
Underwater Target Detection Algorithm Based on Improved YOLOv5

Abstract
:1. Introduction
- (1)
- In order to obtain more useful features and highlight the foreground targets, Swin Transformer was introduced as the backbone network of YOLOv5, thus making the model suitable for those underwater images with blurred targets;
- (2)
- In order to improve the effectiveness of feature fusion at different resolutions, the PANet multi-scale feature fusion method was improved, with consideration given to the contribution of features at different resolutions, and the features of the previous level were fused;
- (3)
- The confidence loss function was improved based on the detection layers. In this way, the model can be biased to learn features of relatively important scales, thus mitigating the negative impact of low-quality anchor boxes on the network, with the network biased to learn high-quality positive anchor boxes;
- (4)
- More than 6000 valid images were labeled in order to demonstrate through experimentation that the accuracy of improved network detection can reach 87.2%(mAP), which exceeds its baseline and outperforms other general target detection models.
2. Improved YOLOv5 Network
2.1. Overview of YOLOv5
2.2. Proposed Model
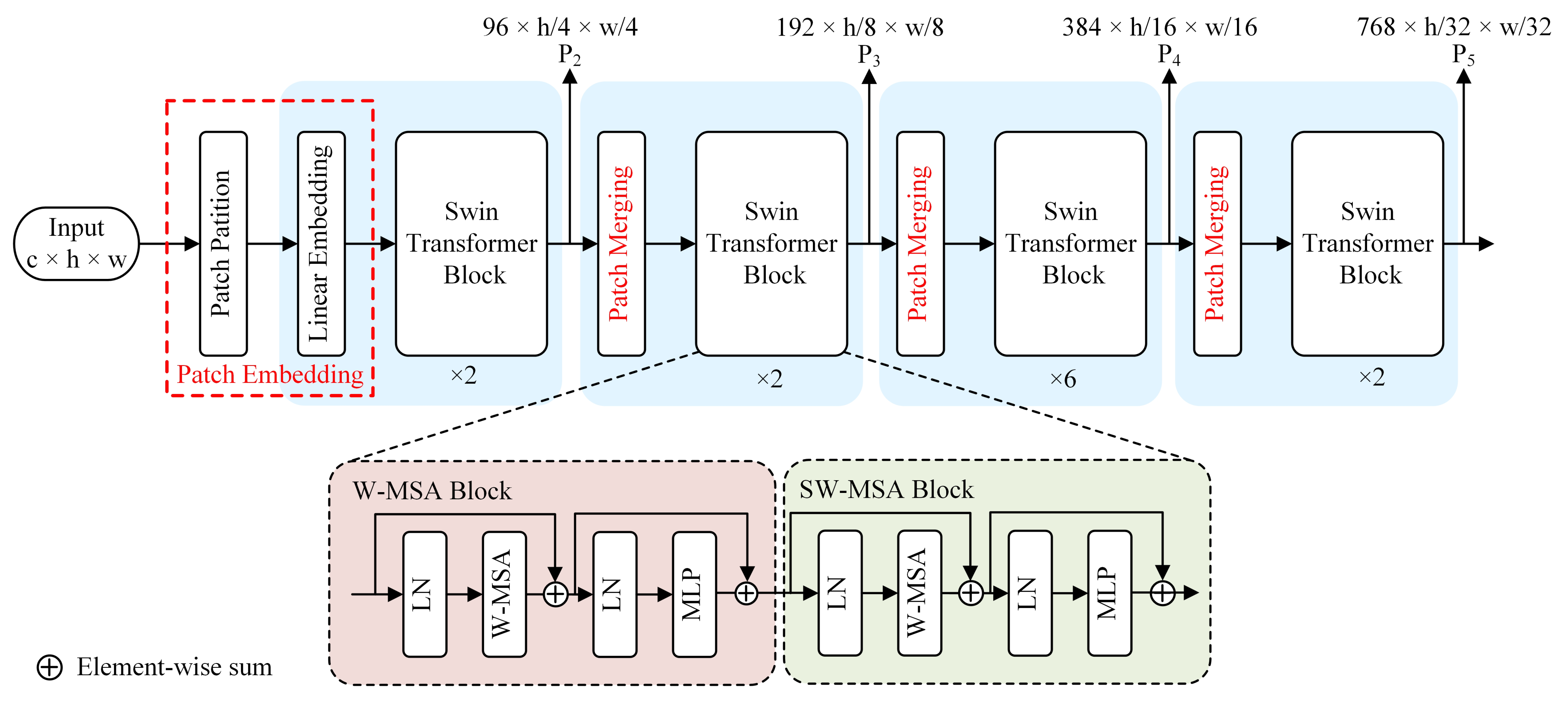
2.2.1. Backbone Network Based on Swin Transformer
2.2.2. Improvement of Multi-Scale Feature Fusion
2.2.3. Improvement of Confidence Loss Function Based on Detection Layers
3. Experiments
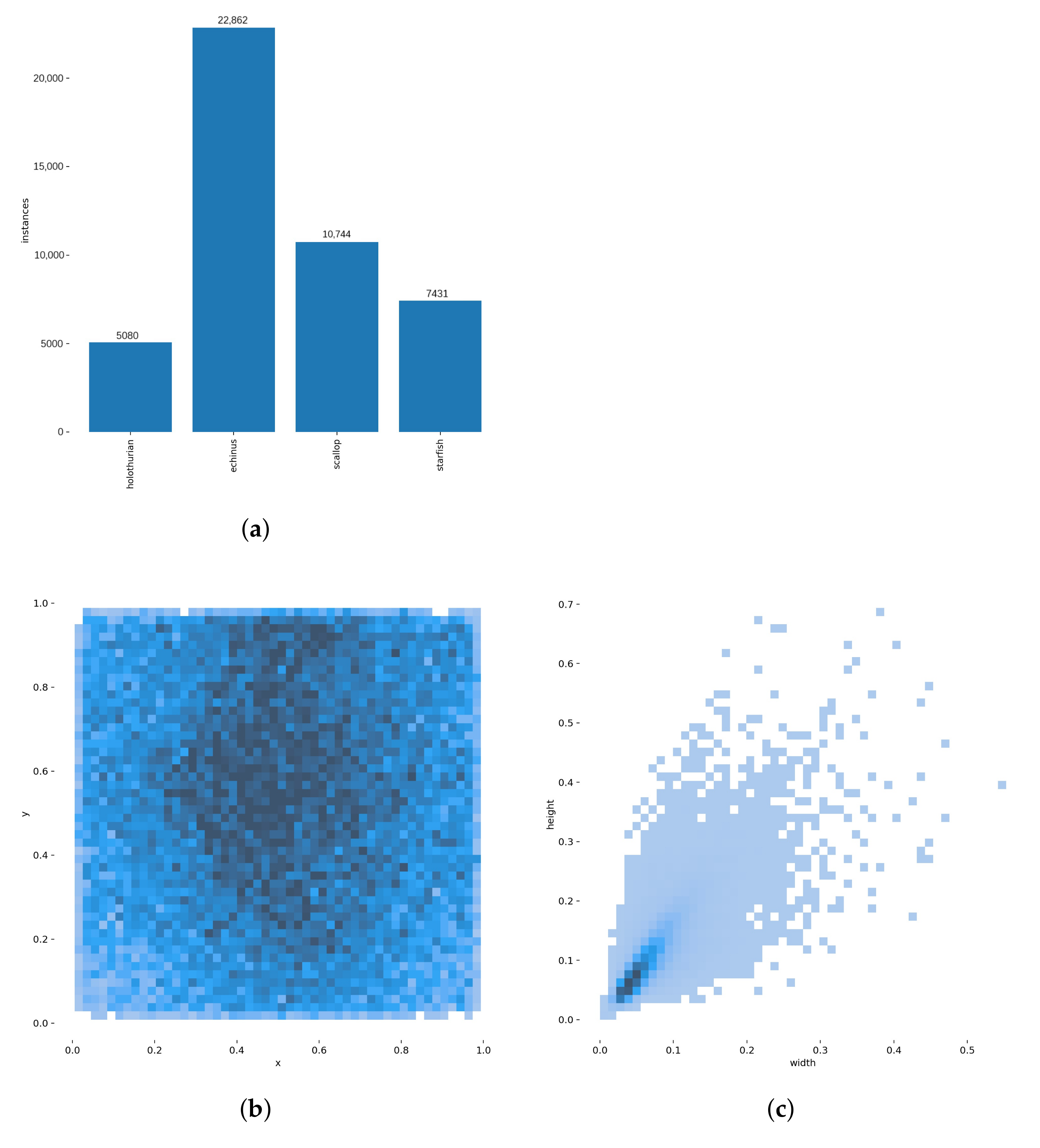
3.1. Data Set
3.2. Model Evaluation Metrics
3.3. Experimental Settings
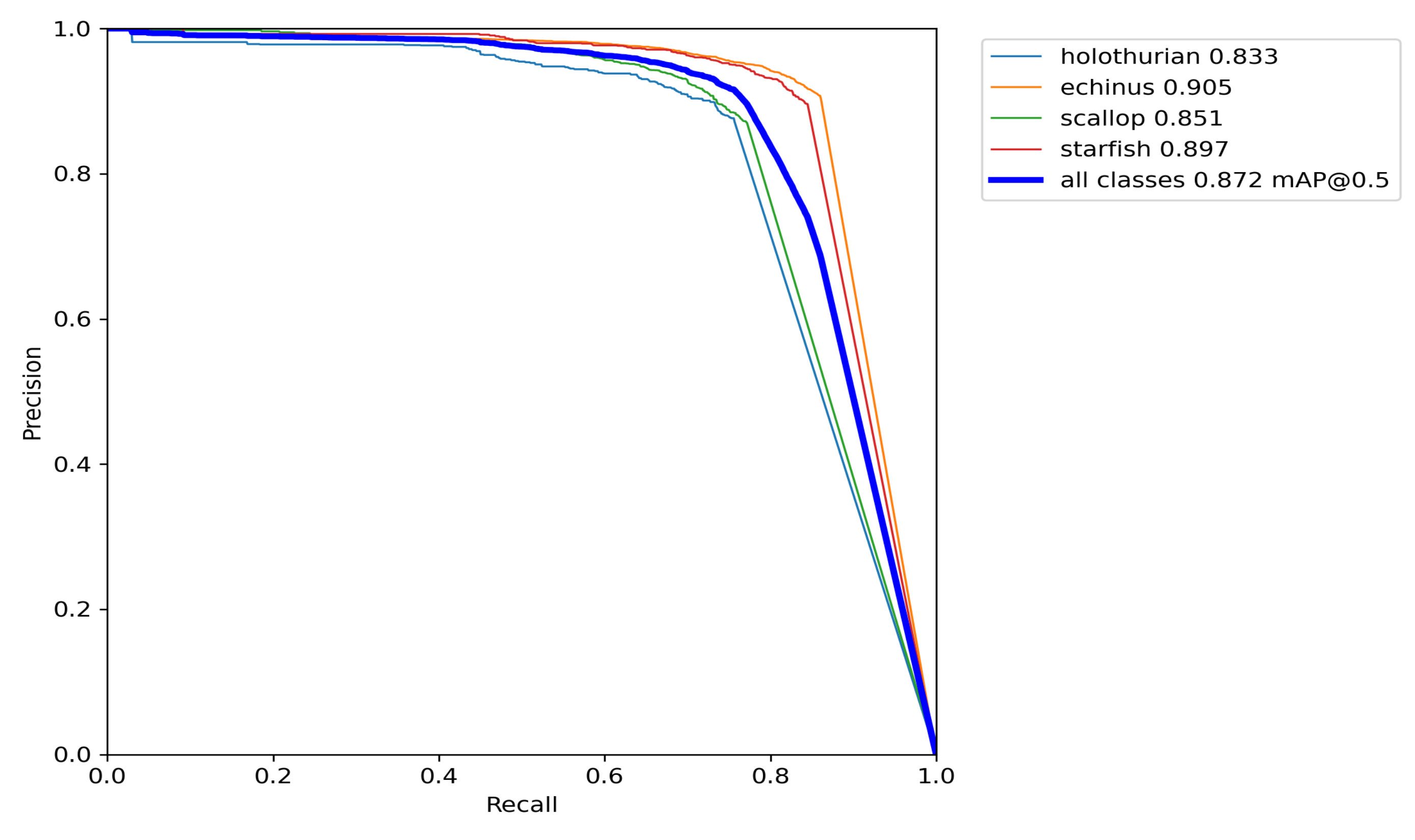
3.4. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Zeng, L.; Sun, B.; Zhu, D. Underwater target detection based on Faster R-CNN and adversarial occlusion network. Eng. Appl. Artif. Intell. 2021, 100, 104190. [Google Scholar] [CrossRef]
- Chen, L.; Zheng, M.; Duan, S.; Luo, W.; Yao, L. Underwater Target Recognition Based on Improved YOLOv4 Neural Network. Electronics 2021, 10, 1634. [Google Scholar] [CrossRef]
- Sahoo, A.; Dwivedy, S.K.; Robi, P. Advancements in the field of autonomous underwater vehicle. Ocean Eng. 2019, 181, 145–160. [Google Scholar] [CrossRef]
- Carlucho, I.; De Paula, M.; Wang, S.; Petillot, Y.; Acosta, G.G. Adaptive low-level control of autonomous underwater vehicles using deep reinforcement learning. Robot. Auton. Syst. 2018, 107, 71–86. [Google Scholar] [CrossRef] [Green Version]
- Forsyth, D. Object detection with discriminatively trained part-based models. Computer 2014, 47, 6–7. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Platt, J. Sequential minimal optimization: A fast algorithm for training support vector machines. Adv. Kernel Methods-Support Vector Learn. 1998, 208. Available online: https://www.microsoft.com/en-us/research/uploads/prod/1998/04/sequential-minimal-optimization.pdf (accessed on 1 January 2022).
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. Dsod: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1919–1927. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Villon, S.; Chaumont, M.; Subsol, G.; Villéger, S.; Claverie, T.; Mouillot, D. Coral reef fish detection and recognition in underwater videos by supervised machine learning: Comparison between Deep Learning and HOG+ SVM methods. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Lecce, Italy, 24–27 October 2016; pp. 160–171. [Google Scholar]
- Li, X.; Shang, M.; Qin, H.; Chen, L. Fast accurate fish detection and recognition of underwater images with fast r-cnn. In Proceedings of the OCEANS 2015-MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–5. [Google Scholar]
- Li, X.; Shang, M.; Hao, J.; Yang, Z. Accelerating fish detection and recognition by sharing CNNs with objectness learning. In Proceedings of the OCEANS 2016-Shanghai, Shanghai, China, 10–13 April 2016; pp. 1–5. [Google Scholar]
- Chen, L.; Zhou, F.; Wang, S.; Dong, J.; Li, N.; Ma, H.; Wang, X.; Zhou, H. SWIPENET: Object detection in noisy underwater images. arXiv 2020, arXiv:2010.10006. [Google Scholar]
- Lin, W.H.; Zhong, J.X.; Liu, S.; Li, T.; Li, G. Roimix: Proposal-fusion among multiple images for underwater object detection. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2588–2592. [Google Scholar]
- Qiao, W.; Khishe, M.; Ravakhah, S. Underwater targets classification using local wavelet acoustic pattern and Multi-Layer Perceptron neural network optimized by modified Whale Optimization Algorithm. Ocean Eng. 2021, 219, 108415. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Ma, J.; Yuan, Y. Dimension reduction of image deep feature using PCA. J. Vis. Commun. Image Represent. 2019, 63, 102578. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7482–7491. [Google Scholar]
- Cai, Q.; Pan, Y.; Wang, Y.; Liu, J.; Yao, T.; Mei, T. Learning a unified sample weighting network for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 14173–14182. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Epochs | Batch Size | Learning Rate | Weight Decay | Momentum |
|---|---|---|---|---|
| 500 | 16 | 0.01 | 0.0005 | 0.9 |
| Translate (Image Translation) | Scale (Image Scale) | Fliplr (Image Flip Left-Right) | Flipud (Image Flip Up-Down) | Mosaic | Mixup |
|---|---|---|---|---|---|
| 0.1 | 0.5 | 0.1 | 0.5 | 1.0 | 0.1 |
| Model | Depth Multiple | Width Multiple | Number of Parameters | Size of Model (MB) | mAP (%) |
|---|---|---|---|---|---|
| YOLOv5s | 0.33 | 0.50 | 14.1 | 84.9 | |
| YOLOv5m | 0.67 | 0.75 | 40.5 | 85.2 | |
| YOLOv5l | 1.0 | 1.0 | 89.4 | 85.6 | |
| YOLOv5x | 1.33 | 1.33 | 167.0 | 85.7 |
| Pre-Set Anchor | Swin Transformer | Improved Multi-Scale Feature Fusion | Improved Confidence Loss Function | mAP (%) |
|---|---|---|---|---|
| 84.9 | ||||
| ✓ | 85.2 (+0.3) | |||
| ✓ | ✓ | 86.7 (+1.5) | ||
| ✓ | ✓ | ✓ | 86.9 (+0.2) | |
| ✓ | ✓ | ✓ | ✓ | 87.2 (+0.3) |
| Method | Backbone Network | mAP (%) | AP (%, Holothurian) | AP (%, Echinus) | AP (%, Scallop) | AP (%, Starfish) |
|---|---|---|---|---|---|---|
| SSD | VGG-16 | 60.9 | 59.5 | 73.8 | 41.1 | 69.1 |
| YOLOv4 | Darknet-53 | 82.2 | 71.8 | 89.6 | 82.3 | 85.2 |
| YOLOv5s | CSPDarknet53 | 84.9 | 74.9 | 91.0 | 85.1 | 88.4 |
| YOLOv5x | CSPDarknet53 | 85.7 | 76.5 | 91.4 | 86.1 | 88.6 |
| Improved YOLOv5s | Swin Transformer | 87.2 | 83.3 | 90.5 | 85.1 | 89.7 |
| Training Time (h) | Time Spent in Detection (ms) | Detection Speed (FPS) | Size of Model (MB) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|
| 45 | 31 | 32 | 775 | 88.4 | 81.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, F.; Tang, F.; Li, S. Underwater Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. https://doi.org/10.3390/jmse10030310
Lei F, Tang F, Li S. Underwater Target Detection Algorithm Based on Improved YOLOv5. Journal of Marine Science and Engineering. 2022; 10(3):310. https://doi.org/10.3390/jmse10030310
Chicago/Turabian StyleLei, Fei, Feifei Tang, and Shuhan Li. 2022. "Underwater Target Detection Algorithm Based on Improved YOLOv5" Journal of Marine Science and Engineering 10, no. 3: 310. https://doi.org/10.3390/jmse10030310
APA StyleLei, F., Tang, F., & Li, S. (2022). Underwater Target Detection Algorithm Based on Improved YOLOv5. Journal of Marine Science and Engineering, 10(3), 310. https://doi.org/10.3390/jmse10030310