2.2. The Detail Steps of the Proposed Method
Step 1: Use VMD to decompose the original wind speed sequence.
In this step, the VMD algorithm is used to decompose the original wind speed time series [
28], which can extract potential patterns and remove noise from the original data, and obtain multiple components with fixed center frequencies. By this means, more wind speed features will be obtained, which is beneficial for improving prediction accuracy [
7].
The VMD algorithm was proposed by Konstantin Dragomiretskiy and Dominique Zosso in 2014 [
29]. Because it can effectively overcome problems, such as the dependence of Empirical Mode Decomposition (EMD) on extreme point selection and frequency overlap, the VMD has attracted increasing attention from researchers [
30].
The VMD can decompose the wind speed time series into several IMF. Its expression is
where
is the non-negative envelope,
is the phase and
,
is the raw wind speed data decomposed to the
k-th IMF.
The corresponding constrained variational model is as
where
is the set of all modes,
is the set of center frequencies of all modes and
f is the raw wind speed data.
To solve the constrained optimization problem Equation (
2), the augmented Lagrangian function is used to convert the above equation constraint problem to an unconstrained problem
where
is the penalty parameter, ∗ represents convolution operation, and
is the Lagrangian multiplier.
Then, the Alternate Direction Method of Multipliers (ADMM) is used to update
, and
Step 2: Use the ARMA model to select the optimal number of inputs.
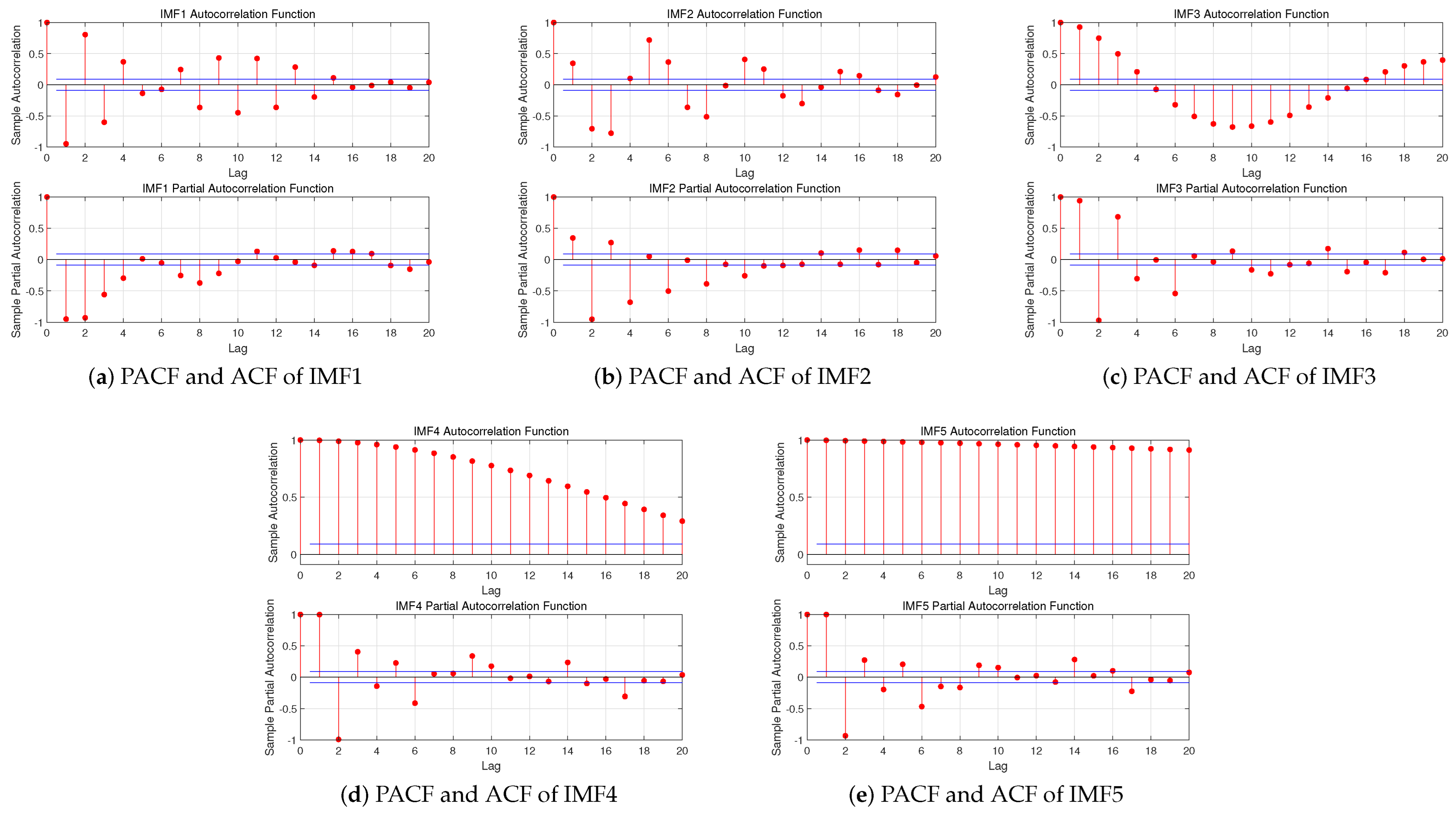
In the Step 2, we use training sets to establish ARMA model to find the optimal number of inputs. The training sets are the multiple IMF decomposed through VMD in Step 1, and then an ARMA (p, q) model is established for each IMF. Since the fact that the decomposed data belongs to a relatively stable sequence, there is no need for stationarity test and an ARMA model can be directly established. For each p and q in ARMA (p, q), we set a loop and use the Akaike Information Criterion (AIC) to find the optimal combination of (p, q). The resulting p-value is the optimal number of inputs we are looking for. It is worth noting that the optimal p-value corresponding to each IMF may be different. Thus, in the final summation, the same length needs to be selected for addition, which will be explained in detail later.
The ARMA (
p,
q) model is one of the earliest models used for time series prediction [
31]. It consists of two models, the Autoregressive (AR) model and Moving Average (MA) model. The mathematical model is
where
is wind speed time series,
is the current wind speed,
and
are the autoregressive and moving average parameter,
p and
q are important parameter called Partial Autocorrelation Coefficient (PAC) and Autocorrelation Coefficient (AC) and
is white nose of time
t.
The ARMA model describes the relationship between current value, historical error, and historical value. From Equation (
7), one can see that the current value
is composed of a linear combination of
p historical values and
q historical errors. It also means that if every
p datum is taken as a group, the internal correlation of this group is very strong. Thus, it is very reasonable to select
p as the basis for dividing the univariate series.
Step 3: Use the p-value to partition data sequence.
In Step 2, the optimal p-values of each IMF was obtained. In this step, we will use them to partition data for each IMF. The specific method is that, for each IMF, starting from the first data, every
p datum is a group, the first
p−1 data are used as input, and the pth data are output. That is, the first
p−1 data are used to predict the
pth value. Then, starting from the second set of data, the previous steps are repeated until all the data are divided. This process can be described as Equation (
8)
where
represents the wind speed value at time
t and
represents the relationship between historical and current value.
Step 4: Use the BLS model to predict each IMF.
In this step, the divided data in Step 3 are used to train the BLS model. For each IMF, triple nested loops are used to find the optimal number of mapping nodes, windows in mapping feature layers, and enhancement nodes. The first 75% of the dataset is used as the training set, and the rest is used as the testing set. The result will be shown in the following section.
Compared with the deep learning system, BLS has a faster training process, and can increase the number of feature nodes and enhancement nodes through incremental learning. Therefore, the system can continuously update parameters without retraining, which is an alternative to deep learning [
32].
The basic structure of BLS model is shown in
Figure 2. It is based on the Random Vector Functional Link Neural Network (RVFLNN), which maps the input to the mapping layer through multiple sets of mappings. The mapping is
in
Figure 2, where
is the wind speed IMF decomposed by the VMD algorithm.
and
are respectively the random weights and bias with the proper dimensions. Each mapping corresponds to a mapping feature:
. The nodes in the mapping feature are called mapping nodes. Each mapping feature is passed to the output layer and the enhancement layer, respectively. In the process of passing from the mapping layer to the enhancement layer, there will also be a layer of mapping, which is
in
Figure 2, where
and
are the random weights and bias with the proper dimensions, respectively. The nodes in the enhancement layer are called enhancement nodes:
. Enhancement nodes and mapping nodes are finally connected to the output layer.
If one wants to train a model and the input
and labels Y are known, one can figure out
w in
Figure 2 by the equation
where
is the augmented matrix of the mapping layer matrix and enhancement layer matrix, that is,
.
Z and
H can be figured out by
. Then, the
w can be calculated as
where
is the pseudo-inverse matrix of
.
From Equations (
9) and (
10) we know that, the BLS inputs all the data into the system for training. There is no weight update process, and the weights are directly calculated, while deep learning needs to pass the data into the neural network one by one to update the weights continuously. Therefore, the training speed of BLS is significantly faster than that of deep learning.
In order to solve the problem that the model training cannot achieve the required accuracy, the author also proposed the BLS with incremental learning, including increasing the number of mapping nodes and enhancing nodes, and increasing the input data. In this paper, the incremental learning is used to find the best number of mapping nodes and enhancing nodes, which can improve the prediction accuracy.
Step 5: Add up prediction results of each IMF.
The predictions for each IMF using BLS model in Step 4 are not the true wind speed, we need to add all the predictions to obtain the wind speed prediction
where
is the wind speed prediction result, and
is the prediction result of each IMF.
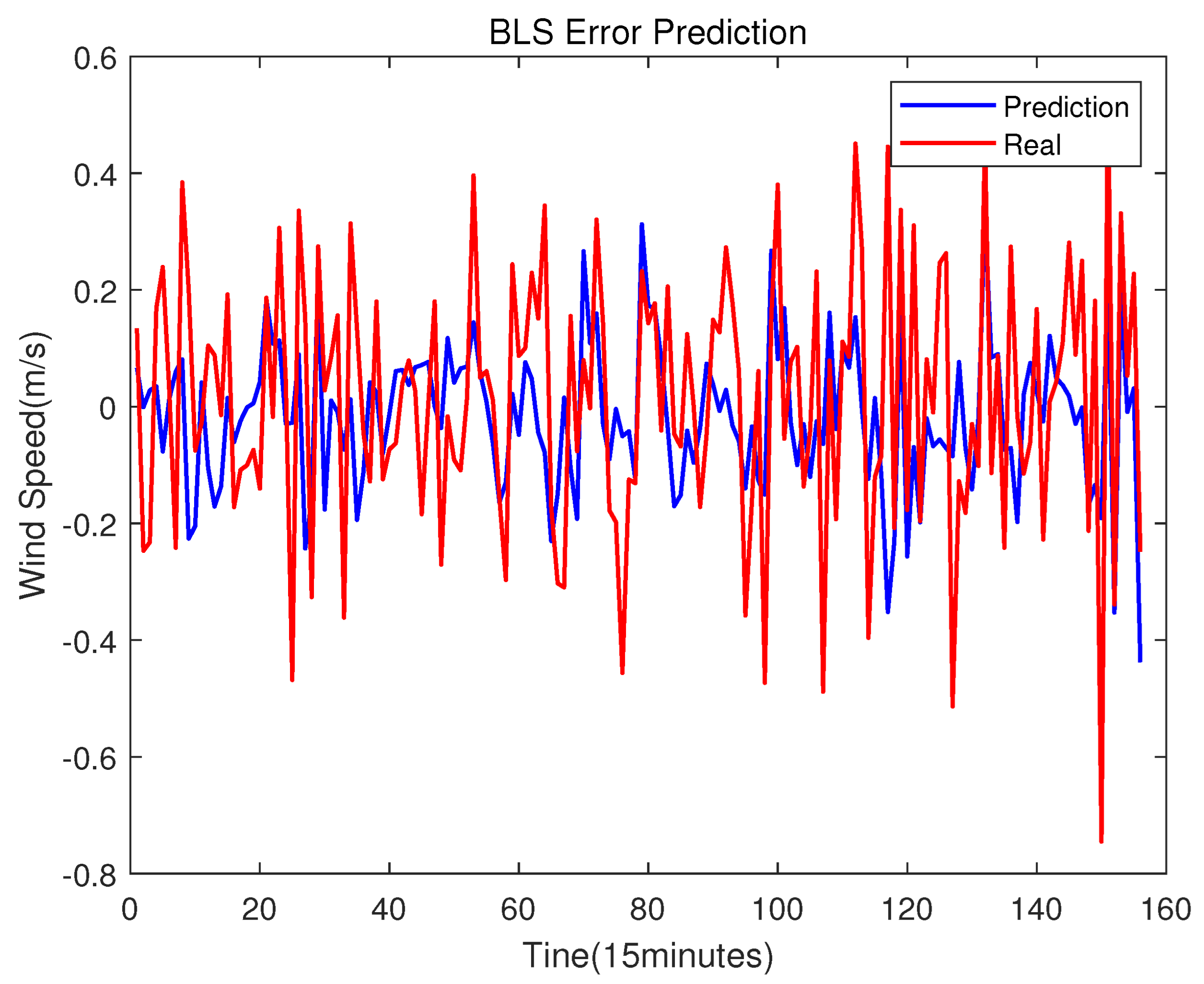
Step 6: Get the prediction error of wind speed.
The error time series can also be predicted due to its non-linear characteristics [
33]. If the predicted error can be added to the predicted wind speed, a more accurate prediction result can be obtained. In Step 4, the training model is obtained. In Step 5, we obtain the prediction result of the testing set. Furthermore, in this step, we subtract the predicted value from the real value of the testing set to obtain the error testing set. Specially, to construct the error training set, the training set is used as the input of the BLS model trained in Step 4 to obtain the prediction result of the training set, and then the error training set can be obtained by subtracting the predicted value from the real value of the training set
where
and
represent error training set and error testing set,
and
represent the real value of training and testing set, and
and
are the prediction value of training and testing set, respectively.
Step 7: Build the ARMA model for error set and partition error set.
This step is very similar to Step 2 and Step 3. The error set obtained in Step 6 is also a univariate time series. Since its fluctuation is very small, there is no need to perform VMD like the original data. The ARMA model is used to select the optimal number of inputs
p for the error set, and its p-value is used to divide the error training set and testing set. The way of division is the same as in Step 3, and only the value of
p may be different
where
represents the error value at time t and
represents the relationship between historical and current error.
Step 8: Use the BLS model to predict error.
In this step, divided data in Step 7 are used to retrain the BLS model. For error training set, triple nested loops are used to find the optimal number of mapping nodes, windows in mapping feature layers and enhancement nodes. After that, the error testing set is used to check the prediction effect of the model. The result will be shown in the following section.
Step 9: Add the wind speed prediction result to the error prediction result.
This is the final step. The final wind speed prediction result will be obtained by adding the wind speed prediction result to the error prediction result
where
is the final wind speed prediction result, and
is the prediction result of error.


 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}