 2004, 96, 195–203. [Google Scholar] [CrossRef]
- Maestrini, B.; Basso, B. Predicting spatial patterns of within-field crop yield variability. Field Crops Res. 2018, 219, 106–112. [Google Scholar] [CrossRef]
- Maresma, A.; Ariza, M.; Martínez, E.; Lloveras, J.; Martínez-Casasnovas, J.A. Analysis of vegetation indices to determine nitrogen application and yield prediction in maize (Zea mays L.) from a standard UAV service. Remote Sens. 2016, 8, 973. [Google Scholar] [CrossRef]
- Campos, I.; González-Gómez, L.; Villodre, J.; González-Piqueras, J.; Suyker, A.E.; Calera, A. Remote sensing-based crop biomass with water or light-driven crop growth models in wheat commercial fields. Field Crops Res. 2018, 216, 175–188. [Google Scholar] [CrossRef]
- González-Gómez, L.; Campos, I.; Calera, A. Use of different temporal scales to monitor phenology and its relationship with temporal evolution of normalized difference vegetation index in wheat. J. Appl. Remote Sens. 2018, 12, 026010. [Google Scholar] [CrossRef]
- Heijting, S.; de Bruin, S.; Bregt, A.K. The arable farmer as the assessor of within-field soil variation. Precis. Agric. 2011, 12, 488. [Google Scholar] [CrossRef]
- Schenatto, K.; Godoy de Souza, E.; Bazzi, C.L.; Betzek, N.M.; Gavioli, A.; Beneduzzi, H.M. Use of the farmer’s experience variable in the generation of management zones. Ciências Agrárias 2017, 38, 2305–2322. [Google Scholar] [CrossRef] [Green Version]
- Lundström, C.; Lindblom, J. Considering farmers’ situated knowledge of using agricultural decision support systems (AgriDSS) to Foster farming practices: The case of CropSAT. Agric. Syst. 2018, 159, 9–20. [Google Scholar] [CrossRef]
- Soil Survey Staff. Keys to Soil Taxonomy, 12th ed.; USDA-Natural Resources Conservation Service: Washington, DC, USA, 2014.
- Ritchie, S.W.; Hanway, J.J.; Benson, G.O. How a Corn Plant Develops; Special Report No. 48; Iowa State University Cooperative Extension Service: Ames, IA, USA, 1997. [Google Scholar]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Rouse, J.W., Jr.; Haas, R.H.; Deering, D.W.; Schell, J.A.; Harlan, J.C. Monitoring the Vernal Advancement and Retrogradation (GreenWave Effect) of Natural Vegetation; NASA/GSFC Type III Final Report; Goddard Space Flight Center: Greenbelt, MD, USA, 1974; 371p.
- Delegido, J.; Verrelst, J.; Alonso, L.; Moreno, J. Evaluation of Sentinel-2 Red-Edge Bands for Empirical Estimation of Green LAI and Chlorophyll Content. Sensors 2011, 11, 7063–7081. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Herrmann, I.; Pimstein, A.; Karnieli, A.; Cohen, Y.; Alchanatis, V.; Bonfil, D.J. LAI assessment of wheat and potato crops by VENμS and Sentinel-2 bands. Remote Sens. Environ. 2011, 115, 2141–2151. [Google Scholar] [CrossRef]
- Allen, R.G.; Pereira, L.S.; Raes, D.; Smith, M. Crop Evapotranspiration: Guidelines for Computing Crop Requirements; FAO Irrigation and Drainage Paper No. 56; FAO: Rome, Italy, 1998. [Google Scholar]
- Sudduth, K.A.; Kitchen, N.R.; Wiebold, W.J.; Batchelor, W.D.; Bollero, G.A.; Bullock, D.G.; Clay, D.E.; Palm, H.L.; Pierce, F.J.; Schuler, R.T.; et al. Relating apparent electrical conductivity to soil properties across the north-central USA. Comput. Electron. Agric. 2005, 46, 263–283. [Google Scholar] [CrossRef]
- Sheets, K.R.; Hendrickx, J.M.H. Non-invasive soil water content measurement using electromagnetic induction. Water Resour. Res. 1995, 31, 2401–2409. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B.; Whelan, B.M. VESPER Version 1.62; Australian Centre for Precision Agriculture, McMillan Building A05, The University of Sydney: Sydney, Australia, 2006; Available online: https://sydney.edu.au/agriculture/pal/software/vesper.shtml (accessed on 28 May 2018).
- Cook, S.; Cock, J.; Oberthür, T.; Fisher, M. On-Farm Experimentation. Better Crops 2013, 97, 17–20. [Google Scholar]
- Tanji, K.; Kielen, N.C. Agricultural Drainage Water Management in Arid and Semi-Arid Areas; FAO Irrigation and Drainage Paper 61; FAO: Rome, Italy, 2002; ISBN 92-5-104839-8. [Google Scholar]
- Maas, E.V.; Hoffman, G.J.; Chaba, G.D.; Poss, J.A.; Shannon, M.C. Salt sensitivity of corn at various growth stages. Irrig. Sci. 1983, 4, 45–57. [Google Scholar] [CrossRef]
- Lark, R.M.; Stafford, J.V. Classification as a first step in the interpretation of temporal and spatial variation of crop yield. Ann. Appl. Biol. 1997, 130, 111–121. [Google Scholar] [CrossRef]
- Zaidi, P.H.; Rafique, S.; Rai, P.K.; Singh, N.N.; Srinivasan, G. Tolerance to excess moisture in maize (Zea mays L.): Susceptible crop stages and identification of tolerant genotypes. Field Crops Res. 2004, 90, 189–202. [Google Scholar] [CrossRef]
- Oliver, Y.M.; Robertson, M.J.; Wong, M.T.F. Integrating farmer knowledge, precision agriculture tools, and crop simulation modelling to evaluate management options for poor-performing patches in cropping fields. Eur. J. Agron. 2010, 32, 40–50. [Google Scholar] [CrossRef]
- Anastasiadis, S.; Chukova, S. An inertia model for the adoption of new farming practices. Int. Trans. Oper. Res. 2016, 1–19. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acquisition Date | Image Identifier | Cloud Cover (%) | Maize Development Stage |
|---|---|---|---|
| 04/16/2017 | S2A_MSIL1C_20170416T105031_N0204_R051_T31TBG_20170416T105601 | 27.0 | Sowing |
| 04/26/2017 | S2A_MSIL1C_20170426T105031_N0204_R051_T31TBG_20170426T105321 | 88.0 (*) | VE |
| 05/06/2017 | S2A_MSIL2A_20170506T105031_N0205_R051_T31TBG_20170506T105029 | 0.4 | V1–V2 |
| 05/16/2017 | S2A_MSIL2A_20170516T105031_N0205_R051_T31TBG_20170516T105322 | 8.0 | V2–V4 |
| 05/26/2017 | S2A_MSIL2A_20170526T105031_N0205_R051_T31TBG_20170526T105518 | 1.0 | V4–V5 |
| 06/05/2017 | S2A_MSIL2A_20170605T105031_N0205_R051_T31TBG_20170605T105303 | 20.0 (*) | V5–V6 |
| 06/15/2017 | S2A_MSIL2A_20170615T105031_N0205_R051_T31TBG_20170615T105505 | 6.0 | V6–V8 |
| 06/25/2017 | S2A_MSIL2A_20170625T105031_N0205_R051_T31TBG_20170625T105322 | 51.0 (*) | V8–V9 |
| 07/05/2017 | S2A_MSIL2A_20170705T105031_N0205_R051_T31TBG_20170705T105605 | 0.5 | V9–V10 |
| 07/15/2017 | Unavailability of image in Copernicus Open Access Hub | V10–V11 | |
| 07/25/2017 | S2A_MSIL1C_20170725T105031_N0205_R051_T31TBG_20170725T105520 | 0.0 | VT |
| 08/04/2017 | S2A_MSIL1C_20170804T105031_N0205_R051_T31TBG_20170804T105328 | 0.0 | VT–R1 |
| 08/14/2017 | S2A_MSIL2A_20170814T105031_N0205_R051_T31TBG_20170814T105517 | 0.3 | R2–R3 |
| 08/24/2017 | S2A_MSIL2A_20170824T105031_N0205_R051_T31TBG_20170824T105240 | 1.0 | R3–R4 |
| 09/03/2017 | S2A_MSIL2A_20170903T105031_N0205_R051_T31TBG_20170903T105515 | 59.0 (*) | R4 |
| 09/13/2017 | S2A_MSIL2A_20170913T105021_N0205_R051_T31TBG_20170913T105335 | 0.5 | R4–R5 |
| 09/23/2017 | S2A_MSIL2A_20170923T105021_N0205_R051_T31TBG_20170923T105717 | 1.5 | R5–R6 |
| 10/03/2017 | S2A_MSIL2A_20171003T105021_N0205_R051_T31TBG_20171003T105856 | 58.0 (*) | R6 |
| 10/13/2017 | S2A_MSIL2A_20171013T105031_N0205_R051_T31TBG_20171013T105315 | 1.0 | R6 |
| 10/20/2017 | Harvest |
| Band Number | Band Name | Central Wavelength (nm) | Bandwidth (nm) |
|---|---|---|---|
| 1 | Coastal aerosol | 443.9 | 27 |
| 2 | Blue | 496.6 | 98 |
| 3 | Green | 560.0 | 45 |
| 4 | Red | 664.5 | 38 |
| 5 | Red Edge 1 | 703.9 | 19 |
| 6 | Red Edge 2 | 740.2 | 18 |
| 7 | Red Edge 3 | 782.5 | 28 |
| 8 | NIR | 835.1 | 145 |
| 8A | Narrow NIR | 864.8 | 33 |
| 9 | Water vapour | 945.0 | 26 |
| 10 | SWIR* Cirrus | 1373.5 | 75 |
| 11 | SWIR 1 | 1613.7 | 143 |
| 12 | SWIR 2 | 2202.4 | 242 |
| Variable | Min | Max | Mean | Standard Deviation | CV (%) |
|---|---|---|---|---|---|
| aNDVI | 2.3 | 7.0 | 5.6 | 0.5 | 8.4 |
| ECa 0–90 cm (mS m−1) | 0.5 | 143.7 | 33.5 | 26.1 | 77.7 |
| Maize yield (t ha−1) | 3.9 | 19.8 | 13.6 | 2.7 | 19.9 |
| Number of Classes | Based on aNDVI | Based on aNDVI-ECa | Based on aNDVI-ECa-DEM | |||
|---|---|---|---|---|---|---|
| FPI | NCE | FPI | NCE | FPI | NCE | |
| 2 | 0.0458 | 0.0164 * | 0.0996 | 0.0350 | 0.1409 | 0.0499 |
| 3 | 0.0435 | 0.0209 | 0.0694 * | 0.0336 * | 0.1088 | 0.5330 |
| 4 | 0.0399 * | 0.0215 | 0.0770 | 0.0431 | 0.0858 * | 0.0483 * |
| 5 | 0.0404 | 0.0230 | 0.0726 | 0.0429 | 0.1004 | 0.0613 |
| Clustered Variables | Class | Number of Validation Points (n = 80) | Average Maize Yield (t ha−1) * | aNDVI | ECa 0–90 cm (mS m−1) | Elevation (m) |
|---|---|---|---|---|---|---|
| aNDVI 2C | 1 | 48 | 14.7 a | 5.8 ± 0.3 | ||
| 2 | 32 | 11.7 b | 5.2 ± 0.4 | |||
| aNDVI 4C | 4 | 20 | 15.5 a | 6.0 ± 0.2 | ||
| 1 | 26 | 13.5 b | 5.6 ± 0.3 | |||
| 3 | 21 | 12.1 bc | 5.2 ± 0.3 | |||
| 2 | 13 | 10.8 c | 4.6 ± 0.6 | |||
| aNDVI-ECa 3C | 2 | 32 | 15.2 a | 5.9 ± 0.3 | 19.2 ± 13.2 | |
| 3 | 20 | 13.1 b | 5.4 ± 0.3 | 65.9 ± 18.5 | ||
| 1 | 28 | 11.8 b | 5.2 ± 0.5 | 21.4 ± 14.6 | ||
| aNDVI-ECa-DEM 4C | 2 | 26 | 14.9 a | 5.9 ± 0.3 | 17.2 ± 13.0 | 230.0 ± 2.3 |
| 4 | 25 | 13.4 ab | 5.6 ± 0.3 | 37.6 ± 17.5 | 220.2 ± 3.5 | |
| 3 | 10 | 13.4 ab | 5.3 ± 0.3 | 74.7 ± 18.8 | 220.0 ± 4.1 | |
| 1 | 19 | 11.7 b | 5.1 ± 0.5 | 19.4 ± 14.0 | 229.0 ± 3.2 |
| Clustered Variables | Class | Num. of Validation Points (total n = 80) | Average Maize Yield (t ha−1) | aNDVI | ECa 0–90 cm (mS m−1) | Elev. (m) |
|---|---|---|---|---|---|---|
| aNDVI-Farmer 3C | 1 | 22 | 15.4 a | 5.9 ± 0.2 | 18.5 ± 14.6 | 230.1 ± 3.8 |
| 2 | 30 | 13.8 b | 5.6 ± 0.3 | 42.6 ± 24.6 | 222.4 ± 5.5 | |
| 3 | 28 | 11.4 c | 5.4 ± 0.4 | 42.3 ± 30.1 | 223.2 ± 6.4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez-Casasnovas, J.A.; Escolà, A.; Arnó, J. Use of Farmer Knowledge in the Delineation of Potential Management Zones in Precision Agriculture: A Case Study in Maize (Zea mays L.). Agriculture 2018, 8, 84. https://doi.org/10.3390/agriculture8060084
Martínez-Casasnovas JA, Escolà A, Arnó J. Use of Farmer Knowledge in the Delineation of Potential Management Zones in Precision Agriculture: A Case Study in Maize (Zea mays L.). Agriculture. 2018; 8(6):84. https://doi.org/10.3390/agriculture8060084
Chicago/Turabian StyleMartínez-Casasnovas, José A., Alexandre Escolà, and Jaume Arnó. 2018. "Use of Farmer Knowledge in the Delineation of Potential Management Zones in Precision Agriculture: A Case Study in Maize (Zea mays L.)" Agriculture 8, no. 6: 84. https://doi.org/10.3390/agriculture8060084
APA StyleMartínez-Casasnovas, J. A., Escolà, A., & Arnó, J. (2018). Use of Farmer Knowledge in the Delineation of Potential Management Zones in Precision Agriculture: A Case Study in Maize (Zea mays L.). Agriculture, 8(6), 84. https://doi.org/10.3390/agriculture8060084