



Underwater Object Detection in Marine Ranching Based on Improved YOLOv8


Abstract
:1. Introduction
- (1)
- Aiming at the characteristics of underwater image features that are not obvious, the backbone network of YOLOv8 was improved by using the InceptionNeXt block, which enhanced its ability to extract image features while maintaining its lightweight advantage.
- (2)
- For the characteristics of underwater images with more overlapping targets, the SEAM attention mechanism was added to the neck, and experimental comparisons were made with two other classical attention mechanisms, which proved that the SEAM was the most effective.
- (3)
- In view of the characteristics of underwater images containing more small targets, NWD loss was added on the basis of the original CIoU loss, and the most suitable ratio of the two functions was found through experiments, which improved the accuracy of small targets detections without causing a loss of detection accuracy for medium and large targets.
- (4)
- In response to the insufficient number of underwater datasets, data from three parts were used to form the final dataset that was used. The dataset was augmented with a combination of Mosaic and MixUp to create the training set during the training process, which improved the generalization ability of the model and avoided the overfitting of the model.
2. Materials and Methods
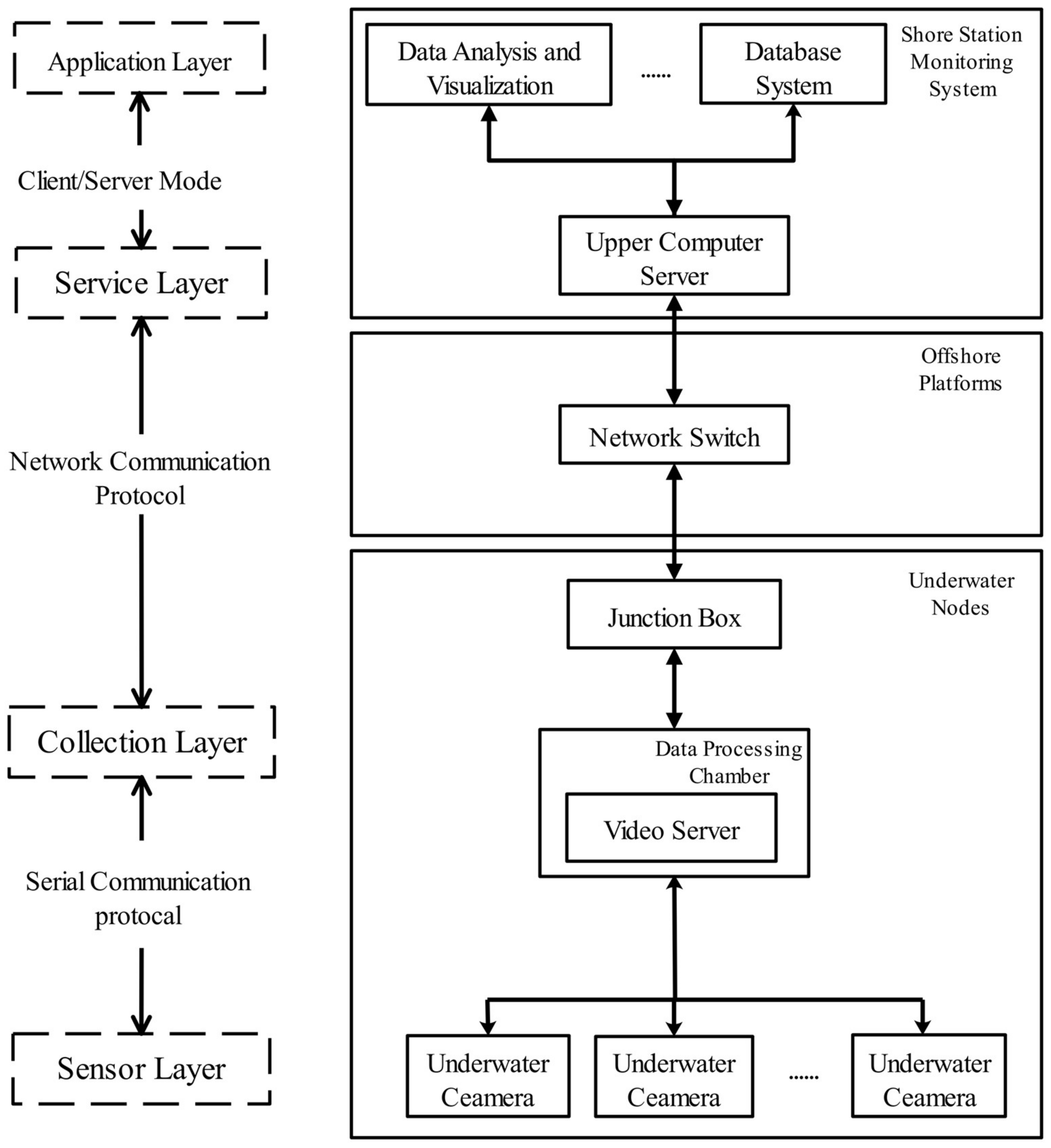
2.1. Design of the Seafloor Video System
2.1.1. General Structural Design
2.1.2. Design of the Video Monitoring System
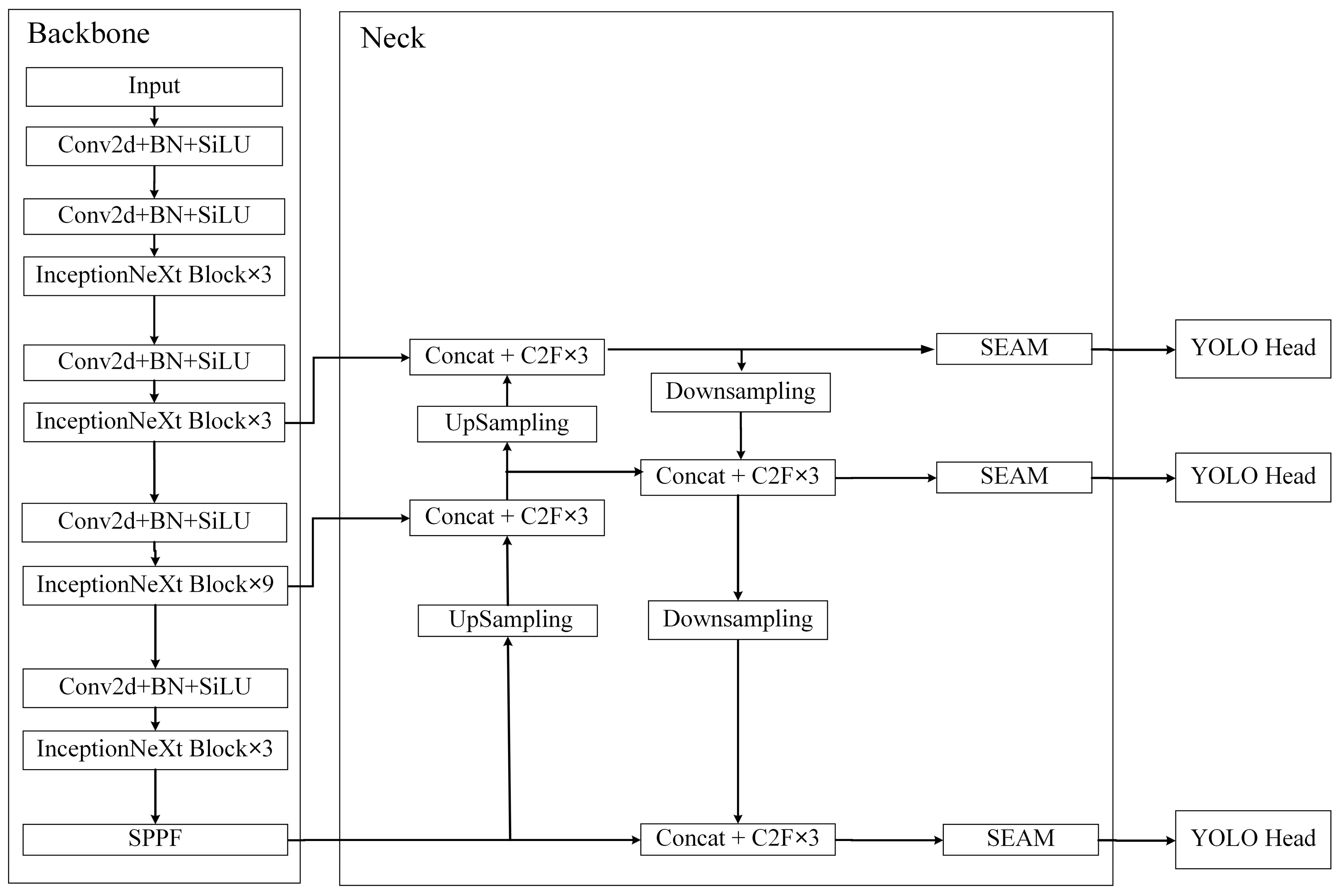
2.2. Structure of the Detector
2.2.1. Backbone
2.2.2. Neck
2.2.3. YOLO Head
3. Results and Discussion
3.1. Experimental Environment and Datasets
3.2. Analysis of the Training Strategies
3.3. Comparison of the Detectors’ Complexity
3.4. Performance Evaluation
3.5. Comparison of the Testing Results
3.6. Ablation Study
3.6.1. InceptionNeXt Block
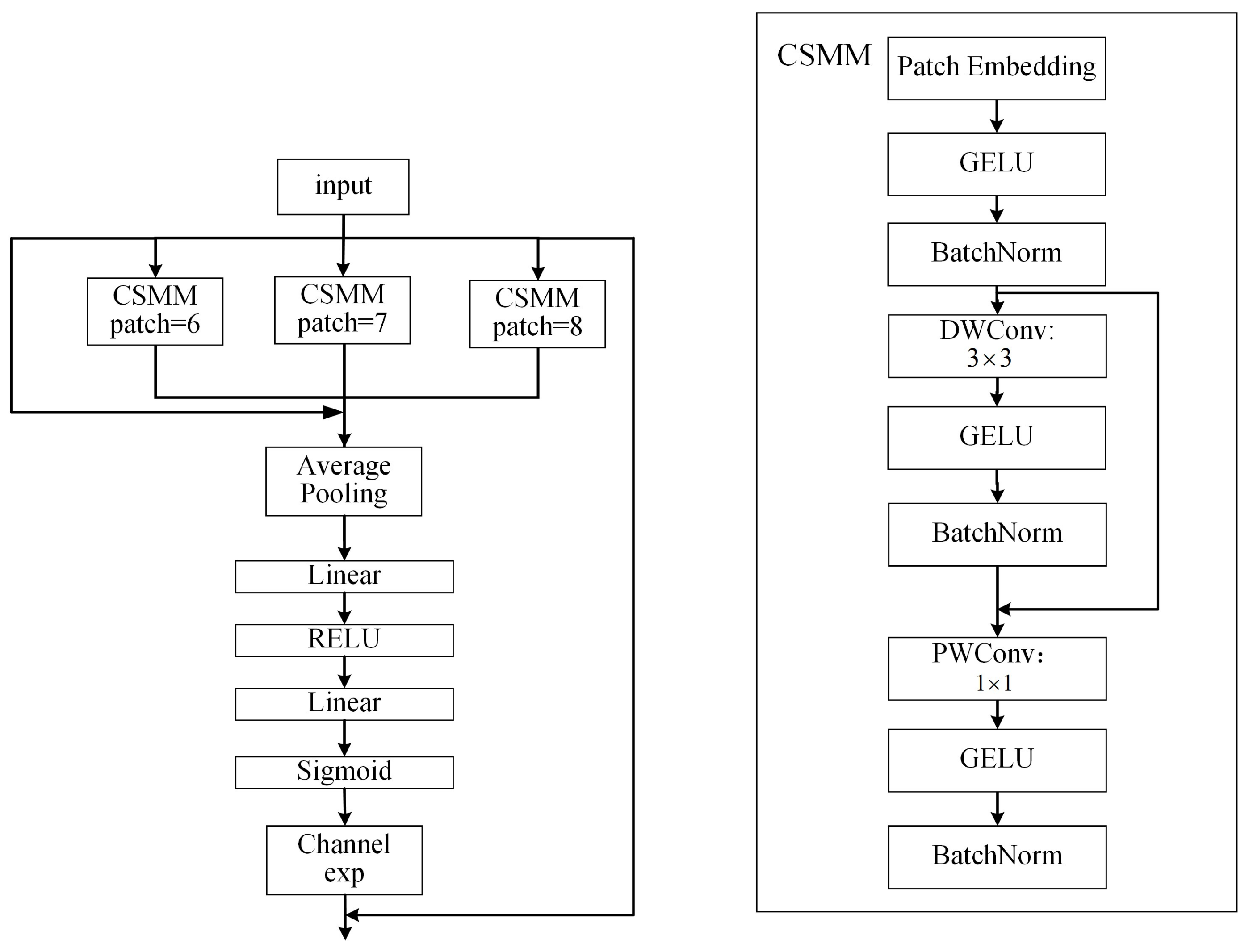
3.6.2. Attention Mechanisms
3.6.3. Loss Function
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Agardy, T. Effects of fisheries on marine ecosystems: A conservationist’s perspective. ICES J. Mar. Sci. 2000, 57, 761–765. [Google Scholar] [CrossRef]
- Greenville, J.; MacAulay, T. Protected areas in fisheries: A two-patch, two-species model. Aust. J. Agric. Resour. Econ. 2006, 50, 207–226. [Google Scholar] [CrossRef]
- Hu, K.; Weng, C.; Zhang, Y.; Jin, J.; Xia, Q. An Overview of Underwater Vision Enhancement: From Traditional Methods to Recent Deep Learning. J. Mar. Sci. Eng. 2022, 10, 241. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.; Zhong, J.; Liu, S.; Li, T.; Li, G. ROIMIX: Proposal-Fusion Among Multiple Images for Underwater Object Detection. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Barcelona, Spain, 4–8 May 2020. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhad, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Han, F.; Yao, J.; Zhu, H.; Wang, C. Underwater Image Processing and Object Detection Based on Deep CNN Method. J. Sens. 2020, 2020, 6707328. [Google Scholar] [CrossRef]
- Chen, L.; Zheng, M.; Duan, S.; Luo, W.; Yao, L. Underwater Target Recognition Based on Improved YOLOv4 Neural Network. Electronics 2021, 10, 1634. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, S.; Lu, J.; Wang, H.; Feng, Y.; Shi, C.; Li, D.; Zhao, R. A lightweight dead fish detection method based on deformable convolution and YOLOV4. Comput. Electron. Agric. 2022, 198, 107098. [Google Scholar] [CrossRef]
- Sun, S.; Xu, Z. Large kernel convolution YOLO for ship detection in surveillance video. Math. Biosci. Eng. MBE 2023, 20, 15018–15043. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Li, Y.; Zhang, Z.; Yin, S.; Ma, L. Marine target detection for PPI images based on YOLO-SWFormer. Alex. Eng. J. 2023, 82, 396–403. [Google Scholar] [CrossRef]
- Shen, X.; Wang, H.; Li, Y.; Gao, T.; Fu, X. Criss-cross global interaction-based selective attention in YOLO for underwater object detection. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Yu, G.; Su, J.; Luo, Y.; Chen, Z.; Chen, Q.; Chen, S. Efficient detection method of deep-sea netting breakage based on attention and focusing on receptive-field spatial feature. Signal Image Video Process. 2023. [Google Scholar] [CrossRef]
- Lv, C.; Cao, S.; Zhang, Y.; Xu, G.; Zhao, B. Methods studies for attached marine organisms detecting based on convolutional neural network. Energy Rep. 2022, 8, 1192–1201. [Google Scholar] [CrossRef]
- Li, Y.; Bai, X.; Xia, C. An Improved YOLOV5 Based on Triplet Attention and Prediction Head Optimization for Marine Organism Detection on Underwater Mobile Platforms. J. Mar. Sci. Eng. 2022, 10, 1230. [Google Scholar] [CrossRef]
- Li, L.; Shi, G.; Jiang, T. Fish detection method based on improved YOLOv5. Aquac. Int. 2023, 31, 2513–2530. [Google Scholar] [CrossRef]
- Favali, P.; Beranzoli, L. Seafloor observatory science: A review. Ann. Geophys. 2006, 49, 515–567. [Google Scholar] [CrossRef]
- Matabos, M.; Best, M.; Blandin, J.; Hoeberechts, M.; Juniper, K.; Pirenne, B.; Robert, K.; Ruhl, H.; Sarrazin, J.; Vardaro, M. Seafloor Observatories: Clark/Biological Sampling in the Deep Sea; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2016. [Google Scholar]
- Chen, J.; Liu, H.; Lv, B.; Liu, C.; Zhang, X.; Li, H.; Cao, L.; Wan, J. Research on an Extensible Monitoring System of a Seafloor Observatory Network in Laizhou Bay. J. Mar. Sci. Eng. 2022, 10, 1051. [Google Scholar] [CrossRef]
- Lv, B.; Chen, J.; Liu, H.; Chao, L.; Zhang, Z.; Zhang, X.; Gao, H.; Cai, Y. Design of deep-sea chemical data collector for the seafloor observatory network. Mar. Georesour. Geotechnol. 2022, 40, 1359–1369. [Google Scholar] [CrossRef]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. InceptionNeXt: When Inception Meets ConvNeXt. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar] [CrossRef]
- Wang, C.; Liao, H.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Pierre, S.; Scott, R.; Dragomir, A.; Dumitrue, E.; Vincent, V.; Andrew, R. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. YOLO-FaceV2: A Scale and Occlusion Aware Face Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, W.; Lei, Y. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Cutter, G.; Stierhoff, K.; Zeng, J. Automated Detection of Rockfish in Unconstrained Underwater Videos Using Haar Cascades. In Proceedings of the Applications and Computer Vision Workshops (WACVW), Waikoloa Beach, HI, USA, 5–9 January 2015. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE/CVF Conf Computer Vision Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, S.I. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Network | FLOPs/G | Params/M | Weights/MB |
|---|---|---|---|
| Faster-RCNN | 370.2 | 137 | 105.7 |
| YOLOv5n | 4.1 | 1.7 | 3.7 |
| YOLOv7-tiny | 13.1 | 6.0 | 11.7 |
| YOLOv8n | 8.1 | 3.006 | 6.09 |
| Improved YOLOv8 | 8.0 | 3.098 | 6.12 |
| Detection Network | Echinus AP | Fish AP | Holothurian AP | Scallop AP | Starfish AP | mAP | FPS |
|---|---|---|---|---|---|---|---|
| Faster-RCNN | 84.1% | 76.3% | 68.7% | 55.6% | 82.9% | 73.5% | 10 |
| YOLOv5n | 86% | 77.8% | 62% | 70.7% | 85.6% | 76.4% | 72 |
| YOLOv7-tiny | 85.8% | 78.4% | 49.5% | 62.9% | 82% | 71.7% | 70 |
| YOLOv8n | 87% | 82% | 63.7% | 72.4% | 86.3% | 78.3% | 68 |
| Improved YOLOv8 | 89.9% | 89.5% | 73.4% | 81.5% | 88.4% | 84.5% | 65 |
| Detection Network | Echinus AP | Fish AP | Holothurian AP | Scallop AP | Starfish AP | mAP |
|---|---|---|---|---|---|---|
| YOLOv8 | 87% | 82% | 63.7% | 74.4% | 84.3% | 78.3% |
| YOLOv8(Neck) | 87.4% | 83.2% | 65.3% | 75.5% | 84.2% | 79.1% |
| YOLOv8(All) | 86.7% | 81.4% | 63.2% | 73.6% | 83.5% | 77.7% |
| YOLOv8(Backbone) | 87.6% | 84.8% | 67.6% | 77.5% | 84.5% | 80.4% |
| Detection Network | Echinus AP | Fish AP | Holothurian AP | Scallop AP | Starfish AP | mAP |
|---|---|---|---|---|---|---|
| YOLOv8 | 87% | 82% | 63.7% | 74.4% | 84.3% | 78.3% |
| YOLOv8+SE | 87.1% | 83.4% | 64.5% | 75.3% | 84.5% | 79% |
| YOLOv8+CBAM | 87.3% | 83.7% | 64.8% | 75.9% | 84.6% | 79.3% |
| YOLOv8+SEAM | 87.4% | 84.3% | 66.2% | 77.5% | 84.6% | 80% |
| CIoU | NWD | Echinus AP | Fish AP | Holothurian AP | Scallop AP | Starfish AP | mAP |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 87% | 82% | 63.7% | 74.4% | 84.3% | 78.3% |
| 0.6 | 0.4 | 86.2% | 84.6% | 65.5% | 75% | 84.4% | 79.1% |
| 0.5 | 0.5 | 86.9% | 85.7% | 66.3% | 77.7% | 84.8% | 80.3% |
| 0.4 | 0.6 | 86.5% | 81.6% | 62.4% | 73.2% | 83.5% | 77.4% |
| 0 | 1 | 86% | 80.7% | 61.5% | 72.8% | 82.4% | 76.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, R.; Lv, B.; Chen, J.; Liu, H.; Cao, L.; Liu, M. Underwater Object Detection in Marine Ranching Based on Improved YOLOv8. J. Mar. Sci. Eng. 2024, 12, 55. https://doi.org/10.3390/jmse12010055
Jia R, Lv B, Chen J, Liu H, Cao L, Liu M. Underwater Object Detection in Marine Ranching Based on Improved YOLOv8. Journal of Marine Science and Engineering. 2024; 12(1):55. https://doi.org/10.3390/jmse12010055
Chicago/Turabian StyleJia, Rong, Bin Lv, Jie Chen, Hailin Liu, Lin Cao, and Min Liu. 2024. "Underwater Object Detection in Marine Ranching Based on Improved YOLOv8" Journal of Marine Science and Engineering 12, no. 1: 55. https://doi.org/10.3390/jmse12010055
APA StyleJia, R., Lv, B., Chen, J., Liu, H., Cao, L., & Liu, M. (2024). Underwater Object Detection in Marine Ranching Based on Improved YOLOv8. Journal of Marine Science and Engineering, 12(1), 55. https://doi.org/10.3390/jmse12010055