1. Introduction
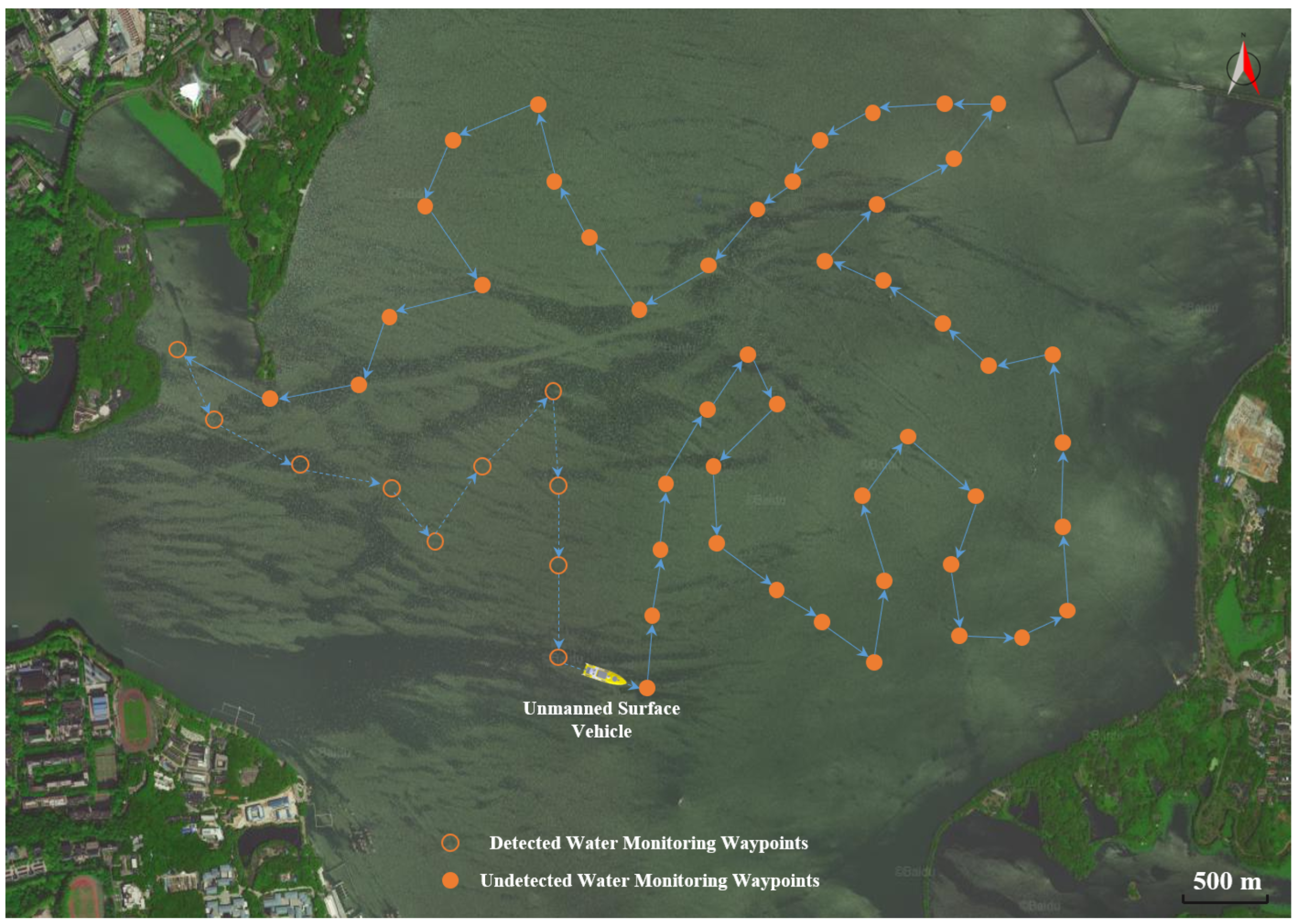
Unmanned surface vehicles (USVs), which have attractive operating and maintenance costs, the capability to perform at high intensity, and good maneuverability [
1], have gained wide attention in scientific research recently. For monitoring pollutant concentrations in lakes or oceans, USVs can be equipped with multiple monitoring sensors to effectively collect environmental data, as well as avoid direct long-term human exposure to hazardous environments [
2,
3] (as shown in
Figure 1). In particular, prior environmental information and sampling path planning are important components for the guidance systems since they facilitate the design of an optimal path based on navigation information and mission objectives [
4]. In this context, effective path planning for USVs is crucial for saving operation time and mission costs. Consequently, it has become a research hot spot to design a fast convergence algorithm that facilitates optimal path planning [
5].
In view of the traversing order of multiple-waypoint for the USV path planning, the problem can be mathematically equivalent to the traveling salesman problem (TSP), which is a famous NP-hard combinatorial optimization problem, and so far lacks a polynomial-time algorithm to obtain an optimal solution [
6]. This problem can be described as follows: a salesman who plans to visit several cities wants to find the shortest Hamilton cycle that permits him to visit each city only once and eventually return to his starting city [
7,
8]. As a typical optimization problem, the TSP is widely seen in a range of practical missions, including robot navigation, computer wiring, sensor placement, and logistics management [
9]. For these reasons, many approaches have been proposed to solve the TSP in past decades, including exact and approximate algorithms. The optimal solution to the problem can be obtained with a rigorous math logical analysis for the exact algorithm [
10,
11]. However, the expensive computational cost makes it inadequate for solving medium-scale to large-scale NP-complete problems. Hence, many researchers turn to solving the TSP using approximation algorithms. These algorithms can be divided into two categories. For the first, local search algorithms, such as 2-opt [
12] and 3-opt [
13], are used to solve the small-scale TSP. Generally, the efficiency of these algorithms decreases as the problem dimension increases and algorithms tend to fall into local optimal solutions. Therefore, many metaheuristic algorithms for solving symmetric TSP have been presented in the literature over the past decades, including: the genetic algorithm (GA) [
14], simulated annealing (SA) [
15], artificial bee colony (ABC) [
16], ant colony optimization (ACO) [
17], Jaya algorithm (JAYA) [
18], etc.
These metaheuristic algorithms solve the TSP in three main phases: initialization, crossover, and mutation [
19]. In general, these metaheuristic algorithms can obtain good results when attempting to solve small-scale optimization problems. However, the larger the scale of optimization problems is, the slower the convergence speed will be, and it is also easier to fall into a local optimum [
20]. Motivated by the aforementioned discussions, a novel discrete group teaching optimization algorithm (DGTOA), inspired by the group teaching optimization algorithm (GTOA) [
21], is proposed to solve TSP. The DGTOA is presented in three phases in this paper. Firstly, in the initialization phase, the DGTOA generates the initial sequence for students through greedy initialization. Then, in the crossover phase, a new greedy crossover algorithm is employed to increase diversity. Finally, in the mutation phase, to balance the exploration and exploitation, this paper develops a dynamic adaptive neighborhood radius based on triangular probability selection to apply in the shift mutation algorithm, the inversion mutation algorithm, and the 3-opt mutation algorithm. In addition, to verify the performance of the DGTOA, fifteen benchmark problems in TSPLIB [
22] are used to test the algorithm as well as compare it with the discrete tree seed algorithm (DTSA) [
6], discrete Jaya algorithm (DJAYA) [
18], ABC [
7], particle swarm optimization-ant colony optimization (PSO-ACO) [
23], and discrete shuffled frog-leaping algorithm (DSFLA) [
24]. From the comparison results, we can conclude that the DGTOA has a comparative advantage. The main contributions of this algorithm to other algorithms in the literature are as follows:
This study presents the first application of the GTOA in the permutation-coded discrete form.
The DGTOA is a novel and effective discrete optimization algorithm for solving the TSP, and the comparison shows that the solutions obtained by the DGTOA have comparable performance.
The dynamic adaptive neighborhood radius can balance the exploration and exploitation for solving the TSP.
The DGTOA has been successfully applied to USV path planning, and the simulation results indicate that the DGTOA can provide a competitive advantage in path planning for USVs.
The remainder of the paper is arranged as follows. A literature survey on techniques to avoid falling into a local optimum and improve the optimization speed is given in
Section 2. In
Section 3, the original GTOA, the TSP, and the dynamic adaptive neighborhood radius model are described. After that, the DGTOA model is introduced in
Section 4. Results and discussions are provided in
Section 5. Finally,
Section 6 concludes the study.
2. Literature Survey
The following section will focus on the current efforts of researchers to develop techniques to avoid falling into a local optimum and improve the optimization speed from the initialization, crossover, and mutation phases. Aiming at solving the TSP, related improvement techniques can be roughly introduced as follows.
The first one is improving the algorithm initialization rules to accelerate convergence. In order to speed up convergence, W. Li et al. discussed K-means clustering as a method to group individuals with similar positions into the same class to obtain the initial solution [
25]. In another study, to ensure that the algorithm would execute within the given time, M. Bellmore et al. developed the nearest neighbor heuristic initialization algorithm [
26]. On the basis of the nearest neighbor initialization, L. Wang et al. introduced the k-nearest neighbors’ initialization method, where the algorithm adopted a greedy approach to select the k-nearest neighbors [
27]. A.C. Cinar et al. presented the initial solution of the tree during the initialization phase using the nearest neighbor and a random approach for balancing the speed and quality of its solution [
6]. C. Wu et al. [
28] and P. Guo et al. [
29] adopted a greedy strategy for generating initialized populations to improve the optimization speed and avoid falling into a local optimum.
The second way to avoid getting trapped in the local optimum is to use crossover rules to increase diversity. For example, İlhan et al. used genetic edge recombination crossover and order crossover to avoid falling into the local optimum and improve their performances [
30]. Z.H. Ahmed presented a sequential constructive crossover operator (SCX) to solve the TSP to avoid getting trapped in the local optimum [
31]. In another study, Hussain et al. proposed a method based on the GA to solve TSP with a modified cycle crossover operator (CX2) [
13]. In their approach, path representations have effectively balanced optimization speed and solution quality. Y. Nagata et al. devised a robust genetic algorithm based on the edge assembly crossover (EAX) operator [
32]. To avoid being limited in the local optimum, the algorithm used both local and global versions of EAX.
The third one is adopting a mutation strategy to balance exploration and exploitation for solving the TSP. For instance, M. Albayrak et al. compared greedy sub-tour mutation (GSTM) with other mutation techniques. GSTM demonstrated significant advantages in polynomial-time [
33]. To further avoid falling into a local optimum, A.C. Cinar et al. presented the use of swap, shift, and symmetric transformation operators for the DTSA to solve the problem of coding optimization in the path improvement phase [
6]. To balance exploration and exploitation, M. Anantathanavit et al. employed K-means to cluster the sub-cities and merge them by the radius particle swarm optimization embedded into adaptive mutation, which could balance between time and accuracy [
34].
Besides the main strategies for improvement mentioned above, some researchers combined a local search algorithm and a metaheuristic algorithm to avoid premature convergence and further improve the solution quality. For example, Mahi et al. developed a hybrid algorithm that combined PSO, ACO, and 3-opt algorithms, allowing it to avoid premature convergence and increase accuracy and robustness [
23]. Moreover, a support vector regression approach is employed by R. Gupta et al. to solve the search space problem of the TSP [
35].
Specifically, in practical ocean survey scenarios, D.V. Lyridis proposed an improved ACO with a fuzzy logic optimization algorithm for local path planning of USVs [
36]. This algorithm offers considerable advantages in terms of optimal solution and convergence speed. Y.C. Liu et al. proposed a novel self-organizing map (SOM) algorithm for USV to generate sequences performing multiple tasks quickly and efficiently [
37]. J.F. Xin et al. introduced a greedy mechanism and a 2-opt operator to improve the particle swarm algorithm for high-quality path planning of USV [
4]. The improved algorithm was validated in a USV model in a realistic marine environment. J.H. Park et al. used a genetic algorithm to improve the mission planning capability of USVs and tested it in a simulation environment [
38].
Following the literature survey, improving the algorithm initialization rules, using crossover rules, adopting a mutation strategy, combining with a local search algorithm, or all of these strategies in combination can be applied to the TSP to avoid falling into a local optimum. However, direct random crossover and global mutation are challenging in terms of convergence speed. Moreover, a higher convergence speed is required for the DGTOA to achieve rapid and optimal path planning for USVs. Thus, in contrast to the studies mentioned above, the DGTOA innovatively incorporates a dynamic adaptive neighborhood radius model, which is applied to the neighborhood mutation mode. Meanwhile, a new greedy crossover method is used to further improve TSP path exploration.
5. Results and Discussions
The DGTOA with dynamic adaptive neighborhood optimization is tested using 15 benchmark TSP cases taken from TSPLIB [
22]. Most of the instances in TSPLIB have been solved, and the optimum values are displayed. The numbers in the problem names indicate the city numbers (e.g., the eil51 benchmark problem means that the problem has 51 cities). Testing is performed using fifteen benchmark problems, which are divided into three categories: small-scale, medium-scale, and large-scale based on city numbers, respectively. For example, the case with less than 100 cities is considered a small-scale benchmark problem; the case with more than 100 but less than 200 cities is a medium-scale benchmark problem, and the case with more than 200 but less than 300 cities is a large-scale benchmark problem. Each of the experiments in this section is carried out 25 times independently, with the best results, mean results, and standard deviation (Std Dev) values produced by the algorithm having been recorded, and the best optimum results are written in bold font in the result tables. The relative error (RE) is calculated as follows:
where
R is the obtained length (mean of 25 repeats) by the DGTOA, and
O is the optimum value of the problem. The optimum problems and their values are given in
Table 1 [
18,
42]. All experiments are carried out using a Windows 11 Professional Insider Preview laptop with an Intel (R) Core (TM) i7-7700HQ 2.8 GHz processor and 16 GB of RAM, with the scripts being written in MATLAB 2021a. The following is a series of experiments in which the maximum number of iterations is 1000 and the number of students is 100.
5.1. Experiment 1: Comparisons with Random Initialization, Neighborhood Initialization, and Greedy Initialization
The experiment uses fifteen benchmark problems to evaluate the efficacy of random initialization, neighborhood initialization, and greedy initialization to solve TSP. The obtained results are shown in
Table 2.
According to the bold part in
Table 2, in terms of mean and RE, the optimization solutions produced by neighborhood initialization and greedy initialization have considerable advantages over random initialization. On the other hand, by analyzing the neighborhood initialization as well as greedy initialization, it is evident from
Table 2 that the greedy initialization has a slight advantage in 11 instances. However, the neighborhood initialization has a slight performance on eil101 and pr152. For further analysis of the three initialization methods iterative process, the convergence RE plots of the middle-scale eil101 and large-scale tsp225 benchmark problems are given in
Figure 8 and
Figure 9, which are used to compare the convergence processes of random initialization, neighborhood initialization, and greedy initialization.
According to
Figure 8, the neighborhood initialization and greedy initialization show a considerable advantage in the initial solution over random initialization. For random initialization, it takes 500 generations to reach an RE of less than 3%, but for neighborhood initialization and greedy initialization, they take only 100 generations to satisfy convergence. Compared to neighborhood initialization, greedy initialization can achieve an RE of less than 1% within 200 generations, whereas neighborhood initialization takes 600 generations to achieve an RE of less than 1%.
As seen in
Figure 9, compared to neighborhood initialization and greedy initialization, the random initialization method has a certain gap in the initial results as well as the final optimization results, and the convergence to an RE of less than 5% has a larger gap. Moreover, the RE of greedy initialization declines less than 3% faster than neighborhood initialization. Hence the DGTOA uses a greedy rule in the initialization phase.
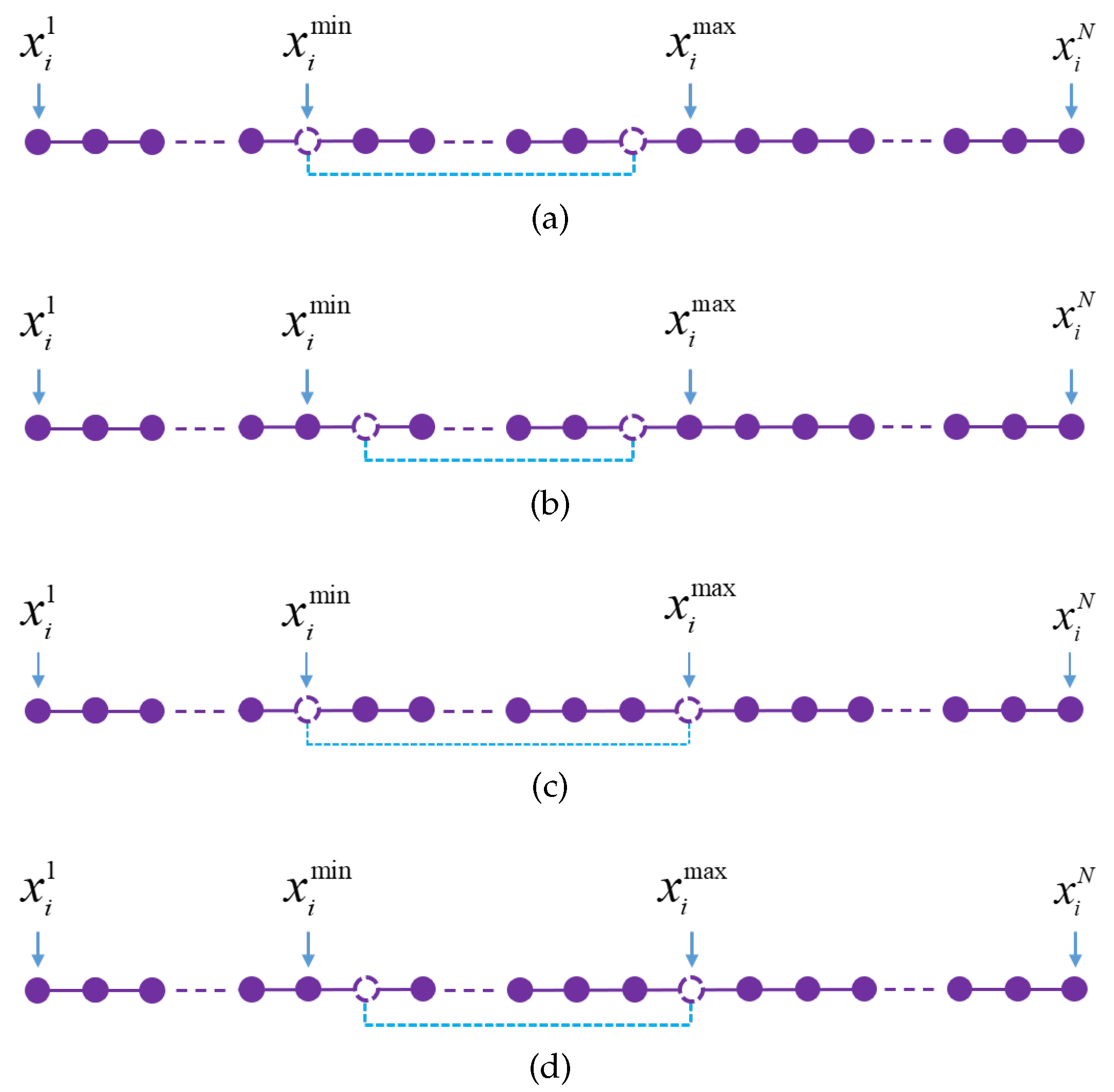
5.2. Experiment 2: Comparisons with Adaptive Neighborhood Mutation and Dynamic Adaptive Neighborhood Mutation
To compare the adaptive neighborhood radius and the dynamic adaptive neighborhood radius during the mutation phase. The adaptive neighborhood radius is assigned
as a value of 500 and fixed (Formula (9)). Fifteen benchmark problems are used to evaluate the effectiveness of the two neighborhood radius methods to solve the TSP, with all parameters except
set the same each time. The results are shown in
Table 3.
As seen from
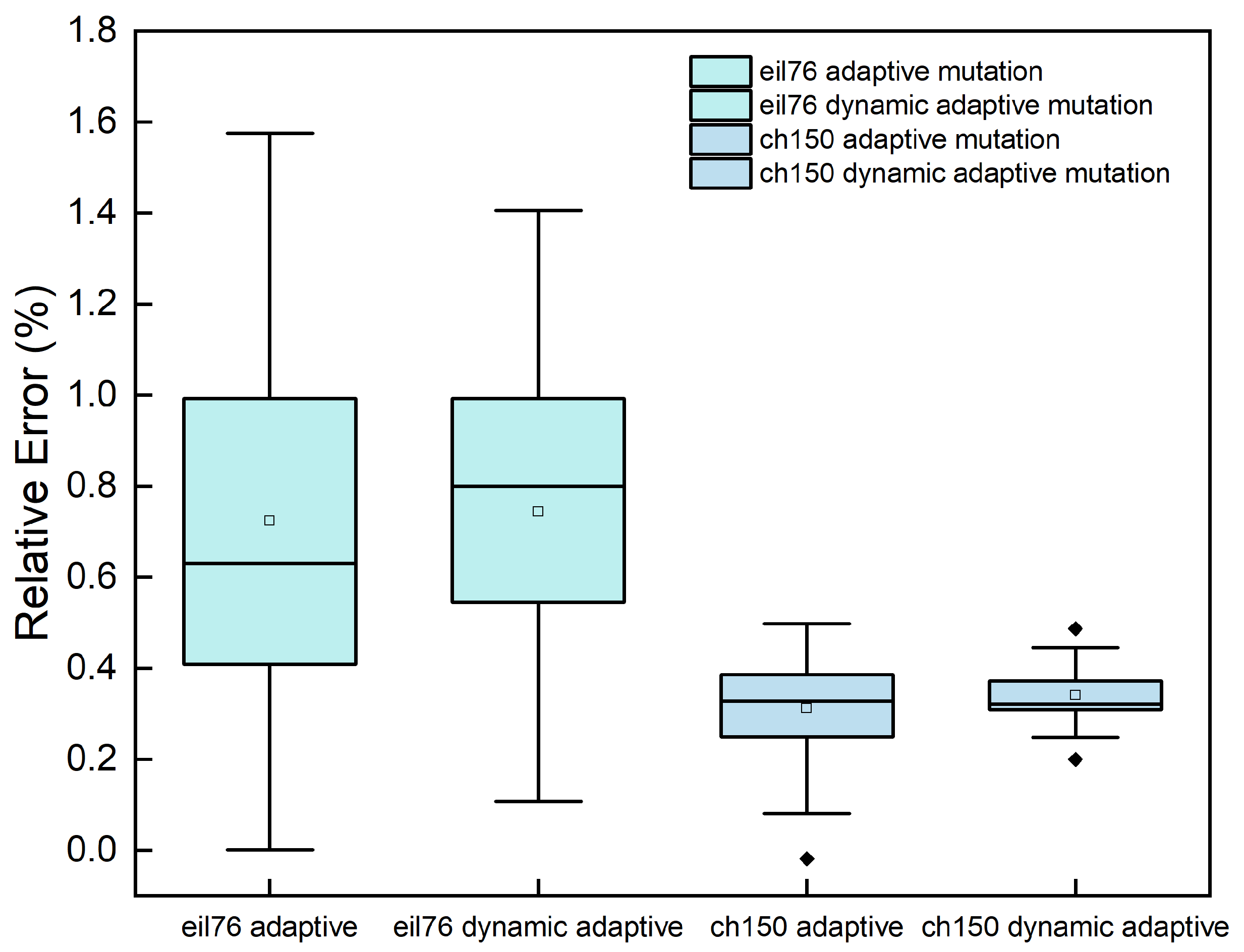
Table 3, the dynamic adaptive neighborhood mutation has a promising advantage over the adaptive neighborhood mutation in terms of mean and RE values, with an advantage in twelve of the fifteen benchmark problems and only a slight disadvantage in eil76 and ch150. Moreover, a box plot of the eil76 and ch150 benchmark problems with the dynamic adaptive neighborhood mutation and the adaptive neighborhood mutation for 25 tests is shown so that the results can be fully analyzed.
From
Figure 10, the results from the dynamic adaptive neighborhood mutation are more concentrated. In contrast, the adaptive neighborhood mutation is less stable and thus presents a smaller final average result than the dynamic adaptive neighborhood mutation. For instance, the average optimal value in ch150 in
Figure 10 is much smaller than the dynamic adaptive neighborhood mutation. However, the middle, upper quartile, and upper edge are larger than the dynamic adaptive neighborhood mutation. Therefore, the dynamic adaptive neighborhood mutation is optimal for the mutation phase due to its stability and efficiency.
5.3. Experiment 3: Comparisons with the DJAYA, DTSA, ABC, PSO-ACO, and DSFLA
The DJAYA [
18], DTSA [
6], ABC [
7], PSO-ACO [
23], and DSFLA [
24] are used to compare with the DGTOA, and the comparison results regarding RE values are shown in
Table 4. The results are taken directly from the related papers for the DJAYA, DTSA, ABC, PSO-ACO, and DSFLA.
As shown in
Table 4, the DGTOA has competitive performance, obtaining optimal solutions for 10 of the 15 benchmark problems, representing 66.77% of all test cases. In terms of the quality of the solutions, DGTOA is obviously superior to the DJAYA, DTSA, and ABC, as well as 6 of 8 (75%) and 7 of 10 (70%) better than PSO-ACO and the DSFLA, respectively (i.e., the DSFLA has the same RE value on the Berlin52 and St70 benchmark problems). The test results show that the ABC, PSO-ACO, DSFLA, and DGTOA perform well at a small scale, but as the scale increases, the performance of the ABC algorithm decreases significantly. Meanwhile, for the tsp225 benchmark problem, the algorithm test result RE value is higher than 5% at a large scale. In addition, PSO-ACO, the DSFLA, and the DGTOA perform similarly on small and medium scales. In contrast, for large-scale kroa200, the DGTOA has a significant advantage over PSO-ACO and the DSFLA. Therefore, the DGTOA has a considered performance in fifteen benchmark problems.
5.4. Experiment 4: Case Study with USV Path Planning
To evaluate the effectiveness of the designed DGTOA in the context of USV path planning, the USV model published in [
43] is used to verify the algorithm’s performance in MATLAB. The control algorithm is derived from the line-of-sight guidance laws described in [
44,
45]. For planning the path, 25 and 50 target waypoints are randomly generated, and then the relevant waypoints are entered into DGTOA. Finally, the optimized paths are provided to the simulated USV for tracking control experiments. The results are shown in
Figure 11a,b, where the blue stars represent the waypoints and the solid red line indicates the USV tracking trajectory with the speed of 1 m/s. The generated paths are of satisfactory lengths, and no paths cross, significantly reducing the time and energy required for USV. Furthermore, the convergence RE plots of the 25 and 50 target waypoints are shown in
Figure 12. When 25 target waypoints are considered, the DGTOA converges to the optimum after only three iterations. Meanwhile, for 50 target waypoints, the DGTOA converges to the optimum in only eight generations. From the two waypoint cases, the DGTOA converges to the optimal solution in 0.47 s and 0.58 s, respectively. In general, the DGTOA has good performance in terms of optimal solution and convergence speed.
6. Conclusions
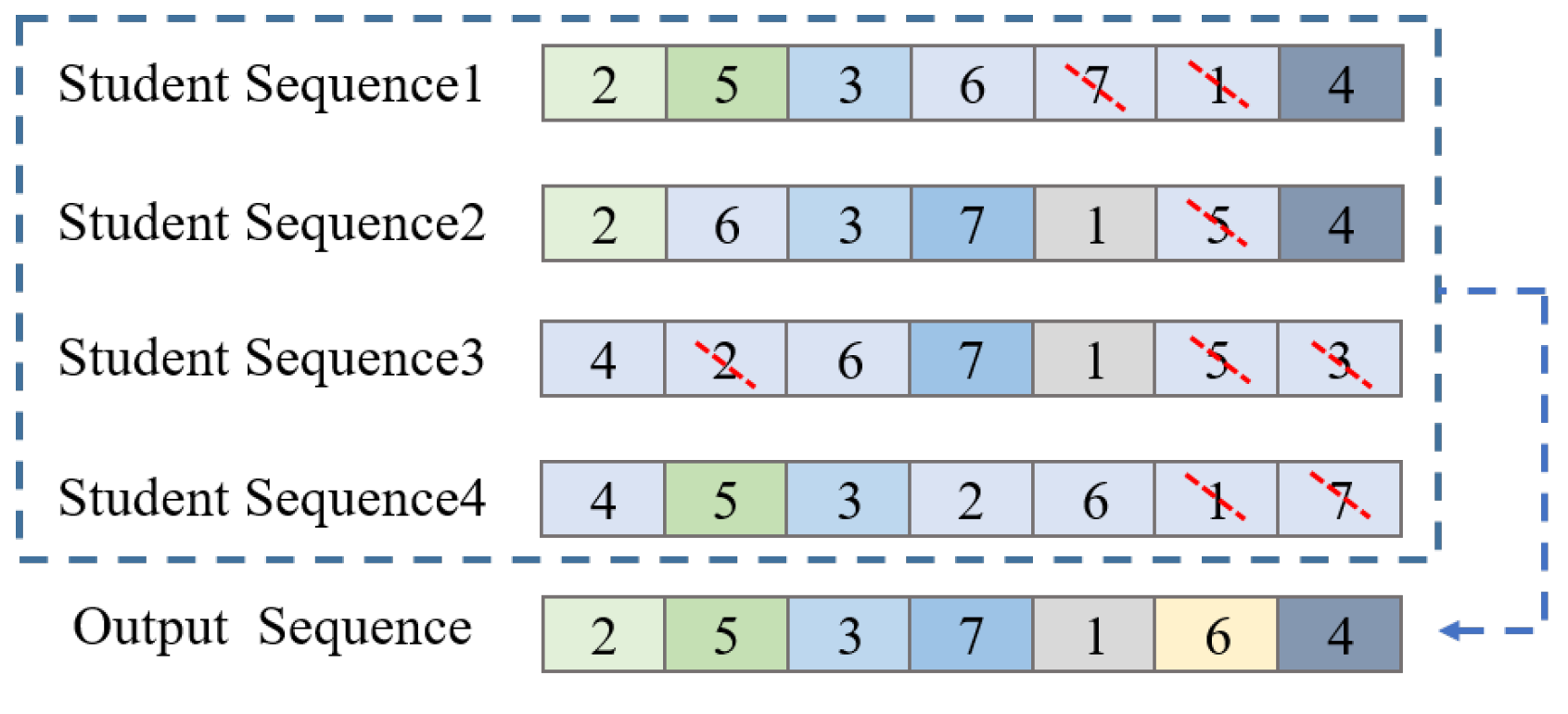
To efficiently solve large-scale waypoint route planning issues, a novel DGTOA method is proposed for USVs. The DGTOA proposes a dynamic adaptive neighborhood radius strategy to balance exploration and exploitation. In the initialization phase, the DGTOA generates initial student sequences using greedy initialization to accelerate the convergence. During the crossover phase, when the new greedy crossover method is used, every student in the group is processed with the shortest sequence and the middle student sequence corresponding to the normal group and the excellent group, respectively. In the mutation phase, the dynamic neighborhood shift mutation algorithm, the dynamic neighborhood inversion mutation algorithm, and the dynamic neighborhood 3-opt mutation algorithm all use the dynamic adaptive neighborhood radius based on triangular probability selection to increase diversity.
In order to verify the effectiveness of the DGTOA, fifteen benchmark problems from TSPLIB are used as benchmarks for testing. In the study, the effects of random initialization, neighborhood initialization, and greedy initialization on the DGTOA are also discussed. In terms of quality and convergence speed, greedy initialization for the DGTOA has an advantage over random initialization and neighborhood initialization. What is more, the dynamic adaptive neighborhood mutation has promising performance relative to the adaptive neighborhood mutation in terms of mean and RE values. In comparison with the DJAYA, DTSA, ABC, PSO-ACO, and DSFLA on 15 benchmark problems from TSPLIB, the DGTOA shows obvious superiority over the DJAYA, DTSA, ABC, and is 75% and 70% better than PSO-ACO and the DSFLA, respectively. Furthermore, the DGTOA has been successfully applied to the path planning for a USV and the results indicate that the DGTOA performs well in terms of optimal solution and convergence speed. Therefore, the proposed DGTOA can provide a competitive advantage in path planning for USVs.
Nevertheless, this study also has some limitations. Firstly, the computation time and results of the algorithm are not optimal, especially as the problem scale increases. Secondly, the DGTOA will be modified to plan routes for multiple unmanned surface vehicles.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}