1. Introduction
Massive maritime operations increase the requirement for improved wave forecasting techniques. Understanding accurate wave conditions allows for more efficient and safer maritime activities and coastal management, for instance, the installation of marine structures, ports and docks, marine transportation and navigation, and shoreline protection, especially to prevent coastal erosion and more [
1,
2]. Furthermore, wave research can further develop ocean wave resources, and the use of wave energy converters can convert wave energy into electrical energy [
3]. Wave prediction data can help to provide motion compensation, which may prevent the crash of cargo in cargo transfer, improve the firing accuracy of ship-borne weapon systems, and performance of the motion control systems [
4]. Significant wave height (SWH) is an effective feature of ocean waves. However, most researchers have only focused on predicting the height of the wave and not on predicting the pair of values of the significant height of the wave and its period, which will make the maritime activities and coastal management more efficient and safer. Therefore, the purpose of this paper is to achieve the efficient prediction of ocean waves by predicting SWH.
Many factors affect wave formation, including air pressure, temperature, wind speed, wind direction, and so on. Over the past few years, several numerical methods have been developed to predict the SWH, such as the Sverdrup, Munk and Bretschneider (SMB), and Pierson–Neumann–James (PNJ) manual-based methods, and the numerical calculation model is based on differential equations [
5]. These methods calculate wave height from the wind information based on wind–wave relationships. However, they need to compute elaborate meteorological and oceanographic data sets and thus involve an enormous amount of computational effort. In addition, due to the uncertainty of the wind–wave relationship, there may be some uncertainty when converting wind energy into wave energy, and the predicted results have not always been very accurate [
6]. The complicated coastal geomorphology, coastal erosion, and structure conditions make wave forecasting very difficult.
Later, artificial intelligence methods based on linear and nonlinear models, or hybrid models were applied to predict the SWH [
7,
8,
9,
10]. The observations based on historical data are often used as the input to predictive models in artificial intelligence. The wind speed is an important parameter for wave prediction. Many scholars had used the wind speed as the input to the prediction model to predict the SWH [
11]. Deo pointed out that providing wave information on certain locations should be carried out based on the sea and/or meteorological measurements in that location, or as near to it as possible [
12]. Mahjoobi used the wind speed as the model input to predict the SWH, which further illustrated that the hysteresis of wind speed can increase the error of the predicted SWH [
13]. Compared with numerical analysis, those methods had achieved good prediction results, and the prediction accuracy had been improved. However, uncertain factors such as wind speed, direction, and wind propagation distance can affect the generation and development of waves; the correlation coefficient of the results between the observed and the predicted data is not always satisfactory. In recent years, many scholars have used the data of past waves as the input of the model to predict the waves at a future moment [
14]. Jain only used the effective wave height as the input of the model when studying local wind, which has a good prediction effect [
15]. Through the above analysis, it can be found that the historical wind and waves contain different information, so the prediction effect is different when used as the input of the model. Using a wind model as an input works well for predicting waves at specific locations. However, due to the hysteresis of wind speed and other unpredictable factors, when we study a local wave using the observed historical wave data—which contain implicitly all the practical factors, such as the air pressure, temperature, local geomorphology, wind speed, and wind direction—as the input of the prediction model, it can have a better prediction effect.
However, accurate SWH prediction requires a large amount of sensor-based data and high-performance computations, so wave height predictions are often not always very accurate [
16,
17,
18]. With the development of machine learning, time series analysis provides computationally alternative solutions mainly based on historical wave height data [
19,
20]. Such modeling approaches have the advantage of being based on previous data and wave patterns, thus avoiding heavy computational resources. Early combinations of wave prediction based on machine learning apply classical time series models, such as the auto-regressive (AR) model, auto-regressive moving average (ARMA) model, and an autoregressive integrated moving average (ARIMA) model [
21,
22,
23]. Soares applied AR models to describe the SWH time series in two Portuguese coast locations. Later, the AR models were further generalized from the application of univariate models of long-term SWH time series to SWH bivariate series and mean periods [
24,
25]. However, predictions based on a single AR model in harsh conditions have poor performance. To further improve the prediction performance, Agrawal applied ARMA and ARIMA models to predict the wave heights for 3, 6, 12, and 24 h of offshore location in India, respectively [
26,
27]. Despite the high efficiency and adaptiveness of classical time series models, the prediction results in severe sea conditions are far from being accurate enough. Since waves are always nonstationary, the linear and stationary classical time series models’ assumptions are not rigorously valid. Consequently, these approaches are not suitable for predicting nonlinear and nonstationary waves.
To address the nonlinear component of ocean waves, intelligent-technique-based nonlinear models such as artificial neural networks (ANNs) models have been extensively studied. Such methods can carry out nonlinear simulations without a deep understanding of the relationships between the input and output variables. Deo and Sridhar Naidu were amongst the first to apply an ANN to predict, in real-time, the wave in the next 3–24 h using past wave data [
28]. To estimate the large wave height and average wave periods, Deo used wind velocity and fetched data [
12]. Tsai applied an ANN-based on data from three wave graph stations in areas with different physical characteristics for short-term estimation of the wave height [
29]. Makarynskyy used ANN for substantial wave height prediction and for the subsequent 1–24 h forecast times [
30]. Mandal and Prabaharan used a recurrent neural network (RNN) for wave height prediction in Marmugao, west coast of India [
31]. They showed that the wave prediction using RNN provides better results than the other neural network-based methods. One of the limitations of the neural network approach is that it needs to find network parameters such as the number of hidden layers and neurons by trial and error, which is time-consuming. Mahjoobi and Adeli Mosabbeb applied support vector machine (SVM) to predict the wave height; the analysis showed that the SVM model had a reasonable precision compared to ANN-based methods, which took less computation time [
32]. Different experiments on the prediction performance in Lake Superior were carried out by Etemad-Shahidi and Mahjoobi, and they compared the model trees and feedforward backpropagation ANNs [
13]. Their findings revealed that the model tree system was the most precise. Dixit found the phenomenon of prediction time lag while using ANNs to predict the ocean wave height. They used a discrete wavelet transform to enhance the predicted values and to remove the lag in the prediction timing [
33]. Akbarifard and Radmanesh introduced a symbiotic organisms search (SOS) to predict the ocean wave heights. Their findings showed that the SOS algorithm performed better than that of the support vector regression (SVR), ANN [
34]. Fan proposed a long short-term network for the quick prediction of the SWH with higher accuracy than the convolutional neural network (CNN) [
35].
SWH is impacted by various components in a nonlinear, dynamic way [
36]. The time series prediction of non-stationary data by ANN methods can lead to the homogenization of the different characteristics of the original input data, which can affect the prediction accuracy. Accordingly, the non-stationarity of the time series of the SWH and input variables should be reduced. To handle the nonstationary features, the inputs of the corresponding data-driven models should be appropriately preprocessed. Hybrid models combining preprocessing techniques with single prediction models are possible alternatives. The wavelet analysis can be used for nonstationary data [
37]. Deka and Prahlada developed a wavelet neural network model by hybridizing ANN with a wavelet transform, and the prediction results suggested that the hybrid models outperformed single models [
38]. Kaloop designed the wavelet-PSO–ELM (WPSO–ELM) model for estimating the wave height belonging to coastal and deep-sea stations. The results showed that the WPSO–ELM outperforms other models for wave height prediction in both hourly and daily leading times [
39]. Essentially, a linear and nonstationary solution is based on wavelet transform. It represents a signal through a linear combination of functions of the wavelet base. For nonlinear data, it may not be suitable [
40]. The other issue with wavelets is that they require a well-suited mother wavelet transform a priori [
41]. This is still an unresolved issue and generally requires a lengthy trial and error process [
42]. In hybrid prediction models, a more effective decomposition technique is needed to overcome the nonlinearity and non-stationarity instantaneously.
When considering nonlinear and nonstationary data sets, a data-driven methodology known as empirical mode decomposition (EMD) is efficient and adaptive [
43]. The EMD multiresolution utility offers self-adaptability by avoiding the need for any basis function and mother wavelets. It functions as a dyadic filter that divides a large frequency band complex signal into relatively essential, time-scale components [
44]. Duan proposed EMD–SVR for the short-term prediction of ocean waves. The result showed the EMD–SVR model shows good model performance and provides an effective method for the short-term prediction of nonlinear and nonstationary waves [
44].
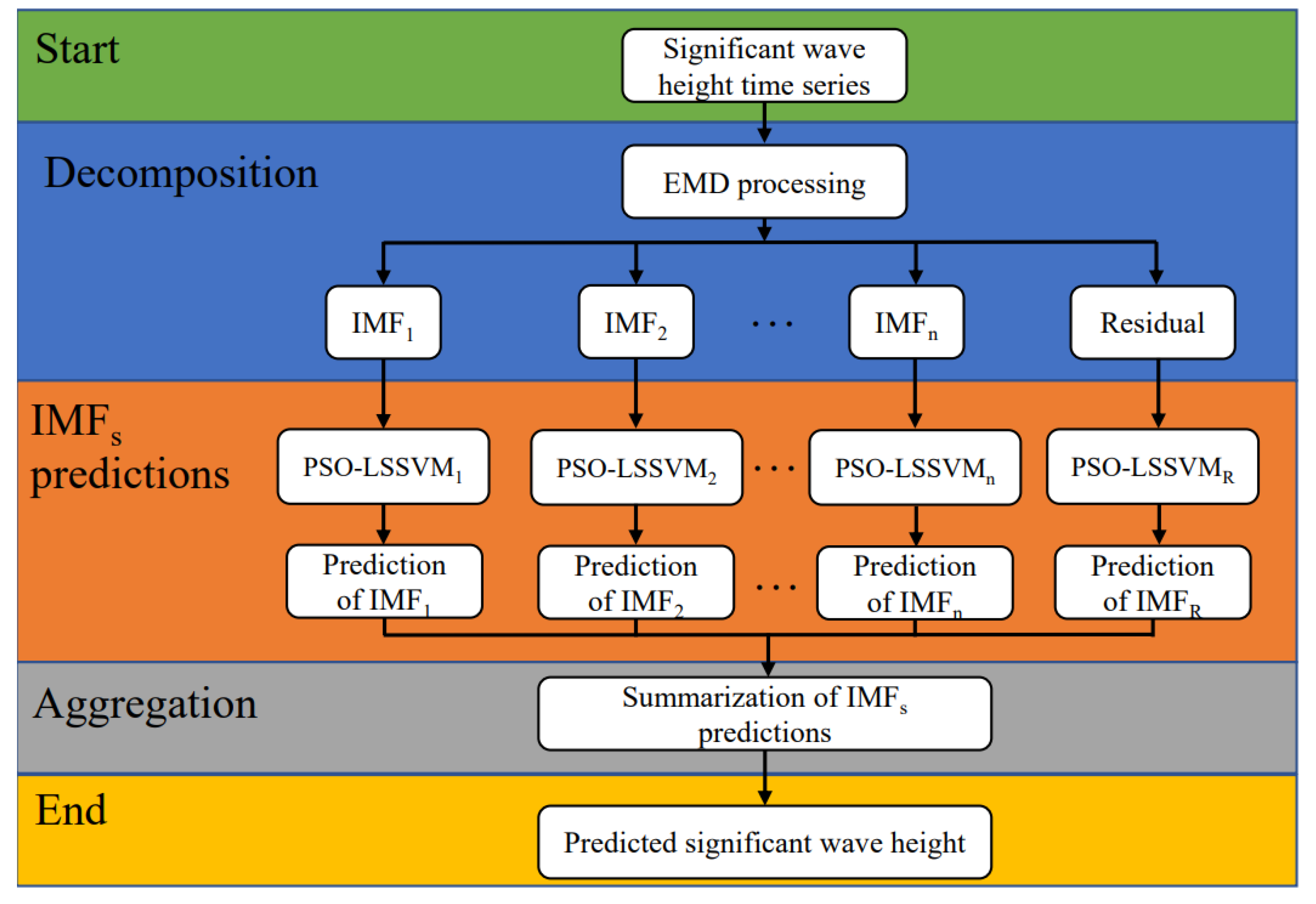
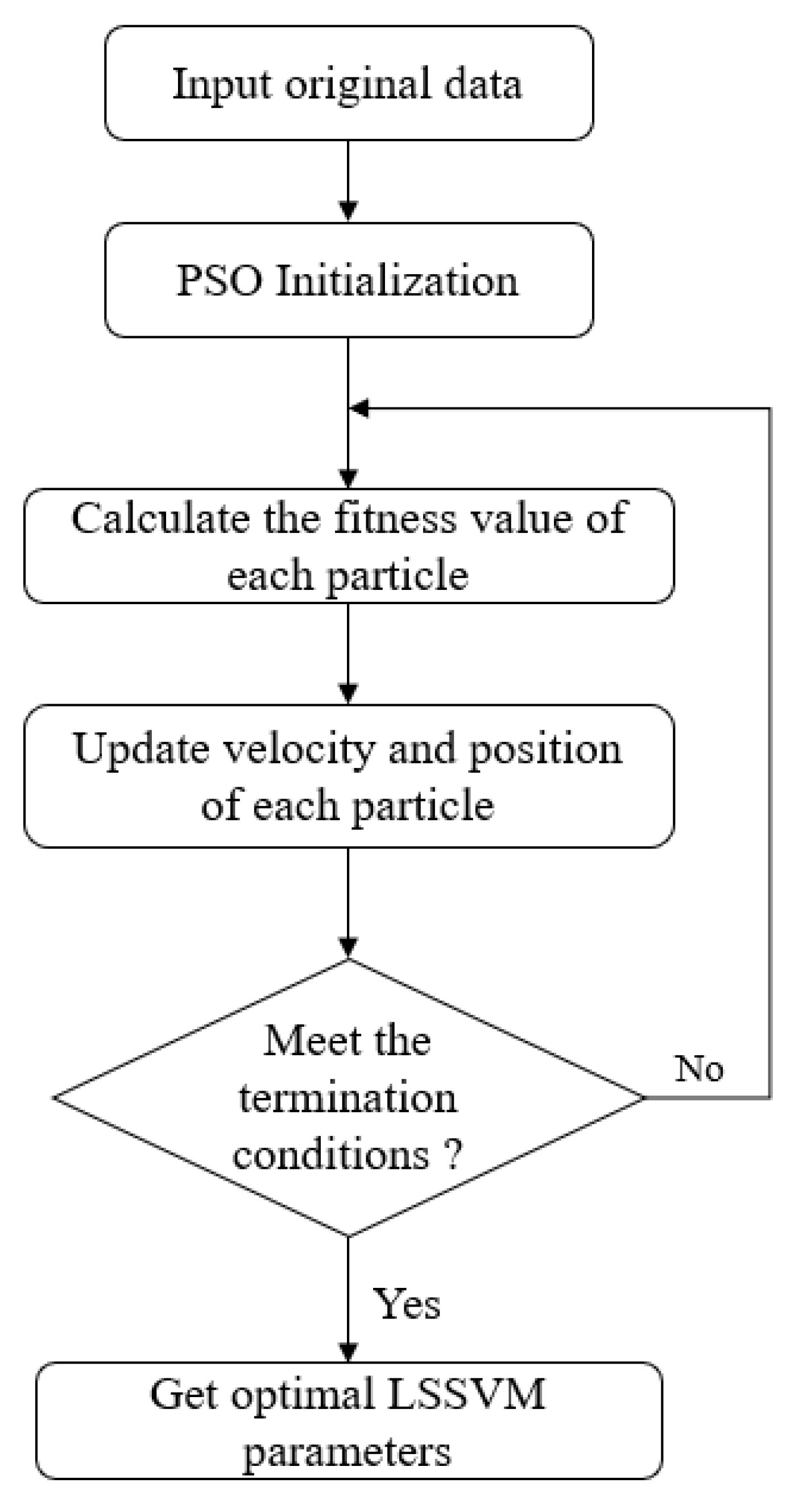
Based on the above analysis, we introduce an EMD and particle swarm optimization (PSO) and least-squares SVM (LSSVM) based model whose objective is to improve the SWH prediction performance. The LSSVM with nonlinear learning ability can be used for signal prediction, while EMD provides an empirical analysis tool for processing nonlinear and nonstationary data sets. Preprocessing with EMD can reduce the prediction complexity; PSO is a swarm intelligence optimization algorithm, and by updating the distance between the current and best locations, the important parameters of LSSVM are optimally adjusted by PSO to improve the prediction accuracy of a single LSSVM.
The remainder of this paper Is organized as follows. The proposed EMD–PSO–LSSVM-based prediction model is described in
Section 2. The wave data and prediction measures are presented in
Section 3. The performance of the proposed method is assessed in
Section 4. Finally, the conclusion is highlighted in
Section 5.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}