


MDNet: A Fusion Generative Adversarial Network for Underwater Image Enhancement


 and
and 
Abstract
:1. Introduction
2. Related Work
2.1. Physical Model-Based Method
2.2. Non-Physical Model-Based Method
2.3. Deep Learning Method
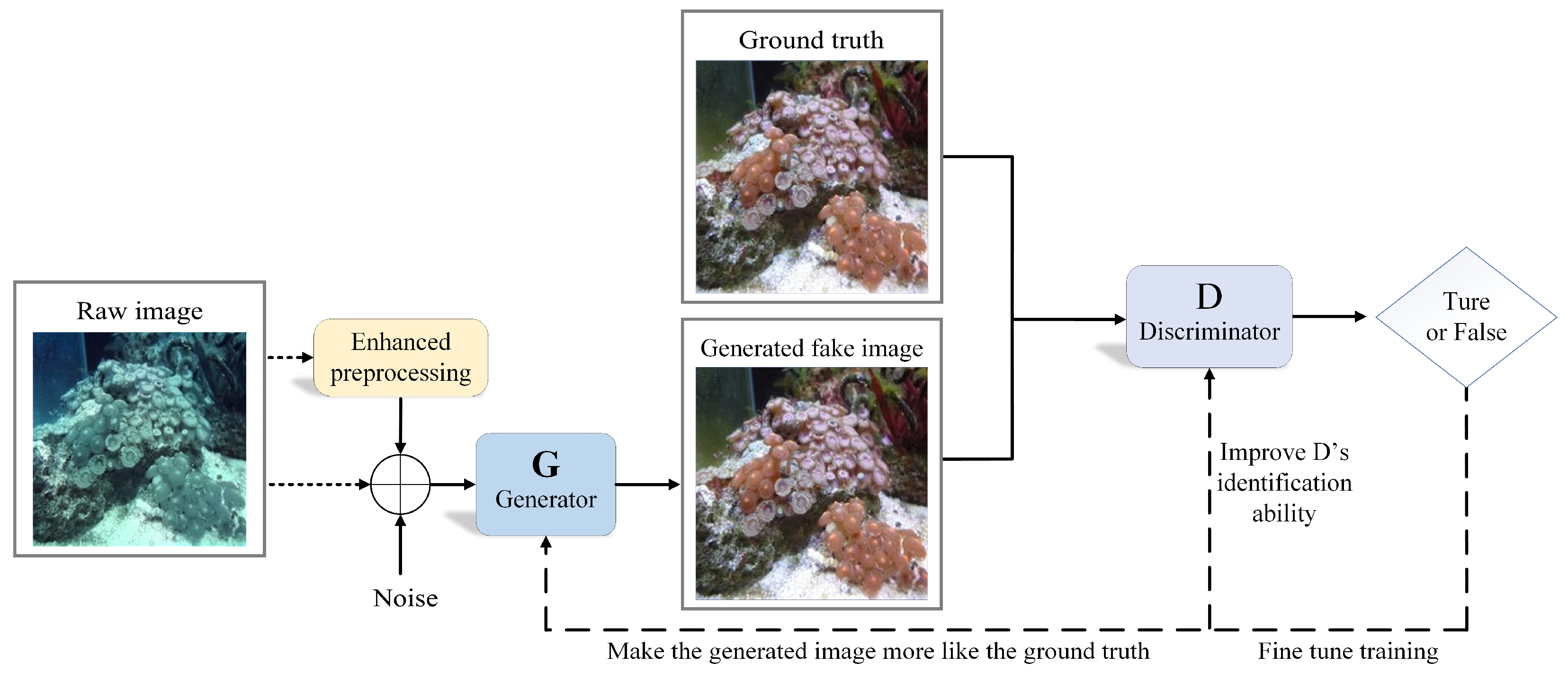
3. The Proposed Method
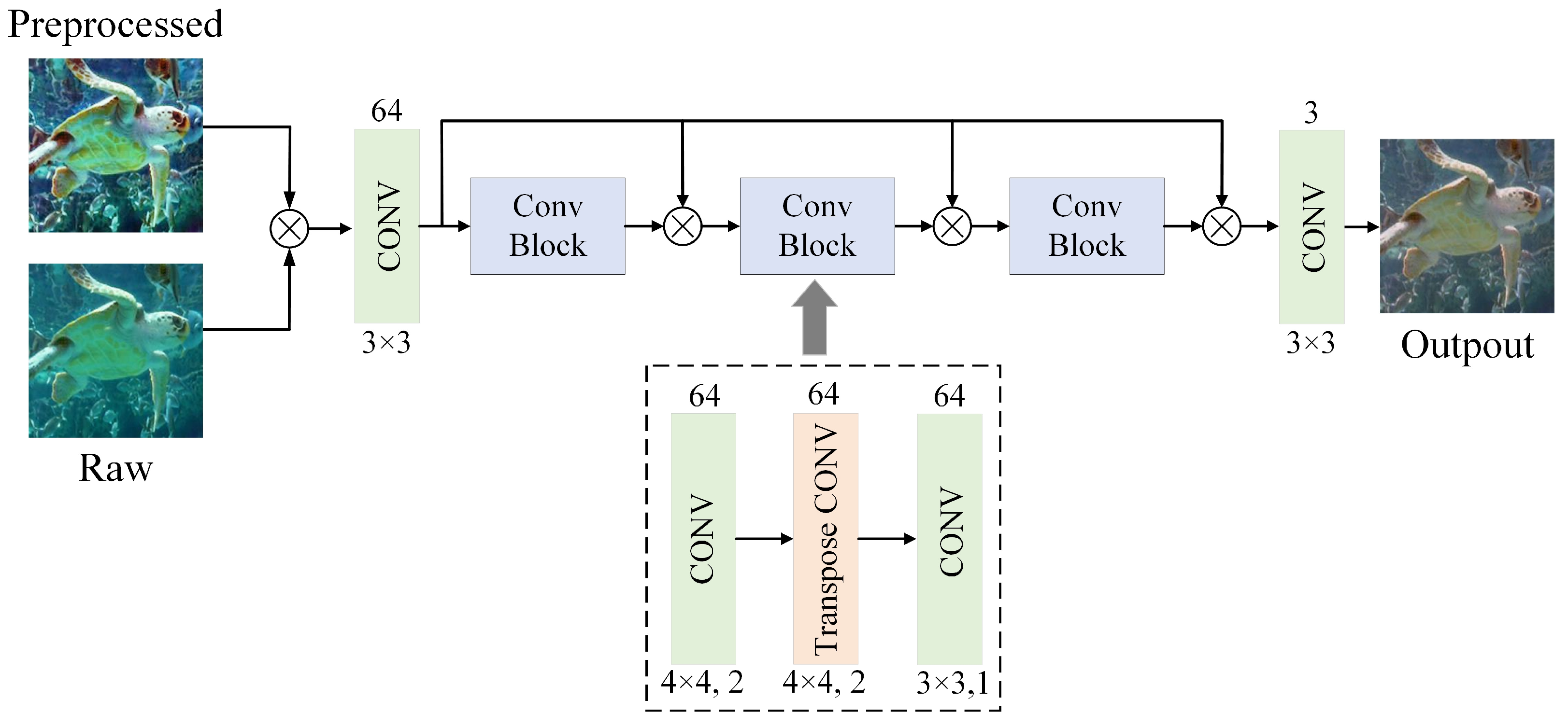
3.1. Model Structure
3.1.1. The Generator
3.1.2. The Discriminator
3.2. Loss Function
4. Results and Discussion
4.1. Datasets
4.2. Implementation Details
4.3. Qualitative Evaluation
4.4. Quantitative Evaluation
4.5. Analysis of Results
4.6. Application Tests
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bingham, B.; Foley, B.; Singh, H.; Camilli, R.; Delaporta, K.; Eustice, R.; Mallios, A.; Mindell, D.; Roman, C.; Sakellariou, D. Robotic tools for deep water archaeology: Surveying an ancient shipwreck with an autonomous underwater vehicle. J. Field Robot. 2010, 27, 702–717. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Ta, X.; Xiao, R.; Wei, Y.; An, D.; Li, D. Survey of underwater robot positioning navigation. Appl. Ocean Res. 2019, 90, 101845. [Google Scholar] [CrossRef]
- Lu, H.; Li, Y.; Serikawa, S. Underwater image enhancement using guided trigonometric bilateral filter and fast automatic color correction. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 3412–3416. [Google Scholar]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Fu, X.; Fan, Z.; Ling, M.; Huang, Y.; Ding, X. Two-step approach for single underwater image enhancement. In Proceedings of the 2017 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Xiamen, China, 6–9 November 2017; pp. 789–794. [Google Scholar]
- Huang, D.; Wang, Y.; Song, W.; Sequeira, J.; Mavromatis, S. Shallow-water image enhancement using relative global histogram stretching based on adaptive parameter acquisition. In Proceedings of the International Conference on Multimedia Modeling, Bangkok, Thailand, 5–7 February 2018; pp. 453–465. [Google Scholar]
- Xiong, J.; Dai, Y.; Zhuang, P. Underwater Image Enhancement by Gaussian Curvature Filter. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; pp. 1026–1030. [Google Scholar]
- Drews, P.L.; Nascimento, E.R.; Botelho, S.S.; Campos, M.F.M. Underwater depth estimation and image restoration based on single images. IEEE Comput. Graph. Appl. 2016, 36, 24–35. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [Green Version]
- Naik, A.; Swarnakar, A.; Mittal, K. Shallow-uwnet: Compressed model for underwater image enhancement (student abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2021; pp. 15853–15854. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Bekaert, P. Color balance and fusion for underwater image enhancement. IEEE Trans. Image Process. 2017, 27, 379–393. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Li, J.; Wang, W. A fusion adversarial underwater image enhancement network with a public test dataset. arXiv 2019, arXiv:1906.06819. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Chao, L.; Wang, M. Removal of water scattering. In Proceedings of the 2010 2nd International Conference on Computer Engineering and Technology, Chengdu, China, 16–18 April 2010; pp. V2-35–V32-39. [Google Scholar]
- Chiang, J.Y.; Chen, Y.-C. Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. 2011, 21, 1756–1769. [Google Scholar] [CrossRef]
- Carlevaris-Bianco, N.; Mohan, A.; Eustice, R.M. Initial results in underwater single image dehazing. In Proceedings of the Oceans 2010 Mts/IEEE Seattle, Seattle, WA, USA, 20–23 September 2010; pp. 1–8. [Google Scholar]
- Wang, Y.; Liu, H.; Chau, L.-P. Single underwater image restoration using adaptive attenuation-curve prior. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 65, 992–1002. [Google Scholar] [CrossRef]
- Akkaynak, D.; Treibitz, T. Sea-thru: A method for removing water from underwater images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1682–1691. [Google Scholar]
- Muniraj, M.; Dhandapani, V. Underwater image enhancement by combining color constancy and dehazing based on depth estimation. Neurocomputing 2021, 460, 211–230. [Google Scholar] [CrossRef]
- Raveendran, S.; Patil, M.D.; Birajdar, G.K. Underwater image enhancement: A comprehensive review, recent trends, challenges and applications. Artif. Intell. Rev. 2021, 54, 5413–5467. [Google Scholar] [CrossRef]
- Liu, Y.-C.; Chan, W.-H.; Chen, Y.-Q. Automatic white balance for digital still camera. IEEE Trans. Consum. Electron. 1995, 41, 460–466. [Google Scholar]
- Iqbal, K.; Odetayo, M.; James, A.; Salam, R.A.; Talib, A.Z.H. Enhancing the low quality images using unsupervised colour correction method. In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1703–1709. [Google Scholar]
- Ghani, A.S.A.; Isa, N.A.M. Underwater image quality enhancement through integrated color model with Rayleigh distribution. Appl. Soft Comput. 2015, 27, 219–230. [Google Scholar] [CrossRef]
- Ghani, A.S.A.; Isa, N.A.M. Enhancement of low quality underwater image through integrated global and local contrast correction. Appl. Soft Comput. 2015, 37, 332–344. [Google Scholar] [CrossRef]
- Buchsbaum, G. A spatial processor model for object colour perception. J. Frankl. Inst. 1980, 310, 1–26. [Google Scholar] [CrossRef]
- Wong, S.-L.; Paramesran, R.; Taguchi, A. Underwater image enhancement by adaptive gray world and differential gray-levels histogram equalization. Adv. Electr. Comput. Eng. 2018, 18, 109–116. [Google Scholar] [CrossRef]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.-P.; Ding, X. A retinex-based enhancing approach for single underwater image. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4572–4576. [Google Scholar]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Guo, Y.; Li, H.; Zhuang, P. Underwater image enhancement using a multiscale dense generative adversarial network. IEEE J. Ocean. Eng. 2019, 45, 862–870. [Google Scholar] [CrossRef]
- Liu, X.; Gao, Z.; Chen, B.M. IPMGAN: Integrating physical model and generative adversarial network for underwater image enhancement. Neurocomputing 2021, 453, 538–551. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Yu, X.; Qu, Y.; Hong, M. Underwater-GAN: Underwater image restoration via conditional generative adversarial network. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 66–75. [Google Scholar]
- Ignatov, A.; Kobyshev, N.; Timofte, R.; Vanhoey, K.; Van Gool, L. Dslr-quality photos on mobile devices with deep convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3277–3285. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Akkaynak, D.; Treibitz, T.; Shlesinger, T.; Loya, Y.; Tamir, R.; Iluz, D. What is the space of attenuation coefficients in underwater computer vision? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4931–4940. [Google Scholar]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Cheng, M.-M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.-M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PSNR↑ | SSIM↑ | UIQM↑ |
|---|---|---|---|
| CLAHE [4] | 20.84 ± 3.59 | 0.85 ± 0.08 | 2.94 ± 0.57 |
| RGHS [6] | 23.24 ± 5.51 | 0.83 ± 0.10 | 2.55 ± 0.70 |
| GCF [7] | 20.43 ± 4.22 | 0.82 ± 0.09 | 3.16 ± 0.43 |
| UDCP2016 [8] | 15.65 ± 3.93 | 0.68 ± 0.12 | 2.15 ± 0.64 |
| FUnIE-GAN [9] | 20.29 ± 3.12 | 0.79 ± 0.06 | 3.08 ± 0.29 |
| WaterNet [10] | 19.52 ± 4.00 | 0.82 ± 0.10 | 2.98 ± 0.39 |
| Shallow-Uwnet [11] | 20.78 ± 5.13 | 0.81 ± 0.10 | 2.84 ± 0.52 |
| MDNet- | 20.67 ± 4.39 | 0.78 ± 0.09 | 2.91 ± 0.43 |
| MDNet | 22.27 ± 3.51 | 0.82 ± 0.06 | 3.09 ± 0.34 |
| Methods | PSNR↑ | SSIM↑ | UIQM↑ |
|---|---|---|---|
| CLAHE [4] | 18.72 ± 1.97 | 0.66 ± 0.08 | 2.92 ± 0.35 |
| Two-step [5] | 18.50 ± 2.77 | 0.65 ± 0.10 | 3.04 ± 0.25 |
| RGHS [6] | 22.56 ± 2.89 | 0.69 ± 0.07 | 2.30 ± 0.41 |
| GCF [7] | 18.18 ± 4.00 | 0.66 ± 0.18 | 3.42 ± 0.27 |
| UDCP2016 [8] | 19.32 ± 4.42 | 0.64 ± 0.09 | 2.20 ± 0.45 |
| FUnIE-GAN [9] | 23.00 ± 2.20 | 0.75 ± 0.07 | 3.14 ± 0.31 |
| WaterNet [10] | 19.89 ± 4.59 | 0.74 ± 0.08 | 2.89 ± 0.42 |
| Shallow-Uwnet [11] | 24.86 ± 2.68 | 0.79 ± 0.07 | 3.08 ± 0.34 |
| MDNet- | 23.04 ± 2.54 | 0.75 ± 0.08 | 3.19 ± 0.30 |
| MDNet | 23.47 ± 2.46 | 0.76 ± 0.08 | 3.21 ± 0.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Zhao, S.; An, D.; Li, D.; Zhao, R. MDNet: A Fusion Generative Adversarial Network for Underwater Image Enhancement. J. Mar. Sci. Eng. 2023, 11, 1183. https://doi.org/10.3390/jmse11061183
Zhang S, Zhao S, An D, Li D, Zhao R. MDNet: A Fusion Generative Adversarial Network for Underwater Image Enhancement. Journal of Marine Science and Engineering. 2023; 11(6):1183. https://doi.org/10.3390/jmse11061183
Chicago/Turabian StyleZhang, Song, Shili Zhao, Dong An, Daoliang Li, and Ran Zhao. 2023. "MDNet: A Fusion Generative Adversarial Network for Underwater Image Enhancement" Journal of Marine Science and Engineering 11, no. 6: 1183. https://doi.org/10.3390/jmse11061183
APA StyleZhang, S., Zhao, S., An, D., Li, D., & Zhao, R. (2023). MDNet: A Fusion Generative Adversarial Network for Underwater Image Enhancement. Journal of Marine Science and Engineering, 11(6), 1183. https://doi.org/10.3390/jmse11061183