Off-Line Training Phase
The first stage in the training phase is acquisition of training data. In the virtual environment, thruster faults are simulated by varying properties of the thruster dynamic model (load, friction, etc.) inside the propulsion subsystem of the ROV dynamics simulator. In the real-world environment, various jammed propeller faults are simulated such that the objects of different sizes, shapes and weights were attached to the blades, while a broken propeller was simulated with all blades removed from the shaft. Further details about acquisition of training data in real-world environment is given in the following. A normal state and four different fault cases were considered (lightly jammed, jammed, heavily jammed and broken (lost) propeller). A test rig has been set up and thruster mounted in a test tank in the University of Limerick. To mimic the jammed thruster states various objects (“blockages”) have been attached to the thruster propeller during tests. The thruster test setup and “blockages” are shown in
Figure 4. Each “blockage” reduces efficiency of the thruster due to increased load on the shaft and reduced flow of the water through the duct.
The relationship between the thruster states and setup for real-world data acquisition is given in
Table 4. For each state in
Table 4, the thruster was actuated with a saw-like command signal
(%) with the following pattern: 0% »
MAX% » 0% »
−MAX% » 0%, with a step size 1%
. The total duration of signal was 20 s, sampling period 50 ms and max. value
MAX = 100%. In each iteration the desired shaft speed
(%), actual shaft speed
(rpm) and current consumption
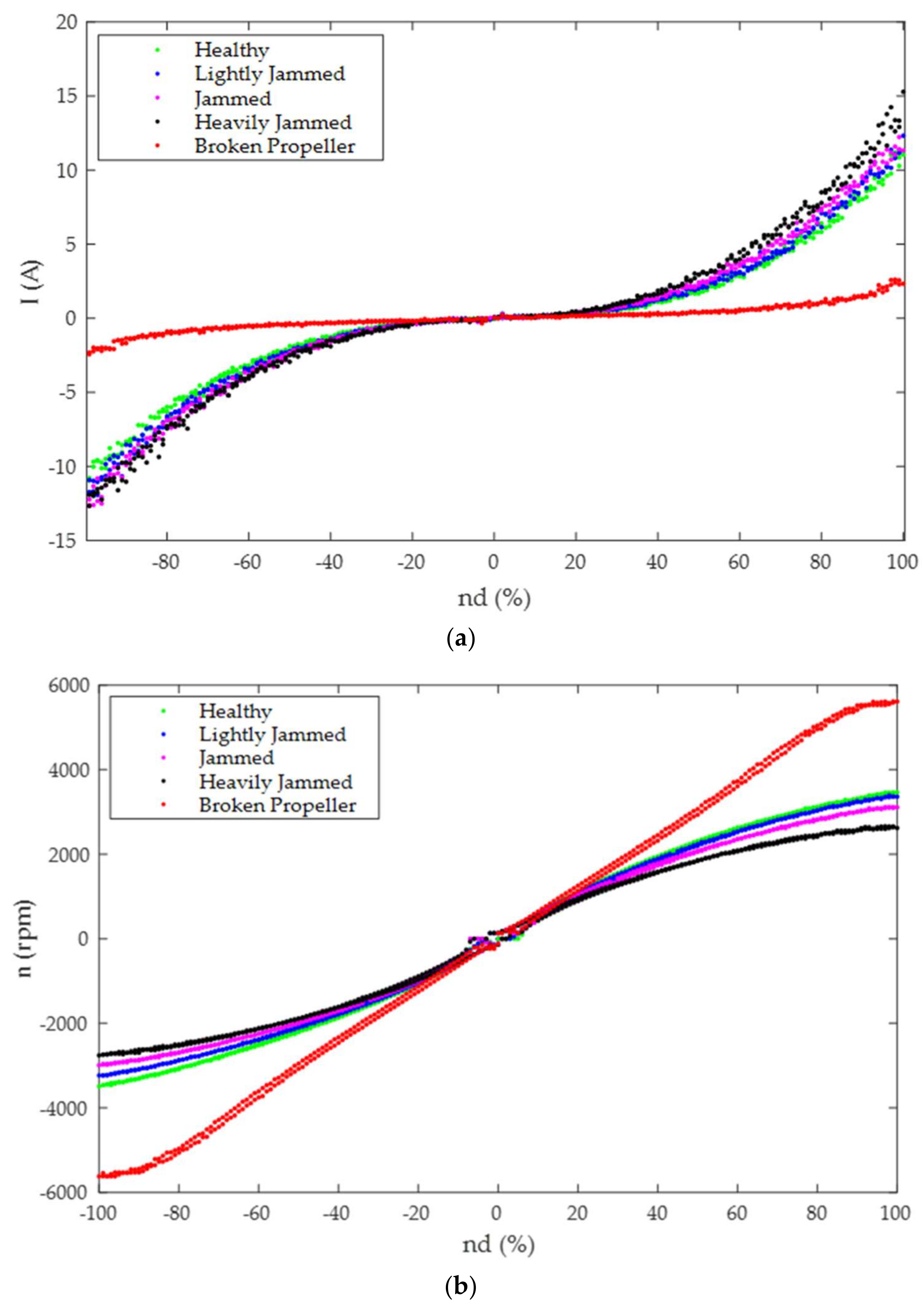
(A) have been logged. The real-world raw data acquired for each thruster state are presented in
Figure 5.
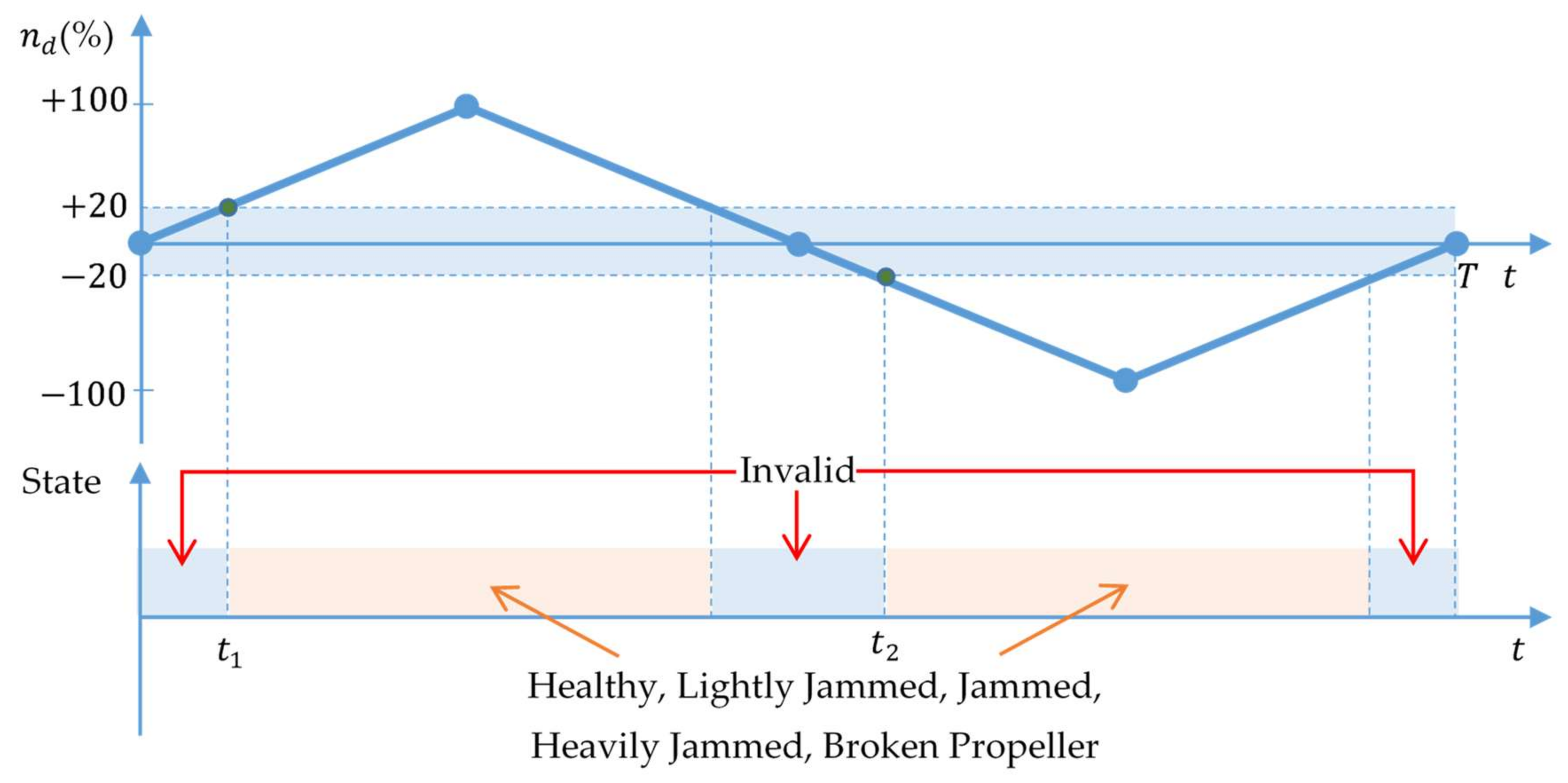
Analysing the distribution of the training data in
Figure 5, the first feature that can be noticed is that each fault type creates a certain pattern. The presence of measurement noise is noticeable in acquired data for currents, resulting in patterns which exhibit a fuzzy (“cloudy”) look. The second feature is that it is very difficult to distinguish individual patterns in the zone around
(called the
critical zone). This makes successful fault detection and isolation in the critical zone difficult to achieve. In particular, for the near-zero velocity case
the thruster does not rotate or rotates very slowly, reliable fault detection is impossible. The solution to this issue is the exclusion of the critical zone from FDI during the on-line fault detection phase. For this reason, the critical zone is called the
forbidden zone with associated “Invalid” thruster state. When desired shaft speed is in this zone, the FDI algorithm goes to sleep mode and outputs the “Invalid” state without any action.
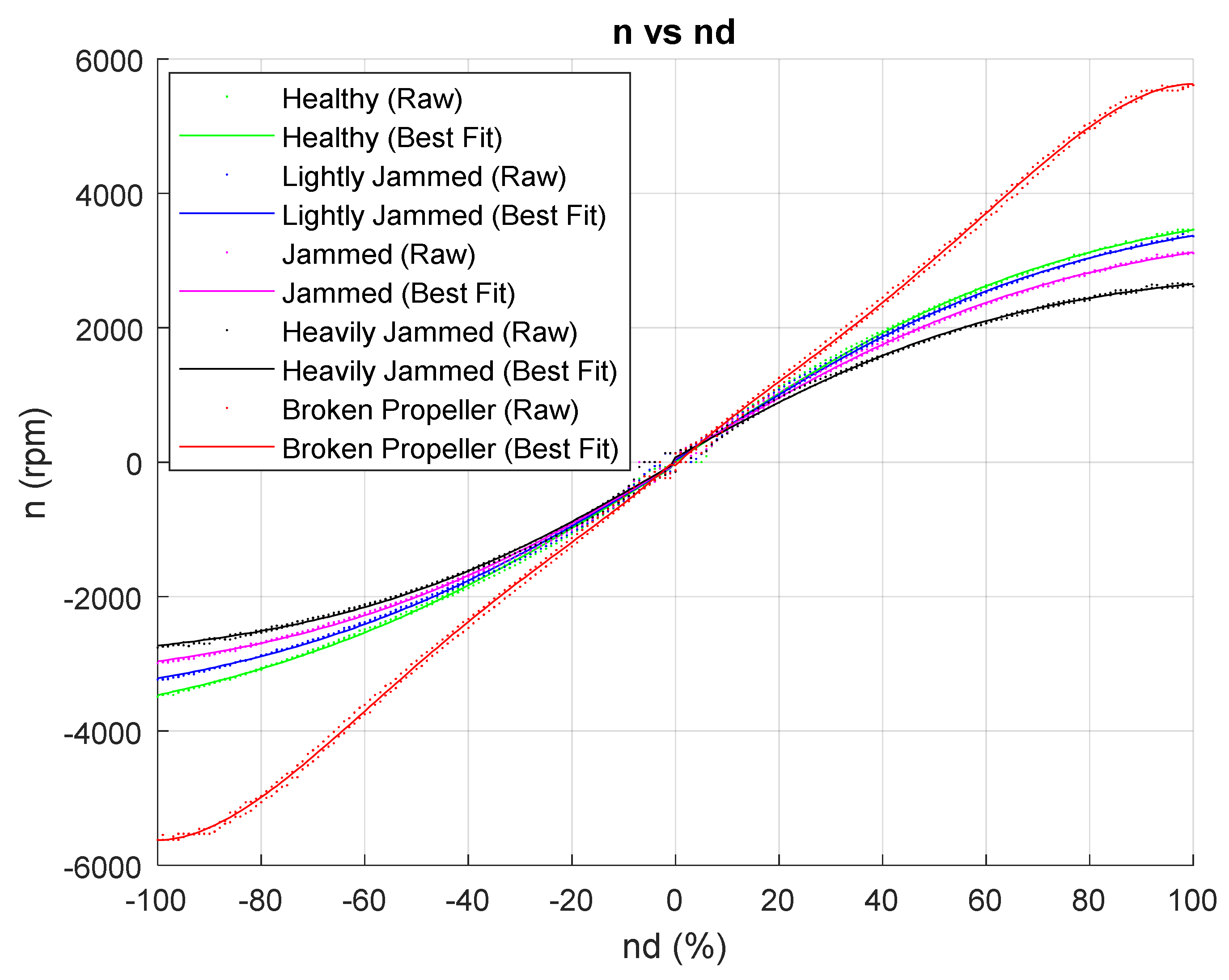
Each fault type in
Figure 5 is characterised by specific features, which makes them different from the other types. These features are discussed in the following. In general, all the variables (
,
and
) are correlated, i.e., they tend to rise and fall together in a non-linear way. For lightly jammed, jammed and heavily jammed propeller states, objects (“blockages”) attached to the blades generate an additional load for the motor, leading to higher current
and lower
than in the fault-free case for the same value of
. In the case of a broken propeller, the absence of the blades means that the load for the motor is much smaller than in other cases, yielding a reduction in current consumption and a significant increase in shaft speed. However, the thruster does not generate any propulsion force in this case.
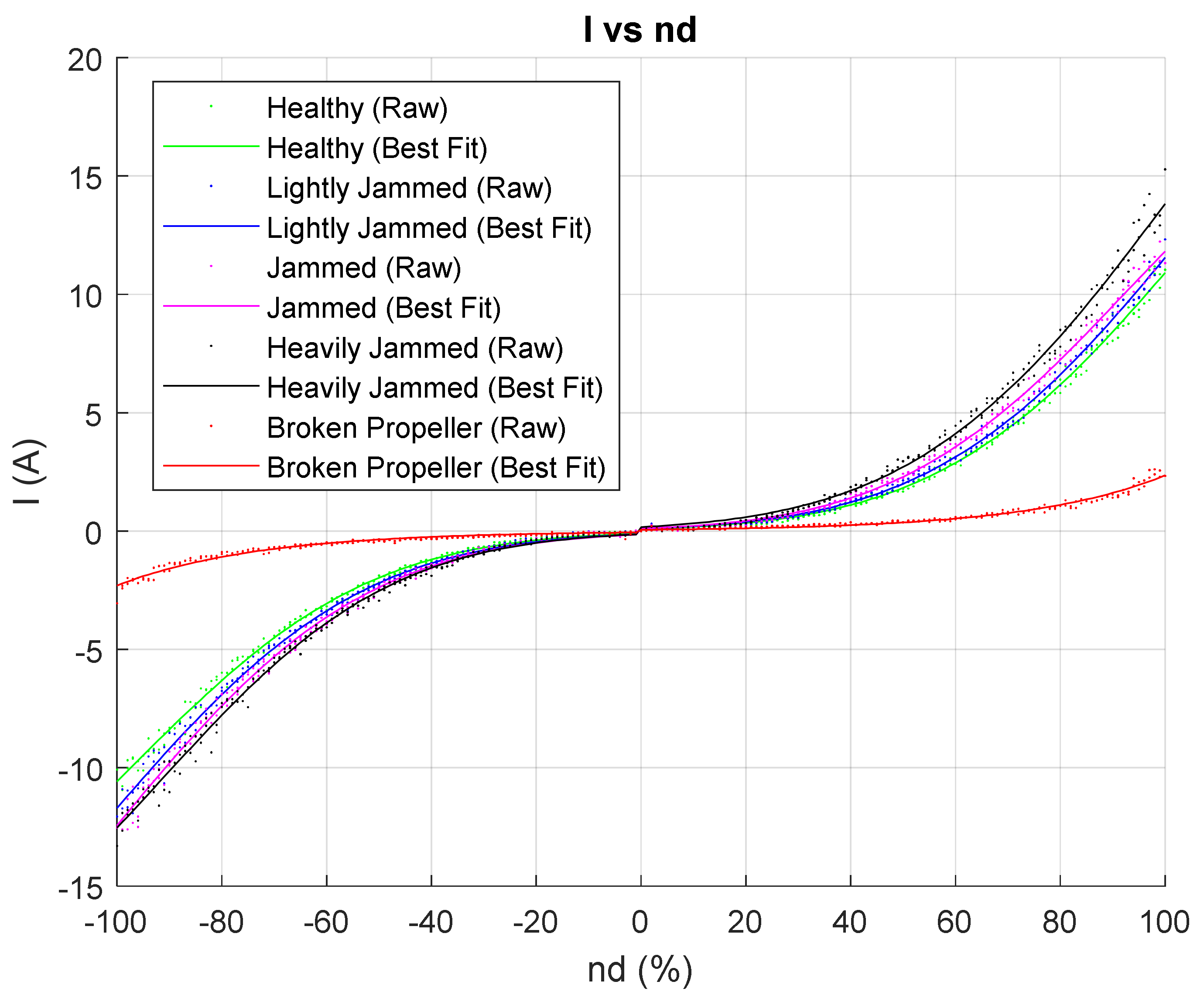
The main idea of the
second stage in the training phase is to use the acquired data from the first stage to train a Pattern Recognition Neural Network (PRNN). In order to improve the PRNN classification accuracy, the raw data shown in
Figure 5 have been first replaced with best fit curves, as shown in
Figure 6 and
Figure 7, before creating input-output data sets for NN training. The MATLAB App “Curve Fitting” has been employed to generate best fit curves. Details of the Curve Fitting functions and their parameters can be found in
Table 5.
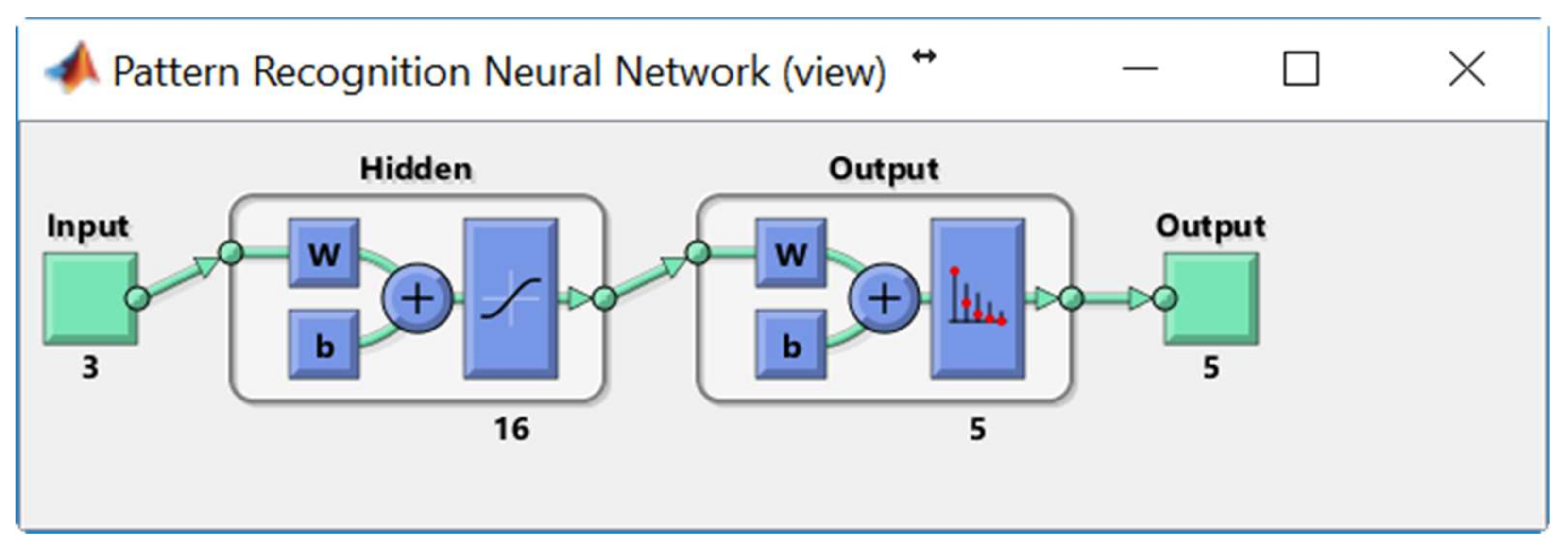
A two-layer feed-forward network, with 16 sigmoid hidden and 5 softmax output neurons has been trained to classify input vectors. The architecture of the Pattern Recognition Neural Network is shown in
Figure 8.
As indicated in
Table 4, there are five classes (Healthy, Lightly Jammed, Jammed, Heavily Jammed and Broken Propeller). The input data set (matrix thrusterInputs_RWE) has dimension 3 × 1005 and consists of five Input Blocks: thrusterInputs0_RWE, thrusterInputs1_RWE, thrusterInputs4_RWE (one block for each class, see
Table 6). Network inputs are stored in columns of the matrix thrusterInputs_RWE. For each class, values of
are −100, −99, +99, +100.
The target data set (matrix thrusterTargets_RWE) has dimension 5 × 1005 and consists of five Target Blocks: thrusterTargets0_RWE, thrusterTargets1_RWE, thrusterTargets4_RWE (one block for each class, see
Table 7). For class
k columns of corresponding Target Block have
1 at position
k, while all other column elements have value 0.
Algorithms used in PRNN training are provided in
Table 8.
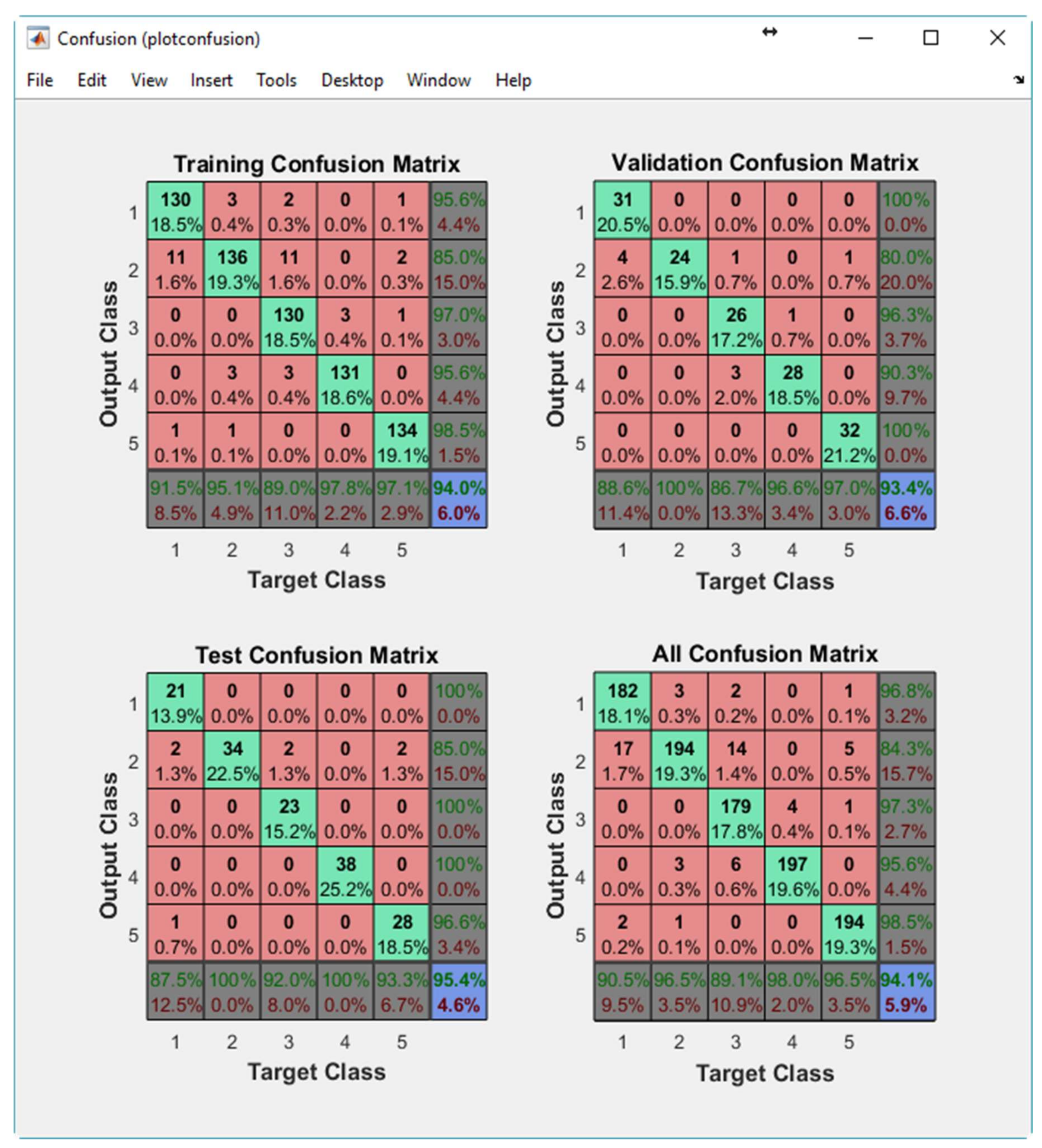
The input matrix thrusterInputs_RWE has been randomly divided up into training samples (70%), Validation samples (15%) and Testing samples (15%). These samples were presented to the network during training, and the network was adjusted according to its error. Validation samples were used to measure network generalization, and to halt training when the generalization stops improving. The testing samples have no effect on training and provide an independent measure of network performance during and after training. The training, Validation and Confusion Matrices are shown in
Figure 9. On the confusion matrix plot, the rows correspond to the predicted class (Output Class), and the columns show the true class (Target Class). The diagonal cells show for how many (and what percentage) of the examples the trained network correctly estimates the classes of observations. That is, it shows what percentage of the true and predicted classes match. The off diagonal cells show where the classifier has made mistakes. The column on the far right of the plot presents the accuracy for each predicted class, while the row at the bottom of the plot shows the accuracy for each true class. The cell in the bottom right of the plot shows the overall accuracy.
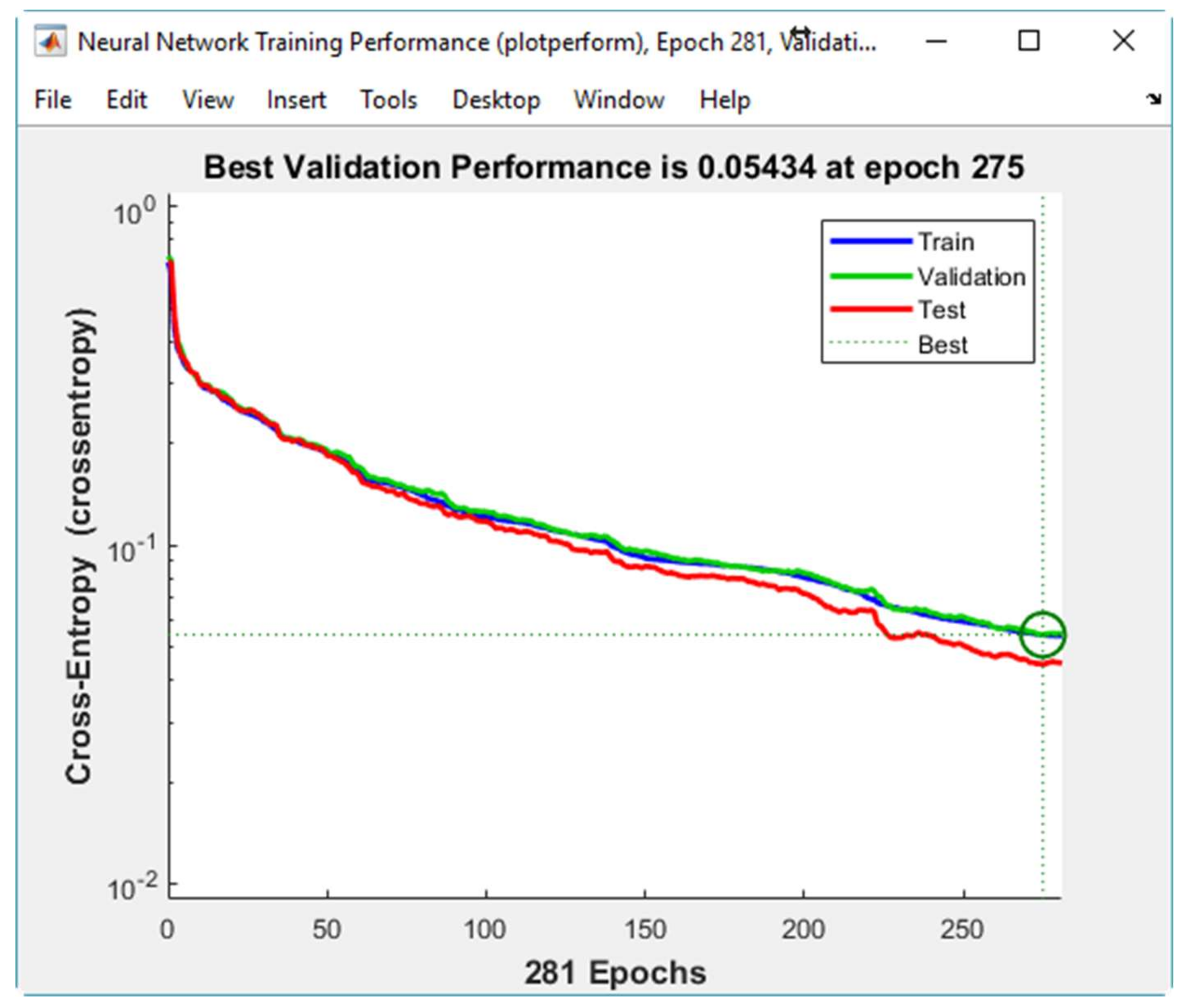
Figure 10 displays the Neural Network Cross-Entropy and Performance plots. Minimizing Cross-Entropy within the neural network results in enhanced classification.
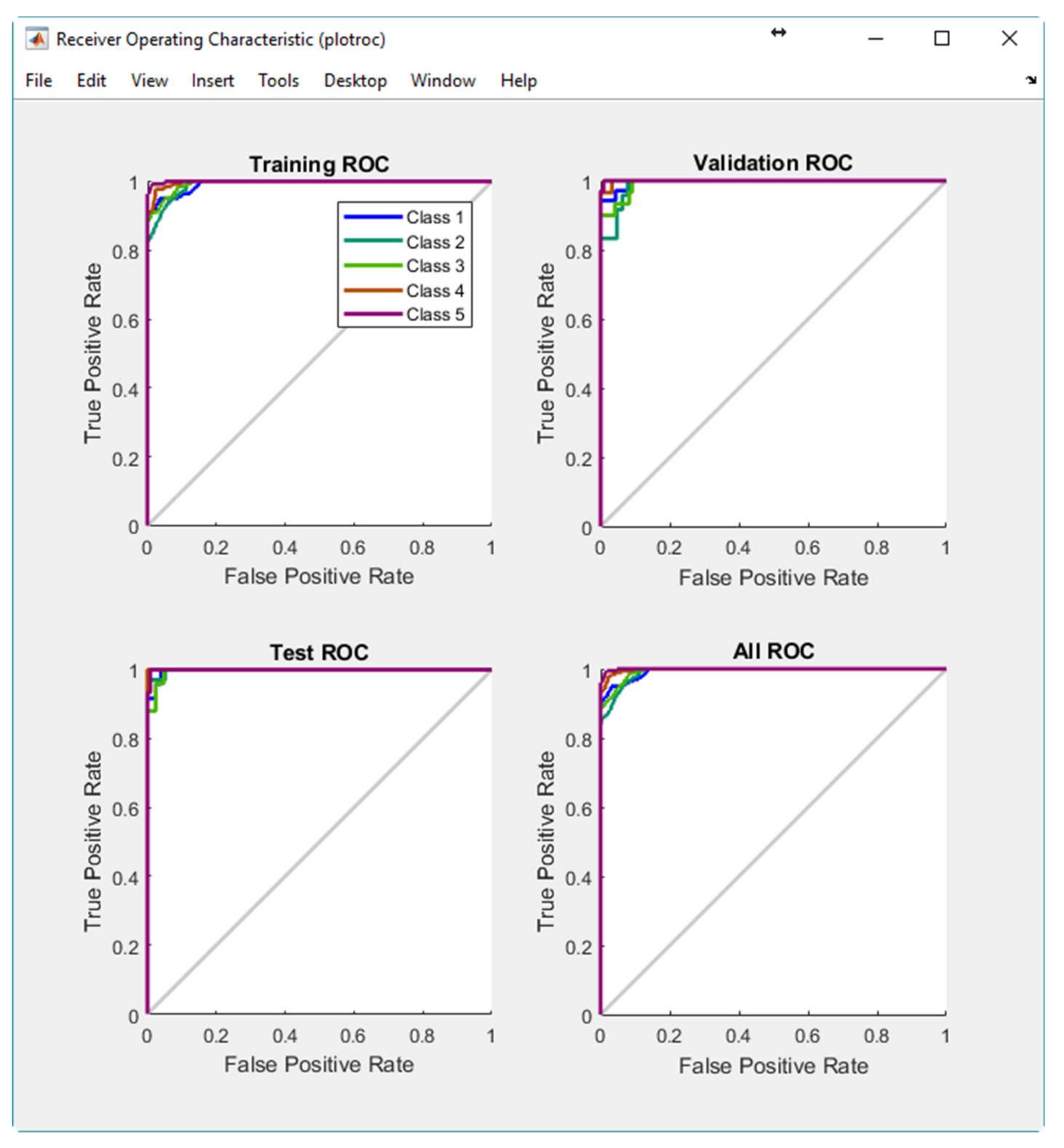
The Receiver Operating Characteristic (ROC) is a metric employed to check the quality of classifiers. For each class of a classifier, the ROC applies threshold values across the interval [0, 1] to outputs. For each threshold, two values are calculated, the True Positive Ratio (TPR) and the False Positive Ratio (FPR). For a particular class
i, the TPR is the number of outputs whose actual and predicted class is class
i, divided by the number of outputs whose predicted class is class
i. The FPR is the number of outputs whose actual class is not class
i, but predicted class is class
i, divided by the number of outputs whose predicted class is not class
i.
Figure 11 displays the ROC for each output class of PRNN. The more each curve hugs the left and top edges of the plot, the better the classification.
The classification performance of the PRNN in the real-world environment is verified in
Section 4.
In the third and last stage of the training phase, the structure of the trained PRNN is saved as a MATLAB function nn_pr_16_RWE on the hard disk for future use. In this way, time consuming training calculations are performed off-line, during the training phase, which enables fast and efficient detection during the on-line phase.
On-Line Fault Detection Phase
From the preceding discussion, the problem of thruster fault detection is considered as a pattern recognition problem. An original method for on-line fault detection, adapted to the specific features of the underlying pattern recognition problem, will now be described.
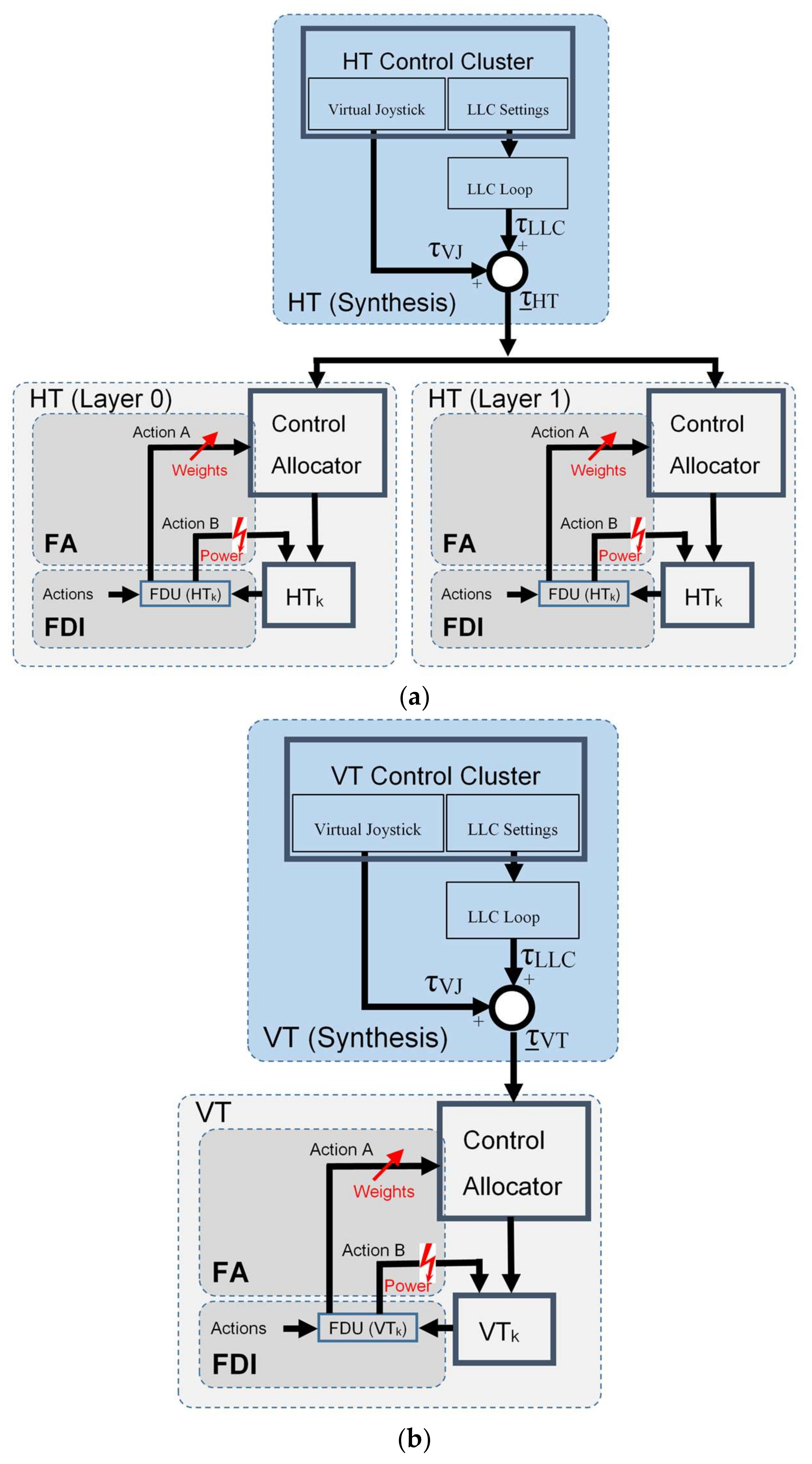
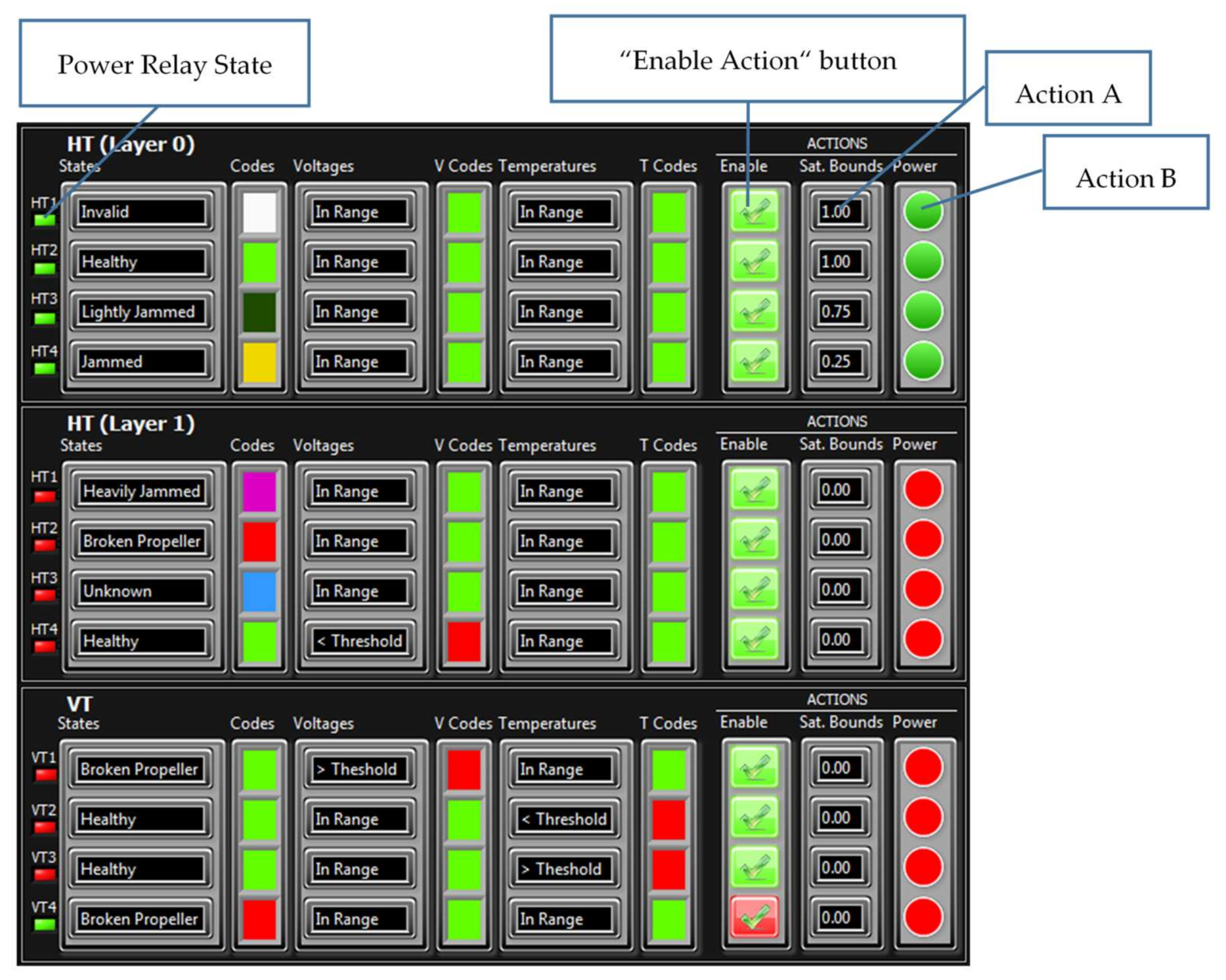
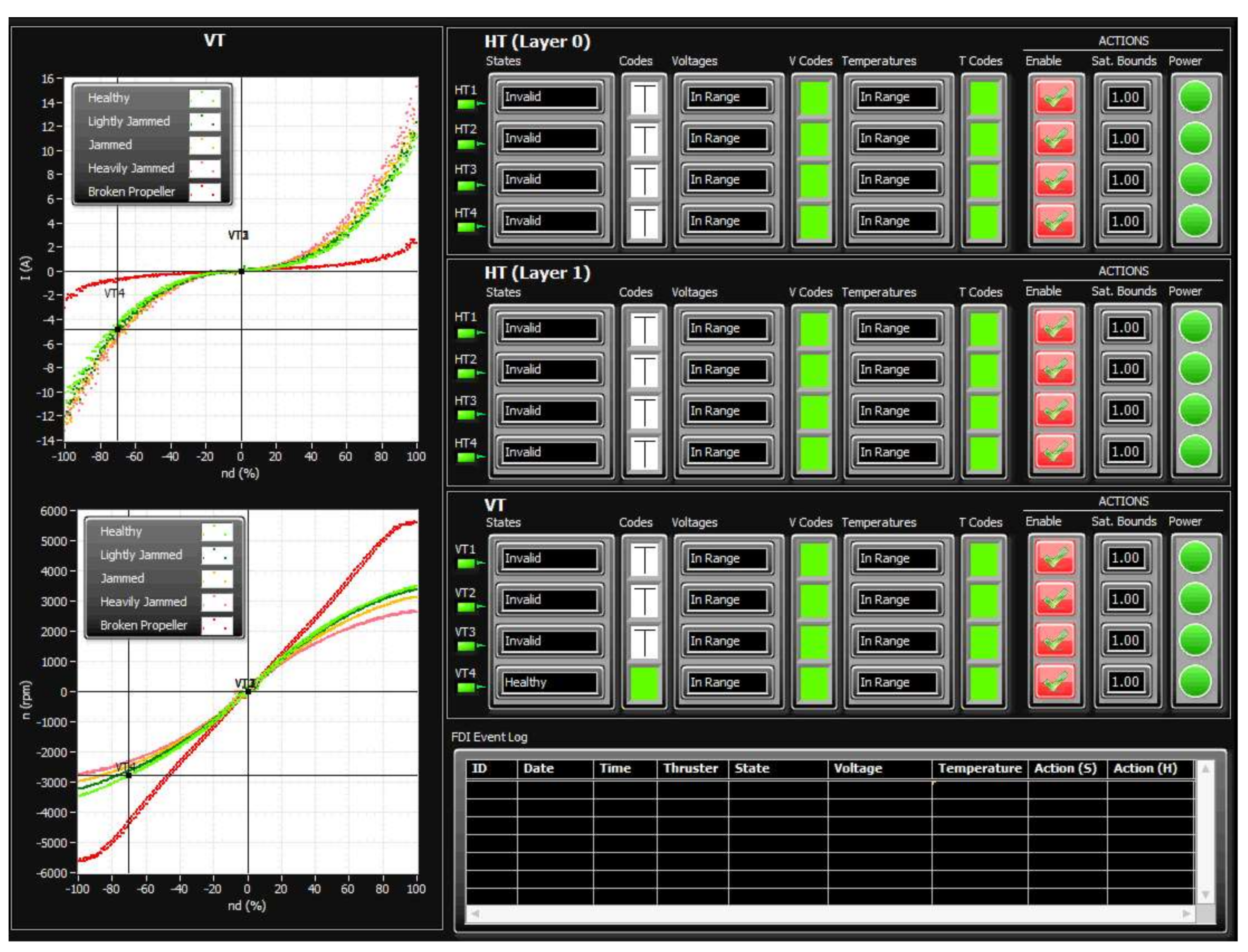
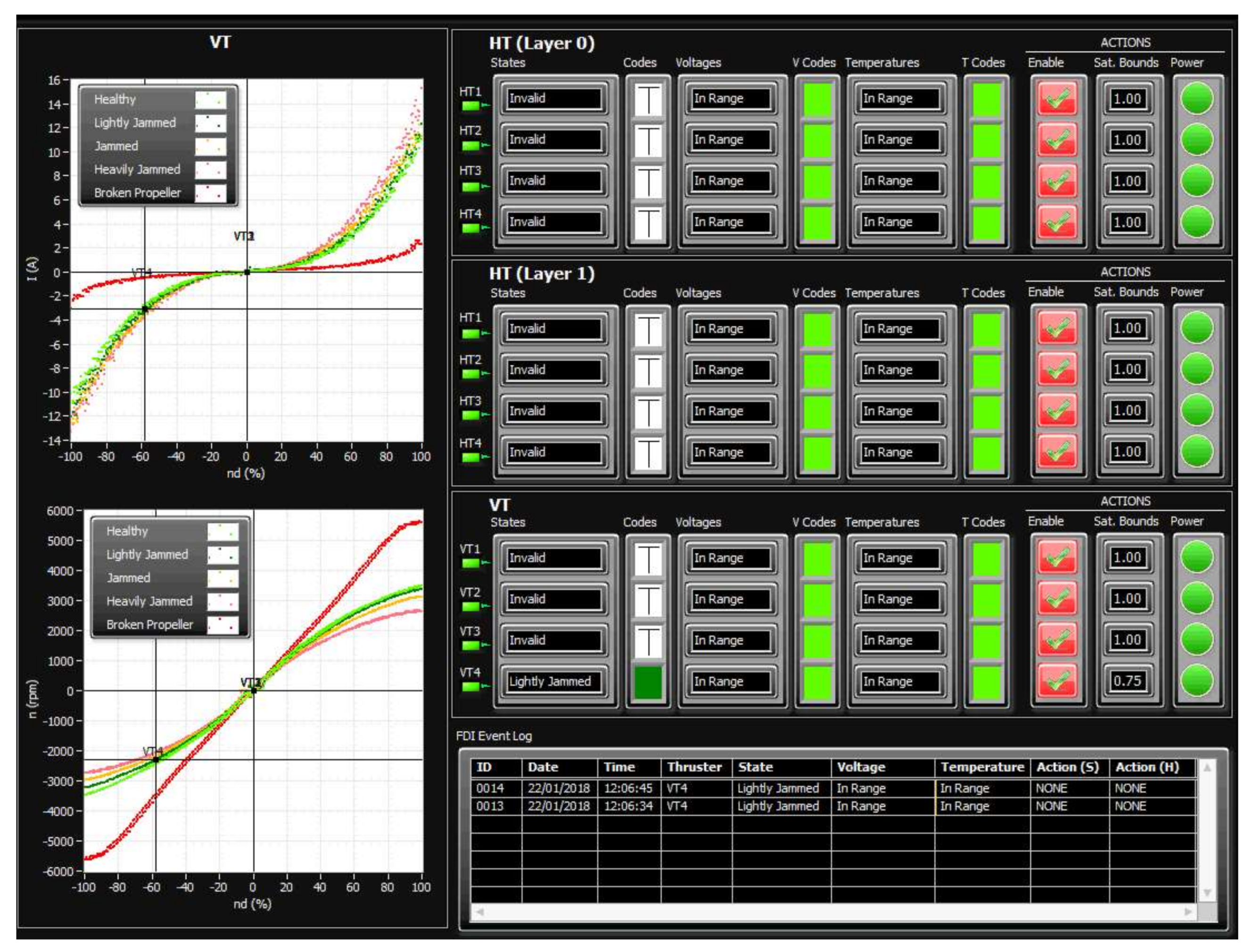
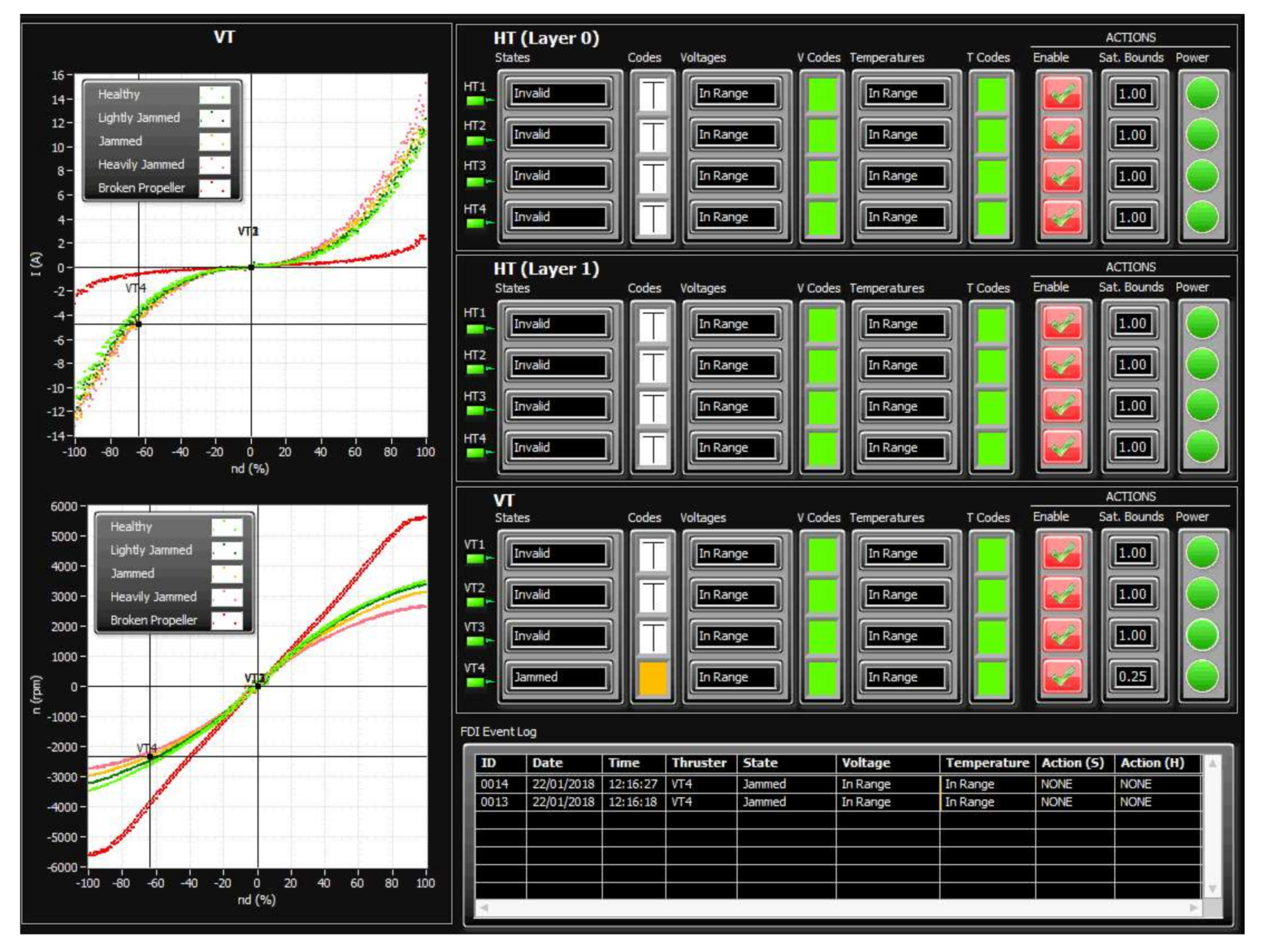
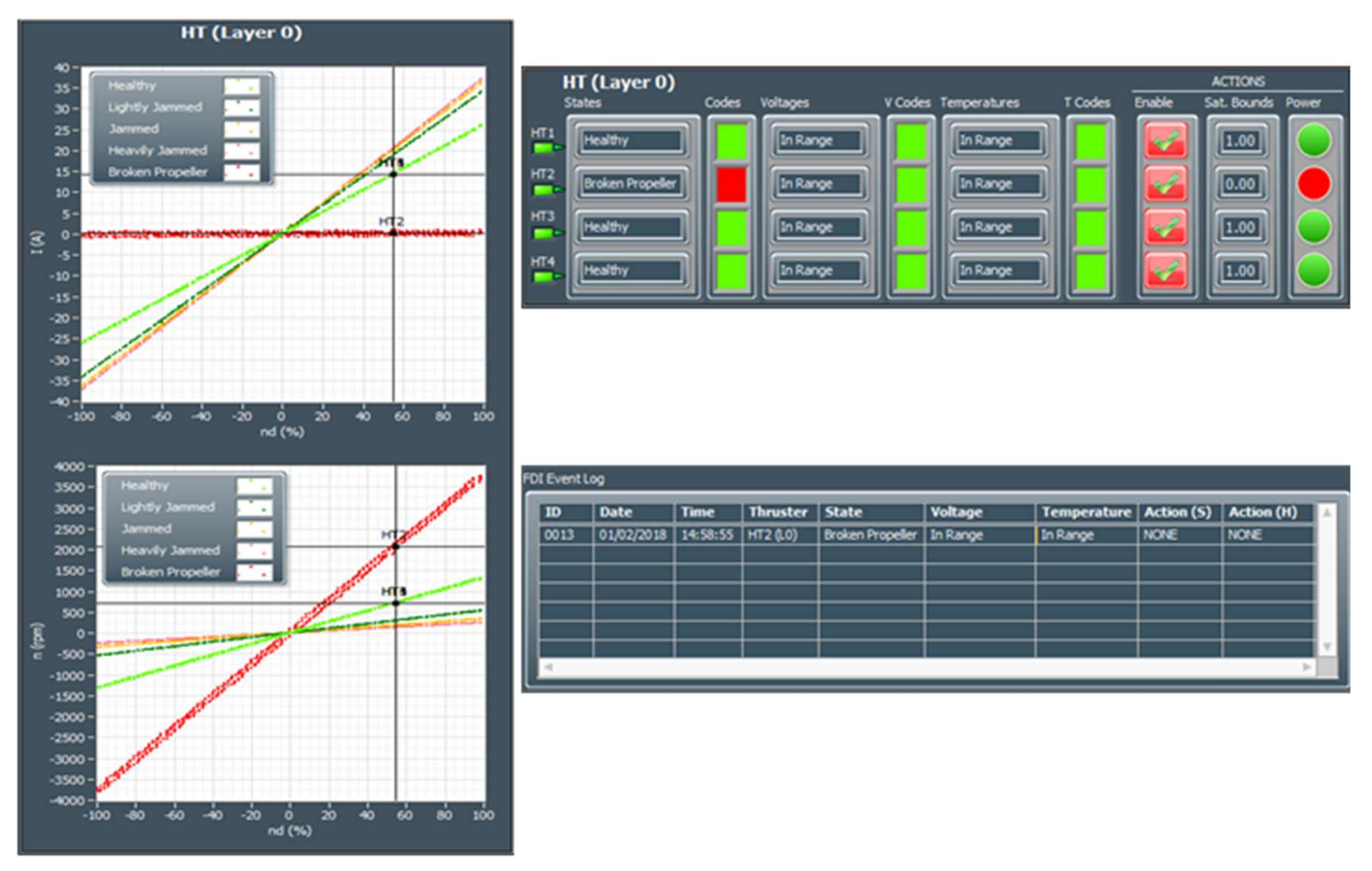
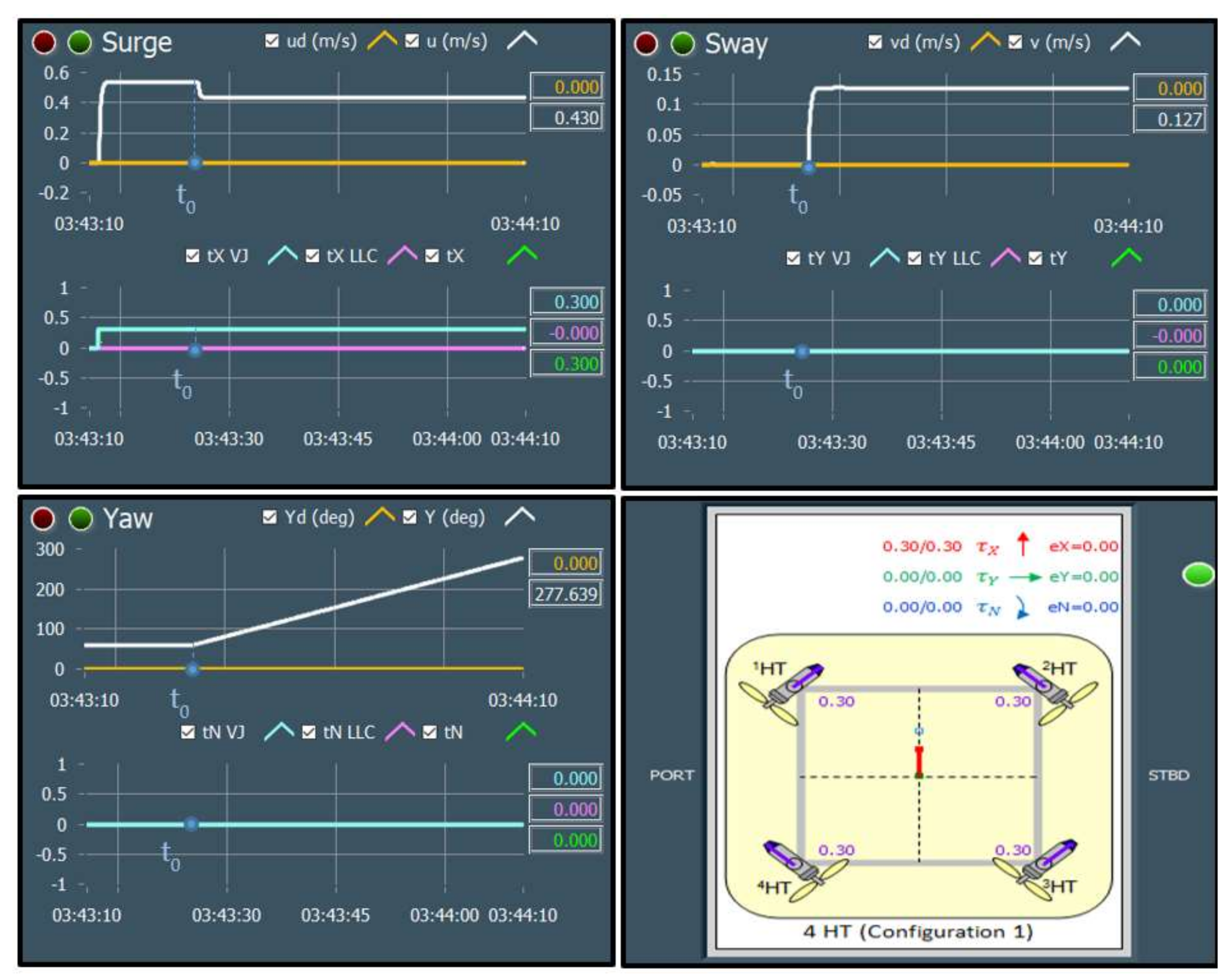
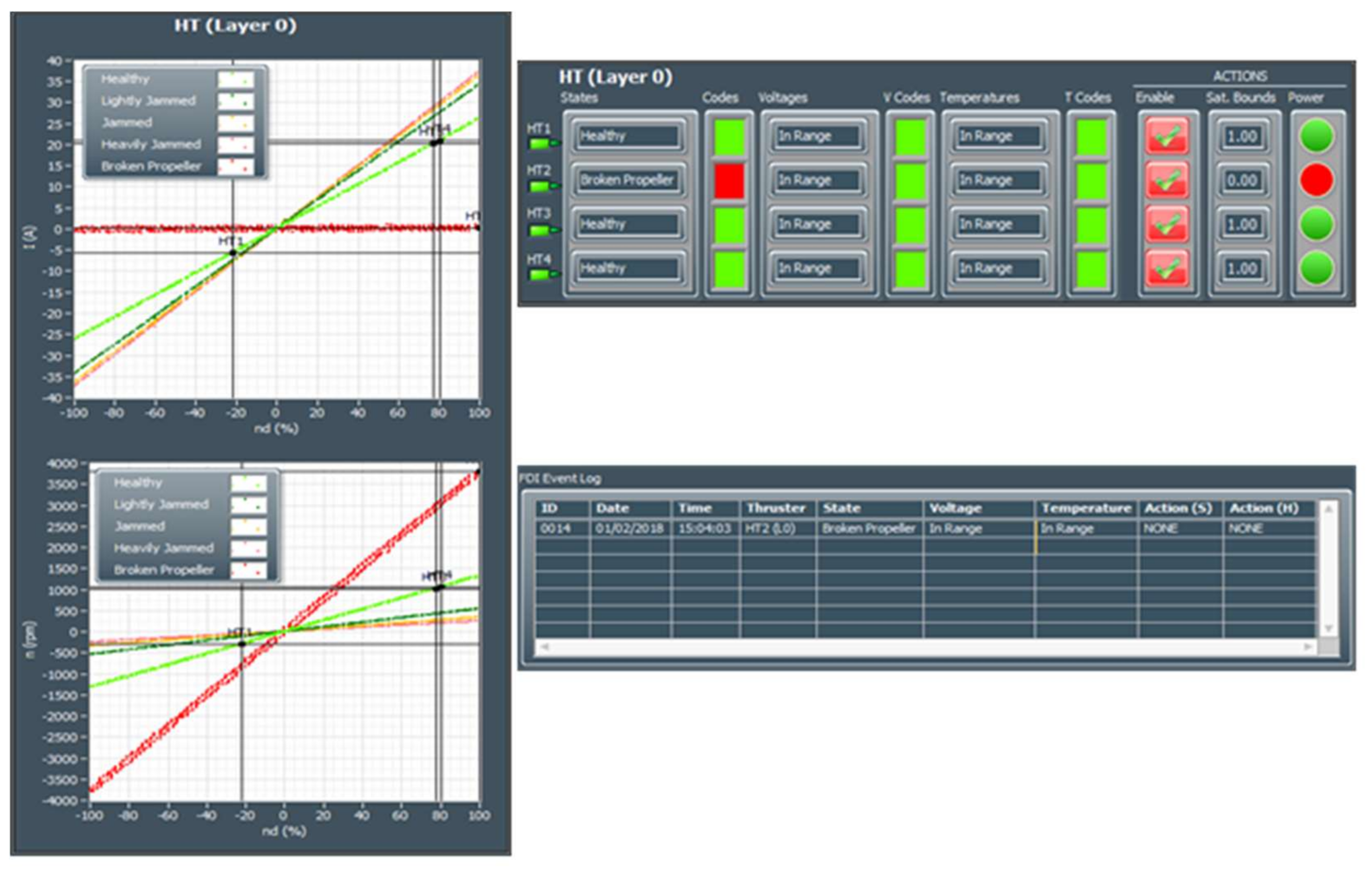
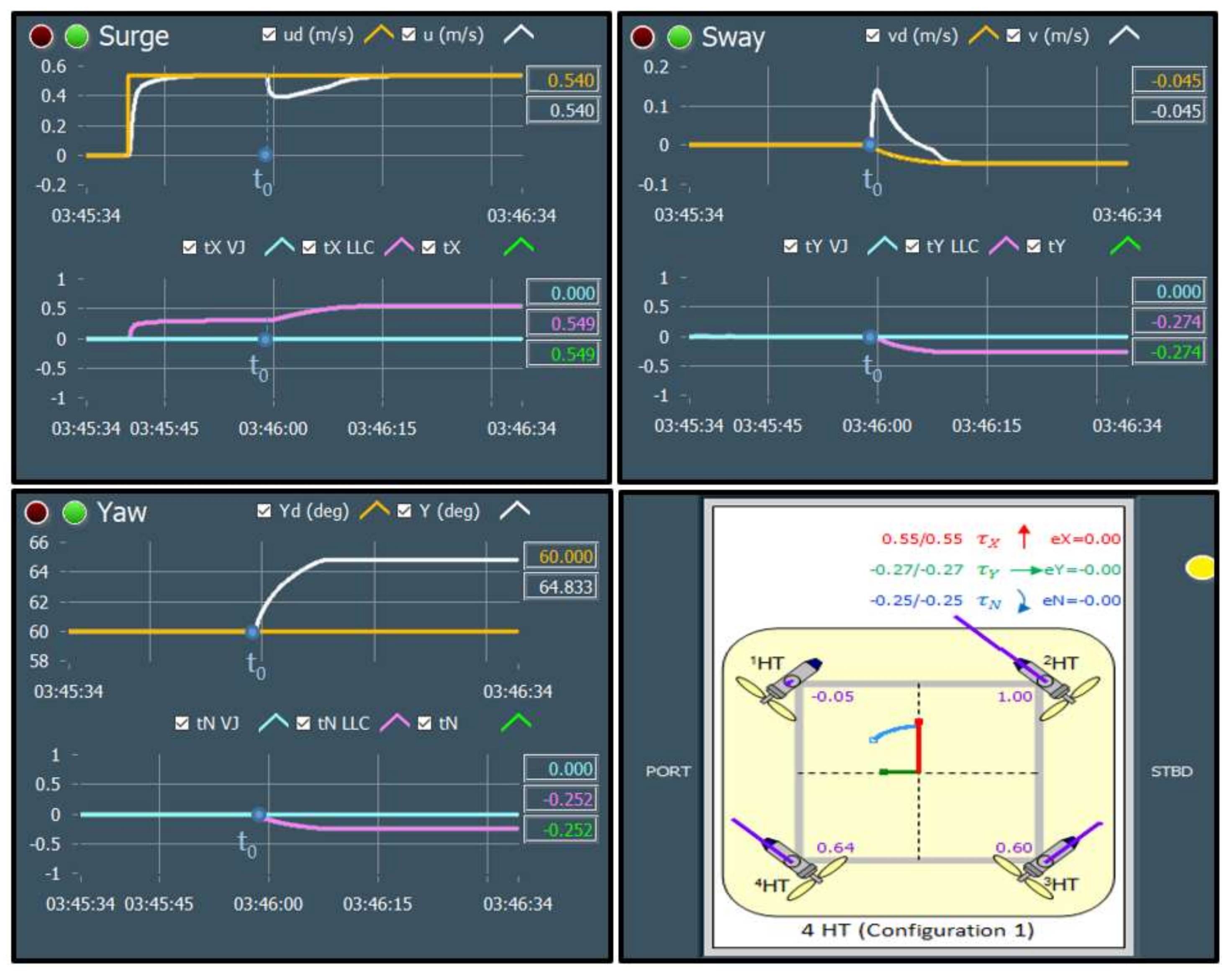
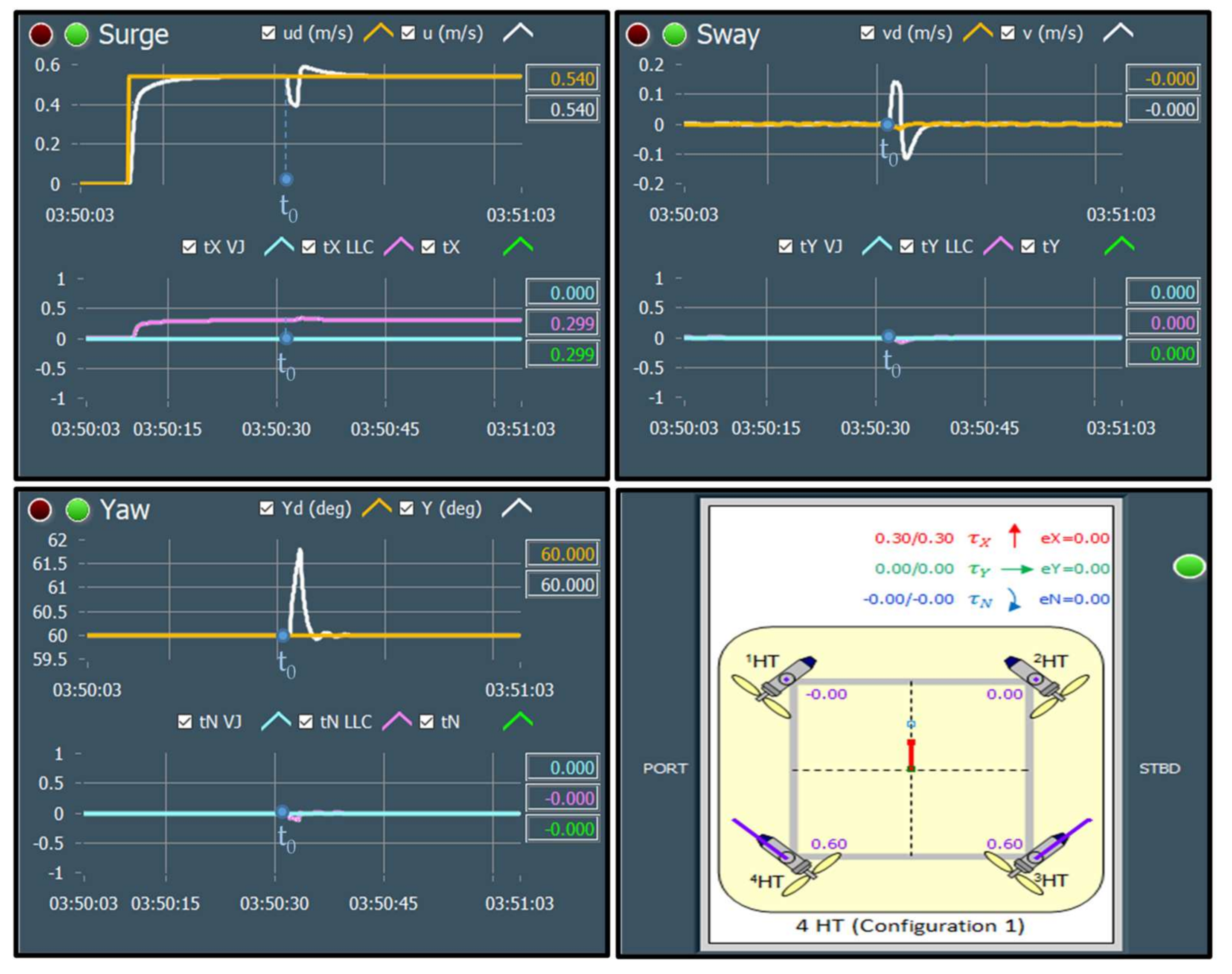
During the initialisation stage of the on-line fault detection phase, training data for each class (acquired in the off-line training phase) are loaded into memory and displayed as separate static background plots versus and versus for each layer (HT Layer 0, HT Layer 1 and VT Layer). These plots are utilised to represent the relationship between variables for different thruster states and for visualisation of actual thruster measurements in real-time. Additional activities during initialisation phase include memory allocation for buffers, reading fault code table settings from file and the creation of action lists.
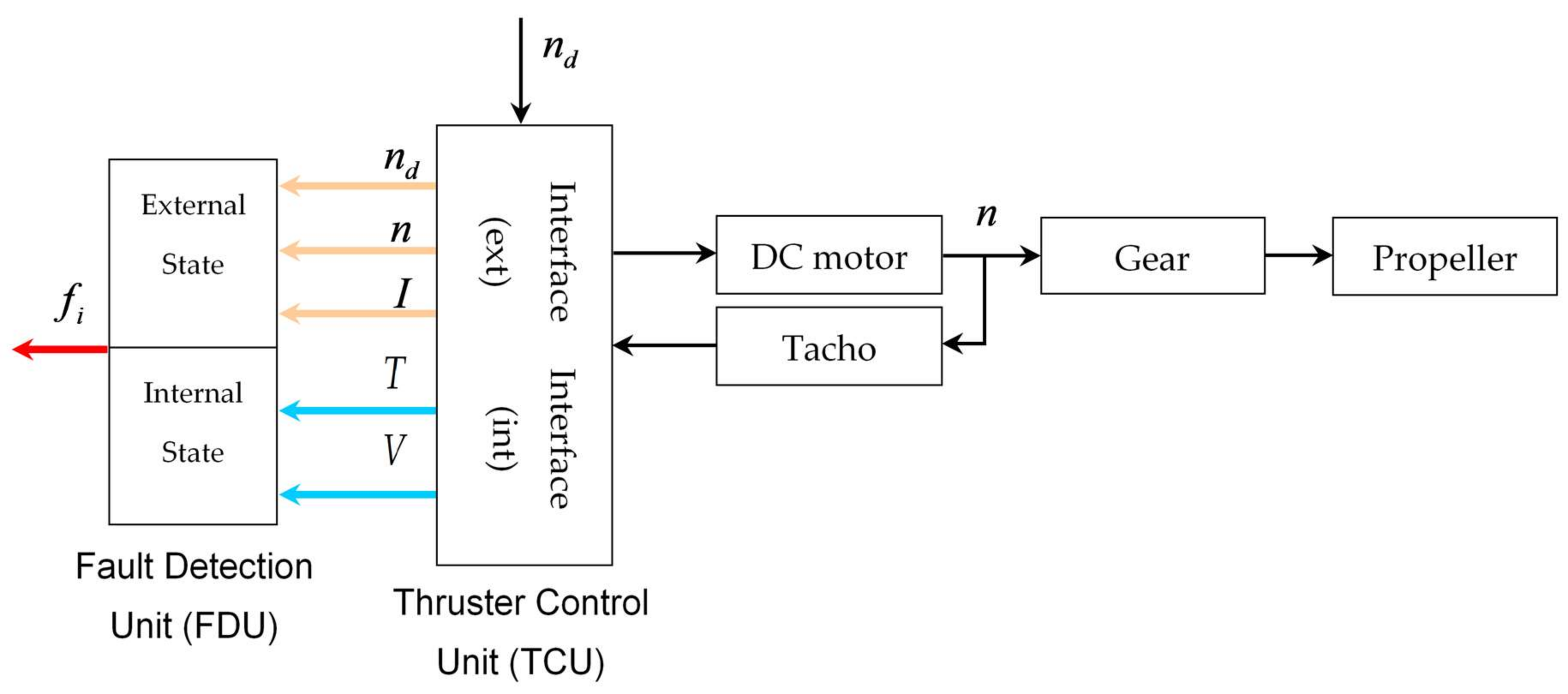
After the initialisation is finished, the fault detection is performed by repeating the steps from the FDU Algorithm (
Table 9) for each thruster at each programme cycle.
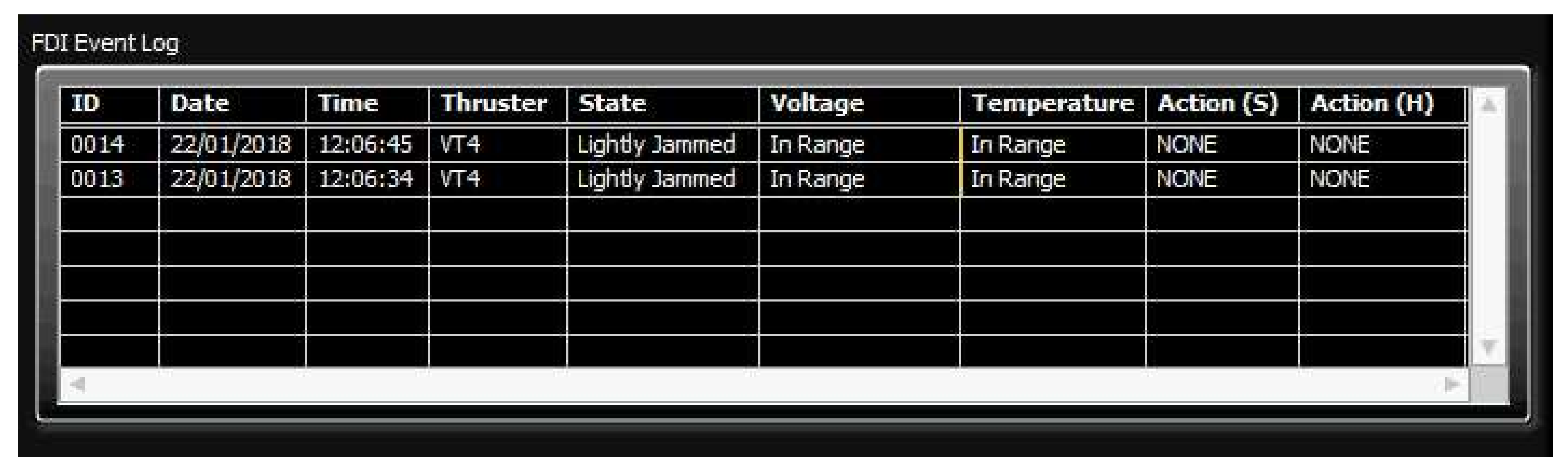
It should be mentioned that, in order to avoid false detection due to outliers and measurement noise, the outputs of FDU Algorithm are buffered i.e., the final decision about thruster fault is not derived from a single measurement, but is accomplished using present and past thruster states (FDU Algorithm outputs), which are stored in the buffer. This buffer operates similar to the shift register: when the new state is pushed into the buffer, the other states are pushed (shifted) down and the ″oldest″ state is pushed (shifted) out. Elements of the buffer are compared to each other, and if all buffer elements have the same value (state), then the aggregate thruster state is set to this value. Otherwise, the previous value is kept as the aggregate state.






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



