1. Introduction
The oceans constitute one of the largest and most biodiverse ecosystems on earth [
1]. The 2010 Global Census of Marine Life suggests that there may be over 2 million species of marine organisms, with only approximately 200,000 species of marine macro-organisms known to us. The ocean concurrently serves as a significant repository for oil, gas, minerals, chemicals, and various other aquatic resources. An increasing number of professionals from diverse fields are involved in the exploration of marine resources [
2]. In the past decade, underwater robotics and detection technologies, including Autonomous Underwater Vehicles (AUVs) and Remotely Operated Vehicles (ROVs) [
3,
4] have experienced rapid development. They play a crucial role in the exploitation and conservation of marine resources and have attracted the attention of many scholars. In this context, the technology of underwater object detection plays a crucial role. Detection of underwater objects can be classified into two main categories: acoustic system detection and optical system detection [
5]. It relies on acquired image information for image analysis, encompassing classification, identification, and detection. In comparison to acoustic images, optical images offer higher resolution and greater information content [
6,
7]. Presently, there is a growing focus on underwater object detection using optical systems. Nevertheless, the intricate underwater environment and lighting conditions, along with the inevitable noise during visual information acquisition, pose significant challenges to the implementation of vision-based underwater object detection.
The objective of general object detection is to ascertain the location of a target instance within a natural image, relying on a vast array of predefined categories. This involves such essential tasks as object categorization and orientation. Presently, object detection methods can be broadly classified into two groups: traditional object detection methods and convolutional neural network (CNN)-based object detection methods [
8].
Traditional object detection begins with a sliding window strategy [
9] for scanning the entire image, considering the target’s position and aspect ratio variations. Features are extracted using methods like SIFT [
10] and HOG [
11], and machine learning classifiers, including SVM, classify these features to detect objects within the window. However, traditional methods face challenges such as a lack of universality, high time complexity, and feature robustness issues, impacting their effectiveness. The emergence of convolutional neural networks (CNN) in recent years has significantly improved accuracy and speed, particularly in handling complex scenarios and targets, including underwater object detection.
Numerous studies have demonstrated the superiority of convolutional neural network (CNN)-based object detection over traditional algorithms. Currently, the presence or absence of anchors in the input data is the primary classification used by object detection algorithms in deep learning. Anchorless object detection models, such as CenterNet [
12], CornerNet [
13], and Transformer [
14]-based end-to-end object detection (DETR) [
15], eliminate the need for target anchors. This enhances model flexibility to adapt to varying sizes and shapes of targets, ultimately improving object detection accuracy and robustness. However, their suitability for real-time applications is limited due to the more complex network structure and higher hardware cost requirements. Anchor-based object detection models [
16] mainly include two-stage object detection methods based on region suggestions such as RCNN [
17], Fast-RCNN [
18], Faster-RCNN [
19], Mask-RCNN [
20], Cascade-RCNN [
21], etc., and regression-based object detection algorithms such as the SSD [
22] and YOLO [
23] (You Only Look Once) series of algorithms [
24,
25,
26,
27,
28,
29], and so on. One-stage object detection algorithms skip the generation of candidate regions and directly execute operations like feature extraction, classification, and regression on the entire image, resulting in quicker detection times. The YOLO series of algorithms, as a classical one-stage object detection approach, is widely utilized for its exceptional detection performance. Through continuous improvements and innovations, its performance in object detection tasks has become increasingly outstanding.
Amidst the advancements in underwater robotics, researchers seek an efficient and easily deployable underwater object detection model to augment the commercial value of underwater robots. In 2015, Li et al. [
30] pioneered the use of deep CNN for underwater object detection, concurrently creating the ImageCLEF dataset. In 2017, Zhou et al. [
19] enhanced VGG16 by integrating image enhancement techniques and the Faster R-CNN network for underwater target detection on the URPC dataset. In 2019, Weihong Lin et al. [
31] introduced a generalization model designed to address challenges such as target overlapping and blurring in underwater object detection tasks. In 2021, to tackle the heterogeneity of underwater passive targets and classification challenges, Weibiao Qiao et al. [
32] presented a design for timely and accurate underwater target classifiers using Local Wavelet Acoustic Patterns (LWAP) and Multi-Layer Perceptron (MLP). With the focus on accuracy improvement, Minghua Zhang et al. [
33] shifted attention to the lightweight aspect of underwater object detection models. To improve real-time and lightweight performance, they introduced a lightweight underwater object detection method that incorporates MobileNet v2, the YOLOv4 algorithm, and an attention mechanism. In 2023, to address the challenges posed by the intricate underwater scenes and the limited ability to extract object features, Zhengwei Bao et al. [
34] proposed a parallel high-resolution network for underwater object detection. Kaiyue Liu et al. [
35] enhanced the model performance by incorporating a residual module and integrating a global attentional mechanism into the object detection network. Dulhare UN et al. [
36] employed Faster R-CNN and data augmentation algorithms to tackle the issue of low accuracy in detecting humans in underwater environments. In 2024, Rakesh Joshi et al. [
37] addressed the issue of underwater scattering caused by suspended particles in water, severely degrading signal detection performance. They proposed a degradation condition-based three-dimensional (3D) integral imaging (InIm) integrated deep learning bifunctional approach for underwater object detection and classification.
Additionally, deploying these object networks on embedded hardware presents a new challenge. The prevalent approach involves employing embedded development boards like Openmv [
38], k210 [
39], and Jetson series [
40] development boards, along with image acquisition modules, to form a vision system. Xin Feng et al. [
41] conducted a comprehensive analysis of recent advances in computer vision algorithms and their corresponding hardware implementations. In 2020, Yu-Chen Chiu et al. [
42] introduced a lightweight object detection model based on Mobilenet-v2, demonstrating a balance between speed and accuracy through real-world tests on the Nvidia Jetson AGX Xavier platform. Subsequently, in 2023, Sichao Zhuo et al. [
43] proposed a lightweight meter reading recognition network using deformable features and aggregation, deploying it on a Jetson TX1 smart vehicle for meter reading applications, and realized the performance of SOTA. Unlike high-performance graphics cards on the host side, limitations such as storage speed and maximum arithmetic support of embedded development boards constrain the practical application of various underwater object detection networks [
44].
In conclusion, owing to the complexity of the underwater environment, current underwater object detection algorithms encounter numerous challenges in practical applications. These challenges include images affected by seawater refraction, scattering, and other factors, resulting in blurred images; multi-scale transformation of underwater targets due to different angles and distances of collected data; target occlusion caused by the aggregation of underwater organisms; the substantial computational overhead of traditional object detection models, making deployment on embedded devices difficult, and more. In the face of these challenges, the field of underwater object detection still has a long way to go.
Among the YOLO series algorithms, YOLOv7 stands out with superior accuracy, faster speed, heightened stability, and increased suitability for industrial applications. Consequently, in this paper, we introduce the YOLOv7-GN model, built upon the YOLOv7 framework, and validate the efficacy of our approach through experiments conducted on underwater images. Our contributions are outlined as follows:
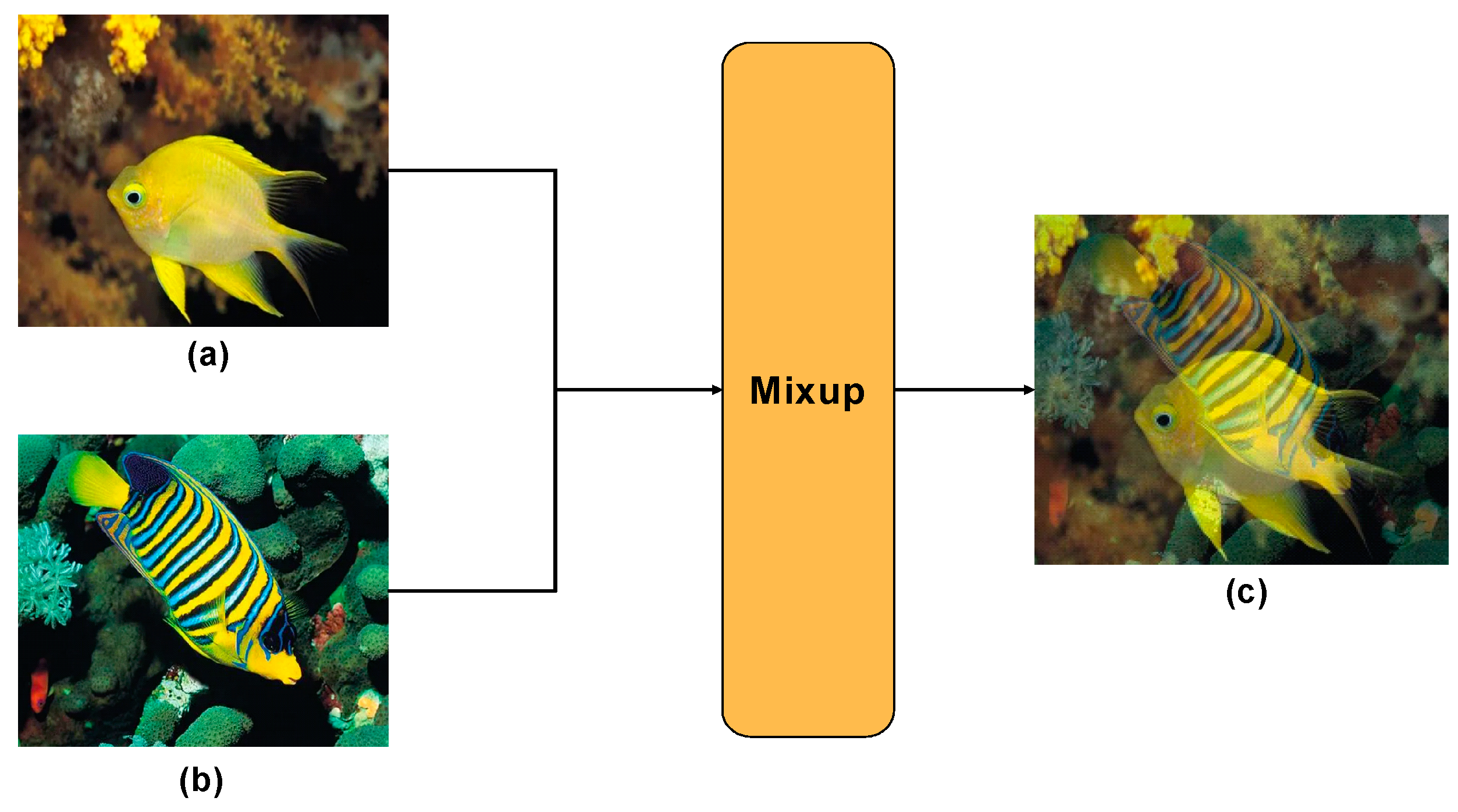
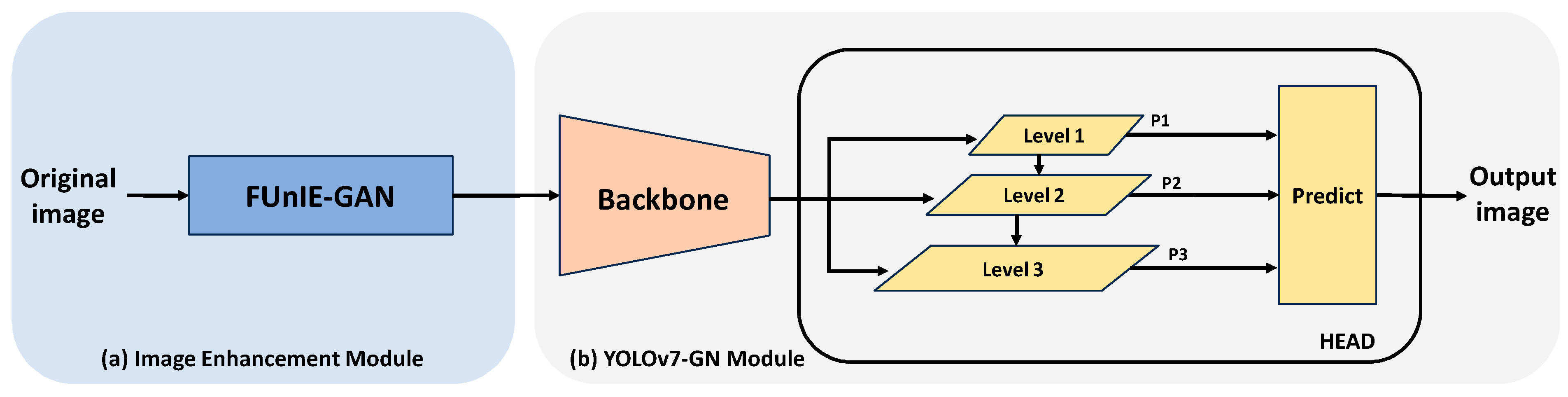
(1) In this study, FUnIE-GAN is employed for underwater image enhancement, and data enhancement methods, including Mixup, are applied during dataset preprocessing to capture the feature information of the object effectively.
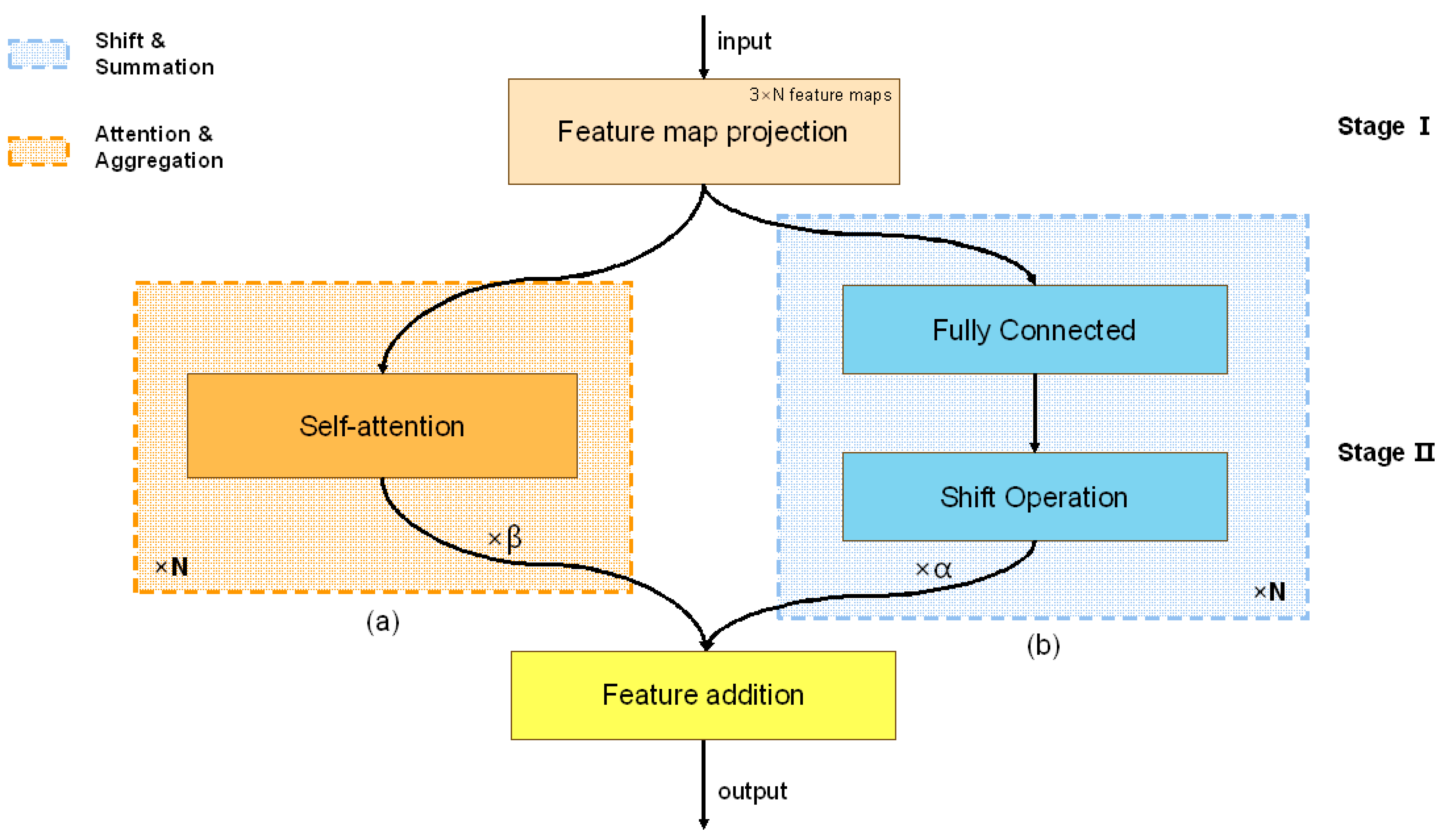
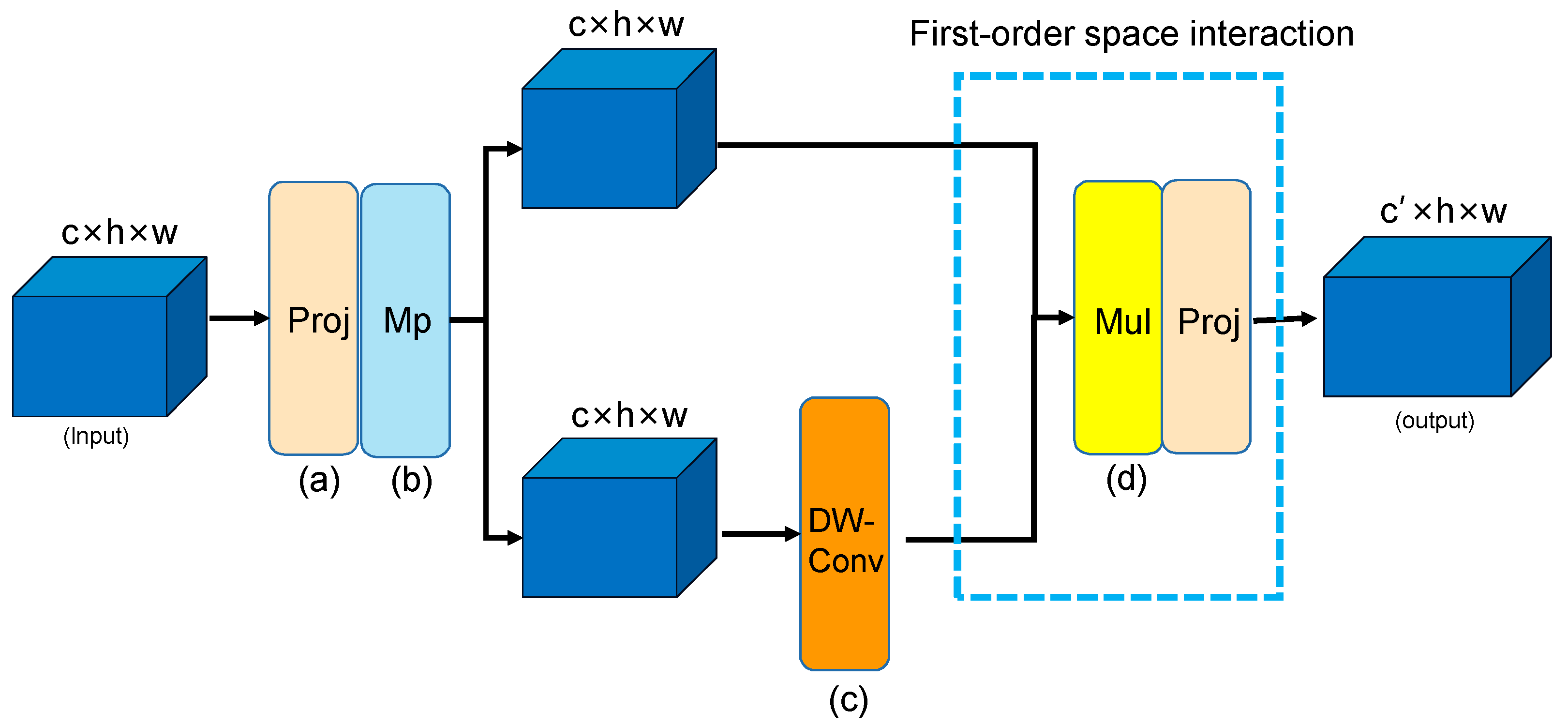
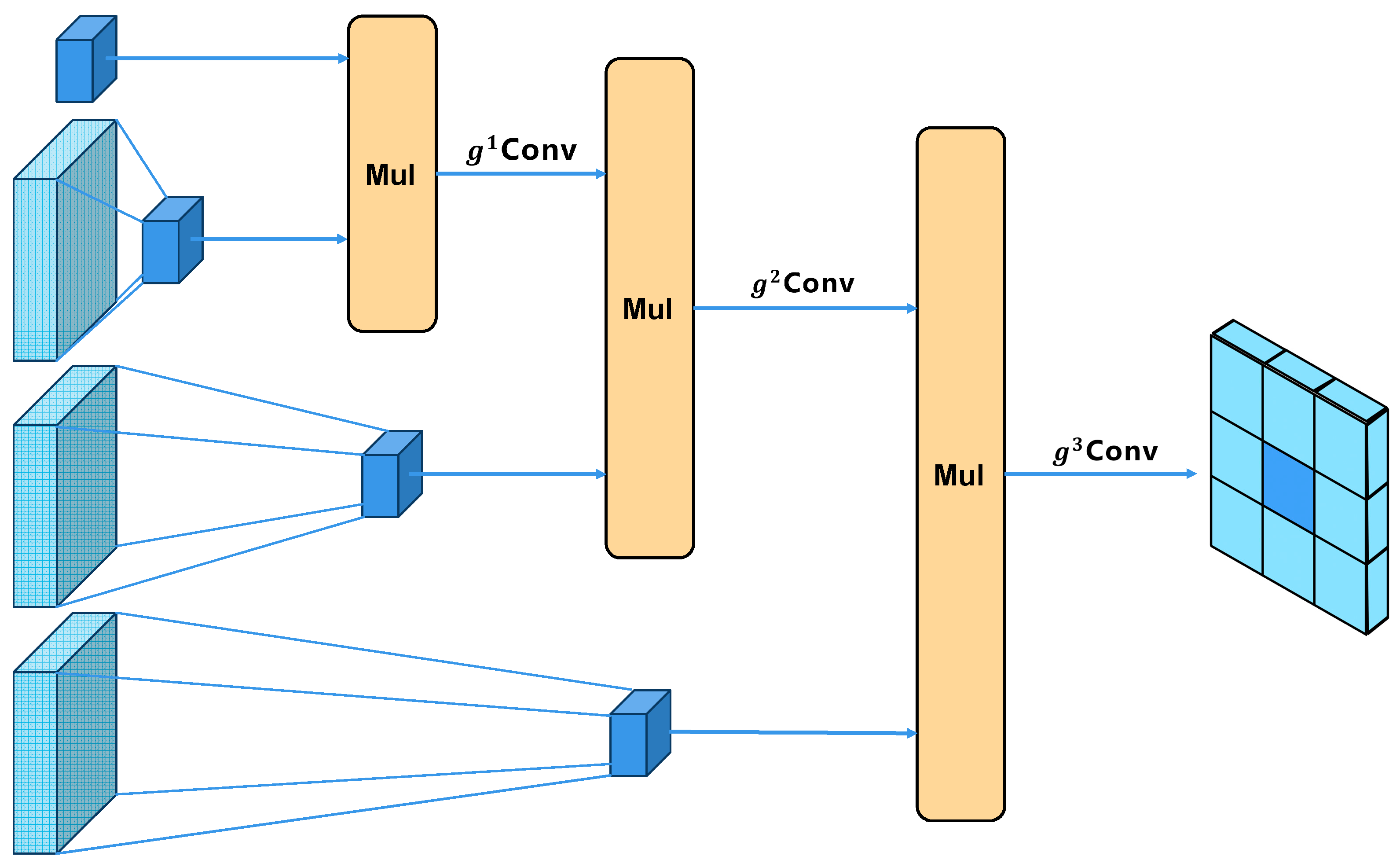
(2) In this study, an enhanced head network is designed for multiscale higher-order information interaction, aiming to enhance the spatial interaction capability of YOLOv7-GN. This improvement allows the extension of self-attention’s second-order interactions to arbitrary orders by integrating recursive gated convolution (Conv) with a high degree of flexibility and customizability, all without introducing a significant computational burden.
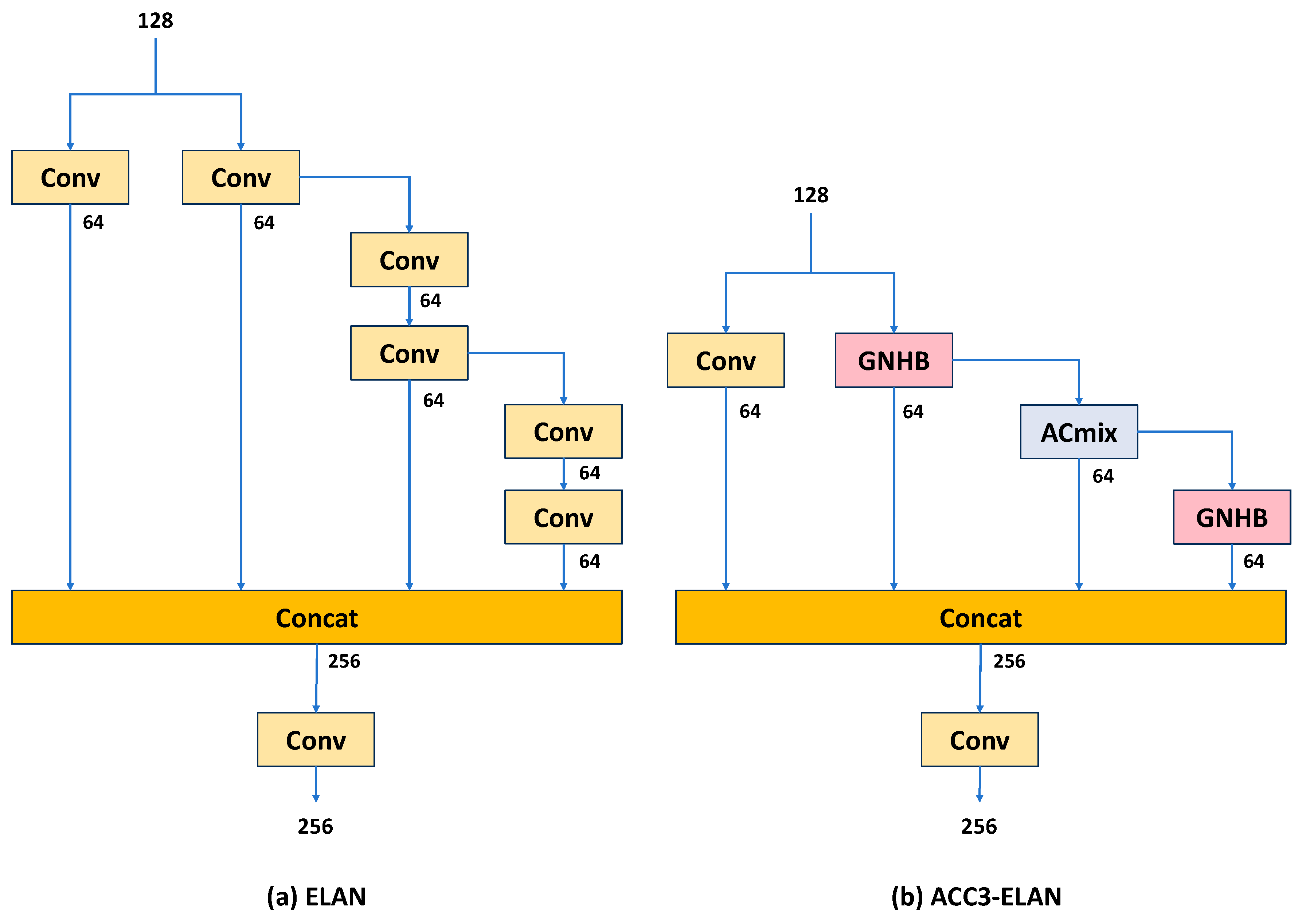
(3) In order to capture more global features in the image, ACmix is incorporated as the fundamental model for self-attention and convolution in YOLOv7-GN. Building on the characteristics of ACmix and Conv, we introduce a novel lightweight higher-order attentional layer aggregation network, denoted as ACC3-ELAN. ACC3-ELAN optimizes the gradient length of the entire network compared to ELAN, reduces the number of parameters, and improves the network’s fusion sensing ability for higher-order features.
(4) To assess the feasibility of deploying our model on embedded devices and its effectiveness in practical applications, we designed a biomimetic underwater robot. Subsequently, we deployed our model into this underwater biomimetic robot to conduct real world testing scenarios.
4. Experiments and Results
In this section, we begin by presenting the experimental configurations and materials. Next, specific ablation experiments are conducted on YOLOv7-GN, followed by a detailed evaluation of the performance of the FUnIE-GAN underwater image enhancement. Finally, the model is compared with mainstream object detection models, and its deployment on an embedded device is discussed.
4.1. Experimental Environment
In our algorithm design and implementation, we employed the PyTorch deep learning framework. For model training, we utilized stochastic gradient descent to optimize the model parameters, setting the momentum to 0.937 and the weight decay parameter to 0.0005, and incorporating the Mixup image mashup data enhancement technique with a probability of 0.15. Additionally, for effective model training, we employed the dynamic learning rate method, initializing the learning rate to 0.01 and gradually decreasing it using the cosine learning rate strategy [
66]. The batch size was set to 16, and the number of workers was set to 30 to enable multi-threaded data loading. The complete training process of the model spanned 300 epochs, with each epoch representing the entire training dataset being fed into the network once.
In this experiment, all parameters are consistent with YOLOv7 [
24] except for batch size and epochs, ensuring experimental fairness. Setting the epochs to 300 aims to prevent model overfitting/underfitting and reduce training hardware costs. The choice of batch size was primarily informed by studies [
67,
68] from other scholars and tasks of similar size. Experimental equipment and environmental setup details are provided in
Table 1.
4.2. Evaluation Metrics and Dataset
4.2.1. Evaluation Metrics
To accurately evaluate the object detection model’s performance in this study, we utilized precision, recall, Mean Average Precision (
), and
F1
score as the performance evaluation metrics. Firstly,
IoU (Intersection over Union) is a commonly used evaluation metric in the field of object detection to measure the degree of overlap between the model detection results and the actual target location. It quantifies the accuracy of detection by calculating the ratio of the intersection area to the union area of the detected box. If
is used to denote a real object box in the dataset and
is used to denote the predicted box after model detection, then the expression of IoU is as follows:
Precision measures how many of the samples that the model recognizes as positive categories are true positive categories. The expression is shown in Equation (9), where
is the number of true cases (samples correctly predicted by the model to be positive), and
is the number of false positive cases (samples incorrectly predicted by the model to be positive). Recall is a measure of how many of the true positive categories are successfully recognized by the model, and the formula is shown in Equation (10), where
is the true cases, and
is the false negative cases (samples incorrectly predicted by the model as negative categories).
Mean Average Precision (
) is a widely used, comprehensive metric used to evaluate object detection.
accounts for the differences between various object categories, and its calculation involves the area under the Precision–Recall curve. In object detection, AP is typically calculated at different confidence thresholds to generate the Precision–Recall (P–R) curve. However, the model may only be effective at a specific threshold (e.g., 50%). Therefore, we specifically use
50 to evaluate performance. Generally, a higher
value indicates better performance of the model in object detection.
The
F1
Score is the reconciled average of Precision and Recall, which combines the precision and recall of the model.
In this study, we denote accuracy, recall, and detection class as , , and , respectively. Additionally, , , and represent true-positive, false-negative, and false-positive instances, respectively. Here, denotes the total number of categorized classes.
For underwater image quality evaluation, we utilize two non-reference evaluation metrics, Naturalness Image Quality Evaluator (
NIQE) [
69] and Underwater Color Image Quality Evaluation (
UCIQE) [
60]. The computation of
NIQE relies on the fitting process of both the natural and distorted images. First,
NIQE establishes the fitting relationship between natural and distorted images by obtaining their means
and variance matrices
. Then, it evaluates the quality of the images, calculating the distance between the fitting parameters of the warped images and the fitting parameters of the natural images. The
NIQE value is a quantification of this difference, with lower values indicative of higher image quality.
UCIQE involves key parameters for image quality assessment. First,
represents the standard deviation of color intensity,
denotes the contrast of luminance, and
is the mean of saturation. These parameters are weighted by specific constant value
, with values of 0.4680, 0.2745, and 0.2576, respectively. These constant values align with the data in the literature [
70].
The UCIQE formula quantifies the overall image quality in a weighted manner by combining the averages of color intensity, brightness contrast, and saturation. A higher UCIQE value corresponds to better image quality.
4.2.2. Dataset
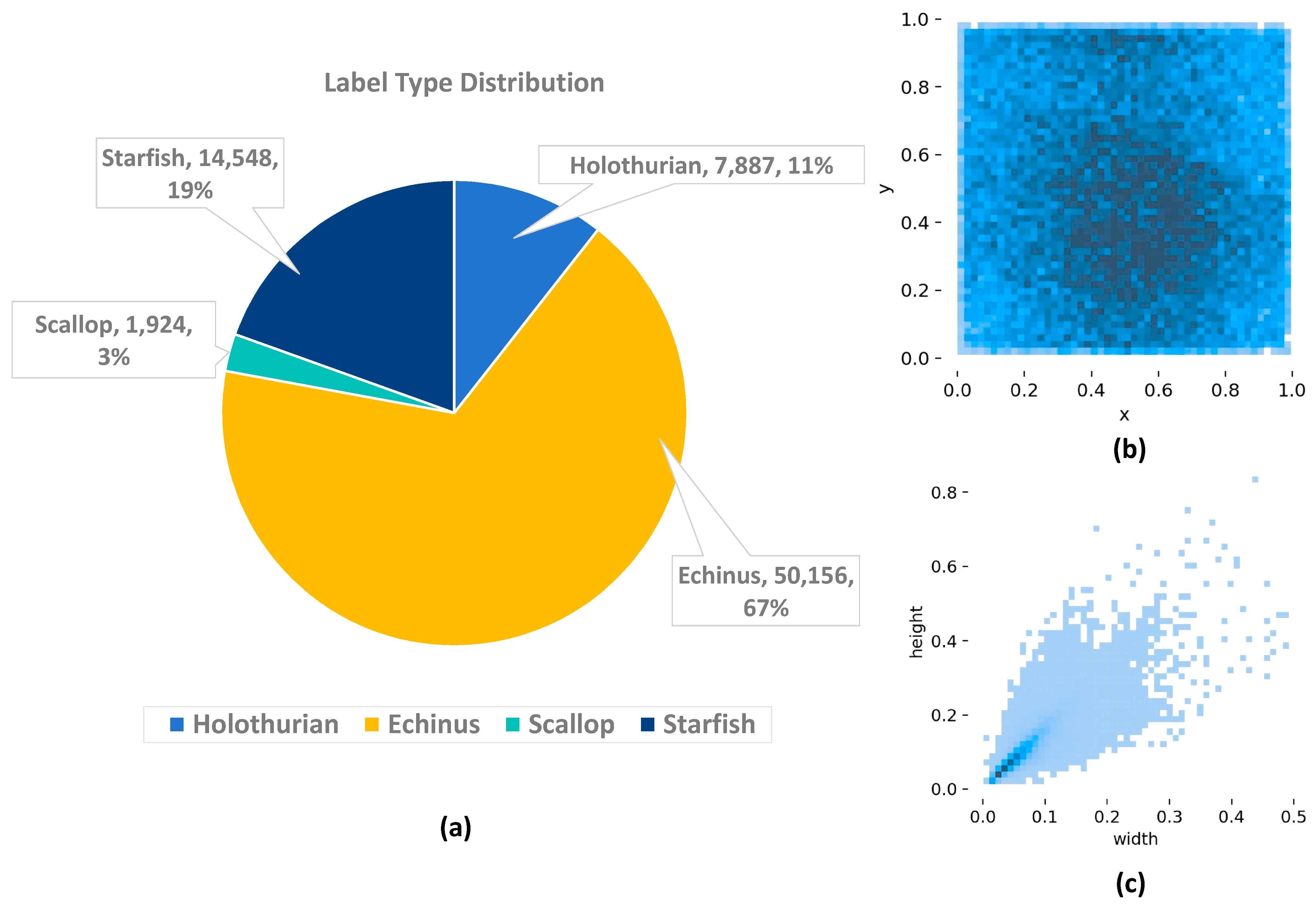
DUO [
71] is an open-source underwater dataset created in 2021. The dataset comprises a total of 74,515 objects including sea cucumbers, sea urchins, scallops, and starfish, with quantities of 7887, 50,156, 1924, and 14,548, respectively. As depicted in
Figure 10, sea urchins are the most numerous, constituting 67% of the overall count. Due to variations in the economic values of different seafood products, leading to differences in species numbers, the overall data distribution exhibits a clear long-tail pattern.
Figure 10 also illustrates the distribution of center coordinates and target sizes of the boxes in the dataset. The overall dataset sample distribution is observed to be unbalanced, with small targets (w < 0.3, h < 0.4) constituting the majority of the data, posing a more significant challenge for each object detection model.
Simultaneously, we employ two non-reference underwater image evaluation metrics, NIQE and UCIQE, to assess the underwater image quality of the dataset. This facilitates the subsequent quantitative comparison of underwater image enhancement effects.
Table 2 presents all the key information of the DUO dataset.
4.3. Ablation Experiments
To comprehensively assess the effectiveness of each scheme for YOLOv7-GN, we conducted ablation experiments on the DUO dataset, outlining the improvement strategies in
Table 3. The performance evaluation focuses on precision (P), recall (R), F1 score, Mean Average Precision (
mAP50 and
mAP50:95), Parameters, Giga Floating-point Operations Per Second (GFLOPs), and the size of the weights file generated after completing model training (Model Size). The results of each scheme are presented in
Table 4. Additionally, the results of the ablation experiments are depicted in
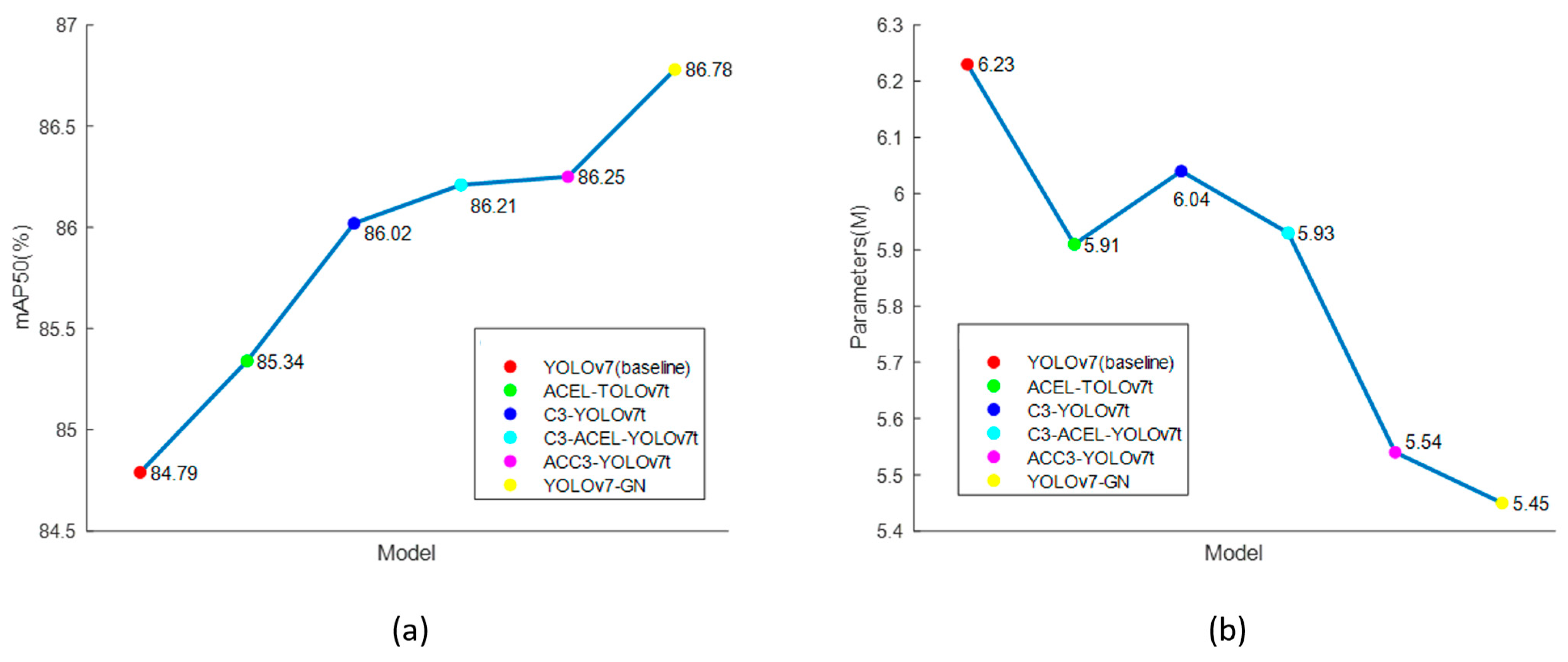
Figure 11 to facilitate the observation of data variations.
Specifically, in the ACEL-YOLOv7t scheme, we integrate the AC-ELAN-t obtained from pruning ACC3-ELAN into the head network. This replaces the original ELAN module connected to the detection head, and we arrange the AC-ELAN-t modules in a gradient according to the size of the feature pyramid. The other ELAN modules in the network remain unchanged. To investigate the impact of ACC3-ELAN on the extraction ability of high and low-frequency features and the overall network size, we primarily replace and improve the ELAN in the Backbone of the ACC3-YOLOv7t scheme. After each MP module in the Backbone, we replace the ELAN module with ACC3-ELAN, using it as a connection to the HEAD feature pyramid (FPN) at a key location. In the C3-YOLOv7t scheme, we primarily explore the gain of higher-order information interaction brought by GNHB to the overall network. We replace the two 1 × 1 convolutional layers connecting the Backbone in the original HEAD feature pyramid (FPN) with GNHB modules. Subsequently, we insert another GNHB module at the end of the Backbone to further enhance the network’s ability to extract higher-order information. The C3-ACEL-YOLOv7t scheme is our proposed improved head network based on multi-scale higher-order information interaction. Combining the above three makes up our improved algorithm called YOLOv7-GN.
The results of the ablation experiments are presented in
Table 4. From
Table 4, we can see that the YOLOv7-tiny algorithm has lower F1 scores, mAP, and other object detection metrics. Simultaneously, there is still potential for further compression of model parameter counts, GFLOPs, and the size of the trained model. ACEL-YOLOv7t introduces our lightweight ELAN module for the first time compared to the original algorithm, resulting in decreased model parameter counts, GFLOPs, and Model Size. Crucially, while the model is lightweighted, the integration of self-attention and convolution through ACmix cleverly improves global dependency modeling. ACEL-YOLOv7t improves mAP by 0.55% and reduces the number of model parameters by 0.32.
In the C3-YOLOv7t scheme, we employ recursive gated convolution at the key connection location of the Backbone and feature pyramid (FPN), providing higher-order feature information of different sizes. This simple design brings a 1.23% performance improvement to the mAP of the network and increases the F1 score by 0.61%. However, the size of the network is increased. For the C3-ACEL-YOLOv7t scheme, compared to the previous scheme, the improved head network based on multi-scale higher-level information interaction achieves a more significant performance improvement. It increases mAP by 1.42%, P by 2.25%, and F1 by 1.65%. The model parameters are reduced by 0.3 million while taking advantage of the higher-level spatial interaction with gated convolution and recursive design.
The ACC3-YOLOv7t scheme demonstrates the performance of the lightweight higher-order attention layer aggregation network. ACC3-ELAN enables Backbone to possess three simultaneous capabilities: an input adaptive weight generation strategy, long-distance spatial modeling capability, and higher-order spatial interaction. This scheme increases R, F1, and mAP by 2.26%, 1.88%, and 1.46%, respectively, while reducing the number of model parameters by 0.69 million and GFLOPs by 1.5. Notably, ACC3-YOLOv7t achieves the best recall (R) and GFLOPs among all scenarios, illustrating that the lightweight higher-order attentional layer aggregation network (ACC3-ELAN) efficiently reduces the calculated load and captures most actual positive samples, minimizing the chances of missing the target.
YOLOv7-GN is a fusion of the previously mentioned schemes, and in comparison with the baseline, YOLOv7-GN achieves significant improvements. Specifically, YOLOv7-GN enhances precision (P) by 3.03%, recall (R) by 0.91%, F1 score by 1.87%, and mean Average Precision (mAP) by 1.99%. Moreover, the number of model parameters and GFLOPs are reduced by 0.78 million and 1.3, respectively. The model size is also decreased by 0.67 MB. Compared to the baseline, YOLOv7-GN showed better performance in terms of accuracy, recognition speed, and model size.
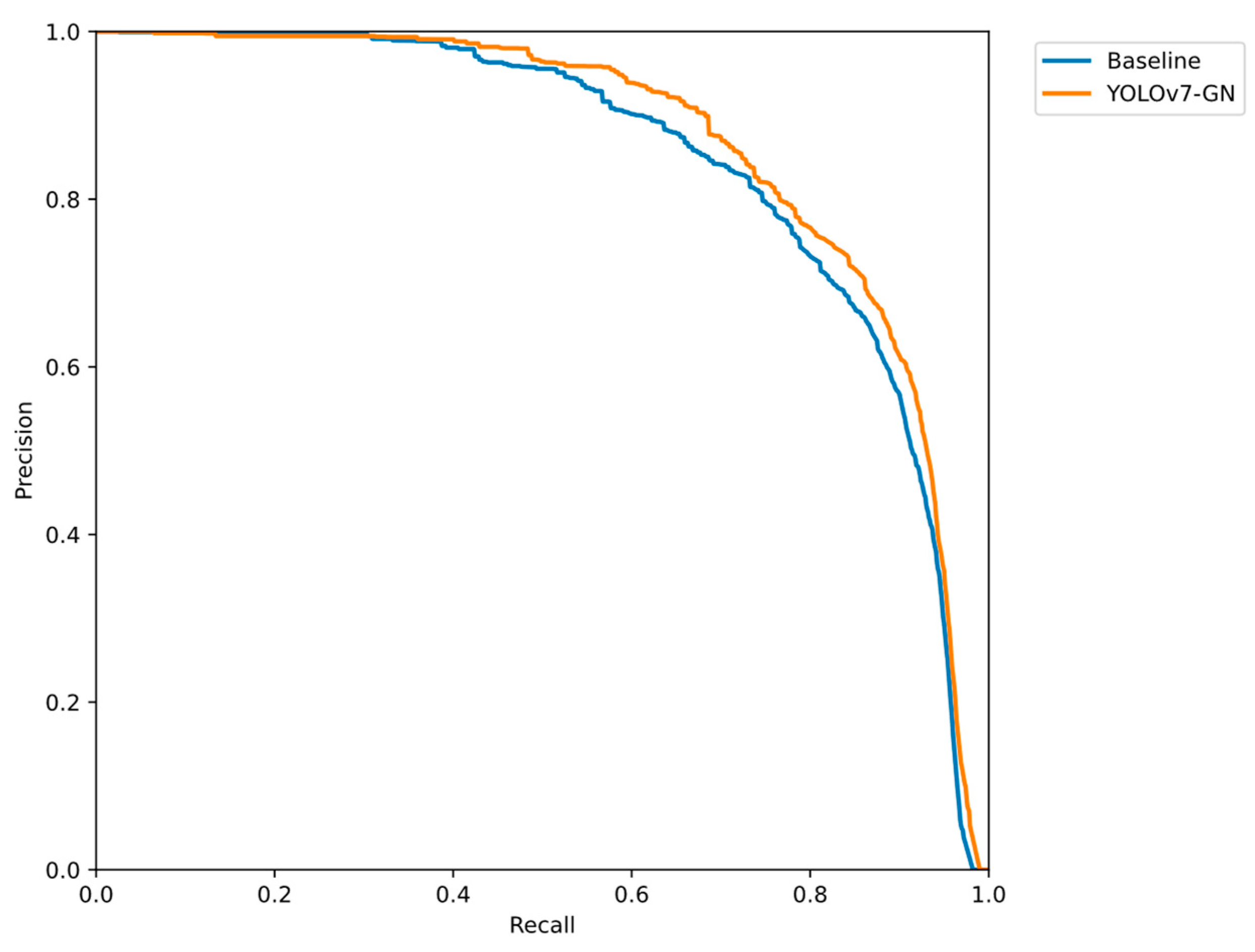
To further characterize the enhancement effect of our method on the original model, we compare YOLOv7-GN with the baseline model’s Precision–Recall curves, as illustrated in
Figure 12. This curve illustrates the trade-off between precision (Precision) and recall (Recall) at varying confidence thresholds, with the area between the curve and the axes representing the Average Precision (AP). The results show that the AP of YOLO-GN is higher, and the overall performance is better, than that of the benchmark model.
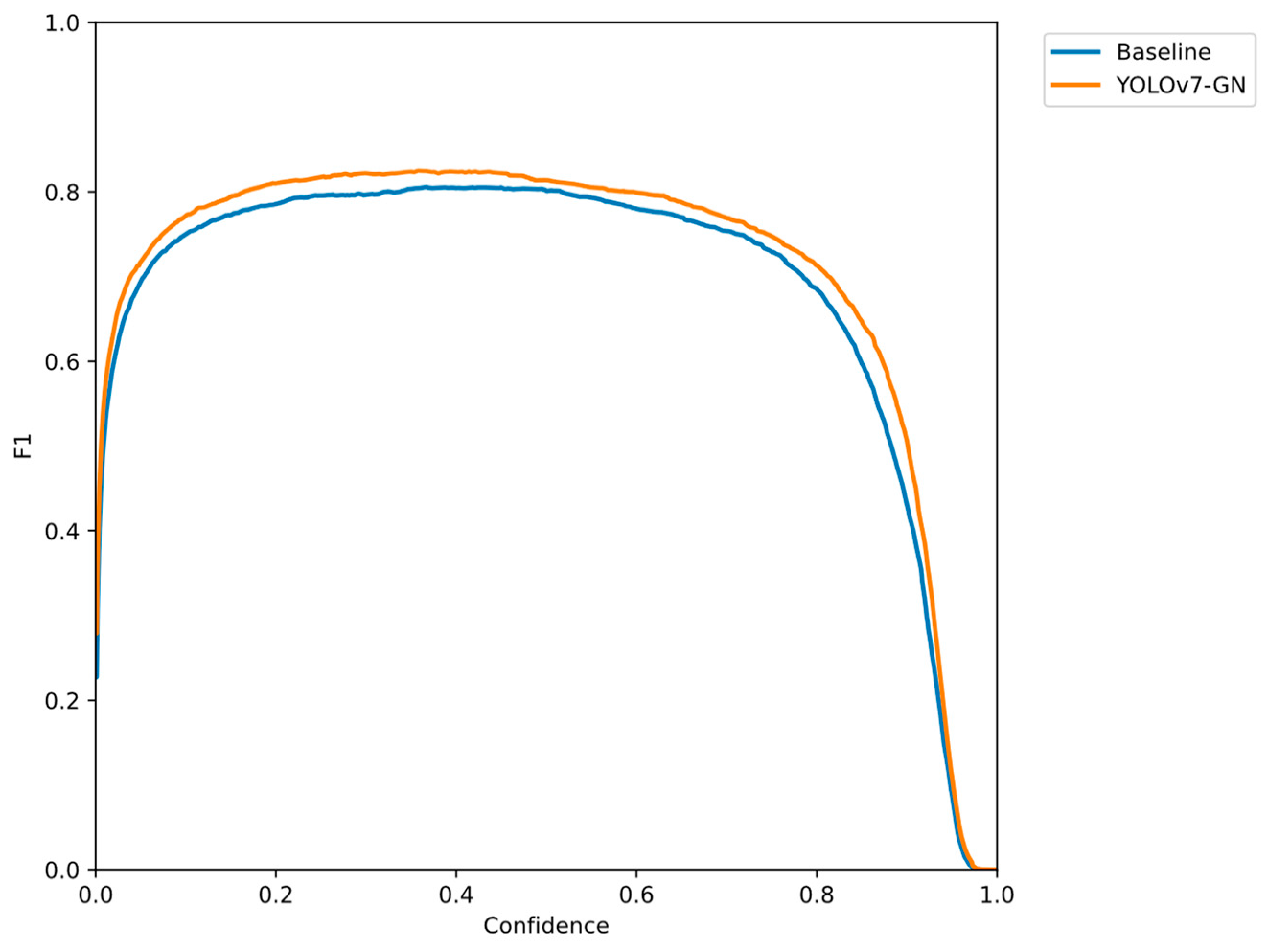
We additionally conducted a comparison of the F1–Confidence curves for both models, as depicted in
Figure 13. Combining the F1 Score and Confidence in the object detection task, the F1–Confidence curve serves as a metric for evaluating the model’s performance. The curve illustrates the correlation between the F1 Score and Confidence across various confidence thresholds, facilitating the analysis of the model’s performance under different confidence levels. Experimental results indicate that YOLOv7-GN exhibits superior recall compared to the benchmark model across most confidence levels. This suggests that YOLOv7-GN strikes a balance between Precision and Recall, enhancing robustness, especially in scenarios with an imbalanced distribution of samples in the target category.
4.4. Underwater Image Enhancement
In this section, we examine the impact of diverse image enhancement methods on underwater image enhancement and compare traditional image enhancement methods with the FUnIE-GAN method. Initially, we illustrate the effects of various image enhancements through subjective evaluation. Subsequently, we employ two non-reference evaluation metrics to assess the enhancement effect objectively. Finally, we implement the optimal underwater image enhancement scheme in YOLOv7-GN and assess the performance of the enhanced version.
4.4.1. Evaluation of Underwater Image Enhancement
We employed various common underwater image enhancement methods for comparative analysis, namely Gamma Correction (GC), CLAHE [
72], HE [
73], ICM [
74], Rayleigh Distribution (RD) [
75], RGHS [
48], UCM [
76], and FUnIE-GAN.
Table 5 presents a comparison of the definitions, advantages, and disadvantages of common image enhancement methods. Illustrated in
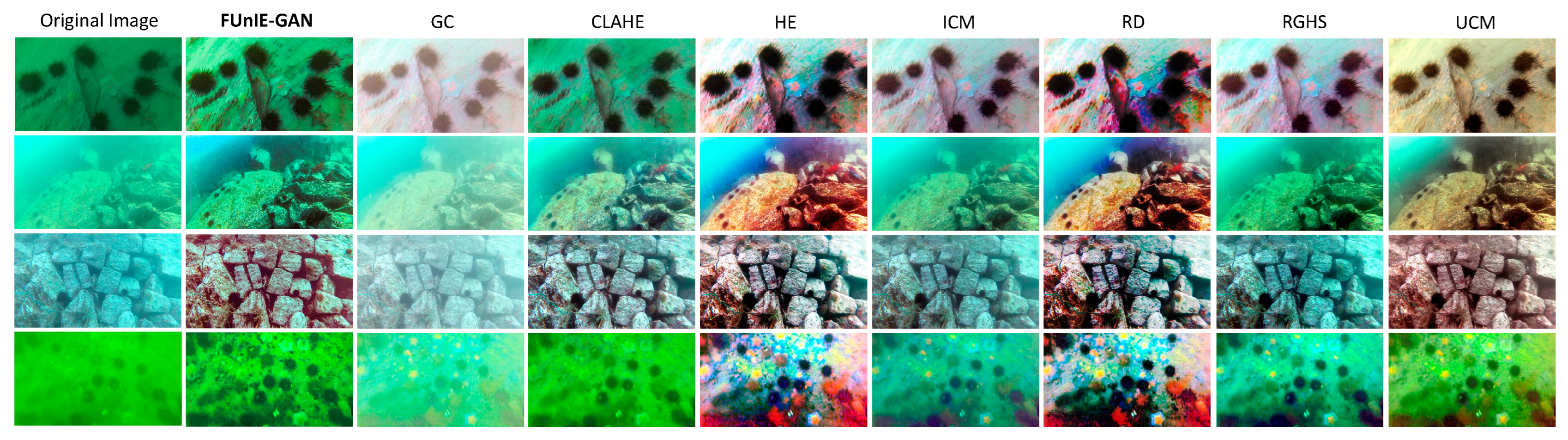
Figure 14, we selected four scenarios with distinct challenges from the DUO dataset as test samples, encompassing green, turbid, and low-visibility scenarios, respectively.
From the results depicted in
Figure 14, it is evident that the FUnIE-GAN method attains a more realistic color restoration of underwater images while maintaining a certain level of clarity during dehazing. The GC method enhances the overall brightness of the photo and is effective in high-contrast scenes between foreground and background, but its overall enhancement effect is relatively weak. The CLAHE, ICM, and RGHS methods all achieve varying levels of dehazing and color restoration on the original image, with RGHS performing the best in the fourth group of photos by naturally eliminating greenish hues. The HE and RD methods achieve strong color restoration on underwater images, resulting in images with richer colors than the real-world images and serious purple fringing around the objects. The UCM method performs comparably to FUnIE-GAN, but FUnIE-GAN outperforms in terms of clarity and color restoration. In the second group of photos, FUnIE-GAN successfully restores the blue ocean in the background, while UCM exhibits a brownish-green hue. Overall, the FUnIE-GAN method achieves the most balanced performance, with clear distinctions between targets and backgrounds in the enhanced images and restoration of more realistic textures and color features.
Then, we employed two non-reference evaluation metrics, UCIQE and NIQE, to objectively assess these various image enhancement methods. A random image from the dataset was selected as the original image, and the score of this image served as the baseline. The final results of the objective evaluation are presented in
Table 6.
From the results in
Table 6, it is evident that, except for GC and RGHS, all other methods exhibit improvement in image quality compared to the original images. FUnIE-GAN achieves the best performance in terms of the EIQE metric, with a score increase of 2.814 points compared to the original image. UCM obtains a score of 13.317, while HE and RD achieve scores of 12.924 and 11.294, respectively. Regarding the UCIQE evaluation metric, all methods, excluding GC, demonstrate improvement compared to the baseline. RD and HE receive scores of 0.6251 and 0.6139, respectively, while FUnIE-GAN achieves a score of 0.6035. It is noteworthy that RD and HE attain slightly higher scores in the UCIQE metric. We speculate that this might be associated with the evaluation criteria of UCIQE, which quantitatively assesses non-uniform color shifts, blurriness, and low contrast using a linear combination of chromatic standard deviation, saturation, and contrast. The higher saturation and contrast in RD and HE could contribute to their better performance in UCIQE. Furthermore,
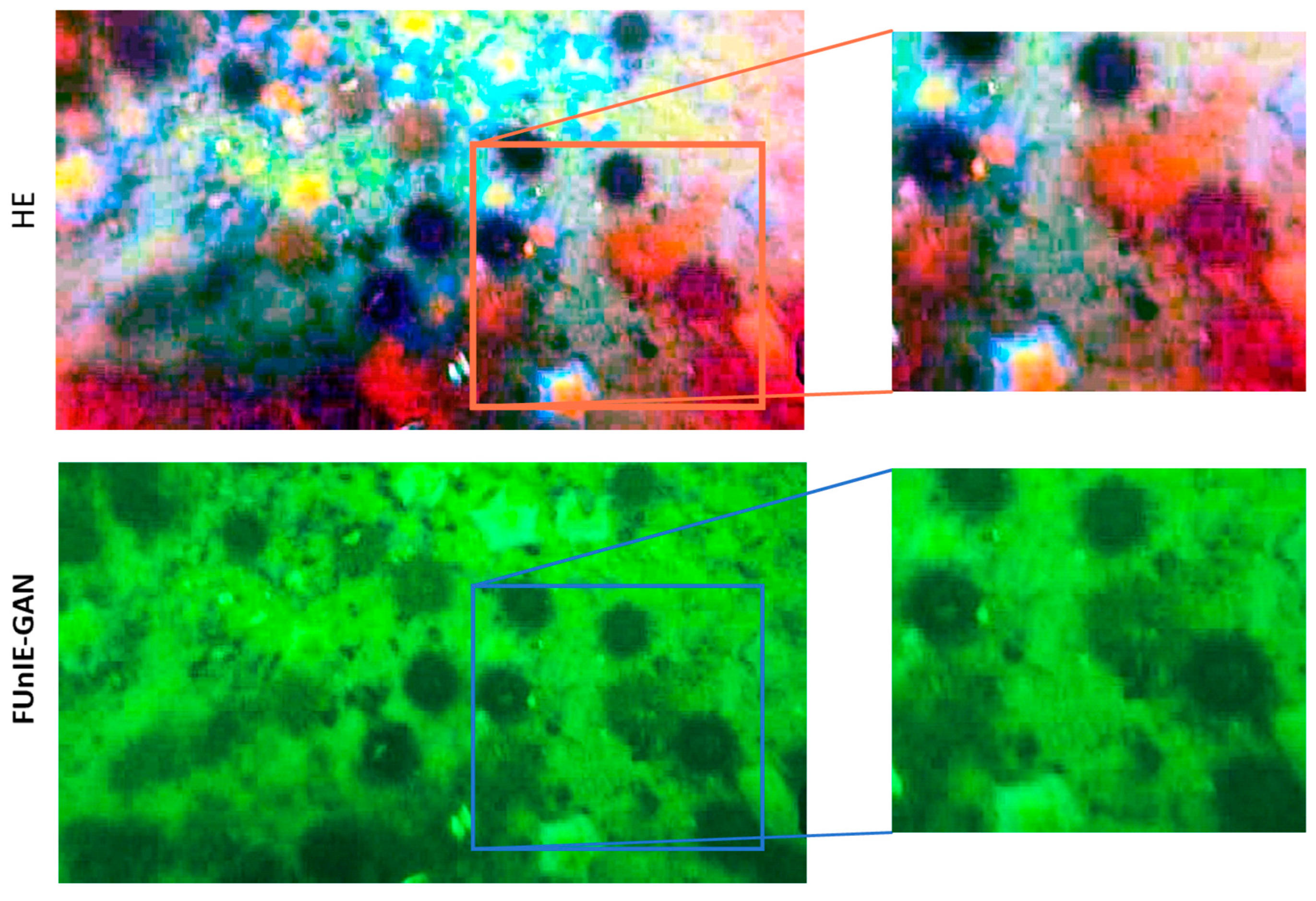
Figure 15 illustrates the detailed performance of FUnIE-GAN and HE methods on the fourth group of photos.
From
Figure 15, it is evident that the images enhanced by the HE method display a broad spectrum of colors but also experience significant local color distortions. In the magnified detail image, it is apparent that the sea urchin has lost its original color and is even subjected to hue shifts, particularly noticeable in the bottom right corner. This clearly impacts on the object detection task.
In conclusion, we assess the image enhancement effects from both subjective and objective perspectives. The evaluation results unequivocally illustrate that the FUnIE-GAN underwater image enhancement method attains a more comprehensive enhancement effect.
4.4.2. Evaluation of Object Detection Models after Underwater Image Enhancement
In order to investigate the potential impact of underwater image enhancement on object detection performance, we selected two relatively balanced methods, CLAHE and FUnIE-GAN, for testing. The enhanced datasets were incorporated into the YOLO-GN network during training, and the test results are presented in
Table 7. CLAHE-YOLOv7-GN denotes the use of CLAHE as the underwater enhancement method, while FUnIE-YOLOv7-GN designates the utilization of FUnIE-GN as the underwater enhancement method. From the experimental outcomes, we found that the CLAHE method achieved the highest improvement in object detection accuracy, but there was a decrease in recall rate and other metrics. This could be attributed to the fact that, in certain scenarios, CLAHE may render it challenging to differentiate between objects and the background, consequently resulting in an elevated rate of missed detections. The FUnIE-GAN method showed improvements in recall rate, F1 score, and mAP, with a 2.64% increase in mAP50:95 and a 0.16% increase in mAP50. In comparing the results of CLAHE and FUnIE-GAN, it is apparent that image enhancement algorithms aim to improve the perceptual quality of images to the human eye. However, improvements in image evaluation metrics do not necessarily correlate directly with improvements in object detection performance. Additionally, diverse underwater image enhancement methods may necessitate fine-tuning for better adaptation to various object detection tasks in different scenarios.
Figure 16 employs the Class Activation Mapping (CAM) feature visualization technique to produce weighted heatmaps, enabling a thorough comprehension and comparison of the detection performance and decision-making procedures among different enhancement methodologies. From the figure, we can see that predicting on the original unprocessed image led to many false positives due to the network showing a high interest in regions where there were no objects. The use of FUnIE-GAN reduced this issue without losing any targets. Although the RD method performed better than FUnIE-GAN in terms of the UCIQE evaluation metric, its actual object detection performance was consistent with our analysis and prediction. The excessive color enhancement interfered with the network’s judgment, making it difficult for the network to detect targets in the lower regions of test images. The YOLOv7-GN combined with the FUnIE-GAN paradigm was the final method proposed.
4.5. Comparison with Other Object Detection Methods
To objectively assess the effectiveness of YOLOv7-GN, we compare our method with several state-of-the-art (SOTA) object detection methods in this section, including Faster R-CNN [
18], the YOLOv5 series, and the latest YOLOv8 series. All experiments were conducted under identical environmental conditions and datasets, and the results are presented in
Table 8. The visual analysis of the results is depicted in
Figure 17.
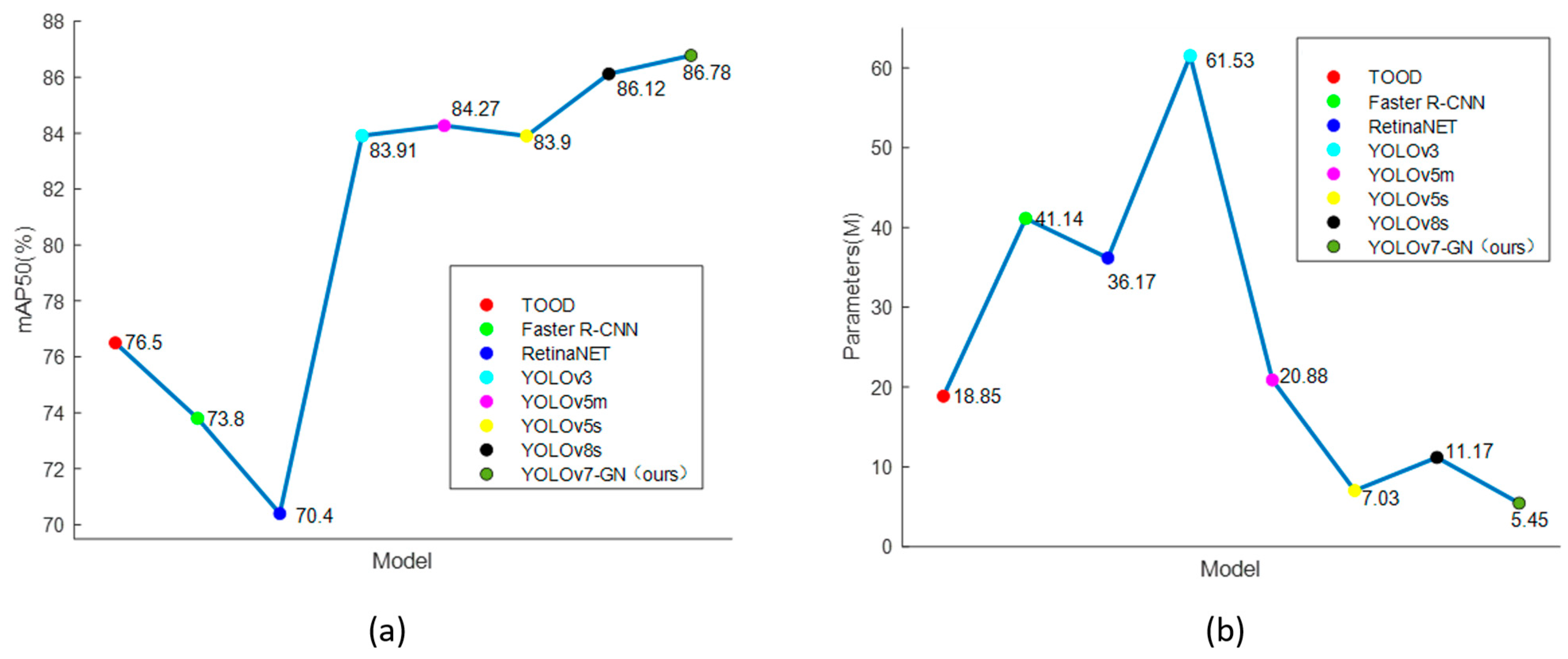
The F1 score reflects the network’s balanced performance in terms of precision and recall. YOLOv7-GN achieved an F1 score of 82.72, which is second only to the best result. Although YOLOv3 showed superior results in the F1 score, it experienced a 2.87% decrease in mAP50% compared to YOLOv7-GN, and the generated model size increased by 10.67 times. YOLOv7-GN demonstrated the best performance in terms of the mAP50% metric, with a 12.98% improvement over Faster R-CNN and a 2.88% improvement over YOLOv5s. It is noteworthy that YOLOv7-GN achieved these performance improvements with only 5.45 million parameters, fewer even than top-performing models such as YOLOv8s and YOLOv5s. In terms of network size comparison, YOLOv5s exhibited similar performance to YOLOv7-GN but significantly compromised accuracy.
4.6. Visual Result Analysis
In this section, we visualize the detection results and further analyze the differences in our method’s detection performance. Underwater object detection is affected not only by factors such as refraction and scattering of seawater, which can cause image blurring, but also by the clustering of underwater organisms. This can lead to multiple overlapping targets, and the varying distances between the captured images and the targets can result in multi-scale transformations, which pose a great challenge to underwater object detection models. We randomly selected six test images for visual comparison and further analysis of the detection results, as shown in
Figure 18.
From the detection results, both models exhibit good performance when the image background is simple and the target stands out. However, in cases where target overlap occurs, such as in the first group of images, the baseline model experiences missed detections. When the target background is complex, YOLOv7-GN detects objects with higher confidence and demonstrates fewer instances of missed detections compared to the baseline model. We have achieved superior performance while compressing the model size, further validating the effectiveness of the improvements proposed in YOLOv7-GN.
To visually illustrate the advantages of YOLOv7-GN, we present the feature attention effects in the form of heatmaps, as depicted in
Figure 19.
From
Figure 19, it is evident that compared to YOLOv7, YOLOv7-GN significantly enhances the focus on the target region by incorporating a lightweight higher-order attention aggregation network. The network concentrates attention more on the core features of the target, effectively suppressing other noise and unrelated features in the image. This observation suggests that YOLOv7-GN exhibits enhanced robustness.
4.7. Embedded Deployed Results
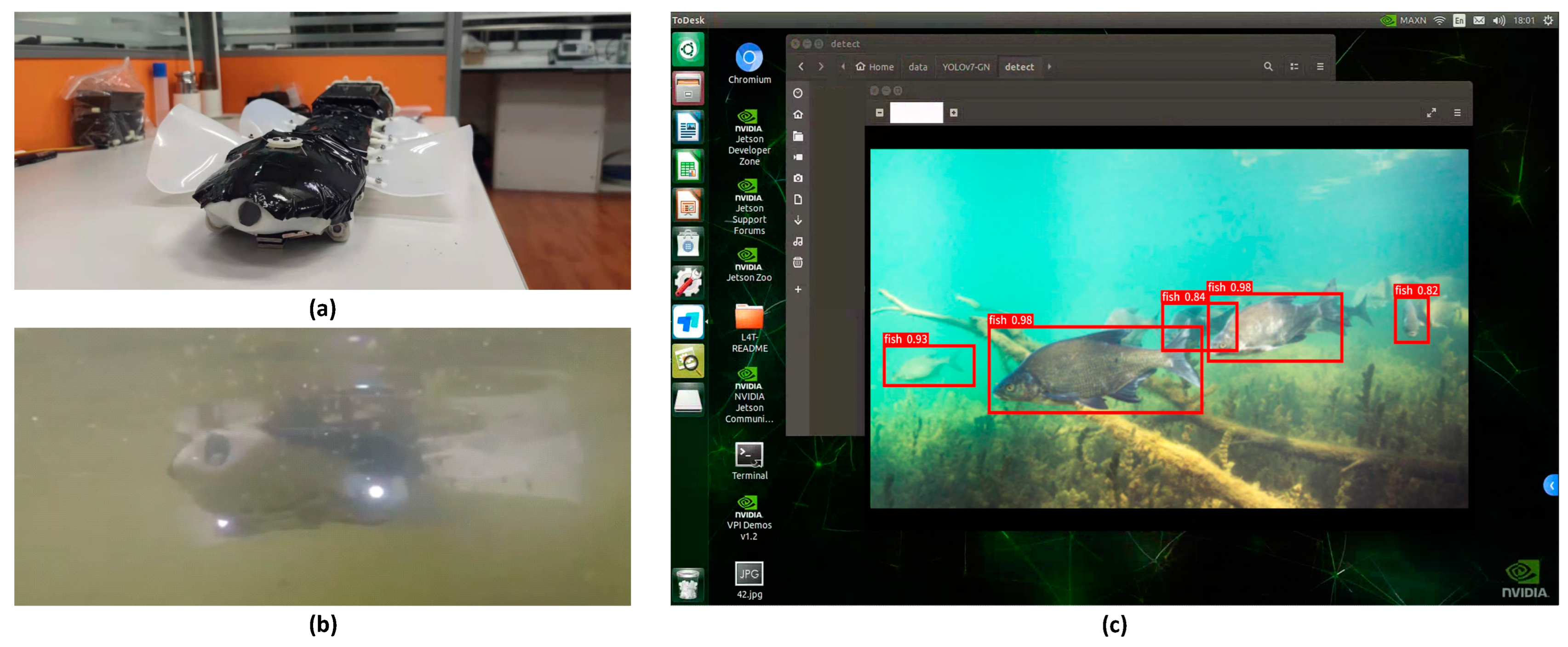
To assess the feasibility of deploying our proposed lightweight model on embedded devices, we designed a biomimetic flatworm underwater robot to validate the algorithm’s practical applications. Illustrated in
Figure 20, this robot utilizes a reciprocating crank rocker mechanism as a power transmission component, employing a drivable flexible skeleton to transmit power. It also features drive fins that oscillate reciprocally, generating a stable waveform to propel the robot forward. We integrated a Jetson Nano [
80] as the visual processing module at the tail of the biomimetic robot, connecting it to the camera module at the robot’s head via a data cable, thereby establishing the visual system of the biomimetic robot.
After assembling the biomimetic robot based on the model, we evaluated the feasibility of deploying our method on embedded devices in an actual underwater environment. Initially, we implemented YOLOv7-GN on the Jetson Nano embedded host computer. Jetson Nano, a small and cost-effective artificial intelligence (AI) computer developed by NVIDIA, incorporates a high-performance NVIDIA Maxwell architecture GPU and a quad-core ARM Cortex-A57 processor known for its exceptional energy efficiency. This device supports various AI frameworks, including TensorFlow, PyTorch, and Caffe, enabling the development and deployment of deep learning models on edge devices. In comparison to the mainstream embedded deep learning development board Jetson TX2, Jetson Nano has 2.75 times less computing power, imposing more stringent requirements on model size deployment. Nevertheless, our method operates smoothly on Jetson Nano, providing a comprehensive visual system. As illustrated in
Figure 21, we fabricated the biomimetic robot and conducted relevant underwater tests.
In the tests, we compare mainstream embedded-oriented object detection models with YOLOv7-GN, including YOLOv7-tiny and YOLOv5s, on this robot. Their corresponding scheme EM-YOLOv7-tiny, EM-YOLOv5s, and EM-YOLOv7-GN. The results are presented in
Table 9. Besides the key metrics, the table displays the accuracy for each category. According to the experimental results, EM-YOLOv7-GN achieves the highest mAP and boasts the smallest parameters and GFLOPs. EM-YOLOv5s exhibits the highest AP value for object recognition in both Echinus and Starfish categories, while EM-YOLOv7-tiny demonstrates a more balanced performance. These results demonstrate the superior balance between accuracy and network size that EM-YOLOv7-GN provides on embedded platforms.
In conclusion, we have conducted both theoretical verification and practical deployment testing of the algorithm. Through the final practical validation, we have seen the possibility of actual application implementation of YOLOv7-GN, rather than just staying at data comparison and theoretical analysis.
5. Discussion
In the domain of underwater object detection, relying solely on 2D convolutions is insufficient for capturing deeper feature information due to substantial environmental variations and diverse target scales and morphologies. The utilization of global attention to capture features would not only escalate the training model’s cost but also substantially increase the overall network size, contradicting our initial goal of developing lightweight networks deployable on embedded devices [
55,
56]. We assert that the key to achieving superior performance with YOLOv7-GN lies in the paradigm of combining convolution and self-attention. This approach not only integrates high and low-frequency information but also strikes a balance between speed and accuracy. Moreover, through network structure design, we have empowered the network to enhance its fusion perception capability of multi-scale higher-order features without an increase in the number of parameters.
In this study, we completed the deployment of the proposed YOLOv7-GN on an underwater robot for practical testing. During the testing phase, we observed limitations in our method. Firstly, the initialization of the model takes longer due to hardware performance constraints. Secondly, the camera transmits jittery images during actual operation due to the robot’s motion mode, posing challenges for the object detection model. The robot scheme discussed in the paper represents our preliminary design, and we plan to enhance both the hardware and software aspects of our program for further improvements.
In our future work, we plan to explore the utilization of our method as a pre-task for object tracking, a prominent research area in computer vision. Object tracking involves continuously monitoring the position of an object in a video sequence and updating its location in response to movement, deformation, or occlusion. Object tracking is widely used in various fields such as remote sensing video target tracking, species conservation, etc. Many object tracking systems utilize object detection to initialize the tracker, providing the initial position and bounding box of the target. We hypothesize that employing our method as a pre-task for object tracking will not only enhance the performance of object tracking but also contribute to making the entire system more lightweight. In the upcoming research, we aim to validate this hypothesis.
Furthermore, we will consider the migration capability of our method in different application scenarios. In our practical research, we have identified several application scenarios in the object detection that pose challenges, such as color shifts in the original image, transformations of the target scale, and similarities between the target and the background. These scenarios include satellite remote sensing images and target detection in UAV aerial images. In UAV aerial image object detection, the color shift of the original image occurs due to the weather or to the noise source generated by the photosensitive element in the equipment. Most notably, UAVs are embedded devices like underwater robots, and the vision system of UAVs also requires a lightweight model to enable more sophisticated control and versatile functionality. Thus, we will extend the application of our method to the task of object detection in remote sensing images from UAVs and explore the possibility of its application in additional fields.


 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}